こんにちは、出前館のプロダクトを担当しているヨンジェです。私は10余りのオープンソースプロジェクトをディレクションして開発し、チームで新しいソフトウェアを設計するときは、なるべくオープンソースへの移行可能性を念頭においています。今回の記事では、その過程で主にどのような点を強調しているかについて紹介します。
インターネットで見られるオープンソース関連記事のほとんどは、オープンソースの哲学について話したり、これから始める人向けにREADMEの書き方やライセンスの違いを説明したりするような記事が多いです。今回の記事では、ソフトウェアの構造や構成方法について説明したいと思います。また、オープンソース活動をする上で価値をおくべき部分とネーミングについても触れる予定です。また最初に書いておきますが、これはあくまで私の考えであり、絶対的な指針ではありません。
この記事では「技術ユーザー」という表現を多用します。これはソフトウェアのエンドユーザー(end-user)ではなく、オープンソースで公開した技術をインストールして運用するエンジニアまたは技術導入を検討する人を指します。
オープンソースで開発する際のマインドセット
自分が作ったソフトウェアを初めてオープンソースで公開するとき、その事実に胸を躍らせる人もいます。世の中に知識で貢献するという聖なる哲学でオープンソースの意味を説明する文章もたくさんあります。しかし、私は、ただ公開方法の一つとして軽く考える方がいいと思います。オープンソースでの開発に哲学的な意味を与えると、2つの副作用があるためです。
まず、きれいなコードにこだわりすぎてしまうことがあります。ソフトウェアは度重なる試行錯誤やデバッグ、実戦での障害を経験しながら成長していきます。とくに、運営中のサービスで使うソフトウェアほど、やむを得ない要件と制約によって望まない構造になったり、分岐が多くなったりします。
オープンソースで開発すると、このすべての欠点を見せたくないという気持ちが非常に強くなります。チームメンバーではなく、前後の事情を知らない誰にでも見られるコードに、自分も望まない構造や分岐を入れて説明することは、ほとんどの人が嫌がるでしょう。
しかし、オープンソース活動が単なる公開方法の一つと思えば、心が楽になります。また、きれいなコードにこだわりすぎると、他人のフィードバックに感謝したり、それを受け入れたりすることがなかなかできません。なお、そのフィードバックが自分の考えに合うかどうかにこだわりすぎて視野が狭くなることがありますが、これも単なる公開方法の一つだと思えば軽減できます。
次に、活動の意味がゆがむ可能性があります。オープンソースを広報手段として考え、SNSのいいねのような意味でStarの数だけを数えてしまうと、ソフトウェアの発展を追求するのではなく、大げさな目標だけで終わりになったり、話題のトピックを取り上げるだけでソフトウェア高度化への工夫に使うべき時間を無駄になります。
結局、力のあるソフトウェアとは、規模がどうであれ、オープンソースプロジェクトで紹介した機能を忠実に実現しながら、技術ユーザーが自分で導入して使いやすいソフトウェアのことです。さらに、着実にバグ修正を行い、依存関係のあるライブラリや環境に応じて更新して育てるソフトウェアのことでもあるでしょう。したがって、外部の数値を気にせず、作成したREADMEなどの解説文をどれだけ忠実に実装したか、どれだけユーザーの期待に応えるかという点に集中して開発していく必要があります。
オープンソースとして公開することのメリット
前述のように、私はオープンソース「活動」というより、オープンソースとしての「公開方法」と表現することが多いです。図で説明すると、下図の青いPublic Repositoryを中心に行われる開発と公開のプロセスに当たります。
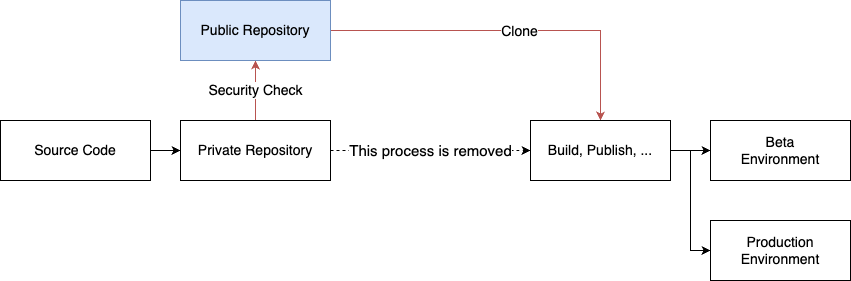
通常、会社で開発するソフトウェアは、上の図のPublic Repositoryのステップは必要ありません。では、このステップを入れることで得られるメリットは何でしょうか? オープンソースとして公開した場合に得られるメリットは下記のとおりです。
1. アーキテクチャの独立性を確保
私はこれを「環境に強制されるアーキテクチャ」と呼んでいます。オープンソースにすることで、ビジネスロジックとは明確に区別して開発することになり、複数の環境に依存するのではなく、できるだけ外部と緩く結合するようにします。たとえば、社内にはSMS送信サーバーがありますが、これを利用するシステムをオープンソースにすると、SMSサーバーのAPIアドレスをコードの中にハードコーディングするのではなく、環境変数で構成したり、インターフェースでラップしたり、あるいは別のライブラリにして注入したりするように構成した方がいいと考えられます。
2. オープンソースライセンスを採用して使用の自由度を高める
社員として会社のお金で開発したソフトウェアは会社の資産(asset)ですが、現在の当社は関係会社が100社以上の非常に複雑な資本関係を持っています。このような場合、公開したオープンソースにApacheのような寛容なライセンスを設定することで、法人間の複雑な資産取り扱い関係や利用可能性を検討する議論から一歩下がって、プロダクトの俊敏性を高められます。
3.初期からよりセキュリティに配慮
一般的な会社の非公開リポジトリ(private repository)には、秘密鍵(secret key)が入っているケースが多々あります。社内で構築したリポジトリをオープンソースで公開しようとしたら、コミット履歴の中にある秘密鍵によって個人情報が漏れてしまう事故が発生する問題は、毎月のように世界中から出ています。最初からオープンソースにすることを意識して開発すると、最初のコミットから環境変数ファイルを定義し、gitignoreファイルにそれを指定して最初からリスクを軽減できます。最初から公開するという条件で必ず守らなければならないようにすれば、環境変数の作成を面倒くさがる人を説得する手間も省けます。
オープンソースのメリットとしてよく言われる「自由な参加」は、付加的な意味だと思います。外部参加者が0人なら意味がないからです。外部からの自発的な参加を着実に引き出すのはかなり難しいことです。ですので、最初は誰も自分のリポジトリに興味がないと思って、ソフトウェア開発に集中した方がいいでしょう。
良いオープンソース構造を作る第一歩
前述で参加を期待しないようにと話しましたが、それでもオープンソースを運営しながら得られる最大の喜びは、技術ユーザーがいつの間にか意見を出す参加者になり、ひいてはコードに貢献する貢献者(contributor)へと自然に変化するという経験でしょう。一般的に良いソフトウェアを設計する方法とは、SOLID原則をきちんと守ろうという言葉で要約できます。この章では「もう少しお手入れしたいソフトウェア」にする方法についてお話しします。

左は多くの方が広く引用するRobert C. Martinのクリーンアーキテクチャ(Clean Architecture)の図です。中央にビジネスが位置しています。ソフトウェアは現�実の問題を解決することが存在理由なので、ソフトウェアが使われるビジネス状況が中央に位置するのは当たり前のように思えます。
しかし、オープンソースはビジネスとは独立して構成すればするほど汎用性を得るので、ビジネスロジックはできるだけ外側に押し出す方がいいでしょう。この点がオープンソースを意識したアーキテクチャの最大の違いだと言えます。そのため、中心には機能の集合がドライに配置されます。あまり関係なさそうな機能も「誰かの役に立つだろう」という感じです。
結果的に、オープンソースで公開するソフトウェアは、そのオープンソースが定義した問題を解決するための技術がどんどん中心に集まってきます。そのため、オープンソースを多くリリースする組織(organization)のリポジトリを見ると、ツールボックスのように見えることもあります。その代表例がNetflix OSSです。
これを踏まえて、オープンソースが発展する方向を上の図の右側のように3つの軸でまとめてみました。各軸は一貫性と拡張性、保守性をテーマに高度化されています。健全なソフトウェアは、この他にもさらに、テスト容易性、可用性、教育利便性など十数種類の品質属性を管理します。オープンソースを始めるとき、とくに意味のあるテーマとして一貫性と拡張性、保守性を挙げ、各属性の代表的な項目を例として説明します。
品質特性については、韓国語版は私が翻訳しましたが、Design It!―プログラマーのためのアーキテクティング入門(日本語版)の「5.2 品質特性を定義する」を参照してくだ��さい。
一貫性 - 明確な世界観の確立
世界観とは、このソフトウェアと技術を使うことで得られる価値と可能性だと言えます。技術ユーザーにとってどのような価値を得られ、どのようなサービスシナリオが可能かを想像させることです。優れたソフトウェアは、最初の一文で世界観を明確に定義しています。以下はいくつかの例で、すべてGitHubリポジトリのREADMEの最初の一文から抜粋したものです。
- デスクトップソフトウェアの例:
Microsoft PowerToys is a set of utilities for power users to tune and streamline their Windows experience for greater productivity.
- SDKの例:
Flutter is Google’s SDK for crafting beautiful, fast user experiences for mobile, web, and desktop from a single codebase.
- データベースの例:
OrientDB is an Open Source Multi-Model NoSQL DBMS with the support of Native Graphs, Documents, Full-Text search, Reactivity, Geo-Spatial and Object Oriented concepts.
これらを一文ずつ見てみると、一つのワードでも外したら方向性が揺らぐほど、注意深く書かれていることがわかります。このようにプロジェクトが目指す目的を明確に定義する必要があります。目的を立てれば、それによって必須機能が整理され、必須機能が整理された後は開発段階(phase)へ向かえます。
想像力が豊かすぎて、目的や機能、それに応じた順序を整理するのに非常に時間がかかり、苦労する方もしばしばいます。そのような場合は、私が旧LINE Engineeringブログに投稿したBANEXテンプレート - ビジネスから開発まですべてのステークホルダーの目線を合わせるプロダクトプランニング(韓国語)
ソフトウェアを開発していると、最初に定義した世界観とは関係のない機能が次第に追加されていきます。これは、リポジトリ単位で役割を再定義し、再設計する時期に来ていますが、それまでは、最小限の機能を集めて、それを明確に説明できる文章で世界観を定義することをおすすめします。
拡張性 - 参加のための外部インターフェース
技術ユーザーがリポジトリをクローンしても、ほとんどの場合、IDEで重要なコードを見るだけになるでしょう。しかし、その中でも好奇心旺盛な一部の技術ユーザーは、「ここで何かを少し修正すれば、自分が望むように使えるのだろうか?」と考える可能性があり、私たちはそれに対する答えを用意しておく必要があります。プロジェクトへ参加したいと思わせるには、信頼できるほど親切なドキュメントも必要ですが、それ以外にもプラグインやエクステンション、API、ウェブフックなど、拡張を意識したインターフェースを最初から検討することも重要です。
このとき、類似のソフトウェアをベンチマークする必要が出てくるかもしれません。似たような世界観のソフトウェアがどのような形で拡張性を提供しているかを研究し、自分のソフトウェアに将来の技術ユーザーが参加する余地を設計時から確保しておくことを考えてもいいでしょう。
拡張機能はソフトウェアの言語と技術によって異なります。たとえば、ウェブアプリケーションなら、Web APIに集中するのも一つの方法です。Web APIは通常、以下のような関係でデータをやりとりします。プログラムの役割に応じて、適切な外部システムとの通信方法を選択します。

最近のプログラム開発で重要なトレンドと言えば、最初から外部接続性を意識することです。これは、技術エコシステムを作る最初の作業だからでしょう。上の図で一番簡単にお試しできる方法は、2番のプッシュ方式だと思います。プログラムにURLを登録できるようにすることで、特定のイベントやスケジュールに応じてHTTPクライアントに送信するだけになるので、開発工数が少なく、プログラムの安定性にも影響が少なくなるでしょう。
保守性 - 設定ファイルで動作が読めるプログラム
オープンソースの第一印象はREADME文書で決まりますが、READMEの内容とは別に、どれだけ技術ユーザーが導入しやすく作ったのかも第一印象になり得ます。この観点から、オープンソースのソフトウェアを導入しようとする技術ユーザーにとって重要な最初の経験は大別すると2つあります。それは、インストールと設定の経験です。
インストールについては、たとえば、Node.jsパッケージを作った場合、npmの接続まで構成して技術ユーザーがインストールしやすいように配慮する必要があります。
設定の便宜を図るために推奨する開発方法の一つとして設定ファイルから��作る方法があります。最初からプログラムロジックをまったく作成せずに設定ファイルから作ってみると、新しいテキストファイルを作った後に任意の名前を定義して値を入れ、技術ユーザーにとって読みやすいか、今後の発展可能性はどのようなものがあるかを考えられます。
以下のコード例は、ある自動化スクリプトを実行するSlackボットサーバーのYAML設定ファイルです。このボットは、GitHubでPR(Pull Request)するときに発行されるウェブフックをサーバーが受け取ると、その内容を適切に加工してSlackに通知を送る役割をします。下記の設定ファイルを見るだけで、ある程度動作が予想できるでしょう。また、認証トークンが変わったり、呼び出すサーバーのURLが変わったりしても、プログラムを理解する必要がなく、次の誰か(未来の自分?)が対応できます。
github-pr-webhook-to-slack-notification:
github:
url: https://sample.github.com
username: sample-name
authtoken: sample-key
slack:
url: sample-webhook.slack.com
authtoken: sample-slack-key
template:
default: sample-template.txt設定ファイルから作るトレーニングには2つのメリットがあります。
- プログラムの寿命が長くなる
私が見た多くの会社の自動化スクリプトは外部設定の余地がまったくなく、すべての値がロジック内にハードコードされており、誰も怖くて触れないという問題がありました。実際、コードを書く物理的な時間は、設定ファイルがあってもなくても同じです。今はほとんどの言語において設定値を読み込んで変数化するコードを書くことがとても簡単になったためです。プログラ�ムは開発者の手を離れて永遠にどこかで動作し、活動できます。ですので、必然的にやってくるメンテナンスを念頭におき、設定機能をロジックと明確に分離して開発すれば、自分以外の誰かが設定を変えながら長く使えます。
- 拡張可能性を明確に示せる
設定ファイルから開発することで、「将来この部分だけ修正すれば簡単に対応できる」と考える余地が増えてきます。これにより、できるだけ設定ファイルのみで変更できるソフトウェア構造を開発でき、設定ファイルで変更可能な部分とそれ以外のコードを分離することでコアロジックの凝集度がより高くなります。上記のサンプルコードを見ると「template」という項目があります。おそらく、Slackメッセージの形式を複数にできると、技術ユーザーが推測できます。初期においてスクリプト機能が単純なときは一つのメッセージ表現で満足できますが、時間がたつにつれてユーザーが複数の表現方法を要求する求めてくることがあります。それに備えてあらかじめ設定ファイルに「template」項目を定義し、それによって構造を作っておけば、現時点では例のようにsample-template.txtファイルだけが存在していたとしても、後で手間をかけずに拡張できます。
ソフトウェア種類別構造
オープンソースは、必ずしも実行できるソフトウェアである必要はありません。HeadVerのバージョニングルールのような技術仕様書もオープンソースになり得ますし、Microsoft Docsのように変化の激しいクラウドサービスのマニュアルをGitHubで運�営するオープンソースも存在します。このように、最近ではオープンソースと言っても、そのオープンソースが必ずしもソースコードだけを意味するわけではない場合が多くなっています。ただし、このセクションでは機能のあるソフトウェアに焦点を当て、ソフトウェアの種類ごとに注意点や得られる経験について説明します。
ここでは、リポジトリやディレクトリを構造の単位として説明していますが、これらを美しく構成することがアーキテクチャであり設計方法であるとは言えません。アーキテクチャは物理的な概念の他に抽象的な概念もあり、物理的で抽象的な意味以外にもプロセス(作業順序、コラボレーションの仕方)の観点もあります。それでも、この記事で物理的なリポジトリの単位として説明する理由は、すべてのソフトウェアの構造や目標を問わず、物理的なリポジトリがオープンソースの技術ユーザーにとって、直感的に最初に認識され、扱われる単位だからです。

上の図でModuleは一つのクラスファイルだったり、ディレクトリだったり、リポジトリだったりします。ただ、共通の概念で集めた機能の集合を意味します。オープンソースプロジェクトが解決しようとする問題の定義と規模によって、上の構造のどれか一つの形であったり、高度化を経ていくつかのものが複合された形で構成されることもあります。抽象化(abstraction)は、ソフトウェア開発において美徳とされるため、最後の「拡張型」が究極の構造だと思うかもしれませんが、それだ��けが正解ではありません。簡単な機能まですべてインターフェースを宣言する必要はないためです。
自分が開発するソフトウェアの特性に応じて、最初から一つの構造を採用して育てていけば、全体的に大きく揺らがず、少しずつ成長していくソフトウェア開発を経験できます。これは、技術ユーザーがオープンソースに目を通すとき、より早く全体の構造を理解する手がかりになります。
では、いくつかのオープンソースの種類による注意点を紹介します。
ユーティリティーライブラリ
最も小さな公開単位のリポジトリです。代表的な例は、テキスト処理や時間換算のライブラリがあります。
外部依存性がほとんどない関数の集まりに近いライブラリの場合、単体テストの実装を練習する目的で試してみてもいいでしょう。ABC Studioの場合、KMP(Kotlin Multiplatform)ベースの開発において、iOSとAndroidで共通して使ういくつかの機能を軽く統合インターフェースにパッケージ化し、リリースしたこともあります。
- abc-kmm-h3:H3 geo-indexライブラリ
- abc-kmm-analytics-tools:開発に便利なイベント、ログトラッカー
- abc-kmm-shared-storage:ローカルストレージ管理統合インターフェース
- abc-kmm-location:位置権限と情報管理統合インターフェース
- abc-kmm-notifications:プッシュ通知管理統合インターフェース
一つのライブラリをオープンソースで公開する場合のメリットは、メンテナンスが難しくないという点です。難しくないように機能と構造を定義しないと開発者自身が不便になるので、仕方なくできるだけ一般化して作ります。きちんと構成したライブラリほど、機能定義による入力と期待する動作や出力が明確なので、追加機能を開発する作業以外は外部依存関係をまれに更新するだけです。
いくつかの関数が集まったユーティリティーの場合、だいたい一体型で構成することが多くなります。このような種類の中で参考になる程の歴史があり、大規模なプロジェクトとしてApache Commons Textライブラリがあります。
データに依存するライブラリ
ライブラリはソフトウェアのある部分をまとめたパッケージに過ぎませんが、複雑な役割を担うように開発すると限りなく複雑になります。ソフトウェアの複雑さは、そのソフトウェアが扱うデータの複雑さにある程度比例します。データベースに直接アクセスして処理したり、データを一時的に保存したりする必要があるライブラリの場合、前述のユーティリティーよりもはるかに広い観点で検討する必要があります。
データやデータベースを扱う時点で、以下の項目をチェックする必要があります。
- 個人情報を扱うかどうか
- ハッシュ化(hashing)などの難読化が必要かどうか
- サポートするデータベースの要件
- 監査(audit)対応:アクセス権限、整合性チェック、データ保存期間の設定などのサポート
- バックアップと復元のサポート
私が経験した試行錯誤をいくつか紹介します。
まず、データベースの要件の場合、小規模で作業するときは多くのデータベースでテストすることが難しいため、仕方なく開発環境のデータベース一つか二つしかテストができないと思います。このような場合は、READMEにてテスト済みのデータベースと仕様上サポート可能なデータベースを分けて説明する必要があります。
データ保存期間や整合性チェック、バックアップと復元は、商用ソフトウェアのレベルで完璧に実装することは難しくても、サポートする程度には考慮した方がいいでしょう。ここでサポートするという意味は、たとえば、データベースのレコードをデータベース(以下DB)管理者が任意に削除すると、データ整合性をチェックするロジックで適切な例外を発生させるといった程度を意味します。
バックアップと復元の場合も、特定の固有値が復元後に合わず、正常に実行されない問題が発生することがあります。DBを初めて作成するときのタイムスタンプを暗号化のハッシュシード(hash seed)として設定した場合、細かい認証に失敗することもあります。したがって、データベースはライブラリ内のロジックではなく、外部からも勝手に修正されたり変更されたりする可能性があるという前提でテストする必要があります。
APIまたはCLIアプリケーション
この記事では、独立して実行できるソフトウェアをアプリケーションと定義します。したがって、API(Application Programming Interface)またはCLI(Command Line Interface)アプリケーションは、視覚化したUIはありませんが、コ�マンドと応答の形がUIであるソフトウェアです。では、これらの最も一般的なUIは何でしょうか。たとえば、HTTPでリクエストしたリソースがない場合の応答コードとして200、403、404、410のうち、どれがより一般的でしょうか。この場合は、だいたいGitHub.com APIをこの時代の最も一般的なAPI設計だとみなして参考にするといいでしょう。ここで一般的というのは正解という意味ではなく、現代において違和感なく機能しているという意味です。
CLIについては、Dockerのコマンドとその応答を参考にしてみてください。Linuxの基本コマンドは、コマンドによる応答がまったくなく、不親切な場合もあります。Dockerは比較的若い(2013年リリース)ソフトウェアであり、言語や技術にあまり依存せず、OSではなくアプリケーションなので、Dockerの方が参考になるかと思います。
一つのヒントとして、このタイプのアプリケーションはOSに依存しない方が反応が良いでしょう。チームで少人数で作業していると、チーム内でのみ通用する環境設定を使用し、利害関係のない技術ユーザーが正常に実行することが難しい場合もあります。実はとても多いのです。簡単な例として、下記のようにOSに依存するファイルパスを参照する場合があります。
# Python
filename = "~/example/file.txt" # マイコンピューターでしか動作しないファイルパス
filename = os.path.join('example', 'file.txt') # 環境に依存しない安全なファイルパス機能が豊富で成熟したソフトウェアはエコシステムが整っているので、多くの参考資料がインストールや実行時の難関を補完してくれることもあります。しかし、規模の小さいソフトウェアなら、ご自分でというより、丁寧に食事を用意してあげるようにする必要があります。たとえば、Dockerの設定ファイル(Dockerfile)をおいた方が、「はじめに」(Getting Started)のドキュメントを読むよりも、どのような環境で実行可能なのかすぐに理解できる開発者もいます。
ウェブベースのソフトウェアやCLIアプリケーションで再現性をテストする良い方法は、開発環境とは異なるさまざまなオペレーティングシステムや環境の組み合わせを構成し、デプロイしたコードを実行してみることです。CI(Continuous Integration)プロセスの一貫として異なる環境のテストを用意できます。bashスクリプトやmakefile、アプリケーションコードでパスや基本的な要件を考慮せずに作成する場合も多いからです。
エンドユーザーが存在するアプリケーション
これまで話してきたユーティリティーやAPIアプリケーションなどは、オープンソース開発者がエンドユーザーを直接相手にする負担はありません。しかし、エンドユーザーが明確に存在するソフトウェアについては、さらに配慮が必要です。オープンソース開発者が、技術をサービスに導入しようとする技術ユーザーと、導入後にサービスとして使用するエンドユーザーの両方を相手にしなければならないためです。
たとえば、以下のABC Studioで開発した ABC User Feedbackのようにきれいなウェブ管理画面を搭載して提供するソフトウェアがあります。ABC User Feedbackの場合、エンドユーザーがテキストフィールドに入力した意見をAPIで受け取って収集するウェブサーバープログラムですが、意見を集めてタグ付けを行う管理画面はCSセンターや運営チームの誰かのためのものです。
このようにオープンソースの掲示板、ブログ、ショッピングモールやエンジニアが主に使用するJenkins、Redmineなどのプログラムは、インストールするとすぐにウェブブラウザで利用可能な管理画面が搭載されており、そのため、少なくとも下記についてさらに考慮する必要があります。
- Profile - システムがエンドユーザーを識別できる場合(ID、ログインなど)、エンドユーザーが使う環境による時間帯表示、言語、各種ロケール対応を考慮した保存スペースが必要です。多言語リソースの設定は、前述の設定経験と同様に、初期から構成するといいでしょう。
- UX - 良いUXを作るのはとても難しいです。開発者の常識がエンドユーザーの常識と異なる場合が多いからです。良いUXのオープンソースソフトウェアを作るのが難しい理由は、多くの場合、UXを改善しても数値的に改善を確認することや明確なフィードバックを得ることがなかなかできず、改善のモチベーションがどんどん下がっていくためです。
- Contact - 前述のように、エンドユーザーが存在するソフトウェアなので、エンドユーザーの意見を聞ける連絡先を入れるといいでしょう。エンドユーザー全員がGitHubアカウントを持っているとは限らないので、メールやDiscordリンクのような、より一般的な接点を設ける方が良い選択になるかもしれません。
エンドユーザーまで配慮するのは面倒ですが、それだけユーザーとの接点が爆発的に増え、口コミ効果が期待できる可能性も高くなります。
その他
ソフトウェアは上記以外にもファームウェア、ゲームエンジン、AI/MLモデルなど非常に多様ですが、残念ながらこの記事では代表的な一部だけをいくつか紹介しました。その他については、既存の成熟したプロジェクトを参考にして勉強すると大きく役立つと思います。
既存のプロジェクトを見るときは、現時点の構造だけではなく、最初のコミットから見ていくといいでしょう。重要な変曲点ごとに構造がどう変わったのか、なぜ変わったのかについて開発者のリリースノートを読みながら、前述の一貫性、拡張性、保守性の面で理解してみると良いトレーニングになると思います。
番外編 - 地味なネーミングと技術ブランディング
ネーミングはソフトウェアの方向性に少なからず影響を与えます。私たちが変数名一つに多くの悩みを抱える理由は、変数一つにその責任と役割が定義されるためです。同様に、変数が集まって作られたソフトウェアプロダクトもその名前で役割の範囲が決まることもあります。
オープンソースを念頭においている場合は、リポジトリの名前をつける際に明確な目的だけをかいつまんで示す努力が必要です。作業をしていると想像力が無限に広がり、宇宙船一機ぐらいは自分の手で作れるという自信がつくこともありますが、だから��といってリポジトリの名前にSputnik(ロシアの宇宙船)やInsight(アメリカの火星探査機)とつけるとプロダクトも方向性を失ってしまう可能性があります。
ネーミングをするときは、機能がそのまま名前になるようにした方がいいでしょう。変わった名前をつけるのは技術ブランディングとも言えますが、その価値は技術で十分な説得力を持ってからでないと、うまく伝わることはありません。簡単に言えば、コードと結果で技術ユーザーにも意味を与えてからでないと話題にもならないでしょう。Armeriaのような有名なリポジトリも長い時間の経験と試行錯誤、Nettyに対する信頼が積み重なって初めて固有のネーミングが説得力を得られ、技術ユーザーにも価値を得られました。
それまでは、機能に基づいた名前をつけることをお勧めします。たとえば、データ変換ライブラリなら「convert」という言葉を入れたり、メッセージングを処理するライブラリなら「messaging」を名前に入れたりする方がいいでしょう。Apache KafkaやZeppelinなど通常のApacheライブラリになることを最初から期待するのではなく、開発ロードマップの機能一つひとつを作りながら、リポジトリで定義した問題を完成度高く解決するソフトウェアを作っていくという考え方が、結局一番早いブランディング方法です。
おわりに
これまで、オープンソースを一つの公開方法として捉えて開発することの意味とそれに適した構造、そしてソフトウェアの種類ごとのチェックリストを紹介しました。オープンソースは単にコードを公開するという意味以外に、ソフトウェアの設計や開発戦略の重要な要素となります。実際にコードをオープンにするかどうかにかかわらず、ソフトウェアを設計・開発する方法の一つとして有意義に活用されることを願っています。
最後に、この記事を監修していただきましたArmeriaとNettyの創設者であるイ・ヒスン(Trustin Lee)さんに感謝申し上げます。
