はじめに
私たちは、社内のプラットフォームにおいて、Cloud NativeなANN(近似最近傍探索)ベクトル検索エンジン「Vald」のマネージドシステムを約4年間にわたり運用・開発してきました。
本記事では、4年という歳月をかけて私たちが積み上げてきた、Vald運用におけるベストプラクティスを公開します。
突然ですが、みなさんはベクトル検索エンジンを実践で使いこなせているでしょうか?
昨今のLLM(大規模言語モデル)の普及に伴い、RAG(検索拡張生成)の文脈でベクトル検索エンジンは一気に身近な存在になりました。
最近ではMCP(Model Context Protocol)のようなAIモデルと外部データソースをシームレスにつなぐプロトコルの台頭もあり、システムへの組み込みを検討し始めた方も多いのではないでしょうか。
しかし、実際に導入してみると期待していたほどの性能が出なかったり、やっとの思いで検証段階を乗り越えても本番環境で大規模な利用を始めると性能が出ず安定しないなどの問題に当たった人も多いと思います。
- 「検索精度を上げようとすると、速度が許容できないほど悪化する」
- 「大量のデータをインサートした途端、Indexingが詰まって最新のデータが検索に反映されない」
- 「リソースを増やしても、期待したほどスループットも精度も伸びない」
これらは、私たちもValdの社内プラットフォームを約4年間にわたり運用・開発する中で、何度も直面してきた問題です。
「理想」と「現実」の差を埋めるために
Valdをはじめとしたベクトル検索エンジンは現代において非常に強力で柔軟な武器です。
しかしそのポテンシャルを引き出すには、公式ドキュメントにあるパラメータの意味や内部エンジンの特性、近傍探索の仕様などを深く理解する必要があります。
とはいえ、すべての開発者が検索エンジンの内部構造に膨大な時間と労力を割けるわけではありません。
そこで今回は、私たちが4年間の運用で得た知見をもとに「実践で特に効果のあった内容」に要点を絞って解説します。
これからValdを導入する方はもちろん、すでに現場でパフォーマンスの限界や不安定さに悩んでいる方にとって、最適解へ辿り着くためのガイドとなれば幸いです。
そもそも性能が出ているとはどういう状態か
性能を評価する前に、まずは「性能が出ている状態」とは何かを定義しておきましょう。
ベクトル検索エンジンの性能は、単に「速い」だけではなく、精度(正確さ)と速度の両方を満たす必要があります。
さらに、実際の運用では、スループット(処理能力)も重要な評価軸となります。
これらの指標はトレードオフの関係にあることが多いため、どこを重視するかはユースケースやユーザーの期待によって異なります。
例えば、リアルタイムな応答が求められるチャットボットの場合は速度が最優先される一方で、バッチ処理であれば精度を重視することが多いでしょう。
性能が出ている状態とは、これらの指標がユーザーの期待やシステム要件を満たしている状態を指します。
検索性能の評価軸(どこをみるべきか)
-
精度
ANNの正確さを測る指標で、私たちはRecall@Kを主に使用しています。ここでのRecall@KはExact(全探索)で得られるTop-Kを正解とみなしたときに、ANNのTop-Kがそれをどれだけ再現できたかを表す指標です。ただし、Recall@KはTop-Kの集合の一致を見るため、順位は区別しません。順位の正確さまで重視したい場合は、MRRやnDCGなどの指標を用います。 -
速度
検索クエリに対する応答時間を指し、主にレイテンシー(Latency)で評価されます。平均レイテンシーだけでなく中央値や99%ileレイテンシーなど、分布を考慮した指標も重要です。 -
スループット
単位時間あたりにどれだけのリクエスト(クエリ)を処理できるかの指標です。システム全体の処理能力を示すもので、特に高負荷環境での性能評価に重要です。
検索性能を左右する要素
性能を左右する要素は大きく分けて「構築時の設定」と「検索パラメータ」の2つに分けられます。これらの要素は密接に関連しており、適切なバランスを取ることが重要です。
例えば、検索パラメータで探索範囲を広げると精度は向上する可能性がありますが、その分速度が悪化することがあります。
逆に、探索範囲を狭めると速度は改善しますが、精度が低下する可能性があります。
したがって、これらの要素を理解し、ユースケースに応じて適切に調整することが、性能を最大限に引き出すための鍵となります。
構築時の設定の一例
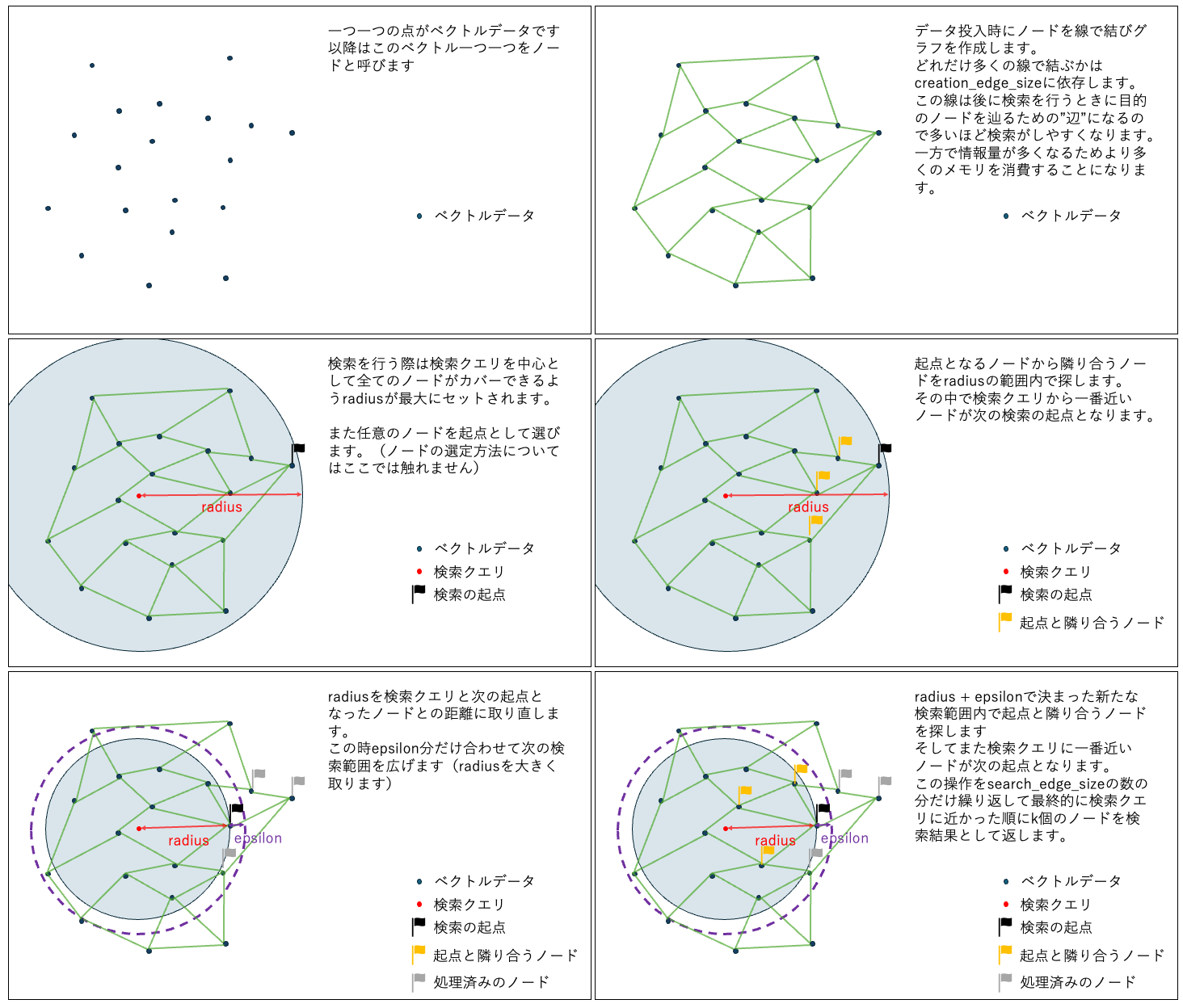
ここではVald構築時のパラメータについて今回の内容に関連するものを解説します。
-
index_replica
Valdのロードバランサーにおける冗長設定です。例えばAgentが2つある場合にindex_replica: 2を設定すると同じIndexを持つAgentが2つ作られるため、そのうち片方に問題が発生しても実質的な検索母数に変動は起きません。ただし、index_replicaを増やすとその分リソースも必要になるため、環境に見合った適切な値を設定することが重要です。また、agentのreplica数はindex_replica数以上にする必要があるため、構成の観点からも注意が必要です。 -
creation_edge_size
Index(グラフ)構築時に各ノードへ何本のエッジを張るかを決めるパラメータです。
値を大きくするとグラフの接続性が高まり検索精度は向上しやすくなりますが、構築時間と構築時のCPUリソースの増加、および構築後のメモリ使用量が増加します。
小さくすると軽量に構築できますが、探索時に遠回りが増え、精度や速度に影響する可能性があります。 -
search_edge_size
探索時に各ノードからどれだけのエッジ(隣接ノード)を辿るかを指定するパラメータです。
値を大きくすると探索の網羅性が高まり精度は向上しやすくなりますが、その分計算量と探索時間が増加します。
逆に小さくすると高速になりますが、最適な経路や近傍を見逃す可能性があります。
検索パ��ラメータの一例
Vald Search APIsのパラメータについて代表的なものを解説します。
-
radius
探索範囲の初期値を指定するパラメータです。
検索の過程でradiusは更新されていくため基本的には -1 (最大範囲)を推奨します。 -
epsilon
こちらも探索範囲を指定するパラメータです。radiusを基準にどれくらい探索範囲を広げる/狭めるかを指定できます。 -
num
検索結果の上限数を指定するパラメータです。
近傍探索などの文脈においては一般的にTop-Kという呼び方で知られています。 -
timeout
検索結果を返す際には全てのAgentコンポーネントの結果を集計しているのですが、この集計に関わる内部timeoutを設定します。これにより、レスポンスが遅いAgentの結果を待たずに検索結果を返すことができます。(その場合精度の低下は起こりえます。)
内部timeout + 40%程度の時間をgRPC timeoutとするのが設定値の目安ですが、実際の設定値はサービスの要件や現在のレイテンシに合わせて調整が必要です。
またこれはデータコンポーネントであるAgentの応答に対する内部的なタイムアウトであり、Search Request全体のタイムアウトではないことに注意してください。
後者はアプリケーション側での設定依存(gRPC Connectionのtimeoutなど)になります。
各パラメータの関係性が視覚的にわかるようにベクトル検索の様子を図にしました。
実例1 データ規模が小さいのに性能が出ない
ではいよいよ実例を見ていきましょう。まずはこの様なケースを想像してみてください。
まずデータセットは数千〜数万件程度の比較的小規模なもので、次元数も高くありません。これならコストを削減した小さなValdクラスタ構成で運用ができそうです。ところが、いざ検証を始めてみるとわずか100qps程度の負荷でリソース上限まで達してしまいます。
小規模なデータセットに対して、なぜこれほどまでに計算リソースを消費するのでしょうか?
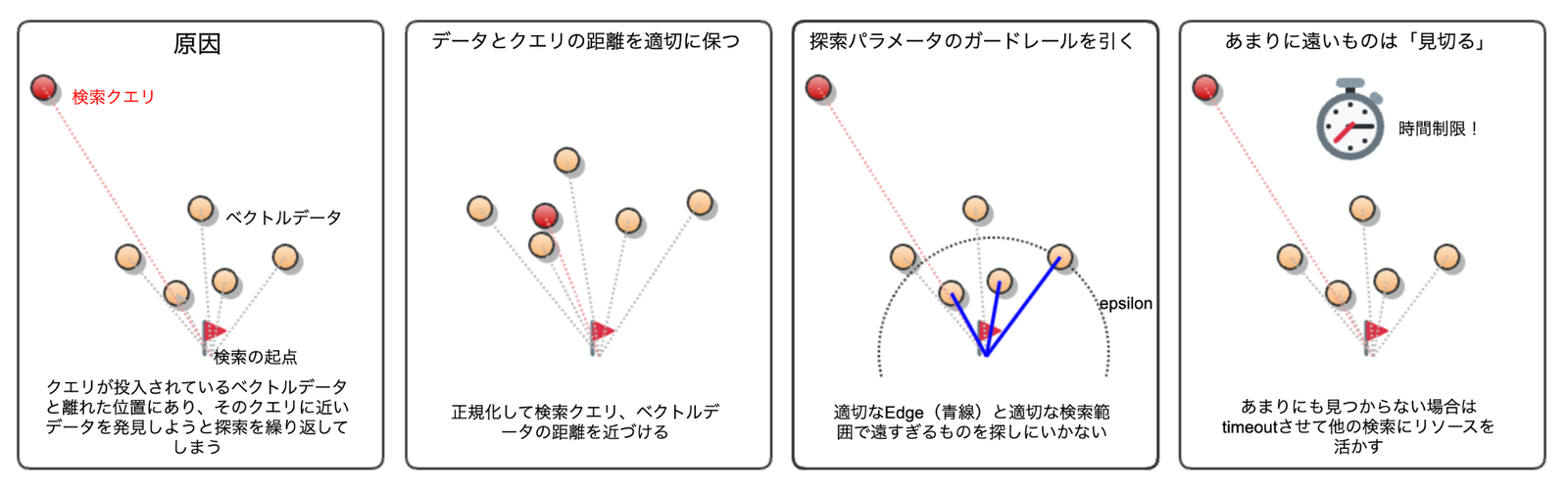
原因
検索クエリとデータの「距離」
私たちのケースで判明した原因は、検索クエリと保存されたベクトルデータの距離が極めて遠かったことにありました。
以下の例のように検索クエリがIndexのデータの塊(クラスタ)から大きく外れた「虚無の空間」にある場合、グラフに存在するほぼ全てのIndexを辿るまで探索が完了しないケースがあり、結果としてCPUリソースを使い切ることがあります。
| name | dim1 | dim2 | dim3 | dim4 | dim5 | ... |
|---|---|---|---|---|---|---|
| Indexデータ | 0.1 | 0.2 | 0.1 | 0.0 | 0.3 | ... |
| 検索クエリ | 10.5 | 20.0 | −15.0 | 8.0 | 12.0 | ... |
対策
データとクエリの距離を適切に保つ(正規化)
まずはベクトルの正規化(Normalize)を検討しましょう。
先述の通りベクトルのノルムのばらつきが大きいと、探索時間や必要なリソースが跳ね上がります。
ベクトル検索はデータ性質の影響を非常に受けやすいため、正規化の有無を比較したり、距離関数(L2やCosineなど)を複数試してみるのがおすすめです。
探索パラメータのガードレールを引く
Index作成時のcreation_edge_size/search_edge_sizeや、検索時のパラメータ(radius + epsilon)が小規模データに対して「過剰」になっていないか見直します。
特にデータ件数が少ない場合は、探索範囲を広げすぎても計算量が増えるだけで精度向上に寄与しないことがあります。
性能向上のためには、状況に見合った適切な「絞り込み」も必要です。
あまりに遠いものは「探索を打ち切る」
さらに実効的な対策は、検索タイムアウト(SearchConfig.timeout)の設定です。
あらかじめ「これ以上の時間はかけない」という閾値を設定し、効果の薄い探索を打ち切ることで、貴重なCPUの時間的リソースを他の有効なリクエストへ解放することが可能になります。
実例2 データインサート中のワークロードで精度が落ちる
検索性能の引き出し方がわかり、検索ロードテストも問題なくクリアできたところで次の課題が見えてきました。いざテスト環境��でデータインサートを始めると、そのタイミングで精度が大きく落ちることがありました。なぜデータインサート中は検索性能が変わるのでしょうか?
原因
Valdの探索はCPUバウンド
ValdのデータコンポーネントであるAgentの探索処理はCPUバウンドであるため、その精度は計算資源の余力に強く依存します。
CPUに余裕があれば十分な探索が行われ精度も安定しますが、データのインサートが始まると状況は一変します。
特にインサートに伴い実行されるIndexingは、エッジ探索やノードの再接続といった高負荷な処理を伴うため、CPU資源を大きく消費します。
加えて、Index更新中のAgentは一時的に検索対象から外れるため、クラスタ全体で検索母数が変動し、これも精度を不安定にさせる要因となります。
これらが組み合わさることで、検索とIndexingの間で深刻なリソース競合が発生します。
もしこの状況下で、低下した精度を補おうと無理にepsilonを引き上げれば、増大した探索量がさらにCPUを圧迫し、スループットと精度の双方を破綻させる負のスパイラルに陥ります。
今回のケースでは、これはパラメータの問題ではなく、計算資源の競合が原因です。
対策
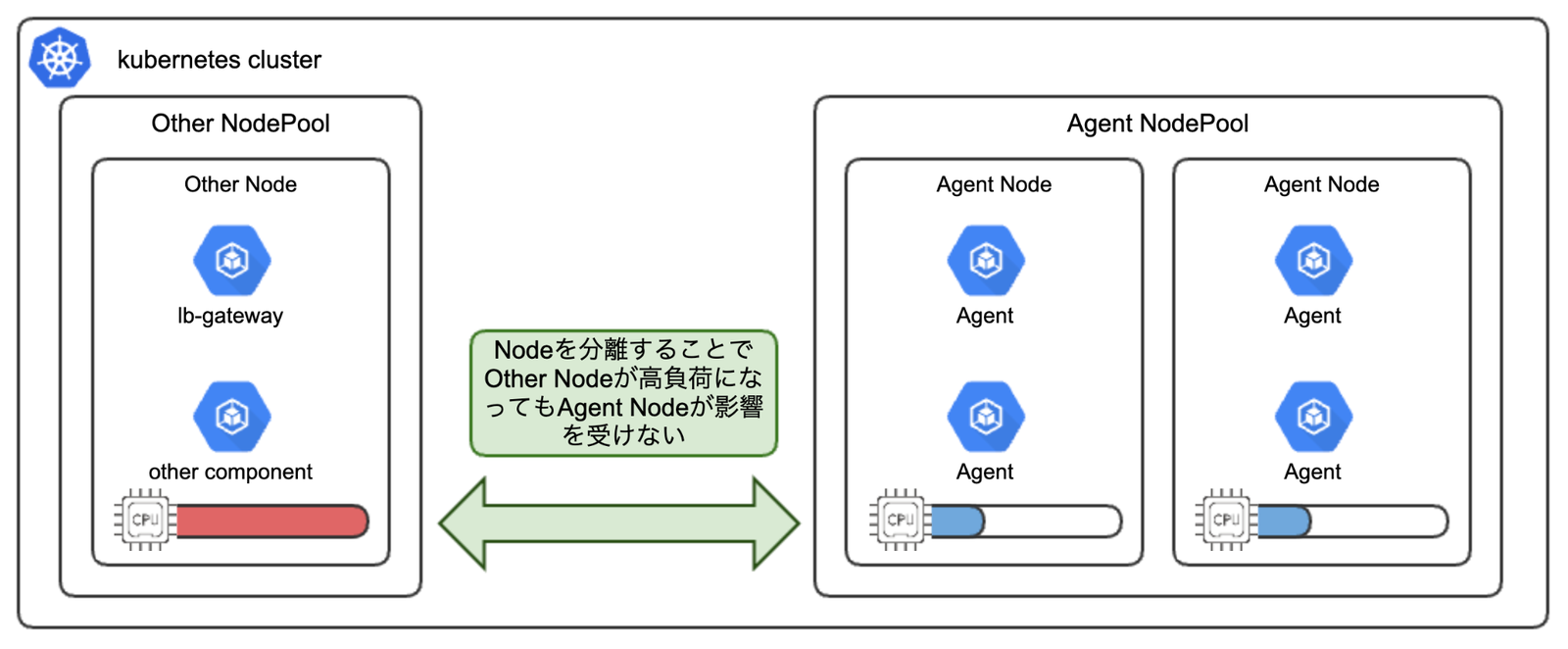
AgentのCPUを物理的に守る
まずValdは単一プロセスのANNエンジンではなく、複数のコンポーネントが協調して動作するマイクロサービス構成をとっています。
インサートに限らず高負荷時はさまざまなコンポーネントとの競合が発生するため、Agent専用のNodePoolを用意し、他のワークロードから完全に隔離しましょう。
具体的には、nodeSelectorやnodeAffinityを用いてAgentを専用Nodeに縛り付け、同時にPod Topology Spread Constraintsを活用してNode間での負荷分散(可用性の担保)を図ります。
また、resources.requestsに十分な値を設定し、計算資源を予約しておくことも重要です。
詳しくはこちらの記事をご覧ください。
特に近傍探索を担うAgentは、他コンポーネントや他アプリと同居させない設計が有効です。
Noisy Neighborを排除することで、精度の揺らぎは改善します。
IndexReplicaを調整する
Valdでは、Indexing中のAgentがSearch対象から一時的に除外されて検索母数が変動するのを防ぐため、IndexReplicaというIndexの冗長設定があります。
例えばIndexReplicaに2を設定すると同じIndexを持つAgentが2つずつ作られるので、そのうち片方がIndexingされてSearch対象から除外されても検索母数に変動は起きません。
またその上で1NodeあたりのAgent数を絞るなど、CPU奪い合いを起こしにくい配置設計も重要です。
可能ならデータインサートと検索のピークをずらす
CreateIndexの実行タイミングを制御する、あるいはインサートフェーズと検索フェーズのピークを分離することで、競合を緩和できます。
たとえば、トラフィックの低い時間帯に一括でIndexを更新する、あるいは書き込み専用のAgentと読み取り専用のAgentを物理的に分離して運用するといった戦略が有効です。
これにより、リアルタイムな更新性を多少犠牲にしてでも、検索クエリに対する計算資源を担保し、精度の安定化を図ることができます。
実例3 同じクラスタ構成なのに性能が違う
次は同じ構成でクラスタを作っているのに性能が違うというケースを見てみましょう。
これまでの知識をもとに、構成を揃えれば同じ性能が出るはずだと考えて、同じKubernetes Manifestを使って同じNode数のクラスタAとBを構築します。
さらに同じデータセットを、同じManifestで、同じNode数のクラスタへ投入しますが...
にもかかわらず、クラスタAとBで精度や速度が大きく異なることがあります。理論上は同じ挙動になるはずなのに、誤差とは言えない差分が出ます。
このとき疑うべきは「構成」ではなく「状態」です。
原因
構成は同じでも「状態」が冪等ではない
先述の通りValdはマイクロサービス構成でAgent・LbGatewayなどのコンポーネントが分散環境で動作します。
Kubernetes Manifestが完全に冪等でなければ、
- Podの配置が変わる
- CPU配分が揺らぐ
- Agent間のデータ分布が偏る
といった「状態の差」が生まれます。
Manifestsの内容が同じでも、クラスタの最終状態が同じとは限りません。
また構成を合わせたとしても、データインサートの流量が違うとIndexデータの分配が崩れることもあります。
この状態の揺らぎが性能差分の正体です。
対策
構成を冪等に固定する
Valdのパフォーマンスを安定させるには、単に設定値を揃えるだけでなく、どの環境でも「同じリソース状態」が再現されるインフラ設計が不可欠です。
具体的には、以下のKubernetesリソース定義を組み合わせ、排他的かつ冪等な実行環境を構築します。
- Resource Requests / Limits
- 期待するリソース使用量を計測した上でCPUとメモリの最低保証(Request)と最大上限(Limit)を等値で明示し、QoSクラスは最低でも
Burstableになるようにしましょう。 - 必要に応じて
Guaranteedに強制することで、他Podからのリソース奪取を防ぎます。
- 期待するリソース使用量を計測した上でCPUとメモリの最低保証(Request)と最大上限(Limit)を等値で明示し、QoSクラスは最低でも
- Node Affinity / Anti-Affinity
- Agentを特定のNodePoolに引き寄せ(Affinity)、かつ同一Nodeに複数のAgentが密集するのを防ぐ(Anti-Affinity)ことで、物理CPUの競合を回避します。
- Pod Topology Spread Constraints
- 可用性ゾーン(AZ)やNode間でPodを均等に分散配置し、特定のホストに負荷が偏ることで生じる「局所的な精度低下」を防止します。
重要なのは、IaCのメリットを活かしてこれらの制約を定義することで「いつ、どこでデプロイしても同じ計算資源が確保されている状態」を強制することです。
スケールアウトやローリングアップデートの際も、この制約下で動作させることで、更新中の負荷変動による精度の揺らぎを抑えることが可能になります。
- 可用性ゾーン(AZ)やNode間でPodを均等に分散配置し、特定のホストに負荷が偏ることで生じる「局所的な精度低下」を防止します。
データインサートを制御する
Valdではベクトルデータインサート後、そのデータがすぐに検索可能になるわけではありません。
このグラフ構造へ組み込まれる前のIndexデータをUncommitted Indexesと呼びます。
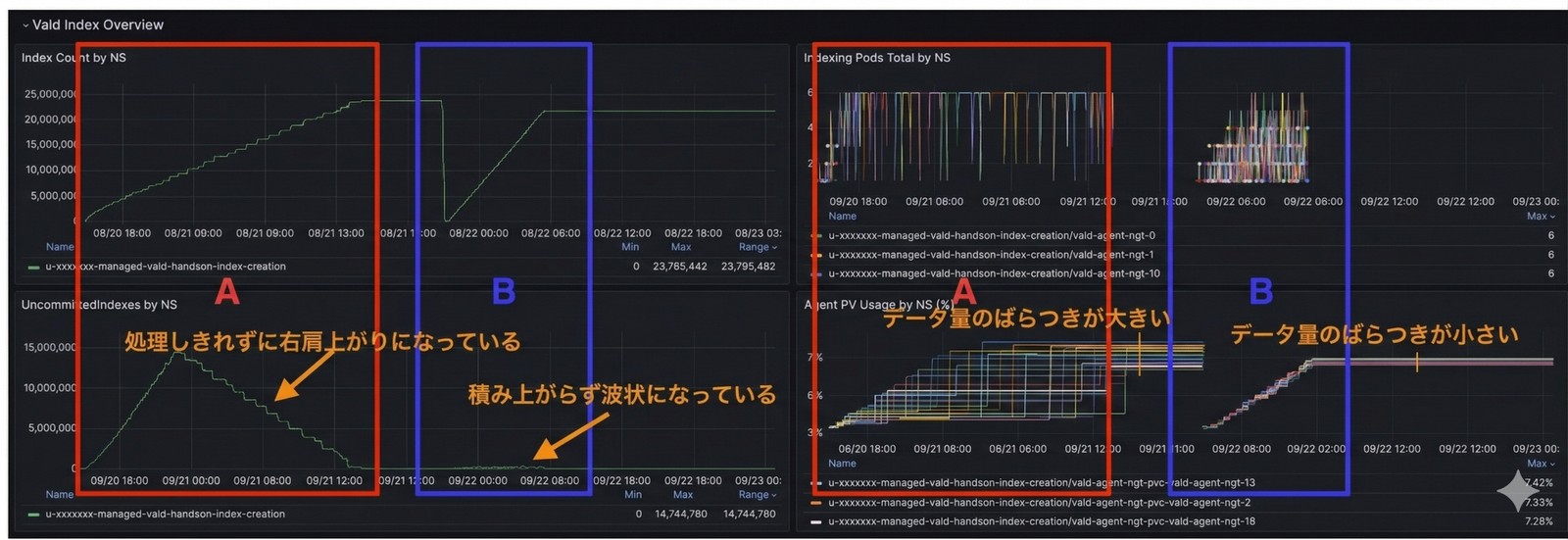
図中のAは、約1500万件のベクトルを3時間で一気にインサートした場合の挙動です。
Uncommitted Indexesが処理しきれず右肩上がりになっていることが分かります。
ValdはWorkerNodeの空きメモリを高頻度で監視し、可能な限り均等にデータを分配します。
しかしUncommittedが過剰に滞留するとIndexing処理が長時間化します。
その結果、分散の粒度が荒くなり、最終的なAgent間のグラフサイズに大きなばらつきが生じます。
一方、図中のBは同じ1500万件を9時間かけて流した場合です。
Uncommittedは波状に推移し、滞留せずに処理されています。
Agent間のデータ量のばらつきも小さく、均質なグラフが形成されています。
重要なのは、Index完了までの総時間はどちらも最終的に約9時間で大きく変わらないという点です。
3時間で急いで流しても、Indexingが追いつかずバックログが発生するため、結局は同程度の時間がかかります。
それどころか、過度な流量はUncommittedの滞留を引き起こし、最終的なグラフ分配を不均一にします。
この不均一さが、その後の検索精度の揺らぎにつながります。
したがって重要なのは「速く流すこと」ではありません。
Uncommittedが右肩上がりにならない流量で、グラフを健全に育てることです。
Insertはスループット勝負ではなく、Indexingが追従できる範囲で制御することが安定運用のために重要です。
おさらい
- 検索性能を引き出す鍵:クエリとデータの「距離」を制御する
- 小規模データでも、検索クエリがIndexing済みベクトル群から大きく外れていると、NGTは探索完了までに時間がかかりCPUを消費します。
- クエリとデータの正規化により距離スケールを揃え、過剰な探索を防ぐことが重要です。
- あわせて探索パラメータの適正化とタイムアウト設定により、効果の薄い計算を抑制し安定した性能を確保します。
- 検索精度を守るには「AgentのCPU」と「検索母数」を守る
- 高負荷時は検索とCreateIndexがCPUを奪い合うため、Agentを専用NodePoolに隔離してNoisy Neighborを排除します。
- Indexing中にAgentが検索対象から外れて母数が揺れるのを防ぐため、IndexReplicaで冗長化し、あわせて1NodeあたりのAgent数を絞るなどCPUの競合を避ける配置にします。
- 可能ならデータインサートと検索のタイミングを分離し、低トラフィック時間帯にまとめるあるいは読み書き分離などで競合そのものを減らして精度を安定させます。
- IaCにより「同じ状態」を再現する:構成の固定+インサート制御が鍵
- requests/limits、NodePool分離、Affinity/AntiAffinity、更新順序やローリング挙動まで含めて、適用すれば毎回同じ配置・同じ資源配分に収束する構成(冪等な“状態”)を作ります。
- Valdはインサート直後は検索可能にならず、組み込み前のUncommitted Indexesが溜まりすぎるとIndexingが長期化し、Agent間のグラフ分配が偏って性能差につながります。
- そのため、インサート流量を段階的に制御しつつ、Uncommitted数やIndexing状況を観測して、健全にグラフが育っていることを確認しながら進めます。
おわりに
最後までお読みいただきありがとうございました。
Valdの運用はパラメータと構成の両軸をうまく調整することで、高いパフォーマンスを持つベクトル検索エンジンとなります。
本記事がみなさんの環境で安定運用を実現するための助けになれば幸いです。


