안녕하세요. ABC Studio 김영재입니다. 저는 오픈소스 프로젝트 10여 개를 디렉팅하고 개발했으며, 팀에서 소프트웨어를 처음 설계할 때에도 어지간하면 오픈소스로의 전환 가능성을 염두에 두도록 하고 있습니다. 이번 글에서는 이 과정에서 주로 어떤 점을 강조하는지 소개하고자 합니다.
인터넷에서 접할 수 있는 오픈소스 관련 글들은 대부분 오픈소스의 철학을 말하거나 처음 시작하는 사람들을 위한 README 작성법 혹은 라이선스 차이를 설명하는 글이 많은데요. 이번 글에서는 프로젝트의 구조나 구성 방식에 대해서 말하고자 합니다. 더불어 오픈소스 활동을 하면서 가치를 두면 좋을 부분과 네이밍도 언급할 예정인데요. 미리 말씀드리자면 이는 어디까지나 저의 관점일 뿐 절대적인 지침은 아닙니다.
참고로 본 글에서는 '기술 사용자'라는 표현을 종종 사용할 예정입니다. 이는 소프트웨어의 최종 사용자(end-user)가 아닌, 오픈소스로 공개한 기술을 설치하고 운영하는 엔지니어 또는 기술 도입을 검토하는 사람을 일컫습니다.
오픈소스로 개발할 때의 마인드셋
처음 오픈소스로 자신이 만든 것을 공개할 때 그 사실에 마음이 설레는 사람도 있습니다. 지��식을 세상에 공헌한다는 거룩한 철학으로 오픈소스의 의미를 설명하는 글도 많습니다. 하지만 저는 그보다는 그저 배포 방식의 하나라고 가볍게 생각하는 편이 좋다고 생각합니다. 오픈소스 개발에 너무 철학적인 의미를 부여하면 두 가지 부작용이 있기 때문입니다.
먼저, 코드의 순수함에 너무 몰두하게 될 수 있습니다. 소프트웨어는 여러 번의 시행착오와 지저분한 디버깅, 실전에서의 장애를 겪으면서 발전합니다. 특히 운영 중인 서비스에서 사용하는 소프트웨어일수록 어쩔 수 없는 요건과 제약으로 원하지 않는 구조로 만들어지거나 분기가 많아지기도 합니다.
오픈소스로 개발하면 이 모든 결점을 보여주고 싶지 않은 마음이 무척 커질 것입니다. 팀원이 아닌, 전후 사정을 모르는 모두가 볼 수 있는 코드에 자신도 원치 않은 구조나 분기점을 넣고 설명하는 일은 대부분 질색할 것이기 때문입니다.
하지만 오픈소스 활동이 그저 배포 방식 중 하나일 뿐이라고 생각하면 마음이 편해질 수 있습니다. 또한 코드의 순수함에 지나치게 몰두하면 타인의 피드백에 고마움을 느끼거나 수용하기 어렵고, 그 피드백이 자신의 관점에 맞는지에 집착하며 시야가 좁아질 수 있는데 이 또한 그저 배포 방식 중 하나라고 생각하면 완화될 수 있습니다.
두 번째로 활동의 의미가 왜곡될 수 있습니다. 오픈소스를 홍보 수단으로 여기며 여느 SNS의 따봉과 같은 의미로 Star 개수를 바라보면 소프트웨어의 발전을 추구하는 것이 아니라 거창한 목표만 말하다가 끝나거나 인기를 끌만한 소재만 다루다가 소프트웨어 고도화에 궁리해야 할 시간을 허비할 수 있습니다.
결국 힘 있는 소프트웨어는 규모가 어떻든 오픈소스 프로젝��트에서 소개한 기능을 충실히 실현하면서도 기술 사용자가 직접 설치해서 사용하기 쉬운 소프트웨어이고, 꾸준하게 버그도 잡고 의존성 있는 라이브러리나 환경에 따라 업데이트하며 가꾸는 소프트웨어입니다. 그러므로 외적인 수치에 신경 쓰지 말고 작성한 README 소개 글을 얼마나 충실히 구현했는지, 얼마나 사용자의 기대에 부응하는지에 집중하며 만들어 갈 필요가 있습니다.
오픈소스 배포 방식의 장점
앞서 말했듯 저는 오픈소스 '활동'보다는 오픈소스 '배포 방식'이라고 말할 때가 많습니다. 그림으로 말하자면 아래 그림의 파란색 Public Repository를 중심으로 이루어지는 개발 및 배포 프로세스라고 말할 수 있습니다.
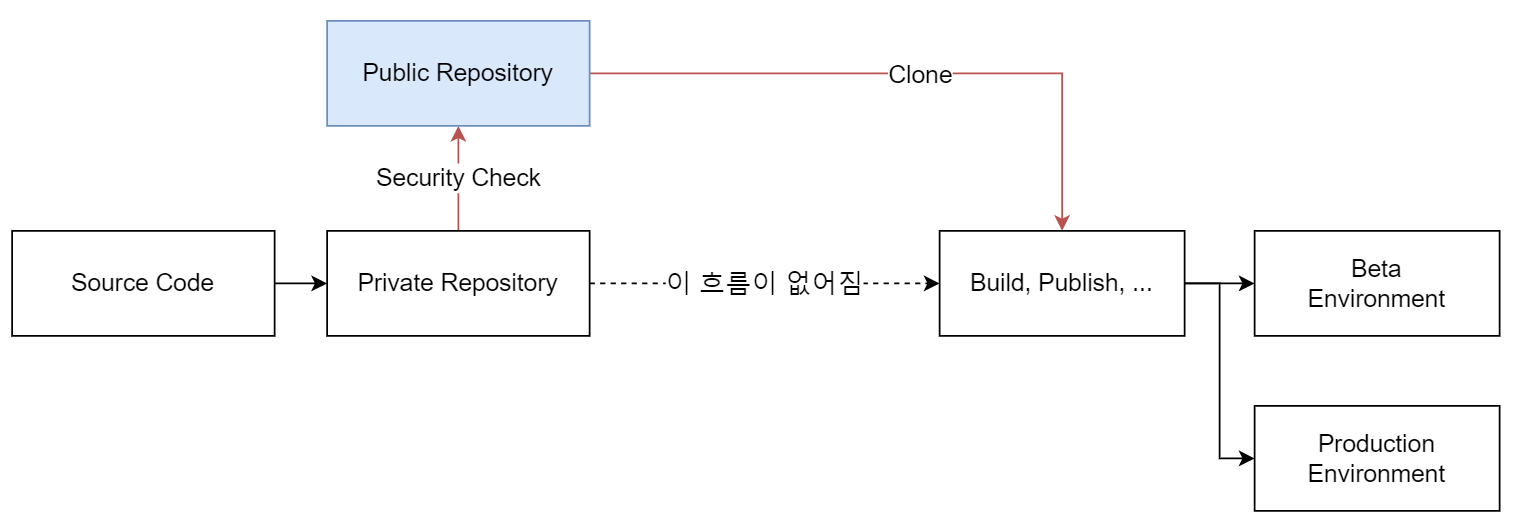
통상적으로 회사에서 개발하는 소프트웨어는 그림의 Public Repository 단계가 필요 없습니다. 그렇다면 이 단계를 넣어서 얻는 장점은 무엇일까요? 오픈소스 배포 방식을 취했을 때 얻을 수 있는 장점은 다음과 같습니다.
- 아키텍처의 독립성을 확보할 수 있습니다.
저는 이것을 '환경이 강요하는 아키텍처'라고 부릅니다. 오픈소스로 만들면 비즈니스 논리와 명확하게 구분하도록 강요받으며 만드는 셈이며, 이에 따라 여러 환경에 의존하는 것이 아니라 최대한 외부와 느슨하게 결합하도록 만들게 됩니다. 예를 들어, 사내에는 SMS 전송 서버가 있는데요. 이를 이용하는 시스템을 오픈소스로 만들면 SMS 서버의 API 주소를 코드 안에 하드 코딩하는 게 아니라, 환경 변수로 구성하거나 인터페이스로 감싸거나 혹은 별도 라이브러리로 만들고 주입하도록 구성하는 게 낫다고 생각하게 됩니다. - 오픈소스 라이선스를 채택해 사용의 자유도를 높일 수 있습니다.
회사원으로서 회사의 돈으로 개발한 소프트웨어는 회사의 자산(asset)이 되는데요, 현재 저희 회사는 관계사가 100개 이상으로 매우 복잡한 법인 관계를 가지고 있습니다. 이때 배포한 오픈소스에 Apache와 같은 일반적인 라이선스를 설정하면, 법인 간 복잡한 자산 취급 관계와 이용 가능성을 검토하는 논의에서 한발 물러나 프로덕트 고유의 민첩성을 높일 수 있습니다. - 시작부터 보안에 더 신경 쓸 수 있습니다.
여느 회사의 비공개 저장소(private repository) 안에는 비밀 키(secret key)가 아무렇지 않게 들어있는 경우가 많습니다. 사내에서 만들어 온 저장소 하나를 오픈소스로 공개하자고 했다가 커밋 기록 안에 있는 비밀 키 때문에 개인 정보 유출 사고가 발생하는 문제는 전 세계에서 매달 나오곤 합니다. 이때 처음부터 오픈소스를 염두에 두고 만들면 첫 커밋부터 환경 변수 파일을 정의하고 .gitignore 파일에 이를 지정해서 처음부터 위험을 줄일 수 있습니다. 처음부터 배포 조건 때문에 필수로 지킬 수밖에 없게 만들면 환경 변수를 별도로 만드는 것을 귀찮아 하는 사람을 애써 설득할 노력도 아낄 수 있습니다.
오픈소스의 장점으로 흔히 말하는 '자유로운 참여'는 부가적인 의미라고 생각합니다. 외부 참여자가 0명이면 어차피 의미가 없기 때문입니다. 외부의 자발적인 참여를 꾸준하게 이끌어 내는 것은 꽤 어려운 일입니다. 그러니 처음에는 아무도 나의 저장소에 관심이 없을 것이라고 생각하고 소프트웨어 개발에 ��집중하는 편이 좋습니다.
좋은 오픈소스 구조를 만드는 첫 걸음
앞서 참여를 기대하지 말라고 했지만, 그럼에도 오픈소스를 운영하면서 얻을 수 있는 가장 큰 기쁨은 기술 사용자가 어느새 의견을 주는 참여자가 되고, 더 나아가 코드에 도움을 주는 공헌자(contributor)로 자연스럽게 변화하는 경험일 것입니다. 일반적으로 좋은 소프트웨어를 설계하는 방법은 SOLID 원칙을 잘 지키자는 말로 요약할 수 있을 텐데요. 이번 장에서는 '조금 더 가꾸고 싶은 소프트웨어'로 만드는 방법을 살펴보겠습니다.
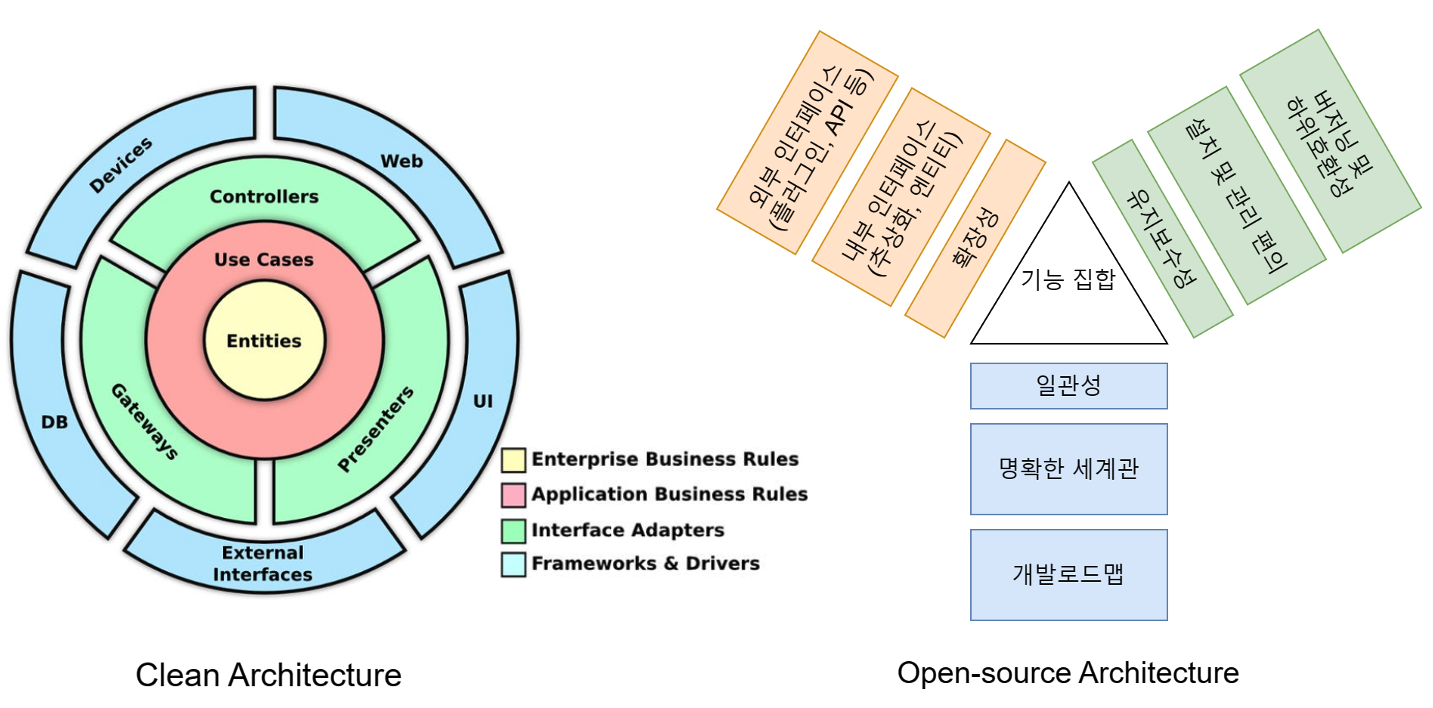
왼쪽은 많은 분들이 널리 인용하는 Robert C. Martin의 Clean Architecture 그림입니다. 중앙에 비즈니스가 자리 잡고 있습니다. 소프트웨어는 현실의 문제를 해결하는 것이 존재 이유이기에 소프트웨어가 쓰이는 비즈니스 상황이 중앙이 위치하는 것은 당연해 보입니다.
하지만 오픈소스는 비즈니스와 독립적으로 구성할수록 범용성을 얻기 때문에, 비즈니스 논리는 최대한 바깥으로 밀어내는 게 좋습니다. 이 점이 오픈소스를 염두에 둔 아키텍처의 가장 큰 차이라고 볼 수 있습니다. 그렇기에 중심에는 기능의 집합이 건조하게 자리 잡습니다. 그다지 관련이 없어 보이는 기능도 '누군가에겐 도움이 되겠지'라는 듯 있곤 합니다.
결과적으로 오픈소스로 배포하는 소프트웨어는 그 오픈소스가 정의한 문제를 해결하기 위한 기술이 점점 중심으로 모입니다. 그래서 대체로 오픈소스를 많이 릴리스하는 조직(organization)의 저장소를 보면 공구 상자처럼 보이기도 하는데요. 대표적인 예로 Netflix OSS가 있습니다.
이에 따라 오픈소스가 발전하는 방향을 위 그림 오른쪽과 같이 세 개의 축으로 정리해 봤습니다. 각 축은 일관성과 확장성, 유지 보수성을 주제로 고도화됩니다. 건강한 소프트웨어는 이 외에도 테스트 가능성, 가용성, 교육 편의성 등 십여 가지 품질 속성을 추가로 관리하는데요. 오픈소스를 시작할 때 특히 의미 있는 주제로 일관성과 확장성, 유지 보수성을 꼽았으며, 각 속성의 대표적인 항목을 예시를 들어 설명하겠습니다.
품질 속성에 대해서는 저의 번역서 개발자에서 아키텍트로의 '5.2 품질 속성 정의하기 (92페이지)'를 참고하시면 좋습니다.
일관성 - 명확한 세계관 수립
세계관이란 이 소프트웨어와 기술을 사용함으로써 얻을 수 있는 가치와 가능성이라고 말할 수 있습니다. 기술 사용자에게 어떤 가치를 얻을 수 있고, 어떤 서비스 시나리오가 가능할지 상상하게 하는 것입니다. 훌륭한 소프트웨어는 첫 문장에 세계관을 명료하게 정의합니다. 아래는 몇 가지 예시로 모두 GitHub 저장소의 README 첫 문장에서 발췌했습니다.
- 데스크톱 소프트웨어의 예: Microsoft PowerToys is a set of utilities for power users to tune and streamline their Windows experience for greater productivity.
- SDK의 예: Flutter is Google's SDK for crafting beautiful, fast user experiences for mobile, web, and desktop from a single codebase.
- 데이터베이스의 예: OrientDB is an Open Source Multi-Model NoSQL DBMS with the support of Native Graphs, Documents, Full-Text search, Reactivity, Geo-Spatial and Object Oriented concepts.
문장을 하나씩 살펴보면 한 단어라도 뺐다가는 방향성이 흔들릴 정도로 꼼꼼하게 작성된 문장이라는 것을 알 수 있습니다. 이처럼 하나의 프로젝트가 바라보는 목적을 명확히 정의할 필요가 있습니다. 목적을 세우면 그에 따라 필수 기능이 정리되며, 필수 기능이 정리된 다음에는 개발 단계(phase)를 세울 수 있습니다.
종종 상상력이 너무 풍부해서 목적과 기능과 그에 따른 순서를 정리하기까지 굉장히 오래 걸리며 어려워하는 분들도 있습니다. 이때 제가 이전 LINE Engineering 블로그에서 발행한 사업부터 개발까지 모든 스테이크 홀더의 눈높이를 맞추는 BANEX 템플릿을 참고하면 좋습니다.
소프트웨어를 만들다 보면 처음에 정의한 세계관과 관계없는 기능이 점점 들어가곤 합니다. 이는 저장소 단위로 역할을 다시 정의하고 재설계할 때가 되었다는 의미인데요. 그전까지는 최소한의 기능을 모아놓고 이를 명확하게 설명할 수 있는 문장으로 세계관을 정의해 보는 것이 좋습니다.
확장성 - 참여를 위한 외부 인터페이스
기술 사용자들이 저장소를 클론 받더라도 대부분은 IDE에서 중요한 코드만 둘러볼 뿐입니다. 하지만 그중 호기심 있는 몇 기술 사용자는 '여기서 무엇을 조금만 수정하면 내가 원하는 대로 쓸 수 있을까?'라고 생각할 수 ��있고, 우리는 이에 대한 답을 준비해 놓아야 합니다. 참여하고 싶도록 자극하려면 믿음을 줄 수 있을 만큼 친절한 문서화도 필요하지만, 그 외에도 플러그인이나 익스텐션, API, 웹훅 등 확장을 염두에 둔 인터페이스를 처음부터 고려하는 것도 필요합니다.
이때 비슷한 소프트웨어들을 벤치마킹하는 과정이 필요합니다. 유사한 세계관의 소프트웨어들이 어떤 형태로 확장성을 제공하는지 연구해서 미래에 기술 사용자가 자신의 소프트웨어에 참여할 수 있는 여지를 설계 시점부터 확보해 놓으면 좋습니다.
확장 기능은 소프트웨어의 언어와 기술에 따라 다릅니다. 예를 들어 웹 애플리케이션이라면 웹 API에 집중하는 것도 한 가지 방법입니다. 웹 API는 통상적으로 아래와 같은 관계로 데이터를 주고받습니다. 프로그램의 역할에 따라 적절한 외부 시스템과의 통신 방법을 선택하면 됩니다.
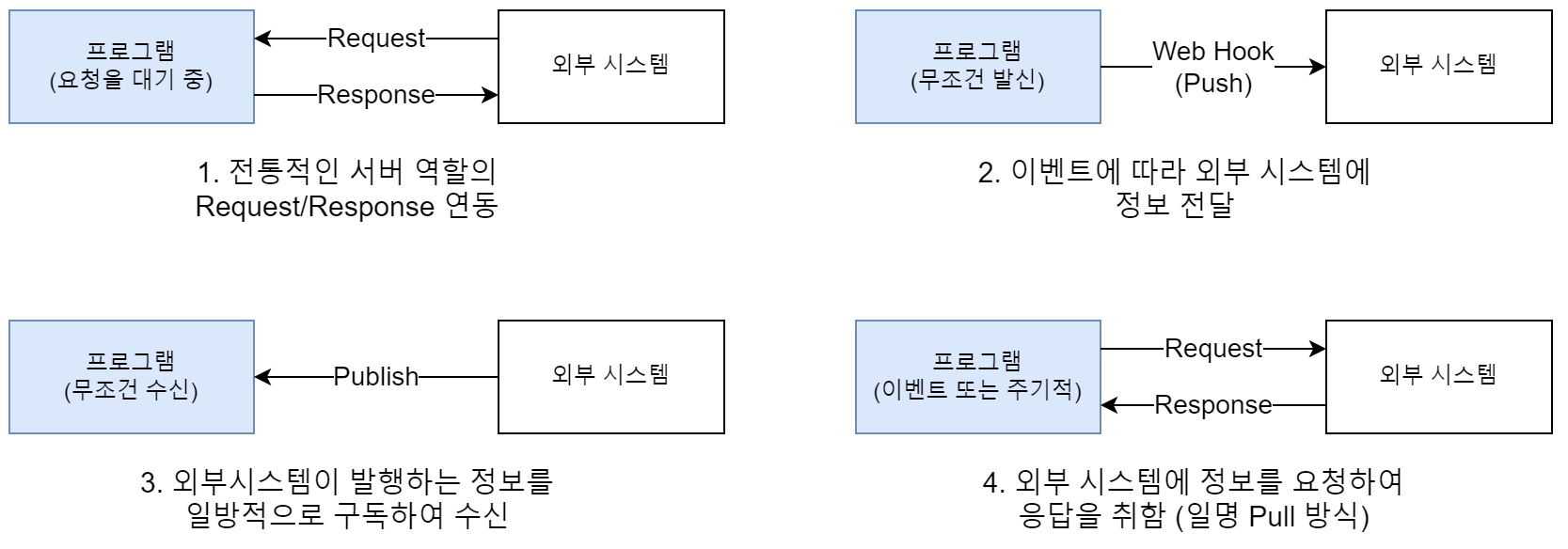
요즘 프로그램 개발에서 중요한 트렌드라면 시작부터 외부 연결성을 염두에 둔다는 점입니다. 이는 기술 생태계를 만드는 가장 첫 작업이기 때문일 것입니다. 위 그림에서 가장 간단하게 시도해 볼 수 있는 방법은 2번의 푸시 방식일 텐데요. 프로그램에 URL을 등록할 수 있도록 해 특정 이벤트나 스케줄에 따라 HTTP 클라이언트로 송신만 하면 되므로 개발 부담이 적고 프로그램 안정성에도 영향이 적습니다.
유지 보수성 - 설정 파일로 동작이 읽히는 프로그램
오픈소스의 첫인상은 README 문서이지만, README 내용과는 별개로 얼마나 기술 사용자가 도입하기 편하게 만들었는지 또한 첫인상이라고 할 수 있습니다. 이 관점에서 오픈소스 프로젝트를 도입하고자 하는 기술 사용자에게 중요한 첫 경험은 크게 두 가지가 있는데요. 바로 설치와 설정 경험입니다.
설치의 경우 예를 들어 node.js 패키지를 만들었다면 npm 연결까지 구성해 기술 사용자에게 설치 편의를 배려할 필요가 있습니다.
설정 편의의 경우 추천하는 개발 방법 중 하나로 설정 파일부터 만드는 방법이 있습니다. 처음부터 프로그램 로직을 전혀 작성하지 않고 설정 파일부터 만들어 보면, 새 텍스트 파일을 만든 후 임의의 이름을 정의하고 값을 넣으며 기술 사용자에게 잘 읽히는지, 앞으로 발전 가능성은 어떤 게 있을지 생각해 볼 수 있습니다.
아래의 코드 예시는 어느 자동화 스크립트를 실행하는 Slack 봇 서버의 YAML 설정 파일입니다. 이 봇은 GitHub에서 PR(Pull Request)할 때 발행되는 웹훅을 서버가 받으면, 내용을 적당히 가공해서 Slack에 알림을 보내는 역할을 하는데요. 아래 설정 파일을 보는 것만으로 어느 정도 동작을 예상할 수 있습니다. 또한 인증 토큰이 바뀌거나 호출할 서버의 URL이 바뀌는 경우에도 프로그램을 애써 이해할 필요 없이 다음 사람(미래의 나?)이 대응할 수 있습니다.
github-pr-webhook-to-slack-notification:
github:
url: https://sample.github.com
username: sample-name
authtoken: sample-key
slack:
url: sample-webhook.slack.com
authtoken: sample-slack-key
template:
default: sample-template.txt설정 파일부터 만드는 훈련은 두 가지 장점이 있습니다.
- 프로그램의 수명이 길어집니다.
제가 본 여러 �회사의 자동화 스크립트는 외부 설정의 여지가 전혀 없이 모든 값이 로직 안에 하드 코딩돼 있어서 아무도 무서워서 건드리지 못하는 문제가 있었습니다. 사실 코드를 작성하는 물리적인 시간은 설정 파일이 있든 없든 비슷합니다. 이제는 대부분의 언어에서 설정값을 읽고 변수화하는 코드를 작성하는 게 무척 쉬워졌기 때문입니다. 프로그램은 개발자의 손을 떠나서 영원히 어딘가에서 작동하며 활동할 수 있습니다. 그러니 필연적으로 닥쳐올 유지 보수를 염두에 두고 설정 기능을 로직과 명확히 분리해서 만들면 내가 아닌 다른 사람이 설정을 바꾸며 더 오래 쓸 수 있습니다. - 확장 가능성을 분명히 표시할 수 있습니다.
설정 파일부터 만들다 보면 '미래에 이 부분만 수정하면 쉽게 대응할 수 있겠다'라고 생각할 여지가 많아집니다. 이에 따라 최대한 설정으로 변경할 수 있도록 소프트웨어 구조를 만들 수 있으며, 설정으로 변경 가능한 부분과 그 외의 코드를 분리하면서 핵심 로직의 응집력이 더 강해집니다. 위 예시 코드를 보면 'template'이라는 항목이 있습니다. 아마도 Slack 메시지의 형식을 여러 가지로 만들 수 있는 것 같습니다(라고 기술 사용자가 유추할 수 있습니다). 처음에 스크립트 기능이 단순할 때에는 하나의 메시지 표현으로 만족할 수 있지만, 시간이 지나면서 사용자들이 여러 표현 방식을 요청할 수 있는데요. 이를 위해 미리 설정 파일에 'template' 항목을 정의하고 그에 따라 구조를 만들어 놓으면 당장은 예시처럼 sample-template.txt 파일 하나만 존재할지라도 추후 수고를 덜 들이고 확장할 수 있습니다.
소프트웨어 유형별 구조
오픈소스가 꼭 �실행하는 소프트웨어일 필요는 없습니다. HeadVer 버저닝 규칙 같은 기술 사양서도 오픈소스가 될 수 있고, Microsoft Docs와 같이 변화가 빠른 클라우드 서비스의 설명서를 GitHub에서 운영하는 오픈소스도 있습니다. 이처럼 요즘은 오픈소스를 떠올릴 때에 그 오픈소스가 꼭 소스 코드만 의미하지는 않는 경우가 많아지고 있습니다. 다만 본 장에서는 기능이 있는 소프트웨어에 초점을 맞추고, 소프트웨어 유형마다 주의할 점과 얻을 수 있는 경험을 설명하겠습니다.
여기서는 저장소나 디렉터리를 구조의 단위로 취급해 설명하고 있지만, 이들을 아름답게 구성하는 게 곧 아키텍처이자 설계 방법이라고 말할 수는 없습니다. 아키텍처는 물리적인 개념 외에 추상적인 개념도 있고, 물리적이고 추상적인 의미 외에도 프로세스(작업 순서, 협업 방식) 관점도 있습니다. 그럼에도 이 글에서 물리적인 저장소 단위로 말하는 이유는, 모든 소프트웨어의 구조와 목표를 떠나서 물리적인 저장소가 오픈소스의 기술 사용자에게 표면적으로 가장 먼저 구분되고 취급되는 단위이기 때문입니다.
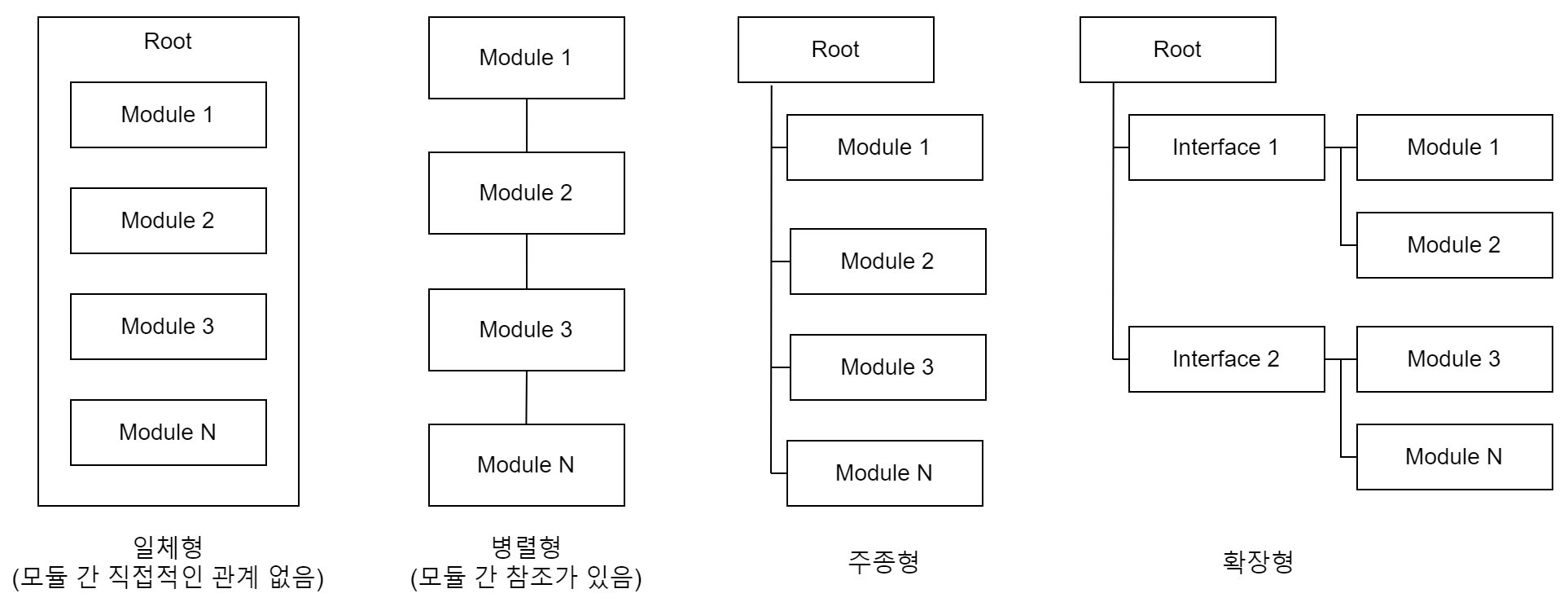
위의 그림에서 Module은 하나의 클래스 파일이거나 디렉터리이거나 저장소일 수 있습니다. 단지 공통된 개념으로 모아 놓은 기능의 집합을 의미합니다. 오픈소스 프로젝트가 해결하려는 문제의 정의와 규모에 따라 위 구조 중 어느 하나의 형태이거나 고도화를 거치면서 몇 개가 복합�된 형태로 구성될 수도 있습니다. 추상화(abstraction)는 소프트웨어 개발에서 미덕으로 삼기에 마지막의 '확장형'이 궁극의 구조라고 생각할지도 모르지만, 그것만이 정답은 아닙니다. 간단한 기능조차 모두 인터페이스를 선언할 필요는 없기 때문입니다.
자신이 만드는 소프트웨어의 특성에 따라 시작부터 하나의 구조를 취해서 가꿔 나가면 전체적으로 크게 흔들리지 않고 조금씩 자라나는 소프트웨어 개발을 경험할 수 있습니다. 이는 기술 사용자들이 오픈소스를 훑어볼 때 보다 빠르게 전체 구조를 이해할 수 있는 단서를 줍니다.
이제 몇 가지 오픈소스 유형에 따른 유의 사항을 알아보겠습니다.
유틸리티 라이브러리
가장 작은 배포 단위의 저장소입니다. 대표적인 예시는 텍스트 처리나 시간 변환 라이브러리가 있습니다.
외부 의존성이 거의 없는 함수 모음에 가까운 라이브러리라면 단위 테스트 구현을 연습하는 목적으로 시도해 봐도 좋습니다. ABC Studio의 경우 Kotlin Multiplatform(KMP) 기반으로 개발하면서 iOS와 Android에서 공통적으로 사용하는 기능 몇 개를 가볍게 통합 인터페이스로 패키징해 릴리스하기도 했습니다.
- abc-kmm-h3: H3 geo-index 라이브러리
- abc-kmm-analytics-tools: 개발 편의를 위한 이벤트, 로그 트래커
- abc-kmm-shared-storage: 로컬 스토리지 관리 통합 인터페이스
- abc-kmm-location: 위치 권한 및 정보 관리 통합 인터페이스
- abc-kmm-notifications: 푸시 알림 관리 통합 인터페이스
라이브러리 하나를 오픈소스로 배포할 때의 장점은 유지 보수가 어렵지 않다는 점입니다. 아니, 어렵지 않도록 기능과 구조를 정의해야 개발자 스스로가 편하기 때문에 어쩔 수 없이 최대한 일반화해 만들게 됩니다. 잘 구성한 라이브러리일수록 기능 정의에 따른 입력과 기대하는 작동 및 출력이 명확하므로 추가 기능을 개발하는 작업 외에는 외부 의존성만 가끔씩 업데이트하면 됩니다.
함수 몇 개가 모인 유틸리티라면 대체로 일체형으로 구성하곤 합니다. 이런 종류에서 참고할 만한 소스 중 유서 깊고 규모가 큰 프로젝트로 Apache Commons Text 라이브러리가 있습니다.
데이터 의존 라이브러리
라이브러리는 소프트웨어의 어느 한 부분을 정리하고 모아 놓은 패키지일 뿐이지만, 복잡한 역할을 담당하도록 만들면 한없이 복잡할 수 있습니다. 소프트웨어의 복잡도는 그 소프트웨어가 취급하는 데이터의 복잡도에 어느 정도 비례하는데요. 데이터베이스에 직접 접속해 처리하거나 데이터를 임시로 저장해 둘 필요가 있는 라이브러리라면 앞서 다룬 유틸리티보다 훨씬 폭넓은 관점에서 검토할 필요가 있습니다.
데이터 또는 데이터베이스를 취급하는 순간 아래 항목을 점검할 필요가 생깁니다.
- 개인정보 취급 여부
- 해싱(hashing) 등 난독화 필요 여부
- 지원하는 데이터베이스의 요구 사항
- 감사(audit) 대응: 접근 권한, 무결성 체크, 데이터 보존 기간 설정 등 지원
- 백업과 복원 지원
제가 경��험한 몇 가지 시행착오를 말씀드리겠습니다.
먼저 데이터베이스 요구 사항의 경우 소규모로 작업할 때는 다양한 데이터베이스로 테스트하기가 어렵기 때문에 어쩔 수 없이 개발 환경의 데이터베이스 한두 개만 말할 수 있을 것입니다. 이런 때에는 README에 테스트해 본 데이터베이스와 스펙상 지원 가능한 데이터베이스를 분리해 설명할 필요가 있습니다.
데이터 보존 기간이나 무결성 체크, 백업 및 복원은 상용 소프트웨어 수준으로 완벽하게 구현하기는 어렵지만 지원하는 정도로는 염두에 두는 편이 좋습니다. 여기서 지원한다는 의미는, 예를 들어 데이터베이스의 레코드를 DB 관리자가 임의로 삭제하면 데이터 무결성을 체크하는 로직에서 적절한 예외를 발생시키는 정도를 말합니다.
백업 및 복원의 경우도 특정 고윳값이 복원 후에 맞지 않아서 정상적으로 실행되지 않는 문제가 발생할 수 있습니다. DB를 처음 생성할 때의 타임스탬프를 암호화의 해시 시드(hash seed)로 설정한 경우 사소한 인증에 실패하기도 합니다. 그러므로 데이터베이스는 라이브러리 내의 로직이 아닌 외부에서도 함부로 수정되거나 변경될 수 있다는 전제로 테스트할 필요가 있습니다.
API 또는 CLI 애플리케이션
이 글에서는 독립적으로 실행할 수 있는 소프트웨어를 애플리케이션으로 정의하겠습니다. 따라서 API(Application Programming Interface) 또는 CLI(Command Line Interface) 애플리케이션은 시각화한 UI는 없지만 명령어와 응답의 형태가 UI인 소프트웨어입니다. 그렇다면 이들의 가장 통상적인 UI는 무엇일까요? 예를 들어, HTTP로 요청한 리소스가 없을 때의 응답 코드로 200, 403, 404, 410 중에 무엇이 더 통상적일까요? 이때는 대체로 GitHub.com API를 이 시대의 가장 통상적인 API 설계라고 생각하고 참고하면 도움이 됩니다. 여기서 통상적이라는 의미는 정답이라는 게 아니라 현시대에서 거부감 없이 통용되고 있다는 의미입니다.
CLI는 Docker의 명령어와 그 응답을 참고하면 좋습니다. Linux 기본 커맨드는 명령어에 따른 응답이 전혀 없어서 불친절한 경우도 있습니다. Docker는 비교적 젊은(2013년 출시) 소프트웨어이기도 하고, 언어와 기술에 보다 독립적이며, 위상으로도 OS가 아닌 애플리케이션이기에 Docker를 참고하는 편이 더 적합하다고 생각합니다.
한 가지 팁이라면 이 유형의 애플리케이션은 OS 독립적으로 만들수록 호응이 좋을 것입니다. 팀에서 소수로 작업하다 보면 팀 내에서만 통용되는 환경 설정을 사용해서 이해관계가 전혀 없는 기술 사용자가 정상적으로 실행하기 어려운 경우가 있습니다. 사실 아주 많습니다. 간단한 예시로 아래와 같이 OS에 의존하는 파일 경로를 참조하는 경우입니다.
# Python
filename = "~/example/file.txt" # 내 컴퓨터에서만 작동하는 파일 경로
filename = os.path.join('example', 'file.txt') # 환경에 보다 덜 의존하는 안전한 파일 경로기능이 많고 성숙한 소프트웨어는 생태계가 갖춰져 있으므로 여러 참고 자료가 설치나 실행 시의 난관을 보완해 주기도 합니다. 하지만 작고 귀여운 소프트웨어라면 알아서 해보라는 자세보다는 정성스럽게 밥상을 차려줄 필요가 있습니다. 예를 들어 Docker 설정 파일(Dockerfile)을 넣어주면 시작하기(Getting Started) 문서를 읽는 것보다 어떤 환경에서 실행 가능한지 더 쉽게 이해하는 개발자도 있습니다.
웹 기반 소프트웨어나 CLI 애플리케이션에서 재현성을 테스트하기 좋은 방법은 개발 환경과 다른 다양한 운영 체제나 환경 조합을 구성한 후 배포한 코드를 실행해 보는 것입니다. CI(Continuous Integration) 과정 중 하나로 다양한 환경의 테스트를 마련할 수도 있겠습니다. bash 스크립트나 makefile, 애플리케이션 코드에서 경로나 기본 요구 사항을 고려하지 않고 작성하는 경우도 많기 때문입니다.
최종 사용자가 있는 애플리케이션
지금까지 언급한 유틸리티나 API 애플리케이션 등은 오픈소스 개발자가 최종 사용자를 직접 상대하는 부담은 없었습니다. 하지만 최종 사용자가 분명히 존재하는 소프트웨어라면 이를 위해 추가로 고민할 필요가 있습니다. 오픈소스 개발자가 기술을 서비스에 도입하려는 기술 사용자와, 도입 후에 서비스로 사용하도록 제공할 최종 사용자를 모두 상대해야 하기 때문입니다.
예를 들어, 아래 ABC Studio에서 개발한 ABC User Feedback처럼 예쁜 웹 관리 화면을 기본 탑재해 제공하는 소프트웨어가 있습니다. ABC User Feedback의 경우 최종 사용자가 텍스트 필드에 입력한 의견을 API로 받아서 수집하는 웹 서버 프로그램이지만 의견을 모으고 태깅을 하는 관리 화면은 CS 센터나 운영 팀의 누군가를 위한 것입니다.
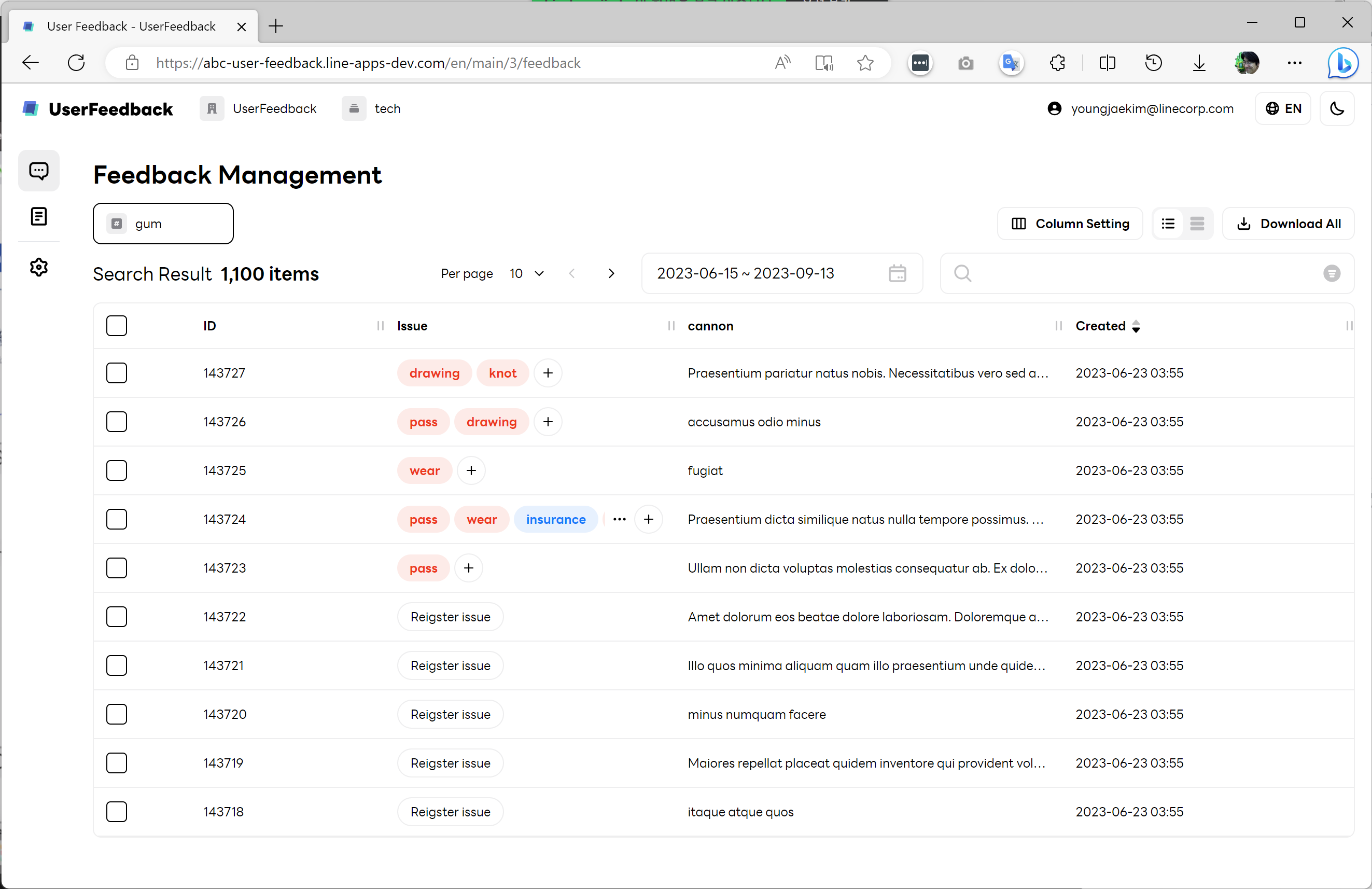
이와 같이 오픈소스 게시판, 블로그, 쇼핑몰이나 엔지니어가 주로 사용하는 Jenkins, Redmine 등의 프로그램은 설치하자마자 웹 브라우저에서 사용할 수 있는 관리 화면을 탑재하고 있으며, 이에 따라 최소한 아래 사항을 추가로 신경 써야 합니다.
- Profile - 시스템이 최종 사용자를 식별할 수 있다면(ID, 로그인 등) 이들이 사용하는 환경에 따른 시간대 표시, 언어, 각종 로케일 대응을 고려한 저장 공간이 필요합니다. 다국어 리소스 설정은 앞서 언급한 설정 경험과 마찬가지로 처음부터 구성할수록 좋습니다.
- UX - UX를 잘 만드는 것은 매우 어렵습니다. 나의 상식이 최종 사용자의 상식과 다른 경우가 많기 때문입니다. UX가 좋은 오픈소스 소프트웨어를 만들기 어려운 이유는 대체로 UX를 개선해도 수치적으로 향상을 확인할 수 있거나 명확한 피드백을 받기 어려워서 개선 동기 부여가 점점 줄어들기 때문입니다.
- Contact - 앞서 말했듯이 최종 사용자가 있는 소프트웨어이므로 최종 사용자의 의견을 들을 수 있는 연락처를 넣으면 좋습니다. 그들이 모두 GitHub 계정이 있다고 전제해서도 안되므로 이메일이나 Discord 링크 같은 보다 대중적인 접점을 마련하는 게 나은 선택일 수 있습니다.
최종 사용자까지 신경 써야 하는 것은 부담스러운 일이지만, 그만큼 사용자의 접점이 폭발적으로 늘어나고 입소문의 힘을 받을 가능성도 높습니다.
그 외에
소프트웨어는 위에 언급한 유형 외에도 펌웨어, 게임 엔진, AI/ML 모델 등 무척 다양하지만, 아쉽게도 이 글에서는 대표적인 유형만 일부 다뤘습니다. 그 외 유형에 대해서는 기존의 성숙한 프로젝트를 받아서 공부해 보면 큰 도움이 됩니다.
기존의 프로젝트를 볼 때는 현재의 구�조만 보는 것이 아니라 첫 번째 커밋부터 살펴보면 좋습니다. 중요한 변곡점마다 구조적으로 어떻게 달라졌고 왜 바꿨는지 개발자의 릴리스 노트를 읽어보며 앞서 언급했던 일관성, 확장성, 유지 보수성 맥락에서 이해해 보면 좋은 훈련이 될 것입니다.
번외 - 심심한 네이밍과 기술 브랜딩
네이밍은 소프트웨어의 방향에 적지 않은 영향을 미칩니다. 우리가 변수명 하나에 많은 고민을 하는 이유는 변수 하나로 그 책임과 역할이 정의되기 때문입니다. 마찬가지로 변수가 모여서 만들어진 소프트웨어 프로덕트도 그 이름으로 역할의 범위가 정해지기도 합니다.
오픈소스를 염두에 둘수록 저장소의 이름을 지을 때 명확한 목적만 적시해 만드는 노력이 필요합니다. 작업을 하다 보면 상상력이 무한히 펼쳐져서 우주선 하나쯤은 내 손으로 만들 수 있겠다는 자신감이 들 때도 있는데요. 그렇다고 저장소 이름을 Sputnik(러시아 우주선) 또는 Insight(미국의 화성 탐사선)라고 지으면 프로덕트도 방향을 잃을 수 있습니다.
네이밍을 할 때는 기능이 곧 이름이 되도록 하는 편이 좋습니다. 별난 이름을 붙이는 것은 기술 브랜딩이라고 할 수 있는데요. 그 가치는 기술로 설득력을 충분히 쌓은 후에야 제대로 전달될 수 있습니다. 쉽게 말해서 코드와 결과로 기술 사용자들에게도 의미를 주고 나서야 입에 오르내릴 수 있습니다. Armeria와 같이 유명한 저장소도 오랜 시간의 경험과 시행착오, Netty에 대한 신뢰가 쌓인 후에야 고유의 네이밍이 설득력을 얻었습니다.
그전까지는 기능에 충실한 이름을 짓는 것이 좋습니다. 예를 들어 데이터 변환 라이브러리라면 'convert'라는 단어를 넣거나, 메시징을 처리하는 라이브러리라면 'messaging'을 이름에 넣는 게 좋습니다. Kafka라거나 Zeppelin 등 통상의 Apache 라이브러리가 될 것이라는 기대를 성급히 품기보다는, 그저 개발 로드맵의 기능 하나하나를 만들어 가면서 저장소에서 정의한 문제를 완성도 높게 해결하는 소프트웨어를 만들어 간다고 생각하는 것이 결국 가장 빠른 브랜딩 방법입니다.
마치며
지금까지 오픈소스를 하나의 배포 방식으로 생각하며 개발할 때의 의미와 그에 적합한 구조, 그리고 소프트웨어의 유형별 체크 리스트를 알아봤습니다. 오픈소스는 단순히 코드를 공개한다는 의미 외에, 소프트웨어의 설계와 개발 전략의 핵심 요소가 될 수 있습니다. 실제로 코드를 오픈하든 하지 않든, 소프트웨어를 설계하고 개발하는 방법 중 하나로 의미 있게 활용되기를 바랍니다.
끝으로 본 글을 감수해 주신 Armeria와 Netty의 파운더 이희승(trustin) 님께 감사드립니다.


