안녕하세요. LY Corporation Observability Infrastructure 팀에서 사내 시계열 데이터베이스(time-series database, TSDB)의 개발 및 운영을 맡고 있는 오기준입니다.
LY Corporation의 사내 프라이빗 클라우드 플랫폼은 단순한 가상 머신(virtual machine)을 제공하는 것을 넘어 쿠버네티스(Kubernetes) 기반의 컨테이너 환경과 데이터베이스, 로드 밸런서(load balancer) 등 방대한 서비스 포트폴리오를 제공하고 있습니다. 이처럼 거대한 규모의 인프라와 그 인프라에서 구동되는 수만 개의 애플리케이션 상태를 어떻게 하면 효과적으로 파악하고 관리할 수 있을까요?
만약 서버가 10대나 100대 정도의 수준이라면 엔지니어가 각 서버에 접속해 상태를 확인하는 것이 가능할지도 모릅니다. 하지만 서버가 수만 대를 넘어서고 서비스 구조가 복잡하게 얽혀 있다면 이는 인간의 인지 능력을 넘어서는 영역이 됩니다.

저희 팀은 바로 이 지점에서 '관찰가능성(observability) 플랫폼'을 제공해 문제를 해결합니다. 개발자는 인프라 상태를 신경 쓰지 않고 비즈니스 로직에 집중할 수 있고, 운영자는 데이터에 기반해 시스템을 안정적으로 관리할 수 있도록 지원하는 것이 저희의 핵심 미션입니다.
여기서 관찰가능성이란 무엇일까요? 본래 제어 이론에서 유래한 이 용어는 '시스템의 외부 출력만으로 시스템의 내부 상태를 얼마나 잘 추론할 수 있는가'를 의미합니다. 이를 소프트웨어 공학에 적용하면, 시스템이 뱉어내는 다양한 데이터를 보고 현재 서비스가 건강한지, 어디에 병목이 발생하지는 않았는지 파악하는 능력을 말합니다.
물론 시스템의 모든 출력을 저장하는 것은 물리적으로 불가능합니다. 따라서 현대의 관찰가능성 시스템은 상태를 파악하기 위한 핵심 데이터로 '지표(metric)', '로그(log)', '트레이스(trace)'라는 세 가지 축을 정의해 수집합니다. 이번 글에서는 그중 '지표'를 효율적으로 저장하고 처리하기 위한 기술 여정을 되짚어보고, 데이터 통합과 AI를 더해 '지능형 플랫폼'으로 진화하기 위한 미래 전략을 공유하고자 합니다.
지표 저장소가 관찰가능성에 미치는 영향
IT 시스템 모니터링 분야에서 지표란 '특정 시점의 시스템 상태를 나타내는 숫자에 타임스탬프(timestamp)를 부여한 시계열(time-series) 데이터'를 말합니다. 사용자는 이 시계열 데이터를 시각화해 서비스의 추세를 모니터링하고, 특정 시계열 데이터의 수치가 미리 지정해 놓은 임계치를 넘었을 때 알림을 받습니다. 여기서 더 나아가 최근에는 단순히 'CPU 사용량이 90%를 넘으면 알림을 보낸다'는 식의 사후 대처를 넘어 ARIMA(AutoRegressive Integrated Moving Average)나 Prophet과 같은 시계열 예측 알고리즘을 도입해 장애 징후를 미리 포착하는 사전 대처로 진화하고 있습니다.
서비스 규모가 작을 때는 시계열 데이터를 관리하는 것이 어렵지 않습니다. 하지만 서비스가 성장하고 인프라가 고도화되면 데이터의 양이 기하급수적으로 증가합니다. 이 규모를 체감하기 위해 다음과 같이 태그(tag)의 키/값 크기를 각각 64바이트로 제한한 가상의 시계열 데이터 구조체를 예로 들어 계산해 보겠습니다.
struct tag {
char key[64]; // 64 bytes
char value[64]; // 64 bytes
};
struct timeseries {
uint64_t timestamp; // 8 bytes
struct tag *tags; // 8 bytes in 64 bits system
uint64_t value; // 8 bytes
};만약 서버의 CPU 사용률을 측정하는 지표 하나가 15초마다 생성된다고 가정해 봅시다. 태그 정보(호스트명, 타입 등)를 포함한 하나의 데이터 포인트 크기는 다음과 같이 추산할 수 있습니다.
struct timeseries ts = {
.timestamp = 1625079600, // 8 bytes
.tags = (struct tag[]) { // 8 bytes (for pointer)
[0] = {.key="host", .value="server1"}, // 128 bytes (64 bytes + 64 bytes)
[1] = {.key="type", .value="cpu"}, // 128 bytes
},
.value = 42 // 8 bytes
};지표 하나에 약 280바이트가 소요됩니다. '겨우 280바이트?'라고 생각할 수 있지만 이를 시간과 규모로 확장하면 이야기가 달라집니다. 서버 1대의 CPU 지표만 저장해도 1년에 약 562 MiB가 필요합니다. 만약 서버가 1,000대로 늘어난다면 548 GiB, 여기에 메모리, 디스크, 네트워크 등 기본 지표만 추가해도 연간 저장 용량은 테비바이트(TiB) 단위로 불어납니다.
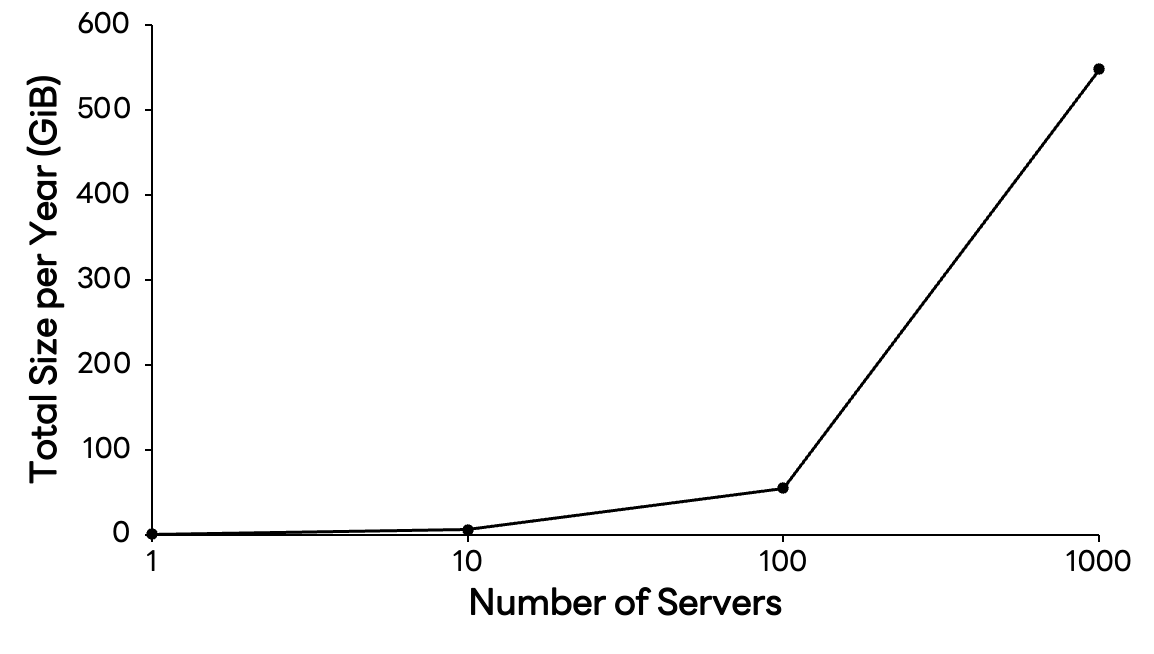
클라우드 네이티브 환경에서는 모니터링 대상(cardinality)이 기하급수적으로 늘어납니다. 이 거대한 데이터의 파도 속에서 '비용 효율적으로 저장하고, 최소 지연으로 조회하는 능력'은 서비스 안정성과 직결됩니다. 범용 데이터베이스로는 해결하기 어려운 이 난제를 풀려면 시계열 특화 엔진(=시계열 데이터베이스)이 필수이며, 저희 팀은 이를 직접 개발해 운영하고 있습니다.
현재 저희 팀의 시계열 데이터베이스는 일간 수조(trillions) 건 규모에 달하는 지표를 처리하고 있습니다. 그렇다면 저희는 과연 어떤 기술적 고민을 거쳐 독자적인 엔진을 개발했고, 어떻게 이 거대한 트래픽을 지탱하는 시스템을 구축할 수 있었을까요?

자체 시계열 데이터베이스 개발까지의 여정: 도전과 극복
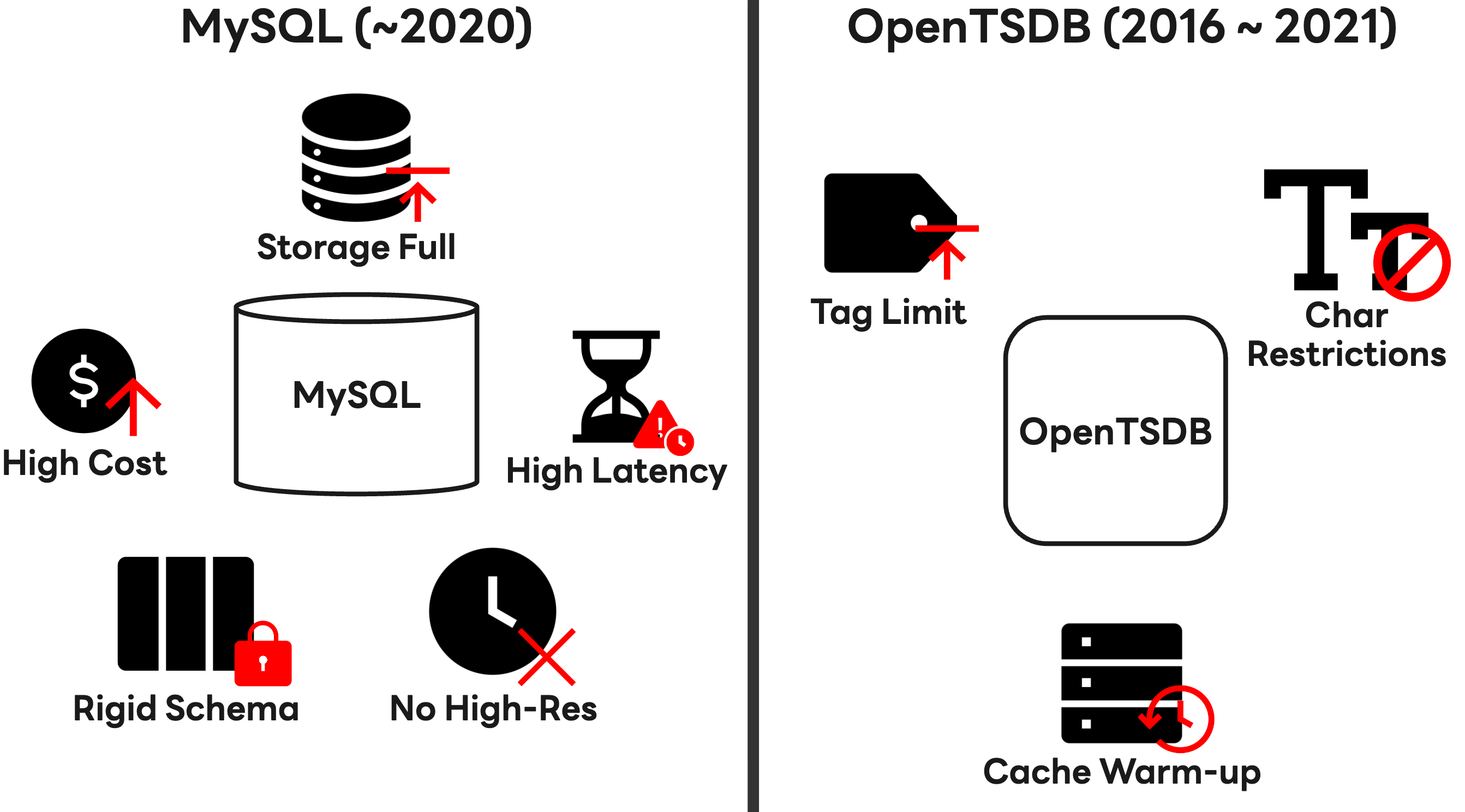
저희 팀은 초기에는 관계형 데이터베이스인 MySQL을 사용해 시계열 데이터를 저장했지만, 아키텍처가 SOA(service oriented architecture)에서 MSA(microservice architecture)로 전환되면서 서비스 컴포넌트가 잘게 쪼개졌습니다. 이에 따라 모니터링해야 할 데이터 증가하면서, 운영 비용 급증과 저장 용량 부족, 쿼리 지연 시간(latency) 증가라는 삼중고에 직면했습니다.
MySQL 샤딩(sharding) 등의 조치를 통해 급한 불은 껐지만 이런 조치가 근본적인 해결책이 되지는 못했습니다. 관계형 데이터베이스의 특성에서 비롯되는 감당하기 힘든 쓰기 부하와 방대한 데이터가 저장된 상황에서의 읽기 성능 때문에 1분 미만의 고해상도 지표 수집이 사실상 어려웠기 때문입니다. 또한 클라우드 환경에서 시시각각 변하는 리소스 정보를 담기에는 태그 스키마(schema) 구조가 너무 경직돼 있었습니다.
이에 저희는 2016년, Apache HBase 기반의 오픈소스 시계열 데이터베이스인 OpenTSDB를 도입했습니다. 도입 초기에는 MySQL 대비 우수한 쓰기 성능을 보여주며 희망을 안겨줬지만, 운영 기간이 길어지면서 다음과 같은 이유로 한계에 부딪혔습니다.
- 태그 활용이 제한적: 태그가 늘어날수록 UID 테이블 조회 성능에 영향을 주는 구조였기에 태그 개수를 현실적으로 제한해야만 했고, 이에 따라 복잡한 현대의 클라우드 리소스를 모두 표현하기가 어려웠습니다.
- 문자 제약:
a-z, A-Z, 0-9, -, _, ., /이외의 문자를 사용할 수 없어서 다양한 언어와 형식을 사용하는 글로벌 서비스의 메타데이터를 담기에 부적합했습니다. - 쿼리 비효율성: 대용량 조회 시 성능을 확보하기 위해서는 데이터를 미리 읽어 캐시에 올리는 '웜업(warm up)' 과정이 필수였고, 이는 운영 복잡도를 높였습니다.
'사용자 경험(UX)을 저해하지 않으면서 급변하는 비즈니스 요구 사항을 즉시 반영할 수는 없을까?'
기존 솔루션으로는 이 질문에 답할 수 없었기에 결국 저희는 자체 엔진 개발이라는 과감한 결단을 내렸습니다. 2018년에 시작한 사내 시계열 데이터베이스 개발 목표는 명확했습니다.
- 유연성: 특정 에이전트에 얽매이지 않는 다양한 프로토콜 지원
- 확장성: 트래픽 폭증에도 선형적으로 성능을 유지하는 무중단 아키텍처
- 성능: 1분 미만의 고해상도 지표를 지연 없이 처리해 데이터 가시성 극대화
- 가용성: 어떤 장애 상황에서도 사용자 경험을 저해하지 않는 견고함
저희는 약 1년의 개발 끝에 2019년, 오픈소스의 장점을 흡수하고 단점을 보완한 자체 시계열 데이터베이스를 완성했습니다.
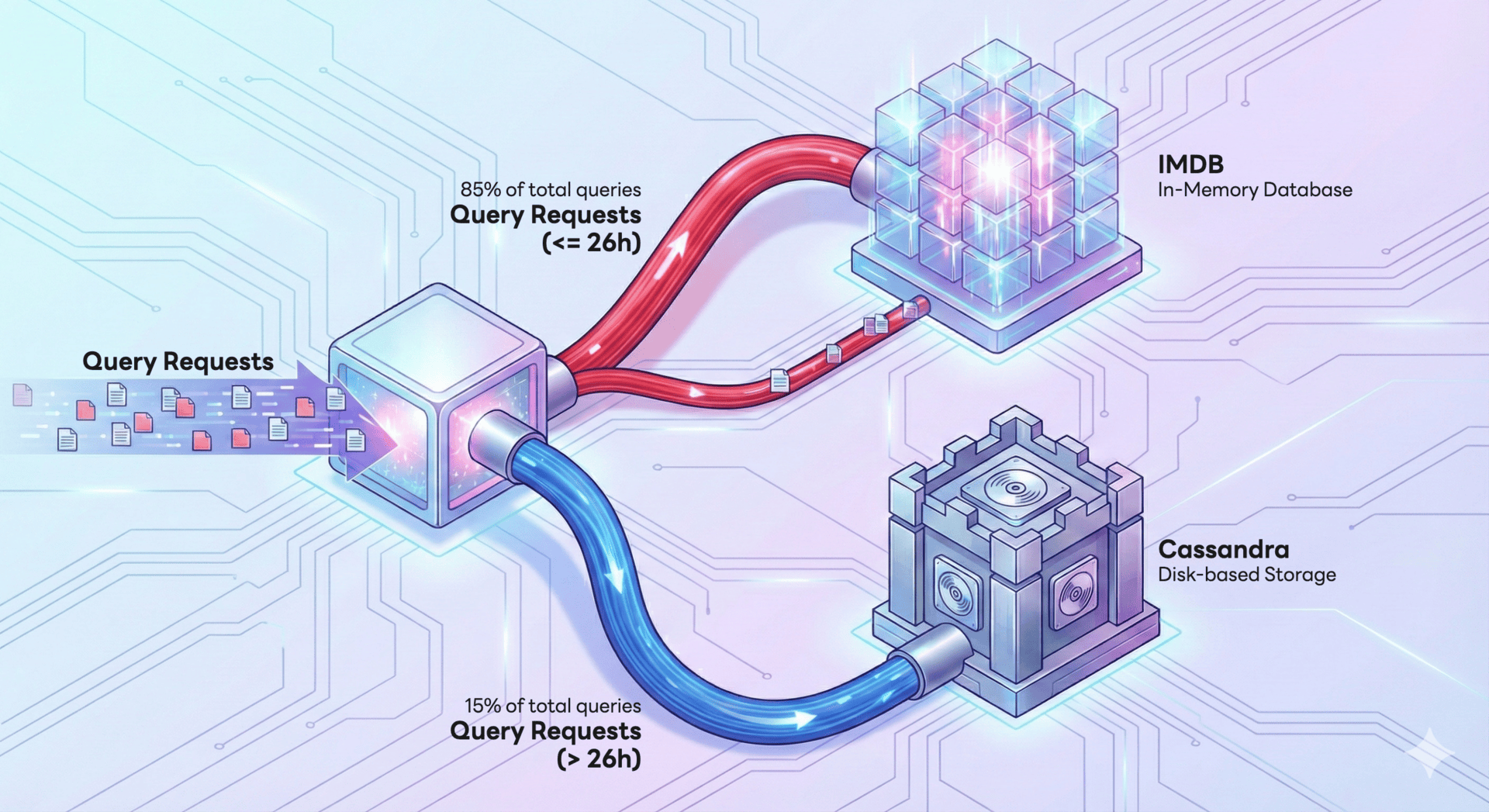
개발 과정에서 얻은 가장 큰 기술적 성과는 데이터 접근 패턴에 기반한 아키텍처 최적화였습니다. 저희는 Meta가 발표한 Gorilla: A fast, scalable, in-memory time series database라는 논문에서 데이터 조회 패턴의 85%가 최근 26시간 내에 집중된다고 말한 점에서 영감을 얻었습니다. 이를 기반으로 성능과 비용의 균형을 맞춘 다중 계층 저장소 전략을 수립했습니다. 구체적으로 말씀드리자면, 자주 접근되는 지표는 IMDB(in-memory database)로 처리해 지연 시간을 최소화하고, 그렇지 않은 데이터는 디스크 기반의 Apache Cassandra(이하 Cassandra)에 저장해 저장 비용을 최적화했습니다. 아래는 이 구조를 형상화한 그림입니다.
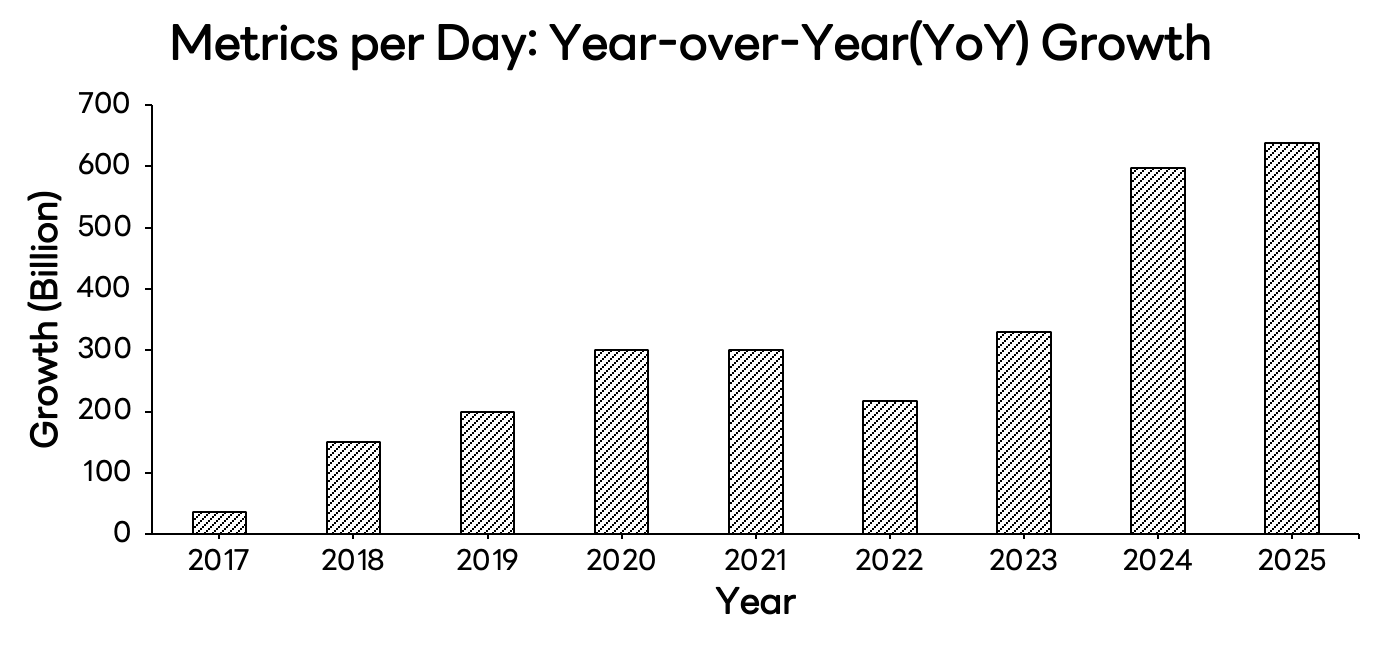
자체 솔루션 도입은 억눌려 있던 기능 요구 사항을 해소하기 위한 기폭제로 작용했고, 2019년 이후 매년 '하루 지표 수집량(metrics/day)'이 전년 대비 2,000억 건 이상씩 늘어나는 성장을 가능케 한 원동력이 되었습니다.
또한 무엇보다도 강조하고 싶은 점은, MySQL에서 시작해 OpenTSDB�를 거쳐 자체 엔진에 이르기까지의 대대적인 변화를 사용자에게 ‘심리스(seamless)’하게 제공했다는 점입니다. 저희는 백엔드 아키텍처를 근본적으로 혁신하면서도 기존 API와의 완벽한 호환성을 유지해 사용자가 별도로 마이그레이션하거나 코드를 수정하지 않아도 자연스럽게 성능 향상의 혜택을 누릴 수 있도록 지원했습니다.
폭증하는 시계열 데이터를 위한 댐
자체 개발의 기쁨도 잠시, 자체 시계열 데이터베이스 출시 이후 사내 인프라 환경은 또 한 번의 격변기를 맞이합니다. 대다수 서비스가 쿠버네티스 환경으로 대거 이관된 것입니다.
가상 머신 환경에서 서버의 수명 주기가 길었지만, 쿠버네티스 환경에서는 파드(pod)가 수시로 생성되고 사라집니다(높은 이탈률). 여기에 볼륨(volume)까지 동적으로 할당되면서, 관찰가능성 플랫폼이 감당해야 할 지표의 양과 복잡도는 상상을 초월하는 수준으로 치솟았습니다. 사용자들은 더 많은 지표와 더 긴 데이터 보관 기간을 요구했고, 이로 인해 저장소 리소스가 급격히 고갈됐습니다.
IMDB와 Cassandra, 두 저장소 모두 확장의 한계에 부딪혔습니다. IMDB 클러스터는 동일한 사양의 장비로만 증설해야 한다는 제약 때문에 노드 확보에 난항을 겪었습니다. Cassandra 클러스터 역시 방대한 데이터로 인해 리밸런싱에 수십 시간이 소요돼 기민한 확장이 불가능했습니다. 홍수가 들이닥치는데 댐 보강 공사가 지연되어 속수무책인 상황과 다를 바 없었습니다.
그렇다면 이 위기를 어떻게 타개해야 할까요? 결론은 홍수에도 끄떡없는 유연하고 견고한 구조를 만드는 것이었습니다. 저희는 댐을 보수하는 차원을 넘어, 다음과 같은 근본적인 아키텍처 개선을 단행했습니다.
- IMDB 최적화: 부하 분산 알고리즘을 노드 간 처리 능력이 다른 점을 고려해 부하를 적절히 분산하는 가중치 기반의 부하 분산 알고리즘으로 개선했습니다.
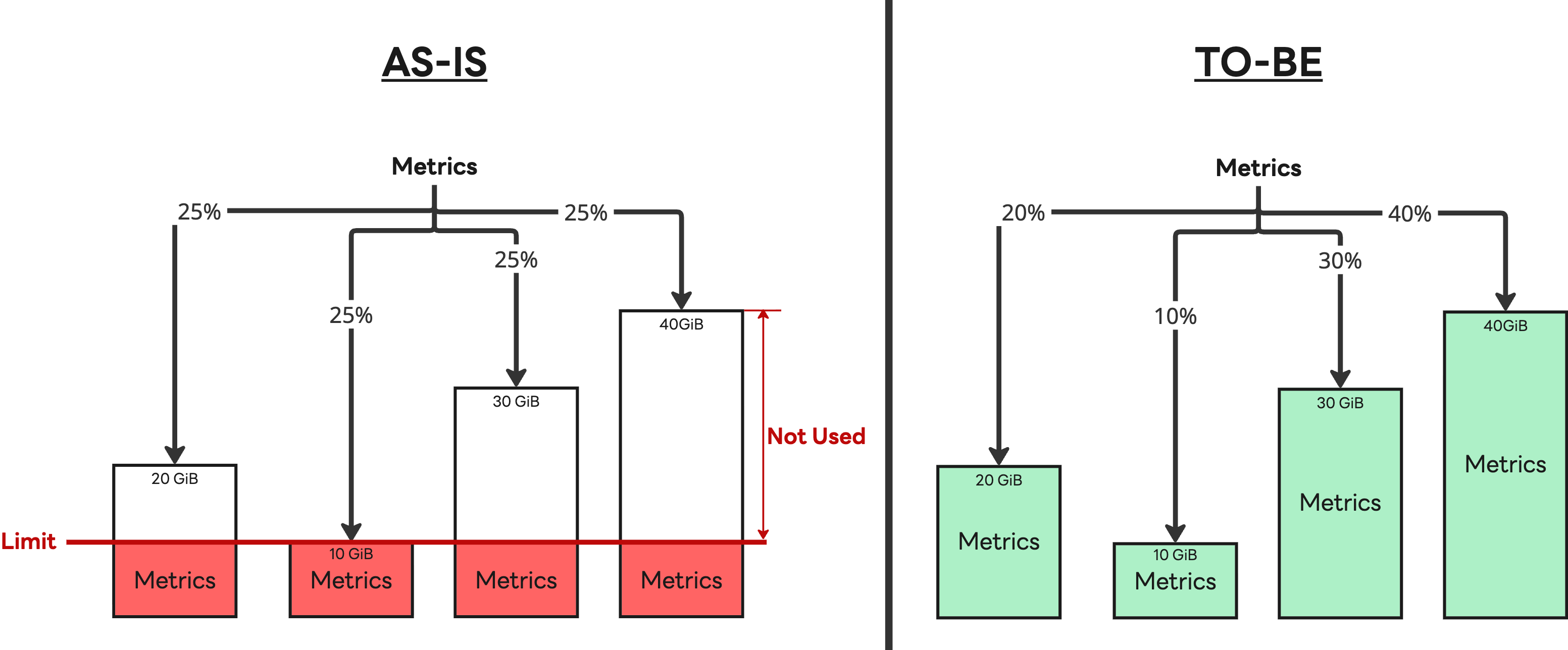
- 계층형 저장소 전략 도입: 모든 데이터를 Cassandra에 저장하던 방식을 버렸습니다. 구조를 단순히 만들기 위해 완전히 이관하는 것도 고려했지만, S3 호환 저장소(캐시 포함)가 Cassandra의 성능을 완전히 대체하기에는 '현재로서는' 아직 이르다고 판단했습니다. 이에 따라 고성능 처리가 필요한 최근 14일치 데이터는 Cassandra에 남겨두고 그 이후의 데이터부터 S3로 적재하는 하이브리드 구조를 채택했습니다.
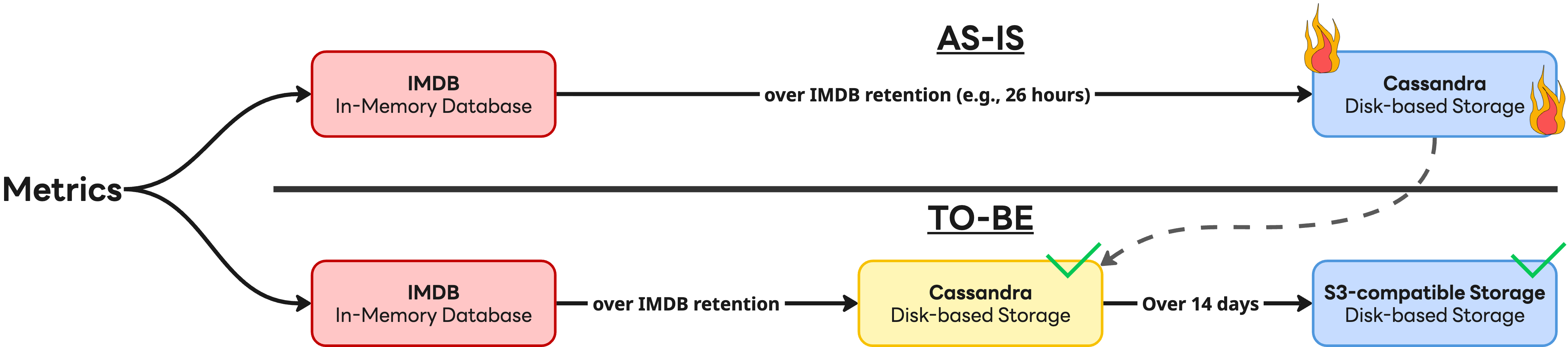
이 전략은 효과적이었습니다. IMDB에 서로 다른 스펙의 노드를 유연하게 투입할 수 있게 돼 변화하는 서버 시장에 기민하게 대응할 수 있었고, Cassandra 의존도를 낮춰 비용 효율화를 달성했습니다. 또한 S3 호환 저장소 도입으로 운영 복잡도가 크게 낮아졌으며, ��더 나아가 주요 컴포넌트들을 쿠버네티스 환경으로 이관함으로써 운영 효율성까지 한층 높일 수 있었습니다.
결과적으로 우리 시스템은 폭증하는 데이터의 홍수 속에서도 물을 안정적으로 가두고(수집), 필요할 때 시원하게 흘려보내는(조회) '거대한 댐'으로 거듭났으며, 덕분에 2024년 이후 더욱 가속화된 대규모 지표 증가세에도 흔들림 없는 운영 안정성을 유지하고 있습니다.
아키텍처 전환 이면에 숨겨진 기술적 도전과 협업
저희는 사용자에게 '코드 수정(breaking changes)'이라는 번거로움을 드리지 않으면서 S3 호환 저장소의 확장성을 온전히 누릴 수 있도록 서비스를 제공하고 싶었고, 고민 끝에 쓰기와 읽기 역할을 분리한 계층형 구조를 도입했습니다.
쓰기 과정은 두 단계로 나뉩니다. 먼저 배치 작업을 수행하는 '덤퍼(Dumper)'가 IMDB에서의 지표 묶음인 '슬롯(slot)' 단위로 데이터를 읽어 자체 정의한 규격의 '서브 블록(sub-block)'으로 변환해 전달합니다. 이어서 '블록 덤퍼(Block Dumper)'가 이 서브 블록들을 취합하고, 최종적으로 하나의 '블록(Block)'으로 패키징해 S3에 적재합니다. 다음은 쓰기 과정의 전체적인 흐름을 나타낸 그림입니다.
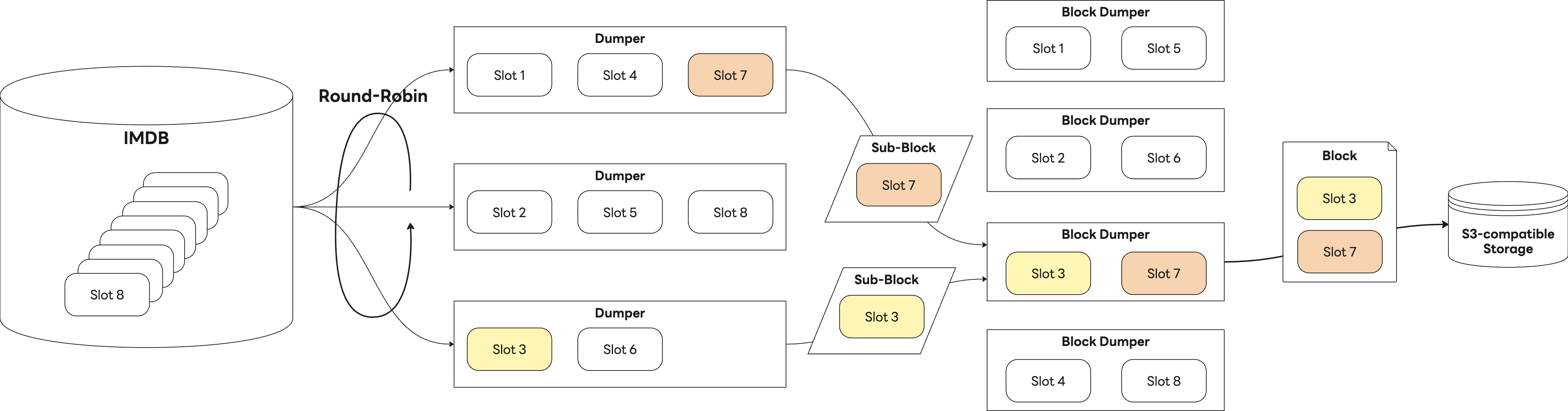
한편 데이터 조회는 'Storage Gateway'가 이 블록을 읽어 처리하는 구조입니다. 다음은 읽기 과정의 전체적인 흐름을 나타낸 그림입니다.
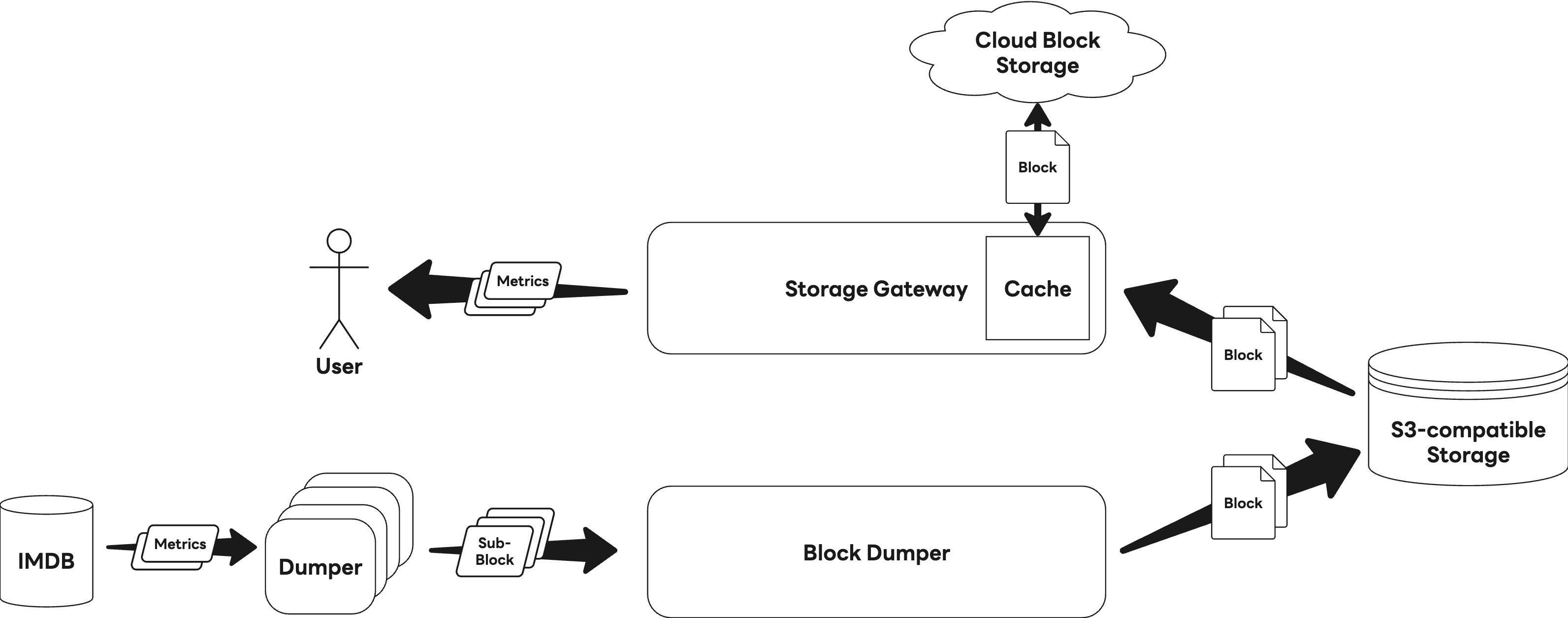
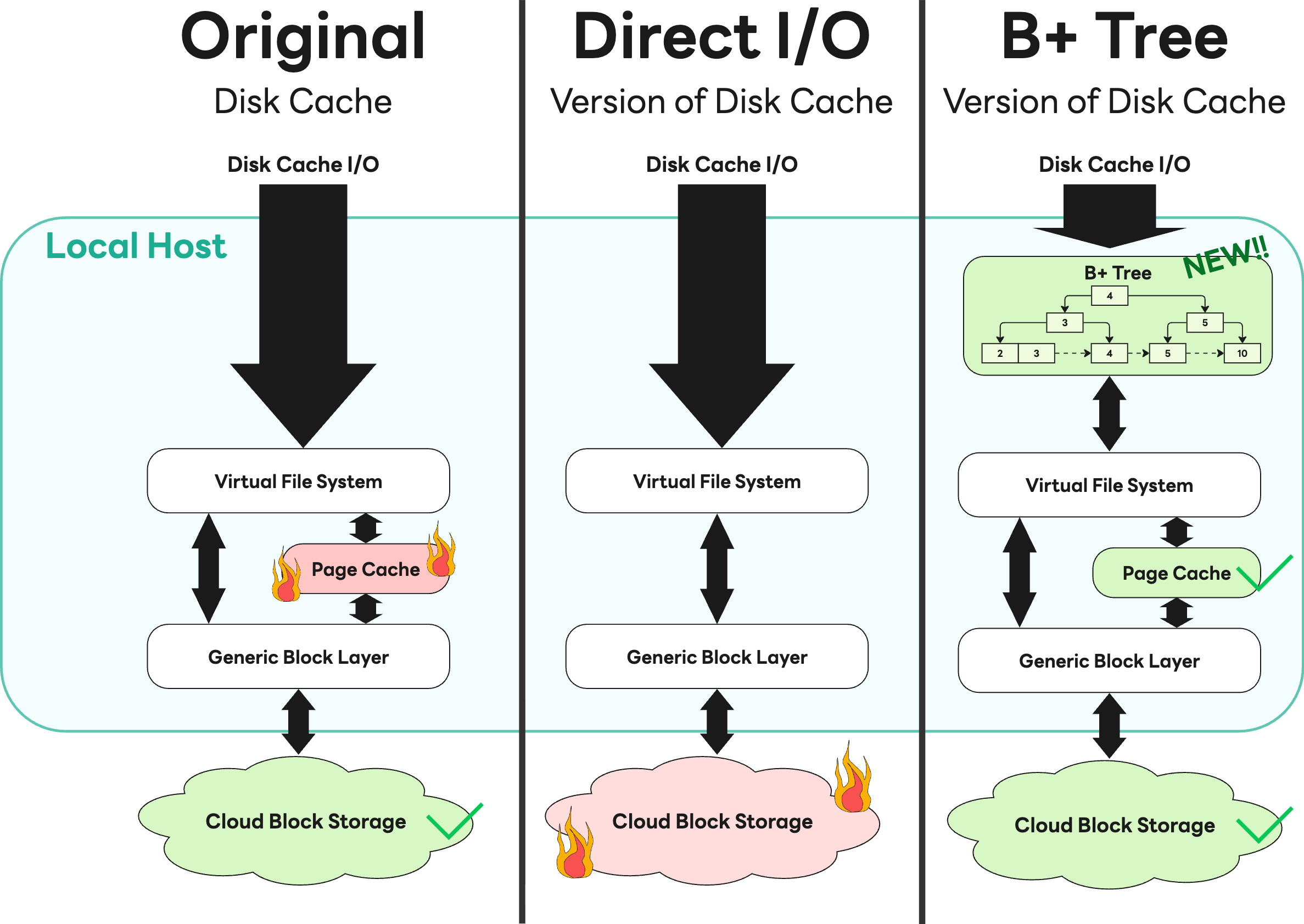
여기서 Storage Gateway는 읽기 성능을 극대화하기 위해 S3에서 가져온 블록 데이터를 디스크에 캐싱(caching)하는 기능을 탑재했는데요. 이 캐시가 다량의 I/O 과정에서 페이지 캐시(page cache) 사용률을 급증시켰고, 결국 메모리가 빠르게 고갈되는 문제점을 야기했습니다.
처음에는 직접 I/O(Direct I/O)를 적용해 해결하려 했으나, 사내 클라우드 스토리지 팀에서 '과도한 대역폭 점유로 타 서비스에 영향을 준다'고 긴급 피드백을 전달해 왔습니다. 저희는 즉시 문제를 공유하고 유관 부서와 머리를 맞댔습니다. 그 결과 직접 I/O 적용을 철회하고, 커널의 페이지 캐시를 효율적으로 활용하는 B+ 트리 기반 캐시로 전환하는 해법을 찾았습니다. 인프라에 무리를 주지 않으면서 성능까지 확보한 이 사례는, 실패를 감추지 않고 소통했기에 최적의 해답을 찾을 수 있었던 값진 경험이었습니다.
향후 계획: 앞으로의 시계열 데이터베이스
AI 시대가 도래함에 따라 데이터의 가치는 '기록'에서 '예측'과 '지능'으로 진화하고 있습니다. 이에 저희 팀의 지향점 또한 단순한 '저장'을 넘어 더 높은 차원의 '활용'을 향하고 있습니다. 이러한 '예측'과 '지능'을 실현하기 위해서는 사내에 파편화돼 저장돼 있는 시계열 데이터를 한곳으로 모으는 과정이 선행돼야 합니다.

하지만 이 통합 과정이 사용자에게 마이그레이션 부담을 지운다면, 기술 관점에서는 진보일지라도 비즈니스 관점에서는 득보다 실이 큰 선택이 될 수 있음을 잘 알고 있습니다. 그렇기에 저희는 지난 수년간 수조 건 규모의 데이터를 이관하면서도 사용자 경험을 보존해 온 경험을 다시 한번 발휘하고자 합니다. 이 검증된 노하우를 바탕으로 현재 사내 곳곳에 산재해 있는 다양한 시계열 데이터베이스들을 '자체 구축한 단일 솔루션'으로 통합해 나갈 예정입니다.
이렇게 하나로 통합된 자체 플랫폼은 AI 기술 혁신의 이점을 흡수하면서도 안정적인 서비스를 가능케 해 사용자에게 다음과 같은 가치를 제공할 수 있을 것으로 기대합니다.
- 데이터의 중앙 집중화(centralized platform): 파편화된 시계열 데이터를 한곳에 모아 데이터 분석가와 엔지니어가 언제든 접근할 수 있는 환경을 만듭니다.
- AIOps 및 예측(forecasting) 고도화: 축적된 방대한 시계열 데이터를 AI 모델과 결합합니다. 사용자가 복잡한 통계 설정 없이도 서비스의 이상 징후를 자동으로 탐지하고 트��래픽 변화를 예측할 수 있는 인텔리전트 엔드포인트를 제공할 예정입니다.
- MCP(model context protocol) 연동: LLM(large language model, 대규모 언어 모델)이 운영 데이터를 쉽게 이해하고 조회할 수 있는 표준 인터페이스를 구축해서 사용자가 자연어로 "지난주 트래픽 이상 원인이 뭐야?"라고 물으면 시스템이 데이터를 분석해 답하는 미래를 그리고 있습니다.
저희의 도전은 멈추지 않습니다. LY Corporation의 기술 성장을 뒷받침하는 든든한 기반이 될 수 있도록 관찰가능성 플랫폼은 오늘도 진화하고 있습니다.
참고 문헌
- Majors, C., Fong-Jones, L., & Miranda, G. (2022). Observability Engineering. O'Reilly Media.
- Naqvi, S. N. Z., Yfantidou, S., & Zimányi, E. (2017). Time series databases and influxdb. Studienarbeit, Université Libre de Bruxelles, 12, 1-44.
- Pelkonen, T., Franklin, S., Teller, J., Cavallaro, P., Huang, Q., Meza, J., & Veeraraghavan, K. (2015). Gorilla: A fast, scalable, in-memory time series database. Proceedings of the VLDB Endowment, 8(12), 1816-1827.
- Dunning, T., & Friedman, E. (2015). Time Series Databases: New Ways to Store and Access Data. O'Reilly Media.
- OpenTSDB. (n.d.). Writing data. https://opentsdb.net/docs/build/html/user_guide/writing/index.html#naming-conclusion


