들어가며
안녕하세요. LINE+ Contents Service Engineering 조직에서 백엔드 개발 및 프런트엔드 개발을 담당하고 있는 문범우, 안현모�입니다.
저희 조직에서는 그룹 구성원의 기술 성장을 돕고 향상된 능력을 적재적소에 활용할 수 있도록 'Tech Group'이라는 조직 내 스터디 그룹을 운영하고 있습니다. Tech Group에서는 여러 주제를 선정해 주제별로 소그룹을 나눠 함께 딥 다이브하는 시간을 보내는데요. 저희 그룹은 쿠버네티스(Kubernetes)를 주제로 다양한 내용을 함께 공부하고 토론하며, 필요한 사례를 연구하고 테스트한 뒤 프로젝트에 적용하고 있습니다.
이 글에서는 저희가 다뤘던 다양한 주제 중 '쿠버네티스의 CPU 리소스'를 주제로 논의했던 내용을 공유드리려고 합니다. 먼저 쿠버네티스에서 CPU 리소스를 관리하는 방법을 소개하고, 더 나아가 애플리케이션의 성능을 개선하기 위해 CPU 상한(cpu.limits) 설정을 이용해 CPU 리소스를 더욱 효율적으로 사용하기 위한 방법을 고민하고 테스트해 본 내용을 공유하겠습니다.
미리보는 결론
이 주제와 관련해서 특히 재미난 점은 CPU 상한 설정을 유지 혹은 제거하는 것에 대해 각 프로젝트에서 서로 다른 결정을 내렸다는 점입니다. 미리 결론을 말씀드리자면, 벡엔드 서버 팀에서는 제거하는 것으로, 프런트엔드 서버 팀에서는 제거하지 않는 것으로 결정했습니다. 저희가 함께 테스트하고 토론했음에도 왜 이렇게 다른 결정을 내리게 됐는지 글을 읽으면서 함께 고민해 보신다면 여러분의 프로젝트를 개선하기 위한 좋은 아이디어를 얻으실 수 있을 것이라고 생각합니다.
그럼 본격적으로 함께 살펴보겠습니다.
쿠버네티스의 CPU 리소스 관리 방법 파헤치기
먼저 쿠버네티스에서 CPU 리소스를 관리하�는 방법을 살펴보면서 저희가 왜 CPU 상한 설정 제거를 고려하게 됐는지 말씀드리겠습니다.
CPU 요청량과 CPU 상한 설정 소개
가장 먼저 살펴볼 내용은 쿠버네티스의 CPU 요청량(cpu.requests)과 CPU 상한(cpu.limits) 설정입니다. 설명하기 위해 간단한 파드 매니페스트(pod manifest)를 가져왔습니다.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m" # Can we remove this cpu limits field?위 내용 중 저희가 살펴볼 사항은 12번째 줄에 설정된 cpu.requests 값과 15번째 줄에 설정된 cpu.limits 값입니다.
CPU 요청량
먼저 CPU 요청량(cpu.requests) 설정을 살펴보겠습니다. CPU 요청량은 파드가 사용을 '보장받는' 최소 CPU 리소스의 값입니다. 이렇게만 생각하면 간단해 보일 수 있지만 간혹 '보장받는'이라는 개념을 '예약'과 혼동하시는 경우가 있습니다.
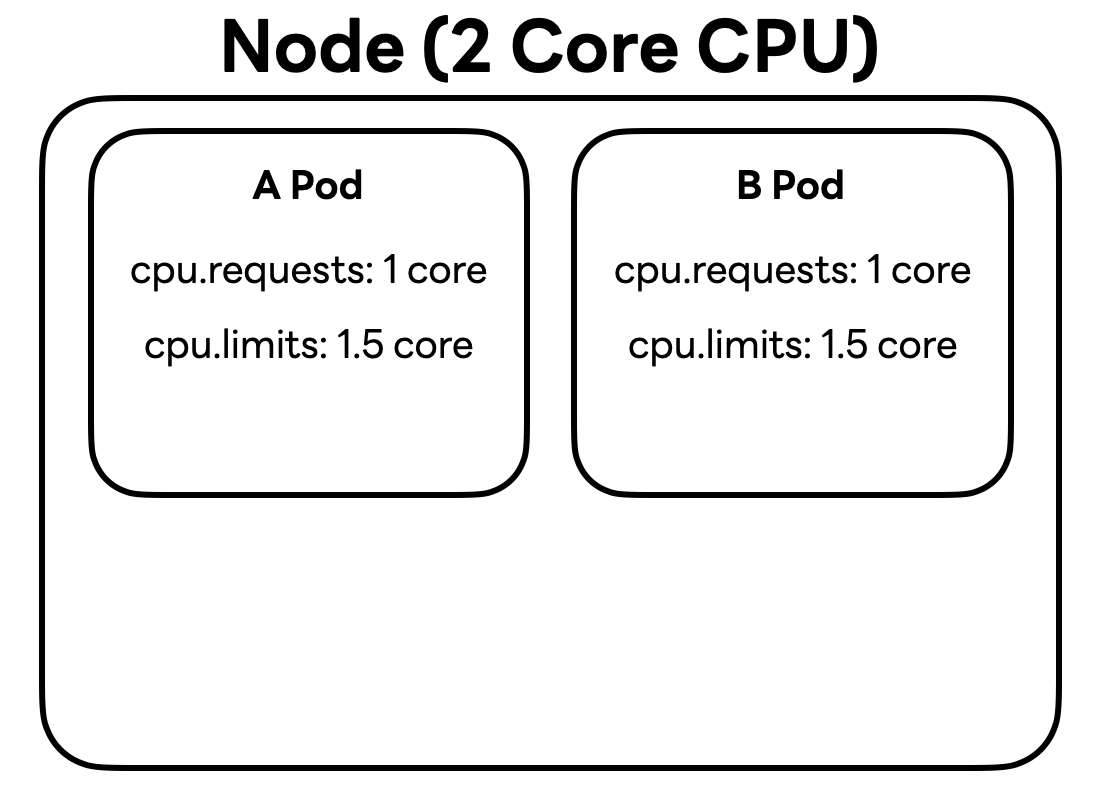
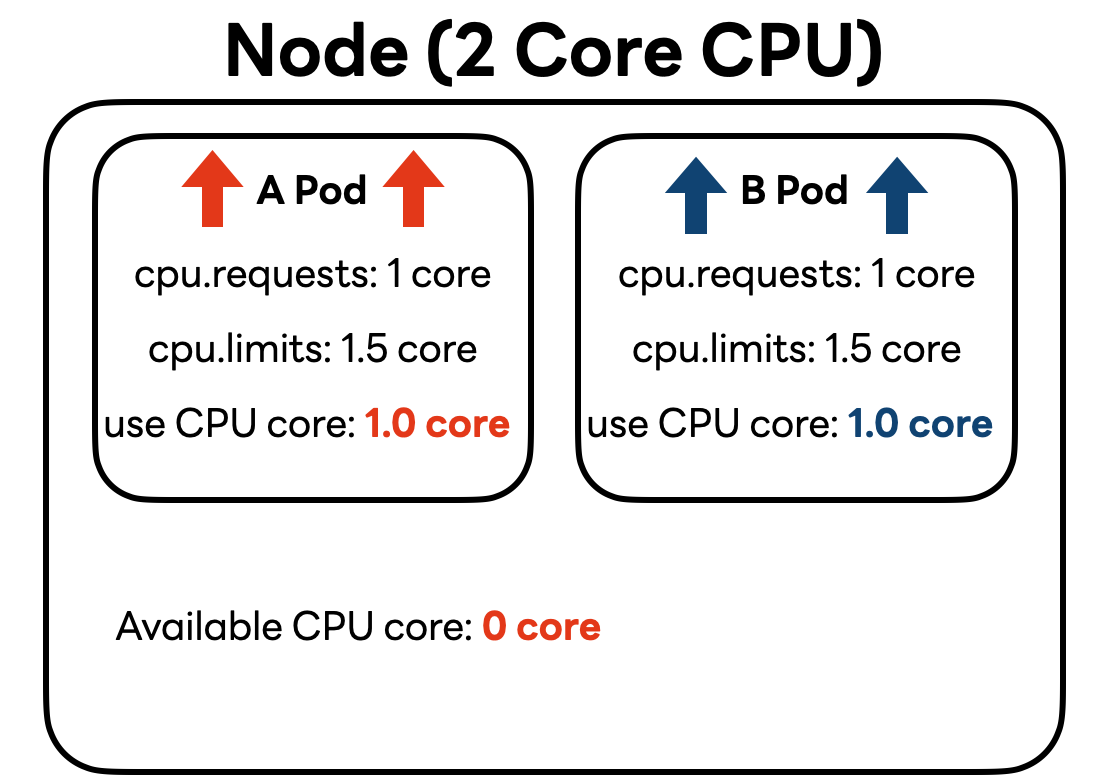
예시를 들어볼까요? 아래와 같이 2 코어 CPU를 가진 노드에 cpu.requests를 1 코어로, cpu.limits는 1.5 코어로 설정한 파드 두 개가 있다고 가정해 보겠습니다(편의를 위해 메모리 리소스 설정은 생략했습니다).
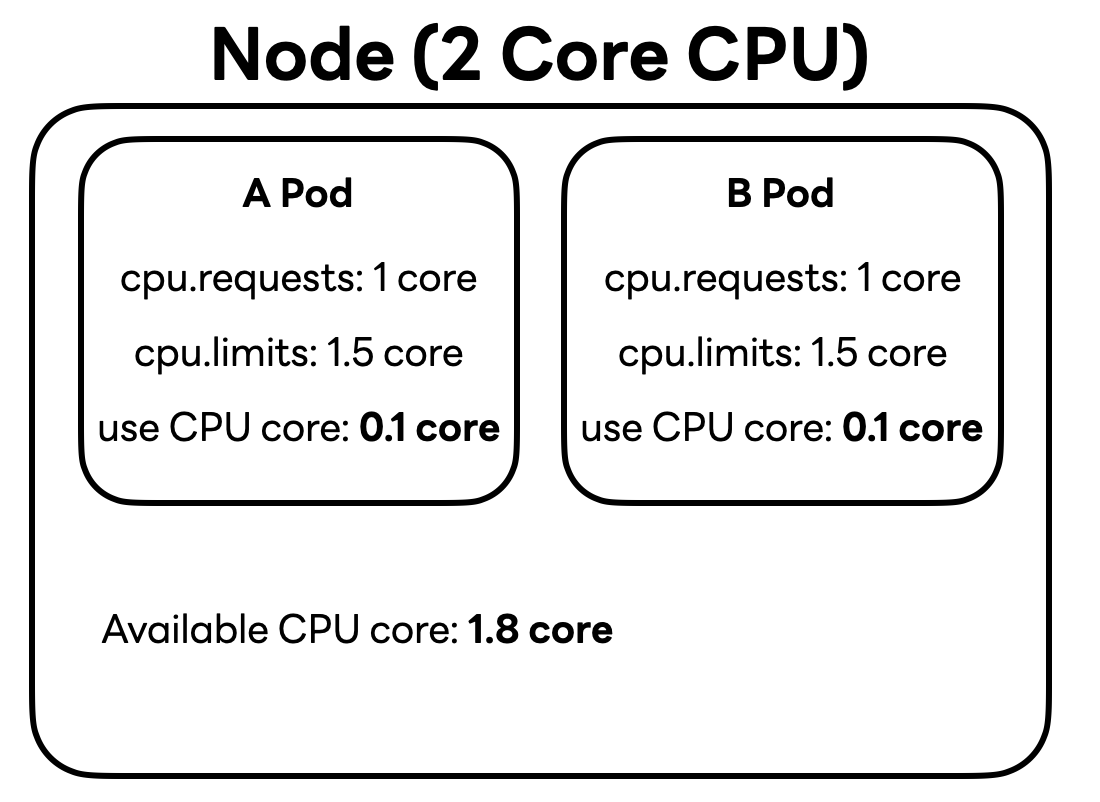
위와 같은 상황에서 다음과 같이 부하가 많이 발생하지 않는 평소에는 각 파드가 모두 0.1 ��코어씩만 사용한다고 가정해 보겠습니다. 그렇다면 현재 노드에서 사용 가능한 여유 코어는 총 1.8 코어가 됩니다.
이때 A 파드의 트래픽이 증가해 CPU 사용량이 많아지면 어떻게 될까요?
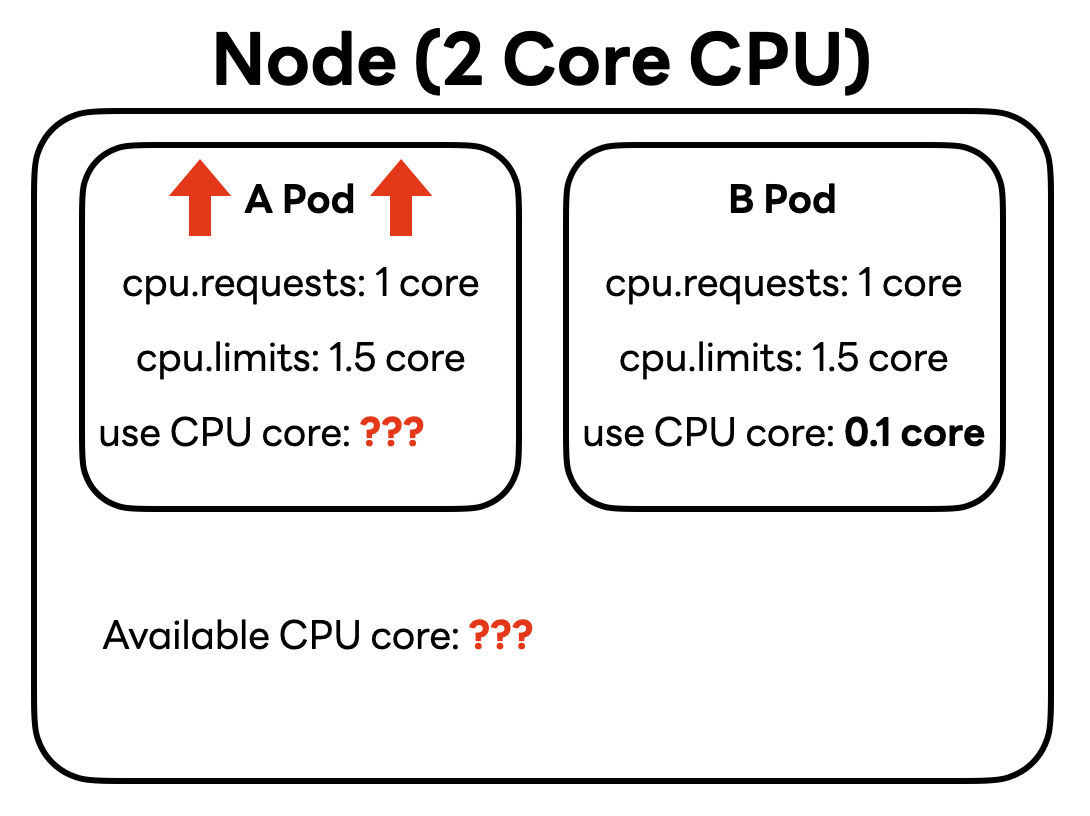
바로 이런 상황에서 cpu.requests 설정값이 '보장'의 개념인지 '예약'의 개념인지에 따라 다르게 작동할 수 있습니다.
만약 '예약'의 개념이라면, A 파드의 트래픽이 증가하더라도 B 파드의 cpu.requests가 1 코어로 '예약'돼 있기 때문에 A 파드는 노드의 여유분 1.8 코어 중 0.9 코어만 사용할 수 있을 것입니다. 하지만 앞서 말씀드린 것과 같이 cpu.requests는 '예약' 개념이 아니라 '보장' 개념이기 때문에 A 파드의 트래픽이 증가하면 A 파드는 설정해 놓은 cpu.limits값인 1.5 코어까지 사용할 수 있습니다.
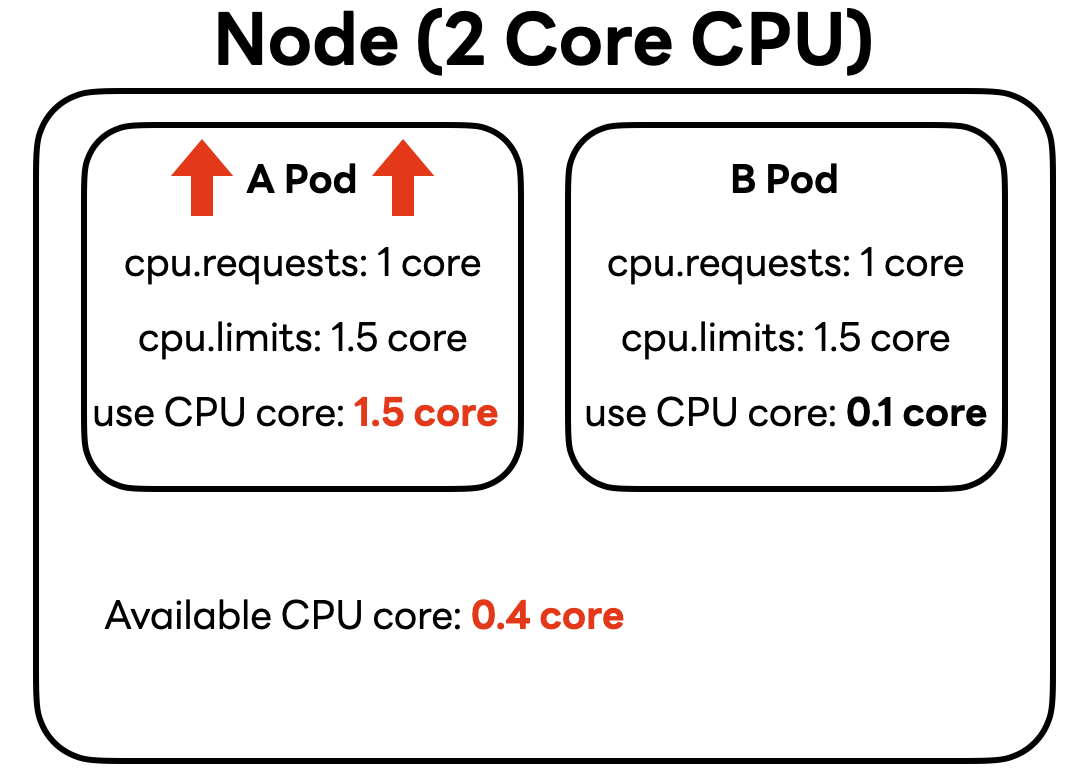
그렇다면 여기서 만약 B 파드의 트래픽도 증가한다면 CPU 리소스는 어떻게 배분될까요? cpu.requests는 해당 설정값만큼 CPU 리소스를 사용할 수 있도록 보장하는 것이기 때문에 B 파드는 최소 1.0 코어를 사용할 수 있어야 합니다. 따라서 이전 상황에서 A 파드가 CPU 상한값에 맞춰 사용하던 CPU 리소스 중 0.5 코어를 반납해 B 파드가 ��사용할 수 있도록 합니다.
이러한 CPU 리소스 분배 과정은 쿠버네티스 내부에서 진행되며, 이때 리소스 할당은 CFS(Completely Fair Scheduler) 알고리즘 기반으로 작동합니다. CFS에 대해서는 아래에서 다시 자세하게 살펴보겠습니다.
CPU 상한
CPU 상한(cpu.limits) 설정값은 말 그대로 파드가 사용할 수 있는 최대 CPU 리소스 값을 의미합니다. 쿠버네티스에서 CPU 상한을 설정하면, 파드가 배치돼 있는 노드의 CPU 리소스가 여유롭다고 해도 설정된 CPU 상한값을 초과해서 자원을 사용할 수는 없습니다.
쿠버네티스의 CPU 리소스 스케줄링 알고리즘(CFS) 작동 방식
이제 앞서 살펴본 CPU 요청량과 CPU 상한 개념을 기반으로 쿠버네티스가 어떻게 CPU 리소스를 할당하고 사용하는지 알아보겠습니다.
쿠버네티스에서는 Linux에서 사용하는 CPU 리소스 스케줄링 알고리즘인 CFS(Completely Fair Scheduler)를 기반으로 CPU 리소스를 관리합니다. CFS는 간단히 말해 CPU 리소스를 '기준 시간' 동안 '얼마만큼' 이용할 것인지에 대한 계획을 수립 및 조정하는 스케줄러라고 생각하시면 됩니다.
쿠버네티스의 CFS는 크게 아래 두 가지 파라미터를 기반으로 CPU 리소스를 사용하도록 설정합니다.
cfs_period_us: CPU 리소스를 할당하는 '기준 시간'입니다. 기본값은 100ms이며, 일반적으로 이 값을 조정하는 경우는 흔치 않습니다. 기본값으로 설정돼 있다고 가정할 때 쿠버네티스는 CPU 리소스를 어떻게 사용할 것인지를 100ms마다 새로 스케줄링합니다. 즉 100ms마다 CPU 사용 계획이 리셋된다고 생각할 수 있습니다.cfs_quota_us: 기준 시간 동안 CPU를 사용할 수 있는 최대 시간을 의미합니다. CFS가 '기준 시간(cfs_period_us) 동안 CPU를 얼마만큼 사용할 것인지를 스케줄링하는 스케줄러'라고 말씀드렸는데요. 이때 기준 시간 동안 스케줄링되는 최댓값이cfs_quota_us로 제한되는 것이라고 생각하시면 됩니다. 결국 앞서 살펴봤던 CPU 상한이 일련의 과정을 통해cfs_quota_us값으로 변환돼 적용되는 것이라고 볼 수 있습니다(참고로cfs_quota_us설정 파일에 직접 접근해 수정하는 것도 가능하나 보안 및 작동 메커니즘 관점에서 직접 수정하는 것은 권장되지 않습니다).
사례와 함께 살펴보는 CFS 작동 방식: '1 코어를 사용한다'
앞서 살펴본 CFS의 파라미터 개념을 기반으로 CFS 작동 방식을 예시와 함께 알아보겠습니다.
일반적으로 '1 코어를 사용한다'는 말을 자주 사용하는데요. 이 문장의 정확한 의미는 무엇일까요? 이 문장을 CFS 알고리즘을 기반으로 한 번 해석해 보겠습니다(예시에서 cfs_period는 기본값(100ms)으로 설정돼 있다고 가정합니다).
아래와 같이 4 코어가 할당된 노드에서 '1 코어를 사용한다'를 나타내면 어떻게 될까요?
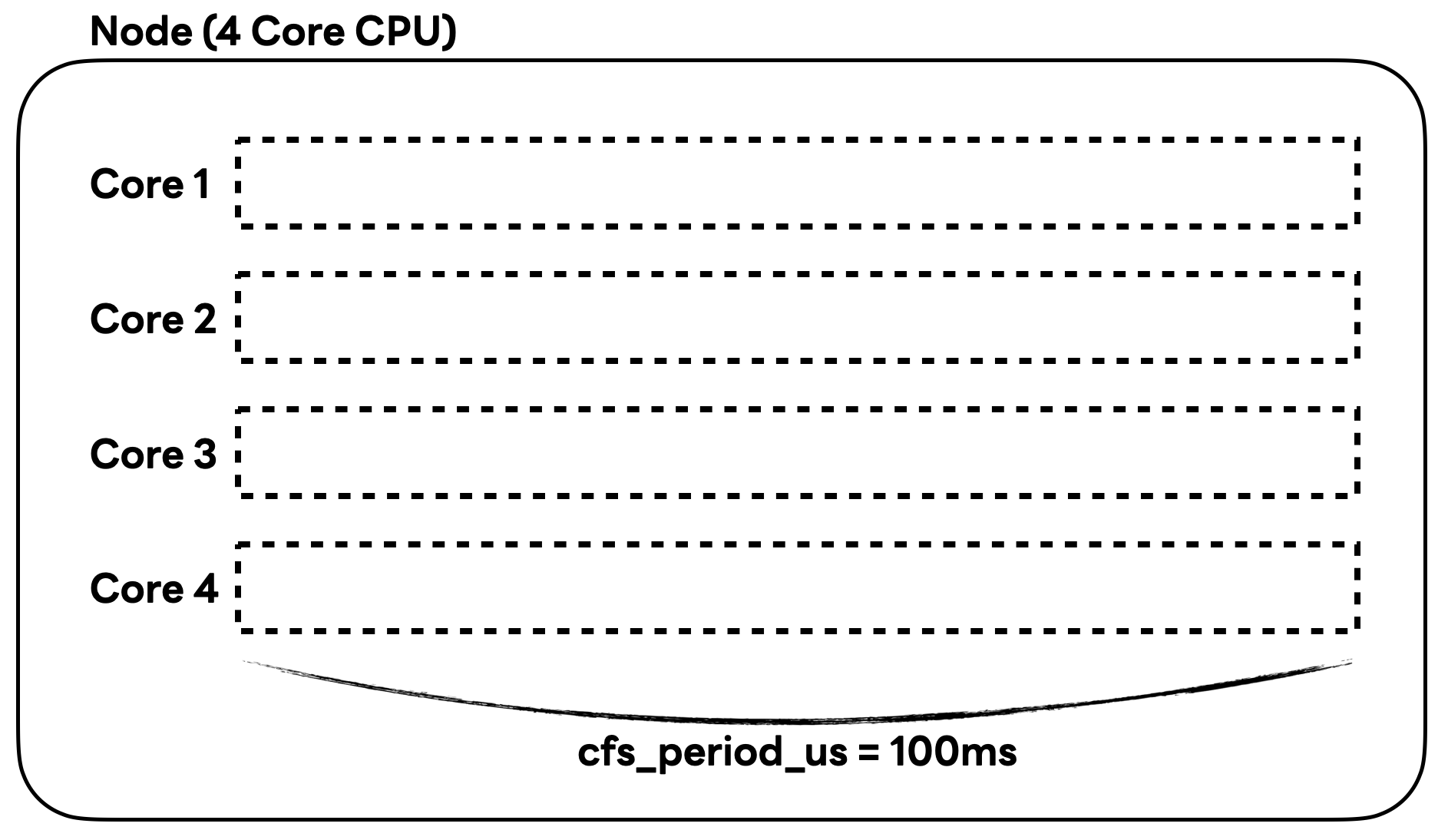
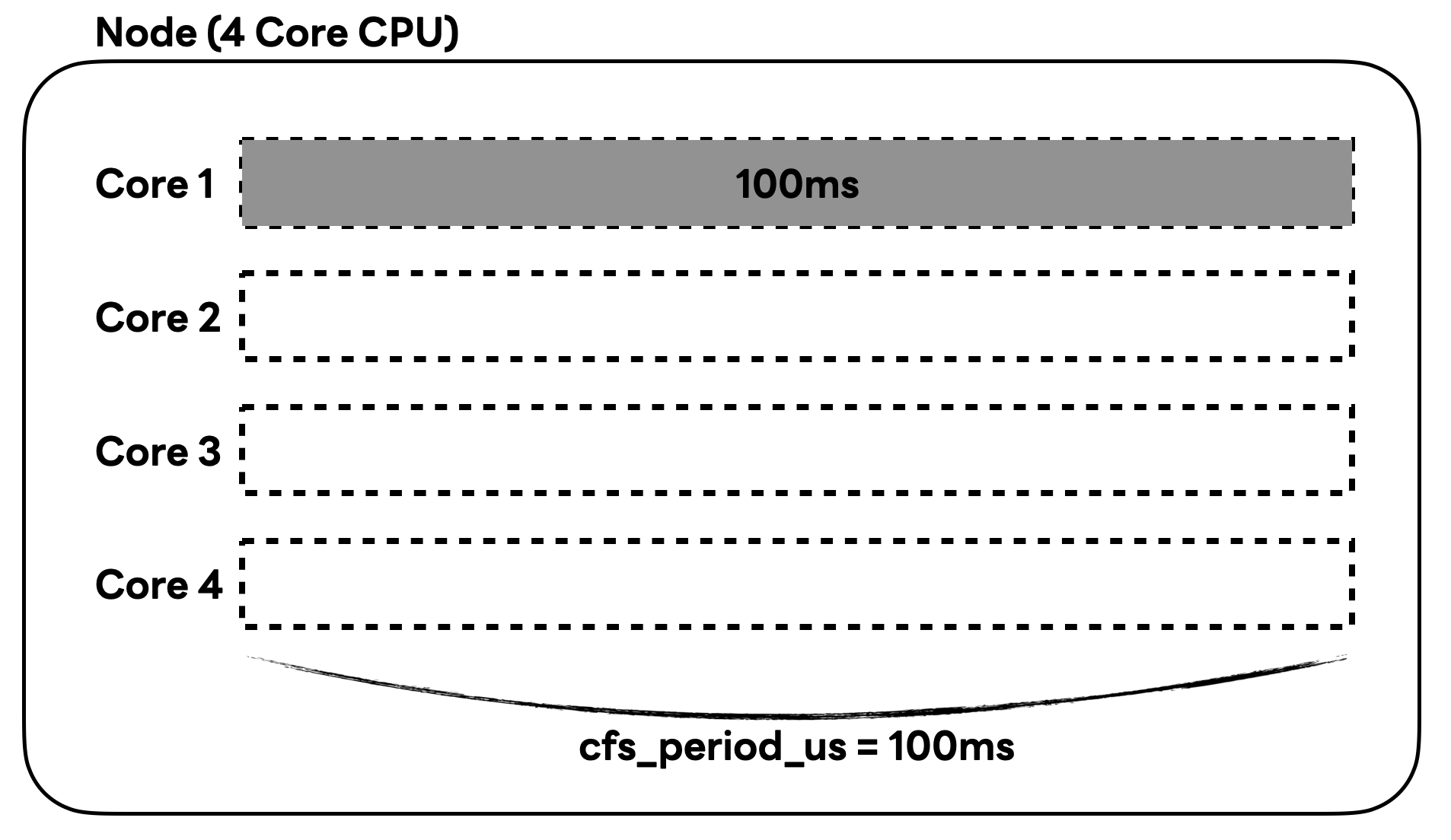
CFS 알고리즘에서 '1 코어를 사용한다'는 것은 cfs_period_us 시간, 즉 100ms 동안 CPU 코어를 100ms만큼 사용하는 것입니다. 이는 아래 그림과 같이 나타낼 수 있습니다.
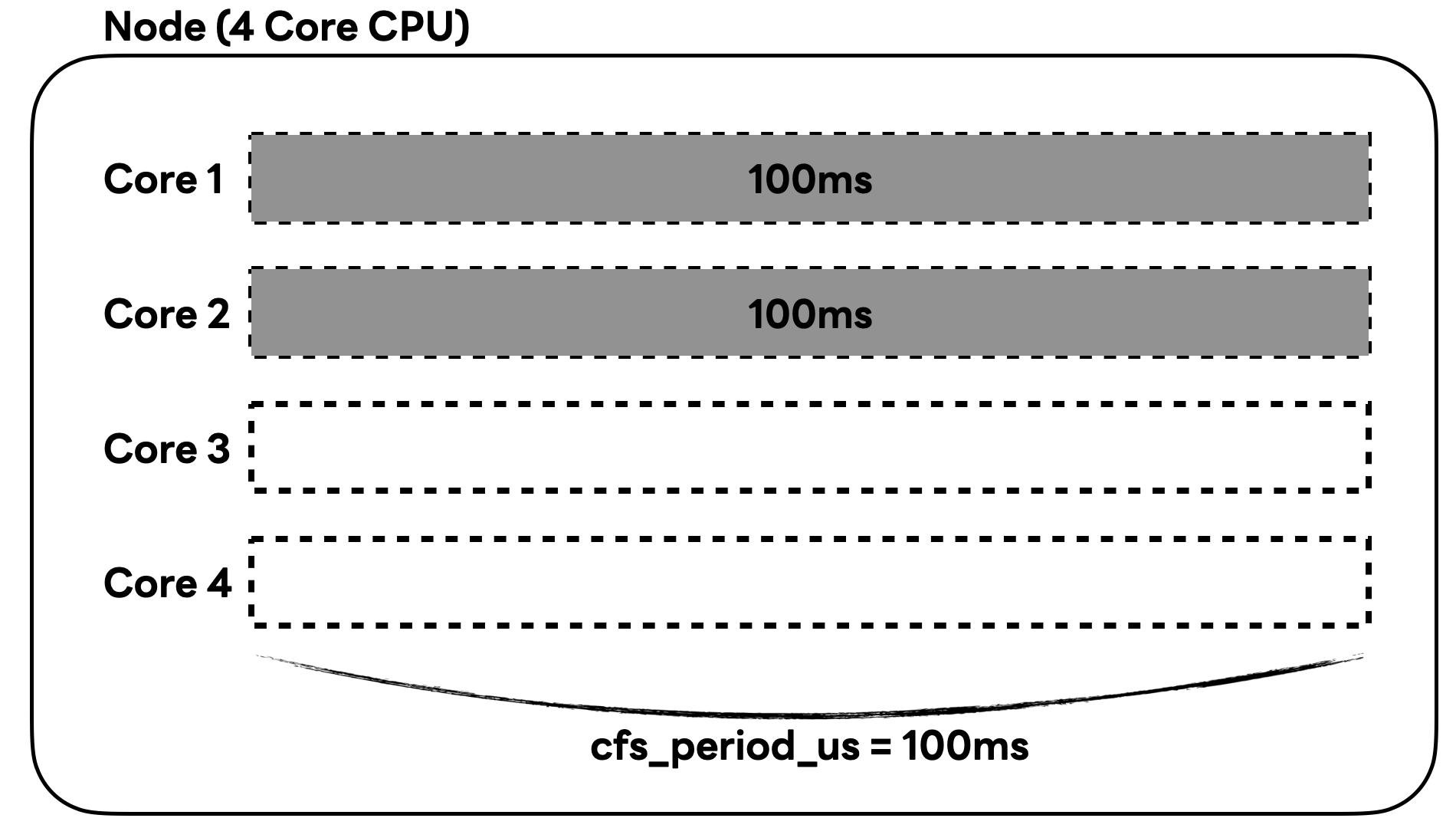
같은 방식으로 '2 코어를 사용한다'는 것은 100ms 동안 총 200ms만큼의 CPU 코어를 사용하는 것으로 아래 그림과 같이 나타낼 수 있습니다.
CFS 스로틀링의 개념과 발생 이유
앞서 살펴본 것처럼 쿠버네티스에서는 CFS 알고리즘을 기반으로 CPU를 사용하는데요. 만약 남아 있는 CPU 리소스가 부족할 때는 어떻게 될까요? 이런 경우 CPU를 사용하지 못하고 cfs_period_us 시간까지 대기합니다. cfs_period_us 시간 이후에는 다시 CFS 알고리즘에 따라 CPU 사용 계획이 리셋될 테니까요.
여기서 cfs_period_us 시간까지 대기하는 상황, 즉 CPU를 사용하지 못하는 상황을 'CFS 스로틀링(throttling)'이라고 합니다(CPU 스로틀링과 매우 유사한 개념이지만 CPU 스로틀링의 의미가 더 넓기 때문에 이 글에서는 CFS 스로틀링이라고 지칭하겠습니다).
그럼 앞서 살펴봤던 1 코어 또는 2 코어 사용 환경에서도 CFS 스로틀링이 발생할까요? CFS 스로틀링은 CPU 리소스가 부족할 때 발생하는 상황이기에 '4 코어 노드에서 4 코어 이상을 사용할 때에만 발생할 것이다'라고 생각�하기 쉬운데요. 실상은 그렇지 않습니다.
CFS 알고리즘에서 CPU 사용의 총합은 시간으로 나타냅니다. 따라서 아래 그림과 같이 4개의 코어를 각각 25ms씩 이용하면 총 CPU 사용 시간은 100ms가 됩니다.
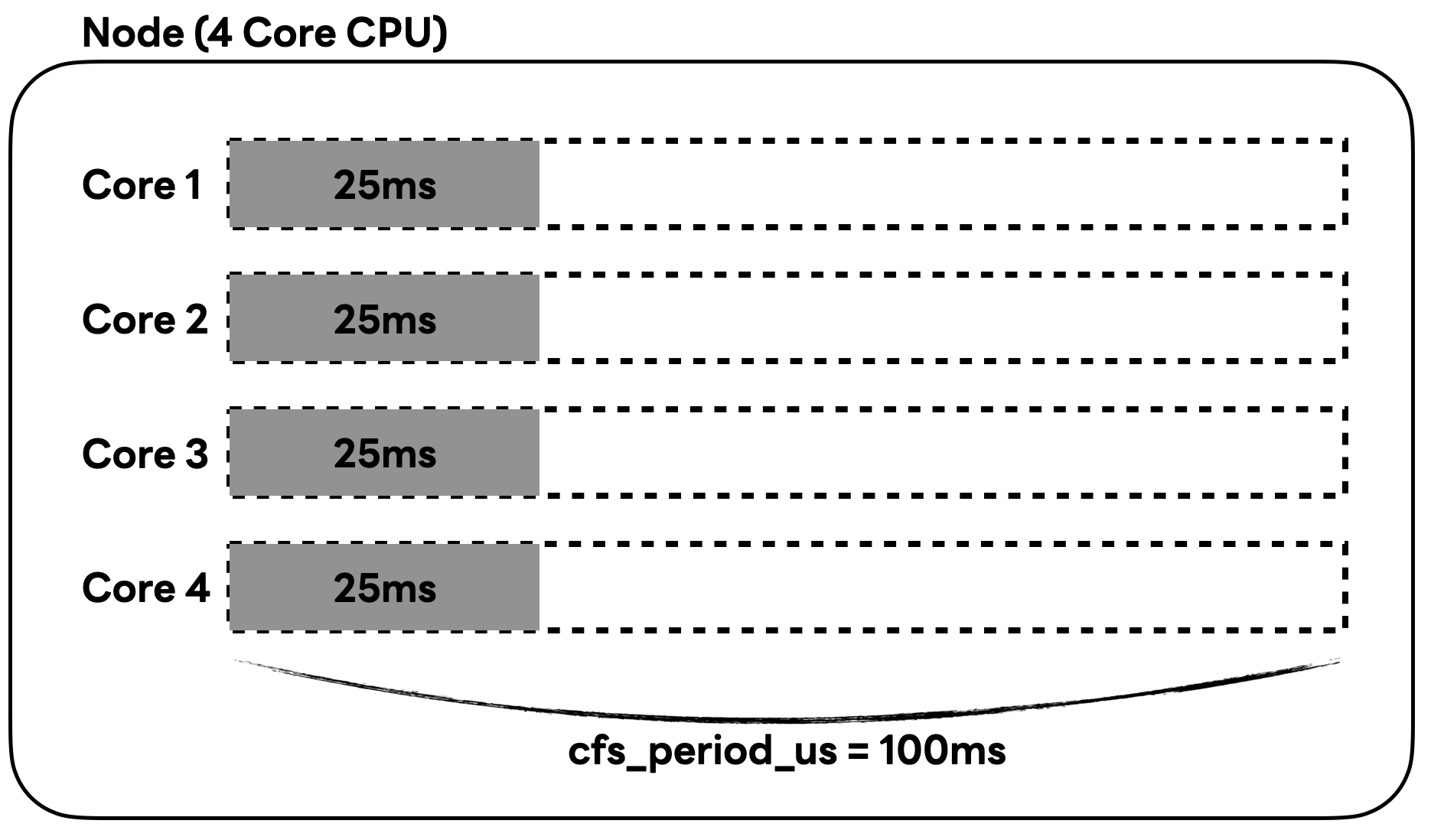
위와 같은 상황에서 해당 파드의 CPU 상한이 1 코어로 설정돼 있었다면 cfs_quota_us 설정 제한에 걸리는데요. 이로 인해 cfs_period_us 시간 100ms 중 나머지 75ms에 해당하는 시간 동안 CFS 스로틀링이 발생합니다. 노드에 CPU 리소스가 여유롭게 할당돼 있더라도 코어를 병렬로 사용하면서 cfs_quota_us 설정으로 인해 제한된다면 CFS 스로틀링이 발생할 수 있는 것이죠.
그래서 CPU 상한을 제거하려는 이유는?
애플리케이션의 성능을 최대로 끌어올리기 위한 방법 중 하나는 주어진 자원을 최대한 활용하는 것입니다. 주어진 자원을 최대한 활용하려면 CFS 스로틀링 발생을 최소화해야 하고, 이를 위해서는 cfs_quota_us로 인한 제한이 발생하지 않아야 하며, cfs_quota_us로 인한 제한이 발생하지 않으려면 CPU 상한을 설정하지 않아야 합니다.
CPU 상한 설정을 제거해도 괜찮을까요?
CPU 상한 설정을 제거해서 cfs_quota_us 설정을 없애 CPU 사용에 제한을 두지 않는다는 것이 조금 우려될 수도 있습니다. 특히 하나의 노드에 두 개 이상의 파드가 존재하는 경우 '한 파드가 CPU를 너무 많이 사용하는 바람에 다른 파드가 적절한 CPU 리소스를 활용하지 못할 수도 �있지 않을까?'라고 걱정할 수 있는데요. 실제로는 그렇지 않습니다. 앞서 살펴본 것처럼 CPU 요청량 설정에 따른 CPU 리소스 할당은 보장받기 때문에 파드의 CPU 상한을 제거해도 다른 파드에 설정된 최소한의 CPU 리소스는 확보되니 걱정하지 않으셔도 됩니다.
그래서 성능에 얼마나 변화가 있을까?
CPU 상한 설정 제거의 목적은 결국 CPU 리소스를 보다 효율적으로 사용하는 것이며, 이를 통해 기대하는 것은 성능 개선입니다. 앞서 살펴본 내용을 이론적으로 살펴보면 성능이 개선될 것이라고 충분히 기대할 수 있는데요. 실제로 개선되는지, 개선된다면 얼마나 개선되는지 꼼꼼히 확인해 볼 필요가 있습니다.
저희는 CPU 상한 설정 제거가 쿠버네티스 구조와 상관없이 성능에 동일한 영향을 끼치는지 파악하고자 서로 다른 쿠버네티스 구조로 설계된 Spring 기반의 서버와 Node.js 기반의 서버를 기준으로 각각 테스트를 진행하면서 성능의 변화를 확인해 보기로 결정했습니다.
CPU 상한 설정 제거 테스트 방법과 결과
테스트는 현재 각 팀에서 운영 중인 애플리케이션의 개발 환경에서 각각 진행했습니다. 즉 백엔드 팀에서 사용하는 Spring 서버 애플리케이션과 프런트엔드 팀에서 사용하는 Node.js 서버 애플리케이션을 대상으로 각각 테스트를 진행했습니다.
각 테스트 결과는 각 팀 내부에서 살펴보고 다양한 의견을 주고받으며 논의했으며, 그 결과 두 팀이 서로 다른 결정을 내렸는데요. 앞서 말씀드렸듯 결론적으로 Spring 서버 애플리케이션에서는 CPU 상한 설정을 제거하기로 결정했고, Node.js 서버 애플리케이션에서는 CPU 상한 ��설정을 유지하기로 결정했습니다.
동일한 내용과 지표로 테스트를 진행했음에도 왜 서로 다른 결정을 내리게 됐는지 그 이유와 배경을 함께 생각해 보시면서 이하 내용들을 읽어보시면 더욱 흥미롭게 읽으실 수 있을 것 같습니다.
테스트에서 참고한 지표
테스트는 모두 nGrinder 기반의 사내 테스트 플랫폼을 이용했으며, 성능 지표로는 TPS(transactions per second)와 최대 TPS, 평균 응답 시간(average response time)을 선정했습니다. 또한 컨테이너의 상태를 확인하기 위해 부하를 발생시키면서 Grafana를 통해 몇 가지 지표를 살펴봤는데요. 대표적으로 다음 지표를 살펴봤습니다.
container_cpu_cfs_throttled_seconds_total: 해당 컨테이너가 CPU CFS에 따라 제한(스로틀링)된 총 시간을 의미합니다. 해당 값이 증가할수록 스로틀링이 더 많이 발생한 것입니다.container_cpu_usage_seconds_total: 컨테이너가 사용한 CPU 시간의 총합입니다. 전체적인 CPU 사용량을 측정하는 지표입니다.
테스트 시 중요하게 고려한 요소들
성능
앞서 이야기했듯 가장 중요한 포인트는 '성능이 얼마나 개선됐는가?'입니다. 성능은 당연히 개선될 것이라고 예측했지만, 실제로 '얼마나' 개선되는지 정확히 확인하고자 했으며, 어떤 특성의 환경에서 성능 개선이 두드러지게 나타나는지도 관찰하고자 했습니다.
CPU 사용량
CPU 상한 설정을 제거하는 것은 결국 노드가 가진 CPU 리소스을 최대한 효율적으로 사용하기 위함입니다. 따라서 부하가 증가함에 따라 자연스��럽게 CPU 사용량에 차이가 발생할 것으로 예측했으며, 테스트 시 해당 지표를 주의 깊게 관찰했습니다.
쿠버네티스 구조 일관성
'쿠버네티스 구조 일관성'은 사람마다 조금 다르게 해석할 수도 있을 것 같은데요. 저희는 '성능 일관성'과 '설정 일관성'을 기준으로 삼고, CPU 상한 설정 제거가 성능이나 설정 일관성에 어떤 영향을 미칠지 고민하고 관찰하며 테스트를 진행했습니다.
그 외 리스크
테스트를 진행하면서 저희가 예상하지 못했던 에러 케이스나 특이 사항이 발생할 것에 대비해 다양한 지표를 폭넓게 관찰했습니다. 결과적으로 별다른 특이 사항은 찾지 못했기에 이후 테스트 내용 및 결과를 공유드릴 때는 위에서 말씀드렸던 대표적인 지표 확인 결과만 언급할 예정입니다. 이와 관련해서는 사내 쿠버네티스 담당 부서와도 함께 논의했는데요. 어떤 내용을 논의했는지 글을 마무리하면서 다시 말씀드리겠습니다.
Spring 서버 애플리케이션 테스트 결과
먼저 Spring 서버 애플리케이션을 대상으로 테스트한 방법과 결과를 말씀드리겠습니다.
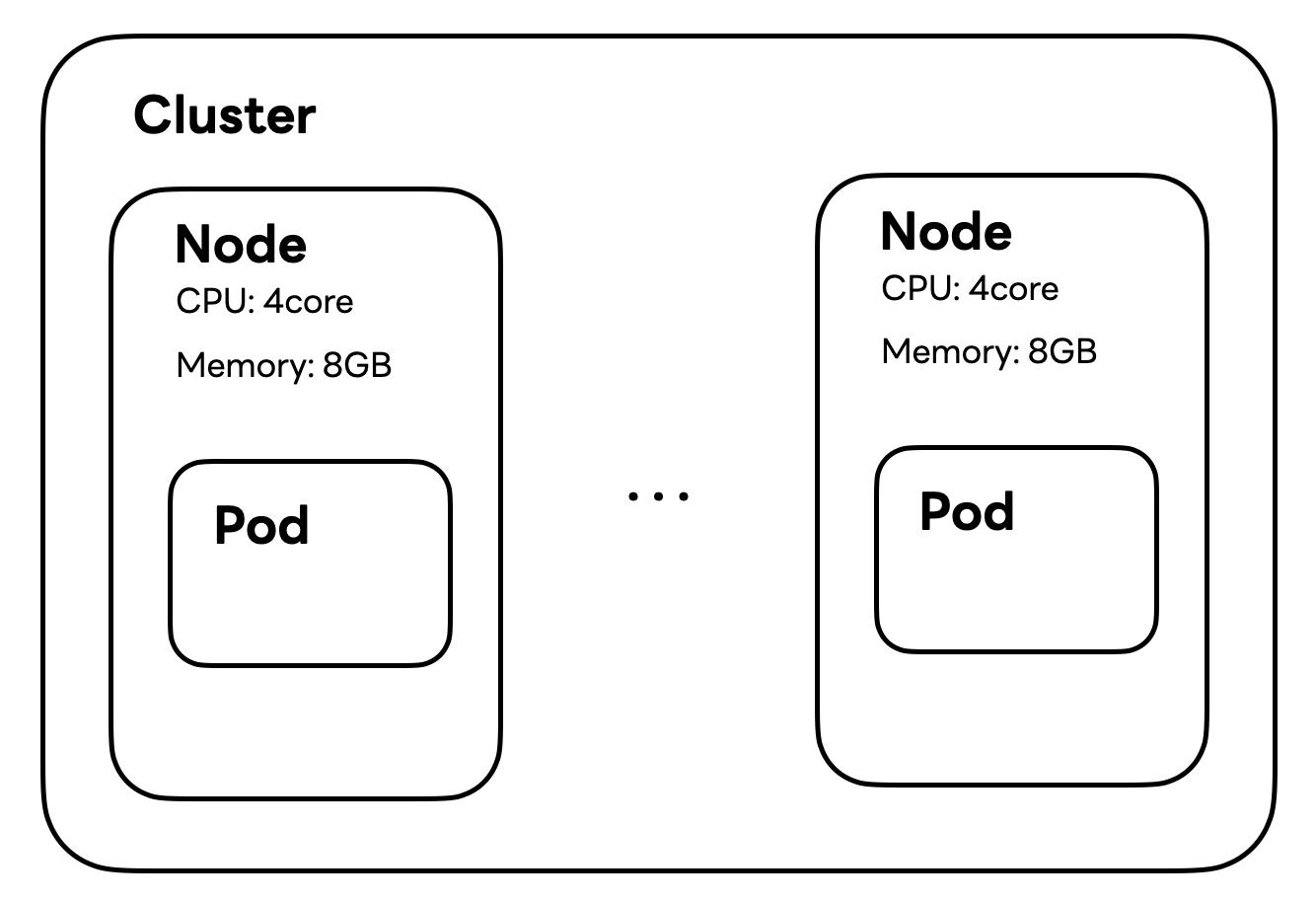
Spring 서버 애플리케이션을 테스트하기 위한 쿠버네티스 구조
Spring 서버 애플리케이션을 테스트하기 위한 쿠버네티스 구조는 다음과 같습니다. 이 구조의 대표적인 특성은 클러스터 및 노드에 다양한 애플리케이션을 배치하지 않은 싱글 테넌시(single-tenancy) 구조로 하나의 노드에 하나의 파드를 배치한 단순한 형태라는 것입니다.
테스트 케이스와 테스트 결과
테스트 케이스는 아래와 같이 총 세 가지를 준비했습니다.
| 테스트 케이스 번호 | CPU 요청량 | CPU 상한 | 파드 개수 | 테스트 케이스 설명 |
|---|---|---|---|---|
| (1) | 1.0 코어 | 1.0 코어 | 2 | 노드의 CPU 리소스보다 적은 수치의 CPU 리소스 사용 |
| (2) | 3.0 코어 | 3.0 코어 | 2 | 노드의 CPU 리소스와 비슷한 수치의 CPU 리소스 사용 |
| (3) | 1.0 코어 | N/A | 2 | CPU 상한 설정 제거 |
테스트는 가상으로 설정된 동시 사용자(vUser)가 250인 경우와 1000인 경우를 나눠 진행했습니다.
| vUser | 테스트 케이스 번호 | TPS | 최대 TPS | 최대 CPU 사용량(코어/파드) | 최대 CFS 스로틀링(s/2m)* | 결과 |
|---|---|---|---|---|---|---|
| 250 | (1) | 247.6 | 317.5 | 0.98 | 2.12 | - |
| (2) | 535.7 | 667.5 | 2.73 | 0.0151 |
(1)번과 비교 결과
| |
| (3) | 570.0 | 707.5 | 2.98 | N/A |
(1)번과 비교시
| |
| 1000 | (1) | 타임아웃 에러 발생해 성능 측정 불가 | ||||
| (2) | 418.0 | 799.5 | 2.65 | 0.00979 | - | |
| (3) | 640.1 | 971.5 | 2.98 | N/A |
(2)번과 비교 결과
|
*s/2m: 2분당 CPU를 사용하지 못한 초
먼저 (1)번 케이스와 (2)번 케이스를 비교해 보면, CPU 사용량이 증가하면서 전체적인 성능이 크게 향상되는 것을 확인할 수 있습니다. 또한 (2)번 케이스와 (3)번 케이스를 비교해 보면, CPU 상한 설정을 제거한 뒤 CPU 사용량이 증가하는 것을 확인할 수 있고, 성능 또한 최대 53%까지 향상되는 것을 확인할 수 있습니다(테스트 중 별도 에러나 이슈는 발생하지 않았습니다).
고민해 볼 점과 결론
테스트 결과 CPU 사용량이 증가하며 성능이 향상되는 것을 쉽게 확인할 수 있었습니다. 또한 CPU 상한 설정을 제거하면 CPU 사용량이 최대로 증가하는 것 또한 확인할 수 있었습니다.
이론적으로는 매번 사용 가능한 CPU 리소스 수치를 확인해 이 값을 CPU 상한으로 설정하는 것도 CPU 상한 설정을 제거하는 것과 동일한 수준의 성능을 보여줄 것이라고 예상할 수 있는데요. 이를 실제로 수행하는 것은 상당히 어려운 작업이라고 판단했습니다. CPU 리소스가 4 코어인 노드를 할당받아도 실제로 사용 가능한 CPU 리소스는 4 코어 미만인 약 3.6~3.8 코어 수준인 경우가 많습니다. 또한 각 노드에 클러스터 운영 등을 위한 일부 파드가 생성된다면 실제 사용 가능한 CPU 리소스를 정확하게 계산하는 것은 어렵습니다. 당연히 노드마다 그 값도 다를 것이고요.
앞서 살펴본 것처럼 Spring 서버 애플리케이션의 쿠버네티스 구조는 싱글 테넌시 구조로 하나의 노드에 하나의 파드가 배치되는 매우 단순한 구조입니다. 저희는 이런 간단한 구조에서 추가로 고려해야 할 리스크는 없다고 판단했으며, 이와 관련해서 사내 쿠버네티스 담당 부서와 논의한 결과 해당 구조에서는 CPU 상한 설정을 제거하는 것이 CPU 리소스를 보다 효율적으로 사용하는 데 도움 될 것이고 추가로 고려할 만한 리스크는 없다는 답변을 받았습니다.
이와 같은 이유로 Spring 서버 애플리케이션에서는 CPU 상한 설정을 제거하는 것으로 결정했습니다.
Node.js 서버 애플리케이션 테스트 결과
다음으로 Node.js 서버 애플리케이션을 대상으로 테스트한 방법과 결과를 살펴보겠습니다.
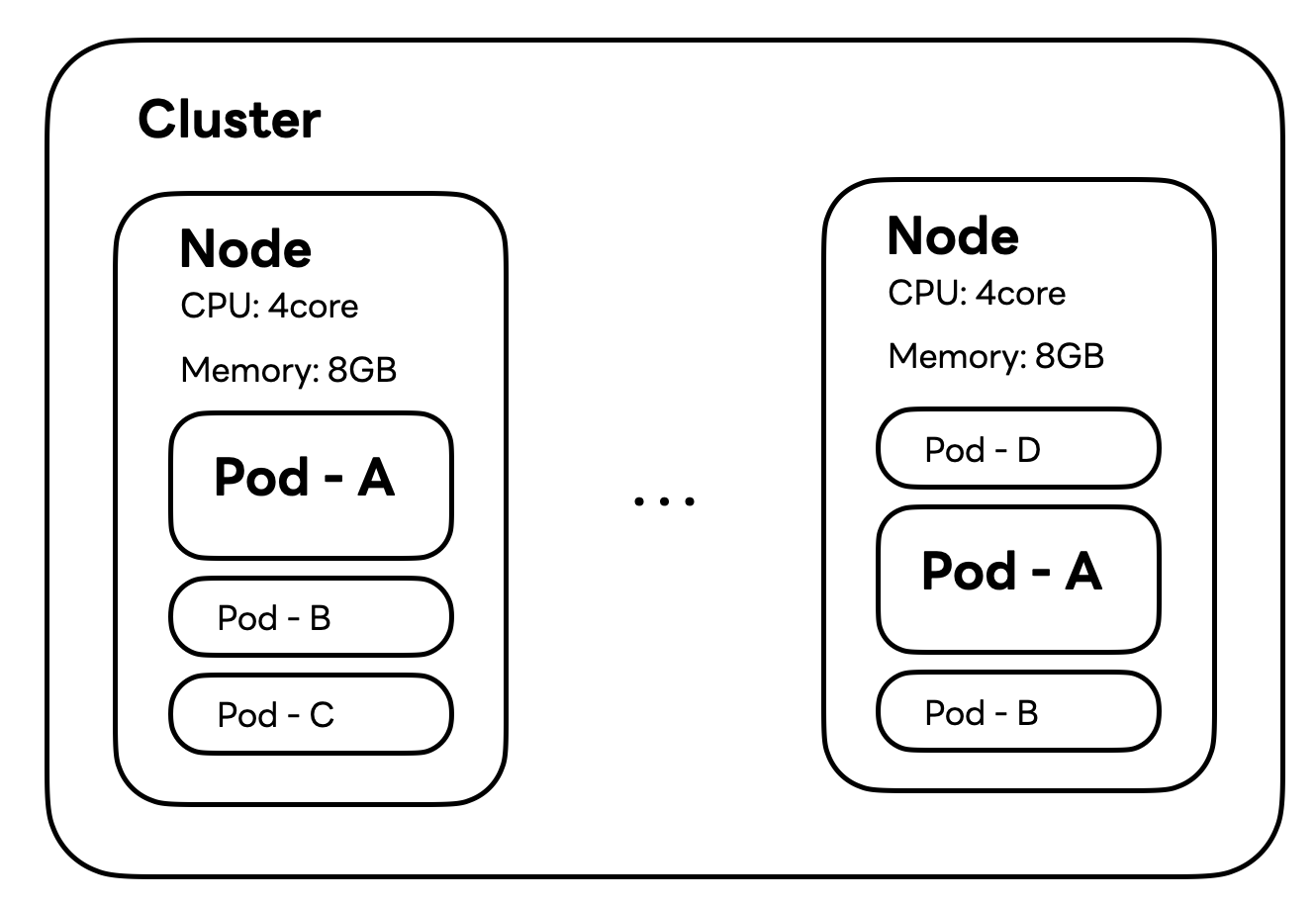
Node.js 서버 애플리케이션 테스트 쿠버네티스 클러스터 구조
Node.js 서버 애플리케이션을 테스트하기 위한 쿠버네티스 클러스터는 앞서 살펴본 Spring 서버 애플리케이션 케이스와는 다르게 멀티 테넌시(multi-tenancy) 구조로, 하나의 노드에 여러 개의 애플리케이션 파드가 배치돼 있습니다.
테스트 케이스와 테스트 결과
테스트 케이스는 아래와 같이 총 두 가지를 준비했습니다.
| 테스트 케이스 번호 | CPU 요청량 | CPU 상한 | 파드 개수 | 테스트 케이스 설명 |
|---|---|---|---|---|
| (1) | 0.8 코어 | 1.15 코어 | 4 | |
| (2) | 0.8 코어 | N/A | 4 | CPU 상한 설정 제거 |
테스트 결과는 아래와 같습니다. CPU 상한 설정을 제거했을 때 TPS 성능이 최대 20% 향상됐으며, CPU 사용량도 증가하는 것을 확인할 수 있었습니다(테스트 중 별도 에러나 이슈는 발생하지 않았습니다).
| 테스트 케이스 번호 | TPS | 최대 TPS | 최대 CPU 사용량(코어/파드) | 최대 CFS 스로틀링(s/2m) | 결과 |
|---|---|---|---|---|---|
| (1) | 128.5 | 137.1 | 1.115 | 0.246 | - |
| (2) | 145.6 | 164.3 | 1.263 | N/A |
(1)번과 비교 결과
|
고민해 볼 점과 결론
앞서 살펴봤던 Spring 서버 애플리케이션에 비해 성능 향상의 정도가 다소 아쉬웠습니다. 다양한 요소가 이런 결과에 영향을 미쳤겠지만 무��엇보다 CPU 상한 설정을 제거하더라도 동일한 노드에 다른 파드가 존재한다는 것과 단일 스레드를 사용하는 Node.js 서버의 특징의 영향이 컸던 것으로 파악했습니다.
또한 Node.js 서버 애플리케이션의 경우 Spring 서버 애플리케이션의 경우와는 달리 멀티 테넌시 구조이기 때문에 앞서 말씀드린 쿠버네티스 구조의 일관성을 유지하는 것이 중요하다는 것도 고려해야 했습니다. 이와 관련해서 앞서 '성능 일관성'과 '설정 일관성' 관점에서 고려했다고 말씀드렸는데요. 각 측면에서 하나씩 살펴보겠습니다.
먼저 결정 과정에서 중요하게 고려한 것은 성능 일관성입니다. 멀티 테넌시 환경에서 CPU 상한 설정을 제거한다는 것은 부하가 발생했을 때 여유분의 CPU 리소스를 끌어다 사용하는 것을 의미합니다. 그렇다면 이때 특정 시점에 A 애플리케이션에 부하가 발생해 2,000 TPS를 문제없이 처리했다고 해서 A 애플리케이션이 항상 2,000 TPS에 대응할 수 있다고 판단할 수 있을까요? 멀티 테넌시 환경에서는 그렇지 않습니다. 다른 B, C 애플리케이션과 CPU 리소스를 공유하고 있기 때문에 만약 동일한 시점에 B 또는 C 애플리케이션에도 부하가 발생한다면 A 애플리케이션 혼자 여유분의 CPU 리소스를 모두 사용할 수 없을 것이고, 따라서 2,000 TPS의 성능이 나오지 않을 수도 있습니다.
이어서 설정 일관성을 측면을 보겠습니다. 설정 일관성을 고려한다면 특정 애플리케이션에서 CPU 상한 설정을 제거했다면 동일한 클러스터를 사용하는 다른 애플리케이션에서도 해당 설정을 제거하는 것이 자연스러울 것입니다. 하지만 그렇게 하면 성능 일관성이 모든 애플리케이션에서 보장되지 않는다는 단점이 발생합니다. 그렇다고 멀티 테��넌시 환경에서 일부 파드만 CPU 상한 설정을 제거하고 일부 파드는 유지한다면 설정 일관성뿐 아니라 성능 관점에서도 이슈가 발생할 수 있습니다(이 글에서 이 부분을 깊게 다루지는 않겠습니다).
위와 같은 이유를 고려해 Node.js 서버 애플리케이션에서는 얼마간의 성능 개선 효과보다는 일관성을 유지하는 것에 초점을 두고 CPU 상한 설정을 유지하는 것으로 결정했습니다.
CPU 상한, 그래서 어떻게 설정해야 할까?
저희가 테스트했던 결과와 이에 따라 결정한 내용을 간단히 정리해 보면 다음과 같습니다.
| 구분 | 애플리케이션 서버 | 쿠버네티스 구조 | CPU 상한 설정 | CPU 상한 설정 선택 이유 |
|---|---|---|---|---|
| 백엔드 서버 | Spring 서버 애플리케이션 | 싱글 테넌시 | 제거 |
|
| 프런트엔드 서버 | Node.js 서버 애플리케이션 | 멀티 ��테넌시 | 유지 |
|
앞서 함께 살펴본 결과와 같이 CPU 상한 설정을 제거하면 양쪽 모두 성능이 향상됐습니다. 다만 단일 스레드 기반의 Node.js 서버 애플리케이션의 경우 성능 향상의 정도가 다소 미미했고, 쿠버네티스 구조가 복잡하다는 것을 고려해 CPU 상한 설정을 유지하는 것으로 결정했습니다. 이와 달리 Spring 서버 애플리케이션의 경우 성능 향상의 정도가 컸으며, 쿠버네티스 구조가 단순하다는 것을 고려해 CPU 상한 설정을 제거하는 것으로 결정했습니다.
이와 같이 CPU 상한 설정을 유지 혹은 제거하는 것에 따른 효과는 각 프로젝트의 다양한 상황과 주변 환경 및 구조에 따라 달라질 수 있습니다. 글에서 살펴본 바와 같이 CPU 상한 설정을 제거하면 일반적으로 성능이 향상되지만 성능 향상의 정도는 프로젝트의 구조나 환경에 따라 다를 수 있습니다. 또한 멀티 테넌시 환경 등 쿠버네티스 구조가 복잡한 경우에는 설정 일관성을 유지할 수 없고, 노드 리소스 관리 또한 어려워질 수 있기 때문에 단순히 성능 향상만 바라보고 판단하는 것은 바람직하지 않습니다.
따라서 단순히 하나의 결과만 보고 결정하는 것보다는 이 글에서 공유한 내용을 참고해 쿠버네티스의 CPU 리소스 관리 방식을 보다 깊이 이해하는 것을 권장합니다. 이후 이를 기반으로 다양한 테스트를 진행하며 각 프로젝트에서 중요하게 여겨야 할 포인트를 도출 및 고려하고, 이와 관련해 내부적으��로 논의한 후 결정하는 것이 제일 좋은 방법이라고 생각합니다.
많은 분들이 이 글을 통해 쿠버네티스의 CPU 리소스를 더욱 효율적으로 사용할 수 있기를 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


