こんにちは、LINEヤフー株式会社の井上 秀一です。私は2024年4月に新入社員としてLINEヤフー株式会社に入社し、現在は社内向け Kubernetes as a Service である FKE チームで開発業務に従事していて、Orchestration Development Workshop ギルドメンバーとしても活動しています。
Orchestration Development Workshopは、CTO から選抜されたエンジニアが集まり、現場の AI 活用の実践知識を横断的に持ち寄るコミュニティです。Orchestration Guildとは、Workshopで扱うテーマ提案、実践的ユースケースの共有、技術的観点での品質アドバイスなどを担当し、Orchestration Development Workshop の コンテンツが属人化せず、継続的に発展していくことを支える役割を担っています。
このテックブログでは、Orchestration Development Workshopで開催したワークショップ「Agent Development Kit(ADK)で学ぶ実践Context Engineering」の内容を紹介します。前回のワークショップ(#2)ではADKを使ったSingle/Multi-Agent開発と社内システムへの統合を扱いましたが、今回はAI Agentのコスト・精度問題を改善するためのContext Engineeringに焦点を当てます。
社内の現状と課題
AI Agentツールの普及と新たな問題
前回のワークショップ以降、社内ではClaude Code、Cline、ADKなどのAI Agentツールの活用が一層進みました。しかし、活用の拡大とともに、以下のような問題が顕在化してきました。
- コストの急増: AI Agentツールの利用拡大に伴い、Token消費量が想定以上に増加
- 期待通りの出力が得られない: プロンプトに指示を書いているにもかかわらず、AIが無視したり、重要な情報が抜け落ちたりする
- 会話が長くなると精度が低下: 長時間の対話で急に的外れな回答をするようになる
これらの問題に共通する主要な原因の一つは、LLMに渡すContext(文脈情報)の管理が適切に行われていないことにあります。
Token消費量が増加する背景
Token消費量が増加する主な要因は以下の通りです。
- 生成AIの利用人口増加: 社内でのAI活用が進み、利用者数が増加
- 試行錯誤: 所望の出力を得るまでの繰り返しでTokenを消費
- AI Agentの役割拡大: Single-AgentからMulti-Agentへ、単発タスクから長時間実行・複雑なタスクへとAgent活用の幅が広がり、Context量が大幅に増加
- MCPなどのTool連携: Tool定義自体がContextを消費
- Context Engineeringの浸透不足: 最適化手法がまだ十分に浸透していない
本ワークショップでは、これらの問題を改善するための体系的なアプローチとしてContext Engineeringを紹介し、ADKを題材に実践的な手法を学びます。
Context Engineeringとは
基礎概念の整理
Context Engineeringを理解するためには、まず3つの基礎概念を押さえる必要があります。
| 概念 | 説明 | わかりやすく言うと |
|---|---|---|
| Token | LLMが文章を理解・生成する際に内部で扱うテキストの最小単位 | 1文字・1単語のようなもの |
| Context | LLMに渡す全情報 | 会話の「中身」 |
| Context Window | 一度に処理できるTokenの上限 | 会話を入れる「器」のサイズ |
GPT-5などのLLMモデルは1M Token単位で課金され、入力と出力の総Token数に基づきます。Token数を意識しないと、知らないうちに高額な費用が発生するリスクがあります。
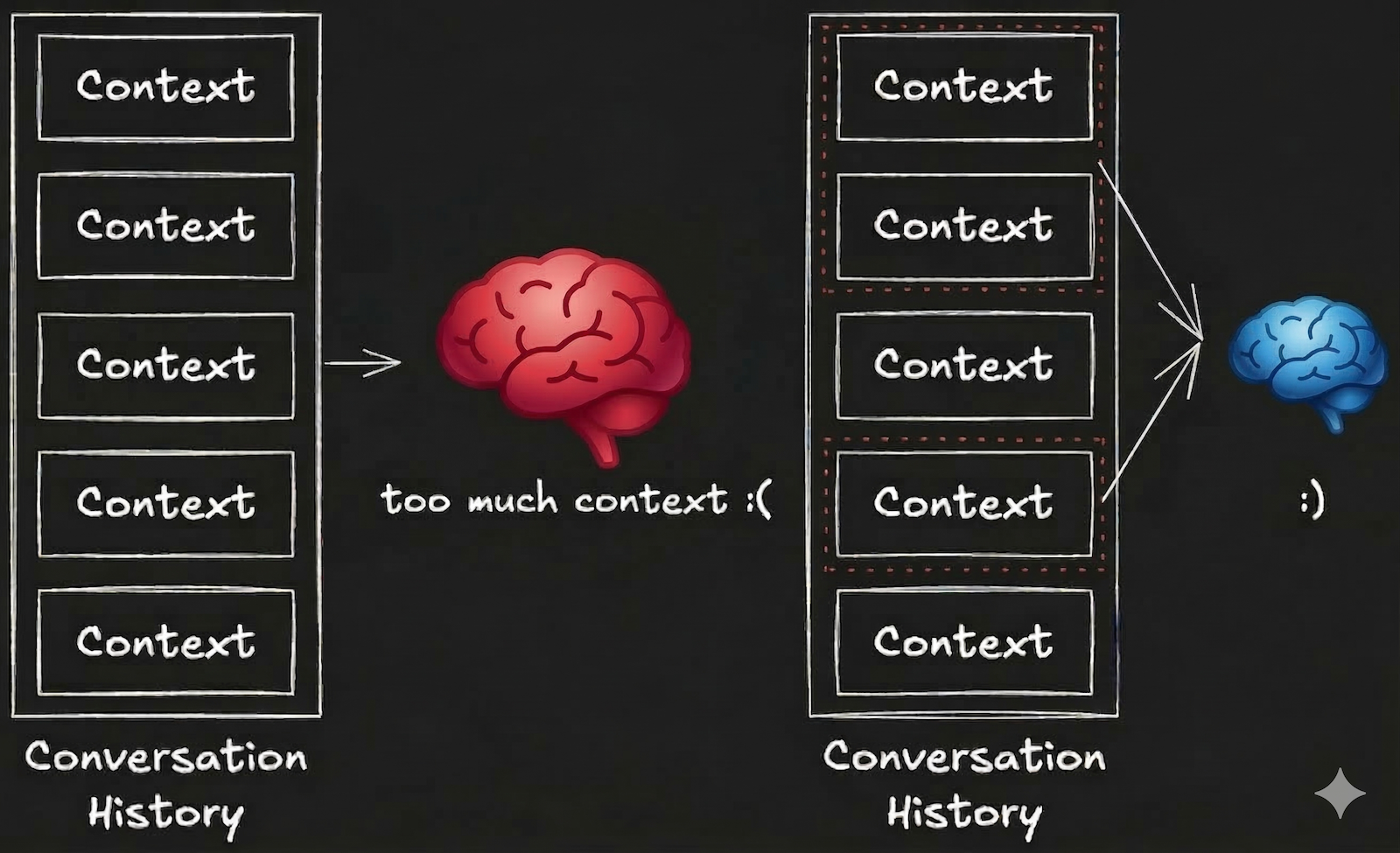
Context Rot(Contextの腐敗)
長時間実行するAgentでは、Context Rotと呼ばれる現象が発生します。これは、時間経過とともにContextが劣化する問題です。
- 情報の蓄積: 対話履歴や中間結果が増え続け、Context Windowを圧迫
- 関連性の低下: 古い情報が現在のタスクに無関係になっても、Context内に残り続ける
- 信号対雑音比の悪化: 重要な情報がノイズに埋もれ、AIの判断精度が低下
「プロンプトに書いてあるのにAIが無視する」「会話が長くなると急に変な回答になる」といった症状の多くは、このContext Rotが原因です。解決策はシンプルで、必要なContextだけをLLMに渡してあげることです。
Context Engineeringの定義
AI Agentが扱うContext(プロンプト、ツール、外部データ、メッセージ履歴等)を適切に設計・管理する最適化手法
具体的には、推論時(inference)にモデルに渡されるすべての情報を戦略的に選別・管理します。管理対象は以下の3種類に分類できます。
- Static Context(静的Context): System Prompts、Tool Definitions
- Dynamic Context(動的Context): User Messages、Conversation History、RAGで取得した外部データ
- Long-horizon Context(長期Context): 長時間実行で蓄積される情報、Session State
核心原則
Context Engineeringには、Anthropicの記事を参考にした2つの核心原則があります。
原則1: Tokenは有限なリソース
"Find the smallest set of high-signal tokens"(最小限の高品質なTokenセットを見つける)
Context Windowには上限があり、Token数に比例してコストが増加し、不要な情報は精度を低下させます。
原則2: 多すぎず、少なすぎず、ちょうど良く
- 抽象度が高すぎると情報不足でAIが推測に頼り、精度が低下
- 抽象度が低すぎると詳細すぎてTokenを浪費し、コストが増加
- タスクに必要な情報だけを適切な粒度で提供することが理想
Prompt EngineeringとContext Engineeringの違い
| 観点 | Prompt Engineering | Context Engineering |
|---|---|---|
| 定義 | AIに何をするかを指示する技術 | AIが能力を最大限発揮できるよう、記憶と環境を設計・管理する技術 |
| スコープ | プロンプトの設計に集中 | プロンプト + ツール + データ + 履歴 |
| 適用場面 | 単発タスク、シンプルな分類・生成 | マルチターン対話、複雑なタスク、長時間実行するAgent |
| 最適化対象 | 指示の明確さ、出力の品質 | Token効率、コスト、スケーラビリティ |
ADKで実現するContext Engineering
なぜADKを題材にするのか
Agent Development Kit(ADK)は、GoogleによるAI Agent構築のためのOSSです。ADKを題材にContext Engineeringを学ぶ理由は以下の通りです。
- チームでの横展開がしやすい: 個人利用のAI CLIツールではスキルの差が出やすいが、ADKならチームの集合知としてAgent設計を共有できる
- 豊富な機能群: ビルトインUI、APIサーバ、評価手法に加え、Multi-Agent System構築のための機能が充実
- Context Engineeringとの親和性: Multi-Agentアーキテクチャの理解がContext Engineeringに密接に関連する
9つのKey Components
ADKにはContext Engineeringを実現するための9つのKey Componentsがあります。ここでは、後述のハンズオンで実際に使う3つを詳しく解説し、残り6つはまとめて紹介します。
ハンズオンで使う3つのKey Components
Structuring Data(output_schema / input_schema): 構造化された入出力
LLMへの入力・出力を特定のJSON形式に強制する機能です。
- 構造化されたデータにより、Agentが効率的に処理可能
- 不要なテキストを排除し、Tokenを削減
AgentTool: 他のAI AgentをToolとして組み込み
他のAI AgentをTool(関数)としてAgent内で利用可能にする機能です。

- AgentTool内部のTool・Contextは呼び出し元に漏れない
- 呼び出し元には最終出力のみが返される
- 中間データの蓄積を防止し、Context消費を抑制
MCP Toolset(tool_filter): Toolの選択的提供
ADKにおけるMCPとのIntegration方法です。MCPサーバーから提供されるToolをフィルタリングして、必要なものだけをAgentに提供することができます。
tool_filterパラメータで許可するTool名のリストを指定- 不要なTool定義を省くことでToken削減とLLMの判断精度向上を同時に実現
その他6つのKey Components
| 手法 | 説明 | 主な効果 |
|---|---|---|
| State | セッション専用のkey-valueストア。Agentが情報を読み書きし、他Agentとも共有可能 | 会話履歴全体�をContextに入れる必要をなくし、Context Rotを防止 |
| include_contents | 会話履歴をLLMに渡すかを'default'/'none'で制御 | 独立タスクのAgentで履歴を省略し、Token削減 |
| Context Filter Plugin | 会話履歴を動的にフィルタリング(最後のN回のみ保持) | 古い情報を自動削除し、Token予算を管理 |
| Callbacks | Agent・Toolの実行前後に任意の処理を差し込み | 不要なLLM呼び出しのスキップ、入力検証・出力後処理 |
| Sub-agents | Parent Agentの下に子Agentを配置し、階層構造を構築 | 各Agentが必要最小限のContextのみ保持し、全体のContext量を削減 |
| Workflow Agents | Sequential / Loop / Parallel の3パターンでSub-agentsの実行フローを制御 | LLM非依存の決定論的実行で、フロー制御のためのContext消費を大幅に削減 |
まとめ
| レイヤー | 手法 | 主な効果 |
|---|---|---|
| データ | State, Structuring Data | 情報の効率的な保存・構造化 |
| Context最適化 | include_contents, Context Filter, Callbacks | 不要な情報の排除・圧縮 |
| アーキテクチャ | AgentTool, MCP Toolset, Sub-agents, Workflow Agents | 責務分離によるContext分離 |
これらを組み合わせて使うことで、効果的なContext Engineeringが実現できます。
ハンズオン: jira_weekly_reportで効果を検証
ワークショップでは、チームのJiraチケットを分析し週次レポートを自動生成するAI Agent「jira_weekly_report」を題材に、Context Engineeringの効果を実際に検証しました。
v1: Context Engineeringを意識しない実装
v1はシンプルな単一Agent構成です。

root_agent = LlmAgent(
name="jira_weekly_report_v1",
description="Reviews team Jira tickets and generates a report.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
instruction=f"""
## Your Role:
You are an excellent project manager. Your mission is to analyze
the team's Jira tickets and create a report.
Please execute the task following these steps:
1. Access {os.getenv("JIRA_URL")} to retrieve the list of Jira tickets.
2. From the retrieved Jira ticket list, select the first one and get its details.
3. Create a Report from the detailed content.
4. Add to the Jira report as a Markdown-formatted table.
5. Repeat the above steps for all Jira tickets.
6. Output the final Jira report.
""",
tools=[
MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="npx",
args=["@<internal-registry>/flava-mcp-connector@latest", "..."],
),
),
)
],
)v1の特徴と課題は以下の通りです。
| 課題 | 影響 |
|---|---|
| 全MCP ToolがContextに含まれる | 不要なTool定義でToken消費 |
| 1つのAgentが全処理を担当 | Context Windowに全情報が蓄積 |
| 出力が構造化されていない | 不要なテキストが含まれる可能性 |
チケット数が増えると、各チケットの詳細がContextに蓄積され、Context Rotが発生します。
v2: Context Engineeringを適用した実装
v2では、3つのContext Engineering手法(tool_filter、AgentTool、input_schema/output_schema)を組み合わせた2-Agent構成に変更しました。
from pydantic import BaseModel, Field
from google.adk.tools.agent_tool import AgentTool
class InputSchema(BaseModel):
issue_key: str
class OutputSchema(BaseModel):
report: str = Field(
...,
description="Summary report of ticket content and progress status "
"(including comments in the ticket)",
)
# Sub-agent: 個別チケット分析専用
single_ticket_analysis_agent = LlmAgent(
name="single_ticket_analysis_agent",
description="Analyzes a single Jira ticket and returns structured results.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
input_schema=InputSchema, # 構造化入力
output_schema=OutputSchema, # 構造化出力
instruction="""
## Your Role:
1. Use the given Jira ticket key to retrieve the Jira ticket details.
2. Create a report from the detailed content.
**Only include facts. Speculation is prohibited.**
""",
tools=[
MCPToolset(
tool_filter=["jira_get_issue"], # 必要なツールのみ
connection_params=StdioConnectionParams(...),
)
],
)
# Root agent: チケット一覧取得・レポート集約
root_agent = LlmAgent(
name="jira_weekly_report_v2",
description="Reviews team Jira tickets and generates a report.",
model=config.LLM_MID_INTELLIGENCE_MODEL,
instruction=f"""
## Your Role:
You are an excellent project manager.
1. Access {os.getenv("JIRA_URL")} to retrieve the list of Jira tickets.
2. Pass all retrieved Jira tickets to single_ticket_analysis_agent to get reports.
3. Create the Jira report as a Markdown-formatted table.
""",
tools=[
AgentTool(single_ticket_analysis_agent), # Sub-agentをToolとして組み込み
MCPToolset(
tool_filter=["jira_search"], # 必要なツールのみ
connection_params=StdioConnectionParams(...),
),
],
)v1 vs v2: 適用したContext Engineering手法
| 観点 | v1(Context Engineeringなし) | v2(Context Engineeringあり) |
|---|---|---|
| Agent数 | 1 | 2 |
| Tool Filter | なし(全Tool使用可能) | あり(必要なToolのみ) |
| 出力構造化 | なし | あり(Pydantic schema) |
| Context分離 | なし(全情報が1つのContext) | あり(役割ごとに分離) |
Token消費量の計測
効果を定量的に測定するために、after_model_callbackを利用したカスタムPluginでToken消費量を計測しました。以下はコードの一部抜粋です。
class TokenTrackingPlugin(BasePlugin):
async def after_model_callback(
self,
*,
callback_context: CallbackContext,
llm_response: LlmResponse,
) -> Optional[LlmResponse]:
entry = TokenUsageEntry(
agent_name=callback_context.agent_name,
total_token_count=llm_response.usage_metadata.total_token_count,
used_context_window=llm_response.usage_metadata.total_token_count
/ self.max_tokens,
used_context_window_percent=f"{llm_response.usage_metadata.total_token_count
/ self.max_tokens:.2%}",
token_usage_for_entire_system=token_usage_for_entire_system,
)
self.TOTAL_TOKENS.append(entry)本ハンズオンではADKのLLMモデルとしてGPT-5を使用しているため、Context Window使用率はtotal_token_count / 400000で計算しています(GPT-5のContext Window(400K tokens)を基準)。
実験結果
v1・v2それぞれ10回試行し、同一期間のJiraチケット(2026年1月26日〜2月1日の FKE チームの Jiraチケット)を同一の入力プロンプトで処理した結果です。
| 評価項目 | v1 | v2 |
|---|---|---|
| Context Window平均使用率(root_agent) | 33.49% | 7.46% |
| システム全体の総Token平均消費 | 174,643 Token | 103,583 Token |

v1→v2でContext Window平均使用率を26.03ポイント削減(削減率77.7%)、総Token消費量を40.7%削減しました。
コード量としては大きな変更ではありませんが、tool_filter、AgentTool、構造化schemaの3つの手法を組み合わせるだけで、大幅なToken削減を実現できています。
コスト試算
この効果を組織規模で試算すると、以下のようになります(月4回 × 12ヶ月 = 年48回/チーム)。
| Model | 規模 | v1 | v2 | 年間削減額 |
|---|---|---|---|---|
| gpt-5-mini | 1回あたり | ¥14 | ¥8 | ¥6 |
| 100チーム(年4,800回) | ¥6.7万 | ¥4.0万 | ¥2.7万 | |
| 1,000チーム(年48,000回) | ¥67万 | ¥40万 | ¥27万 | |
| gpt-5 | 1回あたり | ¥69 | ¥41 | ¥28 |
| 100チーム(年4,800回) | ¥33万 | ¥20万 | ¥14万 | |
| 1,000チーム(年48,000回) | ¥333万 | ¥197万 | ¥136万 |
※ 料金: gpt-5-mini Input 2.00、gpt-5 Input 10.00 per 1M tokens(OpenAI Pricing参照)
※ Input:Output = 85:15で試算、$1 = ¥155換算
1回あたりのコスト差は小さく見えますが、組織規模で掛け算すると無視できない金額になります。Context Engineeringの教育・展開を組織単位で進めることで、精度向上も期待でき、コスト削減も実現できます。
Claude CodeでのContext Engineering
ADKで学んだContext Engineeringの概念は、Claude Codeにもそのまま適用できます。概念は共通で、実現方法がツールによって異なります。
ADKとClaude Codeの対応関係
| ADK手法 | Claude Code対応 | Context Engineering効果 |
|---|---|---|
| State | CLAUDE.md | 永続Contextの管理 |
| include_contents | /clear | 履歴リセット |
| Tool Filter | Skills、MCP Tool Search | 必要なものだけ読み込み |
| Sub-agents | Sub-agent / Task | Context分離 |
| Context Filter | /compact | 履歴の圧縮・制御 |
| Callbacks | Hooks | ライフサイクル制御 |
Claude Code独自の機能
MCP Tool Search: 動的Tool読み込み
MCPサーバーを多数接続すると、Tool定義だけで大量のTokenを消費します。Claude Codeはこれを自動で検知し最適化します。
- Tool定義がContextの10%を超えると自動でTool Search有効化
- 必要なToolのみオンデマンドでロード
| 状態 | Token消費 |
|---|---|
| Tool Search無効(従来) | ~77K Token |
| Tool Search有効 | ~8.7K Token |
| 削減率 | 約85% |
参考: Advanced Tool Use - Anthropic Engineering
参考: Tool Search Tool - Anthropic Docs
MCPサーバーを追加するほどTokenが膨らむ問題を、設定不要で自動解決してくれます。
自動Context管理
- 自動コンパクション: Context使用率95%到達で自動的に要約・継続
- /compact カスタム指示: 「APIキーとDB接続情報は保持して」のように保持対象を指定可能
- 環境変数チューニング:
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE=70で圧縮閾値を調整
ADKではContext FilterやPluginのコード実装が必要ですが、Claude Codeは使うだけで自動最適化されるため、Context Engineeringの恩恵を手軽に受けられます。Claude Codeの詳細な設定方法はCLI Referenceを参照してください。
CodexでのContext Engineering
OpenAIのCLIツールであるCodexにも、ADKで学んだContext Engineeringの概念は適用できます。
ADKとCodexの対応関係
| ADK手法 | Codex対応 | Context Engineering効果 |
|---|---|---|
| State | AGENTS.md | 永続Contextの管理 |
| include_contents | /clear | 履歴リセット |
| Tool Filter | enabled_tools、Agent Skills | 必要なものだけ読み込み |
| Sub-agents | Cloud Container Isolation | Context分離 |
| Context Filter | /compact、config.toml | 履歴の圧縮・制御 |
Codex独自の機能
Reasoning Effort: 推論強度の制御
タスクの複雑さに応じて、推論にかけるToken量をlow〜xhighの5段階で調整できます。変数名変更のような単純タスクにアーキテクチャ設計と同じ推論は不要であり、low設定で推論Token最大30%削減が可能です。
Text Verbosity: 出力量の制御
LLMの出力の詳細度をlow/medium/highの3段階で調整できます。Reasoning Effortが「思考」のTokenを制御するなら、Text Verbosityは「発言」のTokenを制御します。SQLクエリ生成やシンプルなコード修正に長い説明文は不要なため、low設定で出力Tokenを直接削減できます。
CoT Passing: 推論過程の引き継ぎ
前ターンの推論過程(Chain of Thought)を次ターンに引き継ぎ、同じ推論をゼロからやり直さない仕組みです。Codex CLI/IDEでは自動的に適用され、設定不要です。
Prompt Caching: 入力コストの劇的削減
共通の入力部分(System Prompt、AGENTS.md、Tool定義)をキャッシュし、2回目以降のリクエストで再送を不要にします。
- 入力Tokenコスト: 最大90%削減
- レイテンシ: 最大80%削減
- キャッシュ保持: 最大24時間
Codex Context Engineeringの全体像
| レイヤー | Codex機能 | 主な効果 |
|---|---|---|
| ADK共通 | AGENTS.md, Skills, /clear, /compact, MCP filtering | 基本的なContext管理手法 |
| Input最適化 | Prompt Caching | 入力コスト最大90%削減 |
| Reasoning最適化 | Reasoning Effort, CoT Passing | 推論Token最大30%削減 |
| Output最適化 | Text Verbosity | 出力Token直接制御 |
ADK、Claude Code、Codexのいずれにおいても、Context Engineeringの原則は共通です。入力・思考・出力のすべてのフェーズでToken効率を最適化できます。
ワークショップの成果と学び
Context Engineeringの普遍性
今回のワークショップを通じて最も伝えたかったのは、Context Engineeringの原則はツールに依存しないということです。ADKで学んだ「Tokenは有限なリソース」「多すぎず少なすぎずちょうど良く」という原則は、Claude Code、Codex、その他のあらゆるAI Agentツールに適用できます。
ツールが変わっても変わらない普遍的な考え方を身につけることで、新しいツールが登場しても即座に最適な使い方を実践できるようになります。
小さな工夫が大きな差を生む
ハンズオンでは、コード量としてはそれほど大きくない変更で、Context Window使用率を77.7%、総Token消費量を40.7%削減できることを実証しました。tool_filterの追加、AgentToolによるContext分離、input_schema/output_schemaによる構造化という3つの手法の�組み合わせが、この結果を生んでいます。
個人で実践するだけでも効果がありますが、組織単位で教育・展開が進むと、生産性向上とコスト削減の効果は飛躍的に大きくなります。
これから実践する方へ
Context Engineeringを自身の業務に適用する際のステップを紹介します。
- まず現状を把握する: 自分が使っているAI Agentツールで、どれだけのTokenを消費しているかを計測する
- 不要なContextを特定する: Tool定義の肥大化、不要な会話履歴の蓄積、構造化されていない出力など、改善可能なポイントを洗い出す
- 1つずつ手法を適用する: Tool FilterによるTool定義の削減、Agentの分割によるContext分離、入出力の構造化など、効果が見込める手法から試す
- 効果を計測して共有する: 改善前後のToken消費量やコストを比較し、チームで知見を共有する
おわりに
本記事では、Orchestration Development Workshopで実施した「ADKで実践するContext Engineering」の内容を紹介しました。
AI Agentの活用が進む中で、「コストが高い」「期待通りに動かない」といった問題は多くのエンジニアが直面しています。これらの問題の多くは、Context Engineeringの知識と実践によって解決できます。
本ワークショップで示した通り、Context Engineeringは特別に難しい技術ではありません。Toolフィルタリング、Agent分割、構造化入出力といった基本的な手法の組み合わせで、大幅なToken削減を実現でき、精度向上も期待できます。そしてその原則は、ADK、Claude Code、Codexなど、どのAI Agentツールを使う場合でも共通です。
今後もOrchestration Development Workshopを通じて、AI Agent活用の実践知識を社内外に共有していきたいと考えています。本記事の内容が、皆様のAI Agent活用の改善につながれば幸いです。
参考文献
- Effective context engineering for AI agents - Anthropic
- Agent Development Kit (ADK) Documentation
- ADK State
- ADK LLM Agents (Structuring Data)
- ADK Managing Context (include_contents)
- ADK Context Filter Plugin (GitHub)
- ADK Callbacks
- ADK MCP Tools
- ADK Multi-Agents
- ADK Workflow Agents
- OpenAI GPT-5 Models
- OpenAI Pricing
- Claude Code MCP
- Claude Code CLI Reference
- Codex Config Reference
- OpenAI CoT Passing (Latest Model)
- OpenAI Prompt Caching


