안녕하세요. Data Platform Dev에서 쿠버네티스 클러스터를 운영하며 컴포넌트를 개발하는 이현규입니다. 제가 운영하는 쿠버네티스 클러스터는 약 800대 규모로 주로 사내 데이터 플랫폼과 사내 MLOps 플랫폼의 ML 잡들이 실행되고 있는데요. 이번 글에서는 Informer를 사용해 쿠버네티스 중계 API 서버를 구축하고 성능을 개선한 경험을 공유하겠습니다.
쿠버네티스 중계 API 서버가 필요했던 이유
먼저 쿠버네티스 중계 API 서버가 왜 필요했는지 말씀드리겠습니다.
사내 데이터 플랫폼의 쿠버네티스 클러스터는 멀티 테넌트(multi-tenant) 형태로 구성된 대규모 클러스터입니다. 팀별로 각자의 네임스페이스를 생성하고 사용하는 형태로 단일 클러스터에 약 200명 정도의 사용자가 존재하는데요. 기본적으로 RBAC(Role-Based Access Control)으로 사용자 권한을 관리해서 일반 사용자가 민감한 클러스터 레벨의 컴포넌트를 수정하거나 조회하는 것을 방지하고 있습니다. 사용자는 본인 소유의 네임스페이스 레벨의 오브젝트만 조회하고 수정할 수 있습니다. 그래서 일반 사용자는 퍼시스턴트볼륨(PersistentVolume)이나 클러스터롤(ClusterRole) 같은 클러스터 레벨의 오브젝트를 조회할 수 없는 상황입니다.
이런 상황에서 모든 노드의 스케줄링 가능한 리소스 현황을 보고 싶다는 니즈가 들어왔습니다. 노드에서 특정 파드(pod)를 게시했을 때 파드가 스케줄링될 수 있는 노드가 있는지 확인하고 싶었던 것으로, 모든 노드에 대해서 kubectl describe <node> 명령어와 같은 수준의 리소스 체크를 하고 싶다는 니즈였습니다. kubectl describe <node> 명령어를 실행하면 아래와 같이 Allocated resources에서 CPU와 메모리 현황을 파악할 수 있고, 이를 통해 어떤 크기의 파드를 스케줄링할 수 있는지 알 수 있습니다.
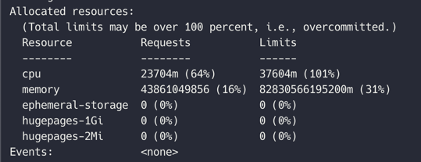
그런데 사용자에게 kubectl describe <node>를 허용하려면 클러스터의 모든 파드에 대한 조회 권한 또한 허용해야 합니다. kubectl describe <node>는 모든 파드를 가져온 다음 노드에 포함된 특정 파드만 필터링해 노드에 스케줄링된 파드의 리소스를 전부 계산하는 형태로 작동하는 명령어인데요. 모든 파드에 대한 조회 권한이 없는 상태에서 kubectl describe <node> 명령어를 사용하면 아래와 같이 'not authorized'라고 나올 뿐 리소스 현황을 파악할 수는 없기 때문입니다.

하지만 최소 권한 원칙에 따라 특정 사용자가 모든 파드를 조회할 수 있도록 허용하고 싶지는 않았습니다. 그래서 다른 방법을 고민했고, 사용자를 위해 특수한 목적의 API 서버를 제공하는 아이디어를 떠올렸습니다. 아래와 같이 쿠버네티스 RBAC과는 별개로 리소스 현황을 JSON 형태로 반환하는 중간자 성격의 API 서버를 별도로 구축하는 것이죠.

Python으로 Informer 없이 쿠버네티스 중계 API 서버 구현하기
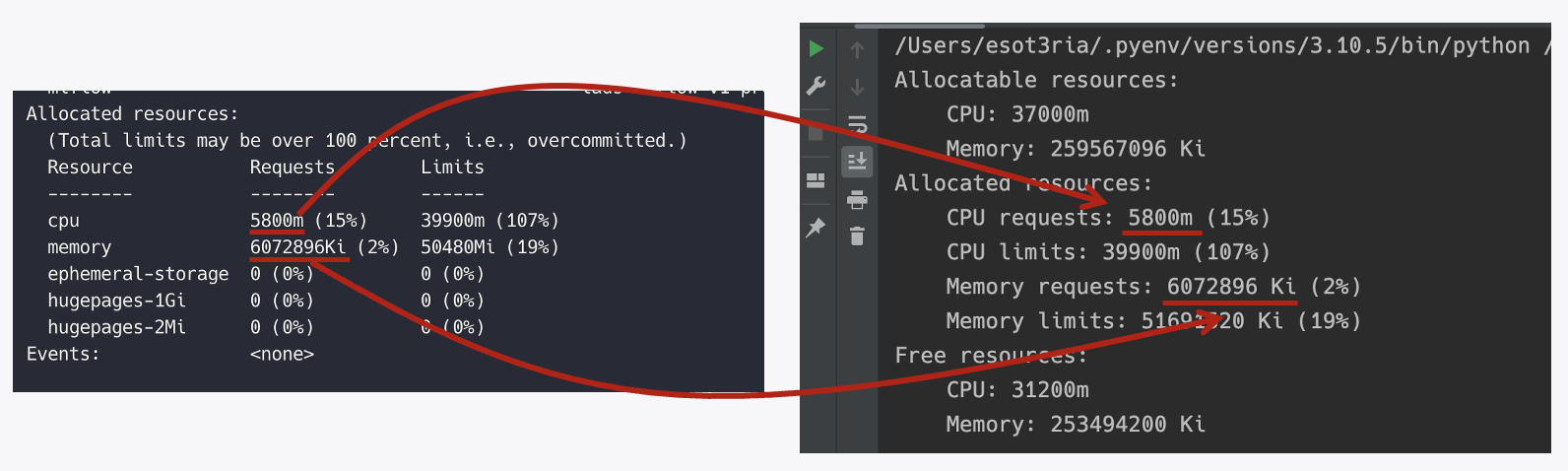
위 아이디어를 처음 구현할 때는 Python으로 Informer 없이 쿠버네티스 중계 API 서버를 구현했습니다. 쿠버네티스 Python 클라이언트를 사용해서 중계 API 서버를 구축하고 kubectl describe <node>의 로직을 그대로 따라 구현해 API 서버에서 describe 정보를 반환할 수 있도록 설계하고 작업했습니다. 이때 반환되는 값은 kubectl top <node> 명령어 실행 결과와는 다르다는 것에 주의해야 합니다. kubectl top <node>는 현재 리소스의 사용량을 반환하지만, 저희가 반환하려는 값은 노드에서 파드를 스케줄링할 수 있는 리소스의 양입니다.
내부 로직 소개
단일 노드의 스케줄링 가능한 리소스 양을 표시하려면 다음과 같은 과정을 거쳐야 합니다.
- 노드에서 파드에 할당 가능한 용량(Allocatable capacity)을 조회합니다.
- 전체 파드 목록을 가져온 후 노드에 스케줄링된 파드들을 fieldSelector로 필터링합니다.
- 필터링된 파드들의 CPU와 메모리 현황을 합산합니다.
- 합산 결과에서 요청 리소스(Requests)의 총합과 할당 가능한 CPU/메모리의 차이가 노드의 스케줄링 가능한 리소스입니다.
이 과정은 kubectl describe <node> 명령어 실행 시 내부에서 진행되는 로직과 동일합니다.
구현 코드 살펴보기
아래는 kubectl describe <node>의 로직을 구현한 코드입니다.
# Get the pods running on the specified node
pods = api_instance.list_pod_for_all_namespaces(field_selector=f'spec.nodeName={node_name}').items
# ...
# Traverse pods
for pod in pods:
# Skip Terminated Pods
if pod.status.phase == "Succeeded" or pod.status.phase == "Failed":
continue
# ...
for container in pod.spec.containers:
if container.resources:
# Calculate cpu request
if container.resources.requests and container.resources.requests.get('cpu'):
container_cpu_requests = container.resources.requests.get('cpu')
if 'm' in container_cpu_requests:
total_requests_cpu += int(container_cpu_requests.strip('m'))
else:
total_requests_cpu += int(container_cpu_requests) * 1000
# ...
# Get information about the specified node
node_info = api_instance.read_node(node_name)
# Get the allocatable CPU and memory on the node
allocatable_cpu = int(node_info.status.allocatable['cpu']) * 1000
allocatable_memory = int(node_info.status.allocatable['memory'].strip('Ki')) * 1024
# ...
# Calculate the free CPU and memory on the node
free_cpu = allocatable_cpu - total_requests_cpu
free_memory = allocatable_memory - total_requests_memory위 코드를 한 부분씩 살펴보겠습니다.
먼저 네임스페이스에서 특정 노드가 스케줄링된 것을 필터링하며 파드를 순회합니다. 실제로는 파드 내 컨테이너를 순회하겠죠. Succeeded나 Failed 상태인 파드의 경우 합산에서 제외합니다.
# Get the pods running on the specified node
pods = api_instance.list_pod_for_all_namespaces(field_selector=f'spec.nodeName={node_name}').items
# ...
# Traverse pods
for pod in pods:
# Skip Terminated Pods
if pod.status.phase == "Succeeded" or pod.status.phase == "Failed":
continue다음으로 파드에 정의된 모든 컨테이너를 순회하며 요청 리소스를 합산합니다. 이때 CPU 리소스를 합산할 때는 서로 다른 단위(코어와 밀리 코어)를 적절히 처리합니다.
for container in pod.spec.containers:
if container.resources:
# Calculate cpu request
if container.resources.requests and container.resources.requests.get('cpu'):
container_cpu_requests = container.resources.requests.get('cpu')
if 'm' in container_cpu_requests:
total_requests_cpu += int(container_cpu_requests.strip('m'))
else:
total_requests_cpu += int(container_cpu_requests) * 1000다음으로 kube-apiserver에서 노드의 할당 가능한 CPU와 메모리양을 조회합니다.
# Get information about the specified node
node_info = api_instance.read_node(node_name)
# Get the allocatable CPU and memory on the node
allocatable_cpu = int(node_info.status.allocatable['cpu']) * 1000
allocatable_memory = int(node_info.status.allocatable['memory'].strip('Ki')) * 1024마지막으로 할당 가능한 리소스와 총 요청 리소스의 차이를 구하면 특정 노드에 파드를 스케줄링할 수 있는 용량(free_cpu, free_memory)이 나옵니다.
# Calculate the free CPU and memory on the node
free_cpu = allocatable_cpu - total_requests_cpu
free_memory = allocatable_memory - total_requests_memory결국 제가 원했던 것은 이것입니다. kubectl describe <node> 명령어를 실행하면 현재 스케줄링된 CPU와 메모리 양이 나오는데 이와 똑같은 결과를 반환하고 싶었습니다.
Python으로 Informer 없이 구현한 쿠버네티스 중계 API 서버의 문제점
이렇게 구현하면 간단하게 요구 사항을 만족시킬 수 있을 것이라고 생각했는데 두 가지 문제가 있었습니다.
먼저 API 응답 속도가 굉장히 느렸습니다. kubectl describe 명령어의 고질적인 문제인데요. 노드 하나의 리소스를 계산할 때도 클러스터의 모든 파드 목록을 조회해야 합니다. 이 질의 비용 자체가 굉장히 비싸기 때문에 클러스터의 규모가 커질수록 API의 알고리즘 성능이 하락할 우려가 있습니다.
또 다른 문제는 kube-apiserver와 etcd에 많은 부하를 가한다는 것입니다. 앞서 말씀드렸듯 파드는 노드 단위가 아닌 네임스페이스 단위로 인덱싱돼 있기 때문에 항상 클러스터의 전체 파드 목록을 조회해야 하는데 이 과정은 kube-apiserver에 과도한 부하를 주었습니다. 스레드를 다수 생성해서 작동 방식을 비동기적으로 바꿔 우회하는 방법을 써도 한 리소스를 계산하는 데 10초 정도�가 걸렸습니다. RESTful API 서버의 한 엔드포인트를 호출하는 데 10초 이상 걸린다면 사실 사용할 수 없다고 봐야 합니다.
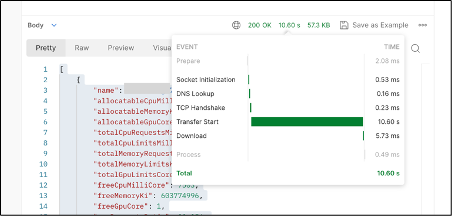
이를 해결하기 위해 캐싱하는 형태로 처리하는 방법을 구상하다가 Informer를 알게 됐고, 이를 이용해 중계 API 서버를 효율화하기로 결정했습니다.

Go로 Informer를 사용해 쿠버네티스 중계 API 서버 구현하기
이제 쿠버네티스 Go 클라이언트를 사용해서 Informer를 적용해 중계 API 서버를 다시 개발한 내용을 소개하겠습니다.
Informer는 굉장히 직관적인 이름입니다. 클러스터 오브젝트의 변화를 로컬 캐시에 동기화해주는 기능인데요. 특정 클러스터 오브젝트 타입에 대한 이벤트가 발생하면 클라이언트에 즉시 알려주는(inform) 역할을 하기 때문에 Informer입니다. CREATE/UPDATE/DELETE에 대한 이벤트를 지켜보고(listen) 있다가 이벤트에 맞춰서 로컬 캐시를 바꾸며, 주로 오퍼레이터(operator) 패턴을 구현하는 데 사용합니다(Informer와 관련해서는 쿠버네티스 커스텀 리소스 정의하고 관리하기(feat.컨트롤러) 글도 참고해 보세요).
Informer 캐시는 Informer로 동기화되는 특정 오브젝트 타입에 대한 로컬 캐시입니다. etcd와 ��별개로 오브젝트 타입의 모든 최신 데이터가 이 Informer 캐시에 유지되는데요. 저는 이를 이용해 kube-apiserver에 직접 질의하는 대신 Informer 캐시에서 오브젝트를 빠르게 읽어오고 싶었습니다.
Python에서 Go로 구현을 변경한 이유
Informer는 쿠버네티스 코어의 구성 요소가 아니며 일부 쿠버네티스 클라이언트에서만 지원하는 추가 기능입니다. 2024년 현재 기준으로 쿠버네티스 Go 클라이언트와 Typescript, Java 클라이언트에서만 Informer 구현을 지원하고 있습니다. 2019년에 Python 클라이언트에 Informer 구현 지원을 요구하는 이슈가 올라왔지만, 글을 작성하는 시점까지 4년째 "any updates on this?"라는 코멘트가 달리며 별다른 진전 없이 정체돼 있는 상황이었습니다.
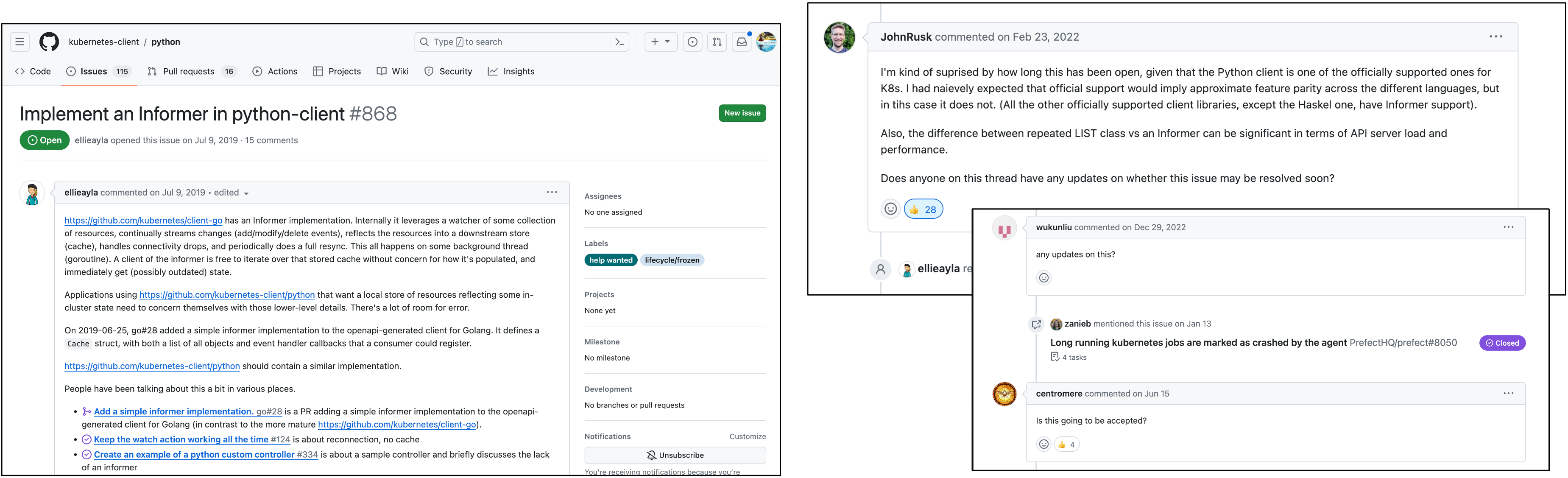
따라서 Python 클라이언트에서는 가까운 시일 안에 Informer를 사용할 수 없겠다고 판단했고, 번거로운 작업이기는 하나 서버의 성능 향상을 위해 API 서버의 구현 언어를 Python에서 Go로 변경하고, API 서버의 전체 로직을 Go 클라이언트를 사용해 재구현하는 작업을 진행했습니다.
Informer 소개
Informer의 작동 원리를 알아보겠습니다.

- 먼저 쿠버네티스 API에서 오브젝트가 변경됐다고 가정하겠습니다. 파드가 신규 배포된 상황이라고 하겠습니다.
- Informer가 파드 생성 이벤트를 감지합니다.
- Create 이벤트를 큐(RateLimitQueue)로 발행합니다.
- Syncer가 큐에서 발행된 이벤트를 팝(pop)합니다.
- Syncer가 Informer 캐시를 갱신합니다.
Informer를 사용하면 클러스터에 배포된 특정 리소스 타입에 대한 정보를 지속적으로 갱신할 수 있습니다. Informer는 클러스터에 배포된 리소스의 전체 정보를 풀 스캔하는 형태가 아니라 캐시와 이벤트 큐를 사용해 변경된 리소스에 대한 정보만 업데이트하는 형태로 구현돼 있으므로 kube-apiserver의 부하가 줄어드는 효과를 기대할 수 있습니다.
쿠버네티스 Go 클라이언트에서는 다음 세 가지 컴포넌트를 사용해 Informer를 구현합니다.
- Reflector: 쿠버네티스 API(etcd)에서 특정 오브젝트 목록을 가져와 Delta FIFO 큐에 넣습니다.
- Informer: Reflector가 가져온 데이터를 읽어 Indexer로 전달하며, 이벤트 핸들러가 등록돼 있다면 호출합니다.
- Indexer: 클라이언트 측의 Informer 캐시를 관리합니다.
Informer가 관리하는 오브젝트에 대한 조회(get/list) 요청은 Indexer가 관리하는 Informer 캐시에서 처리합니다. 요청에 대한 응답이 마스터 노드의 etcd를 거치지 않고 Informer 캐시의 내부 데이터를 기반으로 반환되므로 etcd의 부하를 줄이는 것은 물론 요청 응답 속도 향상도 기대할 수 있습니다.
Informer를 활용한 API 서버 재구현
Informer를 사용하는 방법은 직관적입니다. Go 클라이언트에서는 Informer를 주로 아래와 같이 SharedInformerFactory라는 형태로 사용하고 있습니다.
stopper := make(chan struct{})
defer close(stopper)
factory := informers.NewSharedInformerFactory(k8sClientSet, 0)
nodesInformer := factory.Core().V1().Nodes().Informer()
podsInformer := factory.Core().V1().Pods().Informer()
/***************************************************************************************/
// Start informer and wait until it gets a complete in-memory copy of pods
factory.Start(stopper)
factory.WaitForCacheSync(stopper)
/***************************************************************************************/
// Ignore returned ok and err for brevity
nodeIndexer := nodeInformer.GetIndexer()
nodeItemList := nodeIndexer.List()
for _, nodeItem := range nodeItemList {
println(nodeItem.(*corev1.Node).Name)
}
/***************************************************************************************/
podsIndexer := podsInformer.GetIndexer()
podItem, _, _ := podsIndexer.GetByKey("d8d-test/webserver-7fb67f9d9f-q8ptt")
pod := podItem.(*corev1.Pod)
fmt.Println("The Pod IP is", pod.Status.PodIP)위 코드를 한 부분씩 살펴보겠습니다.
nodesInformer는 노드 변경 이벤트를 추적하고, podsInformer는 파드 변경 이벤트를 추적하도록 정의했습니다.
stopper := make(chan struct{})
defer close(stopper)
factory := informers.NewSharedInformerFactory(k8sClientSet, 0)
nodesInformer := factory.Core().V1().Nodes().Informer()
podsInformer := factory.Core().V1().Pods().Informer()저희의 목표는 쿠버네티스 etcd가 가지고 있는 데이터를 복제한 로컬 캐시 저장소, 즉 Informer 캐시를 만드는 것입니다. 이때 etcd의 모든 리소스에 대한 데이터를 복제하는 것은 아닙니다. 노드 Informer와 파드 Informer만 선언했기 때문에 노드와 파드 오브젝트에 대한 Informer 캐시만 유지하는데요. Informer 팩토리의 동기화 메서드를 호출하면 팩토리가 etcd에게 질의해 'etcd가 그 시점에 가지고 있는 노드와 파드 오브젝트'를 가져오고, 이를 Informer 캐시 형태로 클라이언트의 인 메모리에 저장합니다.
// Start informer and wait until it gets a complete in-memory copy of pods
factory.Start(stopper)
factory.WaitForCacheSync(stopper)그런데 API 서버가 시작될 때 etcd의 데이터를 Informer 캐시에 단 한 번만 동기화한다면, etcd의 데이터와 API 서버의 Informer 캐시의 데이터가 점점 어긋나는 문제가 발생합니다.
앞서 Informer가 직관적인 이름이라고 말씀드렸던 것 기억나시나요? Informer는 etcd에서 오브젝트가 변화하는 이벤트를 감시(watch)하고, etcd 쪽에서 수행된 이벤트를 Informer 캐시에 주기적으로 반복함으로써 Informer 캐시가 최신 상태의 etcd 데이터를 유지할 수 있도록 도와줍니다.
이 부분이 Informer의 핵심이라고 볼 수 있습니다. 원격 측인 etcd에서 수행된 오브젝트를 변화시키는 이벤트를 감시하고, 이를 로컬 측인 Informer 캐시에 그대로 리플레이해 Informer 캐시와 etcd의 데이터를 동일하게 맞추는 것이지요.
이때 etcd의 모든 이벤트를 감지하고 동기화하는 것은 너무 비용이 많이 들고 느리기 때문에 오직 Informer로 미리 정의된 오브젝트에 대한 이벤트만 감시합니다. 저희는 노드와 파드 Informer를 선언했기 때문에 노드와 파드 오브젝트의 이벤트만 추적하며, 노드가 추가/수정/삭제될 때와 파드가 생성/수정/삭제될 때만 Informer가 반응하고 동일한 이벤트를 Informer 캐시에 리플레이합니다. 반면 네임스페이스나 서비스 같은 추적 대상이 아닌 오브젝트의 변경 이벤트는 Informer가 굳이 추적할 필요가 없으므로 무시합니다.
위와 같은 Informer의 동기화 로직에 따라 노드와 파드 리소스에 대한 etcd 복제본의 스냅샷을 로컬 메모리에 Informer 캐시 형태로 유지할 수 있습니다.
Informer 캐시에서 데이터를 꺼내 오는 것도 굉장히 간편합니다. Indexer를 사용해 Informer 캐시에서 노드 데이터를 가져올 수 있는데요. 앞서 보여드렸던 Python 클라이언트에서 노드 정보를 etcd에서 직접 가져오는 방식과 거의 유사합니다.
// Ignore returned ok and err for brevity
nodeIndexer := nodeInformer.GetIndexer()
nodeItemList := nodeIndexer.List()
for _, nodeItem := range nodeItemList {
println(nodeItem.(*corev1.Node).Name)
}파드와 같은 다른 오브젝트도 노드와 동일한 방식으로 Indexer에서 가져올 수 있고, etcd에서 직접 가져오는 것과 동일한 타입의 오브젝트로 다룰 수 있는데요. 다음은 Indexer에서 가져온 파드 오브젝트의 IP를 출력하는 예제입니다. Informer 캐시에서 가져온 오브젝트와 etcd에서 가져온 오브젝트를 다루는 방��식에는 큰 차이가 없습니다.
podsIndexer := podsInformer.GetIndexer()
podItem, _, _ := podsIndexer.GetByKey("d8d-test/webserver-7fb67f9d9f-q8ptt")
pod := podItem.(*corev1.Pod)
fmt.Println("The Pod IP is", pod.Status.PodIP)Informer 사용 결과
Python 클라이언트로 구현한 중계 API 서버를 Go 클라이언트로 재개발한 결과, 800개 노드의 스케줄링 가능한 리소스를 계산하는 데 걸리는 시간이 10초에서 약 0.2초로 줄어들었습니다.
마치며
다시 정리해 보겠습니다. 클러스터 권한 이상의 작업을 요구하는 특수한 사용자를 위해서 중계 API 서버라는 RESTful API 서버 구현이 필요했습니다. 그런데 쿠버네티스 Python 클라이언트로 빠르게 개발하려다 보니 직접 kube-apiserver에 쿼리를 하게 돼 성능과 부하 문제가 발생했습니다. 이 문제를 해결하기 위해 쿠버네티스 Go 클라이언트에서 제공하는 Informer를 사용했고, etcd와는 별도인 로컬 오브젝트 캐시인 Informer 캐시를 사용했습니다. 이를 통해 오브젝트를 읽어오는 비용을 kube-apiserver에 직접 질의할 때보다 크게 줄일 수 있었습니다.
이번 글에서는 중계 API 서버를 Informer를 활용해 재개발한 이야기를 공유드렸습니다. 사실 Informer는 주로 오퍼레이터를 구현하는 데 많이 사용됩니다. 따라서 Informer 자료를 찾아보면 상당수가 오퍼레이터 쪽 구현과 관련돼 있는데요. 이 글에서 소개한 방식처럼 Informer 캐시를 로컬 캐시로 쉽게 사용할 수 있는 방법으로도 활용할 수 있다는 점을 소�개하고 싶었습니다. Go 클라이언트에서 공식적으로 지원하는 Informer 기능을 쓰면 로컬 캐시를 굉장히 쉽게 구현할 수 있고, Redis 등을 사용해 억지로 etcd에 대한 로컬 캐시를 유지할 필요가 없습니다. Informer 캐시만 사용해도 kube-apiserver의 부하를 줄이고 더 효율적으로 통신할 수 있다는 점을 강조하고 싶었습니다. Informer의 새로운 쓰임이 여러분께도 도움이 되길 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


