Tekton을 이용한 성능 테스트
지난 1편에서 LINE 광고 플랫폼에서 사용하는 대용량 스트리밍 파이프라인의 특징을 살펴보면서, 이와 같은 데이터 스트리밍 애플리케이션의 성능을 측정할 때에는 통합 테스트(integration test) 환경을 구축한 뒤 직접 애플리케이션을 통해 데이터를 흘려보내서 테스트하는 것이 가장 효율적이라고 말씀드렸습니다. 또한 통합 테스트 환경을 구축할 때에는 여러 가지 설정을 통해 반복 작업을 간편하게 실행하고 관리할 수 있게 해주는 쿠버네티스 네이티브 워크플로가 필요하다고 말씀드렸습니다.
이번 2편에서는 쿠버네티스 네이티브 워크플로 중 Tekton을 이용해 성능을 테스트한 방법을 살펴보겠습니다.
테스트 대상 애플리케이션 소개
성능 테스트의 대상이 될 애플리케이션은 앞서 1편에서 말씀드린 LINE 광고 데이터 스트리밍 애플리케이션(이하 전처리기)입니다. 성능 테스트의 상세한 내용을 살펴보기 전에 전처리기의 구조를 간단히 소개하겠습니다.
Apache Heron 애플리케이션 소개
Apache Heron(이하 Heron)은 오픈소스 분산 스트림을 처리하기 위한 프레임워크입니다. 전처리기에서 Apache Kafka 브로커에서 읽어들인 데이터를 처리하기 위해 사용하고 있습니다. Heron은 데이터 변환 작업을 용도에 맞게 여러 �단계로 나눠 처리할 수 있도록 지원하며, 각 단계별로 설정을 다르게 할 수 있다는 특징이 있습니다. 이를 통해 병렬로 처리하는 수준을 다르게 설정하거나 메모리를 다르게 할당하는 등 조금 더 세밀하게 조정할 수 있습니다. 예를 들어, 전처리기는 Heron 프레임워크를 기반으로 데이터를 세 단계로 나눠 처리하는데요. Kafka 브로커로부터 데이터를 읽어들이는 Spout, 읽어 온 데이터를 처리하는 Transformer, 마지막으로 Kafka 브로커로 데이터를 적재하는 Publisher로 구성돼 있습니다. 각 단계는 병렬 처리 수준이나 할당된 리소스 등의 설정이 다릅니다.
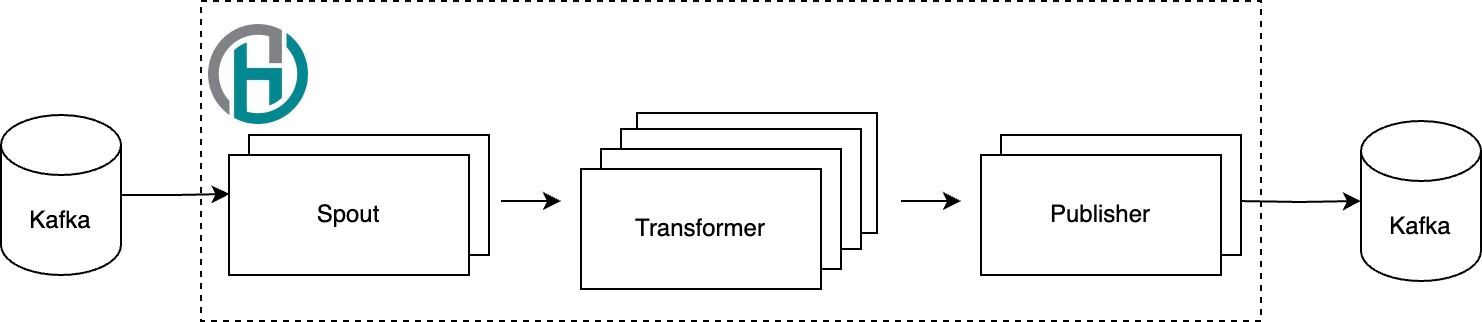
튜닝 포인트
각 단계별로 설정을 달리 할 수 있는 Heron 애플리케이션의 특징은, 다르게 말하면 사용자 입장에서 설정해야 할 부분이 늘어난 것이라고 볼 수 있습니다. 더 높은 성능을 얻기 위해서는 각 설정을 조금 더 세밀하게 튜닝할 필요가 있는데요. 그중에서 특별히 집중했던 설정은 아래 네 가지입니다. 참고로 여기서 컴포넌트란 앞서 말씀드린 Spout, Transformer, Publisher과 같은 각 단계의 프로세스들을 의미합니다.
- 각 컴포넌트의 병렬 처리 수준
- 각 컴포넌트에 할당하는 리소스의 양(CPU, RAM, 디스크)
- Heron 프레임워크 토폴로지 설정
- Kafka 클라이언트 설정
Tekton 소개
Tekton은 클라우드 네이티브 CI/CD 프레임워크입니다. Tekton의 주요 컴포넌트인 Tekton Pipelines는 쿠버네티스 커스텀 리소스를 활용해 CI/CD 파이프라인을 구축하기 위한 기본 구성 요소를 제공합니다.
기본적인 Tekton Pipelines 사용 방법
Tekton Pipelines는 커스텀 리소스인 Task와 Pipeline을 기반으로 쿠버네티스 네이티브하게 작동하며, 직·병렬 실행과 조건부 실행, 반복 실행 등 여러 기능을 지원하고 있습니다.
Tekton Pipelines의 핵심 개념인 Step과 Task, Pipeline을 자세히 살펴보겠습니다.
Step
Step은 Tekton에서 워크플로를 구성하는 가장 기본적인 실행 단위입니다. 각 Step은 지정된 이미지를 쿠버네티스 파드 안의 컨테이너로 실행합니다.
Task
Task는 순서가 있는 Step의 모음으로, 각 Task가 실행될 때마다 별도의 쿠버네티스 파드가 생성됩니다. 파드 내에서는 각 Step이 독립적인 컨테이너로 실행돼 서로 연관된 Step들이 같은 환경 설정이나 볼륨을 공유할 수 있습니다. 아래는 "Hello world!"를 출력하는 Task의 예시입니다.
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: hello-world-task-example
spec:
steps:
- name: hello-world
image: busybox
command:
- echo
args:
- "Hello, world!"steps 하위에 더 많은 Step을 추가해 연속적으로 실행할 수도 있습니다.
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: hello-and-goobye-world-task-example
spec:
steps:
- name: hello-world
image: busybox
command:
- echo
args:
- "hello, world!"
- name: goodbye-world
image: busybox
command:
- echo
args:
- "goodbye, world!"Pipeline
Pipeline은 여러 Task를 포함하며, 복잡한 작업 흐름을 위해 Task 간 팬인(fan-in) 및 팬아웃(fan-out) 설정을 지원합니다. Task는 DAG(Directed Acyclic Graph)로 구성돼 있어서 앞선 Task가 모두 완료된 후에 다음 Task가 실행됩니다. 아래는 Pipeline의 예시입니다.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: pipeline-example
spec:
tasks:
- name: process-a # Run by parallel with process-b
taskSpec:
steps:
- image: busybox
command:
- echo
args:
- "Process[A0] work!"
- name: process-b-0 # Run by parallel with process-a
taskSpec:
steps:
- image: busybox
command:
- echo
args:
- "Process[B0] work!"
- name: process-b-1 # Run after process-b-0 complete
runAfter:
- process-b-0
taskSpec:
steps:
- image: busybox
command:
- echo
args:
- "Process[B1] work!"process-a와 process-b-0는 병렬로 동시에 실행되나, process-b-0와 process-b-1은 직렬로 실행됩니다.
NAME TASK NAME STARTED DURATION STATUS
∙ pipeline-example-run-zj6h7-process-b-1 process-b-1 29 seconds ago 6s Succeeded
∙ pipeline-example-run-zj6h7-process-a process-a 36 seconds ago 9s Succeeded
∙ pipeline-example-run-zj6h7-process-b-0 process-b-0 36 seconds ago 7s Succeeded복합 사용 예시
아래는 Step과 Task, Pipeline을 모두 사용한 복합 예시입니다. Task A의 예시에서 쿠버네티스 매니페스트 파일을 수정하는 Step 1이 완료되면, 해당 변경 사항을 적용하는 Step 2가 실행됩니다. Task A가 완료되면 Task B와 C가 동시에 실행되며, 이들이 모두 완료되면 Task D가 실행됩니다.
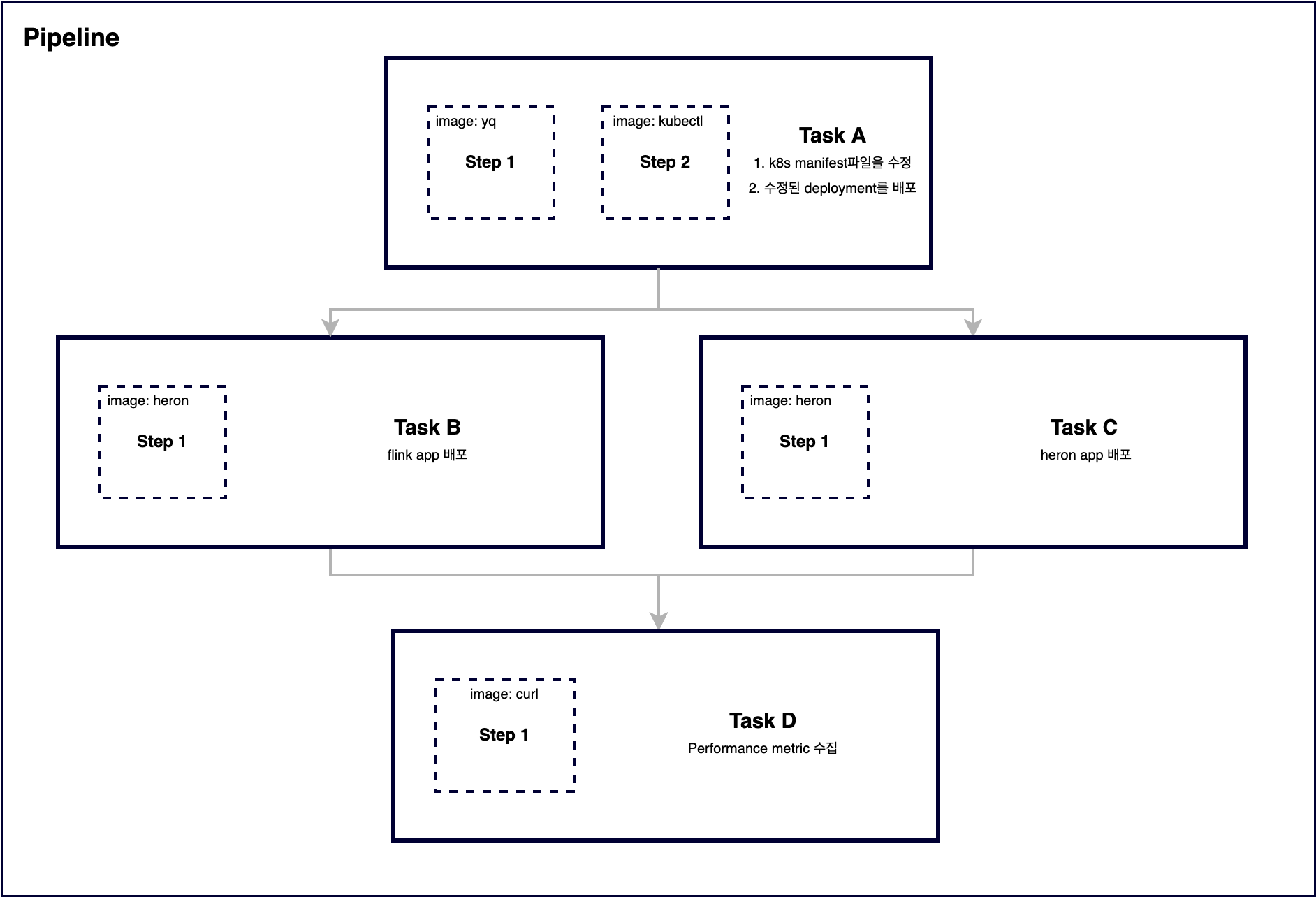
위 다이어그램을 약식 예시로 표현하면 아래와 같습니다. Pipeline은 Task를 레퍼런스로 가져올 수 있고, Task 간 순서를 runAfter를 통해 지정할 수 있습니다. Pipeline 커스텀 리소스의 태스크 역시 Task 커스텀 리소스와 동일하게 steps를 사용할 수 있습니다.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: composite-pipeline-example
spec:
tasks:
- name: task-a
taskSpec:
steps:
- name: step-1
image: busybox
command:
- echo
args:
- "yq"
- name: step-2
image: busybox
command:
- echo
args:
- "kubectl"
- name: task-b
runAfter:
- task-a
taskRef:
kind: Task
name: print-task
params:
- name: message
value: "deploy flink app"
- name: task-c
runAfter:
- task-a
taskRef:
kind: Task
name: print-task
params:
- name: message
value: "deploy heron app"
- name: task-d
runAfter:
- task-b
- task-c
taskRef:
kind: Task
name: print-task
params:
- name: message
value: "collect prom metrics"
---
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: print-task
spec:
params:
- name: message
type: string
description: Message to be printed
default: ""
steps:
- name: print
image: busybox
command:
- echo
args:
- "$(params.message)"사내 도구 PIPE 활용
Tekton을 활용하기 위해서는 쿠버네티스 클러스터가 필요하며, 해당 클러스터에 tekton-pipelines-controller와 CRD(custom resource definitions) 등 다양한 쿠버네티스 오브젝트를 설치해야 합니다. 저희 팀은 이런 환경을 별도로 구축하는 대신, 회사 내부에서 개발된 PIPE라는 도구의 워크플로를 사용하기로 결정했습니다.
PIPE에 대한 더 자세한 내용은 PIPE: 더 나은 개발자 경험을 제공하기 위한 CI/CD를 참고해 주시기 바랍니다.
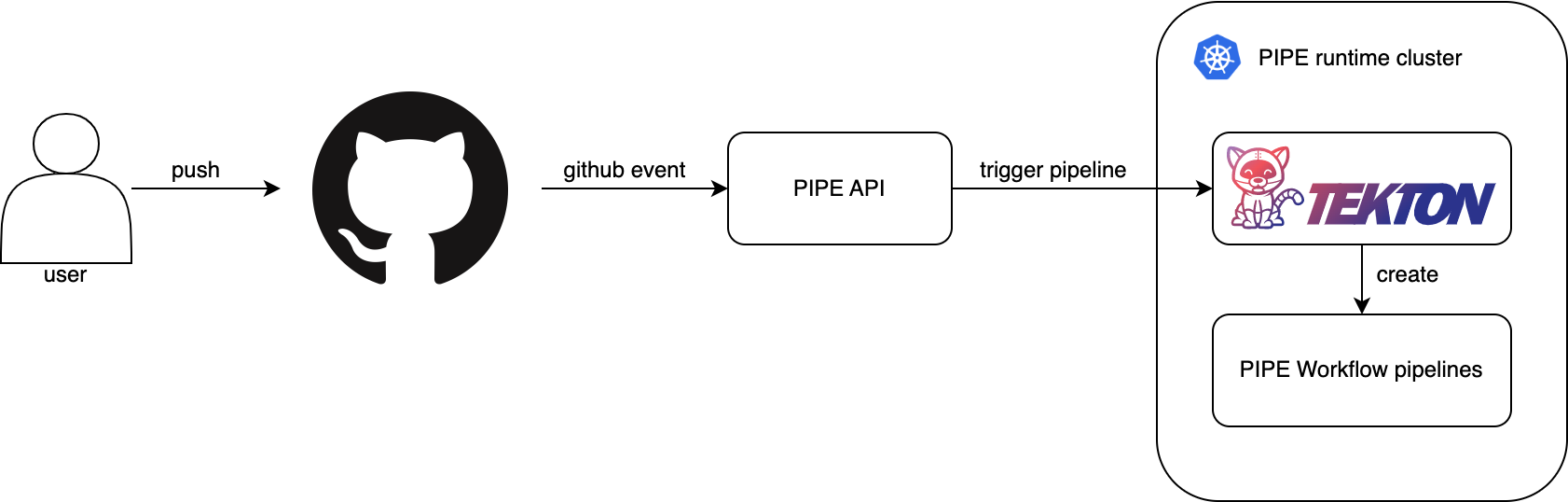
PIPE 워크플로는 Tekton Pipelines의 기능과 GitHub 이벤트를 결합한 모델로, GitHub 이벤트를 기반으로 워크플로의 시작을 트리거할 수 있는 구조입니다. PIPE의 작동 과정은 다음과 같습니다.
- 개발자가 GitHub에 코드를 푸시하거나 PR(pull request)을 생성하는 등의 액션을 실행합니다.
- GitHub에서 발생한 이벤트는 웹훅을 통해 PIPE 서버로 전달됩니다.
- PIPE 서버는 수신한 GitHub 이벤트가 어노테이션으로 설정돼 있는 Tekton Pipeline 파일이 개발자의 리포지터리 내에 존재하는지 확인합니다.
- 조건에 부합하는 Tekton Pipeline 파일을 찾으면, PIPE는 해당 파일을 템플릿으로 사용해 PIPE 런타임 클러스터에 Tekton Pipeline을 생성합니다.
- 실행된 Tekton Pipeline의 결과는 GitHub에 커밋 상태로 반영되며, GitHub UI를 통해 확인할 수 있습니다.
Tekton 기반의 성능 테스트 시스템 구축 및 운영 방법
LINE 광고 플랫폼의 데이터 파이프라인에서는 전처리기의 성능을 검증하고 향상시키기 위해 Tekton 기반의 성능 테스트를 진행했습니다. 실제 서비스에서 사용하는 애플리케이션의 설정 중 튜닝 포인트라고 생각하는 설정들을 빌드 없이 유동적으로 변경하기 위한 사전 작업(dynamic configuration)을 진행한 뒤 아래와 같은 Tekton 기반 워크플로를 구성했습니다.
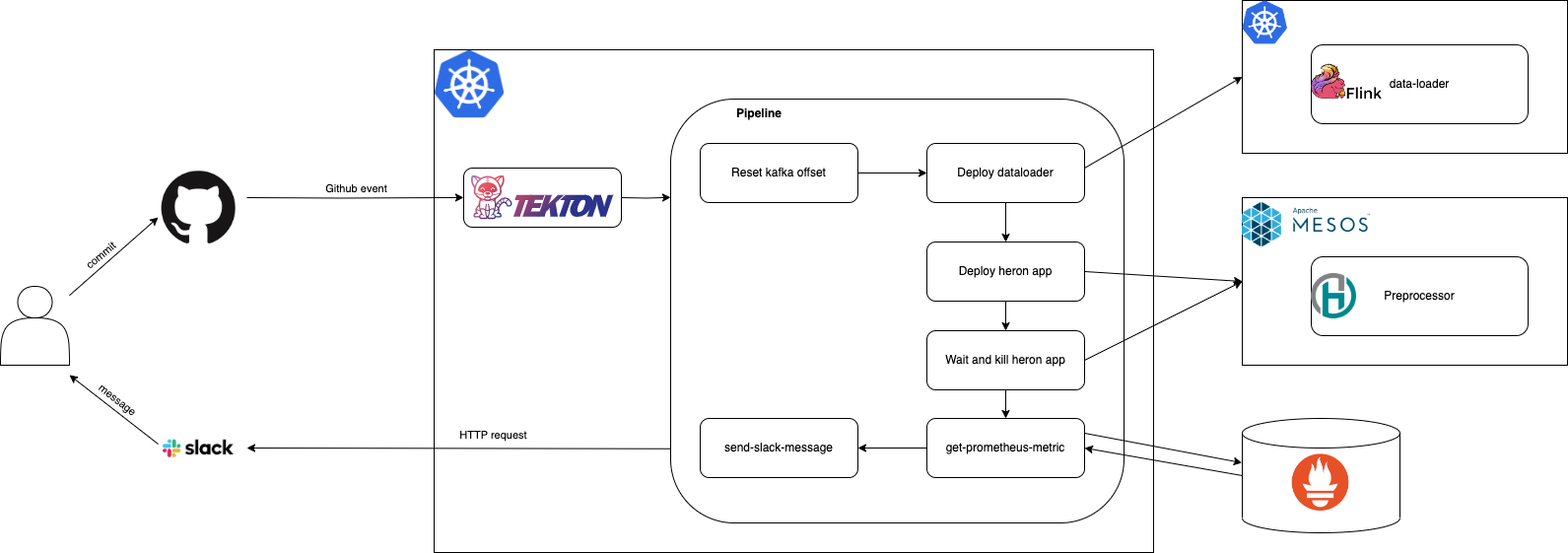
사용자는 Git 커밋을 통해 GitHub 이벤트를 발생시키고, Tekton은 이 이벤트를 기반으로 일련의 성능 테스트를 진행합니다. 성능 테스트 워크플로를 '테스트 환경 구축'과 '테스트 결과 리포트 생성'의 두 단계로 분류해 조금 더 자세히 살펴보겠습니다.
테스트 환경 구축
동적 설정 변경(dynamic configuration)
기존에 사용하던 Heron 애플리케이션에서는 각 컴포넌트의 병렬 처리 수준과 리소스 할당을 애플리케이션의 설정 파일에서 관리하면서 JAR 파일과 함께 패키징했습니다. 이 때문에 성능 테스트 과정에서 설정을 변경하려면 매번 다시 빌드해야 했기에 매우 비효율적으로 진행할 수밖에 없었습니다.
이 문제를 해결하기 위해 설정 값을 애플리케이션 배포 시점에 오버라이딩할 수 있도록 코드를 수정하고, deploy-heron-app이라는 Tekton Task를 만들어 이를 반영했습니다.
코드 변경
먼저 애플리케이션의 설정 파일에서 테스트를 반복��하며 변경할 필요가 있는 동적 설정(preprocessor-dynamic)과 변경이 필요하지 않은 정적 설정(preprocessor-static)을 나눠 아래와 같이 분리했습니다.
preprocessor-static {
kafka {
group.id = "preprocessor-staging"
}
}
preprocessor-dynamic {
kafka {
input {
parallelism = 10
max.poll.records = 4000
}
}
topology {
component.resourcemap {
kafkaSpout {
cpu = 1.5
ram = 2GB
disk = 1GB
}
}
}
}이후 Typesafe Config 라이브러리를 활용해 두 종류의 설정을 각기 다른 방법으로 읽었습니다. 정적 설정은 설정이 위치한 경로를 명시적으로 지정해 읽도록 했습니다. 반면 동적 설정은 시스템 프로퍼티로 설정된 값을 우선 불러온 뒤, withFallback()을 통해 시스템 프로퍼티로 설정되지 않은 경로만 설정 파일에서 값을 불러오도록 코드를 작성했습니다. 이렇게 하면 배포 시점에 시스템 프로퍼티로 설정 파일 값을 오버라이딩할 수 있습니다.
import com.typesafe.config.ConfigFactory;
val profile = "preprocessor";
final var staticAppConf = ConfigFactory.load().getConfig(profile + STATIC_SUFFIX);
final var dynamicAppConf = ConfigFactory.load() // 시스템 프로퍼티가 우선적으로 로드됨
.withFallback(ConfigFactory.load().getConfig(profile + DYNAMIC_SUFFIX)); // 시스템 프로퍼티로 설정되지 않은 값들은 application.conf파일에서 불러옴Tekton 커스텀 Task
쿠버네티스에서 Tekton Task를 생성하면, 같은 네임스페이스의 Tekton Pipeline에서는 taskRef에 명시적으로 Task 이름을 지정해서 불러오는 것이 가능합니다. 저희는 deploy-heron-app Task를 생성하고 동적 설정을 매개 변수화했습니다. 이후 아래와 같이 Tekton Pipeline을 정의하는 파일에서 변경하고자 하는 값들을 매개 변수로 전달해 실험을 반복할 수 있었습니다.
name: deploy-staging-app
params:
- name: spout-parallelism
default: 10
- name: spout-cpu
default: 1.0
- name: spout-ram
default: 2.0
taskRef:
name: deploy-heron-app
kind: Task전달된 값들은 deploy-heron-app Task가 실행될 때 Heron CLI 명령어의 일부로 치환돼 실행됩니다.
$ heron submit --topology-main-jvm-property kafka.input.parallelism=$(params.spout-parallelism) \
--topology-main-jvm-property topology.component.resourcemap.kafkaSpout.cpu=$(params.spout-cpu) \
--topology-main-jvm-property topology.component.resourcemap.kafkaSpout.ram=$(params.spout-ram) 데이터 적재
성능 테스트가 진행되는 동안 충분한 양의 데이터가 테스트용 Kafka 토픽으로 흐를 수 있도록 운영 환경의 데이터를 원하는 만큼 테스트 토픽으로 전송하는 애플리케이션인 'data-loader'을 개발했습니다.
data-loader는 데이터 수를 매개 변수로 받아서 별다른 처리 없이 Kafka에서 Kafka로 전송하는 역할을 담당하는 Apache Flink 애플리케이션입니다. Flink의 Kafka Connector는 스트리밍 모드뿐 아니라 배치 모드로도 작동할 수 있으며, stopping offset을 지정해 정해진 양의 데이터만 전송할 수도 있습니다.
data-loader의 배포는 미리 생성한 deploy-dataloader Task를 taskRef로 불러온 뒤 Tekton Pipeline 파일에서 필요한 매개 변수를 설정하는 방식으로 진행했습니다. 아래와 같이 테스트 시간(duration-min)과 초당 데이터 수(data-count-per-second)를 설정하면, 이 두 값을 곱한 수 만큼의 데이터를 테스트용 토픽으로 전송합니다.
name: load-data
params:
- name: duration-min
default: 30
- name: data-count-per-second
default: 10000
taskRef:
name: deploy-dataloader
kind: Task테스트 결과 리포트 생성
테스트 변경 이력과 결과를 기록하는 방법을 살펴보고, Prometheus로 성능 테스트 결과 지표를 수집해 Slack 메시지로 전송하는 과정을 살펴보겠습니다.
변경 이력 및 테스트 결과 기록
반복해서 성능 테스트를 진행하기 때문에 매번 진행할 때마다 변경한 내용과 테스트 결과를 기록으로 남기고 싶었습니다. 이를 위해 성능 테스트를 트리거하기 위한 PR을 생성하고 동기화 이벤트가 발생할 때 마다, 즉 새로운 커밋이 추가될 때마다 Tekton Pipeline이 실행되도록 어노테이션을 설정했습니다.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: cd-stage
annotations:
pipe.linecorp.com/event: |
pull_request:
branches:
- staging/**
types:
- synchronize위와 같이 설정하면 커밋 기록이 곧 테스트 기록이 됩니다. 또한 커밋 메시지에 어떤 테스트를 진행했는지 간략하게 적어 놓으면 다른 사람들도 자신이 진행한 테스트가 아니더라도 내용을 쉽게 파악할 수 있습니다.

성능 지표를 수집해 Slack 메시지로 전송
Pipeline의 마지막 두 Task의 이름은 get-prometheus-metric과 send-slack으로, 애플리케이션 지표는 모두 지정된 Prometheus로 수집합니다.
get-prometheus-metricget-prometheus-metric은 정해진 시간 동안 Heron 애플리케이션이 생성하는 지표를 PromQL로 조회해 성능 지표 리포트를 생성하는 Task입니다. 테스트 지속 시간은 Tekton Pipeline의 매개 변수로 매번 다르게 지정할 수 있습니다. 초당 처리량, 평균 지연시간 등 관심 있는 지표를 생성하기 위해 PromQL이 포함된 HTTP 요청을 Prometheus DB로 전송한 뒤 수신 결과를 파싱해 사람이 읽기 편한 형식으로 변환합니다.
$ curl -fs --data-urlencode query='avg(avg_over_time(heron_complete_latency{topology="preprocessor",env="staging"}[$(params.duration)m]))' '$prometheus_endpoint'send-slackget-prometheus-metricTask에서 생성한 메시지를 지정된 Slack 채널로 전송합니다.
두 Task를 통해 성능 테스트가 종료될 때마다 요약된 결과를 바로 Slack 메시지로 받아볼 수 있습니다.
Tekton 기반 성능 테스트 시스템 적용 결과
기존에는 설정 하나를 변경하고 테스트하기 위해서 애플리케이션을 프로덕션과 동일한 규모로 스테이징 환경에 한 벌 더 배포해 일주일 이상 테스트를 수행하면서 결과를 분석해야 했습니다. 요일 및 시간대별로 유입되는 데이터의 양이 다른데 데이터가 가장 많이 유입되는 시점에서도 애플리케이션이 정상적으로 작동하는지를 테스트해야 했기 때문입니다.
하지만 Tekton을 이용한 컨테이너 기반의 워크플로를 구성하고 애플리케이션 설정도 동적으로 적용할 수 있도록 구성한 뒤에는 코드 커밋 한 번으로 다양한 변수와 물리적 규모, 유입되는 데이터의 크기를 조정하면서 스트리밍 애플리케이션의 성능을 쉽고 빠르게 측정할 수 있게 됐습니다. 기존에는 하나를 검증하기 위해 일주일간 테스트를 수행했다면 이제 이 시스템을 이용해 2주 동안 약 50회 이상의 실험을 진행할 수 있는 것입니다.
이 시스템을 이용해 진행한 테스트의 구체적인 내용과 결과는 다음과 같습니다.
성능 최적화 테스트
Heron 애플리케이션의 처리량을 높이면서 동시에 최적의 리소스를 찾기 위해 아래와 같은 요인을 고려했습니다.
- Kafka 클라이언트 설정
- Heron 토폴로지 설정
- Heron 토폴로지의 컴포넌트별 할당 리소스
- Heron 토폴로지의 컴포넌트별 병렬 처리 수준
다양한 실험과 반복 검증을 통해 다음과 같은 결과를 얻었습니다.
- 각 컴포넌트별 성능 저하가 없는 최적의 리소스양
- 백프레셔(backpressure) 없는 최적의 컴포넌트 조합
- 최적의 조합으로 구성했을 때 예상되는 처리 가능 트래픽양
예를 들어 다른 변인을 고정시킨 뒤 진행한 실험에서는 아래와 같이 각 컴포넌트의 초당 처리량을 구할 수 있었습니다.
| 컴포넌트 | TPS |
|---|---|
| Spout | 10,000 |
| Transformer | 350 |
| Publisher | 3,500 |
이를 바탕으로 계산한 최적의 조합은 1:28:3 (spout: transformer: publisher)입니다. 1개의 Spout, 28개의 Transformer, 3개의 Publisher로 구성한 토폴로지는 초당 10,000건의 데이터를 처리할 수 있다는 것을 확인한 것입니다.
최적의 조합에서 병렬 처리 수준을 높이면 성능이 특정 지점까지는 비교적 선형적으로 향상된다는 것도 확인할 수 있었습니다. 이는 향후 처리해야 할 트래픽이 증가했을 때 스케일아웃만으로도 충분히 대응할 수 있는, 예측 가능한 토폴로지 구성이라는 것을 의미합니다. 실제로 프로덕션 환경에서 전처리기는 초당 20만 건의 데이터를 처리해야 하는 요구 사항이 있었는데요. 위에서 찾은 조합을 약 20배로 스케일아웃해 대응할 수 있었습니다.
새로운 조합은 리소스 활용 측면에서도 효율적이었습니다. 성능 저하를 발생시키지 않는 최적의 리소스를 구했기 때문입니다. 이를 통해 기존 시스템과 같은 리소스를 사용하면서도 처리량이 50% 이상 향상된 토폴로지를 배포할 수 있었습니다.
아키텍처별 성능 비교 테스트
구축한 워크플로를 활용해 스트리밍 애플리케이션의 아키텍처 변경을 검토할 때 각기 다른 구성의 성능을 쉽게 비교해 볼 수 있었습니다. 인메모리 캐시와 Heron의 조합, Heron과 외부 DB(Redis), Flink 기반의 구성을 검토했는데요. 세 가지 시나리오의 벤치마크 데이터를 빠르게 확보할 수 있어서 의사 결정에 큰 도움이 됐습니다. 자동화한 시스템이 없었다면 이 검증 또한 프로덕션 규모로 한 달 이상 검증해야 할 내용이었습니다.
마치며
이번 글에서는 LINE 광고 플랫폼의 대용량 스트리밍 파이프라인의 성능 테스트 시스템을 Tekton 기반으로 구축한 사례를 소개했습니다. Tekton 기반으로 구축한 성능 테스트 시스템을 이용해 테스트 편의성을 높일 수 있었고, 테스트에 들어가는 시간과 리소스를 절약한 것은 물론 시스템의 성능 관점의 특성을 파악해 트래픽 증가에도 문제 없이 대처할 수 있었습니다.
이 시리즈의 마지막 글인 3편에서는 Litmus를 이용해 카오스 테스트를 진행한 사례를 살펴보겠습니다. 많은 기대 바랍니다.


