こんにちは。LINEヤフー研究所でヒューマンコンピュータインタラクション(HCI)分野の研究をしている山中です。
クラウドソーシングで収集したデータを使って、とても精度が良いとされているモデルに当てはめてみたら、なぜか再現できない、そんな経験はないでしょうか。モデル自体に原因がある可能性もありますし、タスクを依頼した人の説明が不十分だったために、データにノイズが混ざったのかもしれません。あるいは、クラウドワーカーの振る舞いも一因かもしれません。たとえば指示を十分に読まずにタスクを実施したデータが混ざっていれば、どれほど高精度なモデルを使っても、適切な評価は難しくなります。
LINEヤフーのサービス改善を支えるユーザインタフェース(UI)評価の基盤研究の一環として、私たちはクラウドソーシング実験におけるデータ品質向上の手法を検討してきました。
UIの研究では、今ではクラウドソーシングを用いたオンライン実験がとても広く採用されています。しかし、従来のような「実験参加者に大学の研究室へ来てもらい、研究者が見守っている中でUIを操作してもらう」というラボ実験と比べて、管理体制が厳格ではないという制約がありました。そのため、実験参加者(クラウドワーカー)が実験の説明文をじっくり読まなかったり、丁寧にUI操作をしなかったりする問題があると指摘されてきました。
アンケートを主体とする研究では、説明文や質問にいわゆる「注意確認項目」を入れて、しっかりと文章を読んでくれるクラウドワーカーをスクリーニングする方法が従来から採用されてきました。たとえば文章とチェックボックスがたくさん並べてある中で、「ここのチェックボックスだけはチェックを入れずに次に進んでください」と書いておき、すべて��のチェックボックスに機械的にチェックを入れた人の回答データは後で除外する、といった方法です。
一方でUI操作に関する実験では、各クラウドワーカーが「指示に準拠してタスクを遂行した度合い」もUI操作結果で測定するのが良いはずだ、というのが本研究のアイデアです。この研究論文、「Improving Data Quality via Pre-Task Participant Screening in Crowdsourced GUI Experiments」がHCI分野のトップカンファレンスであるCHI 2026に採択されました。本記事では、この論文で提案しているデータ品質向上手法を紹介します。
1. 研究背景:クラウドソーシング実験のメリットとデメリット
HCI研究では、UI操作のパフォーマンス(所要時間やミス率など)を評価する実験は、長らくラボ実験環境で行われてきました。しかし、ラボ実験の参加者数は数十名規模が限界になることも多いです。そこで近年では、より短時間で数百名規模のデータを集めるために、クラウドソーシングが活用されるようになりました。本研究でもYahoo!クラウドソーシングを使っています。
クラウドソーシングの弱点は、研究者が参加者の様子を観察できないことです。従来のラボ実験では、たとえば「UI操作タスクの手順は分かりましたか?」とあらかじめ参加者に理解度を尋ねたり、実験中に誤った操作をしていたらそれを正すこともできます。しかしクラウドソーシング実験では、説明文に準拠せずに操作をしたり、短時間でタスクを終えるために丁寧な操作をしない人がいることが、過去の研究論文で報告されています。
本��研究はこの問題に対処するために、「事前に短時間で終わるタスクをやってもらい、その結果に基づいてクラウドワーカーをスクリーニングすることで、研究者が本来やりたいメイン実験のデータ品質を向上させる」というアイデアを検証しました。
2. メイン実験
ここでは研究者が本来やりたいメイン実験を、「棒をタップする操作の所要時間とミス率が、先行研究で提案されたモデルにしたがうかを検証する追試」に設定しました。具体的には下図のように、スマートフォンの画面に2本の棒が表示されており、青い方を指でタップするともう一方が青くなるので、青い棒を次々にタップする、というタスクをやってもらいます。タップするときは利き手の人差し指を使ってくださいと説明文で指示しました。
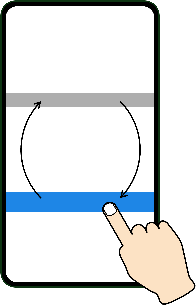
この2本の棒の太さや間の距離をさまざまに変更して、所要時間とミスタップ率を計測します。すると、それぞれが以下のモデルにしたがうことが知られています。
モデル1:所要時間の予測モデル(フィッツの法則)
棒の太さを、2本の棒の間の距離をとすると、タップ1回あたりの所要時間は、
の関係になります。これはフィッツの法則と呼ばれており、とは回帰分析の係数です。
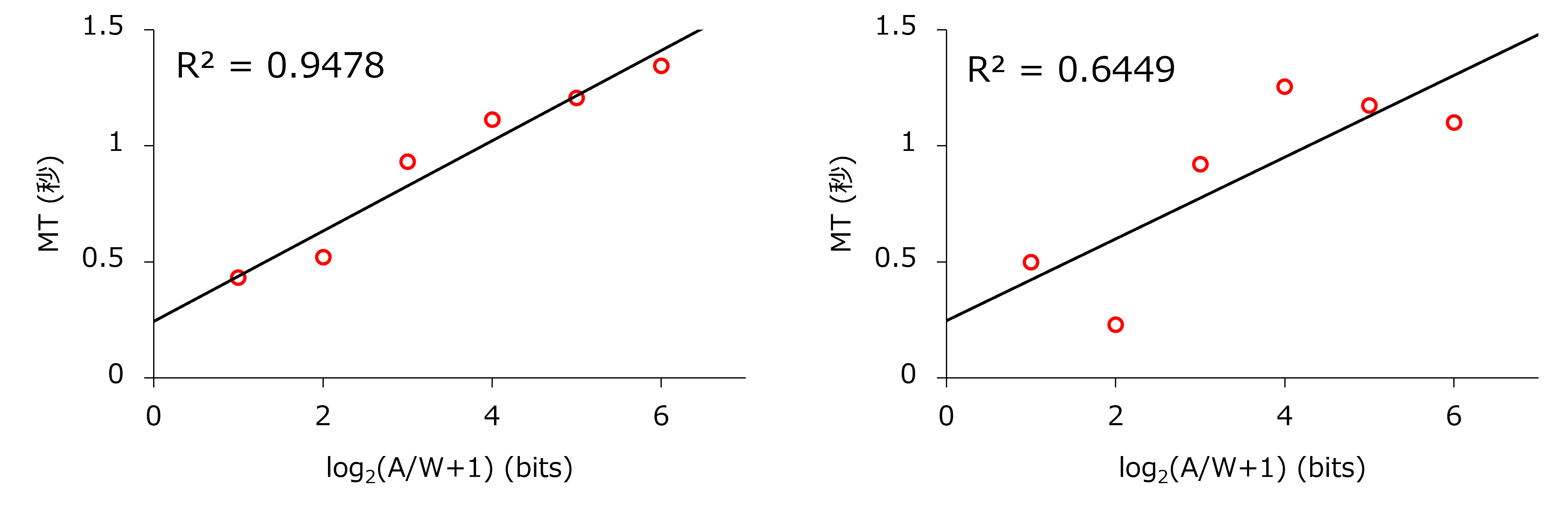
下図は、モデルの適合度の違いが分かりやすいようにシミュレーションで作成したデータです。左側のグラフのように、ラボ実験ではモデルの適合度がを超えることも多いです。このは、測定した所要時間の値が、どのくらい規則的に(ここでは直線的に)並んでいるかを表す指標です。1に近いほど、観測データがモデルに沿っていることを意味します。先行研究ではを超えることも多く報告されています。
一方で、もし実験参加者が指示に準拠しなかったり、操作精度が低ければ、データがモデルにしたがわないと考えました。たとえば両手の人差し指を使って「右手は上側の棒を担当し、左手は下側の棒を担当してタップする」という操作をしてしまうと、移動距離の影響がなくなってしまい、モデルが想定している操作ではなくなってしまいます。その場合は、下図(右)のように、データ点が直線的に並ばなくなり、が低くなるはずです。
モデル2:ミスタップ率の予測モデル
今回のタスクのように棒を繰り返しタップするとき、タップした地点の縦方向のばらつき具合(分散)は、棒の太さの二乗と一次関数の関係になることが知られています。
ここでとは回帰分析の係数です。そしてミスタップする確率は、ガウスの誤差関数と上記のを用いて以下の式で予測できます。
このモデルも、先行研究ではになることが多いです。
フィッツの法則とミスタップ率のモデルは、研究者がしっかりと管理したラボ実験では高い適合度になることが分かっています。しかし、指示に準拠しない操作データが多く含まれていると、適合度が低くなる懸念があります。
3. 事前タスク:画像の大きさをクレジットカードに合わせる
下図のように、クラウドワーカーは自分の持っているクレジットカード(またはそれと同じ大きさのカード)をスマートフォンの画面に乗せて、スライダー操作によって画像サイズをクレジットカードに合わせます。画像の大きさがクレジットカードにぴったり合っていると納得するまでスライダー操作を繰り返してから「次へ進む」ボタンを押します。
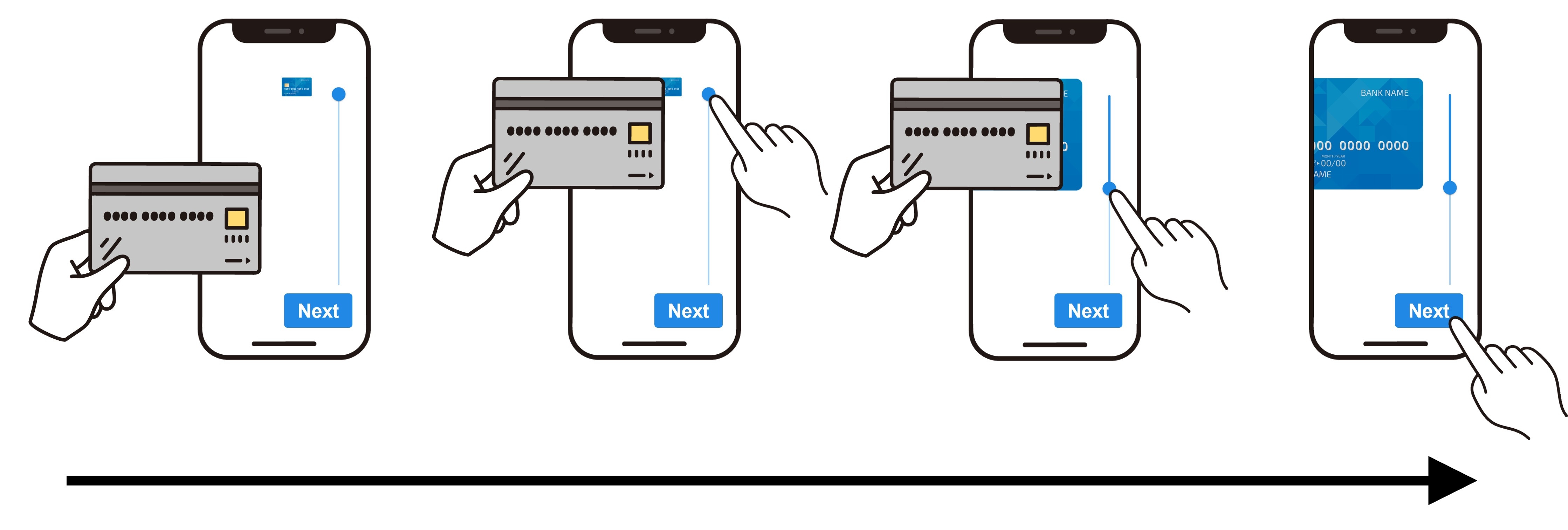
クレジットカードやSuicaなどの交通系ICカードの大きさは、ISO/IEC 7810 ID-1規格で決められており、高さ(短辺)が53.98mmです。また、iPhoneであれば画面の解像度(mm単位、およびピクセル単位)が既知であり、クラウドワーカーが正確に画像サイズを調整したかが分かります。
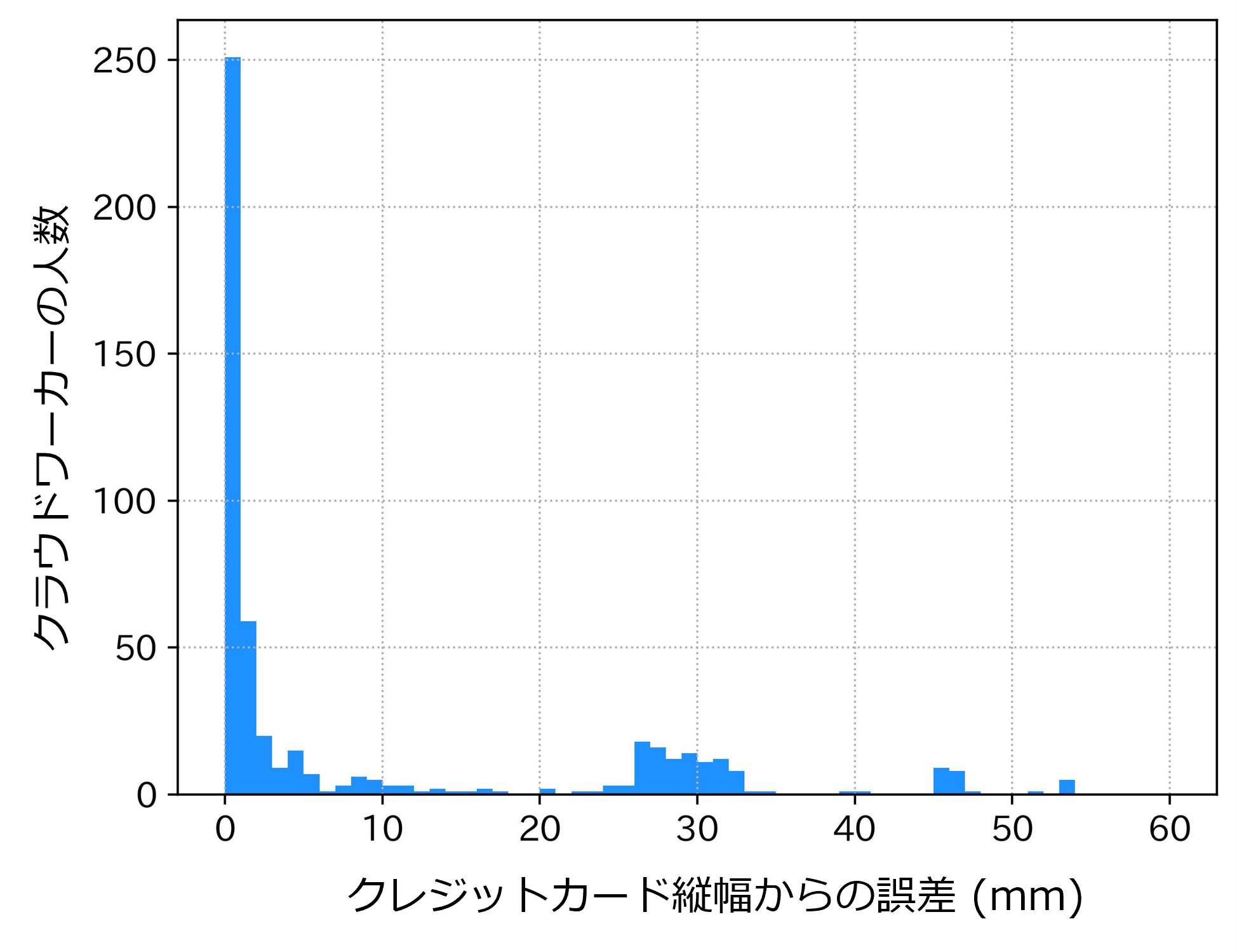
今回の実験では519名のクラウドワーカー(iPhone利用者限定)のデータを分析しました。画像の大きさ調整に要した時間は平均8.44秒です。下図は事前タスクの分析結果で、サイズ調整された画像の縦幅とクレジットカードの縦幅の誤差を横軸にとり、その誤差未満の結果を出した人数を縦軸にとったヒストグラムです。
約250名は、誤差が1mm未満でした。310名(60%)は誤差2mm未満で、このくらいの誤差までは「しっかり指示に準拠してサイズ調整した」と見なしてもよいかもしれません。しかし143名(28%)は誤差が10mm以上であり、画面上で明らかにクレジットカードと画像の大きさにずれがあるでしょうから、指示への準拠度合いが比較的低いと見なせそうです。
4. メイン実験の分析方法
上記の事前タスクの結果(カードのサイズ調整の誤差)を見ると、「指示への準拠度」には閾値があるわけではなく、グラデーションになっていることが読み取れます。たとえば「3mm未満の誤差であれば指示に準拠したと言える」のように、画一的に判断するのは難しそうです。そこで、メイン実験で主眼としているモデル適合度にどのような影響があるかを、以下の項目を変化させて確認します。
- 人数(10、20、40、80名):全519名からランダムに人をサンプリングしてモデル適合度を計算します。つまり、「もし最初から人でメイン実験をしたら、適合度はどうなっていたか」をシミュレーションします。
- 事前タスクの誤差の閾値mm(1から10mmまで、1mm刻み):これ未満の誤差だった人を「対象群」(メイン実験で募集をかける対象のクラウドワーカー)と呼び、それ以外の人を「非対象群」とします。
- 非対象群の人の混在割合%(0から100%まで、10%刻み):分析する名のうち、%を非対象群、%を対象群からランダムに選びます。
たとえば名、mm、%にすると、事前タスクにおける誤差が2mm以上だった人が一切含まれず、指示に十分準拠したと考えられる人だけを20名選出するので、メイン実験データのフィッツの法則やミスタップ率モデルの適合度が高くなると想定されます。それに対し、もしmmにすると、事前タスクの誤差が9.9mmでも指示に準拠したと見なされて対象群に含まれるので、メイン実験での適合度が下がりそうです。同様に、mmのままでも%に上昇させると、事前タスクでの誤差が2mm以上だった人が20名中16名を占めるため、メイン実験での適合度が下がるはずです。
全519名のうち、どの名を選ぶかによっても適合度の結果が変わるため、すべての、、の組み合わせについて1000回ランダムサンプリングをしての平均値をとりました。
5. 分析結果
例として名の場合のミスタップ率モデルの適合度の平均値を下図に示します。
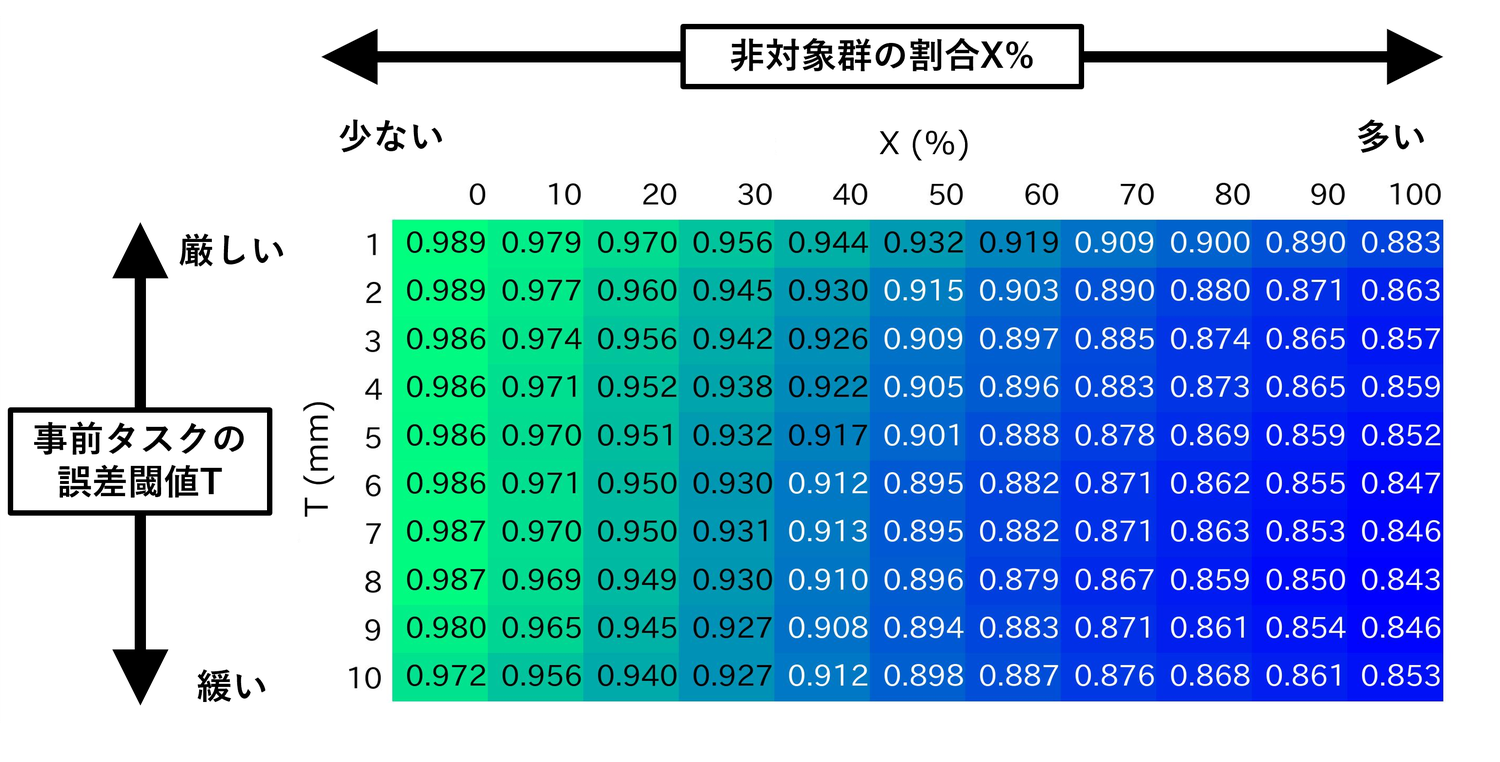
最もが高かったのは左上のマスで、ととても高い適合度でした。これはmm、%の条件なので、事前タスクの誤差を1mm未満に抑えられた人だけが名選出された場合の結果です。つまり、事前タスクをとても正確にできた人のみをメイン実験の募集対象にすれば、ミスタップ率のモデル適合度が良くなります。
一方で、閾値を大きくして「事前タスクの誤差が大きくても対象群にする」か、またはを大きくして「非対象群だった人のデータも多く混ぜる」という処理をすると、が低下していくことが読み取れます。この傾向は他のサンプリング人数でも同様でした。
次に、所要時間のモデル(フィッツの法則)の適合度について、名の平均値を下図に示します。
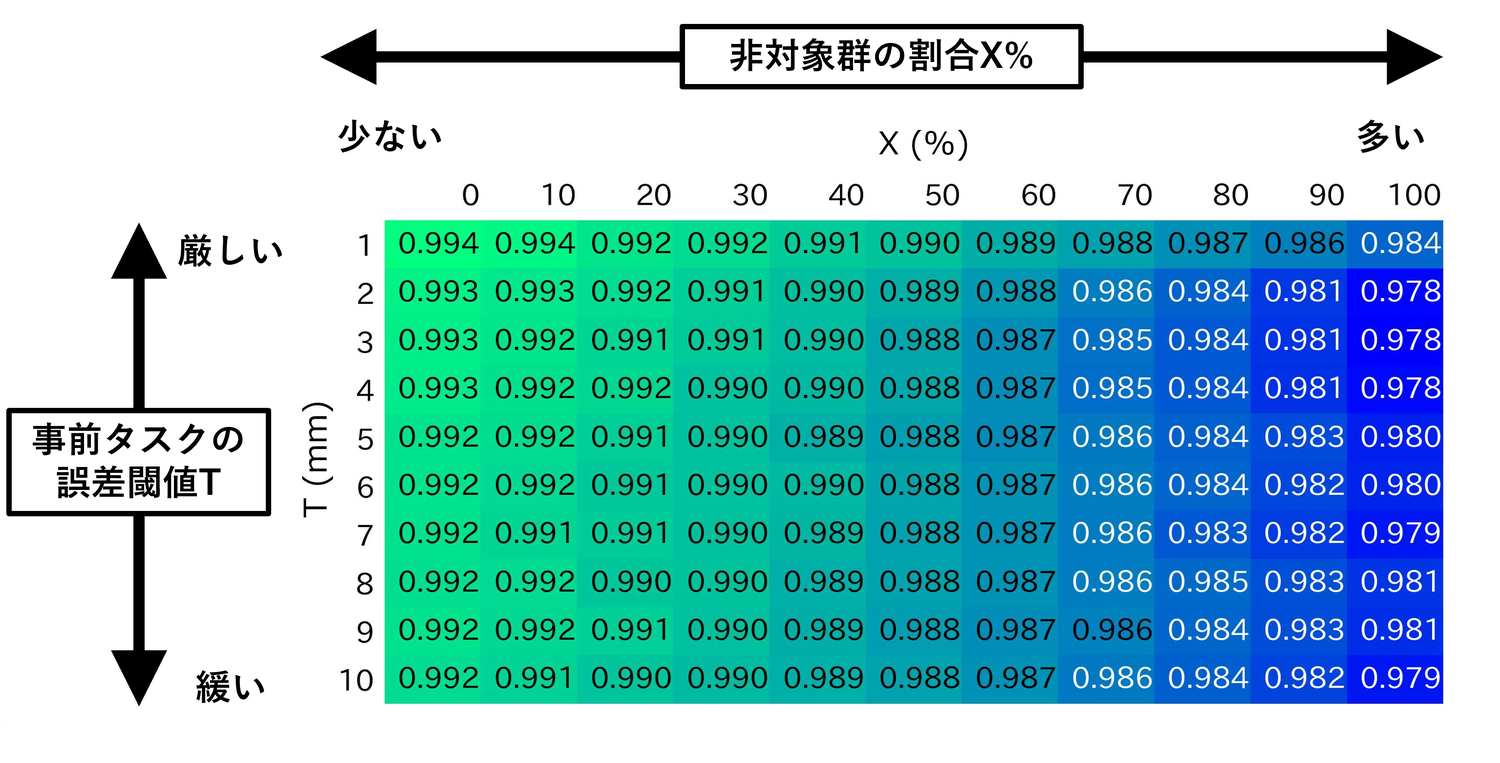
これはミスタップ率モデルと異なり、やを変化させてもが大きく変化しませんでした。事前タスクによるスクリーニングが「どのくらい指示に沿って正確にUIを操作できたか」という基準のため、ミスタップ率モデルの適合度には分かりやすい影響が表れたものの、タスク所要時間のモデル適合度への影響が比較的小さかったのだと考えています。
6. UI研究への応用
不適切な結論を出す可能性を減らす
今回の分析によって、事前タスクの閾値が大きく(緩く)、非対象群のクラウドワーカーの割合が高くなるにつれて、ミスタップ率モデルの適合度が低下する傾向が確認されました。事前タスクは平均9秒未満で終えられる内容ですが、この結果に基づいてメイン実験の募集対象者をスクリーニングすれば、ラボ実験と同様に「ミスタップ率モデルが高い適合度を示す」という結論が得られることが示されました。
逆に、もし指示への準拠度が高くないクラウドワーカーが多いデータを分析した場合は、研究者は「ラボ実験ではミスタップ率モデルがになるとされていたが、クラウドソーシング実験ではそれが成り立たないことを新たに発見した」という結論を導いてしまう可能性があります。しかし実際には、今回の分析で示したように、指示によく準拠してくれるクラウドワーカーにメイン実験を依頼することで、このモデルはの高い適合度を示すことが分かります。
研究費・コストの削減
対象群のクラウドワーカーのみにメイン実験の参加募集をかけることで、限られた研究予算で高品質のデータを収集できることが期待されます。たとえば事前タスクでは、説明文を読むのを含めて1分で終わるので1名あたり30円を支払い、メイン実験は10分程度かかるので300円の報酬を支払うと仮定します。クラウドワーカーを100名募集したいですが、その中には指示に準拠せずに操作をする人が20名いて、事前タスクとメイン実験のいずれのデータからもその20名をうまく特定できるとします。
もし従来のようにメイン実験のみを実施し、100名募集すると支出は300円×100名=30000円です。そして指示に準拠しなかった20名のデータを削除すると、最終的に80名分のデータしか活用できないのに30000円を支払うことになります。これは実質的に、24000円の価値のデータ(300円×80名)に対して30000円かかっていることになります。
これに対して、まず100名全員に30円の事前タスクをやってもらい(30円×100名=3000円)、指示に準拠してくれた対象群の80名のみがメイン実験に参加して全員分のデータを活用すると(300円×80名=24000円)、合計で3000+24000=27000円で済むため、3000円のコスト削減となります。
多様なUI操作実験への汎用性
本研究のメイン実験はスマートフォン上でのタップタスクでしたが、事前タスクではそれに関係のない「画像のサイズ調整タスクの誤差」を計測しました。ここでのポイントは、研究者がメイン実験のデータを使わずに、事前タスクの結果だけでクラウドワーカーの指示準拠度をスクリーニングできることです。したがって、事前タスクはそのままに、メイン実験を別のもの(たとえばパソコンでのマウス操作実験や、スマートフォンでのテキスト入力実験など)であっても、汎用的なスクリーニング方法として適用できる可能性があると考えています。
7. おわりに
本記事では、わずか9秒の画像サイズ調整タスクでクラウドワーカーをスクリーニングし、UI操作実験のデータ品質(ここでは予測モデルの適合度)を向上させる手法を解説しました。しかし、実運用においてはいくつかの課題も残されています。まず前述のように、事前タスクにおける誤差はグラデーションになっているため、閾値を何mmにすれば指示に準拠するクラウドワーカーだけを残せるのかが一意に決められません。また、閾値を極端に厳しくすれば(たとえば誤差1mm以下)、それをクリアしたクラウドワーカーのデータ品質はかなり高くなると期待できますが、対象群の人数が減りすぎてしまい、必要な参加者数を集めるために時間がかかる懸念があります。
さらに、もし研究の目的が「UIを慎重に操作したり、逆に集中せずに操作したりする�など、クラウドワーカーのリアルな操作ログを収集する」などの場合は、このスクリーニングによって有益なデータまで排除してしまうこともありえます。今回の研究では「モデル評価のためにはノイズを除去したデータが望ましい」という前提を置きましたが、多様性を含んだ実態調査に重きを置く研究であれば、今回の方法とは異なるスクリーニング方法を検討する必要があるでしょう。
クラウドソーシング実験にはノイズが混入しがちだという指摘は以前からありました。しかし、メイン実験の性質に合わせた適切なスクリーニング方法を採用することで、クラウドソーシングは研究を支える強固なインフラになってくれるはずです。
なお、本論文のプレプリントはarXivで公開されているので、興味のある方はぜひご覧ください(https://arxiv.org/abs/2602.20594)。
関連するテーマについては、以下の記事でも紹介しています。


