TL;DR
네트워크 호출 없이 모바일 기기 내부에서 작동하는 이미지 이해 기능을 개발했습니다. 이 과정에서 거대 모델(teacher)의 정교한 표현력을 작은 모델(student)에게 전수하여 성능은 유지하면서 크기와 연산량을 획기적으로 줄이는 '지식 증류(knowledge distillation)' 기법을 핵심 전략으로 활용했습니다.
구체적으로는 모바일 앱에서 이미지 캡션 생성의 긴 지연을 해결하기 위해 일반적인 자기회귀(autoregressive, AR) 디코딩이 아닌 비자기회귀(non-autoregressive) 디코더로 대체해 200~400ms급 응답 시간을 달성했습니다. 품질은 '실사용 가능 여부'로 평가해야 한다고 보고 LLM(large language model) 기반 수락 비율(accept ratio) 지표를 도입했으며, 다단계 지식 증류로 최종 품질을 서비스 가능한 수준까지 끌어올렸습니다.
- 핵심 성과
- 초저지연: 비자기회귀로 5초 이상 → 200~400ms(12배 향상)
- 온디바이스: 172MB 모델로 실제 서비스 가능 수준 달성
들어가며
앞선 1편에서는 왜 '메신저'에 이미지 이해 기능이 필요했고 왜 이를 '온디바이스'로 풀어야 했는지, 지연·프라이버시·오프라인·배포 제약 등의 문제를 정의했습니다. 그 위에서 번역 파이프라인의 한계를 짚고, 지식 증류로 텍스트 인코더를 다국어(영어/일본어/중국어(번체)/태국어/한국어)로 확장해 온디바이스 이미지 검색을 실사용 가능한 수준으로 끌어올린 과정을 다뤘습니다.
이어서 2편에서는 메신저 UX에서 더 직접적으로 체감할 수 있는 기능인 이미지 캡션(짧고 자연스러운 문��장 생성)을 다룹니다. 기존의 거대 VLM(vision-language model)/자기회귀 방식 캡션 생성은 모바일에서 수초 단위 지연이 발생해 메신저 시나리오에 맞지 않았고, 단순 경량화만으로는 목표(수백 ms)를 달성하기 어려웠습니다.
이에 저희는 디코딩 방식을 비자기회귀으로 전환해 속도를 먼저 확보한 뒤, LLM 기반 수락 비율로 실사용 품질을 정의하고, 데이터 캡션 재생성(re-captioning)과 다단계 지식 증류로 최종 품질을 서비스 가능 수준까지 끌어올리는 학습 패턴을 구축했습니다. 그 과정에서 겪은 시행 착오와 핵심 선택들을 순서대로 풀어보겠습니다.
왜 기존 캡션 생성(자기회귀/거대 VLM)을 사용하는 것이 어려웠나
탈락한 후보 모델들
온디바이스 이미지 캡션 생성(image captioning)을 구현하기 위해 여러 모델을 조사했지만 대부분 모바일 환경에서 작동하는 것 자체가 어려웠습니다. BLIP-2, MobileVLM, PaliGemma, MiniCPM 계열은 모델 크기와 추론 지연 측면에서 현실적이지 않았습니다. 그나마 BLIP-1은 상대적으로 크기가 작고 라이선스가 명확해서 베이스라인으로 채택했지만, 양자화 이후에도 지연 시간이 5초 이상이어서 모바일 사용 시나리오에는 맞지 않았습니다.
최근에는 Pixel 9이나 10과 같은 최신 Android 기기에 Gemini Nano 모델이 탑재되면서 ‘Image Description’이라는 이름으로 캡션 기능을 제공하기 시작했는데요. 별도 외부 모델 없이 OS에서 자체적으로 기능을 제공한다는 것은 반가운 일입니다만 BLIP-1과 마찬가지로 앞서서 정의했던 사용 시나리오에는 적합하지 않아 제외했습니다.
| 모델 | 크기 | �모바일 지연 | 탈락 이유 |
|---|---|---|---|
| BLIP-2 | ~2GB | N/A | 거대 모델 |
| MobileVLM | 1.4GB | N/A | 거대 모델 |
| PaliGemma | 11.69GB | N/A | 거대 모델 |
| MiniCPM-Llama3 | 3~6GB | *30초 이상 | 거대 모델 |
| Google GenAI Image Description | N/A(OS에 포함) | **5초 이상 | 속도문제 |
| BLIP-1 | 990MB → 227MB | *5초 이상 | 속도 문제 |
지연 측정 기기: *Samsung Galaxy Fold 4, **Pixel 9 Pro
자기회귀 병목
LLM에서 글을 생성할 때는 일반적으로 자기회귀 디코딩을 사용합니다. 즉, 토큰을 하나씩 순차적으로 생성합니다. 이는 길이 T의 문장을 만들기 위해 디코더 전방 통과(forward pass)를 T번 수행한다는 뜻이며, 모바일에서는 이 비용이 그대로 지연으로 드러납니다.
<start> → "a" → "dog" → "on" → "a" → "couch" → <end>Samsung Galaxy 4 Fold 기준으로 저희 초기 모델을 측정했을 때 토큰당 약 142ms가 걸렸고, 20토큰을 생성��하면 약 2.8초가 걸렸습니다. BLIP-1은 디코더가 더 크기 때문에 5초 이상 걸렸습니다. 모바일 UX를 기준으로 보면 '최소 10배' 이상의 속도 향상이 필요했고, 이는 단순 경량화로는 달성할 수 없었습니다.
온디바이스 성능 목표와의 차이
개발 시점에 상정했던 모바일 환경의 사용자 시나리오에서는 최대 '수백 ms' 이내 지연 시간이 목표였습니다. 평균 지연 시간뿐 아니라 네트워크 상태나 콜드 스타트(cold start)와 같은 변수에도 결과가 크게 흔들리지 않는 안정성을 확보하는 것이 중요했습니다.
이 단계에서 얻은 결론은 단순했습니다. 모델을 경량화해 '조금 줄이는' 수준으로는 모바일 환경 시나리오에서 요구하는 지연 목표를 맞출 수 없기에 디코딩(캡션 생성) 방식 자체를 바꿔야 한다는 것이었습니다. 결국 첫 번째, 디코딩 구조를 병렬화하고, 두 번째, 데이터/평가를 실사용 기준으로 다시 설계하는 방향으로 문제를 재정의했습니다.
핵심 아이디어 2: 비자기회귀 캡션 생성으로 속도 향상
앞서 1편에서 첫 번째 핵심 아이디어로 ‘지식 증류로 다국어 텍스트 인코더’를 만든 이야기를 말씀드렸습니다. 이제 두 번째 핵심 아이디어인 비자기회귀 캡션 생성으로 속도를 해결한 방법을 설명하겠습니다.
비자기회귀 개념: 학습 가능(learnable) 쿼리 토큰 기반 디코딩
비자기회귀의 핵심은 '모든 토큰을 동시에 예측'하는 것입니다. 이미지에서 얻은 표현을 조건(prefix)으로 두고, 고정 길이 N개의 학습 가능 쿼리 토큰이 병렬로 토큰을 예측합니다.
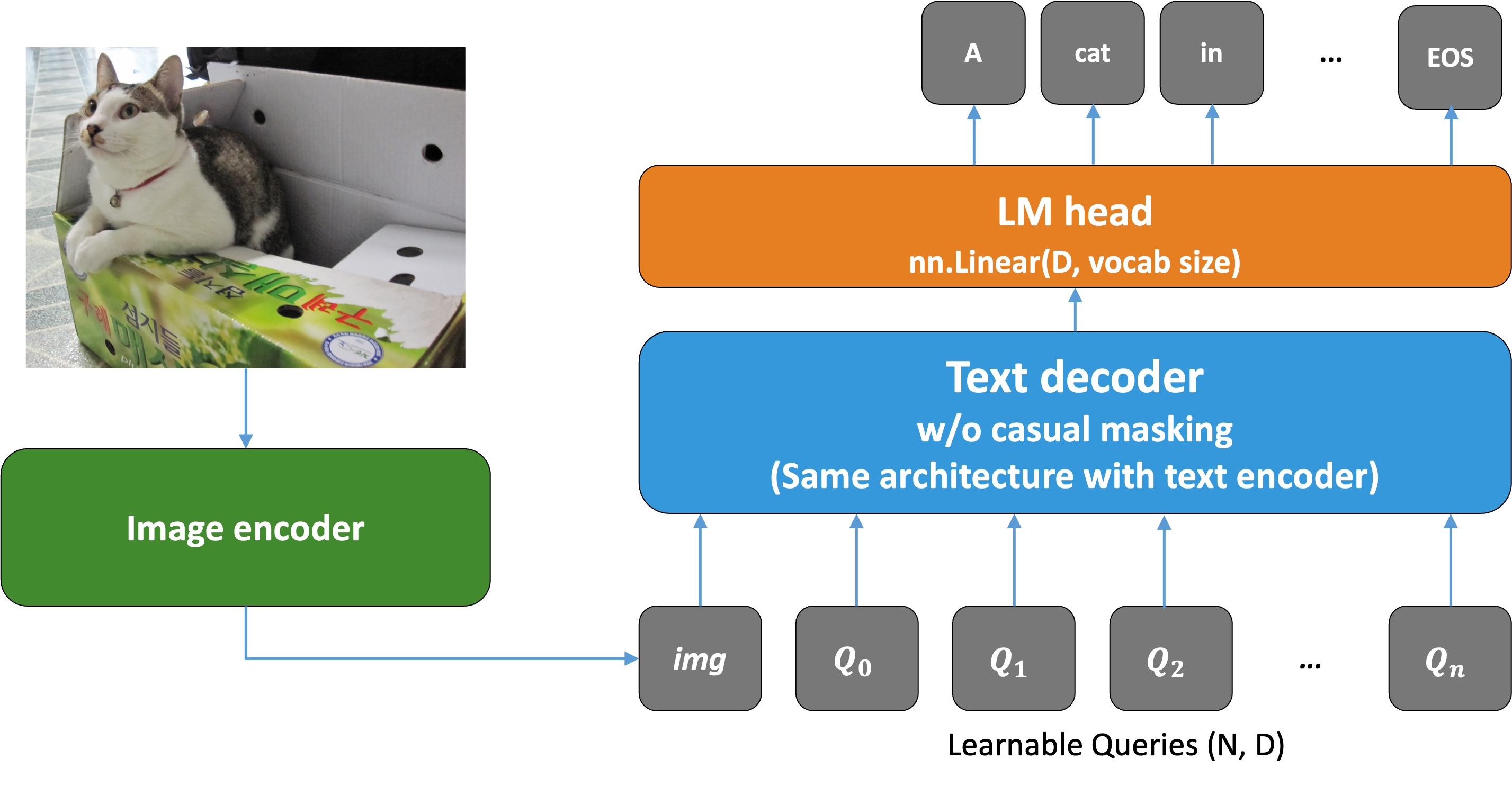
시간 복잡도 측면에서 자기회귀는 토큰 개수에 비례하여 O(T)이지만, 비자기회귀는 병렬 처리로 O(1)입니다. 이 접근법은 Non-autoregressive Sequence-to-Sequence Vision-Language Models (CVPR 2024)와 ClipCap: CLIP Prefix for Image Captioning (ACL 2021) 논문을 참고했습니다.
CTC 계열(Query-CTC) 손실 함수를 활용한 학습
비자기회귀는 병렬로 토큰을 뽑기 때문에 '정답 토큰이 쿼리의 어느 위치에 와야 하는가'라는 정렬(alignment) 문제가 생깁니다. 이를 해결하기 위해 CTC(Connectionist Temporal Classification) 계열의 Query-CTC(이하 Q-CTC) loss를 사용했습니다. 다음은 Q-CTC의 구조를 나타낸 그림입니다.
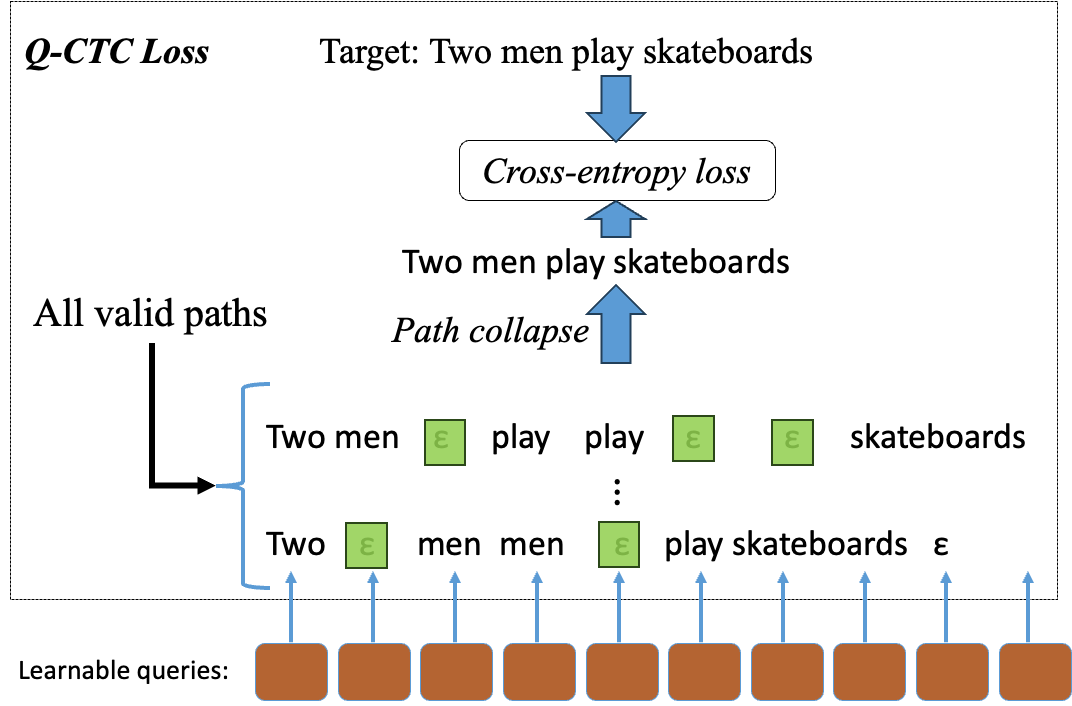
CTC는 발화 시간과 텍스트 정렬 문제와 유사한 상황을 해결하기 위한 방법입니다. 빈(blank) 토큰 (ε)으로 길이를 조정하고 가능한 모든 정렬 경로를 동적 프로그래밍으로 계산해서 가능한 모든 정렬 경로의 확률을 합산해 손실을 계산합니다.
모델 구조 개요: 이미지 인코더 + 비자기회귀 텍스트 디코더
모델은 크게 세 부분으로 구성했습니다.
- 이미지 인코더는 1편에서 사용한 이미지 인코더를 그대로 재사용했습니다.
- 이미지 임베딩을 텍스트 쪽으로 연결할 때는 ClipCap 논문의 아이디어(이미지 임베딩을 조건(prefix)으로 주입)를 차용했습니다.
- 텍스트 디코더는 1편에서 사용한 텍스트 인코더 구조를 재활용해 66.4M 파라미터 규모로 구성했습니다. 그리고 학습 가능 쿼리 토큰은 짧은 문장을 생성할 목적으로 20개의 고정 길이로 설정했습니다.
class NonARCaptioner(nn.Module):
def __init__(self, num_queries=20, hidden_dim=512):
super().__init__()
self.image_encoder = ImageEncoder()
# Learnable query tokens
self.query_tokens = nn.Parameter(torch.randn(num_queries, hidden_dim))
# Transformer decoder
self.decoder = TransformerDecoder(
hidden_dim=hidden_dim,
num_layers=6,
num_heads=8
)
# Projection to vocabulary
self.output_proj = nn.Linear(hidden_dim, vocab_size)
def forward(self, image):
# 1. Image encoding (prefix)
img_emb = self.image_encoder(image) # [1, 512]
# 2. Query tokens
queries = self.query_tokens.unsqueeze(0) # [1, 20, 512]
# 3. Decoder (queries attend to image embedding)
output = self.decoder(queries, prefix=img_emb) # [1, 20, 512]
# 4. Parallel prediction
logits = self.output_proj(output) # [1, 20, vocab_size]
return logits # 모든 토큰 동시 예측
테스트 결과: 속도는 빠르나 품질 문제 발생
원래 모델의 텍스트 인코더를 디코더로 변환하여 텍스트 인코더 구조를 재활용한 비자기회귀 모델을 테스트해 보았을 때, 속도는 매우 만족스러웠습니다. 대략 200ms 안쪽의 준수한 속도를 볼 수 있었습니다. 하지만 품질이 문제였습니다. 일반적인 텍스트 생성의 벤치마크인 CIDEr와 CLIPScore는 괜찮은 점수가 나왔습니다만, 결과를 실제로 눈으로 확인해 보면 같은 단어의 반복이나 오타가 잦았습니다. 예를 들어 “a desk with a computer on a desk"처럼 불필요하게 중복된 단어가 있다거나 "a people ons"처럼 오타가 포함돼 있었습니다. 이는 바로 사용자 불만으로 이어질 수 있는 사안이었기에 해결할 필요가 있었습니다.
품질의 벽 넘기: 속도는 빠른데 이상한 문장이 나오는 현상 해결하기
품질 수치화: 수락(accept)/미수락(non-accept) 자동 판정 지표 도입
우선 저희는 평가를 다시 설계했습니다. 목표가 '논문에서 사용하는 벤치마크 지표 최적화'가 아니라 '실제 서비스에 적용해도 어색하지 않은 문장'이라면, 반복/오타/문법 오류가 발생한 경우를 잡아야 합니다. 저희는 GPT-4o mini로 캡션을 수락/미수락으로 분류하고 수략 비율을 지표로 정의했습니다.
SYSTEM_PROMPT = '''
Your task is to evaluate generated photo captions intended for use in
a messenger app. Please determine whether each caption is acceptable
for production based on:
- No Duplicate Content
- Error-Free
- Clarity and Grammar
Answer with exactly one word: accept or non-accept.
'''
아래는 그 결과입니다.
| 모델 | CIDEr | CLIPScore | 수락 비율 |
|---|---|---|---|
| BLIP-1(자기회귀) | 87.32 | 71.0 | 0.92 |
| Ours(비자기회귀) | 75.2 | 72.9 | 0.21 |
예상했던 대로 실제 서비스에서 사용 불가능한 수준의 낮은 수락 비율이 나왔습니다. 이를 통해 CIDEr나 CLIPScore와 같은 대표적인 벤치마크를 제대로 된 성능 지표로 사용하기 어렵다는 점을 알 수 있었습니다.
아래는 불합격한 예시 문장입니다.
- "a desk with a computer on a desk"(같은 단어가 반복되는 문장)
- "a people ons"(오타가 있는 문장)
- "a man of a person on a wall"(문법 오류가 있는 문장)
- "a"(불완전한 문장)
근본 원인 분석: 학습 데이터의 품질이 성능을 결정
품질 문제가 발생한 근본 원인을 분석한 결과 먼저 눈에 들어온 것은 학습 데이터셋에 포함된 노이즈였습니다. 학습에 사용한 데이터의 내부를 살펴보니 캡션 품�질이 불균일했습니다. 짧은 캡션과 장황한 캡션이 혼재되어 있었고, 이미지 내 텍스트를 읽으려는 OCR 시도 같은 불필요한 정보도 많았습니다.
모델 표현력에도 한계가 있었습니다. 학습에 사용했던 텍스트 인코더는 파라미터 수가 비교 상대인 BLIP-1( 110M) 고작 절반 정도(66.4M)에 불과해 많은 데이터 공간을 충분히 커버하기가 어려웠습니다. 게다가 작은 모델에게는 비자기회귀 구조로 한 번에 전체 문장을 생성하는 것이 꽤나 어려운 작업이었습니다.
앞서 비자기회귀 구조로 변경해 속도 문제를 해결했는데요. 이번엔 품질 문제를 해결하기 위해 학습에 사용하는 데이터셋을 정제하고 조절하는 방향으로 학습 파이프라인 자체를 품질 개선 루프에 맞게 다시 구성했습니다.
데이터 관점에서 보면 흐름은 다음과 같습니다.
- 원본 데이터로 베이스라인 학습
- LLM 기반 평가(수락/미수락)로 실패 케이스 수집
- 학습 데이터 품질 자체를 바꾸기 위해 캡션 재생성(re-captioning) 수행
- 작은 크기의 비자기회귀 모델에게 ‘적절한 난이도’를 만들기 위해 교사-학생 지식 증류 수행
- 미수락 샘플을 교체/정제하며 루프 반복
특히 2~5의 반복이 비자기회귀 방식에서 품질을 높이는 실질적인 과정이었습니다. 모델 구조를 변경하는 실험(이미지 인코더 스케일 업, 데이터 스케일 업, 위치 임베딩 변경 등)을 여러 번 했지만 CIDEr나 CLIPScore는 올라도 수락 비율이 의미 있는 수준으로 개선되는 경우는 많지 않았습니다. 반면 캡션 재생성과 지식 증류 작업은 바로 수락 비율의 차이를 만들었고, 결과적으로 서비스 지표에 더 가깝게 수렴했습니다.
데이터 정제: 캡션 재생성으로 학습 데이터의 질 끌�어올리기
그럼 먼저 캡션 재생성으로 데이터를 정제한 과정을 살펴보겠습니다.
캡션 재생성을 선택한 이유: 노이즈 제거와 스타일 통일
원본 학습 데이터는 캡션에 다양한 길이의 캡션이 섞여 있어 품질 편차가 컸습니다. 작은 모델(66.4M)이 이런 노이즈 공간을 모두 커버하기는 어려웠고, '모바일용 짧은 캡션'이라는 목표 스타일과도 맞지 않았습니다. 이에 데이터 자체를 '모바일에 적합한 스타일'로 재구성하기로 했습니다.
캡션 재생성 정책: '짧고 일반적인 캡션'이 생성되도록 프롬프트 설계
캡션 재생성 모델로는 비전 언어 이해 능력이 뛰어난 Microsoft의 Phi-3.5-vision-instruct를 선택했습니다. Phi-3.5를 사용해 약 1,300만 건의 캡션 전체를 재생성했으며, GPU 클러스터에서 2주 정도 걸렸습니다.
프롬프트는 의도적으로 단순하게 설계했습니다. OCR을 제거하기 위해 이미지 내 텍스트를 무시하고, 고유명사와 제목을 피하며, 8단어 이하의 짧은 표현으로 제한하면서, “A photo of …' 템플릿으로 스타일을 통일하도록 아래와 같이 작성했습니다.
Generate a simple and general caption for the given image using
the template: 'A photo of {caption}.'
- Do NOT read or include any text from the image.
- Focus on describing the main subject in general terms without
specific names or titles.
- Ensure the entire caption does NOT exceed 8 words.캡션 재생성 후 측정 결과
다음은 캡션 재생성 후 측정한 결과입니다.
| 모델 | 학습 데이터 | CIDEr | CLIPScore | 수락 비�율 |
|---|---|---|---|---|
| 비자기회귀 | 원본 | 75.2 | 72.9 | 0.21 |
| 비자기회귀 | 재생성 데이터 | 73.72 | 72.4 | 0.66 |
CIDEr가 75.2에서 73.72로 소폭 하락했는데 이는 캡션이 단순해졌기 때문입니다. 전통적인 지표에서는 다양성이 줄어든 것으로 보이지만 수락 비율은 0.21에서 0.66으로 3배 향상되면서 실사용 품질이 대폭 개선됐습니다. 다만 그럼에도 66%라는 수치는 아직 서비스에 사용하기에는 모자른 수치라고 판단했습니다.
다단계 지식 증류: 비자기회귀 품질을 실사용 수준으로 끌어올리기
캡션 재생성만으로도 어느 정도의 성능 향상이 있었지만 앞서 말씀드렸듯 66%로는 아직 부족했습니다. 여기서 성능을 끌어올리기 위한 아이디어는 지식 증류를 활용한 눈높이 학습이었습니다. 다른 LLM 모델과 비교하면 파라미터 크기가 현저히 작은 텍스트 디코더의 눈높이에 맞도록 ‘텍스트 디코더가 직접 자신의 수준에 맞는 문장을 만들면 어떨까?’라는 아이디어입니다.
상세한 캡션이 항상 학습에 이롭지는 않다: 눈높이 교육이 필요한 이유
캡션을 재생성하다 보면 성능 좋은 LLM이 캡션을 상세하게 만들고 싶어하는 경향이 드러납니다. LLM은 온갖 수식어를 동원해 이미지의 작은 부분까지 묘사하고자 했습니다. 그러나 66.4M 파라미터에 불과한 작은 텍스트 디코더의 표현력은 이와 같이 상세한 텍스트 ��공간을 감당하기에는 한계가 있었습니다. 이는 모델의 능력 수준을 초과하는 복잡하고 과도한 정보를 학습하는 것과 같았습니다. 예를 들면 이동진 평론가의 ‘상승과 하강으로 명징하게 직조해낸 신랄하면서 처연한 계급 우화’라는 영화평을 초등학생이 감당하려고 하는 것과 비슷합니다.
애초에 가정했던 모바일 예제 시나리오에서는 단순하면서 일반적인인 스타일이 더 적합했습니다. 이에 저희는 'Simple & General'을 목표 스타일로 잡은 뒤 이 스타일에 맞춰 학습 데이터를 정제하면 품질을 보다 안정적으로 끌어올릴 수 있을 것이라고 예상했습니다. 개발 팀 내에서는 이를 ‘눈높이 교육’이라고 지칭했습니다.
아래는 ‘Simple & General’ 스타일로 변환한 예제입니다.
- 한 마리의 골든 리트리버 성견과 스코티시 폴드 아기 고양이 한마리 → 개와 고양이
- 베이컨 2줄과 써니 사이드 업으로 조리된 계란 2개와 팬 케이크가 곁들여진 아메리칸 브랙 퍼스트가 놓인 북유럽 스타일의 모던한 식탁 → 식탁 위의 음식
- 단풍이 붉게 물든 산을 배경으로 파란색 아웃도어 재킷을 입은 남성이 바위에 앉아 휴식을 취하고 있다. 그의 옆에는 검은색 배낭과 스테인리스 텀블러가 놓여 있으며, 발 아래로는 구불구불한 등산로가 이어져 있는 풍경 → 등산 중인 남성
1단계 지식 증류: 자기회귀 교사 모델 → 비자기회귀 학생 모델
저희는 바로 비자기회귀 모델을 학습하는 것이 아니라, 우선 기존 모델의 구조를 유지하면서 자기회귀 방식으로 학습을 진행했습니다. 이후 자기회귀로 학습한 모델을 교사 모델로 설정하고 자기회귀 방식으로 생성한 캡션으로 학생 모델인 비자기회귀 모델을 학�습시켰습니다. 이렇게 하면 같은 크기의 텍스트 공간에서 같은 눈높이를 유지하면서 캡션을 생성해 캡션의 품질과 학습 안정성을 높일 수 있을 것이라고 기대했습니다. 아래는 그 결과입니다.
| 단계 | 교사 모델 | 훈련 데이터 | 학생 모델 | 수락 비율 |
|---|---|---|---|---|
| 베이스라인 | Phi-3.5 | 재생성한 데이터 | 자기회귀 교사 모델 | 0.66 |
| 1단계 지식 증류 | 자기회귀 교사 모델 | 자기회귀 캡션 | 비자기회귀 학생 모델 | 0.76 |
위와 같이 첫 번째 지식 증류를 통해서 수락 비율이 0.66에서 0.76으로 10%p 개선됐습니다. 자기회귀 모델의 '눈높이'가 비자기회귀 학습에 도움이 된 것입니다.
2단계 지식 증류: 비자기회귀 모델을 교사 모델로 재활용 + 미수락 캡션 데이터 수정
1단계 지식 증류를 통해서 학생 모델인 비자기회귀 모델이 교사 모델인 자기회귀 모델보다 더 'Simple & General'한 캡션을 생성한다는 것을 관찰했습니다. 자기회귀 모델은 "a living room with a couch, a table, and a lamp"처럼 상세한 문장을 생성하는 반면, 비자기회귀 모델은 "a living room with a couch"처럼 보다 간결한 문장을 생성했습니다. 이런 차이는 자기회귀 방식��과는 달리 전체 문장의 구성 토큰을 병렬로 한 번에 생성해야 하는 비자기회귀 모델이 훨씬 더 간결한 스타일의 문장을 만들려는 경향이 있기 때문에 발생한 것으로 추정됩니다.
여기에 착안해서 1단계 지식 증류에서 학습이 끝난 비자기회귀 모델을 이번에는 교사 모델로 한 번 더 사용하는 아이디어를 떠올렸습니다. 즉, 1단계 지식 증류에서는 모델 파라미터 규모의 차이 관점에서 눈높이를 맞췄다면, 이번에는 토큰 생성 방식의 차이 관점에서 눈높이를 맞춰 주자는 생각이었습니다.
여기서 한 가지 고려해야 할 점은 앞서 1차 지식 증류로 학습한 비자기회귀 모델의 수락 비율이 76%밖에 되지 않았기에 학습을 위해 생성한 캡션 내에도 비슷한 비율의 비문이 있을 수 있다는 것입니다. 이를 해결하기 위해 외부 LLM 모델(GPT-4o mini)을 사용해서 미수락 샘플을 필터링해 다시 LLM으로 비문을 수정(refinement)한 뒤 학습에 사용했습니다. 이를 통해 보다 다양한 데이터를 학습시키는 한편 비자기회귀 방식이 한 번 틀렸던 경우에 대한 오답 풀이를 제공함으로써 성능이 더욱 향상되지 않을까 기대했습니다.
각 단계를 비교한 결과는 다음과 같습니다.
| 전략 | 교사 모델 | 훈련 데이터 | 학생 모델 | 수락 비율 |
|---|---|---|---|---|
| 2단계 지식 증류 | 비자기회귀 학생 모델 (1단계의 학생 모델) | 비자기회귀 캡션 | 비자기회귀 학생 모델 | 0.83 |
| 2단계 지식 증류 + GPT를 이용한 미수락 캡션 데이터 수정 | 비자기회귀 학생 모델 (1단계의 학생 모델) | 비자기회귀 캡선 + 미수락 캡션 데이터 수정 | 비자기회귀 학생 모델 | 0.89 |
GPT-4o mini를 이용해 미수락 캡션 데이터를 수정할 때에는 다음 프롬프트와 같이 ‘문법을 고치고 반복을 제거하라'는 단순한 지시로 캡션을 보정해 교체했습니다. 결과적으로 최종 수락 비율는 0.89로, BLIP-1과 동등한 수준에 도달했습니다.
Fix the following caption to be grammatically correct and
remove any repetition or broken words: {caption}최종 결과
다음은 비자기회귀 캡션 생성 모델을 다단계 지식 증류 방법으로 학습시키는 과정을 단계별로 나타낸 그림입니다.
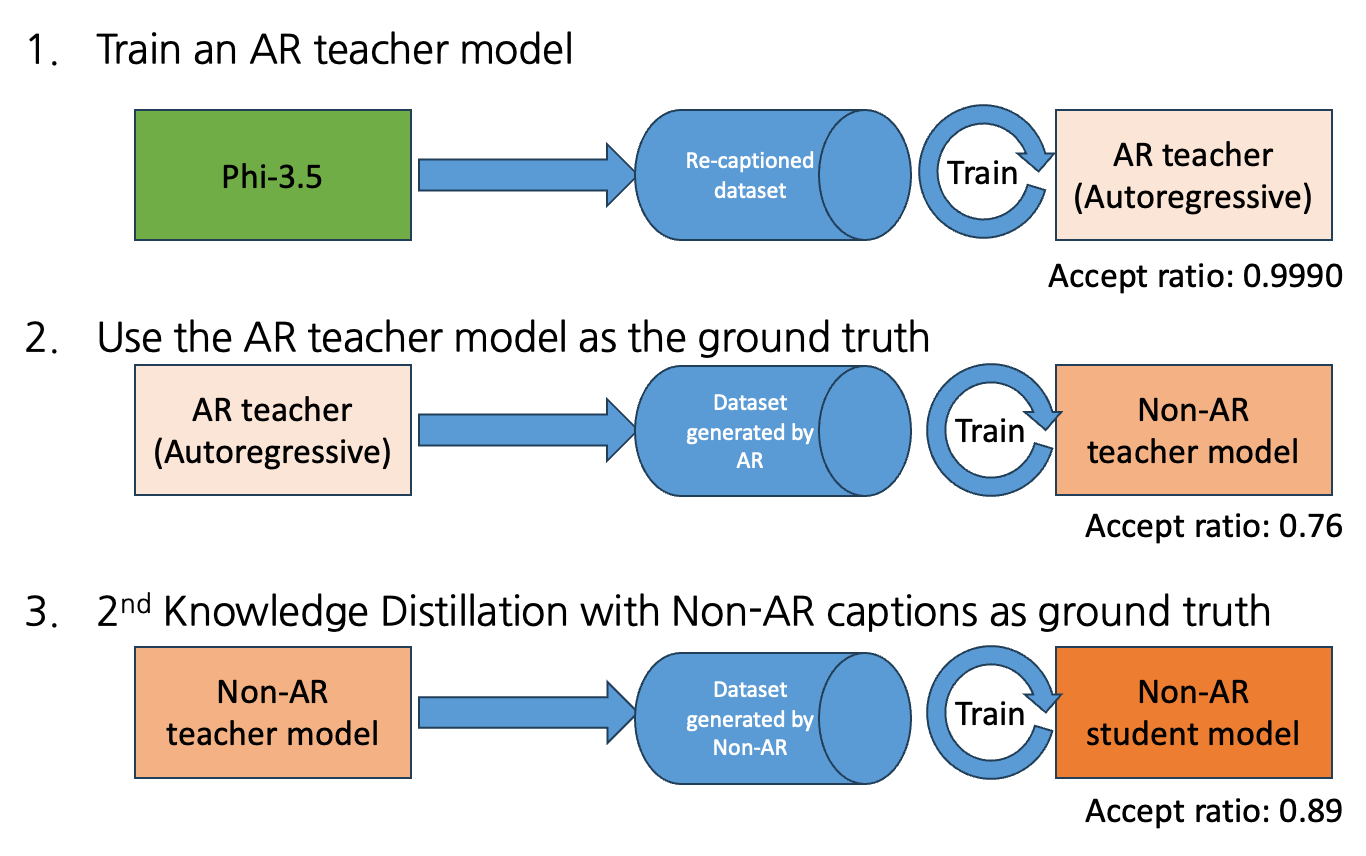
최종적으로 속도는 5초 이상에서 200~400ms로 12배 향상됐고, 크기는 227MB에서 172MB로 24% 감소했으며, 품질은 BLIP-1과 거의 동등한 수준(0.89 대 0.92)을 달성했습니다.
| 모델 | 크기 | 수락 비율 | 속도 |
|---|---|---|---|
| BLIP-1(자기회귀) | 227MB(양자화) | 0.92 | 5초 이상 |
| 자체 모델(비자기회귀) | 172MB | 0.89 | 200~400ms |
인사이트: 눈높이 교육
다단계 지식 증류의 핵심 인사이트는 '단계적 난이도 조절'입니다. Phi-3.5 같은 거대 모델은 생성한 이미지 캡션이 너무 상세해서 파라미터 사이즈도 작고 전체 문장을 한 번에 생성해야 하는 비자기회귀 모델이 따라가지 못했습니다. 이 때문에 최초 수락 비율은 0.66에 불과했습니다.
이를 개선하기 위해 보다 쉬운 난이도인 자기회귀 방식으로 학습한 자기회귀 교사 모델은 파라미터 사이즈가 동일한 만큼 비자기회귀 모델이 배울 수 있는 수준의 캡션을 생성했고 수락 비율은 0.76이었습니다. 마지막으로 비자기회귀 모델 자체가 교사 모델이 되었을 때에는 가장 적합한 ‘Simple & General' 스타일을 학습해 수락 비율이 0.89에 도달했습니다. 각 단계의 교사 모델이 학생 모델의 현재 능력에 맞는 '눈높이'로 맞춰 가르치는 것이 핵심입니다.
온디바이스 성능 개선: 초저지연 달성 방법
최종 모델 크기 및 구성 요소
최종 모델은 이미지 인코더 43MB(FP16)에 텍스트 디코더 129MB(동적 양자화)로 총 172MB였습니다.
실제 기기에서 콜드 스타트/이미지 인코딩/ 텍스트 디코딩 지연 측정 결과
Samsung Galaxy Fold 4(CPU) 기준으로 콜드 스타트는 약 200ms, 이미지 인코딩은 120ms, 텍스트 디코딩은 30ms 수준이었고, 전체 캡션 생성은 200~400ms 범위에서 작작했습니다(번역 작업 시 약 60ms 추가).
| 단계 | 지연 | 비고 |
|---|---|---|
| 콜드 스타트 | 200ms | 첫 실행(모델 로딩) |
| 이미지 인코딩 | 120ms | 이미지 → 임베딩 |
| 텍스트 디코딩 | 30ms | 비자기회귀 병렬 생성 |
| (옵션)번역 | 60ms | 영어 → 한국어(ML Kit) |
| 총합 | 200~400ms | 모바일 시나리오 충족 |
| 지표 | BLIP-1 | 자체 모델 | 개선 |
|---|---|---|---|
| 크기 | 227MB | 172MB | 24% 감소 |
| 속도 | 5초 이상 | 200~400ms | 12배 향상 |
| 수락 비율 | 0.89 | 0.89 | 동등 |
| 지표 | Gemini Nano | 자체 모델 | 개선 |
|---|---|---|---|
| 크기 | N/A(OS에 포함) | 172MB | 22배 경량 |
| 콜드 스타트 | 5~12초 | 200ms | 25배 향상 |
| 총 지연 | 5초 | 200~400ms | 12배 향상 |
비자기회귀의 위력은 텍스트 디코딩에 단 30ms밖에 걸리지 않는다는 점입니다. 자기회귀 방식에서 2,840ms가 걸렸던 것을 생각하면 전체 파이프라인의 성능이 12배 향상됐습니다.동
운영 시 고려 사항
다국어 캡션에서는 번역 모델(예: ML Kit)을 추가로 다운로드해야 하는 경우가 있습니다. ML Kit을 번역 모델로 사용하면 영어-한국어(약 30MB), 영어-일본어(약 30MB) 등을 추가로 다운로드해야 합니다. 첫 실행 시에는 네트워크가 필요하지만 이후에는 완전 오프라인으로 작동합니다. 메모리 사용량은 모델 로딩 시 약 200MB RAM, 추론 시 추가로 100MB 정도가 필요해 총 300MB 수준이며 모바일 서비스에서 허용 가능한 범위입니다. 하지만 앱 첫 실행 시 발생하는 모델 다운로드 과정이 UX에 영향을 줄 수 있으므로 '언제 다운로드할지', '실패 시 폴백은 무엇인지' 같은 운영 정책을 함께 설계해야 했습니다.
마치며: 재사용 가능한 학습 패턴
이 프로젝트의 두 과제(다국어 이미지 검색, 초저지연 이미지 캡션 생성)는 겉보기에는 서로 다른 문제처럼 보이지만 실제로 문제를 해결한 핵심 방법은 같습니다. 바로 지식 증류입니다. 모델의 크기를 키우거나 연산을 늘리는 방식으로 문제를 풀기 어려운 온디바이스 환경을 고려해 큰 모델의 표현력과 정답 분포를 작은 모델이 학습 가능한 형태로 옮겨오는 지식 증류를 활용한 것이 핵심입니다.
다국어 이미지 검색 기능에서는 이미 검증된 영어 임베딩 공간을 그대로 보존한 채 텍스트 인코더만 교사–학생 정렬로 다국어를 확장해 번역 의존도를 줄였습니다. 캡션 생성 기능에서도 비자기회귀로 속도를 먼저 확보한 뒤 품질은 캡션 재생성과 다단계 지식 증류로 끌어올렸는데 여기서 핵심 인사이트는 저희 팀에서 ‘눈높이 학습’이라고 부른 단계적 난이도 조절이었습니다. 처음부터 거대 모델(Phi-3.5)의 상세한 캡션을 그대로 학습시키기보다는 작은 모델이 감당할 수 있는 스타일과 난이도로 데이터를 정리하고, 자기회귀 교사 모델 → 비자기회귀 학생 모델로, 이후 다시 비자기회귀 모델을 교사로 재활용해 목표 문장(짧고 일반적인 캡션)에 수렴시키는 방식이 수락 비율을 높엿습니다.
정리하면, 온디바이스에서의 학습은 '모델을 잘 학습시키는 일'이라기보다 지식 증류를 기반으로 목표 품질과 제약 사이의 간극을 메우는 설계 문제에 가까웠습니다. 같은 조건에서 비슷한 문제를 풀 때도 증류를 어떻게 구성하고(무엇을 고정/재사용할지), 어떤 데이터를 만들고(스타일/난이도), 어떤 지표로 루프를 닫을지(수락 비율)가 결과를 결정한다는 것을 확인할 수 있었습니다.
이 글은 2024년부터 2025년까지 약 6개월간 진행한 온디바이스 이미지 AI PoC 프로젝트의 기술적 경험을 공유하기 위해 작성했습니다. 실험 수��치와 세부 구현 사항은 내부 환경 및 기기 사양에 따라 달라질 수 있습니다.
참고 자료
- 논문
- 지식 증류
- Radford et al., "Learning Transferable Visual Models From Natural Language Supervision", ICML 2021
- Gou et al., "Knowledge Distillation: A Survey", arXiv 2021
- 비자기회귀 및 캡션 생성
- Tewel et al., "Non-autoregressive Sequence-to-Sequence Vision-Language Models", CVPR 2024
- Mokady et al., "ClipCap: CLIP Prefix for Image Captioning", ACL 2021
- Hessel et al., "CLIPScore: A Reference-free Evaluation Metric for Image Captioning", EMNLP 2021
- Graves et al., "Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks", ICML 2006
- 벤치마크
- Ramakrishna et al., “CIDEr: Consensus-based Image Description Evaluation”, CVPR 2015
- Jack et al., “CLIPScore: A Reference-free Evaluation Metric for Image Captioning”, EMNLP 2021
- 지식 증류
- 오픈소스
- 모델
- CLIP4Clip: https://github.com/ArrowLuo/CLIP4Clip
- BLIP-1: https://huggingface.co/Salesforce/blip-image-captioning-base
- BLIP-2: https://huggingface.co/docs/transformers/main/en/model_doc/blip-2
- MobileVLM: https://github.com/Meituan-AutoML/MobileVLM
- PaliGemma: https://ai.google.dev/gemma/docs/paligemma
- MiniCPM: https://github.com/OpenBMB/MiniCPM-o
- Google GenAI Image Description: https://developers.google.com/ml-kit/genai/image-description/android
- Microsoft Phi-3.5-vision: https://huggingface.co/microsoft/Phi-3.5-vision-instruct
- 도구
- 모델


