들어가며
안녕하세요. Cloud AI Platform 팀에서 AI 어시스턴트의 PM 및 기술 리딩을 맡고 있는 한우형입니다. 클라우드 환경에 AI를 도입해 운영 생산성을 높이는 일을 하고 있습니다.
이 글은 LY Corporation의 프라이빗 클라우드 플랫폼인 Flava를 위한 AI 어시스턴트를 개발하면서 겪었던 기술적 난관과 아키텍처 의사결정 과정을 공유하는 '엔터프라이즈 LLM(large language model) 서비스 구축기' 시리즈의 첫 번째 글입니다. 이 시리즈에서는 단순한 기능 구현기를 넘어 '260개 이상의 툴과 수백 페이지의 문서'를 다루는 대규모 LLM 애플리케이션을 만들며 저희가 고민했던 'Why'와 'How'를 깊이 있게 다룰 예정입니다.
LLM 애플리케이션을 개발한다고 하면 많은 분들이 '프롬프트 엔지니어링'을 먼저 떠올립니다. "너는 10년차 전문가야, 답변은 JSON으로 해줘"와 같이 정교하게 명령을 내리면 완벽한 결과를 얻을 수 있을 것이라 기대하죠.
하지만 27개의 클라우드 제품과 260개 이상의 API를 연동해야 한다면 상황은 달라집니다. 아무리 뛰어난 역량을 가진 비서라도 수천 개의 문서를 무작정 건네주며 "알아서 처리해"라고 한다면 성과를 내기 어렵습니다. 이런 환경에서는 AI에게 어떻게 답변해야 하는지 알려주는 '지침'보다는, 상황에 맞는 정보만 골라서 제공하는 '컨텍스트 엔지니어링(context engineering)'이 더 중요합니다.
시리즈의 첫 번째인 이 글에서는 LY Corporation의 사내 클라우드 플랫폼 Flava의 AI 어시스턴트를 구축하며 진행한 컨텍스트 엔지니어링 작업에서 겪었던 시행착오와 그 과정에서 정립한 핵심 전략을 공유하고자 합니다.
��시리즈 로드맵
이 시리즈의 각 편에서 다룰 주제는 다음과 같습니다. 이번 1편에서는 컨텍스트 엔지니어링을 다루고, 다음 2편에서는 에이전트 엔지니어링과 관련해 모델 파인 튜닝과 에이전틱(agentic) 워크플로의 두 영역에서 마주한 세 가지 갈림길을, 3편에서는 프롬프트 엔지니어링을 다룰 예정입니다.
![[그림 2] AI 에이전트 개선을 위한 기술 영역](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/e6213488844340edbadb8be4f83cbadd.png?updatedAt=1772615094000)
단순 검색기를 넘어 내 상태를 아는 비서로
기업용 챗봇을 구축하는 경우 가장 흔한 접근 방법은 RAG(Retrieval-Augmented Generation) 방식입니다. RAG는 위키와 같은 사내 문서를 뒤져서 답을 찾아주는 방식으로, 쉽게 말해 "나 대신 문서 읽고 요약해줘"를 수행하는 도우미인 셈입니다.
그러나 저희가 만든 Flava AI 어시스턴트는 여기서 한 발 더 나아갑니다. Flava 공식 가이드나 그동안 쌓여온 사용자와의 Q&A 같은 문서를 참조하는 것은 기본이고, 다음 그림과 같이 사용자의 권한으로 실제 API를 호출해서 현재 리소스의 상태를 읽어옵니다.
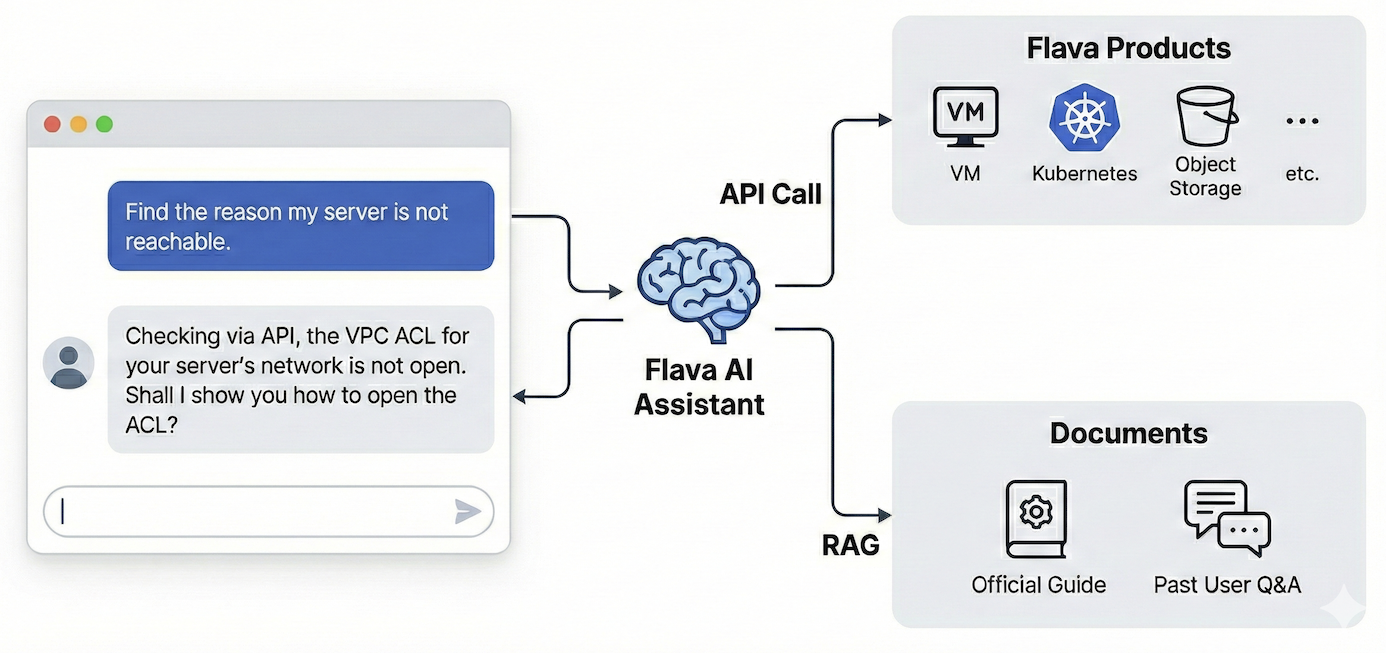
저희 방식이 어떤 차이를 만들어 낼까요? 예를 들어 사용자가 "내 서버에 접속되지 않는 원인을 찾아줘"라고 질문했다면 다음과 같이 답변이 달라집니다.
- 일반 RAG 챗봇: "서버 접속이 안 되면 네트워크 상태나 VPC ACL을 확인해 보세요" → 일반론적인 가이드
- Flava AI 어시스턴트: "API를 통해 확인해 보니 현재 서버가 속한 네트워크의 VPC ACL이 열려 있지 않네요. ACL을 여는 방법을 알려드릴까요?" → 내 상황에 맞는 진단
Flava AI 어시스턴트는 단순히 일반적인 가이드를 알려주는 게 아니라 실제 내 리소스 상태를 직접 확인해서 해결책을 제시합니다. 사용자가 번거롭게 콘솔을 탐색할 필요 없이 AI가 대신 상황을 파악해 주는 것이죠.
그런데 이런 '똑똑한' 친구를 만들려니 다뤄야 할 정보의 양이 폭발적으로 늘어났습니다.
- 27개의 제품군(VM, Kubernetes, Object Storage 등)
- 260여개의 API(각 제품의 목록, 상태 조회 등)
- 수백 페이지의 문서(Flava 공식 가이드, 과거 사용자 Q&A)
이 방대한 정보와 도구를 LLM이라는 '두뇌'에 어떻게 집어넣어야 할까요? 여기서 우리는 '컨텍스트 엔지니어링'이라는 개념을 마주합니다.
컨텍스트 엔지니어링이란?
'프롬프트 엔지니어링(prompt engineering)'은 LLM에게 입력하는 '지시 사항'입니다. "전문가처럼 행동해, JSON 형식으로 답변해"와 같은 것이죠. 반면 '컨텍스트 엔지니어링'은 LLM에게 '필요한 정보만 선별해서 제공하는 것'입니다.
개발자 �온보딩을 예로 들어볼게요. 신입 개발자에게 10년 치 문서를 던져주며 "읽어보고 일하세요"라고 하면 어떻게 될까요? 아마 큰 혼란에 빠질 것입니다. 필요한 순간에 필요한 문서만 딱 집어서 주는 사수가 좋은 사수죠.
AI도 똑같습니다. "요즘 LLM은 컨텍스트 윈도우(기억 용량)가 수십만 토큰이라던데 문서를 다 줘도 괜찮지 않나요?"라고 물으실 수 있지만, 다음 두 가지 연구 결과를 보면 생각이 달라지실 겁니다.
첫 번째, 양(quantity)이 많아지면 성능이 떨어진다
2025년 10월에 발표된 Context Length Alone Hurts LLM Performance Despite Perfect Retrieval 논문에서는 컨텍스트의 길이에 따라 LLM의 성능이 어떻게 떨어지는지 연구한 결과를 발표했습니다. 연구진은 GPT-4o와 Claude-3.5-Sonnet 등 주요 모델을 대상으로 실험을 진행했는데요. 질문에 답변하기 위해 필요한 핵심 정보를 모두 컨텍스트로 제공하면서, 핵심 정보 외에 아무 의미 없는 공백이나 관련 없는 텍스트를 함께 넣었습니다. 그 결과, 모델이 지원하는 컨텍스트 길이 이내에서도 단지 입력 길이가 길어졌다는 이유만으로 최대 13.9%에서 85%까지 성능이 하락했습니다.
실제 RAG에서의 연구 결과도 이를 증명합니다. Databricks의 연구 결과(Long Context RAG Performance of LLMs)에 따르면, GPT-4나 Llama-3.1 같은 모델에서도 컨텍스트가 특정 구간(32K~64K 토큰)을 넘어가면 RAG 성능이 하락하기 시작했습니다. 즉, 아무리 똑똑한 모델이라도 컨텍스트가 길어지면 성��능이 떨어진다는 것입니다.
참고로, 64K개의 토큰은 A4 용지로 70페이지에 달하는 크기입니다. 따라서 '이 정도면 꽤 많은 입력을 받을 수 있네?'라고 생각할 수도 있는데요. 여기에는 함정이 있습니다. LLM은 기본적으로 상태가 없습니다. 스테이트리스(stateless), 즉 이전 대화를 스스로 기억하지 못하기 때문에 대화의 맥락을 유지하려면 지금까지 누적된 모든 대화 내용과 정보를 모두 입력으로 제공해야 합니다. 특히 Flava AI 어시스턴트처럼 API 응답을 다루는 경우 토큰 소모 속도는 훨씬 빨라집니다. 예를 들어 "서버 목록 알려줘"라는 한마디에 수백 개의 JSON 데이터가 반환된다면 어떨까요? 사용자와 대화를 몇 번만 주고받아도 64K개의 토큰을 순식간에 사용하게 될 것입니다.
두 번째, 질(quality) 낮은 정보(노이즈)가 섞이면 판단력이 흐려진다
Context Rot: How Increasing Input Tokens Impacts LLM Performance이라는 연구 리포트에서는 '질'에 주목했습니다. 이 연구에서는 '정답과 유사하지만 관계없는 정보를 섞었을 때 컨텍스트가 길어질수록 방해 요소에 영향을 받아 오답을 내는 비율이 급격히 증가'한다는 결과를 발표했습니다. 특히 GPT 계열에서는 '오답임에도 불구하고 매우 당당하게 가짜 정보를 생성'하는 오류가 발생하기도 했습니다.
결국 모델의 컨텍스트 윈도우가 아무리 커져도 '필요한 것을 골라내는 기술'이 반드시 필요합니다.
Flava AI 어시스턴트의 전략: 점진적 공개
위와 같은 �이유로 저희는 '점진적 공개' 전략을 택했습니다. 처음부터 모든 정보를 제공하는 대신, 사용자의 질문이나 현재 진행 상태에 따라 필요한 정보만 적절히 선택해서 AI에게 제공하는 방식입니다. 전체적인 흐름은 다음과 같습니다.
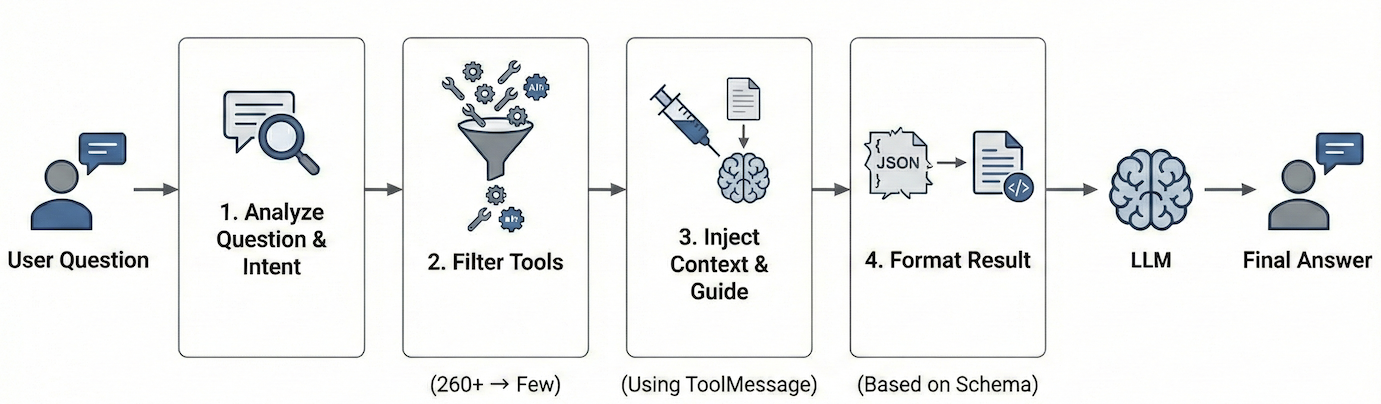
- 질문 분석: 사용자가 무엇을 묻는지 파악
- 도구 선별: 260개 도구 중 필요한 도구만 선택
- 가이드 주입: 질문과 도구에 맞는 매뉴얼만 골라서 제공
- 실행 및 포맷팅: 툴 실행 결과에는 필요한 맥락만 제공
각 단계를 조금 더 자세히 살펴보겠습니다.
1단계: 필요한 도구만 골라내기
사실 '260개나 되는 API를 어떻게 효율적으로 다룰 것인가?'라는 질문은 Flava AI 어시스턴트 개발 과정에서 마주한 가장 큰 도전 중 하나였습니다. 이 과제를 해결하기 위해 다양한 접근 방식을 검토하고 실험했는데요. 어떤 고민을 했고 구체적으로 어떻게 해결했는지는 이 시리즈의 다른 글에서 자세히 풀어볼 예정이며, 여기서 강조하고 싶은 핵심은 '모든 도구를 한 번에 로드하지 않는다'는 것입니다.
예를 들어 사용자가 "Redis 클러스터 상태 알려줘"라고 물으면 시스템이 먼저 27개 제품 중 'Redis' 관련 도구만 딱 집어낸 뒤 LLM에게 전체 도구 중 Redis 관련 도구 8개만 선별해서 보여줍니다. 나머지 252개는 아예 컨텍스트에 올리지도 않습니다. 이렇게 하면 컨텍스트를 획기적으로 절약할 수 있습니다.
2단계: 필요한 사용법만 알려주기
도구만 던져주면 끝이 아닙니다. Flava의 27개 제품은 제품마다 사용법이나 특징이 다릅니다. 예를 들어 'Object Storage'라는 제품은 내부용(private)과 외부용(CDN)의 설정 방법이 다른데요. 이런 내용은 Object Storage의 API를 호출할 때만 필요하기 때문에 실제 Object Storage를 호출하려고 할 때만 제공하면 됩니다.
그런데 이 힌트는 어디에 적어줘야 할까요? 가장 단순한 방법은 시스템 프롬프트에 추가하는 것입니다. 시스템 프롬프트는 단순히 문자열이고 LLM을 호출할 때 전달하면 되기 때문에 기존 시스템 프롬프트에 다음과 같이 추가(append)하는 것이죠.
system_prompt = """
# 기존 시스템 프롬프트
- 친절하되 전문적인 톤으로 답변하세요.
- 반드시 검색된 결과를 기반으로 답변하세요.
(...)
-------------추가되는 내용----------------
# Object Storage 사용 시 주의사항
- Private: 내부망 전용입니다.
- CDN: 외부에서 접근 가능합니다.
파라미터 설정 시 이 점을 꼭 유의하세요.
---------------------------------------
"""하지만 이 방법에는 큰 문제가 있었는데요. 먼저 '응답 가이드라인'을 소개한 뒤 어떤 문제가 발생했고 어떻게 해결했는지 이어서 설명하겠습니다.
3단계: 응답 가이드라인과 '모의 도구 메시지(ToolMessage)' 전략
다음으로 주입할 정보는 '상황별 행동 지침'입니다. 이를 저희는 '선택적 응답 가이드라인', 줄여서 '응답 가이드라인'이라�고 부릅니다.
응답 가이드라인은 시스템 프롬프트와 어떻게 다를까요? 시스템 프롬프트에는 모든 사용자 질문에 적용되는 공통 내용이 들어갑니다. 예를 들어 "반드시 검색된 결과를 기반으로 답변하세요" 같은 지침은 어떤 질문이든 항상 적용해야 하기 때문에 시스템 프롬프트에 들어갑니다. 반면 특정 상황에서만 지켜야 하는 구체적인 절차가 있습니다. 이 절차는 절차가 필요한 '조건(selection criteria)'과 '내용(content)'의 쌍으로 구성됩니다. 두 가지 사례를 살펴보겠습니다.
- 사례 A: 답변 전략 안내(리소스 변경 요청)
- 조건: "사용자가 리소스를 생성/삭제/변경하는 법을 물어보면"
- 내용: "먼저 콘솔 UI를 통한 방법을 안내하세요. 그리고 CLI 도구 사용법도 필요한지 물어보세요."
- 의도: "UI로 드릴까요, CLI로 드릴까요?"라고 되묻는 불필요한 핑퐁을 없애고, 우리가 권장하는 표준 방법(UI)으로 즉시 안내하기 위함입니다.
- 사례 B: 사내 고유 지식 연결(DB 쿼리 질문)
- 조건: "사용자가 DB에 어떻게 쿼리하는지 물어보면"
- 내용: "'Query Runner'라는 제품을 쓰면 가장 간편하다는 것을 먼저 안내하세요."
- 의도: LLM은 우리 회사의 'Query Runner'라는 도구를 모릅니다. 가이드라인이 이 도구의 이름을 먼저 언급해 줘야 비로소 LLM이 검색 도구를 통해 사용법을 찾아보고 안내할 수 있습니다.
사례 A와 B의 내용은 모든 사용자의 질문에 필요한 내용은 아니기 때문에 시스템 프롬프트에 넣을 수준은 아닙니다. 조건에 맞는 경우에만 선택적으로 내용을 로드하면 됩니다. 이와 같은 것들이 응답 가이드라인에 넣을 내용에 해당합니다.
응답 가이드라인의 작동 방식은 1단계에서 필요한 도구만 골라낼 때와 비슷합니다. 먼저 LLM에게 사용자 질문과 가이드라인들의 '조건'들만 던져줍니다. 그리고 "이 질문에 필요한 가이드라인이 뭐니?"라고 묻는 것이죠. LLM이 적절한 가이드라인을 선택하면 그때 비로소 해당 가이드라인의 '내용'을 컨텍스트에 추가합니다.
여기서 이 내용을 '어떻게' 주입하느냐가 핵심인데요. 처음에는 시스템 프롬프트에 내용을 추가했지만 문제가 발생했습니다. 시스템 프롬프트끼리 미묘하게 충돌하면서 대원칙이 깨져버린 것이죠. 관련 사례를 하나 살펴보겠습니다.
- 사용자: "VM 삭제하는 법 알려줘."
- 시스템 프롬프트: "반드시 문서 검색 도구를 사용해 검색된 결과로만 답변하세요."
여기에 다음과 같은 가이드라인이 주입됐습니다.
- 주입된 가이드라인: "리소스 삭제 시에는 UI를 먼저 안내하세요."
예상된 결과는 문서 검색 도구를 사용해서 VM 삭제하는 방법을 찾고 UI로 삭제하는 방법을 먼저 안내하는 것인데요. 실제로는 LLM이 "UI를 먼저 안내하라"에 과도하게 집중한 나머지 "반드시 검색 결과로 답변하라"는 대원칙을 무시해 버렸습니다. 그 결과 실제 검색을 수행하지도 않고 VM을 UI로 삭제하는 방법을 자기 마음대로 상상해 답변해 버렸습니다. 환각이 발생한 것이죠. 사람이 생각하기에는 서로 관계 없어보이는 프롬프트였지만 AI 내부에서는 시스템 프롬프트가 충돌하면서 예상치 못한 방향으로 작동한 것입니다.
저희는 이 문제를 해결하기 위해 LLM의 메시지 처리 방식을 활용했습니다. 결론부터 말하�면 이렇게 추가로 주입되는 컨텍스트는 시스템 프롬프트로 제공하는 대신 도구 메시지 형태로 제공했습니다. 도구 메시지는 LLM이 도구를 실행한 결과를 저장하는 형식입니다. 예를 들어 "Flava란 무엇인가?"라고 물어보면 Flava 검색 결과는 도구 메시지로 저장되며, LLM은 시스템 프롬프트와 도구 메시지에 있는 Flava의 정보를 활용해서 최종 답변을 생성합니다. 저희가 주입하려는 내용이 도구(tool)의 실행 결과는 아니지만 마치 도구 실행 결과인 것처럼 인식하도록 한 것입니다.
이렇게 하면 다음과 같이 정보의 우선순위가 명확해집니다.
- 시스템 프롬프트: "반드시 검색된 결과로만 답변하세요" (행동 강령으로 인식됨)
- 응답 가이드라인: "가이드라인 조회 결과 삭제 시 UI를 먼저 안내하세요" (검색된 결과, 참고 데이터로 인식됨)
이제 가이드라인은 더 이상 무조건 따라야 할 '지침'이 아니라 판단을 위한 '참고 정보'가 됩니다. 따라서 시스템 프롬프트를 지키면서 응답 가이드라인을 전달할 수 있었습니다.
4단계: API 응답의 재구성
마지막 단계는 API가 실행된 직후의 처리입니다. Flava AI 어시스턴트는 27개 Flava 제품의 260여개 API를 호출할 수 있습니다. API 호출 결과는 일반적으로 JSON이며, 필드 이름을 보고 의미를 알 수 있는 경우도 있지만 그렇지 않은 경우도 많습니다. 따라서 개발자는 보통 Swagger 같은 API 문서를 참고해서 이것을 해결합니다.
그러나 260개 API의 모든 응답 스키마를 처음부터 주입하는 것은 엄청난 토큰 낭비입니다. 따라서 저희는 실제 API 응답이 돌아온 그 순간 해당 데이터를 해석하기 위해 필요한 API 스키마 정보를 덧붙여서 전달하기로 결정했습니다. 스키마 정보는 다음과 같이 전달합니다.
services!: array
name!: string
flavor_ref!: string // 서버 사양 ID
status?: "active" | "error"필드명 뒤의 !나 ?는 필수값 여부를 나타냅니다. API 호출 결과의 JSON에서는 값이 없는 경우(null) 해당 필드를 아예 생략하는 경우가 있기 때문에 API 응답만을 보고서는 원래 해당 필드가 있었는지조차 알 수 없는데요. 이를 보완하기 위해 스키마에서는 반드시 모든 필드를 표기하고 필수값 여부를 표현했습니다.
다음으로 주석으로 해당 필드에 설명을 달았습니다. 이때 토큰 절약을 위해 필드명만으로 어떤 필드인지 유추할 수 있는 name 같은 필드에는 설명을 달지 않았습니다.
스키마 이후에는 API 응답 결과를 붙여서 전달합니다. 처음에는 토큰 효율성을 위해 공백을 모두 제거한 JSON(Minified JSON)을 고려했지만, YAML과 비교해 보니 데이터에 따라 조금씩 다르긴 하지만 생각보다 토큰 수 차이가 크지 않았습니다. 이에 따라 가독성이 월등히 높은 YAML을 선택했습니다.
이렇게 해서 최종적으로 다음과 같은 형태로 LLM에게 API 응답을 전달합니다.
# Schema
services!: array
name!: string
flavor_ref!: string // 서버 사양 ID
status?: "active" | "error"
# Data
services:
- name: "prod-redis"
flavor_ref: "m5.large"
status: "active"
- name: "dev-redis"
flavor_ref: "t3.small"이 구조 덕분에 LLM은 최소한의 컨텍스트로 API의 의미를 정확히 파악할 수 있습니다.
마치��며: 덜어내는 것이 기술이다
컨텍스트 엔지니어링의 핵심을 한 줄로 요약하자면 이렇습니다.
"노이즈를 줄이고, 신호(signal)만 남기세요."
LLM의 성능이 아무리 좋아져도 불필요한 정보는 판단이 흐려지게 만듭니다. 개발자가 코드를 짤 때 필요한 모듈만 import 하듯 AI에게도 그 순간에 가장 필요한 정보만 import 해 주는 것. 그것이 대규모 AI 서비스를 똑똑하게 만드는 비결이었습니다.
다음 글에서는 에이전트를 똑똑하게 만들기 위해 시도했던 파인튜닝과 에이전트 워크플로 등의 검증 과정을 다룹니다. 실제 서비스에 적용해 성능을 높인 방법은 무엇인지, 반대로 제외한 기술은 무엇이고 그 이유는 무엇인지 전해 드릴 예정이니 많은 기대 바랍니다.
참고자료
- Du et al., Context Length Alone Hurts LLM Performance Despite Perfect Retrieval(EMNLP 2025)
- Databricks, Long Context RAG Performance of LLMs(2024)
- Hong et al., Context Rot: How Increasing Input Tokens Impacts LLM Performance(Chroma Research, 2025)


