들어가며
안녕하세요. Game Platform Dev의 류동훈, Zhang Youlu(Michael), Takenaka, 이형중입니다. 저희 조직은 게임 퍼블리싱에 필요한 다양한 기능을 개발하고 운영하는 역할을 맡고 있습니다.
저희는 최근 조직 내 업무 효율을 높이기 위해 다양한 LLM(large language model) 애플리케이션을 개발하고, 이와 연계해 LLMOps 시스템 구축 프로젝트를 진행했습니다. 프로젝트의 주요 목표 중 하나는 진입 장벽이 높은 LLM 애플리케이션 개발을 직군에 상관없이 누구나 쉽게 제작할 수 있는 환경을 구축하는 것이었는데요. 이를 위해 여러 가지를 고민하며 시도하는 과정을 거쳤고, 그 결과 누구나 손쉽게 접근할 수 있는 개발 및 배포 환경을 마련할 수 있었습니다.
이번 글에서는 LLM 애플리케이션의 일반적인 개발 방식과 개발 과정에서 마주하는 어려움을 살펴보고, 이런 문제를 해결할 수 있는 환경을 구성하기 위해 저희가 어떤 고민을 하고 노력을 했는지 공유하고자 합니다. 이 글을 통해 LLM 애플리케이션 개발 과정의 병목 지점을 개선하고 고도화해 접근성을 높일 수 있는 인사이트를 얻으시길 바라며 시작하겠습니다.
LLM 애플리케이션의 개발 과정
최근 OpenAI의 GPT와 Anthropic의 Claude 같은 고성능 LLM을 쉽게 활용할 수 있게 되면서, LLM 애플리케이션 개발의 초점이 이러한 모델을 효과적으로 활용해 서비스를 제공하는 방향으로 전환되고 있습니다. 모델을 직접 학습시키거나 파인튜닝(fine-tuning)하지 않고, 비용 효율을 고려해 상용 모델을 그대로 사용하면서 모델의 입력인 프롬프트를 구조화해 모델이 이를 잘 이해하도록 만드는 데 집중하고 있는 것입니다.
프롬프트는 모델이 수행해야 할 작업의 맥락과 방향을 제시하므로 프롬프트를 잘 구조화하면 LLM의 성능을 한층 더 높일 수 있습니다. 또한 프롬프트는 수정하기 쉽기 때문에 비싼 비용을 지불해 모델을 직접 수정하는 것보다 훨씬 저렴하다는 장점도 있습니다. 이런 장점을 이용해 개발자들은 보다 빠르고 경제적으로 모델의 성능을 최적화할 수 있습니다.
하지만 LLM 애플리케이션이 새로운 데이터에 대해 적절히 답변하도록 만드는 문제는 프롬프트 최적화만으로는 해결할 수 없습니다. 그럼 이 문제를 모델을 추가 학습하지 않고 어떻게 해결할 수 있을까요?
일반적으로 이런 문제는 LLM의 몇 가지 기능을 활용해 해결합니다. LLM은 사전 학습된 데이터 외에 프롬프트에 제시된 추가 정보를 통해 즉석에서 정보를 생성할 수 있습니다. 이런 기능을 인 컨텍스트(in-context) 러닝이라고 합니다. 인 컨텍스트 러닝 중 특히 몇 가지 예시 답변을 통해 모델이 패턴을 익히고 더욱 잘 답변하게 만드는 것을 퓨 샷(few-shot) 러닝이라고 하는데요. 이를 이용해 프롬프트에 정보를 주입하면 LLM이 새로운 데이터에 대해 적절히 답변할 수 있게 만들 수 있습니다.
이제 LLM이 새로운 데이터에 대해 답변할 수 있게 됐지만 인 컨텍스트 러닝과 퓨 샷 러닝, 두 가지 기법만으로는 새로운 데이��터에 대해 완벽히 대응하기 어렵습니다. 이를 보완하기 위해 외부 데이터베이스의 적절한 추가 정보나 예시 등을 실시간으로 모델에 주입해 결과를 생성하는 방법인 RAG(Retrieval Augmented Generation)를 사용합니다.
RAG의 기본적인 메커니즘은 두 단계로 나눌 수 있습니다. 첫 번째는 모델이 이해할 수 있는 형태로 데이터를 임베딩(embedding)해 벡터로 만들어 데이터베이스에 저장하는 단계이고, 두 번째는 LLM으로 요청할 때 데이터베이스에 질의해 질문과 유사한 데이터를 검색(retrieval)해서 그 결과를 프롬프트에 주입하는 단계입니다. 그 결과 인 컨텍스트 러닝을 통해 새로운 데이터에 대해서도 패턴을 인식해 LLM이 답변할 수 있게 됩니다.
이와 같이 다양한 기법을 이용해 LLM의 결과를 최적화하는 것을 통틀어서 프롬프트 엔지니어링이라고 합니다. 서비스 결과를 최적화하는 부분이기 때문에 LLM 애플리케이션 개발의 주요 부분이라고 할 수 있습니다. 프롬프트 엔지니어링은 주로 LangChain이라고 하는 오픈소스를 이용해 작업하는데요. 앞서 살펴본 것처럼 좋은 결과를 위해 여러 가지 기법과 다양한 컴포넌트를 사용하기 때문에 복잡한 작업입니다. 아래는 위에서 언급한 기법들을 LangChain을 이용해 작성한 예시로, LangChain과 RAG, 프롬프트 엔지니어링에 대한 정보를 임베딩한 뒤 LLM을 통해 답변하는 것입니다.
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.chains import RetrievalQA
from langchain.retrievers import SimpleRetriever
from langchain.indexes import SimpleIndex
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 설정 생략...
# 데이터 준비
documents = [
"Langchain은 자연어 처리(NLP)를 위한 강력한 툴킷입니다.",
"RAG는 검색과 생성을 결합하여 더 나은 결과를 제공합니다.",
"프롬프트 엔지니어링은 AI 모델의 출력을 최적화하는 기술입니다."
]
# 텍스트 분할 설정
text_splitter = RecursiveCharacterTextSplitter(max_chunk_size=256)
# 인덱스 생성
index = SimpleIndex.from_documents(documents, text_splitter=text_splitter)
# 검색기 설정
retriever = SimpleRetriever(index=index)
# LLM 설정
llm = OpenAI(temperature=0.7)
# RAG 체인 생성
rag_chain = RetrievalQA(retriever=retriever, llm=llm)
# In Context Learning 및 Few-Shot Learning 을 위한 프롬프트 설정
example_context = """
예시:
Q: Langchain이란 무엇인가요?
A: Langchain은 자연어 처리(NLP)를 위한 강력한 툴킷입니다.
Q: RAG의 장점은 무엇인가요?
A: RAG는 검색과 생성을 결합하여 더 나은 결과를 제공합니다.
"""
prompt_template = PromptTemplate(
input_variables=["retrieved_text", "question"],
template=example_context + "\n다음 정보를 바탕으로 질문에 답하세요: {retrieved_text}\n\nQ: {question}\nA:"
)
# LLM 체인 설정
llm_chain = LLMChain(llm=llm, prompt_template=prompt_template)
# 질문 설정
query = "프롬프트 엔지니어링이란 무엇인가요?"
# 검색 및 생성
retrieved_docs = retriever.retrieve(query)
retrieved_text = " ".join([doc.page_content for doc in retrieved_docs])
response = llm_chain.run(retrieved_text=retrieved_text, question=query)
# 결과 출력
print(f"질문: {query}")
print(f"응답: {response}")LLM 애플리케이션 개발 시 부딪치는 문제점
위와 같은 방법으로 다양한 LLM 애플리케이션을 만들 수 있었지만, 개발을 진행하다 보니 여러 가지 문제들과 맞닥뜨리게 되었습니다.
그중 가장 큰 문제는 앞서 제시한 LLM 애플리케이션 코드처럼 자연어 프롬프트와 정적인 Python 코드가 함께 존재한다는 점이었습니다. 프롬프트는 보통 서비스의 도메인 전문가가 수정하는데 만약 프로그래밍 지식이 없는 사람일 경우 코드에 직접 접근해 프롬프트를 수정하기 어려울 수 있습니다. 또한 프롬프트에는 보통 {}와 같은 형식으로 변수가 포함돼 있고, 여러 경우의 수를 고려해 이런 변수의 값을 변경하며 테스트해야 하는데요. LLM 애플리케이션을 통해서만 프롬프트를 실행해야 한다면 변숫값 변경과 같은 프롬프트의 변화에 따른 결과의 변화를 개별적으로 확인하기 어렵습니다. 이와 비슷한 관점에서 모델의 종류에 따라 프롬프트 결과가 크게 달라질 수 있는데, 모델을 변경하면서 결과를 확인하기 어려우면 개발이 지연될 수 있습니다. 그리고 다양한 프롬프트 작성 기법이 코드 내에 분산돼 있으면 노하우를 공유하기 힘들다는 문제도 발생합니다. 이런 문제들은 모두 프롬프트 작성과 코드 간의 의존성 문제로 볼 수 있습니다.
이에 더해 개발 관점에서 봤을 때, RAG를 위한 벡터 데이터베이스와 프롬프트 체이닝 방법은 많은 보일러플레이트 코드를 생성해 개발자가 코드를 이해하기 어렵게 만듭니다. 또한 이런 코드들은 서로 복잡하게 연결되기 때문에 디버깅 과정에서도 많은 문제를 일으킵니다. 실제로 저희 조직에서 LLM 애플리케이션의 PoC(proof of concept)를 �진행할 때 프로젝트가 방대해지면서 관리 비용이 증가하기도 했습니다. 프로젝트를 지속하려면 이런 문제들을 반드시 해결해야 했습니다.
문제를 해결하고 개발 과정을 가속화하기 위한 세 가지 접근 방법
저희는 이런 문제를 해결하기 위해 세 가지 접근 방법을 선택했습니다.
첫 번째는 프롬프트를 즉시 실행할 수 있고 공유할 수 있는 환경을 만드는 것입니다. 프롬프트는 LLM의 가장 기본적인 요소로 가장 먼저 관리해야 하는 대상이었습니다. 저희는 도메인 전문가가 이슈를 즉각 확인할 수 있도록 하나의 프롬프트를 즉시 실행할 수 있는 환경을 만들기로 결정했습니다. 이를 위해 변수를 간단하게 지정할 수 있게 만들었고, 모델도 즉시 선택해 실행할 수 있게 만들었습니다. 또한 프롬프트를 하나의 저장 공간에 모아 이를 공유하거나 쉽게 재사용할 수 있게 해 프롬프트 작성 노하우가 보존되도록 개선했습니다.
두 번째는 개발에 비주얼 스크립팅 방식을 도입하는 것입니다. 프롬프트 엔지니어링에 사용하는 컴포넌트는 대부분 재사용할 수 있는 요소입니다. 다만 그 관계가 복잡하고 반복 호출되기 때문에 코드를 보면서 어떤 컴포넌트가 어떤 관계에서 언제 호출되는지 직관적으로 파악하기 어렵습니다. 저희는 이 문제를 해결하기 위해 개발 환경에 비주얼 스크립팅 요소를 적용해 재사용 가능한 컴포넌트를 가시화하고 각 컴포넌트가 어떤 결과를 통해 호출되는지 시각화하기를 원했습니다. 다행히 저희와 비슷한 고민 끝에 출시된 다양한 오픈소스가 있었고, 그중 Langflow를 바탕으로 비주얼 스크립팅 방식의 개발을 도입했습니다(이 과정은 이후 자세히 살펴보겠습니다).
세 번째는 결과를 빨리 확인할 수 있도록 배포를 쉽게 만드는 것입니다. 단일 프롬프트에 대해 결과를 빠르게 확인할 수 있는 것뿐 아니라 LLM 애플리케이션 내에서 실제 작동하는 것을 빠르게 확인하는 것도 필요한데요. 개발자가 아니라면 애플리케이션 배포가 어려울 수 있기 때문에 배포 작업을 최대한 캡슐화해서 도메인 전문가도 간단한 조작만으로 LLM 애플리케이션을 배포할 수 있도록 만들었습니다.
지금부터 각 접근 방법을 실제로 어떻게 적용했는지 하나씩 소개하겠습니다.
1. 프롬프트를 즉시 실행하고 공유할 수 있는 Prompt Store 개발
저희는 프롬프트를 즉시 실행할 수 있고 공유할 수 있는 환경을 만들기 위해 'Prompt Store'를 개발했습니다. 프롬프트를 테스트하고 공유할 수 있는 Prompt Store의 기능을 간단히 소개하겠습니다.
프롬프트 작성 및 편집 기능
Prompt Store의 기본적인 기능으로 사용자는 프롬프트에 이름을 붙여 저장할 수 있으며, 관리하기 위한 태그를 추가할 수도 있습니다. 또한 프롬프트 내에 변수 키를 삽입할 수 있고, {}을 통해 변수가 삽입된 경우 해당 값을 지정할 수 있는 기능을 제공합니다.
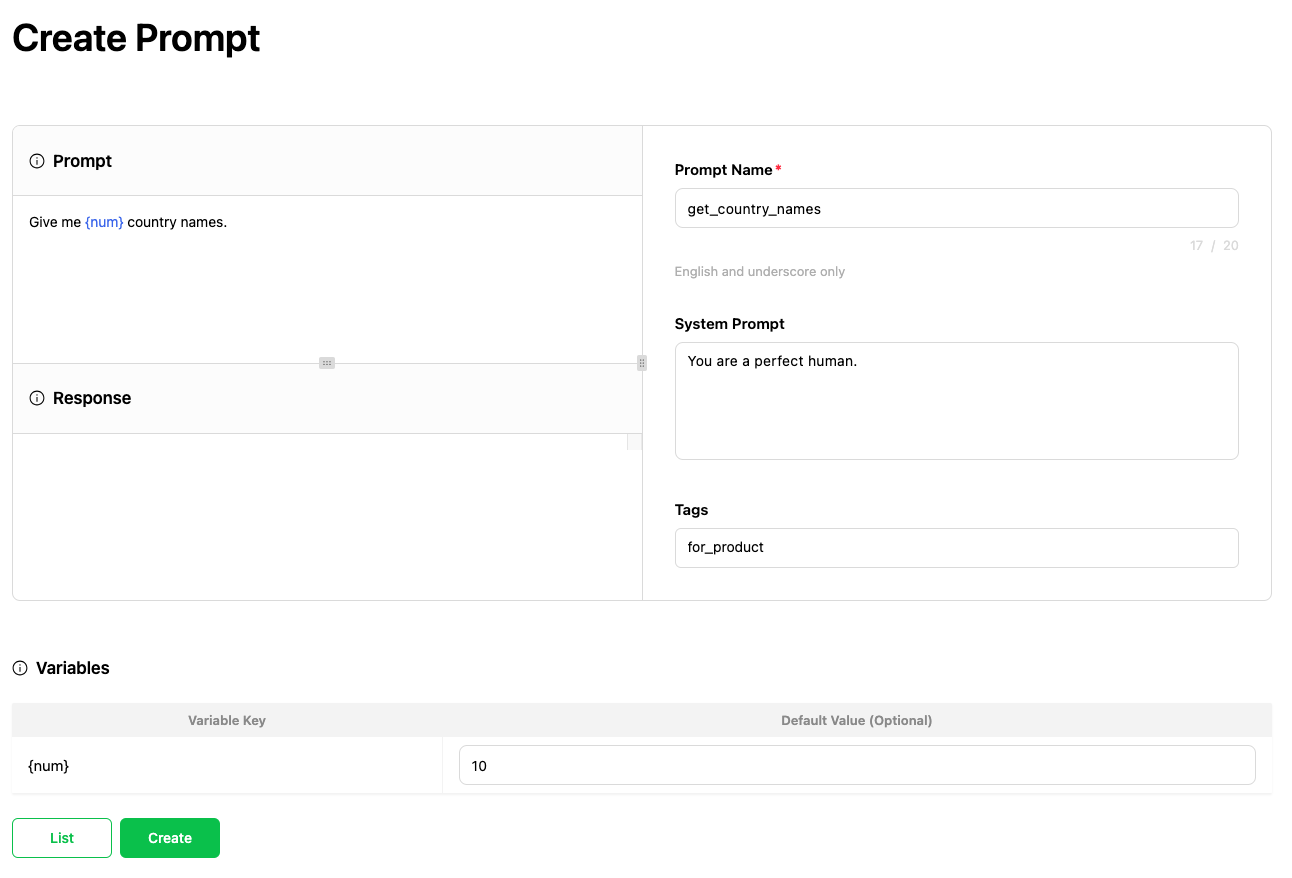
작성한 프롬프트는 다른 사람과 공유하며 함께 관리할 수 있습니다. 이를 통해 프롬프트 작성 노하우를 공유하거나 이미 작성된 프롬프트를 재사��용할 수 있습니다.
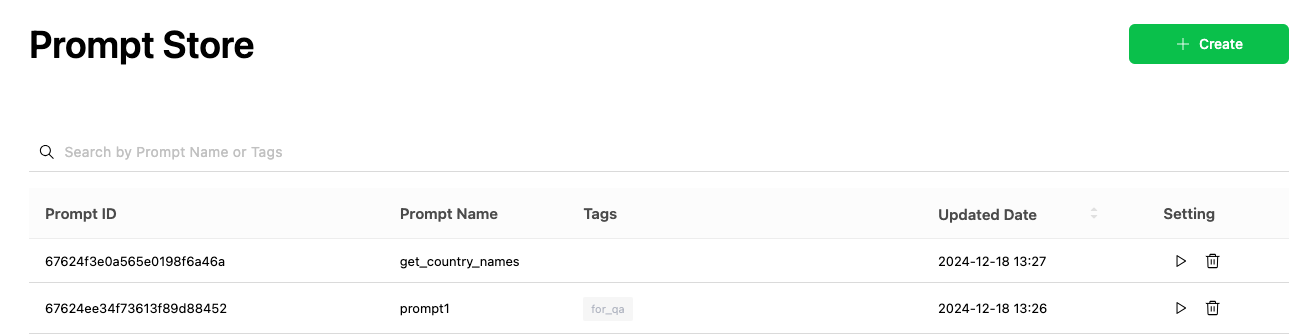
프롬프트를 테스트할 수 있는 Playground 기능
Prompt Store에서는 작성한 프롬프트를 테스트할 수 있는 'Playground' 기능을 제공합니다. Playground에서 실행할 때는 OpenAI의 모델부터 조직 내에서 작성한 커스텀 모델까지 선택할 수 있으며, 다양한 환경에서 작성한 프롬프트의 결과를 다양한 파라미터를 바탕으로 확인할 수 있습니다.
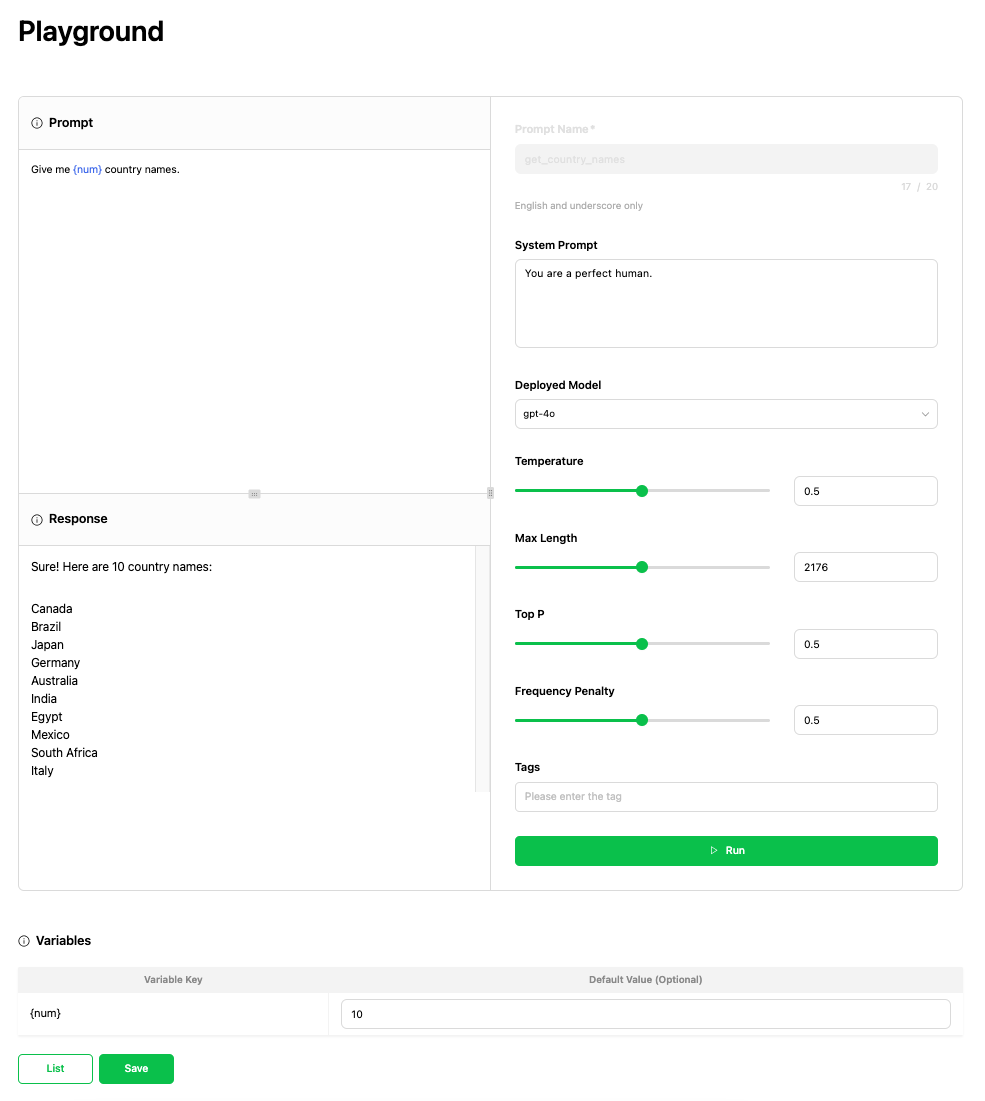
프롬프트 재사용 기능
Prompt Store에서는 작성한 프롬프트를 다양한 컴포넌트에서 사용할 수 있는 기능을 제공합니다. 이를 바탕으로 Langflow를 이용해 애플리케이션을 시각적으로 개발하거나 Harness를 이용해 테스트할 때 최적화된 프롬프트를 일관적으로 사용할 수 있습니다.
2. Langflow를 활용해 LLM 애플리케이션 개발에 비주얼 스크립팅 방식 도입
다음으로 Langflow를 이용해 비주얼 스크립팅 방식을 개발에 도입한 방법을 소개하겠습니다.
Langflow는 비주얼 스크립팅 방식으로 개발할 수 있는 기능을 제공하는 오픈소스로, 복잡한 컴포넌트 간의 관계를 쉽게 파악할 수 있는 환경을 제공합니다. 저희는 여러 방법을 고민하던 중 Langflow를 선택했으며, 그 이유는 다음과 같습니다.
- 드래그 앤 드롭만으로 LLM 애플리케이션을 만들 수 있습니다.
- 프롬프트 엔지니어링과 RAG 등 LLM 애플리케이션 구축에 필요한 작업들을 쉽게 적용할 수 있습니다.
- 컴포넌트를 재활용할 수 있어 반복 개발을 피할 수 있습니다.
- 쉽게 기능을 커스터마이징하거나 새로운 기능을 추가할 수 있습니다.
- Python 기반이기 때문에 내부 프로젝트들과 잘 호환됩니다.
- 단시간에 많은 기여자가 참여해 잘 유지 보수되며 빠르게 성장하고 있는 프로젝트입니다.
- 배포 환경을 구축하기 쉽습니다.
비슷한 기능을 제공하는 Flowise라는 프로젝트도 존재했지만 비교 테스트 결과 Langflow를 선택했는데요. 그 이유는 다음과 같습니다
- Typescript 기반의 프로젝트라서 Langflow와 비교해 호환성이 떨어졌습니다.
- UI/UX 측면에서 Langflow에 비해 상대적으로 부족하다고 판단했습니다.
다음으로는 Langflow 사용 방법 및 기능 소개와 조직 내 도입기에 대해 추가로 설명드리겠습니다.
Langflow 소개
LandFlow 사용법과 기능을 간단히 살펴보겠습니다. 참고로 이 글은 1.0.5 버전을 기반으로 작성했으며, Langflow는 현재 빠르게 업데이트되고 있는 오픈소스 프로젝트이기 때문에 여러분께서 글을 읽는 시점에는 사용법이나 기능에 다소 차이가 있을 수 있습니다.
Langflow 실행해 보기
아래 두 명령어를 실행해 Langflow를 실행할 수 있습니다.
- 설치하기:
pip install langflow - 실행하기:
python -m langflow run
정상적으로 실행되면 다음과 ��같은 화면이 나타납니다.
Langflow에서는 하나의 애플리케이션을 Flow라고 부릅니다. 아주 간단한 Flow의 예시를 살펴보겠습니다. 아래는 채팅하면서 OpenAI의 GPT 모델을 사용해 응답을 받는 Flow입니다. 'Chat Input' 컴포넌트와 'Chat Output' 컴포넌트 사이에 OpenAI 컴포넌트를 배치해 채팅을 통해 GPT와 대화를 주고받을 수 있게 구성했습니다.
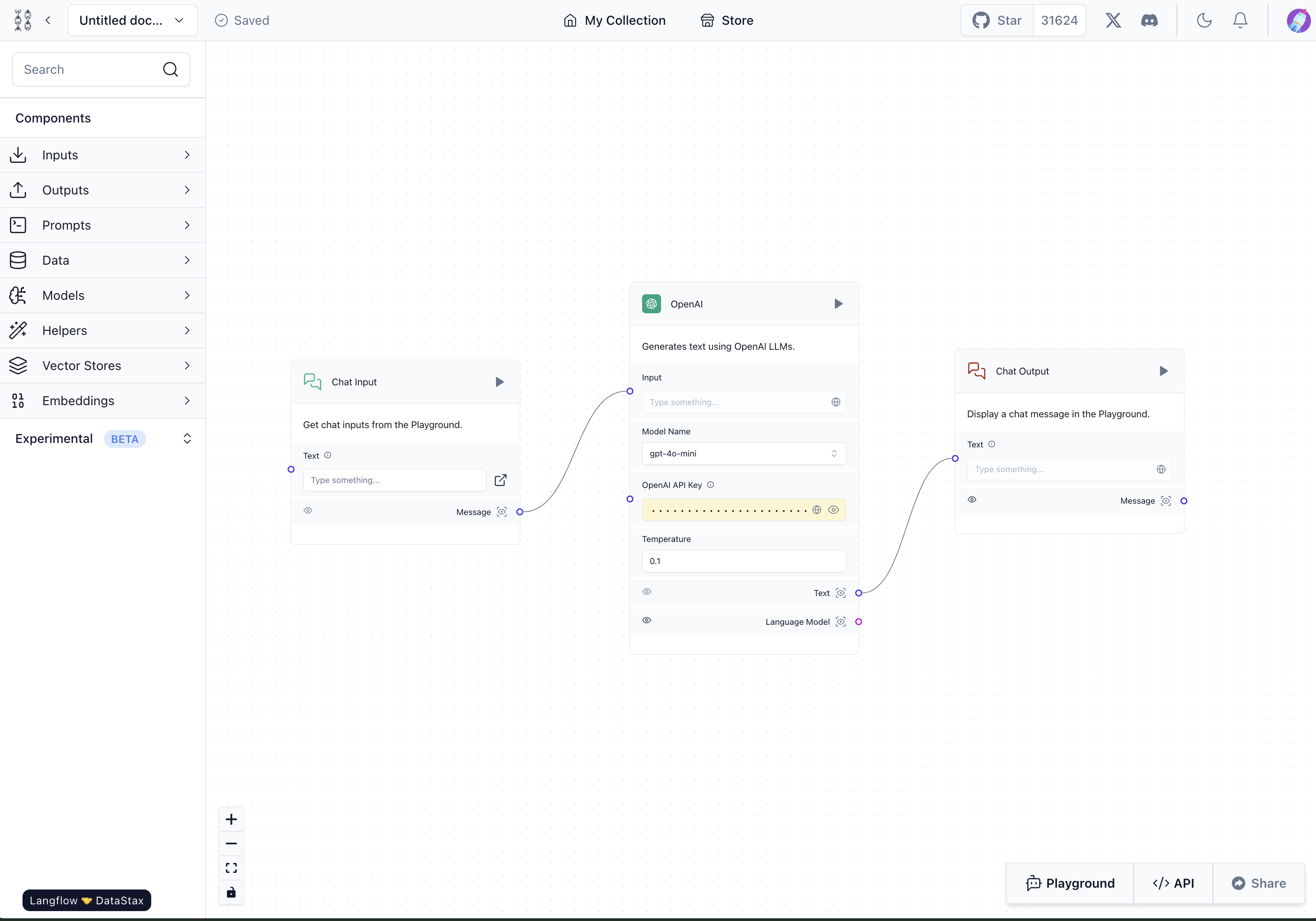
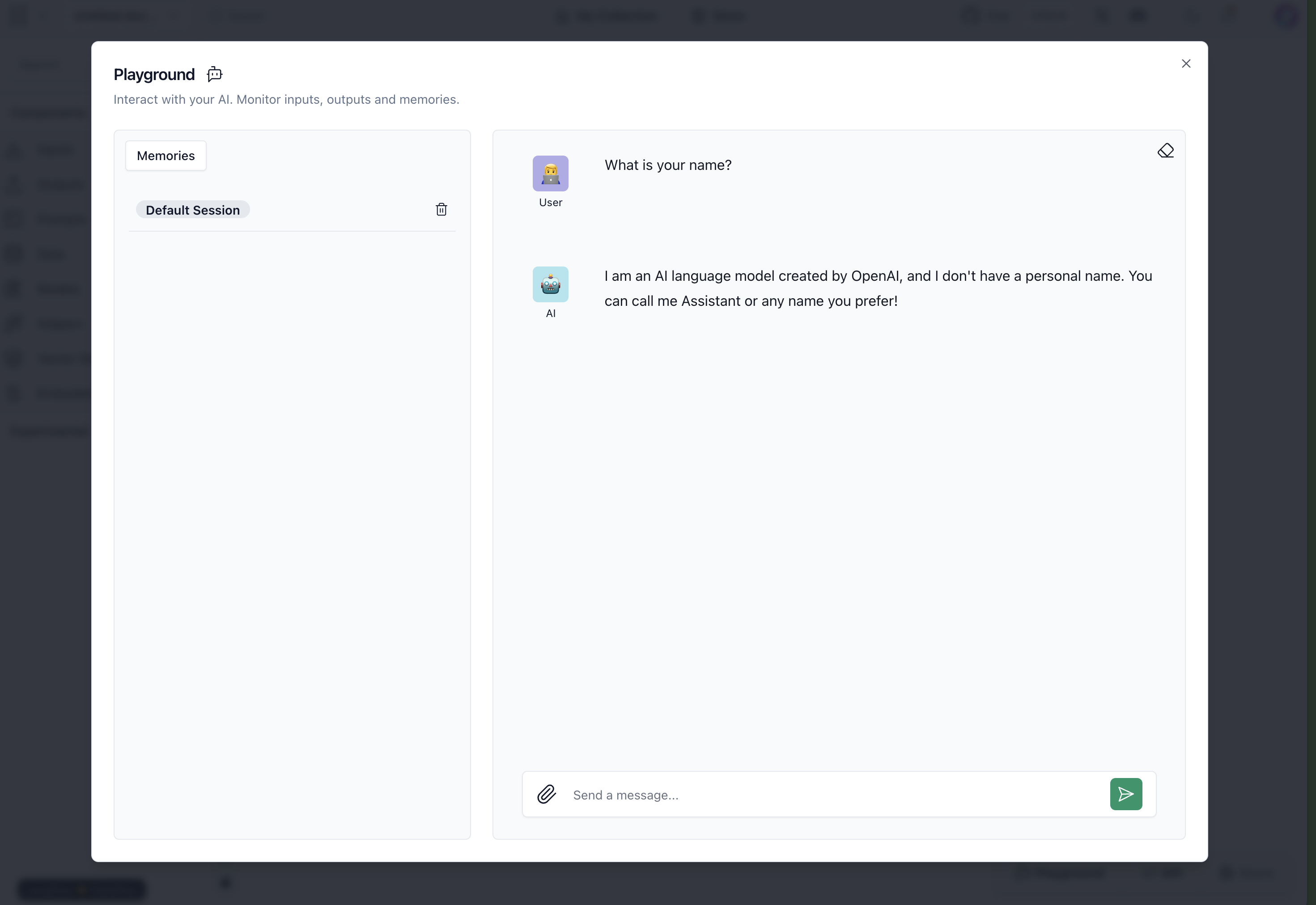
이렇게 구성한 뒤 각 컴포넌트의 오른쪽 상단에 위치한 실행 버튼(▶)이나 화면 오른쪽 하단 Playground 버튼을 누르면 아래와 같이 만든 Flow가 작동합니다.
Langflow 작동 원리
Langflow는 공식 문서에서 작동 원리를 설명하고 있지는 않은데요. 작동 원리를 이해하면 Langflow를 사용할 때 도움이 된다고 생각해 간단히 설명하겠습니다.
앞서 살펴본 예시 Flow에는 Python 코드로 구성된 세 개의 컴포넌트가 있습니다.
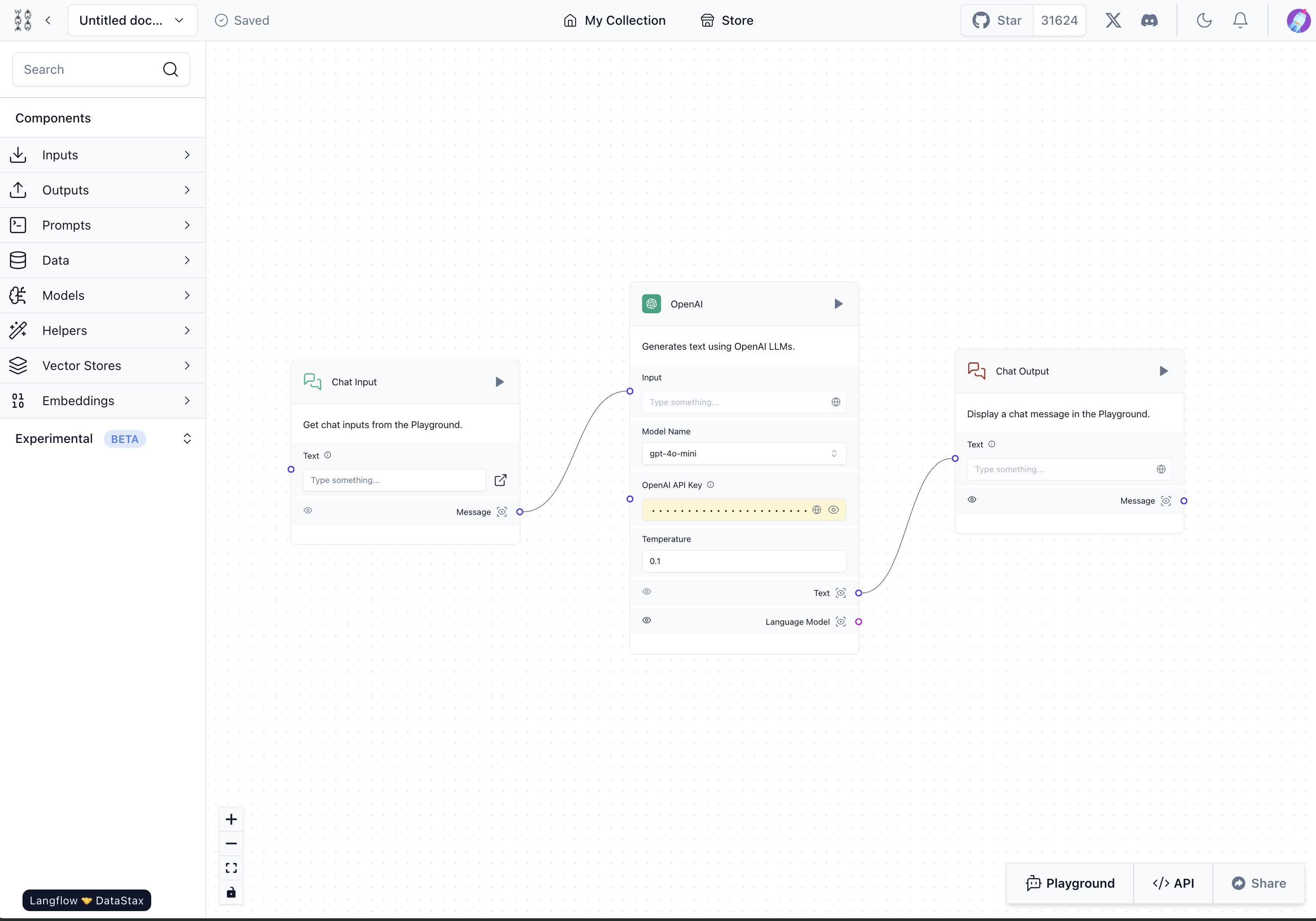
각 컴포넌트는 실행 전에는 정적으로 존재하지만 실행 버튼을 누르면 내부적으로 각 컴포넌트가 다른 컴포넌트와 연결된 정보와 자신의 코드를 파라미터로 Langflow 백엔드 API를 호출하는데요. 위 화면에서 선이 이어진 순서대로 반복문이 실행되면서 각 컴포넌트가 빌드됩니다. 이때 내부적으로 Python 내장 함수인 exec이 호출되며 각 코드가 동적으로 메모리에 로드되어 실행됩니다.
def build_class_constructor(compiled_class, exec_globals, class_name):
exec(compiled_class, exec_globals, locals())
exec_globals[class_name] = locals()[class_name]
# 필요한 모듈을 가져오고 클래스 인스턴스를 생성하는 함수 반환
def build_custom_class(*args, **kwargs):
for module_name, module in exec_globals.items():
if isinstance(module, type(importlib)):
globals()[module_name] = module
# 클래스 인스턴스를 생성
instance = exec_globals[class_name](*args, **kwargs)
return instance
build_custom_class.__globals__.update(exec_globals)
return build_custom_classLangflow는 Flow의 구성 정보와 Flow를 구성하는 각 컴포넌트의 코드 정보를 이용해 동적으로 실행하는 방식으로 작동합니다. 이런 작동 방식 덕분에 UI를 이용해 자유롭게 코드를 수정할 수 있고, Flow의 데이터만 있다면 Langflow 백엔드 로직을 사용해 어디서나 동일한 작동을 수행할 수 있습니다. 더 나아가 Flow의 데이터와 Langflow 백엔드의 의존성만 함께 패키징해 배포한다면 LLM 애플리케이션을 쉽게 배포하는 것도 가능합니다.
커스텀 기능 만들기
Langflow를 선택한 가장 중요한 이유 중 하나가 기능을 자유롭게 커스터마이징할 수 있다는 것입니다. 아래 간단한 예시와 함께 살펴보겠습니다.
class JsonMarkdownParserComponent(Component):
# 커스텀 컴포넌트 이름 정의
display_name = "JSON Markdown Parser"
description = "Receives the key of json in markdown format and returns the value corresponding to the key."
# 입력 파라미터(inputs) 정의
inputs = [
MessageTextInput(
name="input_value",
display_name="Text",
info="JSON string in markdown format",
),
MessageTextInput(
name="key",
display_name="Key",
info="The key of json for which you want to find the value",
),
]
# 출력 파라미터(outputs) 정의
outputs = [
Output(display_name="Text", name="output_value", method="parse_json_markdown_to_str"),
]
# ouput을 만들어 낼 함수 정의
def parse_json_markdown_to_str(self) -> Message:
result: dict = parse_json_markdown(self.input_value)
return Message(text=result[self.key].__str__())
Langflow의 컴포넌트는 각각이 하나의 함수라고 생각하면 이해하기 쉽습니다. 위 코드와 같이 입력 파라미터와 출력 파라미터를 정의하고, parse_json_markdown_to_str과 같은 메서드를 정의하면 됩니다. 이외의 형식은 자유롭기 때문에 아이디어만 있다면 커스텀 기능을 쉽게 구현할 수 있습니다.
이렇게 구성한 커스텀 컴포넌트는 UI에서 바로 코드를 수정해서 만들 수 있으며, 재사용하고 싶은 경우 Langflow를 사용하는 프로젝트에 커스텀 컴포넌트를 모아놓고 아래와 같이 --components-path에 커스텀 컴포넌트가 정의돼 있는 폴더명을 넘기면 됩니다.
poetry run langflow run --host 0.0.0.0 --components-path {custom component path}커스텀 컴포넌트와 관련된 더욱 자세한 내용은 Langflow 커스텀 컴포넌트 공식 문서를 참고하시기 바랍니다.
Langflow 도입기
저희는 Langflow를 도입하면서 저희의 요구 사항을 충족하기 위해 몇 가지 방법을 적용했습니다.
Langflow 리포지터리를 포크해서 사용
앞서 말씀드렸듯 Langflow는 현재 빠르게 업데이트되고 있는 오픈소스 프로젝트로 꾸준히 새로운 기능이 추가되고 있으며, 신생 프로젝트이다 보니 내부적으로 크고 작은 버그들이 계속 발견되고 있습니다. 또한 기존 기능 중 일부는 저희 조직에 맞게 일부 변경해서 사용하고자 하는 니즈도 있었습니다. 이런 상황을 고려해 저희는 Langflow 프로젝트를 내부에서 포크해서 사용하기로 결정했습니다. 단, 이와 같이 사용하면 추후 버전을 업그레이드하는 과정에서 충돌이 발생해 유지 보수가 어려워질 위험이 크기 때문에 다음과 같은 원칙을 세웠습니다.
- Langflow 자체의 코드를 변경하는 것은 최대한 지양합니다.
- 내부 요구 사항을 충족하기 위해 Langflow 코드에 새로운 기능을 추가하는 것이 불가피하다면 최대한 기존 코드와 충돌하지 않는 방향으로 작업합니다.
- 버그 때문에 코드를 수정해야 한다면 먼저 최신 버전에 이 부분이 수정돼 있는지 확인해 버전을 올리는 것을 더 높은 우선순위로 둡니다.
커스텀 컴포넌트를 통해 공통으로 사용할 수 있는 기능 구현
이번에 Langflow를 도입하면서 느낀 점은 Langflow는 아직 실제 업무에서 사용할 수 있는 수준이라기보다는 개인적으로 LLM 애플리케이션을 구현해 보고 싶을 때 간단하게 사용하는 수준의 프로젝트라는 것이었습니다. 그렇다 보니 구현돼 있지만 실제로 실행하면 작동하지 않는 기능들도 있었고, 당연히 있을 법한 기능들이 아직 구현되지 않은 경우도 있었습니다.
앞서 Langflow를 선택한 이유 중 하나가 맞춤형 기능을 자유롭게 구현할 수 있기 때문이라고 말씀드렸는데요. 저희는 이 장점을 활용해 저희에게 필요한 기능 중 현재 Langflow에서 제공되지 않거나 성능이 미흡한 기능을 자체 개발했습니다. 그중 두 가지 컴포넌트를 예시로 소개하겠습니다.
Flow Runner
첫 번째는 'Flow Runner'입니다. 아래는 저희가 자체 개발한 Flow Runner의 UI입니다.
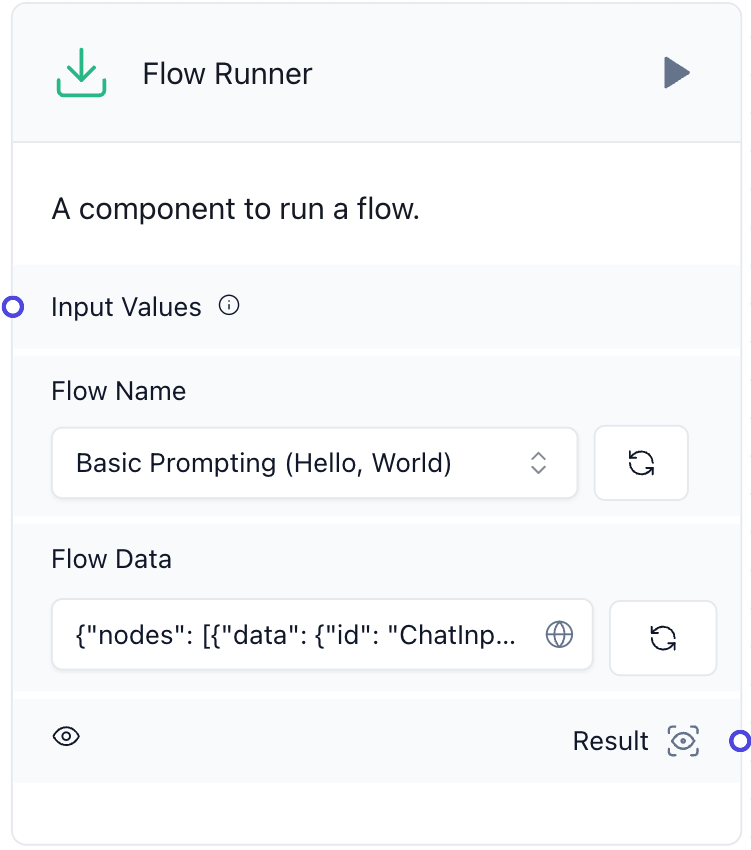
현재 Langflow에서는 여러 개의 Flow를 생성하고 각각을 실행할 수 있지만, 서로 연계해 실행하는 기능은 지원되지 않았습니다. 이로 인해 동일한 기능을 여러 Flow에 반복해서 추가해야 하거나, Flow가 너무 커져서 이해하기 어려운 경우가 발생할 수 있었습니다. 이러한 문제를 해결하기 위해 저희는 한 Flow 내에서 다른 Flow를 실행하거나 반복해서 실행할 수 있는 기능을 구현했습니다. 이 기능은 한 Flow에서 다른 Flow의 내부 로직을 호출하는 방식으로 작동합니다.
class FlowRunnerComponent(Component):
display_name = "Flow Runner"
# skip
outputs = [
Output(name="result", display_name="Result", method="build_flow_outputs")
]
async def __run_flow(self, graph: Graph, inputs: Optional[Union[dict, List[dict]]] = None) -> List[RunOutputs]:
# skip
return await graph.arun(inputs_list, inputs_components=inputs_components, types=types)
async def build_flow_outputs(self) -> list[Message]:
# skip
for message_input in self.input_values:
# skip
results_from_flow: list[RunOutputs] = await self.__run_flow(
graph=Graph.from_payload(flow_data_dict),
inputs=[{"input_value": message_input_text, "type": input_type}]
)
outputs = []
for result_from_flow in results_from_flow:
if result_from_flow:
outputs.extend(self.build_messages_from_run_outputs(result_from_flow))
results.extend(outputs)
return results
def build_messages_from_run_outputs(self, run_outputs: Optional[RunOutputs]) -> list[Message]:
# skip
return messages
Prompt Store
두 번째는 앞서 소개한 Prompt Store입니다. 아래는 저희가 개발한 Prompt Store 컴포넌트의 UI입니다.
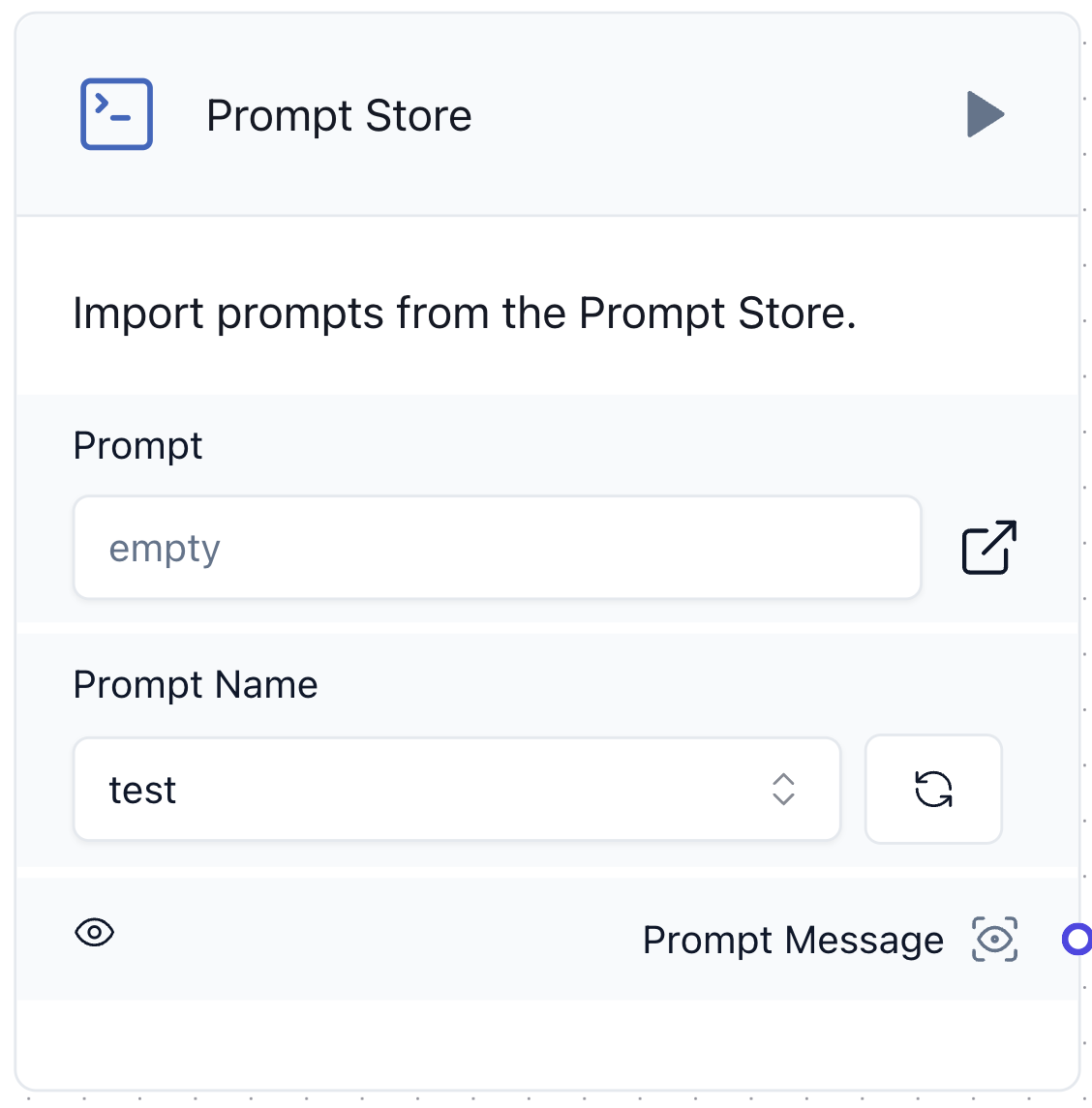
기존에 제공하는 프롬프트 컴포넌트는 그때그때 프롬프트를 직접 입력해야 하는데 그 때문에 LLM 애플리케이션의 핵심인 프롬프트 재사용이 어려웠습니다. 이에 아래와 같이 DB에서 프롬프트를 가져오는 Prompt Store 컴포넌트를 개발했습니다.
class PromptStoreComponent(Component):
display_name: str = "Prompt Store"
description: str = "Import prompts from the Prompt Store."
# skip
outputs = [
Output(name="prompt", display_name="Prompt Message", method="build_prompt"),
]
def __get_prompt_from_store_with_prompt_name(self, prompt_name: str, prompts: dict[str, PromptResult]) -> str:
# skip
return result.template.get("text")
async def build_prompt(self) -> Message:
# 템플릿과 변수를 사용하여 프롬프트 생성
prompt = await Message.from_template_and_variables(**self._attributes)
self.status = prompt.text
return prompt
def post_code_processing(self, new_build_config: dict, current_build_config: dict):
# skip
frontend_node = super().post_code_processing(new_build_config, current_build_config)
template = frontend_node["template"]["template"]["value"]
_ = process_prompt_template(
template=template,
name="template",
custom_fields=frontend_node["custom_fields"],
frontend_node_template=frontend_node["template"],
)
update_template_values(frontend_template=frontend_node, raw_template=current_build_config["template"])
return frontend_node
커스텀 컴포넌트를 쉽게 적용하고 배포하기 위한 구조 설계
커스텀 컴포넌트를 효과적으로 사용하려면 Langflow를 사용하는 프로젝트에 해당 컴포넌트의 코드가 정의돼 있어야 합니다. Langflow UI에서 직접 코드를 추가해 커스텀 컴포넌트를 생성할 수도 있지만, 이렇게 하면 일회성 사용에 그치고 재사용이 불가능하기 때문에 재사용성을 고려해 커스텀 컴포넌트를 정의하는 것이 일반적입니다. 또한 커스텀 컴포넌트를 사용하려면 Langflow에 의존하는 프로젝트에서 구현해야 하는 것과 더불어 새로운 기능에 필요한 새로운 의존성(예: openpyxl)도 고려해야 합니다. 이런 상황에서 생각할 수 있는 구조는 아래 다이어그램과 같습니다.
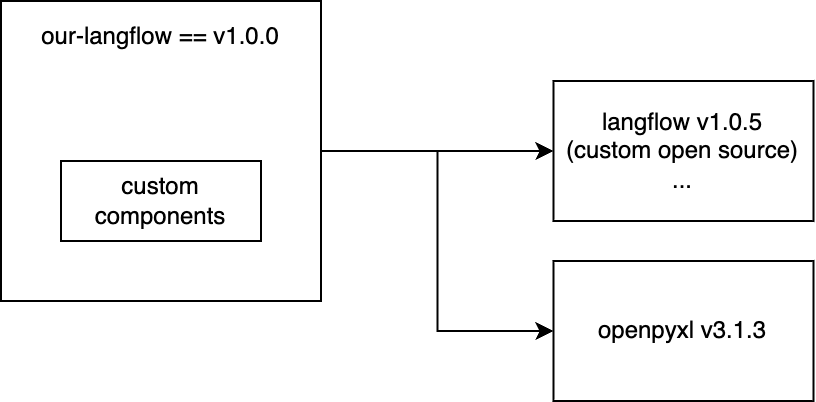
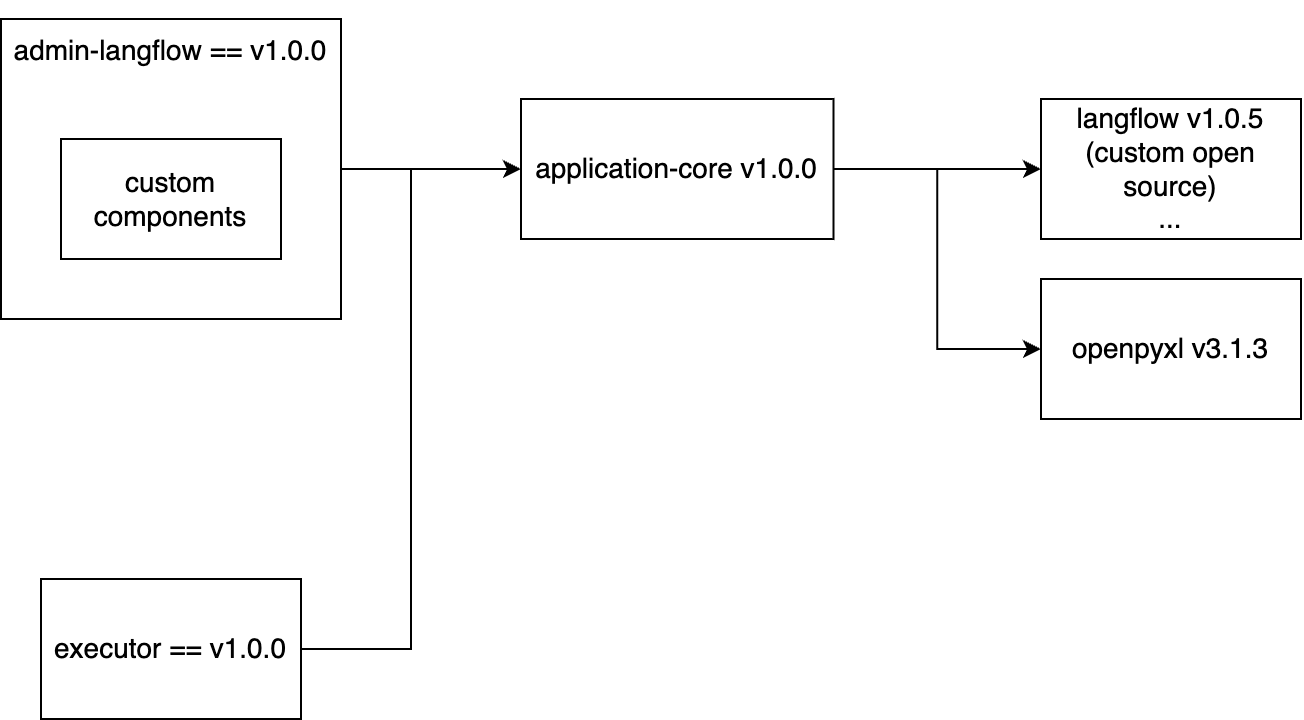
저희는 두 가지 모듈이 필요했습니다. 하나는 Flow를 편집할 수 있는 Langflow UI 모듈이고, 다른 하나는 Flow를 실행해 사용자에게 LLM 애플리케이션으로 제공하는 모듈입니다. 이때 두 모듈 모두 Langflow v1.0.5와 openpyxl v3.1.3에 해당하는 의존성을 공통으로 갖고 있어야 합니다. 이를 위해 저희는 공통 의존성을 관리하는 'application-core'라는 이름의 모듈을 중간에 두었습니다. 그리고 관리자용 모듈을 'admin-langflow', 실제로 LLM 애플리케이션을 실행하기 위한 사용자용 모듈을 'executor'라고 정의해 아래와 같은 구조로 설계했습니다.
3. LLM 애플리케이션을 쉽게 배포할 수 있는 시스템 구축
저희는 LLM 애플리케이션의 결과를 빠르게 확인할 수 있도록 쉽게 배포할 수 있는 시스템을 구축하고자 했습니다. 하지만 현재 Langflow는 개별 인스턴스로 배포할 수 있는 기능이 충분히 구축되어 있지 않기 때문에 기존 기능을 확장했는데요. 아래와 같이 Langflow에서 Flow를 생성한 후 관리자 페이지에서 배포 버튼을 클릭하는 것만으로 가능하도록 만들었습니다. 이 배포 버튼만 클릭하면 LLM 애플리케이션을 다른 서비스와 함께 사용할 수 있도록 API 인스턴스가 생성됩니다.

이를 도입한 결과 배포와 피드백 주기가 단축되면서 LLM 애플리케이션 개발 과정 중 발생하는 병목 현상을 상당 부분 해소할 수 있었습니다.
배포 구조
배포는 오케스트레이터 컴포넌트가 관리합니다. 이 컴포넌트는 데이터베이스에 접근해 Flow를 읽고 쿠버네티스 API를 사용해 해당 디플로이먼트(deployment)를 생성합니다. 배포된 각 Flow마다 하나의 파드(pod)가 생성되는데요. 파드를 공통 도메인 이름의 서브 경로로 매핑해 즉시 LLM 애플리케이션의 API를 호출할 수 있도록 설정했습니다.
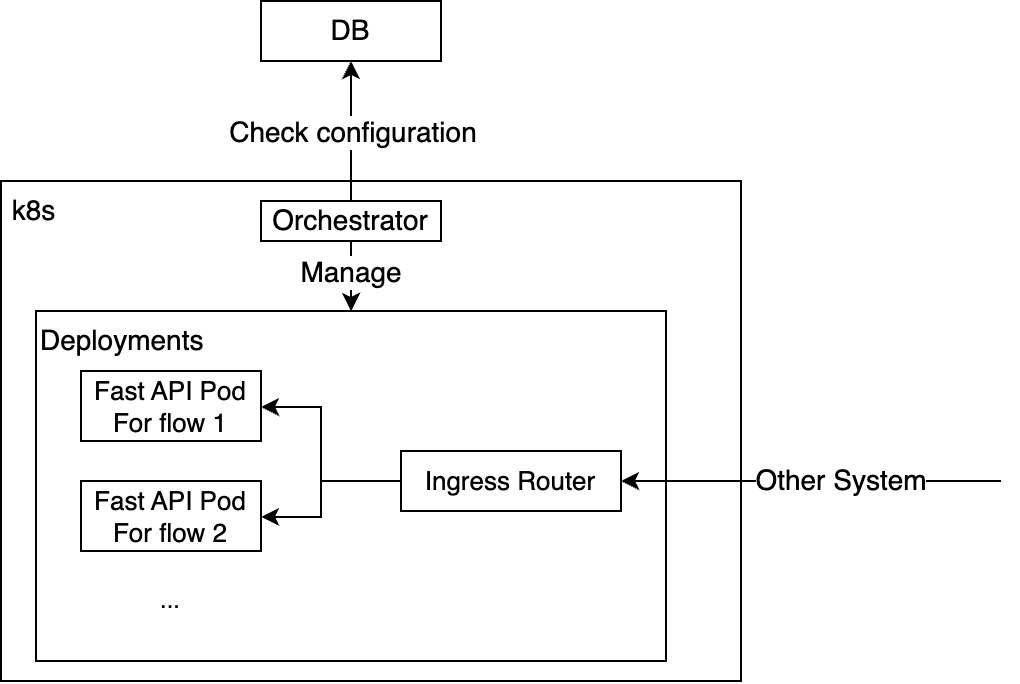
실제 파드 내부에서는 각 Flow를 아래와 같이 JSON 형식으로 로드하며, 사용자의 입력을 받아 실행됩니다. 이런 방식으로 사용자 입력을 Flow의 채팅 입력 컴포넌트의 입력으로 처리하고, 필요한 경우 일부 매개변수를 수정한 후 최종적으로 채팅 출력을 반환하도록 해서 사용자가 작업 환경에서 정의한 Flow를 실제 배포 환경에서도 동일하게 호출할 수 있도록 만들었습니다.
graph = load_flow_from_json(
{"data": flow_data}, tweaks=req.tweak
)
for vertex in graph.vertices:
vertex.update_raw_params({"should_store_message": False}, overwrite=True)
if req.slack_channel_id is not None and "slack_channel_id" in vertex.params:
vertex.update_raw_params({"some_param": req.some_param})
results: List[RunOutputs] = await graph.arun(
inputs=[{"input_value": req.input_value}],
session_id=req.session_id,
)세 가지 접근 방법 도입 결과
앞서 살펴본 설계대로 프로젝트를 구성하고, 활용 가능한 여러 기능을 Langflow에 추가해 내부적으로 여러 목적으로 LLM 애플리케이션을 생성할 수 있는 환경을 구축했습니다. 예를 들어 수식이 입력되면 결과를 반환하는 Flow를 하나 만들어 관리자 기능으로 배포하면 쿠버네티스 환경에 배포됩니다.
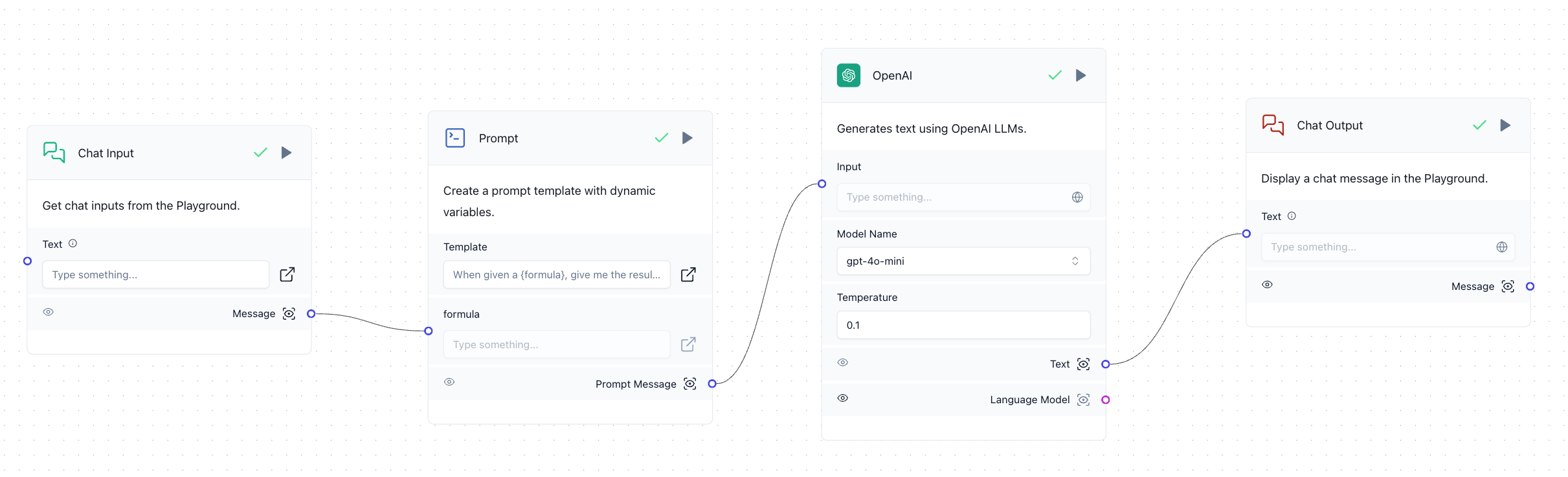
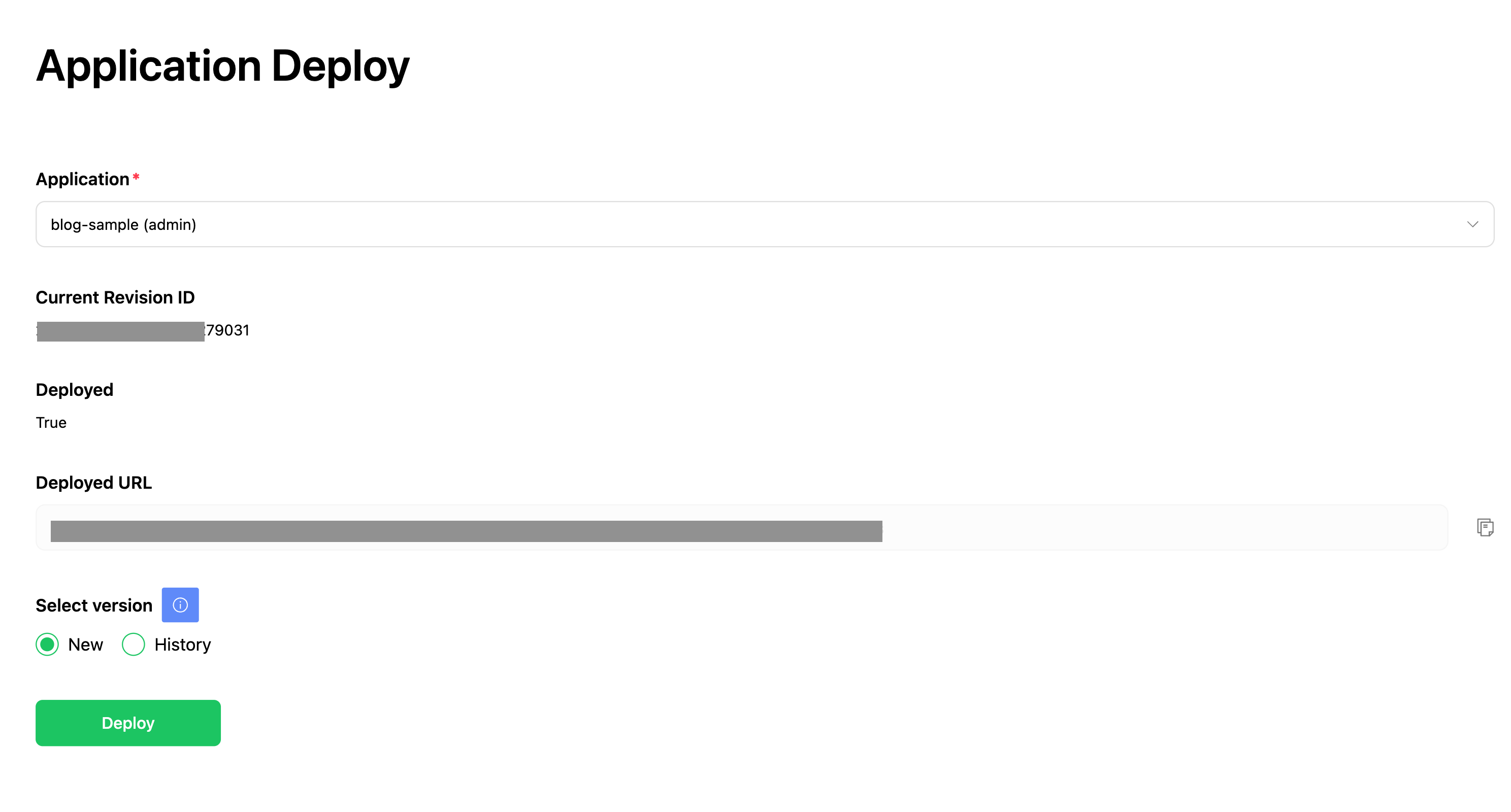
이를 Slack 앱과 연동해 아래와 같이 Slack 앱에서 호출해 원하는 결과를 얻을 수 있게 만들었습니다.
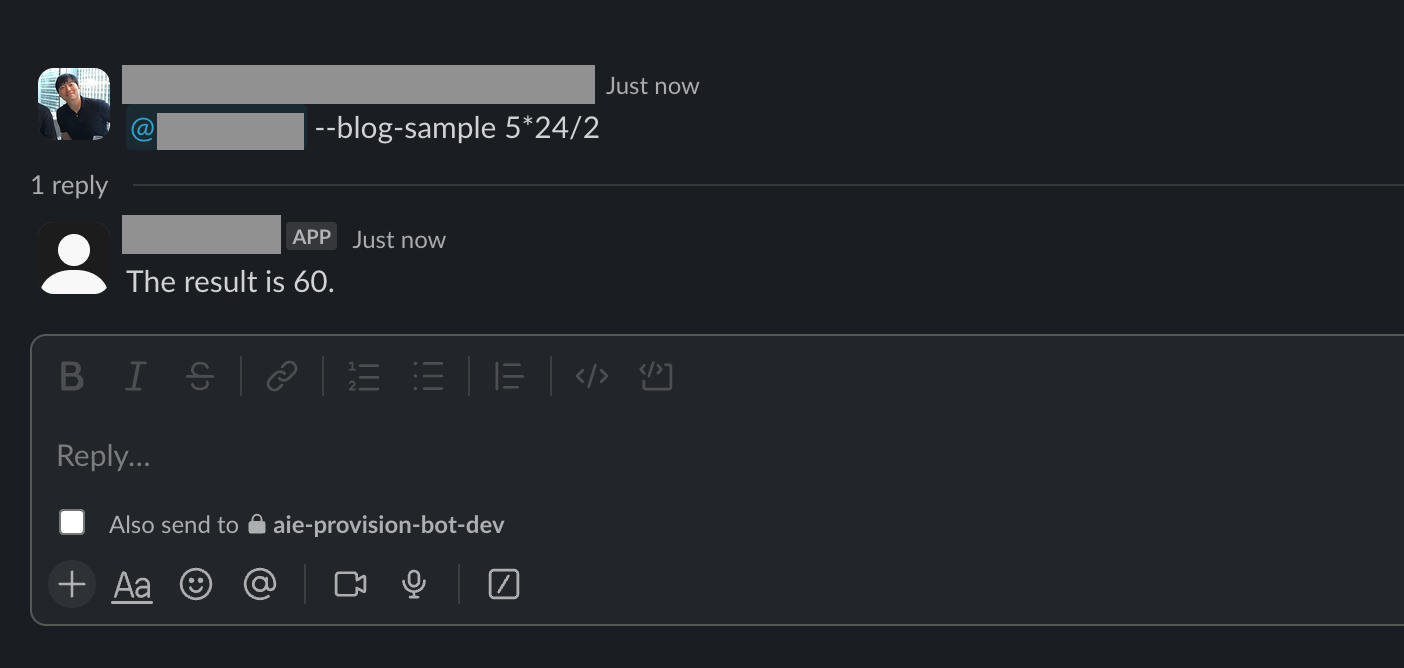
이와 같이 쉽게 만들어 배포할 수 있는 환경을 구축한 결과 현재 저희 조직에서는 직군에 상관없이 많은 분들이 업무에 필요한 LLM 애플리케이션들을 직접 만들어 배포까지 할 수 있게 되었습니다.
마치며
지금까지 직군에 상관없이 LLM 애플리케이션을 쉽게 만들고 배포할 수 있는 환경을 구축하면서 했던 고민과 그 고민을 해결한 방법을 설명드렸습니다. 이 작업을 통해 LLM 애플리케이션의 작업 주기를 단축할 수 있었고, 이를 통해 애플리케이션의 결과를 개선하는 데 더욱 많은 시간을 쓸 수 있게 되었습니다. 이 글이 저희와 비슷한 고민을 하고 계신 분들에게 조금이나마 도움이 된다면 기쁠 것 같습니다. 긴 글 읽어주셔서 감사합니다.


