안녕하세요. 2024년 4월에 신입 사원으로 LY Corporation에 입사한 Inoue Shuichi입니다. 현재 사내용 Kubernetes as a Service인 FKE 팀에서 개발 업무를 담당하고 있고, Orchestration 길드 멤버로 활동하고 있습니다.
Orchestration Development Workshop은 CTO가 선발한 엔지니어가 모여 현장에서 AI를 더욱 적극적으로 활용할 수 있는 실무 지식을 전사적으로 공유하는 커뮤니티입니다(참고). Orchestration 길드는 워크숍에서 다룰 주제 제안, 바로 적용할 수 있는 실무 사례 공유, 기술 관점에서 품질을 높이기 위한 조언 등을 담당하면서 Orchestration Development Workshop 콘텐츠가 개인에 의존하지 않고 지속적으로 발전할 수 있도록 지원하는 역할을 맡고 있습니다.
이 글에서는 Orchestration Development Workshop에서 개최한 ‘ADK로 배우는 컨텍스트 엔지니어링 실습‘ 워크숍 내용을 소개합니다. 먼저 발행한 ODW #2: ADK로 싱글/멀티 에이전트를 개발해 사내 시스템과 통합에서는 ADK를 사용한 싱글/멀티 에이전트 개발과 사내 시스템 통합을 주제로 다뤘는데요. 이번에는 AI 에이전트 사용 비용을 줄이고 정확도를 개선하기 위한 컨텍스트 엔지니어링에 초점을 맞춥니다.
사내 AI 활용이 활성화되면서 나타난 문제
Orchestration Development Workshop 워크숍이 진행되면서 사내에서 Claude Code나 Cline, ADK 등의 AI 도구를 활용하는 사람이 점점 늘어나고 있습니다. 이와 같이 활용 인원 및 범위가 확대되면서 다음과 같은 문제가 드러나기 시작했습니다.
- 비용 급증: AI 도구 활용이 확대되면서 토큰 소비량이 예상보다 크게 증가
- 기대한 출력이 나오지 않음: 프롬프트에 지시를 적었음에도 AI가 이를 무시하거나 중요한 정보가 누락됨
- 대화가 길어지면 정확도 저하: 장시간 대화하면 갑자기 엉뚱한 답변을 하기 시작함
이런 문제가 발생하는 주요 공통 원인 중 하나는 LLM에 전달되는 컨텍스트(문맥 정보)를 적절하게 관리하지 않기 때문입니다.
토큰 소비량이 증가한 배경
토큰 소비량이 증가하는 주요 요인은 다음과 같습니다.
- 생성형 AI 사용 인구 증가: 사내 AI 활용 확대에 따라 사용자 증가
- 시행 착오: 원하는 결과를 얻기 위해 반복하는 과정에서 토큰 소비
- AI 에이전트 역할 확대: 싱글 에이전트에서 멀티 에이전트로, 단발성 작업에서 장시간 실행하는 복잡한 작업으로 확장되면서 컨텍스트 양이 크게 증가
- MCP와 같은 도구 연동: 도구 정의 자체가 컨텍스트를 차지
- 컨텍스트 엔지니어링 확산 부족: 최적화 기법이 아직 충분히 확산되지 않음
이번 워크숍에서는 이와 같은 문제를 개선할 수 있는 체계적인 접근 방법인 컨텍스트 엔지니어링을 소개하고 ADK를 이용해 실무에 적용할 수 있는 방법을 공유했습니다.
컨텍스트 엔지니어링이란
컨텍스트 엔지니어링�을 이해하려면 먼저 아래 세 가지 기본 개념을 짚고 넘어가야 합니다.
| 개념 | 설명 | 쉬운 설명 |
|---|---|---|
| 토큰 | LLM이 문장을 이해하고 생성할 때 내부에서 취급하는 텍스트의 최소 단위 | 한 글자나 한 단어 같은 것 |
| 컨텍스트 | LLM에 전달하는 정보 | 대화의 내용 |
| 컨텍스트 윈도(context window) | 한 번에 처리할 수 있는 토큰 한도 | 대화를 담는 ‘그릇’의 크기 |
GPT-5와 같은 LLM 모델은 1M 토큰 단위로 과금되며 이때 기준은 입력 및 출력의 총 토큰 수입니다. 토큰 수를 의식하지 않고 사용하면 자기도 모르게 많은 토큰을 사용해 큰 비용이 청구될 위험이 있습니다.
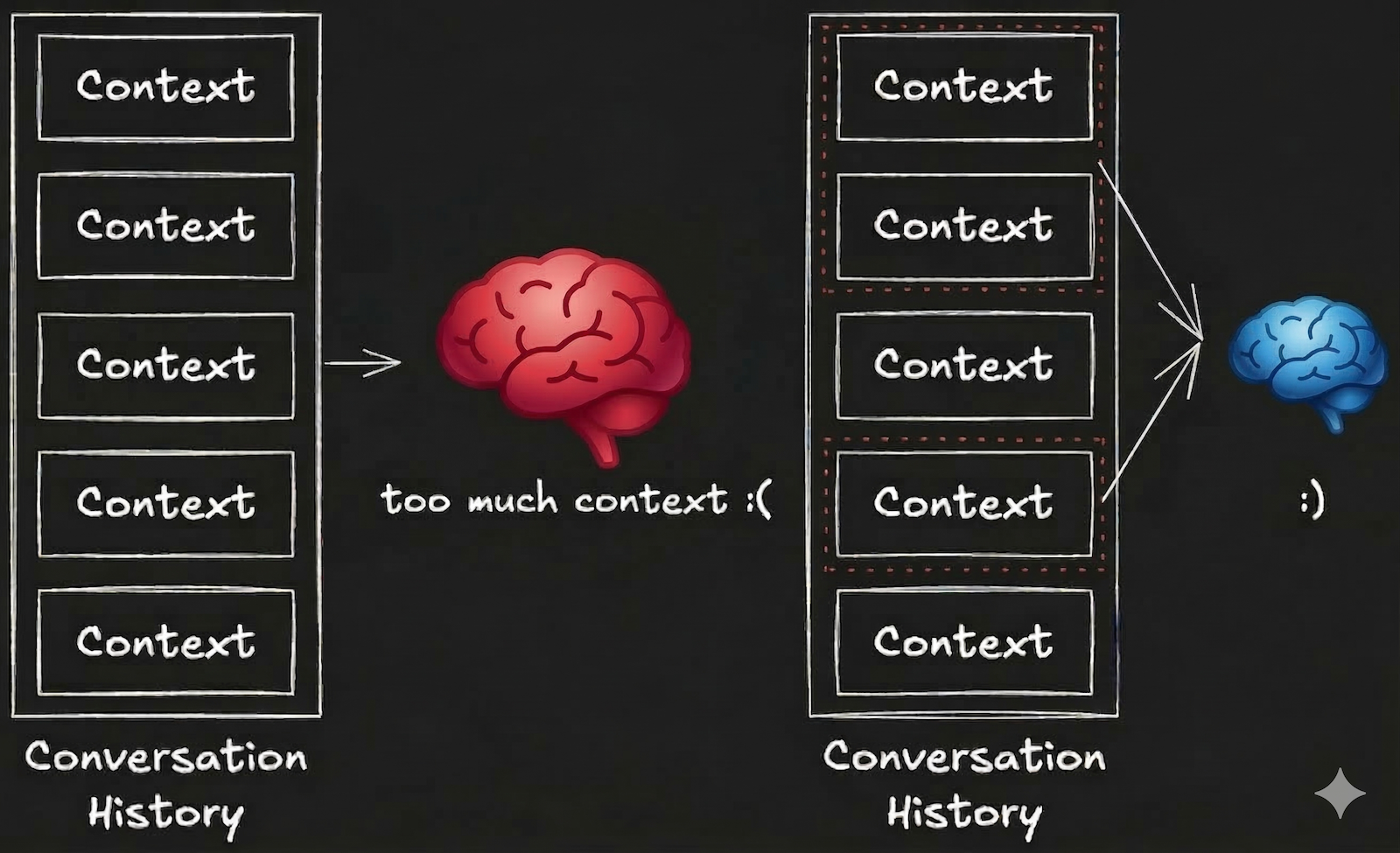
컨텍스트 부패(context rot)
장시간 실행하는 에이전트에서는 컨텍스트 품질이 저하되는 ‘컨텍스트 부패’라는 현상이 발생합니다.
- 정보 축적: 대화 이력과 중간 결과가 계속 쌓이며 컨텍스트 윈도 압박
- 관련성 저하: 현재 작업과 무관한 이전에 쌓인 정보가 컨텍스트에 계속 남아 있음
- 신호 대 잡음비 악화: 중요한 정보가 노이즈에 묻혀 AI 판단 정확도 저하
‘프롬프트에 적혀 있는데 AI가 무시한다�’, ‘대화가 길어지면 갑자기 이상한 답변을 한다’와 같은 증상의 상당수는 컨텍스트 부패가 원인입니다. 해결 방법은 단순합니다. 필요한 컨텍스트만 LLM에 전달하면 됩니다.
컨텍스트 엔지니어링의 정의
AI 에이전트가 다루는 컨텍스트(프롬프트, 도구, 외부 데이터, 메시지 이력 등)를 적절하게 설계·관리하는 최적화 기법
구체적으로는 추론(inference) 시 모델에 전달하는 모든 정보를 전략적으로 선별하고 관리합니다. 관리 대상은 다음과 같이 세 종류로 나눌 수 있습니다.
- 정적 컨텍스트: 시스템 프롬프트, 도구 정의
- 동적 컨텍스트: 사용자 메시지, 대화 이력, RAG로 가져온 외부 데이터
- 장기 컨텍스트: 장시간 실행 중 축적되는 정보, 세션 상태
컨텍스트 엔지니어링의 핵심 원칙
컨텍스트 엔지니어링에는 Anthropic 기사를 참고한 두 가지 핵심 원칙이 있습니다.
원칙 1: 토큰은 유한한 자원
"Find the smallest set of high-signal tokens"(최소한의 고품질 토큰 집합을 찾아라)
컨텍스트 윈도에는 한계가 있으며, 비용은 토큰 수에 비례해 증가하고, 불필요한 정보는 정확도를 떨어뜨립니다.
원칙 2: 너무 많지도 너무 적지도 않게, 딱 적절하게
너무 추상화하면 정보 부족으로 AI가 추측에 의존하기 때문에 정확도가 떨어집니다. 반대로 너무 구체적이면 지나치게 상세해져 토큰을 낭비해 비용이 증가할 수 있습니다. 작업에 필요한 정보만 적절한 수준으로 제공하는 것이 가장 이상적입니다.
프롬프트 엔지니어링과 컨텍스트 엔지니어링의 차이
| 관점 | 프롬프트 엔지니어링 | 컨텍스트 엔지니어링 |
|---|---|---|
| 정의 | AI에게 무엇을 할지 지시하는 기술 | AI가 최대 성능을 발휘할 수 있도록 기억과 환경을 설계·관리하는 기술 |
| 범위 | 프롬프트 설계에 집중 | 프롬프트 + 도구 + 데이터 + 기록 |
| 적용 사례 | 단발성 작업, 간단한 분류 및 생성 | 여러 번 오가는(multi turn) 대화, 복잡한 작업, 장시간 실행하는 에이전트 |
| 최적화 대상 | 지시의 명확성, 출력 품질 | 토큰 효율, 비용, 확장성 |
ADK로 실현하는 컨텍스트 엔지니어링
ADK는 Google에서 제공하는 AI 에이전트 구축용 오픈소스입니다. ADK를 이용해 컨텍스트 엔지니어링을 배우는 이유는 다음과 같습니다.
- 팀 단위로 확산하기 쉬움: 개인용 AI CLI 도구는 숙련도에 따라 성과 차이가 크지만 ADK는 팀의 집단 지식으로 에이전트를 설계해 공유할 수 있음
- 풍부한 기능: 내장 UI, API 서버, 평가 기법은 물론 멀티 에이전트 시스템 구축 기능도 잘 갖추고 있음
- 컨텍스트 엔지니어링을 적용하기 쉬움: ADK의 멀티 에이전트 아키텍처가 컨텍스트 엔지니어링과 밀접하게 연결됨
9개의 키 컴포넌트 소개
ADK에는 컨텍스트 엔지니어링을 실현하기 위한 9개의 키 컴포넌트가 있습니다. 먼저 실습에서 사용할 세 가지 컴포넌트를 소개하고, 이후 나머지 6개를 표로 정리해 보겠습니다.
실습에서 사용하는 세 가지 키 컴포넌트
- Structuring Data: LLM 입출력을 특정 JSON 형식으로 강제하는 기능
- 에이전트 처리 효율을 높일 수 있도록 데이터를 구조화
- 불필요한 텍스트를 제거해 토큰 사용 절감
- AgentTool: 다른 AI 에이전트를 도구(함수) 형태로 에이전트 내부에서 사용할 수 있는 기능

- AgentTool 내부의 툴과 컨텍스트는 호출자에게 노출하지 않고 최종 출력만 반환
- 중간 데이터 축적을 방지해 컨텍스트 소비 억제
- MCP Toolset: ADK에서 MCP와 연동하는 방법으로, MCP 서버가 제공하는 도구 중 필요한 것만 필터링해 에이전트에 제공 가능
tool\_filter파라미터를 이용해 허용할 도구 이름을 목록 형식으로 지정- 불필요한 도구 정의를 제거해 토큰 사용을 줄이고 LLM 판단 정확도 향상
그 외 6개 키 컴포넌트
| 기법 | 설명 | 주요 효과 |
|---|---|---|
| State | 세션 전용 키-값 저장소. 에이전트가 정보를 읽고 쓰며 다른 에이전트와 공유 가능 | 전체 대화 이력을 컨텍스트에 넣지 않아도 돼 컨텍스트 부패 방지 |
| include_contents | LLM에 대화 이력 전달 여부를 default/none으로 제어 | 독립 작업 에이전트에서 이력을 생략해 토큰 절감 |
| Context Filter Plugin | 대화 이력을 동적으로 필터링(최근 N회만 유지) | 오래된 정보 자동 삭제 및 토큰 예산 관리 |
| Callbacks | 에이전트 및 도구 실행 전후에 임의 처리 삽입 | 불필요한 LLM 호출 스킵, 입력 검증 및 출력 후처리 |
| Sub-agents | 부모 에이전트 아래에 자식 에이전트 배치해 계층 구조 구성 | 각 에이전트가 최소한의 컨텍스트만 유지해 전체 컨텍스트 양 감소 |
| Workflow Agents | 연속적/반복/병렬 패턴으로 서브 에이전트 실행 흐름 제어 | LLM에 의존하지 않는 결정론적 실행으로 흐름 제어용 컨텍스트 소비 대폭 절감 |
9개의 키 컴포넌트를 정리하면 다음과 같습니다. 이들을 잘 조합해 사용하면 컨텍스트 엔지니어링을 효과적으로 구현할 수 있습니다.
| 레이어 | 기법 | 주요 효과 |
|---|---|---|
| 데이터 | State, Structuring Data | 정보를 효율적으로 보존하고 구조화 |
| 컨텍스트 최적화 | include_contents, Context Filter, Callbacks | 불필요한 정보 배제 및 압축 |
| 아키텍처 | AgentTool, MCP Toolset, Sub-agents, Workflow Agents | 책임을 분리해 컨텍스트 분리 |
실습: 팀의 Jira 티켓을 분석해 주간 보고서를 자동 생성하는 AI 에이전트 만들기
워크숍에서는 팀의 Jira 티켓을 분석해 주간 보고서를 자동 생성하는 AI 에이전트, 'jira_weekly_report'를 만들어 보며 컨텍스트 엔지니어링 효과를 함께 체감해 봤습니다.
v1: 컨텍스트 엔지니어링을 생각하지 않고 구현
v1은 간단하게 단일 에이전트로 구성하는 것입니다.

root_agent = LlmAgent(
name="jira_weekly_report_v1",
description="Reviews team Jira tickets and generates a report.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
instruction=f"""
## Your Role:
You are an excellent project manager. Your mission is to analyze
the team's Jira tickets and create a report.
Please execute the task following these steps:
1. Access {os.getenv("JIRA_URL")} to retrieve the list of Jira tickets.
2. From the retrieved Jira ticket list, select the first one and get its details.
3. Create a Report from the detailed content.
4. Add to the Jira report as a Markdown-formatted table.
5. Repeat the above steps for all Jira tickets.
6. Output the final Jira report.
""",
tools=[
MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="npx",
args=["@<internal-registry>/flava-mcp-connector@latest", "..."],
),
),
)
],
)
컨텍스트 엔지니어링을 생각하지 않고 구현한 v1의 특징과 문제는 다음과 같습니다.
| 특징 | 문제 |
|---|---|
| 모든 MCP 도구가 컨텍스트에 포함 | 불필요한 도구 정의로 토큰 소비 |
| 전체 작업을 한 에이전트가 처리 | 컨텍스트 윈도에 모든 정보가 축적됨 |
| 출력이 구조화되지 않음 | 불필요한 텍스트가 포함될 수 있음 |
위와 같은 특성 때문에 v1에서는 티켓 수가 증가하면 각 티켓의 세부 사항이 컨텍스트에 축적되면서 컨텍스트 부패가 발생합니다.
v2: 컨텍스트 엔지니어링을 적용해 구현
v2에서는 세 가지 컨텍스트 엔지니어링 기법 ( tool_filter, AgentTool, input_schema/output_schema)을 결합한 2-에이전트 구성으로 변경했습니다.
from pydantic import BaseModel, Field
from google.adk.tools.agent_tool import AgentTool
class InputSchema(BaseModel):
issue_key: str
class OutputSchema(BaseModel):
report: str = Field(
...,
description="Summary report of ticket content and progress status "
"(including comments in the ticket)",
)
# Sub-agent: 개별 티켓 분석 전용
single_ticket_analysis_agent = LlmAgent(
name="single_ticket_analysis_agent",
description="Analyzes a single Jira ticket and returns structured results.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
input_schema=InputSchema, # 구조화 입력
output_schema=OutputSchema, # 구조화 출력
instruction="""
## Your Role:
1. Use the given Jira ticket key to retrieve the Jira ticket details.
2. Create a report from the detailed content.
**Only include facts. Speculation is prohibited.**
""",
tools=[
MCPToolset(
tool_filter=["jira_get_issue"], # 필요한 도구만
connection_params=StdioConnectionParams(...),
)
],
)
# Root agent: 티켓 목록 조회 및 리포트 집계
root_agent = LlmAgent(
name="jira_weekly_report_v2",
description="Reviews team Jira tickets and generates a report.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
instruction=f"""
## Your Role:
You are an excellent project manager.
1. Access {os.getenv("JIRA_URL")} to retrieve the list of Jira tickets.
2. Pass all retrieved Jira tickets to single_ticket_analysis_agent to get reports.
3. Create the Jira report as a Markdown-formatted table.
""",
tools=[
AgentTool(single_ticket_analysis_agent), # Sub-agent를 도구로 내장
MCPToolset(
tool_filter=["jira_search"], # 필요한 도구만
connection_params=StdioConnectionParams(...),
),
],
)
v2에 적용한 컨텍스트 엔지니어링 기법은 다음과 같습니다.
| 관점 | v1 | v2 |
|---|---|---|
| 에이전트 수 | 1 | 2 |
| 도구 필터 | 없음(모든 도구 사용 가능) | 있음(필요한 도구만 사용) |
| 출력 구조화 | 없음 | 있음(Pydantic 스키마) |
| 컨텍스트 분리 | 없음(모든 정보가 하나의 컨텍스트) | 있음(역할별 분리) |
v1과 v2의 토큰 소비량 및 비용 비교 측정
컨텍스트 엔지니어링의 효과를 정량적으로 측정하기 위해 after\_model\_callback을 이용한 커스텀 플러그인으로 토큰 소비량을 측정했습니다. 다음은 코드 일부를 발췌해 온 것입니다.
class TokenTrackingPlugin(BasePlugin):
async def after_model_callback(
self,
*,
callback_context: CallbackContext,
llm_response: LlmResponse,
) -> Optional[LlmResponse]:
entry = TokenUsageEntry(
agent_name=callback_context.agent_name,
total_token_count=llm_response.usage_metadata.total_token_count,
used_context_window=llm_response.usage_metadata.total_token_count
/ self.max_tokens,
used_context_window_percent=f"{llm_response.usage_metadata.total_token_count
/ self.max_tokens:.2%}",
token_usage_for_entire_system=token_usage_for_entire_system,
)
self.TOTAL_TOKENS.append(entry)
실습에서는 ADK LLM 모델로 GPT-5를 사용했습니다. 이에 따라 컨텍스트 윈도 사용률은 total\_token\_count / 400000로 계산했습니다(참고).
다음은 같은 Jira 티켓(2026.01.26~02.01 간 FKE 팀의 Jira 티켓)을 동일한 입력 프롬프트로 처리하는 실험을 v1과 v2로 각각 10번 테스트해 본 결과입니다.
| 평가 항목 | v1 | v2 |
|---|---|---|
| 컨텍스트 윈도 평균 사용률(root_agent) | 33.49% | 7.46% |
| 전체 시스템의 평균 총 토큰 소비 | 174,643 토큰 | 103,583 토큰 |
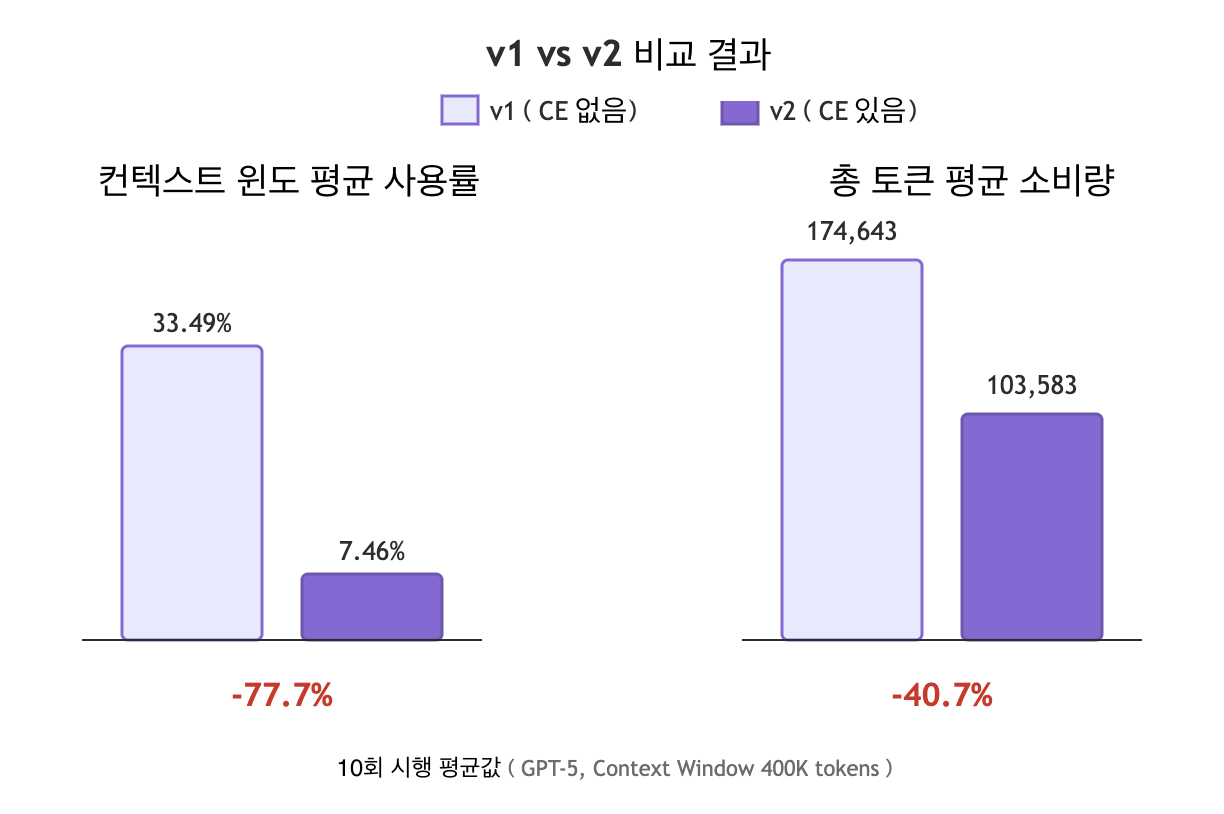
v2는 v1과 비교해 컨텍스트 윈도 평균 사용률을 26.03포인트 줄였고(삭감률 77.7%), 총 토큰 소비량을 40.7% 줄였습니다. 코드만 보면 큰 변화가 아니었지만 tool_filter, AgentTool, 스키마 구조화, 이 세 가지 기술을 결합하는 것만으로 상당한 토큰을 줄일 수 있었습니다.
이 효과를 조직 규모에서 비용으로 살펴보면 다음과 같습니다(월 4회 * 12개월 = 연 48회/팀).
| 모델 | 규모 | v1 | v2 | 연간 감축액 |
|---|---|---|---|---|
| gpt-5-mini | 1회당 | ¥14 | ¥8 | ¥6 |
| 100팀(연 4,800회) | ¥6.7만 | ¥4.0만 | ¥2.7만 | |
| 1,000팀(연 48,000회) | ¥67만 | ¥40만 | ¥27만 | |
| gpt-5 | 1회당 | ¥69 | ¥41 | ¥28 |
| 100팀(연 4,800회) | ¥33만 | ¥20만 | ¥14만 | |
| 1,000팀(연 48,000회) | ¥333만 | ¥197만 | ¥136만 |
- 요금 기준(참고: OpenAI Pricing)
- gpt-5-mini: 1M 토큰당 입력 0.25, 출력 2.00
- gpt-5: 1M 토큰당 입력 1.25, 출력 10.00
- 입력:출력=85:15 기준, $1=¥155 환율 적용
1회당 비용 차이는 작아 보이지만 조직 규모로 확대해 보면 무시할 수 없는 금액이 됩니다. 컨텍스트 엔지니어링을 조직 단위로 교육하고 확산해 나가면 정확도도 올라가고 비용도 절감할 수 있습니다.
Claude Code에서 컨텍스트 엔지니어링
ADK에서 배운 컨텍스트 엔지니어링 개념은 Claude Code에도 그대로 적용할 수 있습니다. 개념은 동일하고 구현 방식만 도구마다 다릅니다.
ADK와 Claude Code의 대응 관계
| ADK 기법 | ADK 기법에 대응하는 Claude Code 기능 | 컨텍스트 엔지니어링 효과 |
|---|---|---|
| State | CLAUDE.md | 영구 컨텍스트 관리 |
| include_contents | /clear | 이력 리셋 |
| Tool Filter | 스킬, MCP 도구 검색 | 필요한 것만 로드 |
| Sub-agents | 서브 에이전트/태스크 | 컨텍스트 분리 |
| Context Filter | /compact | 이력 압축 및 제어 |
| Callbacks | Hooks | 수명 주기 제어 |
Claude Code 고유 기능 소개
다음으로 Claude Code의 고유 기능을 소개하겠습니다.
MCP 도구 검색
먼저 동적으로 도구를 로드하는 MCP 도구 검색입니다. MCP 서버를 많이 연결하면 도구 정의만으로도 대량의 토큰을 소비합니다. Claude Code는 도구 정의가 많아지는 것을 자동으로 감지해 도구 정의가 컨텍스트의 10%를 초과하면 자동으로 도구 검색을 활성화해서 필요한 도구만 온디맨드(on-demand) 방식으로 로딩합니다. 도구 검색을 이용하면 다음과 같이 토큰 소비량이 줄어듭니다.
| 상태 | 토큰 소비 |
|---|---|
| 도구 검색 비활성화(기존) | ~77K 토큰 |
| 도구 검색 사용 | ~8.7K 토큰 |
| 감소율 | 약 85% |
위와 같이 MCP 서버를 추가할수록 토큰 사용량이 증가하는 문제를 별도 설정 없이 자동으로 해결해 줍니다.
자동 컨텍스트 관리
다음으로 자동 컨텍스트 관리 기능입니다. 기본적으로 컨텍스트 사용률이 약 95%에 도달하면 자동으로 압축한 후 이어서 작업을 진행합니다. /compact 사용자 커스텀 지시를 이용해서 ‘API 키 및 DB 연결 정보 유지’와 같이 유지할 대상을 지정하는 게 가능하며, CLAUDE\_AUTOCOMPACT\_PCT\_OVERRIDE 환경 변수를 이용해 CLAUDE\_AUTOCOMPACT\_PCT\_OVERRIDE=70과 같이 압축 임곗값을 조정할 수 있습니다.
ADK는 컨텍스트 필터나 플러그인을 구현해야 하지만 Claude Code는 사용하는 것만으로 자동으로 최적화되므로 컨텍스트 엔지니어링의 혜택을 손쉽게 얻을 수 있습니다(Claude Code를 구성하는 자세한 방법은 CLI Reference를 참고하세요).
Codex에서 컨텍스트 엔지니어링
OpenAI의 CLI 도구인 Codex에도 ADK에서 사용한 컨텍스트 엔지니어링 개념을 �적용할 수 있습니다.
ADK와 Codex의 대응 관계
| ADK 기법 | ADK 기법에 대응하는 Codex 기능 | 컨텍스트 엔지니어링 효과 |
|---|---|---|
| State | AGENTS.md | 영속 컨텍스트 관리 |
| include_contents | /clear | 이력 리셋 |
| Tool Filter | enabled_tools, Agent Skills | 필요한 것만 로드 |
| Sub-agents | Cloud Container Isolation | 컨텍스트 분리 |
| Context Filter | /compact, config.toml | 이력 압축 및 제어 |
Codex 고유 기능 소개
다음으로 Codex 고유 기능을 소개하겠습니다.
Reasoning Effort: 추론 강도 제어
작업의 복잡도에 따라 추론에 투입되는 토큰량을 low에서 xhigh까지 5단계로 조정할 수 있습니다. 변수명 변경과 같은 단순 작업에는 아키텍처 설계와 같은 수준의 추론이 필요하지 않으므로, low로 설정해 추론 토큰 소비량을 최대 30%까지 절감할 수 있습니다.
Text Verbosity: 출력량 제어
LLM 출력의 상세도를 low/medium/high의 3단계로 조정할 수 있습니다. Reasoning Effort가 ‘생각’의 토큰을 제어한다면 Text Verbosity는 ‘말하기’의 토큰을 제어합니다. SQL 쿼�리 생성이나 간단한 코드 수정에는 긴 설명이 필요 없으므로 low로 설정해 출력 토큰을 줄일 수 있습니다.
CoT Passing: 추론 과정 전달
CoT Passing은 이전 턴의 추론 과정(chain of thought, CoT)을 다음 턴으로 전달해 같은 추론을 처음부터 반복하지 않는 메커니즘입니다. Codex CLI/IDE에서는 별도 설정없이 자동으로 적용됩니다.
Prompt Caching: 입력 비용 감소
Prompt Caching은 공통 입력 부분(시스템 프롬프트, AGENTS.md, 도구 정의)을 캐싱 처리해 두 번째 요청부터는 재전송하지 않는 방법입니다. 이를 통해 입력 토큰 비용을 최대 90% 절감할 수 있고 지연 시간을 최대 80%까지 줄일 수 있습니다. 캐시 유지 시간은 최대 24시간입니다.
Codex 컨텍스트 엔지니어링 전체 구조
| 레이어 | Codex 기능 | 주요 효과 |
|---|---|---|
| ADK 공통 | AGENTS.md, Skills, /clear, /compact, MCP filtering | 기본 컨텍스트 관리 기법 |
| 입력 최적화 | Prompt Caching | 입력 비용 최대 90% 절감 |
| 추론(reasoning) 최적화 | Reasoning Effort, CoT Passing | 추론 토큰 소비량 최대 30% 감소 |
| 출력 최적화 | Text Verbosity | 출력 토큰 소비량 직접 제어 |
ADK, Claude Code, Codex 모두에서 컨텍스트 엔지니어링 원칙은 동일합니다. 입력/추론/출력의 모든 단계에서 토큰 소비 효율을 최적화할 수 있습니다.
워크숍 성과와 학습
이번 워크숍의 성과와 워크숍 과정에서 배운 점을 소개하겠습니다.
보편적으로 적용할 수 있는 컨텍스트 엔지니어링 원칙
이번 워크숍에서 가장 전달하고 싶었던 점은 컨텍스트 엔지니어링 원칙은 특정 도구에 종속되지 않는다는 점입니다. ADK에서 배운 ‘토큰은 유한한 자원’, ‘너무 많지도 적지도 않게, 딱 적절하게’라는 원칙은 Claude Code와 Codex는 물론 그 외 모든 AI 에이전트 도구에 적용할 수 있습니다. 보편적으로 적용할 수 있는 원칙을 알아두면 새로운 도구가 등장하더라도 즉시 최적의 방식으로 활용할 수 있습니다.
작은 개선이 큰 차이를 만든다
실습에서는 코드 변경량이 많지 않았음에도 컨텍스트 윈도 사용률을 77.7%, 총 토큰 소비량을 40.7% 절감할 수 있었습니다. 이와 같은 결과는 tool\_filter 추가, AgentTool을 이용한 컨텍스트 분리, input\_schema/output\_schema 기반 구조화라는 세 가지 기법을 조합해 만들어 낼 수 있었습니다. 이 방법을 개인이 각자 실천해도 효과가 좋겠지만, 조직 단위로 교육하고 확산하면 생산성 향상과 비용 절감 효과가 훨씬 더 커질 것입니다.
향후 적용해 보려는 분들을 위해
컨텍스트 엔지니어링을 업무에 적용할 때의 단계는 다음과 같습니다.
- 현재 상태 파악: 현재 사용하는 AI 에이전트 도구에서 얼마나 많은 토큰을 소비��하고 있는지 측정
- 불필요한 컨텍스트 식별: 도구 정의 비대화, 불필요한 대화 이력 축적, 구조화되지 않은 출력 등 개선 포인트 파악
- 기법을 하나씩 적용:
tool\_filter를 이용해 도구 정의 분량 절감, 에이전트를 분리해 컨텍스트 분리, 입출력 구조화 등 효과가 기대되는 기법부터 적용 - 효과 측정 및 공유: 개선 전후 토큰 소비량과 비용을 비교해 팀에 공유
마치며
이번 글에서는 Orchestration Development Workshop에서 진행한 ‘ADK로 배우는 컨텍스트 엔지니어링 실습’ 워크숍 내용을 소개했습니다.
AI 에이전트 활용이 확대되는 가운데 많은 엔지니어가 ‘비용이 높다’, ‘기대한 대로 작동하지 않는다’와 같은 문제에 직면하고 있는데요. 이와 같은 문제의 대부분은 컨텍스트 엔지니어링을 이해하고 실천하는 것으로 해결할 수 있습니다.
이번 글에서 소개한 것처럼 컨텍스트 엔지니어링은 특별히 어려운 기술이 아닙니다. 도구 필터링, 에이전트 분리, 입출력 구조화 같은 기본 기법을 조합하는 것만으로도 토큰 소비량을 큰 폭으로 절감하고 정확도를 향상할 수 있습니다. 또한 이는 ADK나 Claude Code, Codex 등 어떤 AI 에이전트 도구를 사용하더라도 똑같이 적용할 수 있습니다.
앞으로도 Orchestration Development Workshop을 통해 AI 에이전트 활용과 관련된 실전 지식을 사내외에 공유해 나가고자 합니다. 이 글이 AI 에이전트를 보다 효율적으로 활용하시려는 분들께 도움이 되길 바랍니다.
참고 자료
- Effective context engineering for AI agents - Anthropic
- Agent Development Kit (ADK) Documentation
- ADK State
- ADK LLM Agents (Structuring Data)
- ADK Managing Context (include_contents)
- ADK Context Filter Plugin (GitHub)
- ADK Callbacks
- ADK MCP Tools
- ADK Multi-Agents
- ADK Workflow Agents
- OpenAI GPT-5 Models
- OpenAI Pricing
- Claude Code MCP
- Claude Code CLI Reference
- Codex Config Reference
- OpenAI CoT Passing (Latest Model)
- OpenAI Prompt Caching


