LitmusChaos를 이용해 카오스 테스트 시스템 구축하기
이번 글은 쿠버네티스 네이티브 워크플로를 이용한 대용량 스트리밍 파이프라인 검증 자동화 시리즈의 마지막 글입니다. 지난 1편과 2편은 아래 링크에서 확인하실 수 있습니다.
지난 2편에서는 Tekton 기반으로 성능 테스트 시스템을 구축한 사례를 소개했는데요. 이번 글에서는 LitmusChaos를 이용해 카오스 테스트를 진행한 사례를 소개하겠습니다.
카오스 테스트 대상 애플리케이션 소개 및 카오스 테스트가 필요한 이유
카오스 테스트의 대상 애플리케이션은 Apache Flink 프레임워크 기반의 전처리기입니다. LINE 광고 데이터 파이프라인에서는 앞서 2편에서 말씀드렸던 Heron 프레임워크 기반의 전처리기를 대체할 다음 버전의 전처리기로 Flink 프레임워크 기반의 전처리기를 준비하고 있으며, 이를 도입하기 준비하는 과정에서 LitmusChaos 기반의 카오스 엔지니어링을 진행했습니다.
Apache Flink 시스템 소개
Apache Flink(이하 Flink)는 데이터 스트리밍을 지원하는 분산 처리 엔진으로, 자체 상태 저장소를 갖추고 있기 때문에 스테이트풀(stateful)한 연산이 가능하다는 특징이 있습니다. 아래는 쿠버네티스 환경에서 실행되는 Flink 애플리케이션의 구조를 간략히 나타낸 그림입니다.
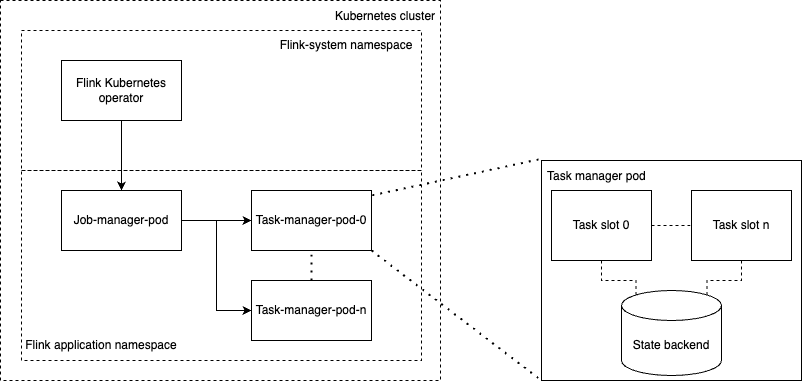
Flink 프레임워크에서는 하나의 Flink 애플리케이션을 '잡(job)'이라고 표현합니다. 하나의 잡은 Flink의 기초 실행 단위인 '태스크(task)'로 구성되는데요. Flink는 이 태스크라는 실행 단위를 통해 데이터를 분산 처리합니다.
위 구조에서 'Flink 시스템 네임스페이스(Flink-system namespace)'의 'Flink 쿠버네티스 오퍼레이터(Flink Kubernetes operator)'는 쿠버네티스 커스텀 리소스(이하 커스텀 리소스)와 오퍼레이터 패턴을 기반으로 Flink 애플리케이션의 배포와 업그레이드 등의 작업을 담당합니다.
오퍼레이터가 배포한 Flink 애플리케이션은 크게 '잡 매니저(job manager)'와 '태스크 매니저(task manager)'로 나뉜 파드들을 갖고 있습니다. 잡 매니저는 잡의 태스크를 어떤 태스크 매니저에서 실행할지 결정하고 태스크 매니저의 상태를 관리하는 등 잡을 관리하는 역할을 담당하며, 태스크 매니저는 태스크를 직접 실행하는 역할을 담당합니다. 이 두 매니저를 묶어서 'Flink 클러스��터'라고 칭합니다.
Flink 쿠버네티스 오퍼레이터가 관리하는 Flink 애플리케이션에는 크게 두 가지 모드가 있습니다. 각 애플리케이션이 독립적으로 Flink 클러스터를 각각 하나씩 갖는 애플리케이션 모드가 있고, 하나의 Flink 클러스터를 여러 애플리케이션이 공유하며 각 애플리케이션이 해당 Flink 클러스터에 세션 잡(session job) 형태로 제출되는 방식으로 작동하는 세션 모드가 있습니다.
애플리케이션 모드는 잡 매니저 및 태스크 매니저를 하나의 애플리케이션이 독점하기 때문에 독립성이 높습니다. 반면 세션 모드의 경우 Flink 클러스터를 애플리케이션과 별도로 따로 가동하고 해당 클러스터에 Flink 세션 잡을 제출하는 방식으로 작동합니다. 여러 애플리케이션이 하나의 Flink 클러스터를 공유하기 때문에 태스크 매니저의 태스크 슬롯에 빈 슬롯이 없을 경우 스케줄링되지 않을 수 있습니다.
LINE 광고 데이터 파이프라인에서는 애플리케이션이 자신이 점유하는 자원을 독립적으로 활용할 수 있도록 애플리케이션 모드를 사용하고 있습니다. 즉, Flink 클러스터에서 실행되는 잡은 하나라고 전제하고 카오스 테스트를 진행했습니다.
카오스 테스트의 필요성
위와 같은 Apache Flink 프레임워크 기반의 전처리기를 운영할 때에는 다음과 같은 상황에 대비해야 합니다.
- 잡 매니저 파드가 다운된다면?
- 태스크 매니저 파드 중 하나가 다운된다면?
- 어떤 파드의 네트워크가 일시적으로 먹통이 된다면?
- 쿠버네티스의 리소스가 부족한 상태에서 파드 하나를 새로 할당해야 한다면?
위와 같은 상황에서 Flink 쿠버네티스 오퍼레이터와 잡 매니저는 해당 Flink 애플�리케이션을 다시 정상 상태로 복원할 수 있을까요? 또한 복원됐을 때 태스크 매니저가 저장하고 있던 태스크의 상태가 제대로 복구될까요? 카오스 테스트는 이런 의문에 해답을 제시하고 시스템의 신뢰도를 보증합니다.
LitmusChaos 소개
LitmusChaos 프로젝트는 오픈소스 카오스 엔지니어링 프레임워크로, 여러 클라우드 플랫폼을 대상으로 카오스 엔지니어링을 지원합니다. 현재 CNCF(Cloud Native Computing Foundation)의 Incubating 프로젝트입니다.
LitmusChaos의 아키텍처 및 특징
사용자는 LitmusChaos의 포털 사이트인 ChaosCenter를 통해 카오스 엔지니어링을 진행할 수 있습니다. 테스트 시나리오는 ChaosCenter에서 제공하는 UI를 이용해 작성할 수도 있고, 쿠버네티스 네이티브 워크플로인 Argo Workflows를 기반으로 직접 작성해 제출할 수도 있습니다.
다음은 LitmusChaos 아키텍처를 간단히 표현한 그림입니다.
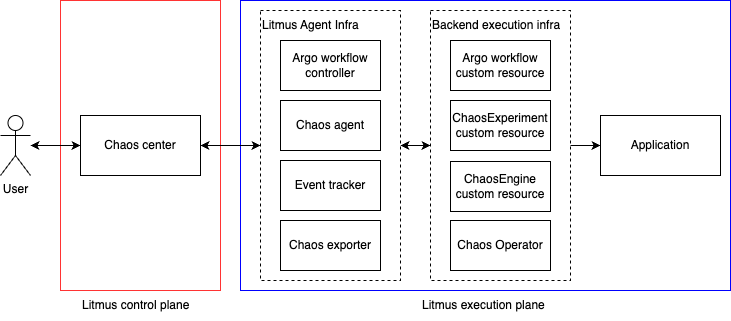
LitmusChaos는 크게 컨트롤 플레인(control plane)과 실행 플레인(execution plane)으로 나뉘어 있습니다.
컨트롤 플레인에는 ChaosCenter의 기능을 구현하기 위해 필요한 컴포넌트들이 포함돼 있습니다. 예를 들면 사용자의 신원을 파악하는 인증 서버나 카오스 엔지니어링 실행 이력을 보관하는 데이터베이스 등이 컨트롤 플레인에 포함됩니다.
실행 플레인에는 실제 오류를 �주입하기 위해 필요한 컴포넌트들이 포함돼 있습니다. 예를 들어 카오스 엔지니어링의 뼈대가 되는 Argo Workflows 컨트롤러나 오류를 주입하는 카오스 오퍼레이터(chaos operator) 등이 실행 플레인에 포함됩니다.
기본적인 LitmusChaos 사용 방법
LitmusChaos는 Argo Workflows를 기반으로 합니다. ChaosCenter의 웹 UI를 이용해 작성된 시나리오도 작동할 때에는 Argo Workflows를 기반으로 작동합니다. 따라서 LitmusChaos의 카오스 엔지니어링을 보다 깊이 이해하고 사용하기 위해서는 Argo Workflows의 사용법을 익혀야 합니다.
기본적인 Argo Workflows 사용 방법
Argo Workflows는 쿠버네티스를 기반으로 작동하며, 직·병렬 실행과 조건부 실행, 반복 실행 등의 여러 기능을 지원합니다. 아래는 간단한 Argo Workflows의 워크플로 예시입니다. print-hello-world라는 템플릿을 실행하는 워크플로이며, "Hello, world!"를 출력하고 종료됩니다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: hello-world
spec:
templates:
- name: print-hello-world
container:
image: busybox
command: ["echo", "Hello, world!"]
entrypoint: print-hello-worldspec.templates: 워크플로에서 실행될 각 단계의 구체적인 명세 사항을 포함합니다.spec.entrypoint: 워크플로가 시작할 때 실행되는 템플릿의 이름입니다.
직·병렬 실행 기능 사용 방법
아래는 Argo Workflows에서 어떻게 직렬과 병렬 실행을 제어할 수 있는지 살펴보기 위한 예시입니다. spec.templates.steps는 2차원 배열의 템플릿을 원소로 갖는데요. 여기서 고차원 원소들은 직렬로 실행되고, 저차원 원소들은 병렬로 실행됩니다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: serial-parallel-example
spec:
templates:
- name: serial-parallel-example
steps:
- - name: process-a-0 # Run before process b
template: process
arguments:
parameters:
- name: id
value: A0
- - name: process-b-0 # Run process-b-0 with process-b-1 by parallel
template: process
arguments:
parameters:
- name: id
value: B0
- name: process-b-1 # Run process-b-1 with process-b-0 by parallel
template: process
arguments:
parameters:
- name: id
value: B1
- name: process
inputs:
parameters:
- name: id
container:
image: busybox
command: ["echo", "Process[{{inputs.parameters.id}}] work!"]
entrypoint: serial-parallel-example이해를 돕기 위해 조금 더 자세히 살펴보겠습니다. 위 예시에서 spec.templates.steps에는 두 개의 원소가 있으며, 각 원소에는 각각 하나와 두 개의 원소가 있습니다.
spec.templates.steps = [
["process-a-0"], # process-a
["process-b-0", "process-b-1"] # process-b
]여기서 '고차원 원소는 직렬로 실행된다'의 의미는 'process-a가 실행된 후 process-b가 실행된다'는 것을 의미합니다. 또한 '저차원 원소는 병렬로 실행된다'의 의미는 'process-b-0와 process-b-1은 병렬로 실행된다'는 것을 의미합니다.
아래는 실행 결과입니다. 이와 같이 Argo Workflows는 템플릿의 구성을 통해 직·병렬 실행을 제어할 수 있습니다.
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ serial-parallel-example serial-parallel-example
├───✔ process-a-0 process serial-parallel-example-process-3403903862 4s
└─┬─✔ process-b-0 process serial-parallel-example-process-2087617974 4s
└─✔ process-b-1 process serial-parallel-example-process-2104395593 5s 조건부 실행 기능 사용 방법
Argo Workflows에서는 명령어 when을 이용해 조건을 지정할 수 있습니다. when을 사용하면 해당 조건에 충족하는 경우에만 해당 템플릿이 실행됩니다. 아래는 0이나 1을 랜덤하게 생성한 후 그 결과에 따라 다음에 실행할 템플릿을 설정하는 예시입니다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: conditional-example
spec:
templates:
- name: conditional-example
steps:
- - name: random
template: random
- - name: when-0
template: print-when-0
when: "{{steps.random.outputs.parameters.result}} == 0"
- name: when-1
template: print-when-1
when: "{{steps.random.outputs.parameters.result}} == 1"
- name: random
container:
image: busybox
command: ["sh", "-c", "echo $((RANDOM %2)) > /tmp/result.txt"]
outputs:
parameters:
- name: result
valueFrom:
path: /tmp/result.txt
- name: print-when-0
container:
image: busybox
command: ["echo", "0"]
- name: print-when-1
container:
image: busybox
command: ["echo", "1"]
entrypoint: conditional-example아래는 위 예시를 실행한 결과입니다. 임의로 생성된 값이 1이기에 print-when-0 템플릿은 실행되지 않고 스킵된 것을 확인할 수 있습니다.
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ conditional-example conditional-example
├───✔ random random conditional-example-random-1597183703 3s
└─┬─○ when-0 print-when-0 when '1 == 0' evaluated false
└─✔ when-1 print-when-1 conditional-example-print-when-1-391214529 3s Argo WorkflowTemplate 사용 방법
워크플로를 작성하다 보면 템플릿이 많아져 워크플로가 너무 길어지는 경우가 있습니다. 이를 막기 위해 일부 템플릿을 별도 커스텀 리소스로 등록해서 필요할 때 불러와 사용하는 것이 가능한데요. 이때 사용하는 커스텀 리소스가 바로 WorkflowTemplate입니다. WorkflowTemplate을 이용하면 같은 템플릿을 여러 워크플로에서 반복적으로 사용할 수 있습니다.
아래는 WorkflowTemplate을 사용한 예시입니다. templateRef을 이용해 WorkflowTemplate을 설정합니다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: using-template-example
spec:
templates:
- name: hello
steps:
- - name: hello-world
arguments:
parameters:
- name: message
value: hello, world!
templateRef:
name: example-template
template: print
entrypoint: hello
---
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: example-template
spec:
templates:
- name: print
inputs:
parameters:
- name: message
container:
image: busybox
command: ["echo", "{{inputs.parameters.message}}"]오류 주입 방법
LitmusChaos는 Chaos Experiment와 Chaos Engine이라는 커스텀 리소스를 기반으로 작동합니다. Chaos Experiment는 각각의 카오스를 발생시키기 위해 실행되는 명령어와 조정할 수 있는 변수 대한 정보를 담고 있습니다. Chaos Engine은 어떤 Chaos Experiment를 어떤 조건으로 어떤 대상에 주입할지에 대한 정보를 갖고 있습니다.
아래는 Chaos Experiment와 Chaos Engine 사용 예시입니다. install-chaos-experiments 단계에서 pod-delete라는 Chaos Experiment를 생성하고, pod-delete 단계에서는 앞 단계에서 생성된 Chaos Experiment를 어떻게 실행할지에 대한 정보를 담은 Chaos engine을 생성합니다.
kind: Workflow
apiVersion: argoproj.io/v1alpha1
metadata:
namespace: litmus
spec:
serviceAccountName: argo-chaos
arguments:
parameters:
- name: adminModeNamespace
value: litmus
entrypoint: custom-chaos
templates:
- name: custom-chaos
steps:
- - name: install-chaos-experiments
template: install-chaos-experiments
- - name: pod-delete
template: pod-delete
- name: install-chaos-experiments
inputs:
artifacts:
- name: pod-delete-experiment
path: /tmp/pod-delete.yaml
....
- name: pod-delete
inputs:
artifacts:
- name: pod-delete
path: /tmp/chaosengine-pod-delete.yaml
....어떤 앱에 오류를 주입할 것인지는 ChaosEngine.spec.appinfo에서 설정할 수 있습니다. 아래 예시는 chaos=target이라는 라벨이 있는 쿠버네티스 디플로이먼트를 대상으로 오류를 주입하는 예시입니다.
install-chaos-experiments 템플릿
- name: install-chaos-experiments
inputs:
artifacts:
- name: pod-delete-b7n
path: /tmp/pod-delete-b7n.yaml
raw:
data: >
apiVersion: litmuschaos.io/v1alpha1
description:
message: |
Deletes a pod belonging to a deployment/statefulset/daemonset
kind: ChaosExperiment
metadata:
name: pod-delete
labels:
name: pod-delete
app.kubernetes.io/part-of: litmus
app.kubernetes.io/component: chaosexperiment
app.kubernetes.io/version: 2.14.0
spec:
definition:
scope: Namespaced
permissions:
- apiGroups:
- ""
resources:
- pods
verbs:
- create
- delete
- get
- list
- patch
- update
- deletecollection
- apiGroups:
- ""
resources:
- events
verbs:
- create
- get
- list
- patch
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- apiGroups:
- ""
resources:
- pods/log
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods/exec
verbs:
- get
- list
- create
- apiGroups:
- apps
resources:
- deployments
- statefulsets
- replicasets
- daemonsets
verbs:
- list
- get
- apiGroups:
- apps.openshift.io
resources:
- deploymentconfigs
verbs:
- list
- get
- apiGroups:
- ""
resources:
- replicationcontrollers
verbs:
- get
- list
- apiGroups:
- argoproj.io
resources:
- rollouts
verbs:
- list
- get
- apiGroups:
- batch
resources:
- jobs
verbs:
- create
- list
- get
- delete
- deletecollection
- apiGroups:
- litmuschaos.io
resources:
- chaosengines
- chaosexperiments
- chaosresults
verbs:
- create
- list
- get
- patch
- update
- delete
image: litmuschaos/go-runner:2.14.0
imagePullPolicy: Always
args:
- -c
- ./experiments -name pod-delete
command:
- /bin/bash
env:
- name: TOTAL_CHAOS_DURATION
value: "15"
- name: RAMP_TIME
value: ""
- name: FORCE
value: "true"
- name: CHAOS_INTERVAL
value: "5"
- name: PODS_AFFECTED_PERC
value: ""
- name: LIB
value: litmus
- name: TARGET_PODS
value: ""
- name: NODE_LABEL
value: ""
- name: SEQUENCE
value: parallel
labels:
name: pod-delete
app.kubernetes.io/part-of: litmus
app.kubernetes.io/component: experiment-job
app.kubernetes.io/version: 2.14.0
container:
name: ""
image: litmuschaos/k8s:2.14.0
command:
- sh
- -c
args:
- kubectl apply -f /tmp/pod-delete-b7n.yaml -n
{{workflow.parameters.adminModeNamespace}} && sleep 30pod-delete 템플릿
- name: pod-delete-b7n
inputs:
artifacts:
- name: pod-delete-b7n
path: /tmp/chaosengine-pod-delete-b7n.yaml
raw:
data: |
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
namespace: "{{workflow.parameters.adminModeNamespace}}"
generateName: pod-delete-b7n
labels:
workflow_run_id: "{{workflow.uid}}"
spec:
appinfo:
appns: litmus
applabel: chaos=target
appkind: deployment
engineState: active
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
components:
env:
- name: TOTAL_CHAOS_DURATION
value: "30"
- name: CHAOS_INTERVAL
value: "10"
- name: FORCE
value: "false"
- name: PODS_AFFECTED_PERC
value: ""
probe: []
container:
name: ""
image: litmuschaos/litmus-checker:2.14.0
args:
- -file=/tmp/chaosengine-pod-delete-b7n.yaml
- -saveName=/tmp/engine-nameLitmusChaos 기반의 카오스 테스트 적용하기
앞서 말씀드렸듯 LINE 광고 데이터 파이프라인에서는 Flink 프레임워크를 도입하기 위해 LitmusChaos 기반 카오스 엔지니어링을 진행했습니다. 특정 장애 상황이 발생했을 때 어느 정도의 오차가 발생하는지 확인하기 위해 오류가 주입되지 않은 안정적인 애플리케이션(이하 스테이블(stable) 앱)과 오류가 주입될 불안정한 애플리케이션(이하 카오스 앱)을 동시에 배포한 뒤 그 차이를 비교하는 방식으로 진행했습니다.
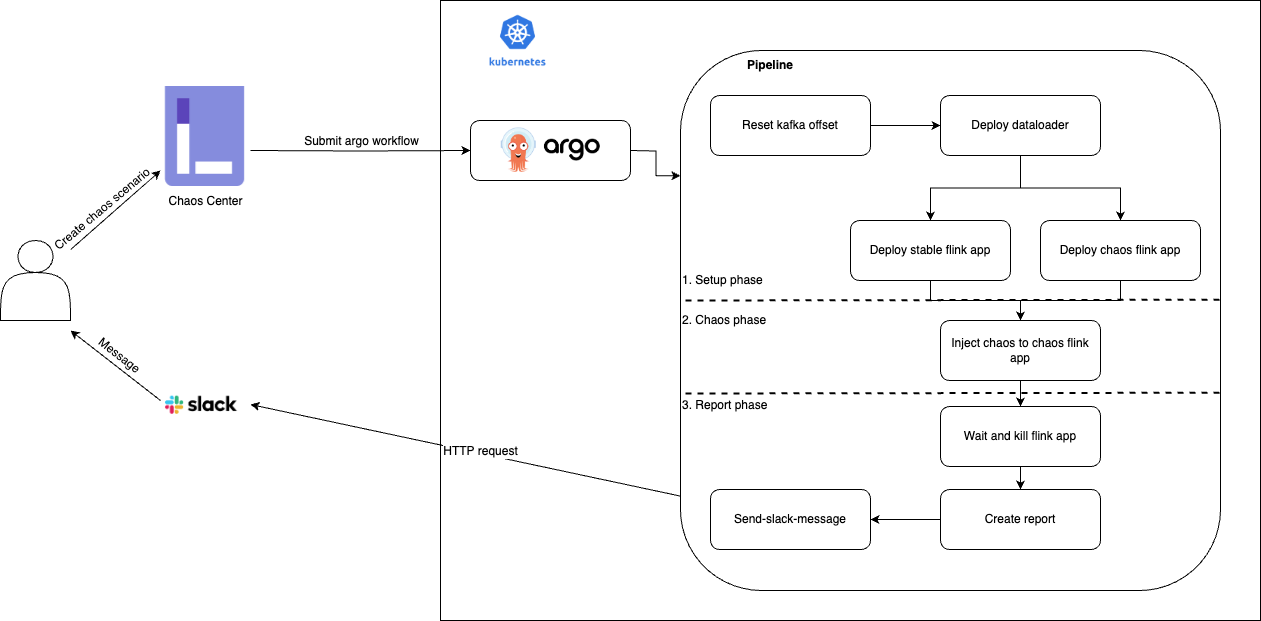
사용자는 LitmusChaos의 ChaosCenter를 통해 Argo Workflow가 정의된 파일을 제출하면서 카오스 시나리오를 생성합니다. 제출된 Argo Workflow는 쿠버네티스로 전달되고, 이를 Argo Workflows 컨트롤러가 실행합니다.
카오스 시나리오의 각 단계는 Argo Workflows의 WorkflowTemplate 커스텀 리소스의 형태로 정의해 사용합니다. 워크플로가 성공적으로 실행되면 사용자는 테스트 결과를 Slack으로 확인할 수 있는 구조입니다.
카오스 엔지니어링 워크플로를 카오스 테스트 환경 구성과 오류 주입, 리포트 생성의 세 단계로 분류해 조금 더 자세히 설명하겠습니다.
카오스 테스트 환경 구성
카오스 테스트 환경 구성에는 카오스 테스트를 위한 Source DB(Apache Kafka)를 초기화하는 과정과 애플리케이션을 배포하는 과정이 포함돼 있습니다. 매 테스트마다 Apache Kafka(이하 Kafka) 컨슈머의 오프셋을 latest로 조정하고 그 ��이후에 데이터를 쌓아서, 애플리케이션은 새로 쌓인 데이터만 소비하도록 구성했습니다. 이런 식으로 구성한 이유는 실제 데이터 스트리밍 환경을 최대한 비슷하게 재현하기 위해서인데요. Kafka와 같은 메시징 큐의 경우 최신 데이터를 메모리에 보관하고 있다가 디스크로 옮기기 때문에 이미 적재된 데이터를 사용하는 것과 새로 적재되고 있는 데이터를 사용하는 것에는 성능의 차이가 있습니다.
Kafka 초기화
Kafka는 생성자-소비자 패턴으로 사용하는 메시징 큐입니다. 토픽이라고 하는 논리적 그룹 단위가 있으며, 소비자는 토픽을 구독(subscribe)함으로써 데이터를 소비할 수 있습니다.
Kafka를 테스트 용도로 준비하는 경우 두 가지 선택지가 있습니다.
- 매 테스트마다 새로운 Kafka 토픽을 생성하고, 해당 Kafka 토픽에 테스트용 데이터를 적재한다.
- 고정된 테스트용 토픽을 하나 생성하고, 매 테스트마다 해당 토픽의 오프셋(offset)을 조정한다.
첫 번째 방식은 독립성이 높다는 장점이 있으나, 생성된 토픽을 테스트를 위해 한 번 사용한 뒤에는 매번 삭제해야 한다는 번거로움이 있습니다. 두 번째 방식은 동시에 여러 테스트를 진행하지 못한다는 단점이 있으나, 토픽이 무분별하게 생성되지 않아서 관리하기 편하다는 장점이 있습니다. 저희는 Kafka 토픽을 편히 관리하기 위해 두 번째 방식을 선택했습니다.
아래는 워크플로에서 사용한 Kafka 오프셋 초기화 워크플로 템플릿입니다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: kafka-templates
spec:
serviceAccountName: argo-chaos
templates:
- name: reset-offsets
inputs:
parameters:
- name: bootstrap-servers
- name: group-id
- name: topic
- name: option
value: "--to-latest"
script:
image: bitnami/kafka:1.1.1-debian-9-r307
command:
- sh
resources: { }
source: |
echo "Reset offsets."
kafka-consumer-groups.sh --bootstrap-server {{inputs.parameters.bootstrap-servers}} --group {{inputs.parameters.group-id}} --topic {{inputs.parameters.topic}} --reset-offsets {{inputs.parameters.option}} --execute데이터 적재
데이터 적재에는 2편에서 말씀드렸던 data-loader를 재사용했습니다. data-loader를 Flink 프레임워크를 기반으로 개발했기 때문에, 이를 배포하기 위한 워크플로 템플릿은 FlinkDeployment를 해당 쿠버네티스 클러스터에 적용시키는 과정을 포함하고 있습니다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: flink-templates
spec:
serviceAccountName: argo-chaos
templates:
- name: load-data
inputs:
parameters:
- name: data-count-to-load
resource:
action: apply
manifest: |
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: data-loader-chaos-test
namespace: litmus
spec:
....애플리케이션 배포
배포할 애플리케이션 역시 Flink 프레임워크 기반의 애플리케이션이기에 FlinkDeployment를 적용시키는 방식으로 구현했습니다.
스테이블 앱과 카오스 앱을 배포하기 위한 워크플로 템플릿을 작성해서 이를 반복 사용했는데요. 오류를 주입하기 위해서는 metadata.labels가 설정돼 있어야 하기에 카오스 앱의 경우 FlinkDeployment의 podTemplate에 chaos 라벨을 추가했습니다.
앱 배포 예시
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: flink-templates
spec:
serviceAccountName: argo-chaos
templates:
...
- name: deploy-stable-test-flink-preprocessor
inputs:
parameters:
- name: flink-checkpoint-interval
value: "20s"
- name: flink-checkpoint-timeout
value: "10s"
- name: job-manager-memory
value: "2048m"
- name: job-manager-cpu
value: 1
- name: task-manager-memory
value: "4096m"
- name: task-manager-cpu
value: 4
resource:
action: apply
manifest: |
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: stable-app
namespace: litmus
spec:
...
- name: deploy-chaos-test-flink-preprocessor
inputs:
parameters:
- name: flink-checkpoint-interval
value: "20s"
- name: flink-checkpoint-timeout
value: "10s"
- name: state
value: "running"
- name: upgrade-mode
value: "stateless"
- name: job-manager-memory
value: "2048m"
- name: job-manager-cpu
value: 1
- name: task-manager-memory
value: "4096m"
- name: task-manager-cpu
value: 4
resource:
action: apply
manifest: |
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: chaos-app
namespace: litmus
spec:
...
jobManager:
podTemplate:
metadata:
labels:
chaos: jobmanager
resource:
memory: {{inputs.parameters.job-manager-memory}}
cpu: {{inputs.parameters.job-manager-cpu}}
taskManager:
podTemplate:
metadata:
labels:
chaos: taskmanager
resource:
memory: {{inputs.parameters.task-manager-memory}}
cpu: {{inputs.parameters.task-manager-cpu}}
...오류 주입
앞서 오류 주입 방법 섹션에서 살펴본 예시와 동일한 형태의 템플릿을 사용합니다. 앞서 말씀드렸듯 ChaosEngine.spec.appinfo 하위 값을 통해 어떤 앱에 오류를 주입할 것인지 설정할 수 있습니다. applabel을 chaos=jobmanager로 설정할 경우 잡 매니저에, choas=taskmanager로 설정할 경우 태스크 매니저에 오류가 주입됩니다.
아래는 잡 매니저 컴포넌트에 파드 삭제 오류를 주입한 예시입니다.
잡 매니저 컴포넌트에 파드 삭제 오류 주입 예시
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: pod-delete-template
spec:
serviceAccountName: argo-chaos
templates:
- name: pod-delete-b7n
inputs:
artifacts:
- name: pod-delete-b7n
path: /tmp/chaosengine-pod-delete-b7n.yaml
raw:
data: |
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
namespace: "{{workflow.parameters.adminModeNamespace}}"
generateName: pod-delete-b7n
labels:
workflow_run_id: "{{workflow.uid}}"
spec:
appinfo:
appns: litmus
applabel: chaos=jobmanager
appkind: deployment
engineState: active
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
components:
env:
- name: TOTAL_CHAOS_DURATION
value: "30"
- name: CHAOS_INTERVAL
value: "10"
- name: FORCE
value: "false"
- name: PODS_AFFECTED_PERC
value: ""
probe: []
container:
name: ""
image: litmuschaos/litmus-checker:2.14.0
args:
- -file=/tmp/chaosengine-pod-delete-b7n.yaml
- -saveName=/tmp/engine-name리포트 생성
오류를 주입한 후 오차율을 보기 위해서는 스테이블 앱과 카오스 앱 모두 처리가 완료돼야 합니다. 따라서 애플리케이션 처리 완료 여부를 확인하기 위해 Kafka 컨슈머의 랙(lag)을 주기적으로 체크하며, 컨슈머 랙이 모두 해소되면 애플리케이션을 종료하고 리포트를 생성합니다.
컨슈머 랙 체크
애플리케이션에서 사용하고 있는 컨슈머 그룹의 랙이 모두 소진될 때까지 랙 체크를 반복하는 템플릿을 작성해서 스테이블 앱과 카오스 앱 모두에 사용했습니다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: kafka-templates
spec:
serviceAccountName: argo-chaos
templates:
...
- name: check-lag
inputs:
parameters:
- name: bootstrap-servers
- name: group-id
- name: topic
script:
image: bitnami/kafka:1.1.1-debian-9-r307
command: [sh]
source: |
BOOTSTRAP_SERVERS="{{inputs.parameters.bootstrap-servers}}"
GROUP="{{inputs.parameters.group-id}}"
TOPIC="{{inputs.parameters.topic}}"
echo "Bootstrap servers: $BOOTSTRAP_SERVERS"
echo "Group id: $GROUP"
echo "Topic: $TOPIC"
while true; do
# Check the lag
lag=$(kafka-consumer-groups.sh --bootstrap-server $BOOTSTRAP_SERVERS --group $GROUP --describe | grep $TOPIC | awk '{sum += $5} END {print sum}')
# Check if the lag is not 0
if [ "$lag" -eq "0" ]; then
echo "Lag is 0, exiting successfully."
break
fi
echo "Current lag is $lag."
sleep 30
done리포트 생성
스테이블 앱과 카오스 앱이 처리해 생성한 데이터를 서로 비교해 차이를 도출한 것이 카오스 테스트의 결과입니다. 데이터의 차이를 계산하기 위해서 Flink Table API를 사용했습니다. Flink Table API는 Kafka나 HDFS(Hadoop File System) 등의 여러 커넥터를 지원하는 테이블 API로, 여러 데이터베이스에서 데이터를 읽어온 뒤 SQL 형태로 질의할 수 있다는 장점이 있습니다.
아래는 리포트 생성 템플릿 예시입니다. 작성한 SQL을 Flink Table API의 엔드포인트로 제출한 뒤 그 결과를 파일 형태로 저장합니다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: flink-templates
spec:
serviceAccountName: argo-chaos
templates:
....
- name: create-report
inputs:
artifacts:
- name: dummy
path: /tmp/dummy
raw:
data:
- name: report-sql-file
path: /tmp/report.sql
raw:
data: |
...
image: ...
command:
- sh
source: |
pwd
beeline -u "jdbc:hive2://flink-sql-gateway/default;auth=noSasl" -f /tmp/report.sql --silent=true > /mnt/out/output.txt
cat /mnt/out/output.txt
volumeMounts:
- name: out
mountPath: /mnt/out
volumes:
- name: out
emptyDir: { }
outputs:
parameters:
- name: report-message
valueFrom:
path: /mnt/out/output.txtSlack으로 결과 전송
아래는 리포트 생성 템플릿을 통해 생성된 결과 파일을 읽어서 Slack으로 메시지를 보내는 워크플로 템플릿 예시입니다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: util-templates
spec:
serviceAccountName: argo-chaos
templates:
...
- name: send-slack
inputs:
parameters:
- name: message
- name: channel
value: "sys-ladp-streaming-for-test"
- name: username
value: "Chaos-test"
- name: icon_emoji
value: ":ladp-stream:"
- name: color
value: "good"
script:
name: ""
image: curlimages/curl:8.4.0
command:
- sh
resources: { }
source: |
echo "Sending slack"
echo "{{inputs.parameters.message}}"
new_message=$(echo "{{inputs.parameters.message}}" | sed ':a;N;$!ba;s/\n/\\n/g' | sed 's/\t/\\\\t/g' | sed 's/"/\\"/g')
echo "<<<<<<<>>>>>>>>"
echo $new_message
curl -X POST "http://slack-proxy.com/api/chat.postMessage" -H 'Content-Type: application/json;charset=utf-8' -d "{\"channel\": \"{{inputs.parameters.channel}}\", \"username\": \"{{inputs.parameters.username}}\", \"icon_emoji\": \"{{inputs.parameters.icon_emoji}}\", \"attachments\": [{\"text\": \"${new_message}\", \"color\": \"{{inputs.parameters.color}}\"}]}"카오스 테스트 제출
앞서 세 단계(카오스 테스트 환경 구성과 오류 주입, 리포트 생성)로 구성된 카오스 엔지니어링 워크플로를 살펴봤습니다. 이를 워크플로 템플릿을 조합해 Argo Workflows로 작성한 뒤 ChaosCenter에 제출하면 카오스 테스트가 진행됩니다.
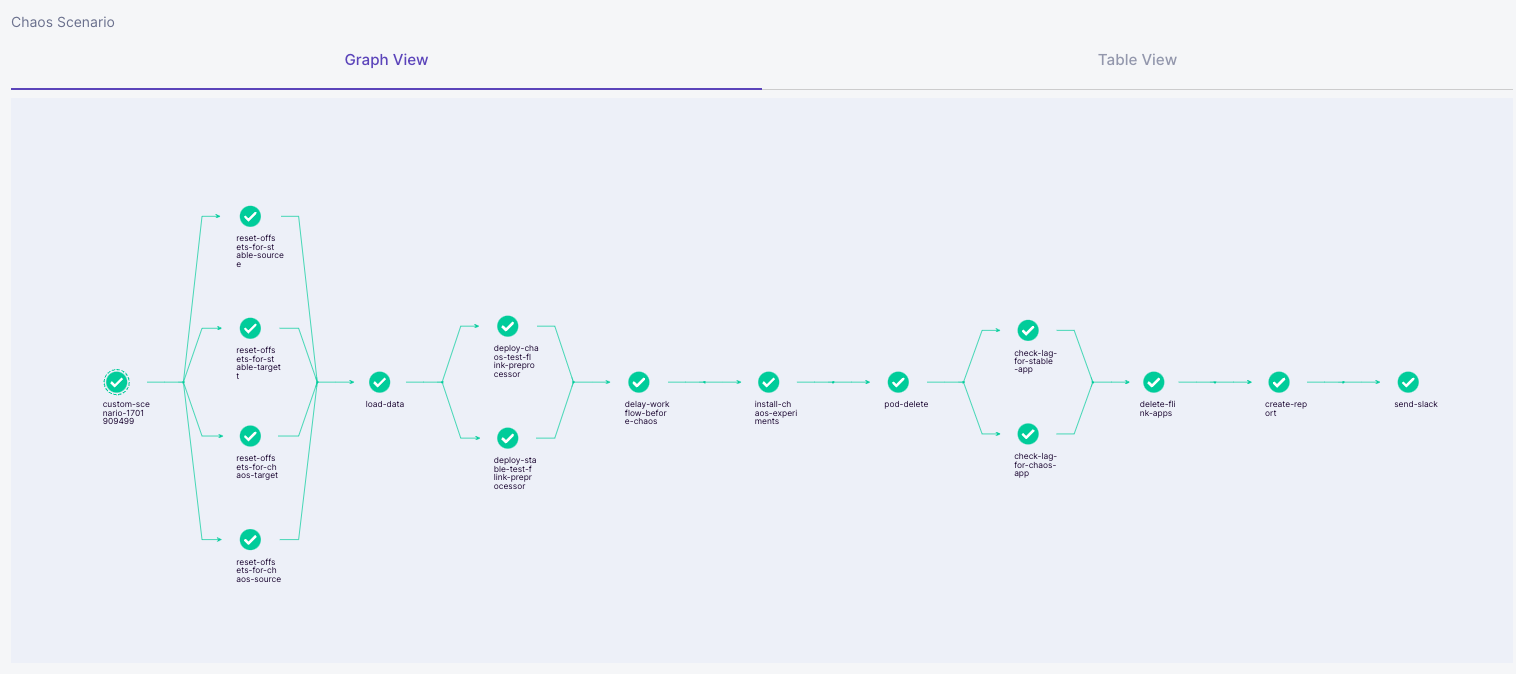
아래는 위 템플릿을 기반으로 작성한 Argo Workflows를 ChaosCenter를 통해 제출한 뒤 테스트 실행 결과를 ChaosCenter UI로 확인한 것입니다. 하나의 카오스 테스트는 여러 태스크가 DAG(directed acyclic graph) 형태로 연결된 워크플로로 구성되어 있는 것을 확인할 수 있습니다. 각 태스크별 성공 실패 여부와 여러 태스크 사이의 순서 및 병렬 조건이 알기 쉽게 시각화돼 있어서 전체 결과를 한눈에 파악할 수 있는데요. 아래 그림은 모두 에러 없이 정상 수행된 워크플로의 모습입니다.
아래는 카오스 테스트 실행 완료 후 Slack으로 전송된 메시지입니다. 리포트를 생성하기 위해 실행한 SQL의 결과가 Slack으로 전송됩니다.

자세히 표시를 누르면 SQL 질의를 통해 비교한 여러 결과가 나타납니다. 아래는 그 결과 중 일부를 발췌한 것입니다. valid_status�라는 데이터가 스테이블 앱과 카오스 앱에서 어느 정도의 차이가 발생했는지 확인할 수 있습니다.
+---------------+---------------+------------+-----------+----------------------+
| valid_status | no_chaos_cnt | chaos_cnt | diff_cnt | diff_cnt_percentage |
+---------------+---------------+------------+-----------+----------------------+
| 0 | 1094117 | 1276076 | 181959 | 16.630671126 |
| 1 | 147271 | 171587 | 24316 | 16.511057846 |
| 2 | 228 | 293 | 65 | 28.50877193 |
| 3 | 1166 | 1321 | 155 | 13.293310463 |
| 6 | 6 | 6 | 0 | 0 |
+---------------+---------------+------------+-----------+----------------------+LitmusChaos 기반 카오스 테스트를 통해 발견한 취약점과 개선점
앞서 소개한 것처럼 LitmusChaos 기반의 카오스 테스트 환경을 구성해 실제로 카오스 테스트를 진행하고 취약점 및 개선점을 발견할 수 있었습니다. 각 테스트를 하나씩 살펴보겠습니다.
네트워크 지연 카오스 테스트
네트워크 지연 카오스 테스트에 활용한 Chaos Experiment는 Pod Network Latency입니다. 태스크 매니저 파드와 체크포인팅 스토리지(HDFS) 간에 네트워크 지연을 유발하는 오류를 주입해서 체크포인팅에 일정 시간 동안 실패하는 상황을 연출했습니다. 네트워크 카오스가 해소된 뒤 Flink 애플리케이션은 가장 최근에 성공했던 체크포인트 기준으로 복구돼 데이터 처리를 이어나갔습니다.
Flink 애플리케이션의 Kafka Sink에서 메시지 전송 전략(message delivery semantics)을 다르게 설정하면서 테스트를 반복했는데 모두 기대했던 결과를 보였습니다. AT_LEAST_ONCE로 설정돼 있으면 데이터 유실 없이 중복 데이터만 발생했고, EXACTLY_ONCE로 설정되면 데이터 유실과 중복이 모두 없다는 것을 확인했습니다.
취약점 및 개선점
테스트를 진행하면서 취약점도 발견했습니다. 네트워크 카오스가 오랜 시간 발생하면서 체크포인팅에 연속적으로 실패할 경우 Flink의 태스크 실패 리커버리 설정과 허용 가능한 체크포인팅 실패 횟수 설정에 따라 애플리케이션이 멈출 수도 있다는 것을 확인했습니다. 이 위험에 대비하기 위해 지속적으로 체크포인팅 실패를 감지하면서 후속 조치로 체크포인팅 스토리지를 변경해 주는 모니터링 시스템을 추가로 개발해야 했습니다.
파드 실패 카오스 테스트
파드 실패 카오스 테스트에 활용한 Chaos Experiment는 Pod Delete입니다. 지정한 파드를 삭제하는 카오스를 통해 테스트 매니저 파드와 잡 매니저 파드가 예상치 못한 상황에서 종료되는 상황을 연출했습니다. 태스크 매니저 파드가 삭제되면 새로운 파드가 생성되고 가장 최근 체크포인트 기준으로 애플리케이션이 복구됩니다. 잡 매니저 파드가 삭제되는 경에도 잡 매니저의 HA(high availability) 구성을 설정했다면 마찬가지로 가장 최근 체크포인트 기준으로 애플리케이션이 다시 생성됩니다.
취약점 및 개선점
두 경우 모두 메시지 전송 전략 설정에 맞게 기대했던 결과가 나왔습니다.
노드 실패 카오스 테스트
노드 실패 카오스 테스트에 활용한 Chaos Experiment는 Node Drain입니다. 쿠버네티스 노드에 문제가 발생해 해당 노드에 스케줄링됐던 파드가 모두 종료되는 카오스를 실험했습니다.
취약점 및 개선점
파드 실패 테스트와 같은 결과가 나타났는데요. 문제가 발생한 노드의 범위가 넓어서 클러스터의 리소스가 부족해지는 상황이 발생하면 Flink 애플리케이션이 복구되지 못하고 처리가 멈출 수 있다는 취약점을 발견했습니다.
이 취약점에 대비하기 위해 클러스터의 리소스 운영 전략을 다음과 같이 세웠습니다.
- LINE 광고 전처리기 전용 고성능 노드를 하나의 노드 풀로 지정
- 해당 노드 풀에 테인트(Taints) 설정으로 Flink 외에 다른 애플리케이션이 스케줄링되지 않도록 보장
- Flink가 실행하는 파드는 QoS를 Guaranteed로 운영
- 해당 노드 풀 기준으로 항상 30%의 여유 공간이 유지되도록 리소스 확보 및 모니터링
세이브포인트 테스트
세이브포인트 테스트는 오류 주입 없이 세이브포인트 모드로 애플리케이션을 종료하고 복구했을 때 어떻게 작동하는지 작동 방식을 검증하기 위한 테스트입니다. 세이브포인트 모드는 주로 애플리케이션을 정기적으로 재배포할 때 사용하는 옵션으로, 애플리케이션을 그레이스풀(graceful)하게 종료하면서 그 당시 스냅숏을 저장하는 방식입니다. 따라서 Kafka의 메시��지 전송 전략이 AT_LEAST_ONCE로 설정돼 있어도 다시 복구하면 데이터 중복이 발생하지 않는데요. 실험을 통해 기대한 결과를 확인할 수 있었습니다.
취약점 및 개선점
특별한 취약점은 없었으나, 카오스 테스트를 수행하면서 디버깅과 Flink의 코드 확인 결과를 바탕으로 FlinkDeployment를 사용하는 배포 프로세스를 체계적으로 세울 수 있었습니다.
카오스 테스트 결과 정리
카오스 테스트를 진행하면서 프레임워크 및 쿠버네티스가 복구 능력을 갖추고 있음에도 발생할 수 있는 여러 취약 지점을 찾아낼 수 있었습니다. 외부 데이터베이스와의 송수신 과정에서 네트워크 지연이 발생한 경우 혹은 노드 실패 등으로 배포 환경인 쿠버네티스에 장애가 발생한 후 복구가 늦어진 경우 등에 발생할 수 있는 문제점들을 파악했고, 그에 대비하기 위해 모니터링 및 장애 복구 프로세스를 추가해야 한다는 것을 파악할 수 있었습니다. 또한 여러 카오스 테스트를 진행하면서 배포 환경에 문제가 없을 경우 분산 처리 프레임워크인 Flink의 전송 전략(delivery semantics)이 정상적으로 작동한다는 것을 알 수 있었습니다.
이와 같이 카오스 테스트를 통해 여러 장애 시나리오를 검증해 보며 각 장애 상황이 애플리케이션에 미치는 영향을 파악할 수 있었고, 이를 통해 장애 상황에 강건한 애플리케이션이라는 것을 보증할 수 있었습니다. 카오스 테스트를 활용하면 장애 상황 재연과 검증에 도움이 될 뿐 아니라, Flink와 같이 역사가 오래되고 코드가 방대한 오픈소스 프레임워크를 사용할 때 개발자가 자신이 사용하는 기능과 그 작동 방식을 경험하면서 파악할 수 있기 때문에 연구 개발 관점에서도 유용합니다.
맺음말
대용량 실시간 처리 파이프라인은 시스템의 복잡도가 높고 처리하는 데이터의 양이 많다 보니 TDD와 같은 기존의 코드 또는 규칙 기반의 검증 방법을 적용하기가 어렵습니다. 그럼에도 대량의 데이터를 지연 또는 장애 없이 안정적으로 처리하기 위해서는 실제 데이터에 기반해 다양한 테스트를 거쳐 시스템 안정성을 보장하는 것이 필요한데요. 이때 Tekton과 LitmusChaos를 활용할 수 있습니다. 둘 모두 오픈소스 쿠버네티스 네이티브 시스템이기 때문에 선언적으로 시스템을 구축할 수 있고, 필요에 따라 리소스나 설정을 조정하기도 쉽습니다. 또한 선언적으로 워크플로를 정의할 수 있기 때문에 템플릿 정의만 한 번 잘 해놓으면 다양한 검증 시나리오를 적은 공수와 리소스로 실행할 수 있습니다.
이와 같이 사용하고 있는 분산 시스템의 구성 요소와 특징을 잘 파악한 뒤 여러 쿠버네티스 네이티브 도구를 적극 활용한다면, 적은 인력으로도 대용량 시스템 검증을 자동화해서 높은 수준의 시스템 신뢰도와 운영 노하우를 확보할 수 있습니다. 이 글이 저희와 같은 고민을 하고 계신 분들께 도움이 되길 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


