こんにちは。LINE VOOM AI組織のサーバー開発者、Chanwoo ParkとYousung Yangです。
本記事ではAIに使用されるリアルタイム埋め込みを提供するサーバーを構築するにあたり、性能向上とインフラ費用削減を両立させたプロセスと結果についてお伝えします。
この記事は、AIに限らず、大量のデータをリアルタイムで提供するサーバーの構築を必要とする、あらゆる分野に通じる内容となっています(埋め込み自体の生成方法については触れていません)。サーバー構築時に常に課題となる性能向上とコスト削減に、この記事が参考になることを願います。
この記事では、具体的な数値をなるべく省略しました。開発者が扱うデータはそれぞれ違うので、具体的な数値を提示するより、問題のアプローチ方法と解決策を詳しく説明し、みなさんがそれを簡単に再現して効果を体感できるように記事を構成しました。
プロジェクトの紹介
今回のプロジェクトを一文で説明すると、「大量の埋め込みをリアルタイムでAIモデルに提供するためのプロジェクト」です。AIモデルのニーズに合った埋め込みをリアルタイムで提供するサーバーを構築するにあたり、高TPSと高速な応答速度を実現し、それと同時にインフラコストを最小限に抑えることを目標としました。
プロジェクトの目標
プロジェクトの目標を重要度の高い順に一つずつ具体的に紹介します。
1. 高TPS(transactions per second)達成
今回のプロジェクトで最も重要な目標は、要求されるTPSを達成することでした。TPSが達成されないとサービスが成り立たないためです。AIモデルが要求するTPSは、数値だけを見ると他のLINEサービスでも見られる通常のレベルでしたが、細かく分析してみると他のサービスのTPSに数十倍、数百倍を掛けたようなレベルでした。その理由については、後述の埋め込みのデータ特性で説明します。
2. 高速な応答速度
どれだけ良いサービスでも、応答時間が遅くてユーザーを待たせてしまうと、決して良いユーザーエクスペリエンスを提供できません。後述しますが、データサイズが大きく、応答速度が遅かった、それを短縮することが重要でした。
3. インフラコスト削減
高TPSを実現するためには、必然的に大規模なインフラを使用することになります。となると、コスト削減の重要性が増し、プロジェクトの主な目標の一つとなります。例えば、VM10台規模のサービスでサーバーの性能向上と効率化によって5台に削減するのと、VM100台規模のサービスで50台に削減するのとでは、その割合は同じでも、実際のコスト削減効果は10倍違います。
埋め込み(embedding)とは?
まず、この記事でよく出てくるキーワードである埋め込みとは何かを解説します。
AIと埋め込み
まず、埋め込みの例を見てみましょう。
"data": [
{
"embedding": [
1.543545822800004554,
-0.014464245600309352,
-0.021545555220005484,
...
-2.547132266452536e-05,
-1.5454545875425444544,
-1.0452722143541654544
],
}
],ご覧のとおり、何を意味するのか人間には分かりにくい数字の配列です。埋め込みは元々人間のためのものではなく、AIのためのものです。埋め込みは、単語、画像、動画などの実際のオブジェクトをコンピュータが処理できる形で表現したものです。カンマで区切られた数字一つ一つが次元であり、その数字の配列全体がベクトルであると考えると、各埋め込みをn次元の空間に表示できます。
これに基づいて、オブジェクトAの埋め込みとオブジェクトBの埋め込みを空間に表示し、お互いの距離を測定して、お互いの類似度を判断できます。画像を例に挙げると、黒猫の写真と白猫の写真は、シマウマの写真よりも隣接した空間に表示されます。このように、埋め込みはAIがオブジェクト間の類似度を評価する際に使用する必須要素です。
リアルタイム埋め込みとは?
AIに埋め込みが必要なタイミングは大きく2つに分けられます。1つは、モデルを学習させるときで、もう1つは、学習されたモデルを実際のサービスに適用した後、ユーザーのリクエストを受けるときです。後者の場合、ユーザーのリクエストに素早く応答しなければならないため、サーバーはモデルがリクエストした大量の埋め込みを非常に速いスピードで提供する必要があり、このとき使用する埋め込みをリアルタイム埋め込み(realtime embedding)と言います。
埋め込みのデータ特性
埋め込みがより高い次元で構成されるほど、構成している値の範囲が大きいほど、AIモデルはより正確に判断できますが、これは埋め込みがより大きなデータになるという意味でもあります。さらに、AIモデルはこのような埋め込みを1件だけリクエストすることはありません。サーバーの観点から大きな埋め込みが複数件同時に入出力されるということは、大量のI/Oが発生することを意味します。
プロジェクトに適したDB選定
プロジェクトを開始して最初に行ったのは、DBの選定でした。プロジェクトの非常に高い性能要求レベルを達成するためには、高性能DBが必須だったからです。
必要なDBの特性を整理
まず、必要なDBの特性を把握したうえで、その基準をもとにどのDBを使うか判断できるため、具体的にどのような特性が必要かを以下のように整理しました。
RDB、NoSQLのどちらでもOK
今回のプロジェクトはリアルタイム埋め込みをキーと値で保存し、キー(サブキー(sub-key)を含む)で取得することで十分でした。保存されたデータの関係性を取得する用途ではないため、NoSQL種類のDBも使用できました。
シャーディング対応
QPS(query per second)レベルが変わっても、大量のI/Oを柔軟かつ高速にサポートし、拡張が必要なときに無停止でスケールアウトするためには、シャーディングがサポートされている必要があります。特に、ネイティブシャーディングをサポートするDBが推奨されます。MySQLのようにシャーディングを実装できる場合もありますが、効率性とメンテナンスを考慮すると、ネイティブシャーディン��グをサポートするDBが有利です。
ネイティブシャーディングを前提に設計されたDBは、複数のノードにデータが配置されるため、リクエストがノード全体に均等に分散され、その分ネットワーク負荷が分散されるというメリットがあります。このメリットは、特に埋め込みのようにネットワーク帯域幅を多く占有するデータを保存する場合、非常に重要な特性です。Redis ClusterやMongoDB Sharded Clusterがその代表例です。
複数のI/Oに特化しているか
複数の埋め込みを一度に大量取得する必要があるため、DBレベルで特化したコマンドをサポートし、そのコマンドが単発のコマンドより性能が良い方が有利でした。代表例としてRedisのmgetやhmgetコマンドは、個別のgetリクエストを繰り返すより数倍から数十倍も性能が優れています。
速い応答時間
どのサービスでもそうですが、リアルタイム埋め込みサーバーは特に応答時間が重要です。通常、メモリを基盤にしたDBが一番速い応答時間を示し、Redis ClusterやMemcachedがその代表例です。
QPSごとの構築費用
スケールアウトが可能なほとんどのDBは、コストを投入すればするほど性能が向上するため、どのDBでも目標QPSを達成できます。しかし、コストを考慮すると、投入費用に対してQPSが高いDBを選ぶ必要があり、特に今回のプロジェクトは要求されるQPSが非常に高かったので、QPSごとの構築費用がさらに少なくなるべきでした。QPSごとの構築費用は、Redis ClusterがMongoDBやMySQLよりはるかに少なくなります。
Reactive Driver対応
サーバーをReactorで実装し、DBがReactiveドライバーをサポートすると、Reactive Processingの優れた性能を享受できます。RedisやMongoDB、Cassandra、まだ一部機能に制限はありますが、MySQLもR2DBCというReactiveドライバーをサポートします。
DB選定 - Redis Cluster
私たちに必要なDBの特性を整理した結果、Redis ClusterをメインDBとして使うことにしました。
「Redis Clusterはキャッシュ用ではないですか?」
このような質問をされる方もいらっしゃると思います。実際、Redis ClusterはメモリベースのDBで、サーバーが再起動されるとデータが失われる可能性があります。通常、キャッシュの用途で使うことが多いです。
しかし、私たちは以下のようにもう少し深く考えてみた結果、データ保存用として使っても問題ないという結論を出しました。
- まず、Redis Clusterは複製することで、フェイルオーバー(fail over)と高可用性(high availability、HA)を実現します。Primary - Replica構造で動作し、Primaryに障害が発生した場合、フェイルオーバーが作動して自動的にReplicaがPrimaryに昇格されます。そのため、PrimaryとReplicaに同時に問題が発生しない限り、大きな問題はありません。個人的にRedis Clusterを10年前から使っていて、フェイルオーバーが動作した状況を経験したことは数えるほどで、全面障害でサービスが長時間停止したり、データが消失したりしたことはありません。フェイルオーバー動作時のサービス停止時間は10~30秒程度で、このとき、欠落した書き込み要求があれば、ログなどを使�って復旧できます。
- 最悪の場合にデータが失われても、復旧できるように設計できます。サービスによって外部からデータを再注入して失われたデータを埋めることができ、普段はバックアップ用DBに二重書き込みを行い、これを活用することもできます。
- DB障害発生時、サーキットブレーカーを通じて関連モジュールを停止させ、ユーザーに代替データを提供できます。この措置により、全面障害ではなく、一部機能の障害レベルになるので、サービスへの影響を最小限に抑えられます。
Redis Clusterのメリット(優れたQPSと応答性能)がメモリベースのDBというリスクを上回る場合、Redis Clusterをデータ保存用に使用することが有利です。このとき、リスクは上記の1を考慮した発生確率で、2と3の方法を通じてリスクを低減できる点を踏まえて評価を行う必要があります。私たちは評価結果、リアルタイム埋め込み用DBとしてRedis Clusterを採用する場合、メリットがリスクよりはるかに大きいと判断しました。
「Redis Clusterをキャッシュとして使えばいいのでは?」
以下の2つの案について、一度に複数の案件の取得と応答がすべて完了したときにデータを使用する必要がある場合、体感できる差は非常に大きいです。
- A:Redis Clusterをキャッシュとして使用し、他のDBをメインで使用
- B:Redis Clusterをメインで使用し、他のDBに二重書き込みしてバックアップとして使用
例えば、キーが違う100個の埋め込みをリクエストして応答を受けた場合、AとB、それぞれの状況に対するキーごとの応答時間が以下のようになるとします。
A: (10, 14, 15, 120, 15, 112, ... ,10)
B: (10, 12, 15, 12, 11, 15, ... , 20)
(単位: ms)このとき、最終応答時間が、AはMAX(A) = 120ms、BはMAX(B) = 20msです。ここで、Aのみにある100msを超える応答時間は、キャッシュヒットが発生せず、他のDBで応答した時間が含まれた時間です。つまり、Aのようにキャッシュヒット率が100%でない状況で他のDBの応答速度が遅くなると、Bに比べて応答時間の面で非常に不利になります。したがって、高速な応答速度が重要だった今回のプロジェクトには、AのようにRedis Clusterをキャッシュとして使う方法は適切ではありませんでした。
Redis Clusterをどのように使うのか?
選定されたDBとしてのRedis Clusterをシステム要件に合わせて使うためのプロセスを説明します。
データモデリング
データモデリング(以下、モデリング)はRedis Clusterに実際にどのような形でデータを保存するかを決める段階です。
モデリングの際には、以下の観点で十分に検討する必要があります。
- Redis Clusterは、キーをハッシュしてデータを分散配置します。そのため、キーが均等に分散されなければ、高い性能を得られません。キーが分散されず、特定のスロットにリクエストが集中する現象をホットスポット(hot spot)と言いますが、ホットスポットが発生すると、性能が大幅に低下してシャーディングの意味が薄れてしまいます。
- 「Big Key Issue」(参考)が発生しないよう��にします。Big Key Issueが発生すると、性能低下はもちろん、サービス障害まで発生する可能性があります。
- サービスのデータアクセスパターンを考慮して最適化します。
- Redisでサポートされるデータ型を考慮して設計します。
私たちは上記のような点を考慮してモデリングを行い、Redis hashesをデータ型として採用しました。
Redis hashesを選択した理由
Redis hashesを選択した理由は、以下のようなメリットがあるからです。
- AIで使う埋め込みにはさまざまな種類があり、1つのキーで同時に複数の種類の埋め込みを取得する場合が多いです。このとき、Redis hashesを使用すると、キーの下にサブキーを作成できるため、複数の種類の埋め込みを一度に取得できます。
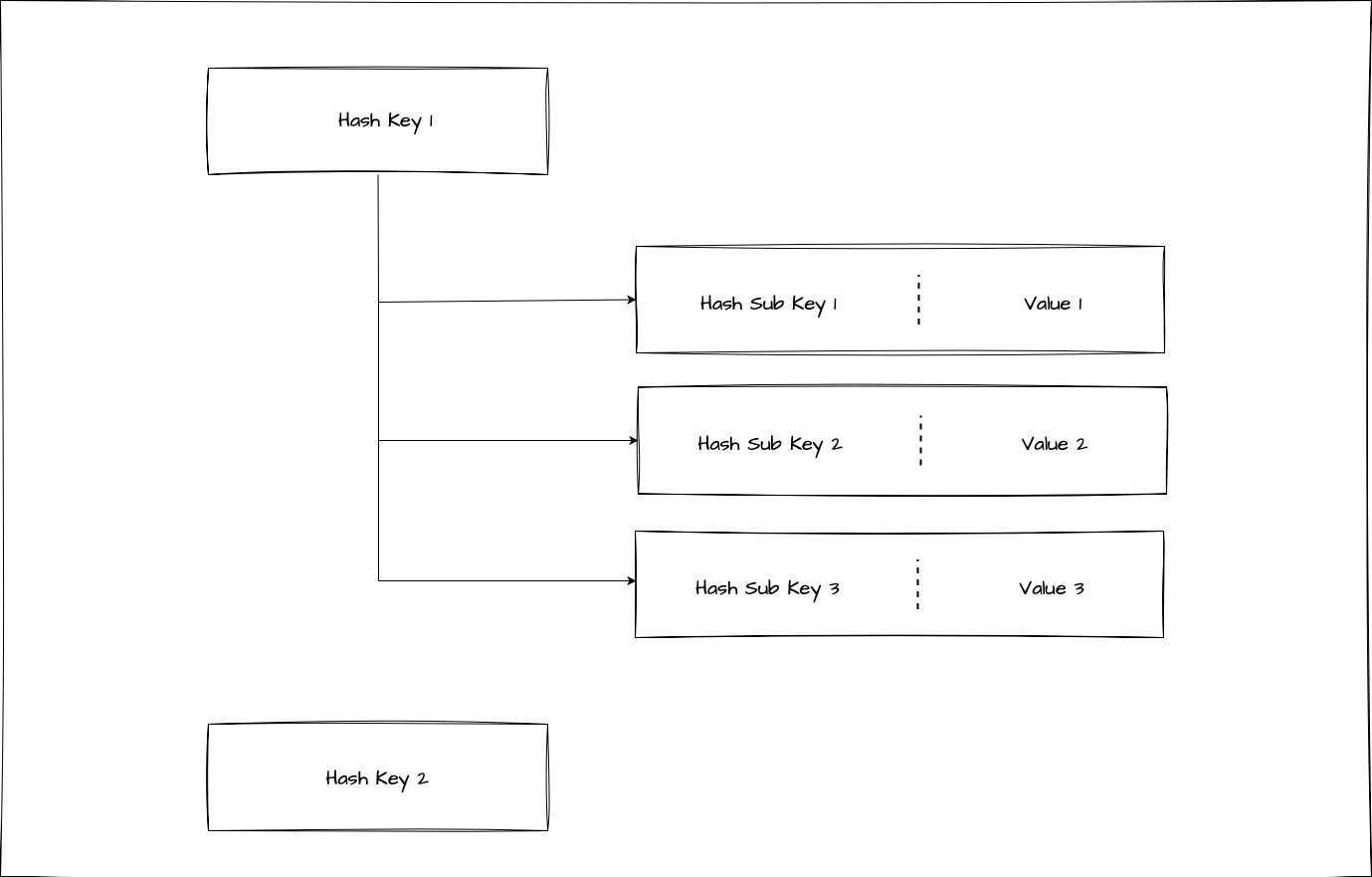
- Redis hashesのデメリットとして指摘されるサブキーごとにTTL(time to live)の設定ができないという問題は、サービス要件上、大した問題ではありませんでした。
- Redisがサポートするhmgetコマンドを使うと、必要なサブキーの全体または部分集合としてデータを読み込めます。このような特徴はデータアクセスパターンの観点から大きなメリットです。
mget vs hmget
Redis hashesを使わず、埋め込みタイプごとにキーをより分散配置し、mgetコマンドで一度に読み込む方法も可能でしたが、埋め込�みタイプが追加されるほどキーも増えるというデメリットがありました。また、Redis hashesを使う方がキーを基準にデータを一度に管理しやすいという点を考慮して、データタイプとしてRedis hashesを選択し、コマンドとしてhmgetを選択しました。
ネットワークトラフィックとデータサイズを減らす
ネットワークが問題ですか?
サーバー開発において、ネットワーク帯域幅を気にすることはそれほど頻繁にはありません。ここで言うネットワークとは、呼び出し元サーバーと応答サーバー間、ロードバランサーとサーバー間、DBとサーバー間、サーバー内の個別のPodのネットワークなど、すべてを指します。
ネットワークが問題になるくらいなら、ユーザーのリクエストが数十万TPS以上で、サーバーとDB間のQPSは数十万から100万単位になるのが一般的です。しかし、今回ははるかに少ないTPSでもネットワークトラフィックが懸念されました。その理由は、非常に大きなデータを大量に取得しなければならなかったからです。
これを体験するには、性能の良いDB群とサーバー群を用意し、サーバーで制限なしで大量のデータを読み込むようにした後、ネットワークとサーバーの反応を観察してみます。監視設定がよくできているインフラ環境であれば、多くの警告メッセージと通知が届くはずです。それだけ重大な問題を引き起こす可能性があります(まさか本番環境で試すことはないと思います)。
データサイズと性能の関係
たとえネットワーク帯域幅を占有�しないとしても、別の問題があります。入出力データのサイズが大きいほど、応答時間は増加します。DBのデータ入出力性能にも影響を与え、ネットワーク転送時間も増加するためです。応答時間が長くなると、TPSが低くなる問題も発生します。
このような問題を解決するには、データサイズを小さくする必要があります。しかし、必要なデータのみを含めるようにデータ構造を設計しても、埋め込みのように除外できる部分がないデータもあります。このような場合、結局データを圧縮する必要があります。圧縮には略語を使って簡単に長さを短くする方法から、圧縮フォーマットを使って本格的にデータを圧縮する方法もあります。
しかし、圧縮が万能の解決策にはなりません。圧縮と解凍のためにCPUリソースを消費することになり、追加の処理時間が発生して、全体的な性能低下につながる可能性があるためです。効率的な圧縮方法が見つからなければ、かえって性能が低下することになります。
情報エントロピーとは?
データ圧縮の話をする前に、まず情報エントロピーについて説明する必要があります。情報エントロピー(以下、エントロピー)というのは、アメリカのコンピュータ科学者であるクロード・シャノンが1948年に論文で紹介した概念です。データ圧縮において、エントロピーは圧縮アルゴリズムに入力するデータのランダム性を意味します。
エントロピー式は次のようになります。
H(X) = - ∑p(x)logP(x)ここで、H(X)はエントロピーを、P(x)は確率変数Xの各状態の確率を意味します。
実際にエ�ントロピーを計算してみましょう。以下の文のエントロピーは1.80です。
abcaacbbbaaabdcdbbaa一方、以下の文のエントロピーは4.12です。
abhijklmcdefgxyzuvux一目でわかるように、ランダム性が高いほどエントロピーも高くなります。
圧縮と情報エントロピーの関係
圧縮は元データのエントロピーと密接な関係があり、圧縮とエントロピーの関係については多くの論文もあります。簡単に言えば、エントロピーを基にデータ圧縮で達成できる圧縮後の容量の下限値を知ることができます。
以下のグラフは、元データのエントロピーレベルとデータ型、各圧縮方式の圧縮効率を示したものです(数値は説明のために任意に調整しました)。
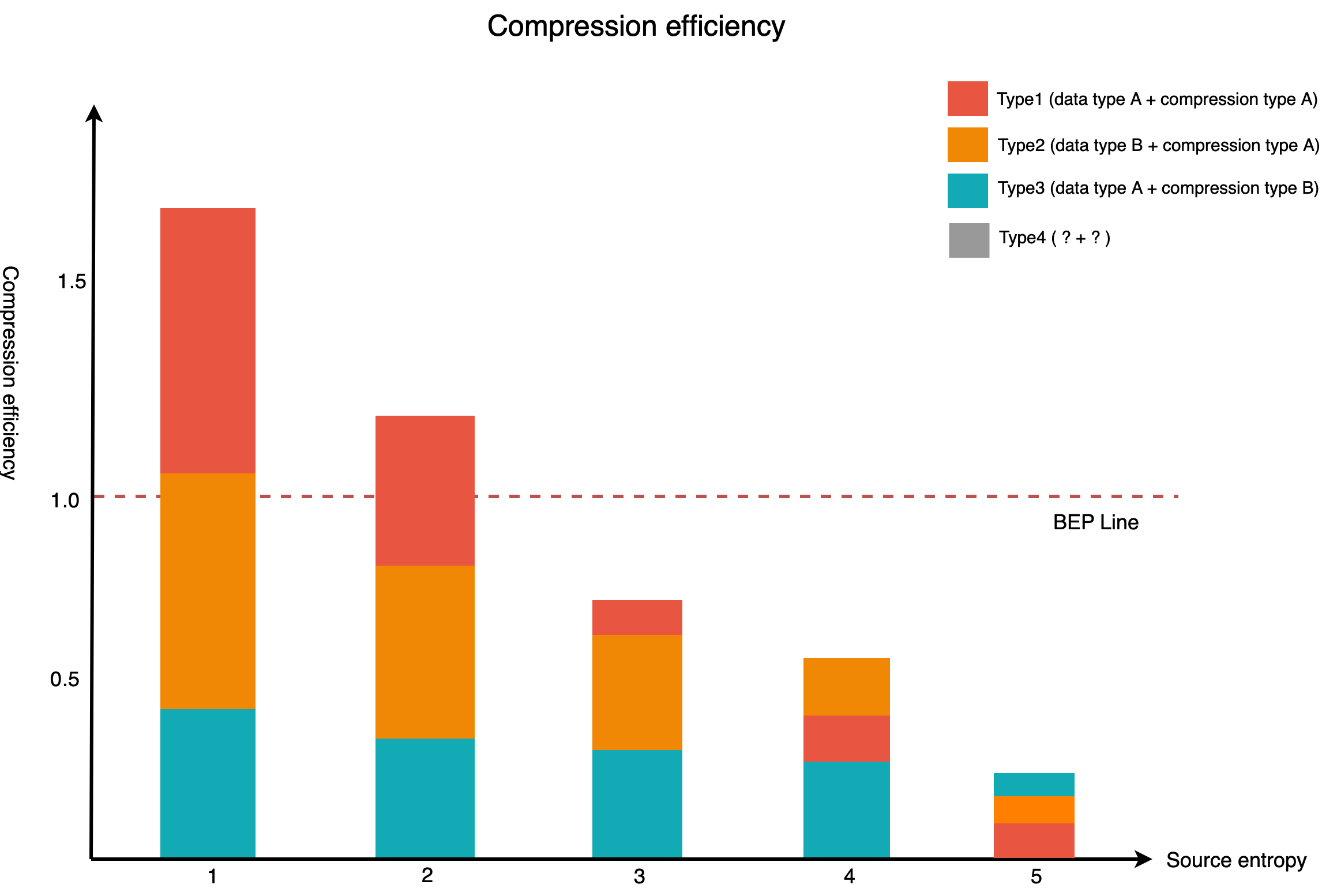
上のグラフを見ると、X軸のエントロピーが増加するにつれて、Y軸の圧縮効率が低下することが確認できます。BEP(Break Even Point)ラインは、圧縮効果とコストが等しくなる地点です。元データのエントロピーが高いほど圧縮効率は低下し、極端に高いデータの場合、圧縮効果がありません。圧縮効率がBEP線である1.0にならない場合は、圧縮することでかえって性能が低下します。
クエスチョンマークで表示したType4については、以下のセクションで説明します。
埋め込みを圧縮できますか?
埋め込みの場合、エントロピーレベル�がさまざまで、エントロピーが極端に高いデータもあります。もし、埋め込みのエントロピーが上記のグラフで3以上であれば、圧縮を適用する方法はないのでしょうか?
必ずしもそうではありません。上記のグラフでクエスチョンマークで表示したType4の圧縮効率が、BEPラインを越えればいいのです。圧縮効率を上げるには、圧縮効果を上げるか、同じ圧縮効果を出しながら圧縮コストを下げる方法があります。今回のプロジェクトでは圧縮コストを下げる方法で圧縮効率を上げた結果、画期的な性能向上を達成できました。
圧縮コストを少しでも削減するために、データ型と圧縮方式を一緒に変数として置いて、新しい組み合わせを見つける多くのテストを行いました。ここでデータ型とは、プログラミング言語やDBのデータ型だけを意味するのではなく、埋め込みをデータ化するためのすべての方式を意味します。
上のグラフを見ると、Type1とType2は同じ圧縮方式を適用していますが、効率面で大きな差があることがわかります。データ型と圧縮方式は、データサイズの削減にそれぞれ単独でも効果がありますが、組み合わせて使うことで相乗効果を生み出すこともあります。そのため、効率の高い新しい組み合わせが見つかれば、より多くの種類の埋め込みに圧縮を適用し、サイズを削減できます。
もちろん、埋め込みのエントロピーが非常に高く、圧縮には適さないケースでは、圧縮を採用せず、データ型の変更のみを検討することも可能です。しかし、埋め込みにはさまざまな種類があり、多くの場合、AIが複数の埋め込みを同時に要求するため、圧縮も変数として検討する必要があり�ます。
埋め込み圧縮で得られた効果
埋め込み圧縮は、前述したプロジェクトの目標である応答時間の短縮とTPS達成、インフラコスト削減の達成に多くの貢献をしました。特に、応答時間の短縮は、Redis ClusterをメインDBとして採用したメリットを除けば、ほとんどが圧縮によって得られた結果でした。
他にも重要な効果がもう一つあります。同じインフラ環境でプロジェクトをより簡単に拡張できるようになったことです。インフラ環境、例えば、ネットワークは帯域幅に限界があります。しかし、圧縮することでデータのサイズが小さくなり、まるで帯域幅が上がったような効果が得られ、プロジェクトの拡張の余地も大きくなりました。
インフラコスト削減のためのさらなる工夫
ここまで紹介した内容だけでも埋め込みサーバーの性能を向上させ、インフラコストを削減できましたが、これだけでは不十分だと考え、インフラコストを削減するための追加の方策を検討しました。
コードの最適化
プロジェクトの全モジュールを最新バージョンのReactive Stackで構成しました。いつもReactorを使ってきましたが、今回は特にビジネスロジックを実装する部分で代替案を考える余地が多かったです。性能向上の余地があれば、何度もコードを修正し、開発者間で相互コードレビューを行いました。Reactorは最も高い性能を発揮できる技術の一つですが、間違った使い方をすると性能が著しく低下する技術でもあります。これを防ぐために、開発者間でコードレビューを行い、その��ために何よりもコードレビューに抵抗感がない雰囲気作りに努めました。また、レビュースピードを上げるために、PR(pull request)の内容が多くて複雑な場合、Zoomを利用して頻繁にビデオでディスカッションを行いました。
サーバープロファイリングとGC方式を選択
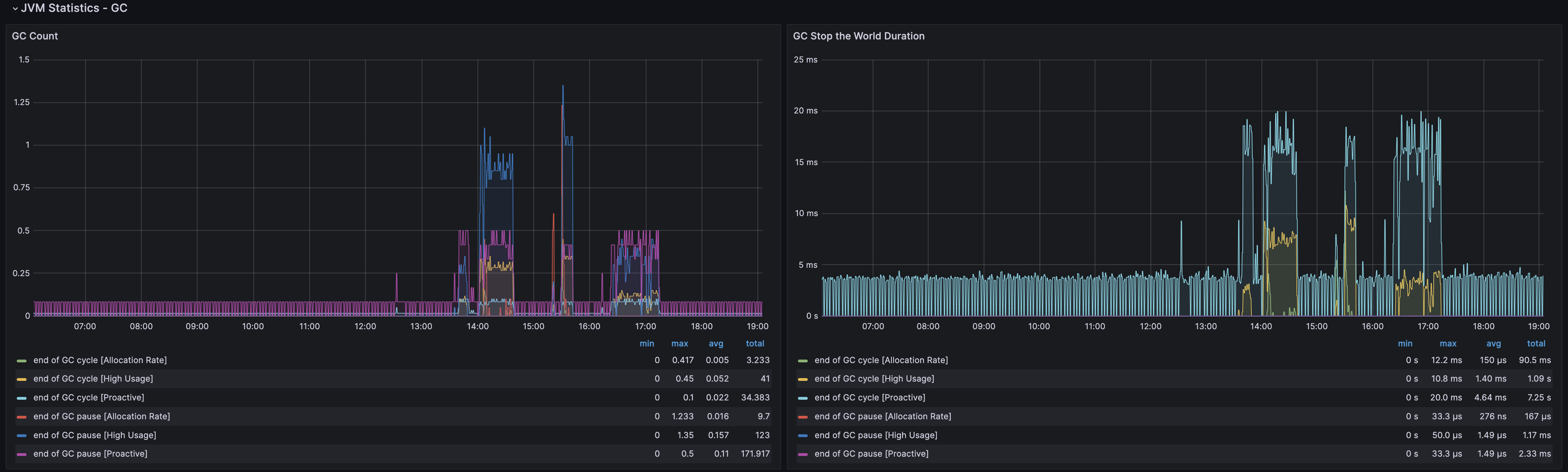
サーバーにプロファイリングツールをインストールし、特にメモリとGC(garbage collector)の動作を注意深く観察しました。GCとしては、開発初期にはZGCを使用していましたが、運用開始頃にGenerational ZGCの性能レポートを見て、私たちのサービスに重要ないくつかの性能が向上することを期待してGenerational ZGCに変更しました。
Generational ZGCは、ZGCより効率を上げるために「young」と「old」で世代を区分し、各領域に対してGCを実行します。Generational ZGCを使用するには、JDK21以上で以下のオプションを追加してください(既にZGCを使っている場合は、-XX:+ZGenerationalを追加するだけになります)。
java -XX:+UseZGC -XX:+ZGenerationalGenerational ZGCが動作すると、2つのGCがそれぞれ実行されることを観測できます。サーバーの負荷が低いときはZGCと大きな差がないですが、負荷が上がるときは性能差を感じられます。
Kubernetes環境でリソースの割り当てを最適化する
今回のプロジェクトもKubernetes環境で動作するように開発したので、リソースをより細かく調整して割り当てられました。
ここ数年で手掛けた他のプロジェクトもKubernetes環境で開発しましたが、今回のプロジェクトはとりわけネットワーク使用量が多いという違いがありました。今まで実施してきたプロジェクトで常に性能テストと最適化を行ってきたので、その経験からおおよその最適設定値は知っていました。しかし、ネットワーク使用量がとりわけ多いことを考慮すると、以下のことをすべて白紙に戻して再検討を行い、新しい最適設定値を見つけなければなりませんでした。
- サーバーのスペック
- ノードあたりのPod数
- Podに割り当てるCPUやメモリなどのリソース量
- JVMオプション
- 新しく採用した技術の特定リソースの使用量
結果として、前述で説明した圧縮に次いで、この部分で最も大きなインフラコスト削減効果が得られました。これにより、データに基づいて判断するためには、すべてのファクターの影響を測定する性能テストを実施し、それを基に最終的な設定値を決定する必要があるという結論に至りました。
効率的に性能テストを行う
性能テストは通常、性能テストプラットフォームで行います。実際と同様にリクエストを発生させてシステムに負荷をかけながら、それによる性能の変化を測定します。リクエストを作成する際、実際のサービスと同様に再現すればするほど、性能測定の精度が高くなります。
この方法の一番大きなデメリットは時間と労力が��かかるという点です。そのため、開発者のローカル環境でテストを行うこともありますが、ローカル環境は実際のサーバー環境と大きく異なるため、結果もかなりの差が出ることがよくあります。
今回のプロジェクトでは、テストすべき性能ファクターが非常に多く、それに応じて検証すべきテストシナリオも多様でした。そこで、各テスト方式のメリットとデメリットを考慮し、2つの方式を組み合わせることで時間も節約し、精度も高める方向で性能テストを行うことにしました。
性能ファクター間の相対比較は、効率を考慮したJMHによるローカルテストで
ローカルテストは精度を上げるためにJMH(Java Microbenchmark Harness)を使用し、主に性能ファクター間の相対比較を行いました。
例えば、前述で説明したデータ型と圧縮方式に関するテストは、その候補群が非常に多かったです。圧縮方式だけでも、圧縮方式によっては圧縮レベルを何段階にも設定できるため、これをすべて性能テストプラットフォームで実施すると、時間がかかりすぎてプロジェクト全体のスケジュールに支障をきたすことが予想されました。
そのため、すべてをテストプラットフォームで行う前に候補群をある程度絞り込む必要があり、その作業をJMHを用いたローカルテストで行いました。
本格的な性能テストは、十分なスペックで準備した性能テストプラットフォームで
JMHを用いたローカルテス�トで候補群を絞った後は、性能テストプラットフォームで本格的な性能テストを行いました。
性能テストプラットフォームを構築する際に注意した点は、埋め込みサーバーに十分な負荷を与えられる程度のサーバーを確保し、各インスタンスが十分なネットワーク帯域幅を確保するように配置することでした。実際に性能テスト中に渋滞区間が発生して確認したところ、埋め込みサーバーの問題ではなく、テストのために負荷を発生させていたサーバーの問題であることが確認され、テスト中にクラスターを増設することもありました。
私たちは、目標性能(TPS、応答時間)達成とリソース使用削減のバランス点を見つけるために他のプロジェクトよりはるかに多くの性能テストを実施しました。その結果、すべての性能テストを終えて決定した最終設定値は、それまで実施した他のプロジェクトの設定値とはかなり差が大きいものでした。
結果の解釈が主観的にならないように、結果の整理と解釈作業も全員一緒に
テストシナリオが多いということは、結果を整理して解釈しなければならないことも多いことを意味します。このとき、テスト結果を主観的に解釈しないように、結果について一緒に議論も行いました。このように結果の整理作業を行ったおかげで、性能テストレポートを一目瞭然に整理でき、これはどんな言葉よりも説得力のある根拠になりました。
適用効果
今回のプロジェクトでは、結果的に全く新しいサーバーを開発しましたが、当初は既存のレガシーサーバーを�段階的に改善していく作業と並行して行いました。レガシーサーバーに前述で紹介した内容が適用されるたびに、大小の性能改善やインフラコストの削減効果がありました。その後、最終的に今回のプロジェクトでレガシーサーバー群を完全に置き換えた後は、個々のサーバーのスペックを大幅に下げ、必要台数も減らすことができました。ここまで紹介したプロセスを経ていなければ、高スペックのサーバーを何倍も増やし、それだけ追加費用が発生したでしょう。
下表は、当初のプロジェクト目標と各項目の適用効果を示したものです。
| 目標 | 目標達成への貢献度 | ||
|---|---|---|---|
| 高い | 普通 | 低い | |
| 高TPS達成 |
|
|
|
| 高速な応答速度達成 |
|
| |
| インフラコスト削減 |
|
|
|
他にも目標達成のために試した方法のうち、今回は効果がなかったためこの記事では紹介していない方法がいくつかあります。失敗した試み自体は経験として蓄積され、今後、他のプロジェクトで活用できることを期待しています。
おわりに
今回の記事で紹介した内容が、高性能サーバー構築やインフラコスト削減に興味を持たれている方に少しでも参考になればと思います。短期間でプロジェクトを完了できたのは、ご協力いただいた方々のおかげです。ありがとうございました。


