こんにちは。LINEヤフーでAIプラットフォーム向けのKubernetesクラスタの設計や構築、運用を担当している大村です。
LINEヤフーでは、100を超えるサービス向けにAI/機械学習を��活用したサービスのライフサイクル全般(MLOps)をサポートするAIプラットフォームを内製しています。
最近、AIプラットフォーム向けのKubernetesクラスタであるAI Cloud Platform(ACP)において、H100 GPUクラスタの導入が行われ、本格的に分散深層学習ワークロードを受け入れる基盤が整ってきました。それを契機として、ACPにおけるバッチスケジューラの選定を行いました。その結果、kube-scheduler(Scheduling Frameworkによる拡張)+Kueueという組み合わせを導入することにしました。
このブログでは、その検討の軌跡を紹介することで
- ACPにおけるスケジューリングの現状その課題
- AI向けKubernetesにおけるバッチスケジューラに求められる典型的な要件
- 現状における主な選択肢と評価基準
- なぜACPではkube-scheduler+Kueueという選択をしたのか
を共有させていただきたいと思います。AI/バッチ処理系のKubernetesクラスタに関わる方々にとって参考になれば幸いです。
LINEヤフーのAI Cloud Platform(ACP)の概要
LINEヤフーでは、100を超えるサービス向けにAI/機械学習を活用したサービスのライフサイクル全般(MLOps)をサポートするAIプラットフォームを内製しています。このプラットフォームでは、MLOpsを実践するためのライフサイクル全般をサポートしています。
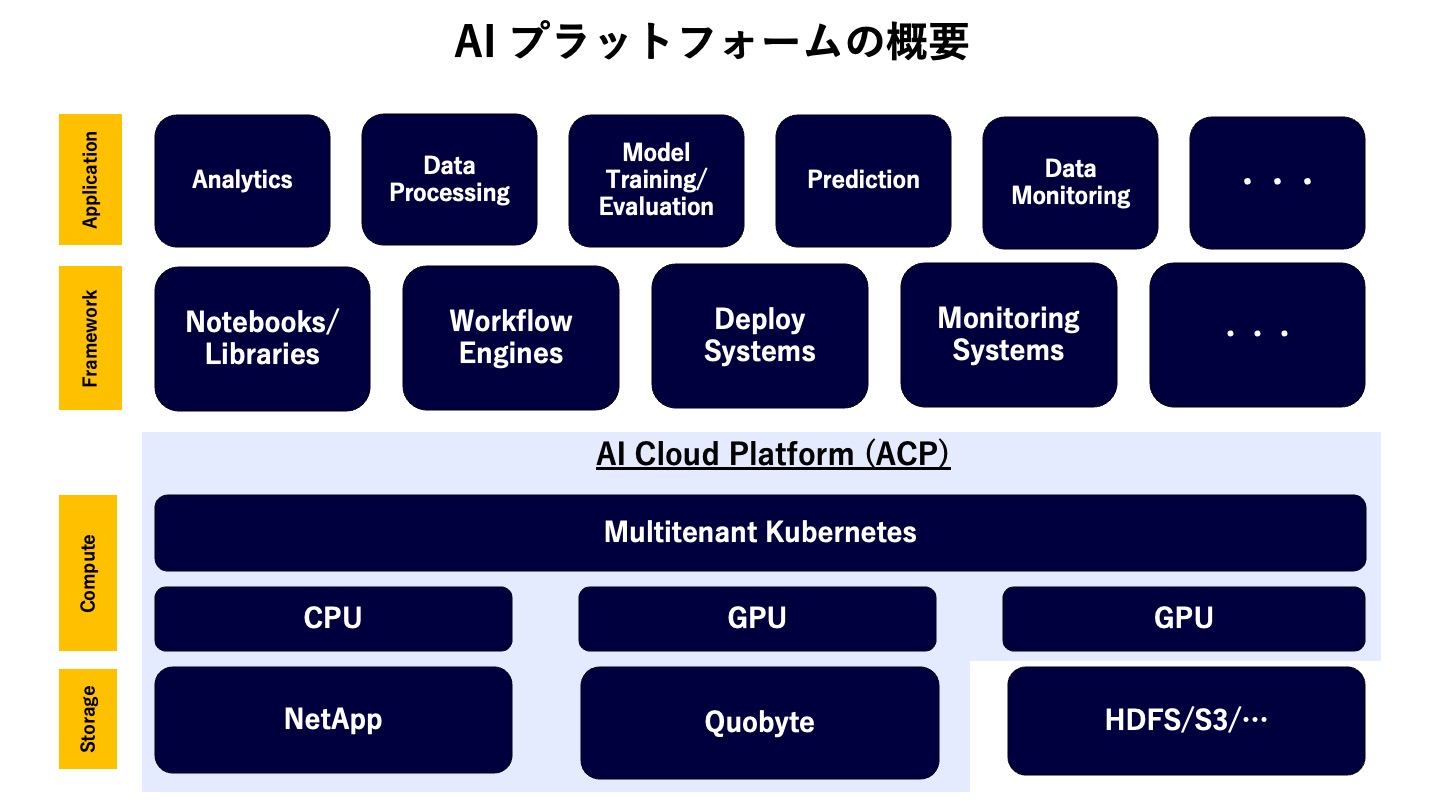
AIプラットフォームの中で、機械学習、大規模データ処理の計算処理の中心的な役割を担っているのがAI Cloud Platform(ACP)というKubernetesクラスタです。このクラスタは、CPUサーバだけでなく、複数のGPUモデルのサーバ群からなる、いわゆるMultitenant Heterogeneous GPUクラスタとなっています。
また最近、Rethinking AI Infrastructure Blogシリーズでも紹介させていただいている通り、データセンターレベル、物理GPUネットワークレイヤ、GPUサーバレイヤ/Kubernetesレイヤに至るまで、RDMAを活用した大規模分散深層学習に最適化された構成になっています。
これまでのACPにおけるスケジューリングの課題
ACPは、AIプラットフォームのKubernetesクラスタとして、これまで6年以上新規のフレームワークのサポート、社内システム連携のサポート、新規GPUのサポートなどの多角的な面で改善を行いながら多くのユーザを収容しつづけています。
ただし、スケジューリングについては、下記のような標準的なチューニングにとどまっていました。
- 重要なワークロードとそうでないワークロードを分けるためにPriority Classを活用
- kube-schedulerのNodeResourceFit/NodeResourcesBalancedAllocation Pluginをチューニングを導入しBinPackingを実現
- ResourceQuotaの仕組みを使ってテナント(Kubernetes Namespace)ごとに利用できるリソース上限を設定
かつ、これには下記のような課題があることも認識されていました。
- All-Reduce型の分散深層学習ジョブが多いと学習ジョブ同士がデッドロックしてしまう(i.e. Gang Schedulingがない)
- 大規模な分散深層学習ジョブを実行すると他のテナントのPodが大量に止められてしまう
- Quotaの上限値しか管理しておらず、テナントごとの利用可能リソース下限値の設定が難しかった
- ResourceQuotaのScope SelectorによるPriority ClassごとのQuota制御は利用可能ですが利用はしていませんでした
- Quotaの制限を超えるとPod作成エラーとなりジョブを投げることもできない
などです。
ACPにおけるバッチスケジューラの選定
そこで、今一度ACPにおけるバッチスケジューラの選定を行いました。選定においては、
- バッチスケジューラに求められる機能要件・運用要件を再整理
- 現時点での現実的な選択肢の選定
- それぞれの選択肢の比較
- ACPとしてのバッチスケジューラの決定
のステップを踏んで行いました。
次節から、これらの検討の軌跡を紹介していきます。
ACPにおけるバッチスケジューラに求められ��る要件
この節では、ACPのバッチスケジューラに求められる要件についてまとめました。大きく機能要件・運用時要件に分けて検討を行いました。
機能要件
Kubernetesにおける標準的な要件
Kubernetesの最もPrimitiveなワークロードの単位であるPodに備わっている、もしくは標準のkube-schedulerに備わっているスケジューリング機能においてよく使われるであろう要件をまとめました。サードパーティのカスタムスケジューラを選択する際、これらの機能はサードパーティが独自に実装する必要があります。
- Priority and Preemption
- Node selector, Node-affinity/anti-affinity
- Inter-pod affinity, anti-affinity
- Taint/Toleration
- Image Locality
- Scheduling Readiness
- Pod Overhead
- Sidecar Containers
大規模機械学習・バッチ処理特有の要件
Kubernetes上で大規模に機械学習・バッチ処理を動作させる際に必要となると思われる要件をまとめました。これらの要求は独特なものが多いので要件ごとに概要を説明していきます。
Gang Scheduling (Co-Scheduling)
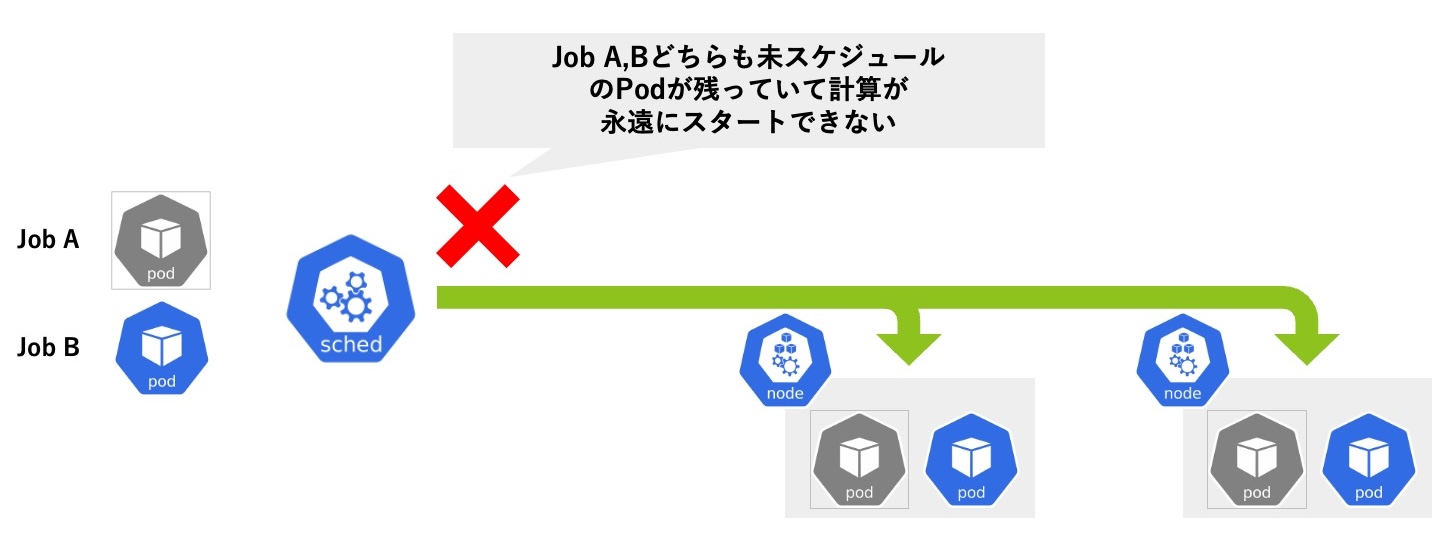
All-Reduce型の分散深層学習では、すべてのワークロードが動作していないと計算が始められないという特性を持っています。1 Podずつスケジュール判断を行うスケジューラの場合、下記のように簡単にデッドロックが起こってしまいます。
- 2 Nodeあると仮定します。簡単のためそれぞれのNodeには2 Podまで配置できるとしましょう
- この状態で、Job A(3 Pod), Job B(3 Pod)が要求されたとして
- Job A, Job BのPodが交互にスケジュールされると、各Nodeに2 Podずつ配置された状態でNodeが満杯になってしまい、
- Job A, Job Bともに1 Podずつが未スケジュールのまま永遠に待たされることになってしまいます
- もちろんJob側でtimeout等のヒューリスティックを用いてデッドロックを解決することはできますが、Kubernetesクラスタ管理者としてはこのようなJob側での対応を行わなければならない状況は避けたい
なので、
デッドロックが起きないようにJob Aの3 Pod, もしくは Job Bの3 Podを同時にNodeに配置したい
という機能要求が発生します。
Bin Packing
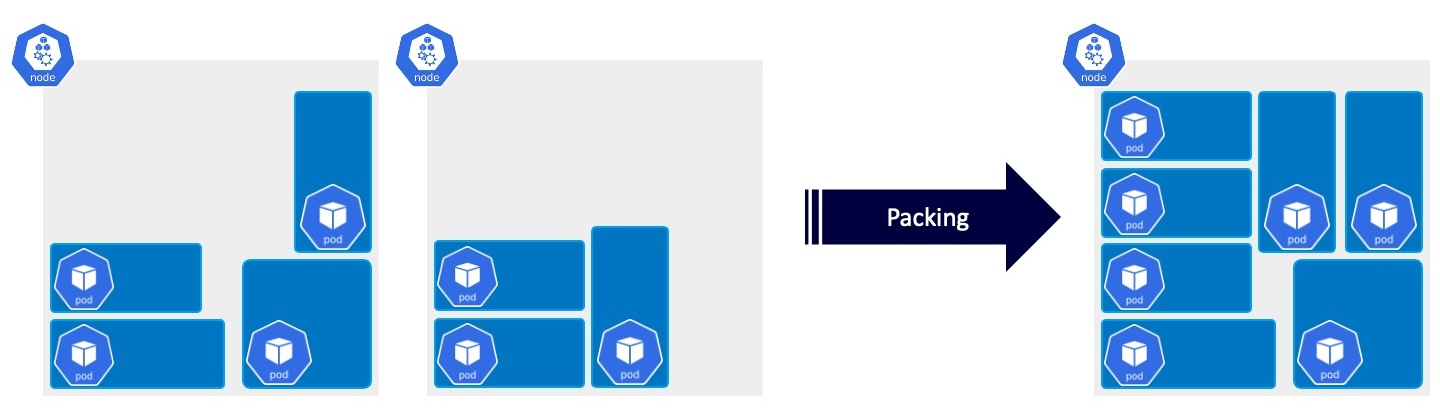
これは計算リソースをできるだけ効率的に活用したいという要求です。クラスタ全体でフラグメンテーション(Podが配置できないような小さな隙間)を少なくなるようにしたほうが、よりたくさんのジョブを同時に処理できるというわけです。
Network Topology Aware Scheduling
分散深層学習においては、Pod同士が大量のデータ(重みやニューラルネットワーク上を流れるデータなど)をやり取りします。つまり学習に参加するPod同士の通信遅延が学習時間に大きく影響することになります。ACPのH100 GPUクラスタは800 Gbpsという広帯域を持っていますが、それでもPod同士が近いに越したことはありません。
下図はRethinking AI Infrastructure Blogシリーズ Part2で紹介されたACPのH100 GPUクラスタのネットワーク構成図です。この図でいえば、SU(Scalable Unit) 1, SU 16にジョブを分散して配置するよりも、SU 1に閉じ込めて配置したほうが、Super Spineスイッチを経由する必要がないため低遅延で計算ができるのです。
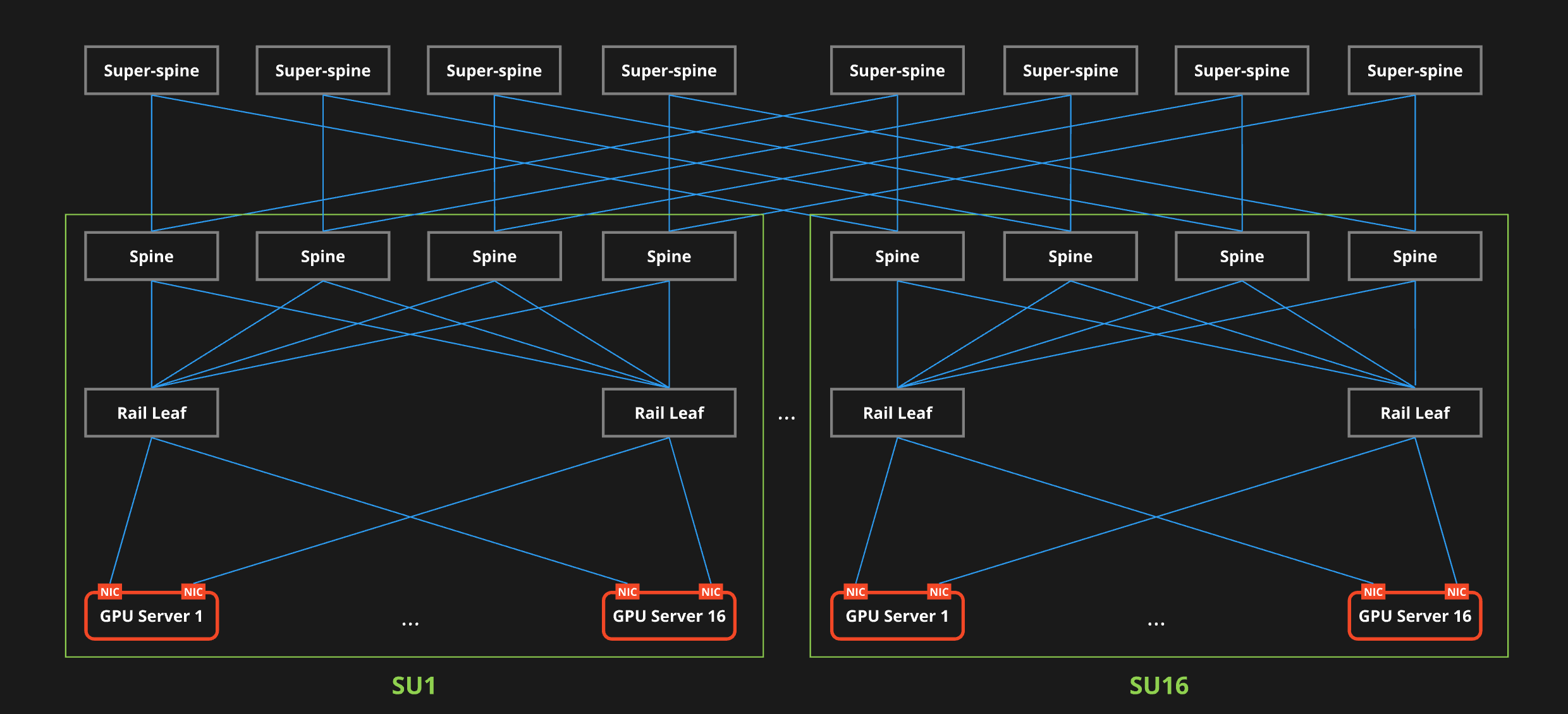
出典:GPUクラスタネットワークとその設計思想(Rethinking AI Infrastructure Part 2)
Oracle CloudのFirst Principles: Superclusters with RDMA—Ultra-high performance at massive scaleで��はNetwork Topology Awareなスケジューリングを実践しているとのことです。一概には比較できませんが、Oracle Cloudのデータセンタでは、データセンタ内の一番遠いGPU同士のラウンドトリップ遅延が20マイクロ秒、一番近いGPU同士のラウンドトリップ遅延が6.5マイクロ秒とのことです。大雑把に計算すると、ジョブ全体を閉じ込めたほうが実行時間が2倍以上速くなるということです(※帯域についてはフルバイセクションが確保されていると仮定します)。
Intra-Node Topology Aware Scheduling
同じようなことがNode内でも発生します。Node内にもさまざまなトポロジが存在します。典型的には、NUMA(Non-Uniform Memory Access)トポロジ、PCIeトポロジがあります。NUMAトポロジは計算が実行されるCPUからメモリを読み込むスピードに影響しますし、PCIeトポロジはGPUとNICのデータ転送スピードに影響します。つまりPodをNode内で実行する際に、これらのトポロジを考慮してより近くに配置したいという要求です。
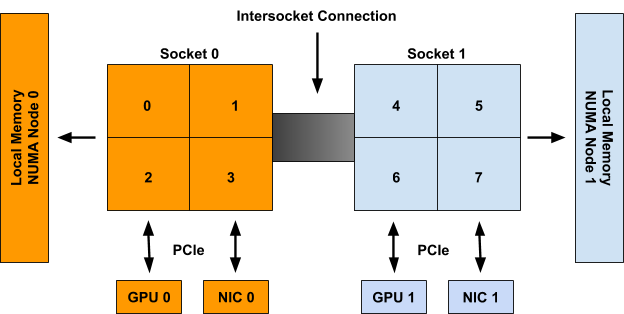
出典: Kubernetes Topology Manager Moves to Beta - Align Up!
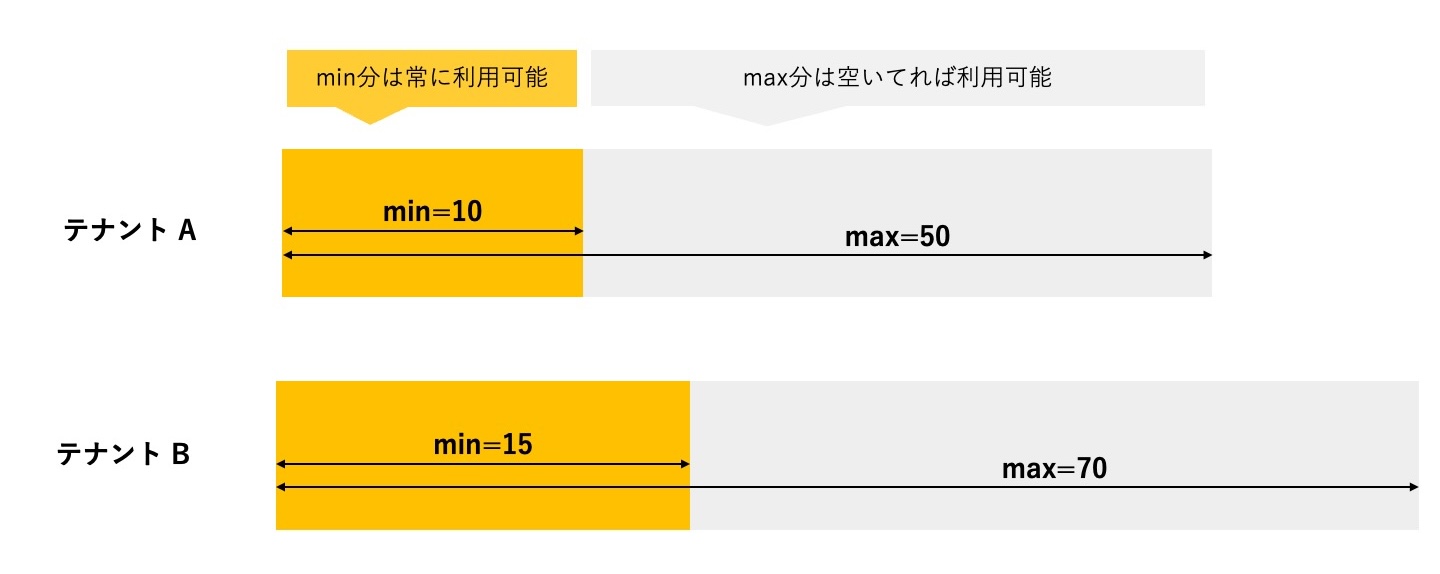
Min-Max Quota管理
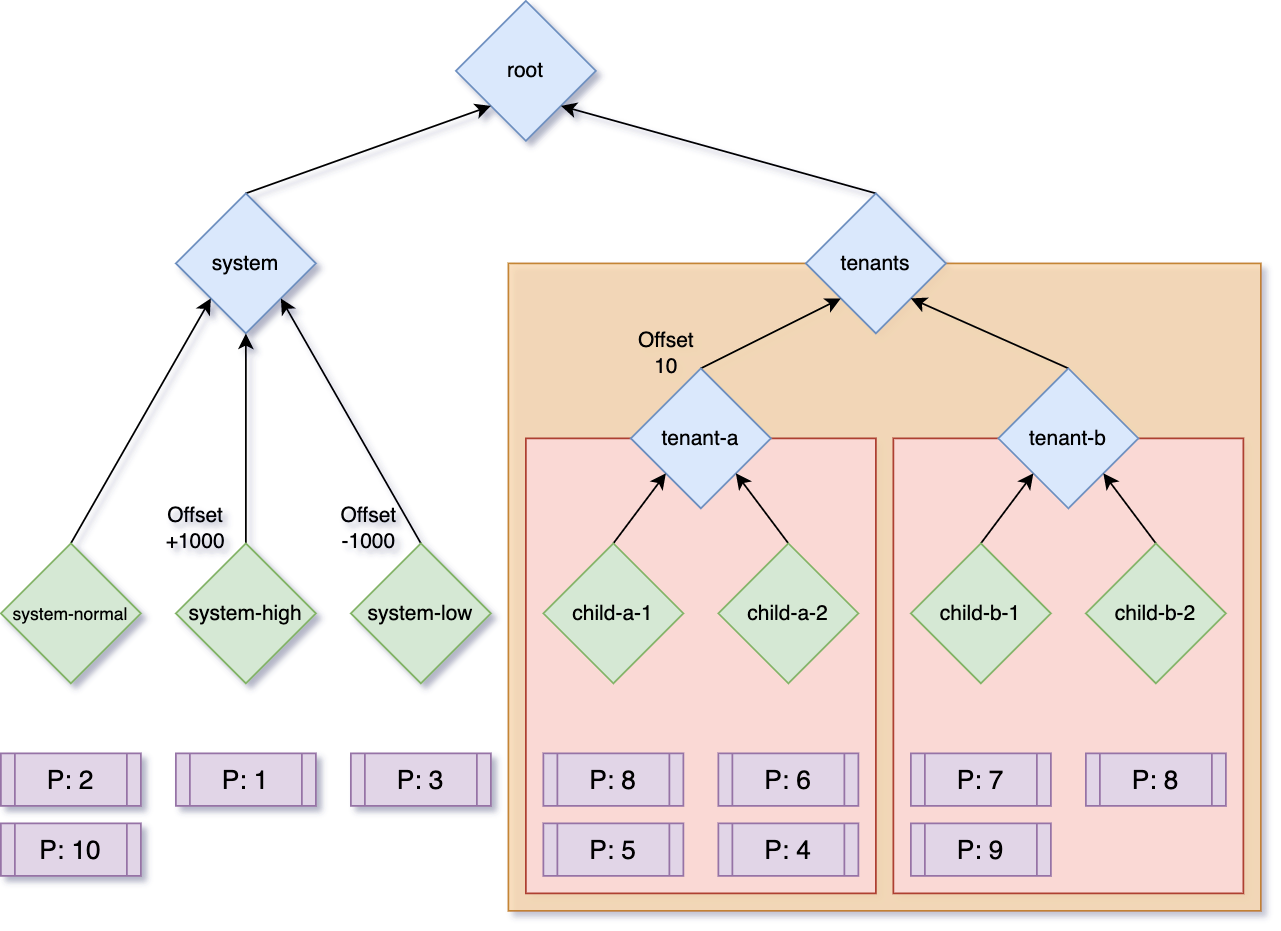
課題の節でも述べた通り、Kubernetes標準のResource Quotaでは上限値しか指定できません。マルチテナントなクラスタでは、各テナントにおいて、「このくらいは最低限使いたい」という要求は一般的です。また、クラスタ管理者としては、各テナントに割り当てる計算リソースの上限値を割り当て、乱用を防いだり、空き計算リソースをテナント間で融通しあえるように管理したいという場合も多いです。このように、本要件は、割当計算リソースの上下限を指定してQuota管理を行いたいという要求です。一般的にはElastic Quota, Capacity Schedulingと呼ばれることが多いと思います。この要件の拡張として、Quotaの管理を階層的に管理したいという要求もあります。
Resource Fairness
マルチテナントなクラスタでは、クラスタ内の計算リソースは複数のテナントが共有して利用しています。前節のようなMin-Max Quota管理を行っている場合、最低利用リソース量(Quotaの下限値)として払い出されている分はテナント固有のリソースと捉えられますが、払い出されていない分の計算リソースについては共有リソースとして捉えられます。この場合、共有資源をどのテナントがどのくらい利用できるか?という点で公平性を確保したいというのも一般的な要求です。共有リソースが空いていたからといって、特定のテナントがクラスタ全体を長時間独占/寡占してしまうことは一般的には良くないと考えられます。ただし、プロジェクトやテナントには企業としての重要度も存在するため、現実的には重みをつけた上での公平性が求められます。
Job Queueing
これは想像しやすいと思います。いわゆる「キュー」にジョブを詰めて順番に実行したいという要求です。Kubernetes標準のResource Quotaでは上限値を超えるとAPIエラーとなりPodを作成することができなくなってしまいます。管理されたQuotaの範囲内で、空きができ次第順番にジョブを実行してほしいという要求です。
運用系の要件
機能要件だけでなく、長く安定して運用していくためにも気になることはあります。今回の検討では下記を要件として挙げました。
- Observabilityを確保するためのメトリクスはあるか?
- リリースサイクルは安定しているか?
- ドキュメントは適切に整備されているか?
- アップグレード作業にあたって適切な情報が提供されているか?
拡張性
機能要件を満たさない場合、独自に拡張することが求められます。できるだけForkを行わない形で独自拡張部分だけ内部でメンテナンスできると望ましいです。
検討を行った選択肢
選択肢を選ぶ上で、OSSであること、OSSプロジェクトの成熟度を重要視して選定を行いました。今回の検討では下記を対象としました。バージョンは検討を行った時点での最新バージョンとなっています。
- kube-scheduler(Scheduling Frameworkによる拡張) + Kueue
- バージョン:
- プロジェクト成熟度:
- Kubernetes自体はCNCF Graduated Project
- KueueはSIG Schedulingのサブプロジェクトとして開発が行われている
- Volcano
- バージョン: v1.10.0
- プロジェクト成熟度: CNCF Incubation Project
- もともとSIG Schedulingのサブプロジェクトとして開発されていたkube-batchが前身となっている。
- Apache Yunikorn
- バージョン: v1.6.0
- プロジェクト成熟度: Apache Graduated Project
- Apache Hadoop YARNを強く意識して開発されている。特徴としてKubernetesに依存しない作りになっており、Kubernetes依存部分はyunikorn-k8sshimという独立したコンポーネントに切り出されている
koordinatorも初期検討では候補に上がったのですが、プロジェクト成熟度がCNCF Sandbox Projectであることを考慮し、選択肢としては採用しませんでした。
選択肢ごとの比較
本節では、選択肢ごとの対応概況を説明していきます。各機能の詳細説明は本ブログでは割愛します。それぞれのWebサイトを参照ください。
機能要件
それぞれのサポート状況を大まかに判定するために下記のマークを用いて記載していきます。
- ⭕: サポートしている
- 🔺: サポートが限定的(or 拡張をsupportしている)
- ❌: サポートしていない(要fork)
Kubernetesにおける標準的な要件
Priority and Preemption
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
- kube-scheduler+Kueue
- PodとKueueの2レベルで優先度・Preemptionが利用可能
- Priority and Preemption
- Kueue - Workload Priority Class
- Kueue - Preemption
- Volcano
- Volcano - Priority
- 公式のPriorityClassを参照可能
- ただしPreemptionロジックは独自(Fair Share等導入するPluginによって異なる)
- Yunikorn
- Yunikornでは優先度が柔軟に設定できる。
- 公式のPriorityClassの値をベースに、queueごとにoffset, fencingが設定でき、それらを基に計算されるEffective Priorityが使われる
- Yunikorn - Queue Priority - offset
- queueにpriority offsetが設定を指定して優先度が調整可能
- Yunikorn - Priority Fencing
- fencingを利用すると、queue内で見たときと別のqueueから見たときで優先度が変えられる
- 外から評価したときはqueueのoffsetが優先度として使われる
- この図がわかりやすい
- Preemptionロジックは独自実装
- ただしintra-queue(queue内) preemptionは未実装
Node selector, Node-affinity/anti-affinity
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | 🔺 |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- Yunikorn
- preferredDuringSchedulingIgnoredDuringExecutionが未サポート(PodSpecに定義しても無視される)
Inter-pod affinity, anti-affinity
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | 🔺 |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- Yunikorn
Taint/Toleration
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | 🔺 |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- Yunikorn
Image Locality
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | 🔺 |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- Yunikorn
Scheduling Readiness
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ❌ |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- v1.10.0 (upstreamから5ヶ月遅れ)で対応
- Yunikorn
- 未サポート(明示的に評価しないように実装している)
Pod Overhead
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- Undocumentedだが実装では考慮している
- Yunikorn
- サポートしている
- Undocumentedだが実装では考慮している
Sidecar Containers
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
- kube-scheduler+Kueue
- サポートしている
- Volcano
- サポートしている
- v1.10.0(upstreamから9ヶ月遅れ)で対応
- Yunikorn
- サポートしている
- v1.6.0(YUNIKORN-2475, upstreamから9ヶ月遅れ)で対応
大規模機械学習・バッチ処理特有の要件
Gang Scheduling (Co-Scheduling)
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | 🔺 |
- kube-scheduler+Kueue
- Scheduling Frameworkによる拡張が利用可能(kubernetes-sigs/scheduler-plugins, pfnet/scheduler-plugins)
- Kueueにも厳密な意味でのGang Schedulingではないが、課題の本質であるデッドロックをtimeoutベースで解決するAll-or-Nothingという機能が利用可能
- Volcano
- Volcano - PodGroupを利用可能
- API Groupは
scheduling.volcano.sh/v1beta1となっていて、kubernetes-sigs/scheduler-pluginsで提供されているscheduling.x-k8s.io/v1alpha1のPodGroupとは異なる。
- API Groupは
- 基本的にはVolcanoにおけるPrimitiveであるVolcanoJobから使う想定だが、Bare Podでも
scheduling.k8s.io/group-nameannotationをつければPodGroupに所属させられるように実装されている
- Volcano - PodGroupを利用可能
- Yunikorn
- Yunikorn - Gang Scheduling
- 仕様がSparkに最適化されており、All-Reduce型の分散深層学習には向かない挙動がある
- 指定されたGangの要求する計算リソース総量がqueue上で確保できることが確認できたら、Placeholder Podを作成し、対応するPodが作成されたらPlaceholder Podと置き換えるという挙動を行う
- もしユーザ側でGangのPod数を誤って多く指定すると、余分なPlaceholder Podが作成され、処理もスタートできない
- 期待としては、指定された数のPodが作成されるまでスケジュールされてほしくない
Bin Packing
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
- kube-scheduler+Kueue
- Resource Bin Packing (
NodeResourceFit,RequestedToCapacityRatioplugin)
- Resource Bin Packing (
- Volcano
- Volcano - BinpackでRequestedToCapacityRatioによく似た機能が利用可能
- Yunikorn
Network Topology Awareness
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| 🔺 | 🔺 | ❌ |
- kube-scheduler+Kueue
- Kueue - Topology Aware Scheduling
- またScheduling Frameworkを用いて独自拡張を行うことが可能
- Volcano
- 未サポート
- カスタムプラグインを挿入可能なので独自拡張を行うことが可能
- Yunikorn
- 未サポート
- 内部的にはPlugin化されているが、外部からカスタムプラグインを挿入するようなことが不可能なためフォークが必要
Intra-Node Topology Awareness
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ❌ |
- kube-scheduler+Kueue
- Volcano
- Volcano - Numa-aware
- volcano-sh/resource-exporterをデプロイする必要がある
- Volcano - Numa-aware
- Yunikorn
- 未サポート
- 内部的にはPlugin化されているが、外部からカスタムプラグインを挿入するようなことが不可能なためフォークが必要
※ schedulerではないが、スケジュール先のNodeのCPU Managerでも一応考慮可能だがpolicyによってはbind後にエラーになる
Min-Max Quota管理
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
- kube-scheduler+Kueue
- Kueue - Cluster Queue
- min:
nominalQuotaで設定 - max:
borrowingLimitで他のCluster Queueから借りられる総量を設定
- min:
- 階層Quota管理
- AlphaレベルAPIだがCohort APIで階層構造を構成可能(v0.9.0でリリース)
- Kueue - Cluster Queue
- Volcano
- Volcano - Queueには詳細な記載がないが、GitHubのdocsにCapacity scheduling Designに詳細が記載されている
- min:
guaranteeで設定 - max:
capacityで設定 - (
deservedフィールドをつかって他のqueueから借りてきて利用できる量が設定可能)
- min:
- 階層Quota: サポートしている
- Volcano - Queueには詳細な記載がないが、GitHubのdocsにCapacity scheduling Designに詳細が記載されている
- Yunikorn
- Yunikorn - Resource Quota Management
- min:
guaranteedで設定 - max:
maxで設定
- min:
- 階層Quota対応: サポートしている
- Yunikorn - Resource Quota Management
Resource Fairness
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| 🔺 | ⭕ | ⭕ |
- kube-scheduler+Kueue
- Kueue - Fair Sharingで利用可能だが、Preemption時のみ考慮される
- 階層Quotaの機能を利用した場合は未サポート(Support Hierarchical Cohorts with FairSharing #3759)
- Volcano
- Volcano - DRF
- queue, resourceごとに重み付け設定可能(Volcano - Queue - weight)
- Volcano - DRF
- Yunikorn
- Yunikorn - Fairness Policy, Yunikorn - FairSortingPolicy
- queueごとにresourceごとに重み付け設定も可能(Yunikorn - Resource weighting)
Job Queueing
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ⭕ |
それぞれサポートしている。定義されたQuotaに沿ってJob Queueingが可能。
運用時要件
- Observabilityを確保するためのメトリクスはあるか?
- kube-scheduler+Kueue
- Volcano
- 公式ドキュメントに記載はないが、GitHubの
docs/ディレクトリにScheduler Monitoringのページが有る
- 公式ドキュメントに記載はないが、GitHubの
- Yunikorn
- リリースサイクルは安定しているか?
- kube-scheduler+Kueue
- kube-scheduler(Kubernetes): 4ヶ月サイクル
- Kueue: 随時(最近は毎月minor upgradeしている)
- Volcano
- Volcano - Recent Postsによると約2ヶ月ごとにリリースされている
- Yunikorn
- Yunikorn - Release Announcementsによると約2ヶ月ごとにリリースされている
- kube-scheduler+Kueue
- ドキュメントは適切に整備されているか?
- kube-scheduler+Kueue
- Kubernetes: 公式ドキュメント
- 詳細にドキュメントされている
- 最新情報もメンテナンスされている
- Kueue: 公式ドキュメント
- 詳細にドキュメントされている
- 最新情報もメンテナンスされている
- Alpha API(例えばCohort API)についてはReferenceのみの記載
- Kubernetes: 公式ドキュメント
- Volcano
- 公式ドキュメントあり
- Volcano - Recent Postsにあるリリースノートだけに載っていて公式ドキュメント未記載の機能がある。
- そうした機能の多くはGitHubの
docs/ディレクトリにあることが多い(例: vGPU, JobFlow API, Capacity Scheduling, Rescheduling, Load Aware Scheduling)
- Yunikorn
- 公式ドキュメント
- 細かくドキュメントされている印象を受ける
- 最新情報もメンテナンスされている
- kube-scheduler+Kueue
- アップグレード作業にあたって適切な情報が提供されているか?
- kube-scheduler+Kueue
- kube-scheduler(Kubernetes): リリースノートが発行されておりUrgent Upgrade Notesの記載もある
- Kueue: リリースノートが発行されており、Urgent Upgrade Note (v0.10.0)の記載もある
- Volcano
- リリースノートが発行されており、Upgrade時の手順の記載がある
- Yunikorn
- リリースノートが発行されており、Incompatible changesの記載がある
- kube-scheduler+Kueue
拡張性
| kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|
| ⭕ | ⭕ | ❌ |
- kube-scheduler+Kueue
- kube-scheduler
- Scheduling Frameworkを利用してPluginを独自拡張可能
- Kueue
- External Controllerを実装することによって、KueueがNativeに対応するジョブにも対応できる
- kube-scheduler
- Volcano
- Volcano - Custom Pluginを利用して独自にプラグインを実装し、実行時に挿入可能
- Yunikorn
- 内部実装はPluginになっているが、独自に拡張したカスタムプラグインを刺すということはできない
- 柔軟な設定を通して拡張を行うスタイルに見受けられる
- 足りない機能を実装する場合はForkを行う必要がある
選択肢ごとの比較のまとめ
長くなってしまったので表にまとめます。
| 要件 | kube-scheduler+Kueue | Volcano | Yunikorn |
|---|---|---|---|
| Kubernetesにおける標�準的な要件 | - | - | - |
| Priority and Preemption | ⭕ | ⭕ | ⭕ |
| Node selector/Node affinity,anti-affinity | ⭕ | ⭕ | 🔺 |
| Inter-pod affinity,anti-affinity | ⭕ | ⭕ | 🔺 |
| Taint/Toleration | ⭕ | ⭕ | 🔺 |
| Image Locality | ⭕ | ⭕ | 🔺 |
| Scheduling Readiness | ⭕ | ⭕ | ❌ |
| Pod Overhead | ⭕ | ⭕ | ⭕ |
| Sidecar Containers | ⭕ | ⭕ | ⭕ |
| 大規模機械学習・バッチ処理特有の要件 | - | - | - |
| Gang Scheduling | ⭕ | ⭕ | 🔺 |
| Bin Packing | ⭕ | ⭕ | ⭕ |
| Network Topology Awareness | 🔺 | 🔺 | ❌ |
| Intra-Node Topology Awareness | ⭕ | ⭕ | ❌ |
| Min-Max Quota管理 | ⭕ | ⭕ | ⭕ |
| Resource Fairness | 🔺 | ⭕ | ⭕ |
| Job Queueing | ⭕ | ⭕ | ⭕ |
| 運用系の要件 | - | - | - |
| Observability | ⭕ | ⭕ | ⭕ |
| リリースサイクル | ⭕ | ⭕ | ⭕ |
| ドキュメント | ⭕ | 🔺 | ⭕ |
| アップグレード情報 | ⭕ | ⭕ | ⭕ |
| - | - | - | |
| 拡張性 | ⭕ | ⭕ | ❌ |
- kube-scheduler+Kueue
- 機能要件: Resource Fairness以外はVolcanoと要件のカバー率は問題ない
- 運用要件: Kueueのバージョンがまだv0系である以外はアクティブに開発されており懸念なし
- 拡張性: 懸念なし
- Volcano
- 機能要件: 古くからあるKubernetes向けBatchスケジューラとして一番機能的なカバー率が高い
- 運用要件: ドキュメントが公式サイト/GitHubに分散されていたりして管理体制に少し懸念がある
- 拡張性: 懸念なし
- Yunikorn
- 機能要件: Apache Hadoop YARNを意識して開発されているからか、機能カバー率は良くない。ただしPriority制御については一番柔軟に設定できる。Apache Hadoop YARNで動作させていたワークロードをKubernetesへ移行する際には候補となり得る
- 運用要件: 懸念なし
- 拡張性: 設定が柔軟だが、その範囲から外れると拡張性は低い(Forkが必要)
kube-scheduler(Scheduling Frameworkによる拡張)+Kueueを選択した理由
前節からも分かる通り、機能要件的にはVolcanoが一番カバー率が高いという結果になりました。古くからKubernetes上でのバッチスケジューラとして開発されている一日の長というところでしょうか。
ただし、ACPでは、下記の観点を考慮してkube-scheduler+Kueueを選択することにしました。
- 要件カバー率はほぼ同等なこと
- カバーできていないのは階層型Quota管理を行ったときのResource Fairnessの機能のみであり、Kueue自体非常に活発に開発されているため近い将来サポートされる見込みが高いと判断
- Volcanoはサードパーティとして公式Schedulerの新機能への追従にラグがある
- 例えば、Scheduling Readiness, Sidecar Containersといった機能は、Upstreamから9ヶ月遅れてリリースされています。
- Podのスケジュール、Quota管理はそれぞれ独立した責務なのでそれぞれ別のコンポーネントが担う方が、柔軟な管理・運用が可能
- Volcanoの場合schedulerが両方の責務をカバーしますが、
- kube-scheduler+Kueueの場合
- kube-scheduler: PodをスケジュールするNodeを選択する
- Kueue: Quota/Job Queueingの管理
- とそれぞれ独立したコンポーネントが独立した責務が割り当てられている
おわりに
本ブログでは、AI Cloud Platform(ACP)におけるバッチスケジューラとして、kube-scheduler(Scheduling Frameworkによる拡張)+Kueue、Volcano、Yunikornを比較検討し、kube-scheduler(Scheduling Frameworkによる拡張)+Kueueを選定した軌跡を紹介しました。現在は、具体的なリリースプランの策定・準備を進めており、今後具体的なリリースを行っていく予定です。



{kind=link}