안녕하세요. Cloud DBS 팀에서 사내 클라우드인 Verda의 데이터베이스와 OpenSearch 서비스 개발을 맡고 있는 강인배, 문현균입니다. 이번 글에서는 저희 팀에서 쿠버네티스 컨트롤러(이하 컨트롤러)를 활용해 커스텀 리소스를 사용하고 있는 방법을 사례와 함께 살펴보며 컨트롤러의 작동 방식을 설명하고 사용 팁을 공유하겠습니다.
참고로 이 글은 쿠버네티스 v1.21.9와 controller-runtime v0.12.3, client-go v0.24.2를 기준으로 작성했습니다.
컨트롤러 개요
컨트롤러가 내부에서 어떻게 작동하는지 간단히 한 번 살펴보겠습니다.
파드(pod)나 디플로이먼트(deployment) 같은 쿠버네티스 리소스는 크게 봤을 때 모두 동일한 방식으로 관리됩니다. 리소스가 변경되면 변경이 감지돼 컨트롤러로 이벤트가 전달되고, 이벤트를 받은 컨트롤러는 리소스가 '원하는 상태(desired status)'가 될 때까지 Reconcile이라는 함수를 이용해 조정하는 과정(참고)을 수행합니다.
 조금 더 친근한 예시로 살펴보겠습니다. 디플로이먼트를 생성하면 컨트롤러는 스펙 중
조금 더 친근한 예시로 살펴보겠습니다. 디플로이먼트를 생성하면 컨트롤러는 스펙 중 replicas의 값을 보고 해당 개수만큼 파드를 만듭니다. 아래 그림의 왼쪽 예시에서는 현재 원하는 상태의 replicas 값이 2이기 때문에 두 개의 파드를 생성합니다.
 만약 위 그림의 오른쪽처럼
만약 위 그림의 오른쪽처럼 replicas 값을 3으로 변경하면 파드가 세 개로 변경됩니다. 변경 과정을 살펴보면, 먼저 디플로이먼트라는 리소스에 변경이 발생했으니 관련 이벤트가 디플로이먼트를 관장하는 디플로이먼트 컨트롤러로 전달됩니다. 그럼 디플로이먼트 컨트롤러가 파드가 하나 부족하다는 것을 파악하고 새로 파드를 하나 생성합니다.
이 설명 과정에 의문이 있는 분들도 계실 것 같은데요. 사실 디플로이먼트와 파드 사이에는 레플리카셋(ReplicaSet)이라는 쿠버네티스 리소스가 존재하지만, 컨트롤러의 작동을 직관적으로 간단하게 설명하기 위해 중간 과정을 어느 정도 생략했습니다.
컨트롤러 활용 사례
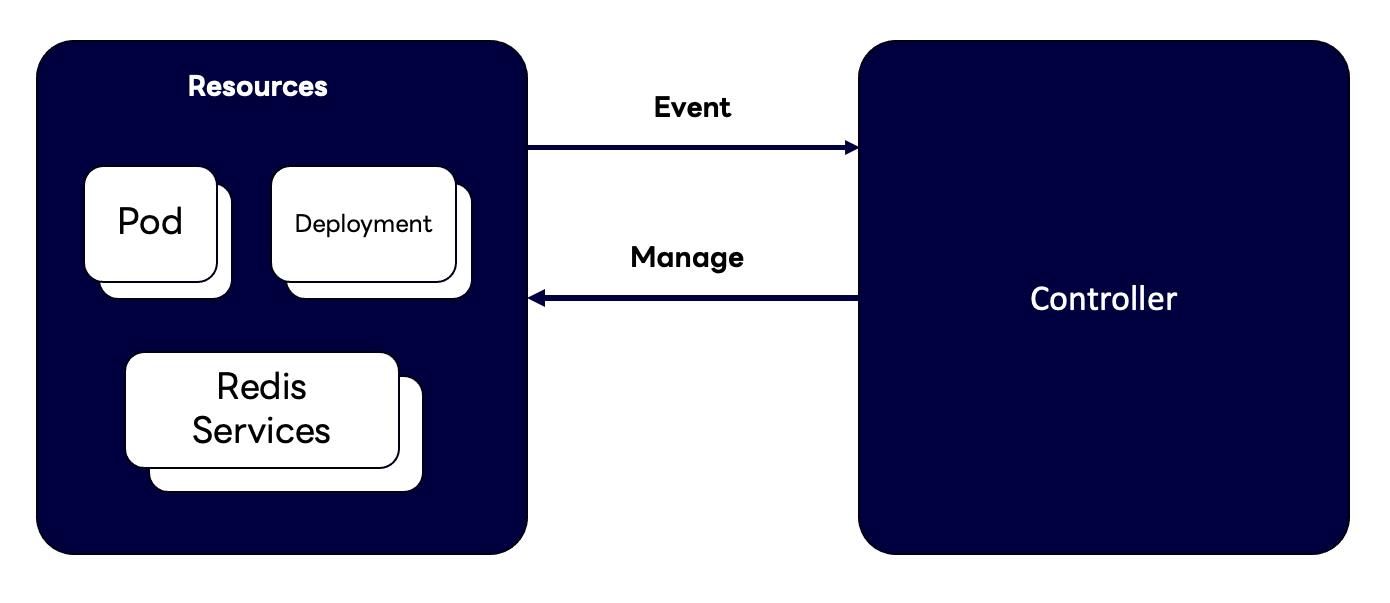
다음은 저희 팀에서 컨트롤러를 어떻게 사용하고 있는지 간단하게 나타낸 그림입니다.

위 그림을 보면 보편적으로 사용하는 리소스가 아니라 Redis Services라는 다소 생소한 이름의 리소스가 하나 있습니다. 쿠버네티스를 사용하시는 분들도 본 적이 없으실 텐데요. 저희 팀에서 커스텀 리소스로 정의하고 컨트롤러를 작성해서 관리하고 있는 프로덕트이기 때문입니다.
저희 팀에서는 앞서 살펴본 파드랑 디플로이먼트를 관리하는 방식으로 이 Redis Services를 관리하고 있습니다. Redis뿐 아니라 MySQL과 MongoDB, OpenSearch와 같은 프로덕트를 이렇게 컨�트롤러를 이용해서 관리 및 제공하고 있습니다.
이 관리 방식을 디플로이먼트와 비교해서 설명해 보겠습니다. 디플로이먼트를 만들어서 replicas를 지정하면 지정한 개수에 맞게 파드가 생성됩니다. 이와 비슷하게 Redis Service를 생성하고 replicas를 지정하면 replicas 개수에 맞는 VM이 생성돼 사용자에게 제공됩니다. 커스텀 리소스를 생성하면 커스텀 리소스를 관리하는 컨트롤러가 VM을 생성하는 것이지요.

다음은 Redis Service 예시로 살펴보는 구체적인 커스텀 리소스 활용 방법입니다.
- 파드를 생성하기 위해
kubectl get pod명령어를 실행하는 것처럼 Redis Service를 생성하기 위해서kubectl get redisservice을 실행합니다. - YAML 파일로 Redis Service 스펙을 지정하고 해당 스펙에 맞게 Redis Service가 생성되도록
kubectl apply -f redisservice.yaml명령어를 실행합니다. - 생성된 커스텀 리소스에 대응하는 서버가 잘 생성됐는지 확인합니다.
커스텀 리소스 등록 및 컨트롤러 작성하기
저희는 위와 같은 방식으로 커스텀 리소스를 정의해서 사용자에게 데이터베이스 서비스를 제공하고 있습니다. 커스텀 리소스를 정의하고 제공하기 위해서는 쿠버네티스에 커스텀 리소스를 등록하고 컨트롤러를 작성하는 과정이 필요합니다.
VM을 예시로 들어보겠습니다. 저희는 Verda라는 사내 클라우드 서비스를 사용하고 있습니다. Verda VM이라는 리소스는 실��제로 Verda의 VM과 일대일로 대응되는 커스텀 리소스입니다. 따라서 Verda VM이라는 리소스가 생성되면 Verda에 실제 VM이 생성돼야겠죠. 아래는 파드를 이를 위해서 아래와 같은 역할을 하는 컨트롤러를 작성합니다.
커스텀 리소스 등록하기
우선 쿠버네티스 API에 커스텀 리소스를 등록해야 합니다. 아래 그림을 보면 쿠버네티스 API를 블록 장난감처럼 묘사했습니다. 마치 블록을 하나 만들어 붙이는 것처럼 커스텀 리소스에 대한 API도 쿠버네티스 API에서 제공하도록 붙여 넣을 수 있기 때문입니다. 쿠버네티스 API에서 Verda VM에 대한 CRUD도 제공하도록 만드는 것이죠. 이와 같이 Verda VM이란 커스텀 리소스에 대한 API를 쿠버네티스 API 서버에서 제공하도록 만들면, 컨트롤러나 클라이언트가 해당 커스텀 리소스에 대한 작업을 수행하거나 업데이트하는 과정을 거칠 수 있습니다.

조금 더 구체적으로 설명드리자면, '블럭 만들기'에 비유할 수 있는 작업은 아래 verdaVM-crd.yaml과 같이 커스텀리소스데피니션(CustomResourceDefinition)이라는 쿠버네티스 리소스를 매니페스트 파일로 작성하는 것입니다. 이어서 '만든 블럭을 기존 블럭에 붙이는 과정'은 apply(`kubectl apply -f verdaVM-crd.yaml`) 명령어를 실행해서 생성하는 것이라고 할 수 있습니다.
# verdaVM-crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadate:
name: verdaVMs.pushnpull.linecorp.com
spec:
...컨트롤러 작성하기
커스텀리소스데피니션을 쿠버네티스 클러스터에 등록했다면 이제 컨트롤러를 작성해야 합니다. 컨트롤러의 궁극적인 목표는 리소스 스펙을 충족하는 상태로 만드는 것입니다. VM의 경우, 아래와 같이 스펙(flavor, image)에 맞게 VM을 생성하고 이를 ACTIVE 상태로 만든 뒤 이 상태를 기록하는 것이라고 할 수 있습니다.

즉, 컨트롤러가 담당해야 하는 중요한 두 가지 로직은 아래와 같습니다.
- VerdaVM 리소스가 생성됐을 때 실제 사내 클라우드 Verda에 VM 생성
- VerdaVM 리소스의 서버 상태를 확인해서
ACTIVE상태까지 도달했는지 검증
이 두 로직을 잘 수행하게 만들기 위해서 어떻게 컨트롤러를 작성해야 하는지 간단히 살펴보겠습니다. 참고로 아래에서 스텝 1과 2로 나눠 설명하지만 각 스텝이 순차적으로 실행되는 것은 아닙니다. 각 동기화 함수가 모두 같이 수행되는데 스텝 2의 주요 로직이 스텝 1 성공을 기다린 후에 작동하기 때문에 나눈 것입니다.
스텝 1: VerdaVM 리소스 생성
처음에 VerdaVM 리소스를 생성하면 UUID(universally unique identifier) 필드가 비어있습니다. 이 필드가 비어있다면 ‘아직 Verda에서 VM을 생성하지 않았다’고 판단하고, Verda VM 생성 API를 호출한 뒤 이후 UUID를 전달받으면 VerdaVM 리소스에 업데이트합니다. 업데��이트 후에는 UUID 필드에 값이 있으므로 ‘VM이 이미 생성됐다’고 판단하고 종료합니다.
스텝 2: VerdaVM 리소스의 서버 상태 확인
VM을 생성한 뒤에는 아래와 같은 과정으로 상태를 검사합니다.
- 만약 UUID가 없다면 아직 VM이 생성된 것이 아니니 애초에 상태를 검사할 필요가 없습니다. 이런 경우에는 UUID가 생성될 때까지, 즉 VerdaVM 리소스가 생성될 때까지 기다립니다.
- UUID가 있다면 상태를 확인합니다. 아직 ACTIVE가 아니라면 API를 일정 간격으로 계속 호출해서 ACTIVE라는 결과가 나올 때까지 상태를 업데이트하는 과정을 거칩니다.
- ACTIVE라는 결과를 받으면 상태를 ACTIVE로 업데이트하고 로직을 종료합니다.
컨트롤러를 어떻게 작성하는지 매우 간단하게 말씀드렸는데요. 저는 컨트롤러를 작성하면서 여러 가지 이슈를 만났고, 컨트롤러가 내부에서 어떻게 작동하는지 파악한 뒤에야 문제가 발생하는 위치와 해결 방법을 알 수 있었습니다. 저와 같은 어려움을 겪지 않으시도록 컨트롤러의 내부 작동 방식을 조금 더 깊이 설명하겠습니다.
컨트롤러 내부 작동 방식 살펴보기
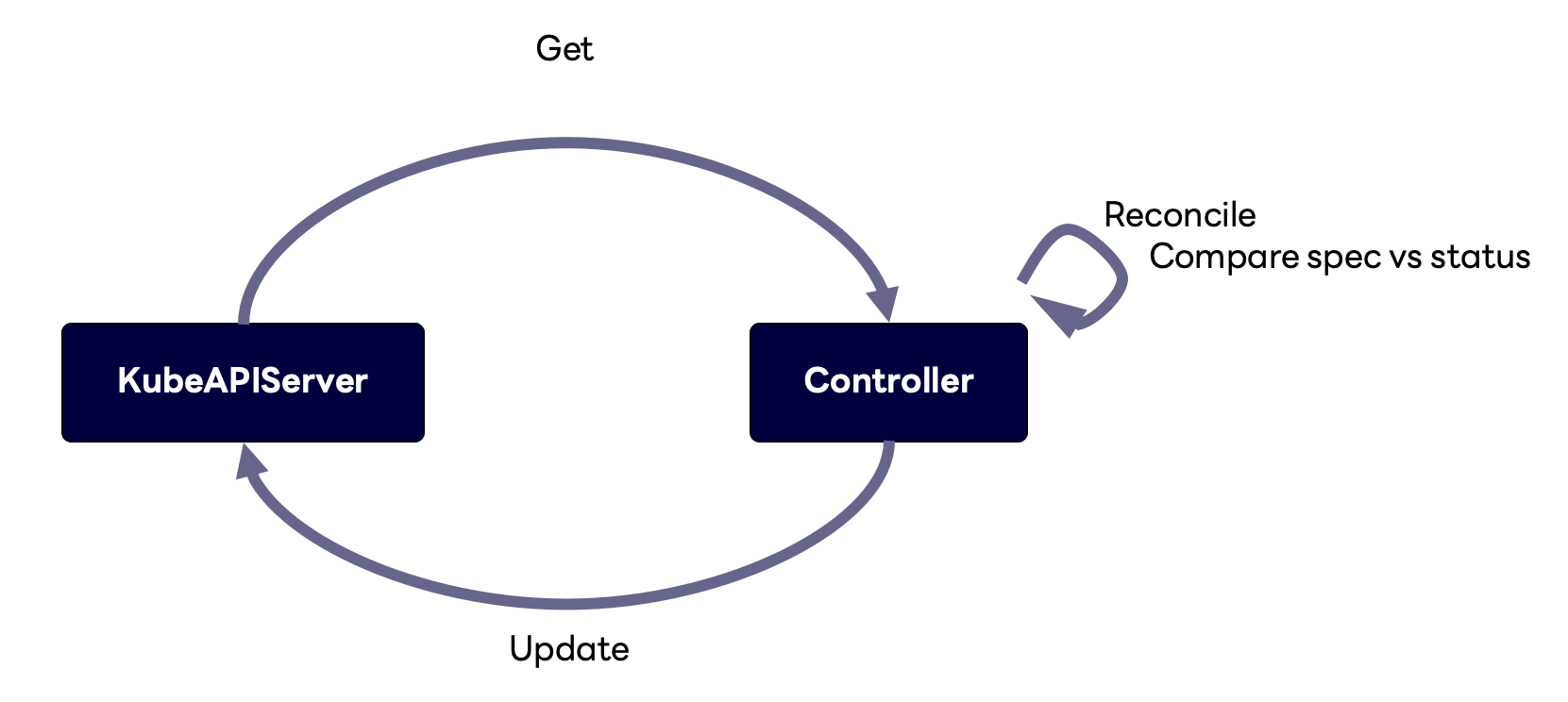
먼저 컨트롤러에 어떻게 이벤트가 들어오는지와 어떻게 오브젝트를 가져오는지 등 작동 방식에 초점을 맞춰 살펴보겠습니다. 앞서 본 컨트롤러는 API 서버를 통해 오브젝트를 가져와서 스펙과 상태를 비교한 뒤, Reconcile이라는 함수를 이용해 스펙과 상태가 다르면 스펙에 따른 특정 액션을 취한 뒤 상태를 업데이트하는 조정 과정을 거칩니다.
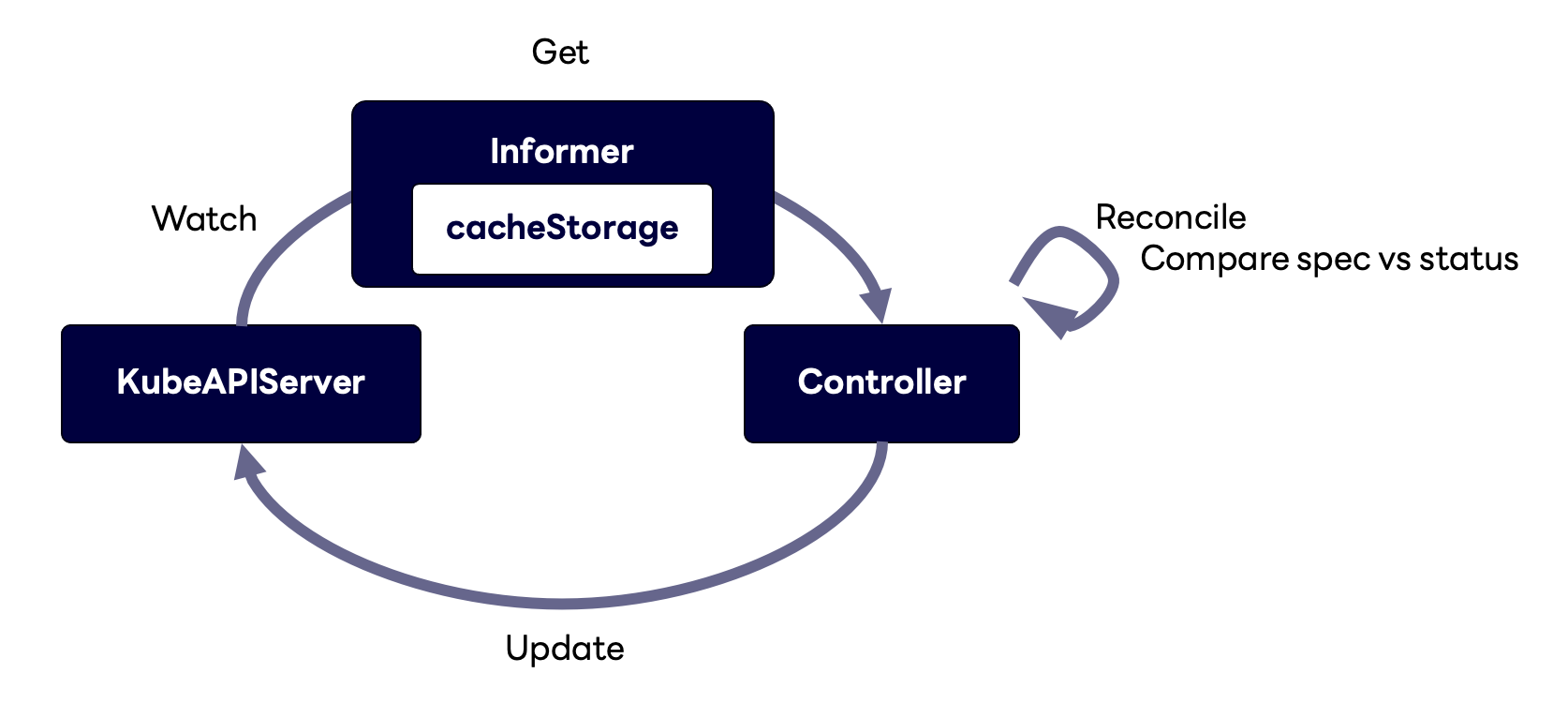
 그런데 이때 컨트롤러는 API 서버의 부하를 줄이고 속도를 높이기 위해 오브젝트를 바로 가져오는 것이 아니라 Informer라는 구조체를 이용해서 가져옵니다. Informer에는 캐시 스토리지가 있는데요. 'Watch'를 통해 API 서버에서 오브젝트를 가져와서 캐시에 저장하는 것이죠. 여기서 'Watch'란 객체의 변경 사항을 실시간으로 모니터링하는 기능을 의미합니다. 이 기능을 사용하면 클러스터 내의 리소스(파드, 서비스, 디플로이먼트 등)의 생성, 수정, 삭제 이벤트를 실시간으로 감지할 수 있습니다. 오브젝트가 변경될 때 이벤트를 받아서 오브젝트를 가져오는
그런데 이때 컨트롤러는 API 서버의 부하를 줄이고 속도를 높이기 위해 오브젝트를 바로 가져오는 것이 아니라 Informer라는 구조체를 이용해서 가져옵니다. Informer에는 캐시 스토리지가 있는데요. 'Watch'를 통해 API 서버에서 오브젝트를 가져와서 캐시에 저장하는 것이죠. 여기서 'Watch'란 객체의 변경 사항을 실시간으로 모니터링하는 기능을 의미합니다. 이 기능을 사용하면 클러스터 내의 리소스(파드, 서비스, 디플로이먼트 등)의 생성, 수정, 삭제 이벤트를 실시간으로 감지할 수 있습니다. 오브젝트가 변경될 때 이벤트를 받아서 오브젝트를 가져오는 kubectl –w의 Watch와 동일한 기능입니다.
 컨트롤러 조금 더 깊이 살펴보기
컨트롤러 조금 더 깊이 살펴보기
컨트롤러의 작동 방식을 조금 더 깊이 살펴보겠습니다.
etcd와 쿠버네티스 API 서버 사이 살펴보기
쿠버네티스는 키-값 구조인 etcd를 사용하고 etcd는 Watcher 인터페이스를 구현해 놓았기 때문에 API 서버에서는 Watcher 클라이언트를 통해 etcd 내부 오브젝트의 변화를 확인할 수 있습니다. 즉, 변화가 있을 때마다 Watch를 통해 이벤트를 전달받습니다.
 전달받은 이벤트는 내부에서 아래와 같이 타입과 오브젝트만 있는 이벤트 구조체로 변환됩니다. 타입에는 세 가지(
전달받은 이벤트는 내부에서 아래와 같이 타입과 오브젝트만 있는 이벤트 구조체로 변환됩니다. 타입에는 세 가지(create, delete, update)가 들어갈 수 있습니다.

쿠버네티스 API 서버와 Informer 사이 살펴보기
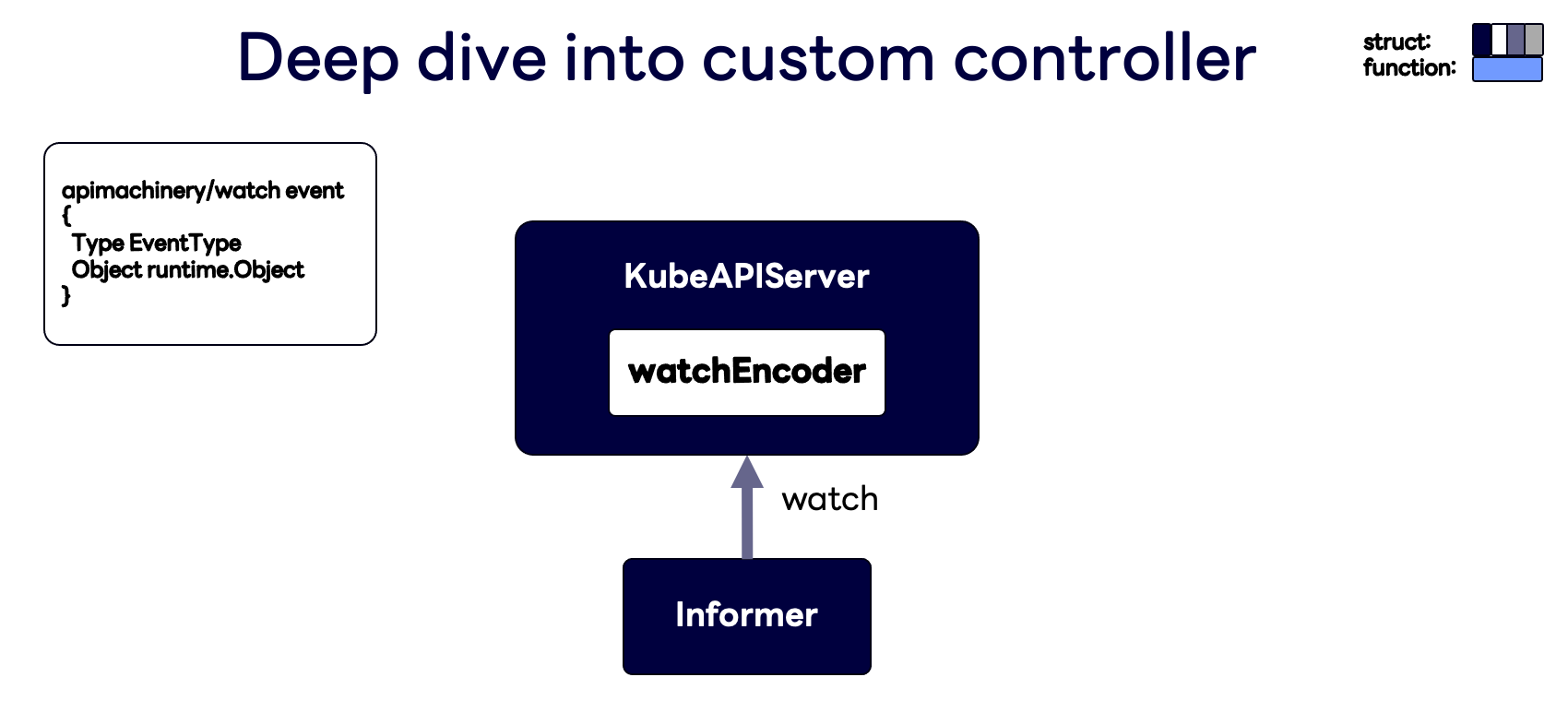
이제 이 API 서버를 사용하는 Informer를 살펴볼 차례입니다. 앞서 말씀드렸던 것처럼 Informer에는 캐시 스토리지가 있으며, 오브젝트가 변경될 때마다 캐시를 업데이트하고, 이 Informer를 갖고 있는 컨트롤러들에게 이벤트 구조체를 전달합니다. 아래 그림과 같이 Informer는 이 이벤트 구조체를 전달하기 위해 쿠버네티스 API 서버를 Watch하고, 쿠버네티스 API 서버는 watchEncoder 구조체를 이용해 이벤트 구조체를 전달합니다.
Informer 내부 살펴보기
조금 더 정확히 말씀드리면, Informer 안의 Reflector라는 컴포넌트에서 streamWatcher라는 구조체를 통해서 전달받은 이벤트 구조체를 DeltaFIFO 큐에 넣습니다. DeltaFIFO 큐는 아래 그림과 같이 큐 하나만 있는 게 아니라 맵과 큐로 구성돼 있는데요. 맵에는 전달받은 이벤트 구조체를 Delta 구조체로 변경해 키-값 중 값으로 넣고, 이��때 키(ID)는 오브젝트의 namespacedName으로 만들고, 만약 이 키가 큐에 없다면 큐에도 집어넣습니다.

이제 아래 그림과 함께 DeltaFIFO 큐에 들어간 ID가 어떻게 활용되는지 살펴보겠습니다.
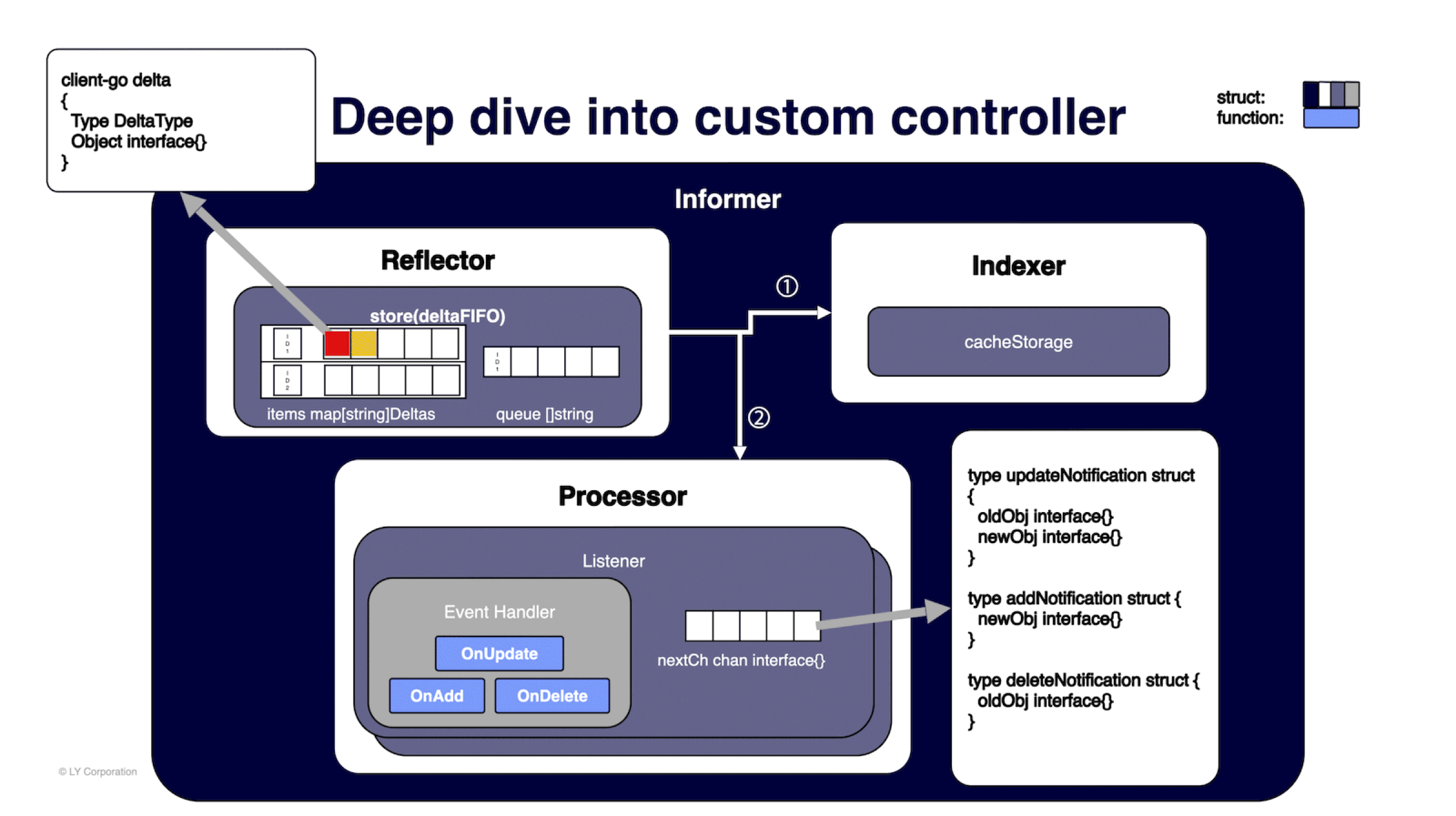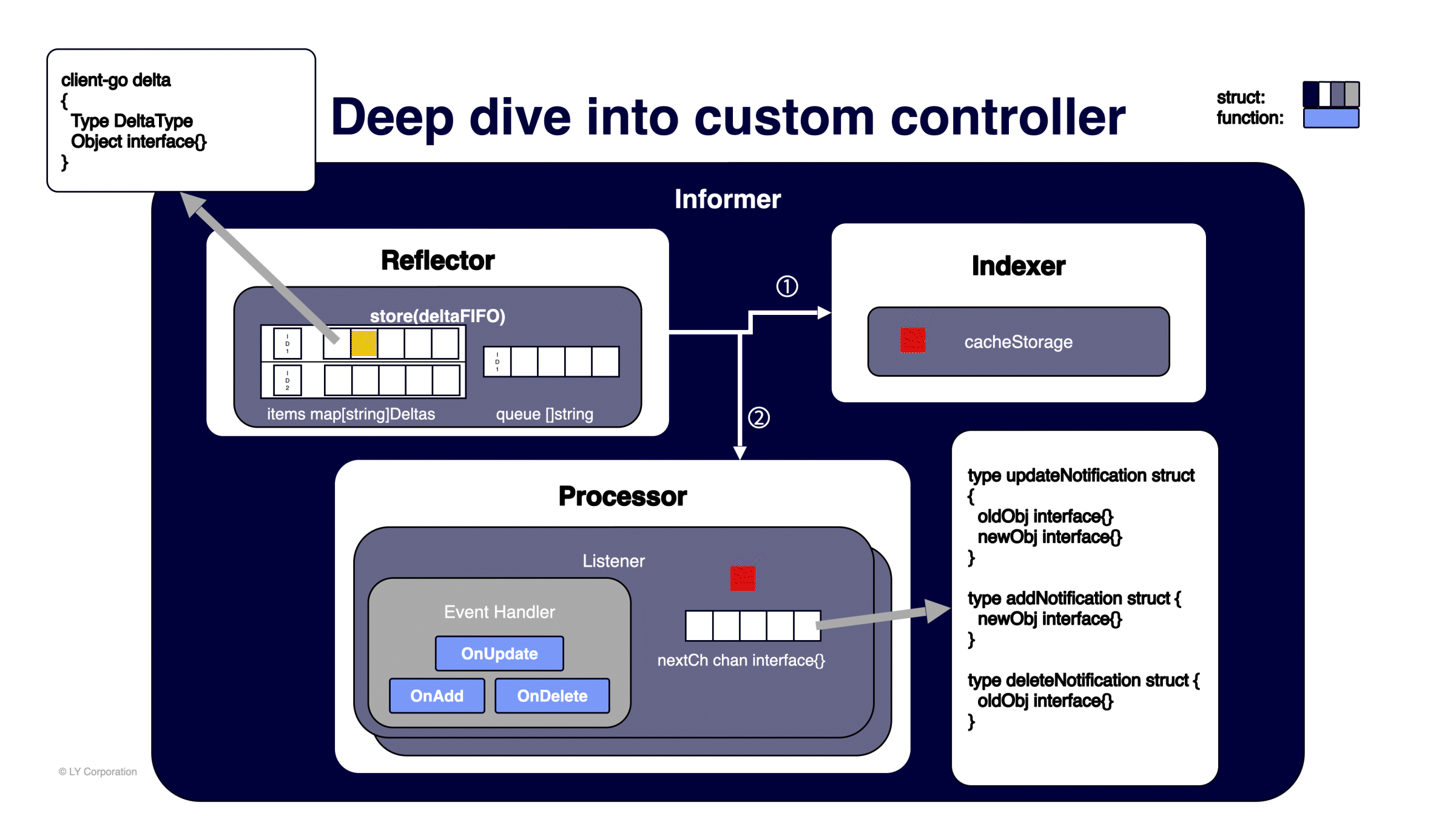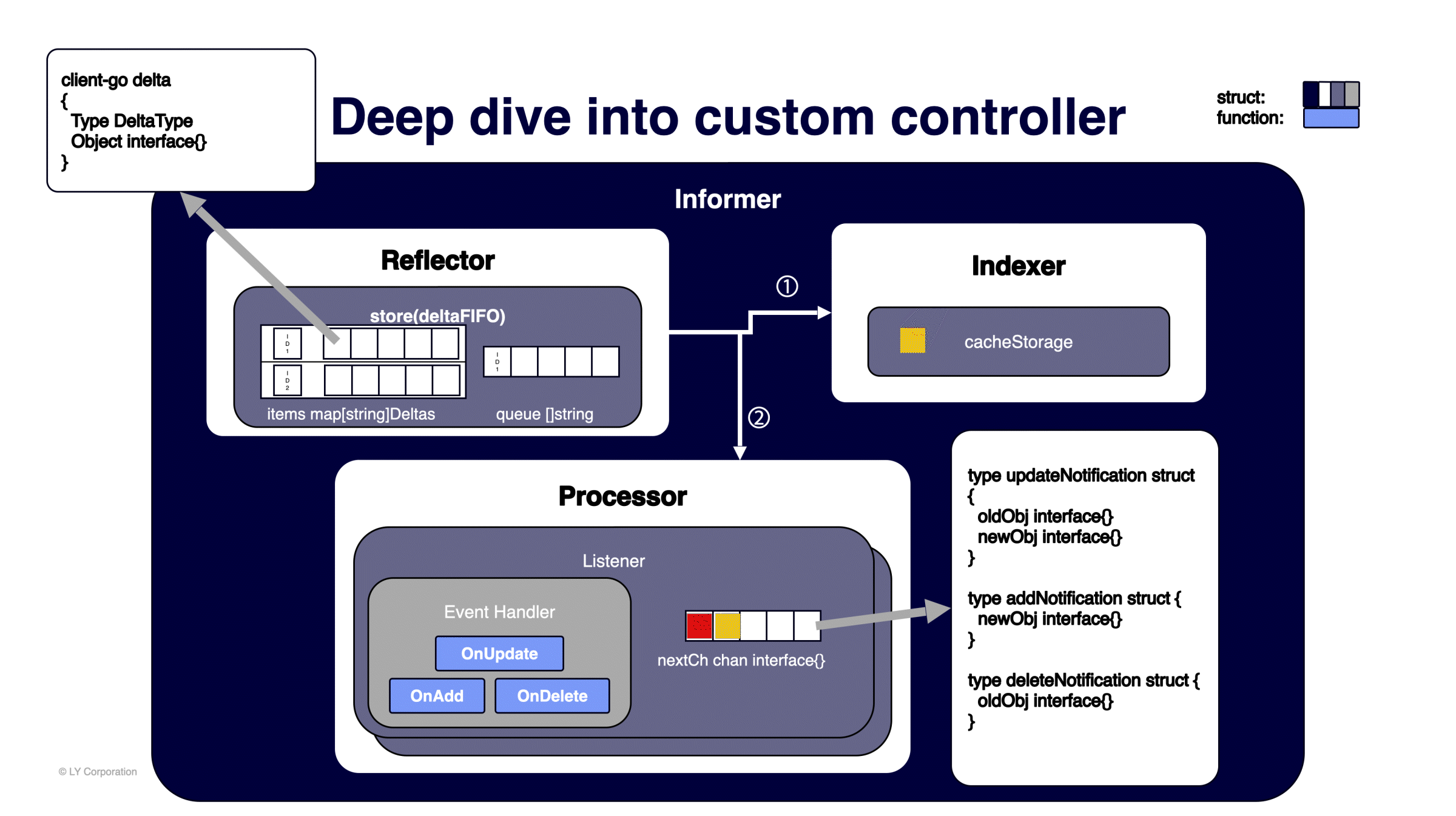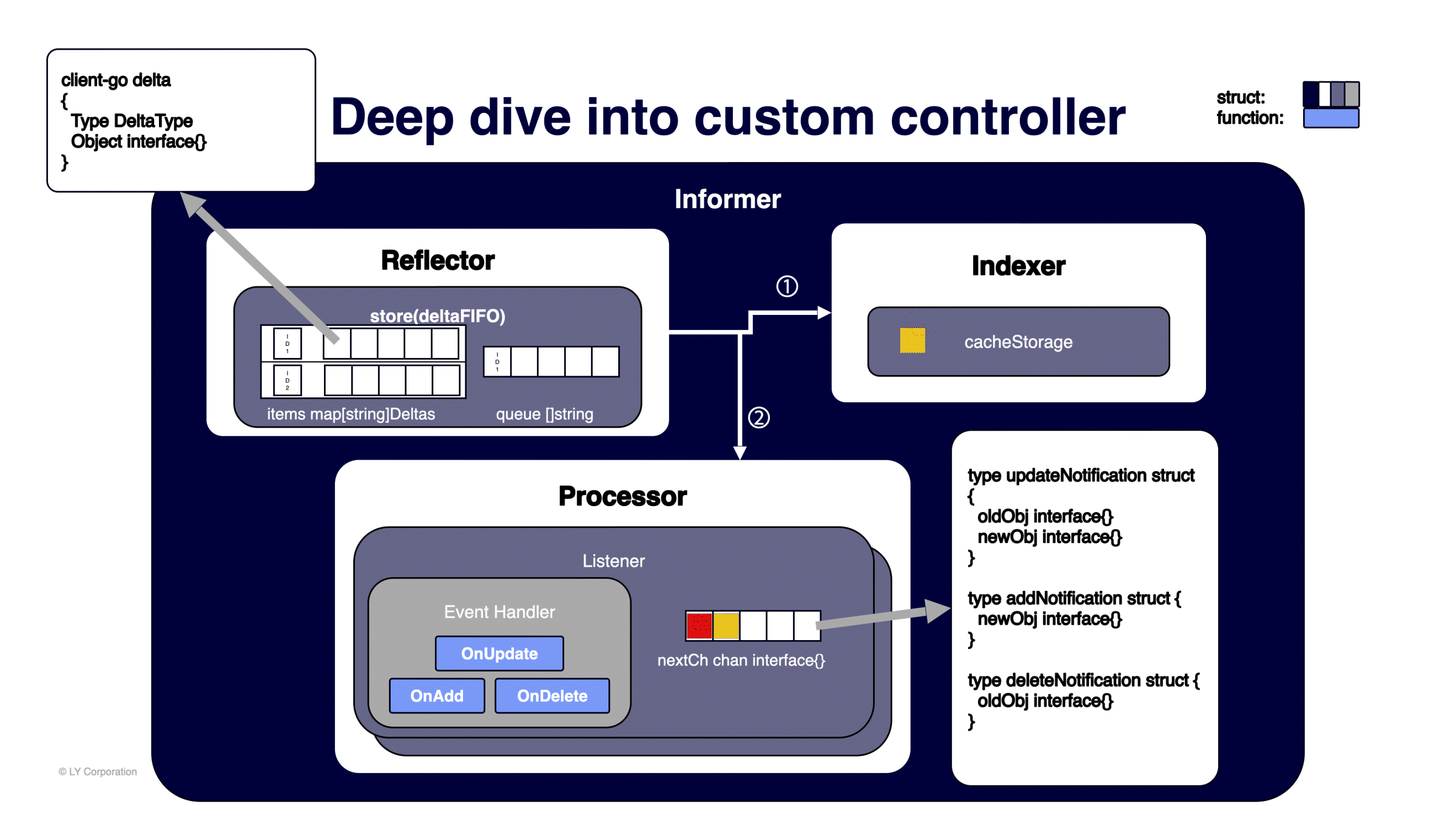
ID가 큐에 푸시되면 기다리고 있던 goroutine에서 ID를 하나씩 팝(pop)해서 각 ID에 해당하는 Delta 값으로 다음 작업을 진행합니다.
- 캐시 스토리지를 업데이트할 수 있는 Indexer로 오브젝트를 전달합니다. 캐시 스토리지는
namespacedName을 키로, 오브젝트를 값으로 하는 스레드-세이프(thread-safe) 맵으로 구성돼 있습니다. - 변경된 오브젝트를 처리할 수 있는 핸들러가 있는 Processor로 전달합니다.
- 맵의 같은 ID에 저장돼 있는 다른 Delta 값을 모두 처리할 때까지 반복합니다.
변경된 오브젝트가 Processor로 전달되면 리스너를 통해 각 타입(updateNotification / addNotification / deleteNotification)에 따라 이벤트 핸들러의 OnUpdate / OnAdd / OnDelete를 호출합니다. 정리하자면, Watch를 통해 가져온 이벤트 구조체는 Reflector가 캐시 스토리지에 업데이트하고 이벤트 핸들러로 전달합니다.
이벤트 핸들러의 OnAdd, OnUpdate, OnDelete는 아래 그림과 같이 모두 같은 작업을 ��합니다. 바로 WorkQueue라는 큐에 푸시하는 것인데요. 이때 큐에는 셋 중 무엇이든 상관없이 모두 NamespacedName만을 갖고 있는 구조체가 들어가며, 이렇게 들어간 구조체는 WorkQueue를 가져오는 goroutine을 통해 Reconcile 함수의 파라미터로 넘어가면서 실행됩니다.
 Reconcile 함수는 일반적으로 캐시 스토리지를 통해 오브젝트를 가져와서 특정 작업을 진행한 뒤 API 서버에 업데이트합니다.
Reconcile 함수는 일반적으로 캐시 스토리지를 통해 오브젝트를 가져와서 특정 작업을 진행한 뒤 API 서버에 업데이트합니다.

Reconcile 함수와 관련해 유명한 예제로 Memcached-operator가 있습니다. 코드의 48번째 줄(func (r *MemcachedReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error)을 살펴보면,req가 들어오고req.NamespacedName을 통해 오브젝트를 가져와서 일련의 작업을 진행한 후 상태를 업데이트하는 과정을 볼 수 있습니다.
컨트롤러 작동 방식 종합
아래 그림은 앞서 살펴본 것을 종합한 그림입니다.
 컨트롤러 작동 순서는 다음과 같습니다.
컨트롤러 작동 순서는 다음과 같습니다.
- API 서버는 etcd Watcher를 통해서 이벤트 구조체를 전달합니다.
- Reflector는 먼저 그 이벤트 구조체를 DeltaFIFO 큐에 넣어서 캐시 스토리지를 업데이트합니다.
- Reflector는 다음으로 이벤트 핸들러에게 알립니다(
notify). - 이벤트 핸들러는 전달받은 이벤트의
Name과Namespace를 유형과 상관 없이 모두 WorkQueue에 넣습니다. - Reconcile 함수가 WorkQueue에서
Name과Namespace를 가져와 이를 키로 사용해서 캐시 스토리지에서 오브젝트를 가져옵니다. - Reconcile 함수에서 일련의 작업을 진행한 뒤 상태를 업데이트하기 위해 API 서버를 호출(
POST/PUT)합니다.
컨트롤러의 작동을 Redis에서 replicas를 2에서 3으로 변경하는 작업을 예시로 살펴보면 다음과 같습니다.
- API 서버는
replicas가 2에서 3으로 변경됐다는 이벤트를 Watch를 통해 전달합니다. - DeltaFIFO 큐로 들어가서 캐시에 있는 Redis Service 커스텀 리소스의
replicas를 3으로 업데이트합니다. Notify를 통한onUpdate가 호출됩니다.- 이벤트 핸들러는 Redis Service의
namespacedName를 WorkQueue에 넣습니다. - Reconcile 함수에서
namespacedName을 기준으로 캐시 스토리지에서 오브젝트를 가져옵니다. - 노드 개수를 확인하고 노드를 하나 더 생성(
POST)하는 작업을 진행합니다.
마치며
컨트롤러 작성해서 리소스를 선언적으로 관리하는 것을 오퍼레이터 패턴이라고 하는데요. 오퍼레이터 패턴을 작성할 때 이런 것들을 처음부터 모두 파악하고 들어가기는 너무 어렵습니다. 여기서 팁을 드리자면, OPERATOR SDK라는 툴을 활용해 보면 좋습니다. 이 툴은 Reconcile의 내용만 구현할 수 있도록 스캐폴딩을 제공하거나 Go 코드만으로 커스텀리소스데피니션을 생성할 수 있게 해주는 등 다양한 기능을 제공하는데요. 이를 활용하면 선언적 프로그래밍인 오퍼레이터 패턴을 만드는 데 도움을 받을 수 있습니다.
이번 글에서는 쿠버네티스 컨트롤러를 활용해 커스텀 리소스를 활용한 방법과 사례를 공유드렸습니다. 캐시 스토리지 때문에 어려움을 겪은 경험을 떠올리며 컨트롤러 내부 구조까지 함께 살펴봤는데요. 쿠버네티스 코드와 같이 보시면 보다 쉽고 빠르게 이해하실 수 있을 것이라고 생각합니다. 이 글이 많은 분께 도움되기를 바라며 이만 마치겠습니다.


