들어가며
지난 엔터프라이즈 LLM 서비스 구축기 1: 컨텍스트 엔지니어링에서는 260개의 도구와 수백 페이지의 문서를 다루는 환경에서 LLM에게 필요한 정보만 골라서 제공하는 '점진적 공개' 전략을 공유해 드렸습니다. 1편이 AI에게 '무엇을 전달할 것인가?'에 대한 답이었다면, 이번 2편은 그 다음 질문으로 넘어갑니다. 정제된 맥락을 전달받는 에이전트를 '어떻게 만들 것인가?'입니다.
본격적인 이야기에 앞서, 먼저 현재 Flava AI 어시스턴트(이하 FAA)의 실전 성적표를 공개합니다. 저희 팀은 FAA 릴리스 후에도 매일 쏟아지는 사용자의 질문 패턴과 AI의 답변 결과를 추적하는 '인텔리전스 리포트' 시스템을 자체 구축해 모니터링하고 있습니다.
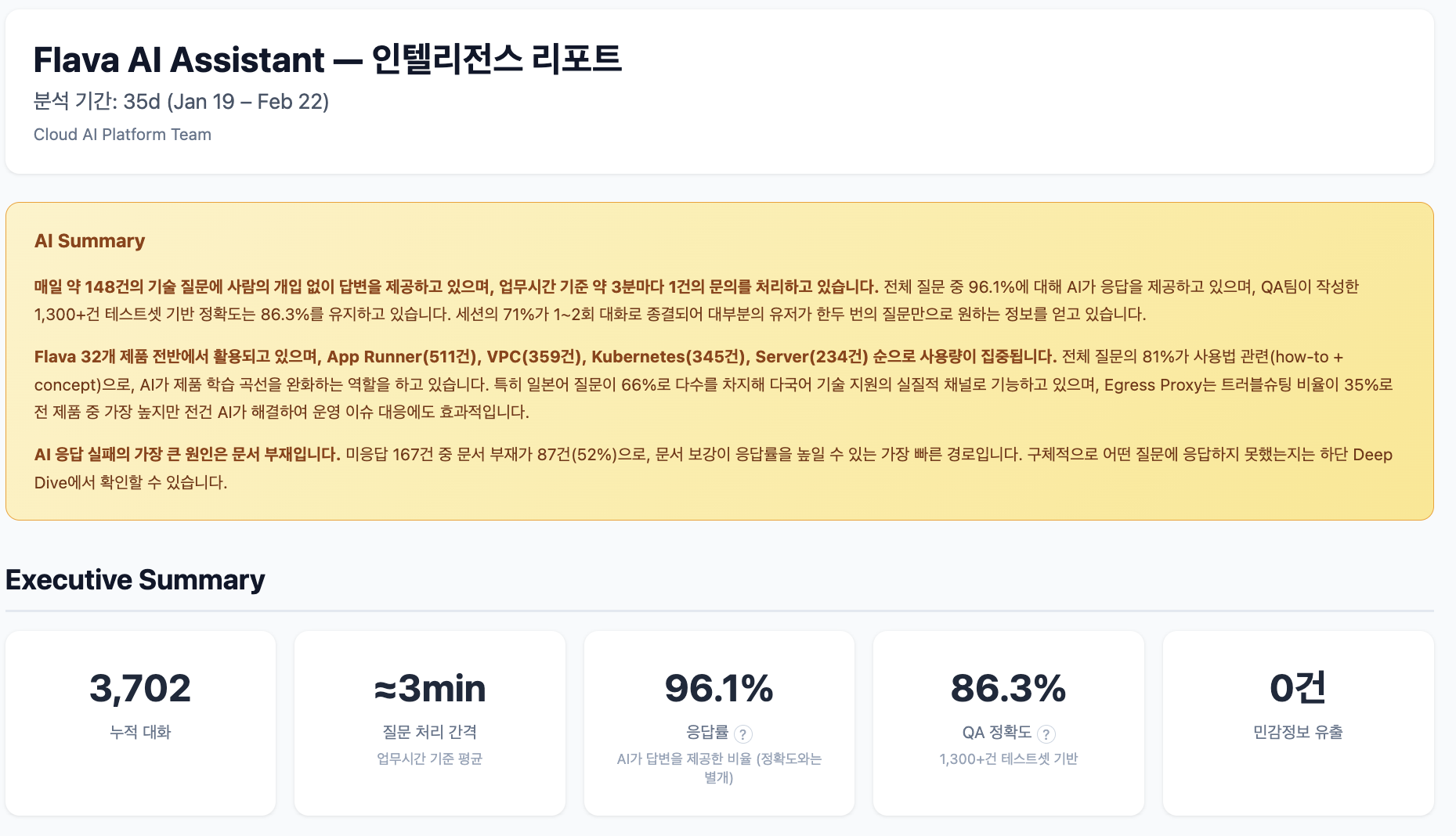
현재 FAA는 Flava 관련 문의의 약 96.1%에 대해 답변을 제공하고 있습니다. 여기서 응답률은 별도 평가 모델이 매 대화를 분석해서 AI가 실질적인 답변을 제공했는지를 자동으로 판정한 수치이며, 답변의 정확도와는 별개입니다. 답변 품질과 관련해서는 별도 평가 체계를 운영하고 있으며, 이번 글에서는 이와 관련된 이야기는 일단 배제하고 기술 선택에 집중하겠습니다.
이 수치는 화려한 기술을 도입해서 얻은 결과가 아닙니다. 오히려 그 반대입니다. 제한된 비용과 속도라는 현실 속에서 '어떤 기술을 취하고 ��어떤 기술을 버릴 것인가?'를 결정하기 위한 소거법의 결과물입니다.
시리즈 로드맵
본격적으로 이야기를 시작하기 전에 이 시리즈의 각 편에서 다룰 주제를 소개하겠습니다.
![[그림 2] AI 에이전트 개선을 위한 기술 영역](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/e6213488844340edbadb8be4f83cbadd.png?updatedAt=1772615094000)
지난 1편에서는 컨텍스트 엔지니어링을 다뤘고, 다음 3편에서는 프롬프트 엔지니어링을 다룰 예정입니다. 이번 2편에서는 모델 파인 튜닝과 에이전틱(agentic) 워크플로의 두 영역에서 마주한 아래 세 가지 갈림길을 다룹니다.
- AI에게 지식을 어떻게 줄 것인가? 파인 튜닝 vs RAG
- 문서를 어떻게 찾을 것인가? 청킹(chunking) vs 검색 후 자르기(post-split)
- 어떻게 행동할 것인가? 복잡한 워크플로 vs ReAct(reasoning and acting)
1. AI에게 지식을 어떻게 줄 것인가? 파인 튜닝을 제외하다
AI 서비스를 오픈하면 가장 많이 듣는 질문 중 하나가 "AI가 우리 사내 문서를 다 학습한 것인가요?"입니다. 결론부터 말씀드리면, 아닙니다. FAA는 사내 문서를 '학습(파인 튜닝)'한 것이 아니라 '참조(retrieval)'합니다. 시험에 비유하면 파인 튜닝은 교과서를 외운 뒤 기억만으로 시험을 보는 것이고, RAG(retrieval-augmented generation)는 교과서를 펴놓고 찾아보며 답을 쓰는 오픈북 시험입니다.
저희도 초기에는 파인 튜닝을 진지하게 검토했는데요. 두 가지 이유로 내려놓았습니다.
첫째, 파인 튜닝은 지식 주입에 비효율��적입니다. UC Berkeley와 Google Research의 From Style to Facts (Zhao et al., 2025) 연구에서 Gemini 모델 700개를 대상으로 실험한 결과, 위키백과 형식의 학습 데이터로 새로운 지식을 주입한 뒤 QA 형식으로 평가했을 때 답변 정확도는 약 11%에 불과했습니다. 반면 말투를 바꾸는 데는 약 97%의 성공률을 보였습니다. 학습과 평가의 형식을 맞추면 지식 주입 정확도도 올라가지만, 그만큼 양질의 데이터를 구성하기 위한 난이도도 함께 올라갑니다. 결과적으로 파인 튜닝은 '무엇(what)을 알게 하는 도구'가 아니라 '어떻게(how) 말하게 하는 도구'로 사용할 때 더 효과적입니다.
둘째, 직접 실험해 본 결과 기존 지식의 벽을 넘지 못했습니다. 'Flava란 무엇인가'처럼 절대 변하지 않는 기본 지식만 골라 약 40개의 학습 데이터를 만들었습니다. 자주 바뀌는 제품 스펙이 아니라 플랫폼의 기초 개념만 담았기에, 데이터셋 크기는 작더라도 파인튜닝이 잘 동작해야 하는 조건이었습니다.
실험 결과, 아래와 같이 모델은 학습 데이터에 사용한 질문(Flava란 무엇인가?)을 그대로 던질 때에는 정확한 답변을 내놓았지만, 학습한 질문에서 조금만 다르게 질문해도 잘못된 답변을 내놓았습니다. 대규모 텍스트로 형성된 기존 지식을 수십 개의 학습 데이터로 완전히 덮을 수는 없었던 것입니다.
![[그림 3] 파인 튜닝 실험 결과](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/584e6d7fdb0b467fab12d7407cd649bf.png?updatedAt=1772615146000)
40개의 학습 데이터셋이 부족하다면 400개, 4,000개로 늘리면 되지 않겠냐는 의문이 들 수 있습니다. 하지만 양질의 학습 데이터를 만들려면 도메인 전문가가 질문을 설계하고, 정답을 작성하고, 교차 검수까지 해야 합니다. 게다가 Flava의 제품 문서는 수시로 갱신되기 때문에 문서가 바뀔 때마다 관련 학습 데이터를 찾아 동기화하는 유지 보수 비용이 끊임없이 발생합니다. 반면 RAG는 원본 문서만 업데이트하면 됩니다.
물론 파인 튜닝이 항상 비효율적인 것은 아닙니다. 의료나 법률 같은 전문 도메인에서는 파인 튜닝으로 인상적인 성과를 보인 사례가 있습니다. 다만 이러한 성과는 새로운 사실을 주입한 것이 아니라, 도메인 특화 추론 패턴과 용어 체계를 학습한 결과입니다. FAA의 과제는 수시로 바뀌는 제품 문서에서 정확한 최신 정보를 전달하는 것이었기에 지식을 모델에 주입하는 것보다 문서를 직접 참조하는 RAG가 적합했습니다.
의사 결정 #1: 파인 튜닝 제외. 파인 튜닝으로 지식을 주입하려면 양질의 데이터를 구성하기 위한 부담이 크고, 직접 실험해 본 결과도 이를 뒷받침했습니다. 데이터셋 규모를 키우는 것은 이론적으로는 가능하지만, 문서가 바뀔 때마다 학습 데이터도 함께 갱신해야 하는 유지 보수 비용까지 고려하면 문서를 직접 참조하는 오픈북(RAG) 방식이 합리적인 선택이었습니다.
2. 문서를 어떻게 찾을 것인가? 청킹하지 않는 RAG
파인 튜닝 대신 RAG에 모든 것을 걸기로 했으니 검색 전략은 저희에게 가장 중요한 전장이었습니다. 그 전장에서 가장 치열한 전투를 치러야 했던 의사 결정 하나를 자세히 살펴보겠습니다.
대부분의 RAG 시스템이 문서를 자르는 이유
RAG 시스템을 구축할 때 가장 먼저 하는 일은 문서를 잘게 쪼개는 청킹입니다. 이유는 간단합니다. 텍스트를 수학적 벡터로 변환하는 과정을 임베딩(embedding)이라고 하는데 의미가 비슷한 텍스트는 벡터값도 비슷하므로 '의미로 검색'하는 것이 가능해집니다. 조각이 작을수록 이 벡터가 특정 의미를 더 정교하게 가리키고요.
예를 들어 사용자가 "오브젝트 스토리지 용량은 최대 얼마까지 가능해?"라고 물었을 때, 이 내용만 담긴 200토큰짜리 청크가 존재한다면 질문과의 벡터 유사도가 매우 높게 나옵니다. 반면 같은 내용이 5,000토큰짜리 가이드 문서 속 한 줄로 묻혀 있다면 그 문서의 벡터는 여러 주제가 뒤섞인 모호한 위치를 가리킵니다. 당연히 검색 정확도가 떨어지겠죠.
청킹의 대가: 문맥 상실
하지만 문서를 자르면 전후 문맥이 사라집니다. 예를 들어 "이 경우에는 아래 설정을 적용하세요"라는 문장이 청크의 경계에서 잘리면 '이 경우'가 무엇인지, '아래 설정'이 무엇인지와 관련된 문맥을 잃어버립니다.
이를 보완하기 위해 청크 간 겹치는 구간(overlap)을 두는 것이 일반적이며, 최근에는 청크에 원본 문맥을 첨부하는 문맥 검색(contextual retrieval)이나 문서 전체를 먼저 읽어 단어들 사이의 관계를 파악한 뒤에 구역을 나누는 지연 청킹(late chunking) 같은 기법이 제안되고 있습니다. 하지만 이 모든 것은 결국 '자른 뒤 생긴 문제를 수습하려는 노력'입니다. 자르지 않으면 수습할 필요도 없겠죠.
역발상: 자르지 않기로 했습니다
문서를 통째로 임베딩하면 특정 정보의 벡터값이 희석되지 않을까 걱정할 수 있는데요. 저희가 이 역발상을 택할 수 있었던 것은 FAA가 참조하는 문서의 특성 덕분입니다.
- 명확한 주제: 각 문서가 하나의 제품(VM, Redis 등)에 대한 하나의 주제(생성, 삭제, 설정 등)만 다룹니다.
- 적은 분량: 대부분의 가이드 문서가 A4 수 페이지 분량입니다.
이미 잘 정리된 문서를 억지로 쪼개면 오히려 완결된 문맥을 파괴하는 셈입니다. 법률 문서처럼 수십 페이지에 걸쳐 맥락이 이어지는 데이터라면 청킹이 필수겠지만, 저희 데이터에는 해당하지 않았죠. 그래서 저희는 문서를 통째로 임베딩하고 검색 이후에 필요한 부분만 잘라내는 '검색 후 자르기(post-split)' 전략을 택했습니다.
검색 후 자르기: 검색은 통째로, 추출은 정밀하게
구체적인 흐름을 따라가 보겠습니다. 다음은 사용자가 "VM을 만들고 삭제하는 방법 알려줘"라고 질문했다고 가정했을 때 작동 흐름입니다.
![[그림 4] 검색 후 자르기 파이프라인](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/b9c8aaa4caac4583b261c4030f59f1dc.png?updatedAt=1772618472000)
위 흐름을 각 단계별로 살펴보겠습니다.
검색 단계: 통째로 찾기
각 문서를 통째로 임베딩합니다. 검색 시에는 질문의 대상 제품을 파악하여 해당 제품의 문서군 안에서만 검색을 수행합니다. 사용자가 “VM을 만들고 삭제하는 방법 알려줘”라고 물으면 VM 가이드 문서가 개요, 생성, 사양 변경, 삭제 등의 내용을 모두 담은 채로 통째로 검색됩니다.
정제 단계: 필요한 부분만 잘라내기
문서를 통째로 가져왔기 때문에 불필요한 내용이 섞여 있을 수 있는데요. 여기서 두 �단계의 정제를 거칩니다.
- 1단계: 헤더 기반 분할. 마크다운 형식의 검색된 문서를 헤더(
##) 구조를 기준으로 의미 단위의 조각으로 나눕니다. - 2단계: LLM 필터링. 나뉜 조각들의 헤더 목록을 경량 LLM에게 보여주며, 질문에 관련 있는 조각만 골라내도록 합니다.
질문: "VM을 만들고 삭제하는 방법 알려줘"
프롬프트: "다음 섹션 중 질문과 관련 있는 인덱스를 골라줘"
→ LLM 응답: [1, 3]최종적으로 메인 LLM에게는 위 그림과 같이 [1] VM 생성 방법과 [3] VM 삭제 방법 두 조각만 전달됩니다. 5개 섹션 중 질문에 꼭 필요한 2개만 남긴 것이죠. "LLM을 한 번 더 호출하면 느려지지 않나요?"라고 질문할 수 있는데요. LLM 호출 비용은 크게 두 부분으로 나뉩니다. 입력 토큰을 처리하여 첫 번째 토큰이 나올 때까지의 시간(time to first token, TTFT)과 이후 출력 토큰을 생성하는 시간입니다. 그런데 LLM 필터는 출력 부분이 특히 가볍습니다. 문서 전체 내용을 출력하는 것이 아니라 인덱스만 출력하면 되니 출력 시간도 짧고, 토큰 비용도 거의 들지 않죠. 일반적으로 출력 토큰이 입력 토큰보다 수 배 비싼 데 반해, LLM 필터를 이용하면 추가 LLM 호출 비용 부담 없이 정밀한 필터링이라는 이점만 취할 수 있습니다.
청킹하지 않고 검색 후 자르는 방식이 통한 이유
핵심은 '자르는 시점'입니다.
![[그림 5] 임베딩 전 자르기(pre-split) vs 검색 후 자르기(post-split)](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/2583359ebee244c590f28cda03d51675.png?updatedAt=1772615232000)
일반적인 RAG는 임베딩 전에 자릅니다(pre-split). 이 시점에서는 아직 어떤 질문이 들어올지 모르기 때문에 기계적으로 자를 수밖에 없습니다. 반면 검색 후 자르기 방식에서는 검색 이후, 즉 질문을 이미 알고 있는 상태에서 자릅니다. 결과적으로 수천 토큰의 원문이나 문맥이 상실된 청크 대신 질문에 딱 맞는 핵심 조각들만 모은 가볍고 정제된 컨텍스트를 배달받게 됩니다.
의사 결정 #2: 청킹 대신 검색 후 자르기. 모든 RAG에 청킹이 필요한 것은 아닙니다. 문서의 특성(크기, 구조, 주제의 명확성)에 따라 '통째로 검색하고 나중에 자르는 것'이 문맥 손실 없이 더 정확한 결과를 낼 수도 있습니다. 자를 시점에 질문의 맥락을 알고 있다는 것, 그 차이가 결정적이었습니다.
3. 어떻게 행동할 것인가? 복잡한 워크플로 대신 ReAct 선택
마지막 갈림길, 에이전틱 워크플로(agentic workflow)입니다. LLM이 문제를 풀어가는 행동 구조를 설계하는 영역으로, 단순한 반복 루프면 충분한지 아니면 사전 계획이나 전문가 분업이 필요한지를 따져 봤습니다.
계획 후 실행(plan-and-execute): 계획을 세워주면 더 잘할까?
계획 후 실행 방식은 복잡한 질문을 먼저 하위 태스크로 쪼개어 계획을 세운 뒤 순차적으로 실행하는 접근법입니다. 반면 저희가 최종적으로 택한 ReAct(reasoning and acting)는 한 걸음 걷고, 결과를 확인한 뒤, 다음 걸음을 결정하는 단순한 루틴입니다.
![[그림 6] 계획 후 실행 vs ReAct](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/fbc2585d2c6c4678832f4640bc906eca.png?updatedAt=1772615270000)
FAA에서는 계획 후 실행 방식을 도입하지 않았습니다. 초기에 구현하여 테스트해 봤지만, 계획 수립과 재 계획 로직이 더해지면서 시스템 복잡도는 크게 늘어난 반면 답변 품질이 개선된지는 체감하기 어려웠습니다.
모델은 좋은 도구와 충분한 맥락을 주면 별도 계획 없이도 논리적 순서를 만들어 냅니다. 1편에서 다룬 점진적 공개로 260개 도구를 정리하고, 이번 글에서 소개한 검색 후 자르기로 정제된 컨텍스트를 전달하니, 에이전트는 복잡한 트러블슈팅 질문에서도 필요한 도구를 순서대로 호출하며 스스로 답을 찾아갔습니다.
흥미롭게도 이는 FAA만의 경험이 아닙니다. 코딩처럼 고도로 복잡한 영역의 에이전트에서도 계획과 실행을 엄격히 분리하는 대신 매 단계마다 추론과 행동을 반복하는 에이전틱 루프를 택하는 추세입니다(참고: How Claude Code works).
멀티 에이전트: 전문가를 나누면 더 잘할까?
다음으로 멀티 에이전트(multi-agent) 구조도 검토했습니다. 'VM 전문가', '쿠버네티스 전문가'와 같이 에이전트 역할을 나눈 뒤 질문을 배분하는 방식입니다. 실제로 쿠버네티스 API 전문가 에이전트를 분리해 테스트한 결과 단순한 질문에서도 응답 시간이 약 50%(9초 -> 14초) 증가했습니다. 전문가 에이전트에게 질문을 위임하고 결과를 조립하기 위해 LLM 호출이 2회 추가되기 때문입니다. 더 큰 문제는 크로스 도메인 질문이었습니다. "VM에서 오브젝트 스토리지로 데이터를 옮기려면 어떻게 해?"라는 ��질문은 어느 전문가에게 보내야 할까요? 각 전문가는 자기 도메인만 알기 때문에 전체 맥락이 필요한 질문에서 정보를 빠뜨리는 문제가 있었습니다. 이와 같은 점을 고려할 때 멀티 에이전트도 답이 아니었습니다.
기본으로 돌아가다: ReAct
결국 저희가 한 일은 화려한 프레임워크를 도입한 것이 아니라 ‘기본에 머무르는 것’이었습니다. FAA의 에이전트는 가장 단순한 형태인 ReAct 방식으로 작동합니다. 복잡한 질문이 들어와도 모델은 스스로 필요한 도구를 순서대로 호출하며 답을 찾아갑니다.
의사 결정 #3: 기본에 머무르기. 좋은 도구와 충분한 맥락이 주어지면 복잡한 워크플로 없이도 모델은 논리적 순서를 만들어 냅니다. 컨텍스트 엔지니어링과 검색 후 자르기로 기반을 다진 뒤 모델을 믿는 ReAct가 더 나은 선택이었습니다.
마치며
처음에 펼쳤던 기술 지도를 다시 들여다봅니다.
![[그림 7] 이번 편의 기술 선택 결과](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/a4d0b6539c8f4ae88ed358a545759858.png?updatedAt=1772615339000)
세 갈림길에서 저희가 공통적으로 택한 방향은 '단순함'이었습니다. 복잡한 학습 대신 문서 참조, 사전 청킹 대신 질문을 아는 상태에서의 후처리, 복잡한 워크플로 대신 단순한 루프. ‘기술을 더하는 것이 아니라 덜어내는 것’에서 답을 찾았습니다.
그렇다면 이 소거법은 정말 유효했을까요? 인텔리전스 리포트가 그 답을 보여줍니다.
![[그림 8] 미답변 원인 분석 차트](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/50c0249f0a3c439baa3e0f4f77804101.png?updatedAt=1772615361000)
현재 FAA가 답변하지 못한 케이스를 분석한 결과, 미답변 원인의 약 50%가 애초에 참조할 문서가 존재하지 않는 '문서 부재(Doc Gap)'였습니다. 그 외에는 일시적인 API 호출 실패나 저희의 답변 범위가 아닌 것이 대부분이었습니다.
이는 역설적으로 시스템이 제 역할을 하고 있다는 증거입니다. 문서가 있는 영역에서는 높은 응답률을 보이고 있으니까요. 이제 남은 과제는 AI의 뇌를 개조하는 것이 아니라 AI에게 건네줄 '교과서'를 보강하는 것입니다. 실제로 리포트에서 발견된 미답변 질문들을 각 제품 팀에 공유하고 있으며, 보강된 문서는 다시 임베딩돼 다음 리포트에 반영됩니다.
엔터프라이즈 환경에서 '마법의 은탄환'은 없습니다. 유행하는 기술을 무작정 좇기보다 서비스의 본질에 맞는 기술만 남기는 것. 그것이 96%대의 응답률을 뒷받침하는 기술 선택의 이야기입니다. 다음 3편에서는 이렇게 만든 에이전트에서 AI의 답변 품질을 한 단계 끌어올린 한 수, 프롬프트 엔지니어링 이야기를 들려드리겠습니다.
참고 자료
- Zhao et al., From Style to Facts: Mapping the Boundaries of Knowledge Injection with Finetuning(2025)
- Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models(2023)
- Anthropic, How Claude Code works


