こんにちは。LINEヤフーでAIプラットフォームのコンピュート基盤の設計や構築、運用を担当している道下です。
この記事ではRethinking AI Infrastructureの連載の第三弾として、LINEヤフーのAIプラットフォームを支えるGPUクラスタのサーバ構成やパフォーマンスについて解説します。この記事が普段GPUクラスタのサーバ内部の設計やパフォーマンスチューニングなどを行っている方々にとって有益な情報になれば幸いです。
本資料の内容は前回のPart2をすでに読んでいることを前提として記載されています。 そのため、まだPart2を読んでいないという方はそちらを先に読むことを推奨します。
LINEヤフーにおける機械学習基盤とその課題
LINEヤフーのAI Cloud Platform(ACP)
サーバの内部設計の話を始めるには、まず弊社における学習基盤クラスタであるAI Cloud Platformについて触れる必要があります。
LINEヤフーには、社内のAI・MLユーザ向けのプラットフォームであるAI Cloud Platform(ACP)というプラットフォームが存在しています。ACPはKubernetesをベースとした基盤にさまざまなフレームワークをホスティングしているプラットフォームであり、学習用途でGPUを利用したい社内のユーザやテナントを受け入れています。ユーザはこのフレームワークなど自由に利用し、独自の学習タスクをPodとして起動し実行することができます。
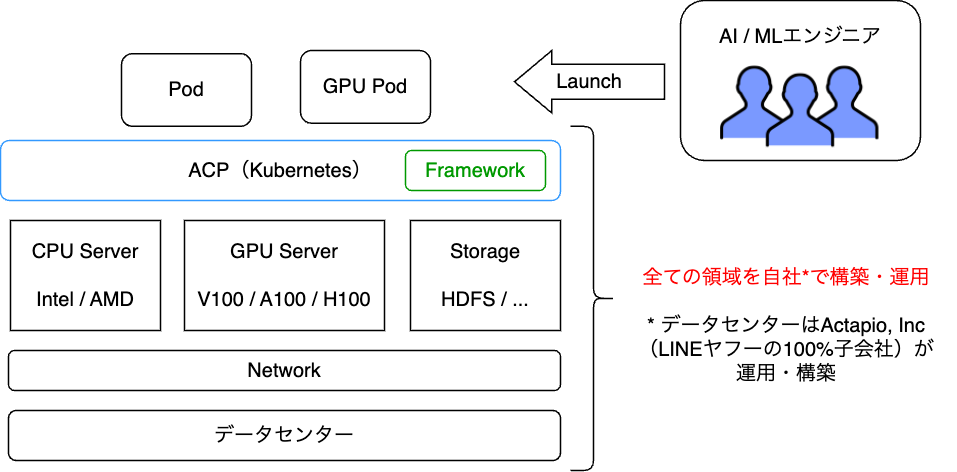
この機械学習基盤は、6年ほど�前から稼働を開始し、現在も新規のフレームワークのサポート、社内システム連携のサポート、新規GPUのサポートなどの多角的な面で改善を行いながら多くのユーザを収容しています。
従来のACPの構成とその課題
ACPはもともと、IaaS基盤チームから提供されるGPU VMを利用して、Kubernetesクラスタを構成していました。IaaS基盤チームはACP向けのOpenStackクラスタを提供しており、PCI Passthroughを利用してGPUやNICをVMにアタッチしACPに提供していました。 特にこのACP向けクラスタは特殊で1HVあたり1VMで提供していました。
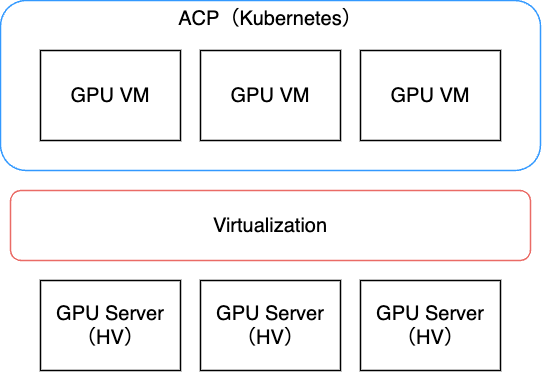
1HVあたり1VMでは、仮想化による集約面でのメリットはありませんが、それ以外に以下のようなメリットがありました。
- サーバ操作をOpenStack API経由で実行できること。
- OS再インストールなどの再構成もAPI経由で簡単に実施できる。
- 仮想NWによるネットワークポリシーの適用が行えること。
- ハイパーバイザ(ここではGPUサーバをハイパーバイザ化)のレイヤで、複雑なNW機能を実現している。
また、以下のような方針をとることで、VMの性能がベアメタルと比較してほぼ遜色がなくなるため、仮想化することにメリットが大きかった、という経緯があります。
- 1HVあたり1VMの構成の場合、CPUもPinningして提供しているため、リソース量も性能もほぼハイパーバイ�ザと同じ。
- GPUやNICなどのデバイスはPCI Passthroughの仕組みを利用するため、ベアメタルでデバイスを取り扱うのとほぼ同等の性能が出る。
そのため、従来のACPのサーバはすべてこのVM構成を取っていました。
一方で、今回の連載記事の主題となっているGPUインフラのサーバでは、GPU間の通信を高速化する上で、次のような課題を抱えることになりました。
- GPUサーバのPCIeトポロジーのレベルで最適化を考えていく必要があり、サーバ構成や仮想化の可否を改めて考え直す必要があった。
- サーバ構成の変更に伴って、従来の仕組みをそのまま利用することが難しくなり、サーバ内部のネットワークの構成を再設計する必要があった。
結果的に、これらの課題を解決する目的で、サーバ構成やサーバ内のネットワーク構成を大きく変更することになりました。以降ではわれわれがこの判断に踏み切った理由や方針について、それぞれ詳細に説明していきます。
GPUサーバの変化とLINEヤフーの構成
AIの発展に伴うGPUサーバの変化とPCIeトポロジーレベルの最適化の必要性
従来、単一ノード上のGPUメモリでは収まらないサイズのモデルを学習するケースや、大規模なデータを分割して学習させたいケースなどでは、複数ノードを利用した分散学習が行われてきました。特に昨今では、大規模な基盤モデルの需要が増加し、パラメータ数が膨大になったことにより、大規模にGPUサーバを確保し分散学習を行う需要が顕著に増加してきました。
その��ような中で、サーバシステムの構成自体も大きく変化を見せており、近年の大規模学習向けGPUサーバは、サーバ1基に対して8個のGPUと8枚の高帯域NICが搭載されている形になります。この話はPart2でも取り上げましたが、今回は特にパフォーマンス最適化において重要な話になるため、少し深掘りしていこうと思います。
ご存じの通り、サーバ内部ではGPUやNIC、DISKなどのデバイスはサーバ内部のバスによって接続されています。 基本的に現在のサーバではPCI-Express (PCIe) と呼ばれるバスで接続されることが一般的です。普段意識することは多くありませんが、OSではこのPCIeによって接続されたデバイスのトポロジーを認識し、論理的なトポロジーのデータ構造を作ります。 これは例えば以下のように確認できます。
$ lspci -tv
-+-[0000:e0]-+-00.0 Advanced Micro Devices, Inc. [AMD] Device 14a4
...
+-[0000:a0]-+-00.0 Advanced Micro Devices, Inc. [AMD] Device 14a4
| +-00.3 Advanced Micro Devices, Inc. [AMD] Device 14a6
| +-01.0 Advanced Micro Devices, Inc. [AMD] Device 149f
| +-01.1-[a1-a5]----00.0-[a2-a5]--+-00.0-[a3]----00.0 NVIDIA Corporation GH100 [H100 SXM5 80GB]
| | +-01.0-[a4]----00.0 Mellanox Technologies MT2910 Family [ConnectX-7]
... ...
+-[0000:60]-+-00.0 Advanced Micro Devices, Inc. [AMD] Device 14a4
| +-00.3 Advanced Micro Devices, Inc. [AMD] Device 14a6
| +-01.0 Advanced Micro Devices, Inc. [AMD] Device 149f
| +-01.1-[61-66]----00.0-[62-66]--+-00.0-[63]----00.0 Mellanox Technologies MT2910 Family [ConnectX-7]
| | +-01.0-[64]----00.0 NVIDIA Corporation GH100 [H100 SXM5 80GB]
... ...近年のサーバでは、それぞれのデバイスが同一バス上にすべてつながる構成というのは珍しく、基本的にはSwitch(PCIe Switchとも呼ぶ)というコンポーネントを通して接続されることが多いです。
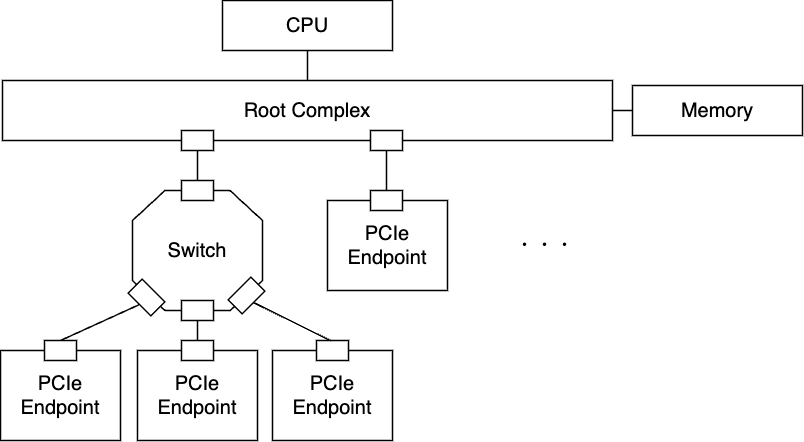
これにはいくつか理由がありますが、ポート数を増やすことでより多くのデバイスを同一システム上で取り扱うことができる、というのが最大の理由です。一方で、このSwitchによってPCIeデバイスがつながる構成は、今回のようなGPU間通信の文脈においては別の側面で非常に大きな意味を持つことになります。
話を戻しましょう。 現在のGPUサーバはGPU 8個に対して、NICが8枚搭載される、という話をあげましたが、これは単純にそれぞれのデバイスを8枚ずつ搭載すれば良い、というものではありません。この構成の元になっているのはGPU Direct RDMAという技術になります。 これはあるサーバのGPUに搭載されているメモリのデータを、別のサーバのGPUのメモリに転送する際に、RDMAによって転送するという技術です。通常のメモリ転送は、GPUのメモリを一度主記憶メモリに載せ、それをNICから送るという手法を取りますが、これはメモリ転送に大きな時間的、帯域的制約がかかります。一方で、このGPU Direct RDMAはGPUとNICがPCIe上でSwitchを介して繋がっている場合、GPUから直接NICを経由してリモートのGPUメモリにメモリ転送を行うことができる仕組みです。GPU Direct RDMAが実行できる場合、�異なるサーバ間のGPUメモリ転送を大規模に、かつ短時間で行うことができます。
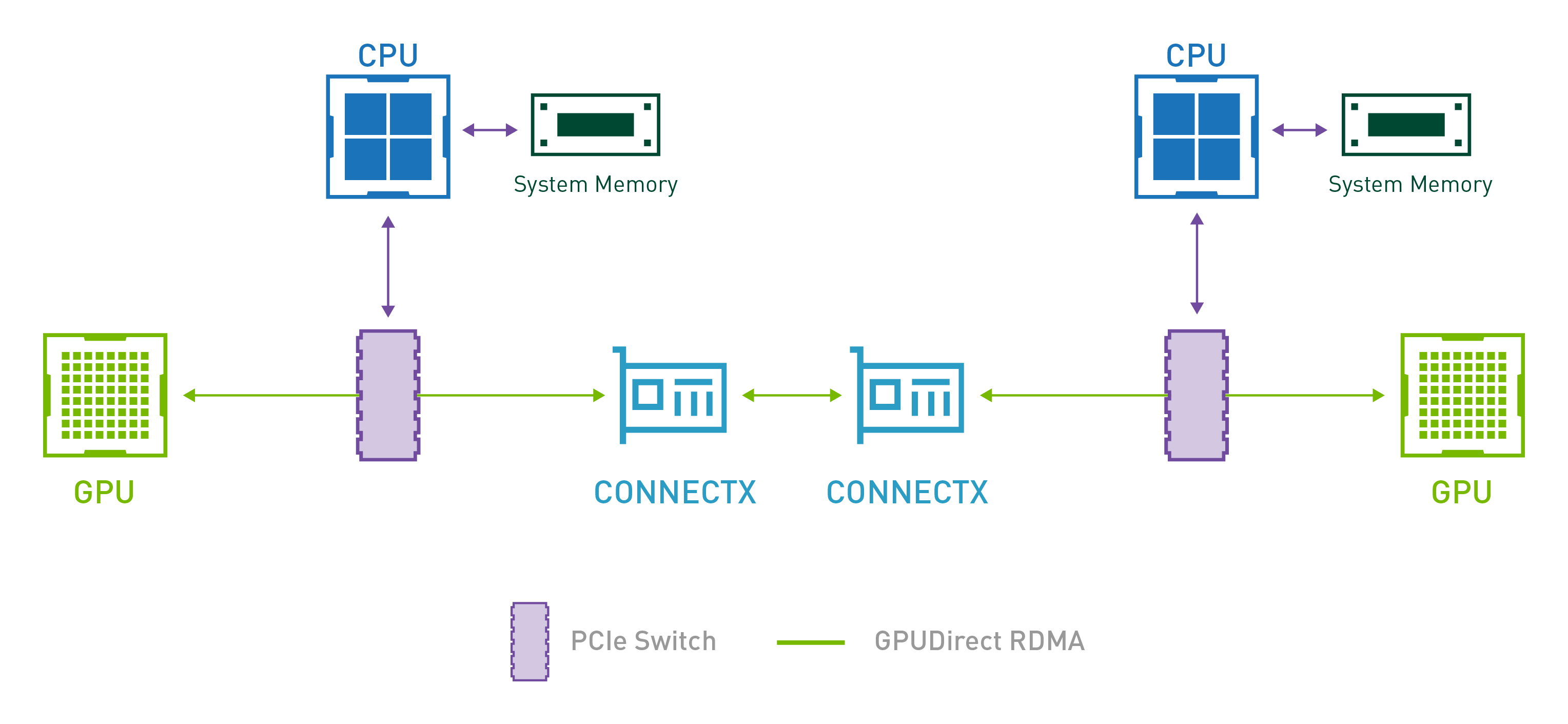
そのため、 昨今のGPUサーバでは各GPUが各NICとSwitch跨ぎで接続できるという構成が重要であり、そのペアの構成が8つ存在するようなPCIeトポロジーの設計になっています。
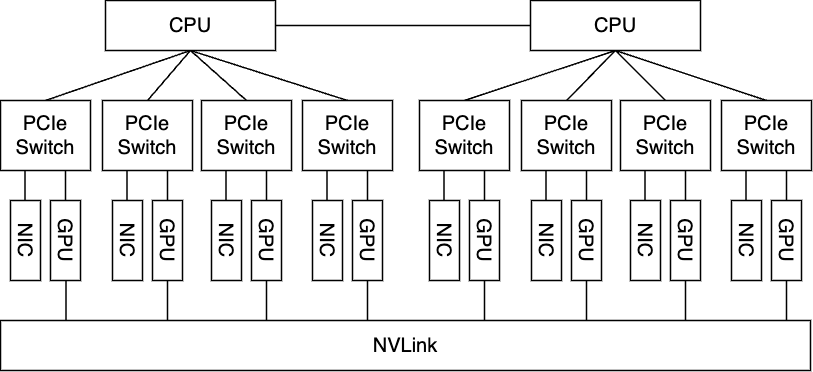
改めて上述したコマンドの出力を改めて見てもらうとわかると思いますが、同一SwitchにNVIDIAのGPU(H100 SMX5 80GB)とNIC(Mellanox ConnectX-7)が接続されていることがわかります。
この構成では、サーバを跨いだ通信が発生する際は、各GPUがそれぞれ近傍のNICを利用してGPU Direct RDMAによる転送を行うため、最も良い通信性能を達成できます。さらに、サーバ内部のGPU間での通信は、それぞれのGPUがPCIeとは別の超高帯域バス(NVIDIA GPUの場合は、NVLinkという高帯域バス)で接続されているため、このバスを経由して高速に通信を行うことができます。
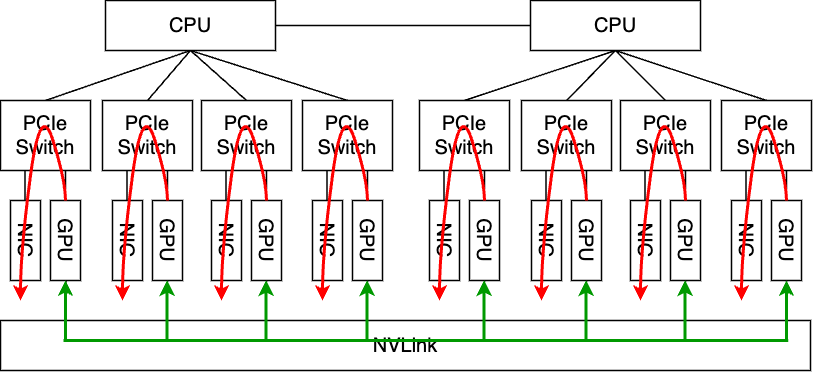
このようにサーバ内部に目を向けると、GPU間通信ではサーバのハードウェアトポロジーのレベルでの最適化も非常に重要になります。特にNVIDIA社のGPU専用ボードを搭載したサーバ筐体はこのような構成が基本となるように変化を遂げてきました。
これらを考慮したLINEヤフーのGPUサーバのデバイス構成
ここからは、われわれのGPUサーバのデバイス構成についてお話しします。
上述した通り、現在のGPUサーバにおいて最も良い性能が出る構成は8個のGPUと8枚のNICを搭載したものです。一方で、われわれはサーバのデバイス構成を決める際には、これを鵜呑みにせず、現時点でのACP上で実行されるワークロードや、今後の需要を考慮しました。その結果、現時点でこのようなフルスペックの構成を載せることはかなり過剰な投資になってしまうと判断し、今回新規に投入するサーバに関してはNICの枚数を2枚まで減らすことに決定しました。NICを2枚にした理由は、各NUMAに1枚はあった方が良いだろう、という判断に基づいています。
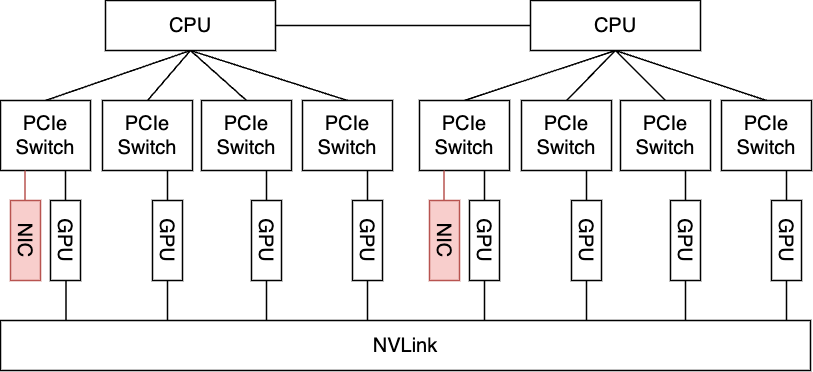
当然、NICの枚数を減らすことは通信の帯域性能に影響しますが、それを理解した上で今回はこのような構成を選択しました。この構成は6枚のGPUについてはSwitchを経由してNICと繋がらず、GPU Direct RDMAが実施できないため、理論最大帯域である800Gbpsよりももっと性能が悪化する可能性も考えられました。この懸念点については実際に測定をした結果と考察を後ほど紹介しますが、GPUサーバの購買時点では不確定事項として残っていました。
一方で、良い面としてこの変更はコストダウンにつながります。 この構成は単純にNICの単価 x 6枚分のコストを下げられるのみでなく、NICがつながる先のRail Leafや、その間を接続するためのトランシーバ、光ケーブルのコストダウンも含まれます。
このように、今回のGPUサーバは、コスト最適化を行いつつ、不確定事項に対しては実際に測定などを行いつつ、対応可能な部分はエンジニアリングで解決しようという方針でデバイス構成の選定を行いました。
GPUサーバのトポロジーと仮想化レイヤの考慮
ここまではGPUサーバのトポロジーについて議論し、弊社のサーバにおける構成についても紹介しました。
一方でこのGPUサーバ上で起動するVMの中から見たPCIeトポロジーがどうなるかというと、仮想化レイヤーにおける設定に大きく依存する形になります。弊社のIaaS基盤で利用しているQEMU、Libvirtをベースとした仮想化において、ベアメタルサーバと同じトポロジーにするのは非常に煩雑で難しいという問題があります。そのため、例えばNVIDIA社のソフトウェアでは、ベアメタルサーバのPCIeトポロジーをダンプしたファイルを利用し、VM上でのGPU間通信の実行時にそのダンプファイルを読み込ませることで、トポロジーを最適化する仕組みが提供されています。
しかし、仮想化の場合はPCIのAccess Control Service(ACS)を無効化することができないため、PCIeデバイス同士の通信がRoot Complex経由に強制され、パフォーマンスが低下する可能性があります。この問題を解消する手段として、Address Translation Service(ATS)の設定を適切に行うなどの追加の対応が必要になります。
このように仮想化環境では、最適化を考える上で追加の考慮事項が存在しますが、逆に言うと正しく設定をすることで仮想環境であっても十分な性能の達成が見込まれます。ただし、後述しますが、われわれはGPUサーバ内部のネットワークデザインを考える上で、仮想化を行わない方針に切り替えたため、仮想環境における具体的な性能検証は行っていません。
システム構成検討 : GPU NW向けサーバ内ネットワークのデザインパターン
以降で利用するGPU NWという単語は、GPU間通信で利用するネットワークのことを指します。これはPart2で紹介したGPU向けのサーバ外ネットワークと、そのネットワークに接続するサーバー内部のネットワークを含めた意味になります。
ACP環境でも分散学習をサポートするために、いくつかのサーバ内ネットワークのデザインを考えました。最終的にその中から一つを選択して適用しましたが、この選択の背景にはプライベートなインフラであることなどの社内的な事情を大きく含んでいるため、汎用的にすべての環境に適用できるかと言われると難しいかもしれません。
そのため本資料では、採用には至らなかったものの、これまで考案したアーキテクチャについてもそれぞれ紹介し、メリット・デメリットについても紹介させていただこうと思います。
案1 : 仮想化を継承したシステム(NIC PF Passthrough)
初期設計はこれまでのACPと同様に仮想化を前提として、分散学習に向けた最適化を図る構成を考えました。
VMに対してGPUやNICをPassthroughするという部分は従来の形から変更はないものの、VM上に起動するPodに対してPassthroughしたNICを割り当てる部分のみ調整をする必要がありました。この構成は仮想化を前提とする場合は最も単純な構成です。
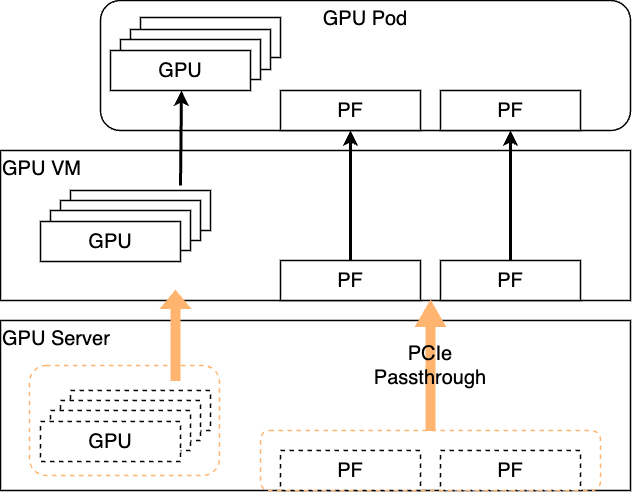
これは以下の点で不採用としました。
- VM上に起動できるPodの数が、PFの数に制限される。
- PF(NIC)をPassthroughしても、VMの中でSR-IOVの有効化ができないなど、NICの機能に一部制限がかかってしまうため。
1については、さまざまなワークロードが実行されるACPでは、ユーザがGPU NWのためのPF(NIC)リソースを簡単に使用し尽くしてしまう懸念がありました。 これは、本当にGPU NWが必要なユーザに対して正しく機能を提供する妨げとなってしまう可能性がありました。 ユーザ全体に対してガバナンスを効かせるのも難しいため、仕組み的に解消すべき問題ですが、物理的なリソースが足りないため解決できない問題です。
2については、もしこれが実�施可能であれば1の問題の対応策となりうるものでした。 VMの中でSR-IOVによるNICの多重化ができれば、少なくともNICの枚数問題は解決するのですが、検証や調査を行ったところ、現時点でのわれわれが採用している仮想化ソフトウェアではこれが実現できないため、1の解決策ともなり得なかった、という経緯がありました。
案2 : 仮想化を継承したシステム(NIC VF Passthrough)
上記の例ではNICの枚数に関する問題が表出しました。
一方でサーバに搭載するNICの枚数は2枚と決まっているため、この問題を解決する構成としてあらかじめハイパーバイザのレイヤでVFを必要枚数作成し、それをすべてVMにPassthroughする構成を検討しました。
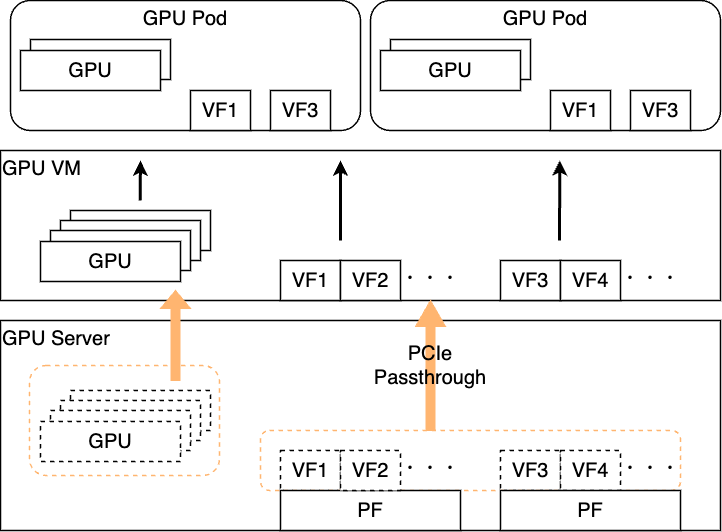
これであれば先ほど問題になっていたPodの収容数という側面の問題は解決します。
一方でこの仕組みは、あくまで論理的な分割であり、見かけ上のインターフェイス数を増やすことはできますが、帯域性能自体はPF(NIC)の帯域が最大値となるため注意が必要です。ただし、機械学習の典型的なトラフィックパターンはバーストトラフィックです。そのため、ユーザワークロード次第ではありますがバーストトラフィックのタイミングが被らなければそこまで問題ないのではないかという、楽観的な見立てはありました。
正直なとこ��ろ、このVF Passthroughの方式は案としては悪くありませんでしたし、VMの構成でなんとかしなければいけないとなった場合にはこの案を採用する以外にほぼ選択肢はないように思います。
一方で考慮すべき点として、どのようにIPアドレスを管理するかという話があります。 PCIe Passthroughによるデバイス提供方式は通常IPアドレスの紐付けがないため、何らかの仕組みでIPを管理する必要があります。もしくは、VMからPodに対してVFをアサインするタイミングでIPをアサインすれば良いという見方もありますが、その場合もサーバの外のネットワーク越しのどのようにそのIPで通信をさせるか考える必要はあります。Flatなネットワークで繋ぐのか、ネットワーク管理者と事前に決め打ちしたレンジやVLANなどを利用するのか、などいくらでも方式は考えられますが、スケーラビリティの観点やPod間の通信の分離などを考えるとこれを決めるのも難しい点です。
案3 : 仮想化を継承したシステム(NIC VF Passthrough + Open vSwitch Hardware Offload)
上記の案は悪くないものでしたが、もう一歩踏み込んでGPU NWにおける通信ポリシーの実現についても考えることにしました。
弊社にはネットワークポリシーというものが存在しており、基本的にすべての環境において通信のポリシー制御を行っています。今回のGPU NWに関してはGPU通信のみが発生する閉じたネットワークが前提になるため、このポリシー制御も現時点では基本的に考える必要はないと合意しています。一方で、今後のAI領域の発展に伴い、GPU通信で取り扱われるデータの特性が変�わるかもしれませんし、会社の方針としてGPU NWにも適切なポリシーの敷設を徹底する必要性が出てくる可能性も捨てきれません。そのため、GPU NWにおいても同様のポリシー制御が実現できるような形にしておくのが無難であろうという判断のもと、先の案を拡張する形でデザインを考案しました。
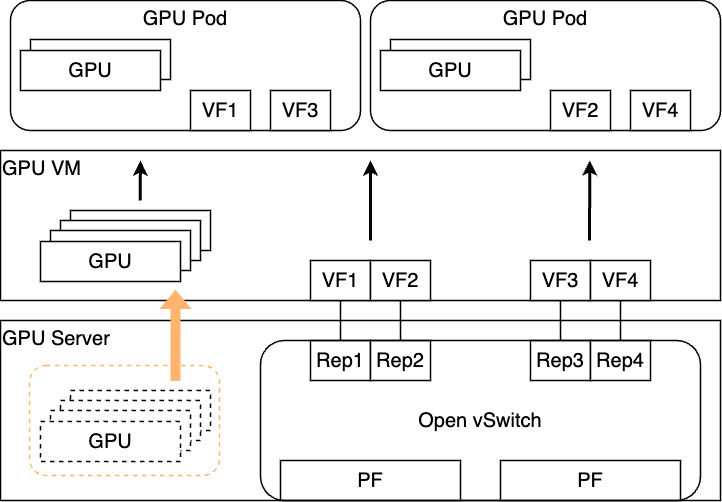
先ほどと違う点は、ハイパーバイザにOpen vSwitchと呼ばれているソフトウェアが登場していることと、VFに対してVF Representorというデバイスが作成されつながっている点です。詳細は後ほど紹介しますが、この仕組みにより技術的にはポリシー制御自体も実現できるようになります。
一方でこの構成の難しい部分は、PodのVFに紐づくIPアドレスなどの情報を利用し、ハイパーバイザ上のOpen vSwitchに対してフロールールを書き込む必要があることです。あらかじめIPアドレスが決まっており、それに変更がないなどかなり静的な構成で組み上げれば、合意したIPアドレス情報などを元にフロールールが記述できるかもしれませんが、柔軟性に乏しく、運用面からみてもあまり採用したくない構成でした。
また、当然ながら先に話したような外部のネットワークとの繋ぎをどうするかということも場合によっては考えなければいけません。
そのため、この構成は目的自体は実現できる可能性があるものの、かなり複雑な仕組みになり、運用負荷も高そうという印象でした。実際には、この構成をベースにどのようにすればPodのIP管理をうまく自動化できるかや、この構成でPod同士BGPで接続しL3で到達性を確保する方法などについても考案しましたが、かなり長くなってしまうため本誌面では割愛します。
上記の通り、いくつか案を考えるなかで、システムを複雑にしている背景は仮想化レイヤが存在していることであることが明確になってきました。そのため、別軸として仮想化の廃止についても検討を進めることにしました。前述した通り、仮想化にはいくつかメリットがありました。 そのため、仮想化を廃止する場合は、このメリットをつぶさずに現実的な代替案を講じることができるかが重要でした。
- サーバ操作をOpenStack API経由で実行できること
- サーバに搭載されているBMCチップ経由で、普段の業務で必要としていたサーバ操作は可能だった。
- このBMCチップを操作する仕組みが社内的に提供されているため、これをうまくシステム的にAPI操作を通して実行できるように調整できればよい。
- 仮想NWによるネットワークポリシーの提供が行えること
- ベアメタルサーバを利用しているユーザ向けに提供されているネットワークポリシー提供の実装を利用する。
上記のように、 ACPが仮想化によって享受していたメリットは、代替となる仕組みを利用できるように調整することで実現できることがわかりました。ACPのKubernetesとしても、そのNodeがVMであるか、ベアメタルであるかはそこまで重要ではなく、ベアメタルサーバであっても適切にセットアップすればクラスタにジ�ョインできます。さらに、仮想化を避けることができると、前述したVM内部のPCIeトポロジーを意識した調整を行う必要がなくなり、さらに仮想化に特有のGPU専用ボード向けの設定も不要になるなどのメリットが生まれるという側面もありました。
そのため、われわれは新規GPUサーバでは仮想化を廃止し、ベアメタルサーバを利用するという構成を検討することになりました。
案4 : ベアメタルサーバ前提のシステム(Baremetal + Open vSwitch Hardware Offload)
ベアメタルサーバを利用する構成の場合、仮想化の構成に比べて構成がより単純化されます。
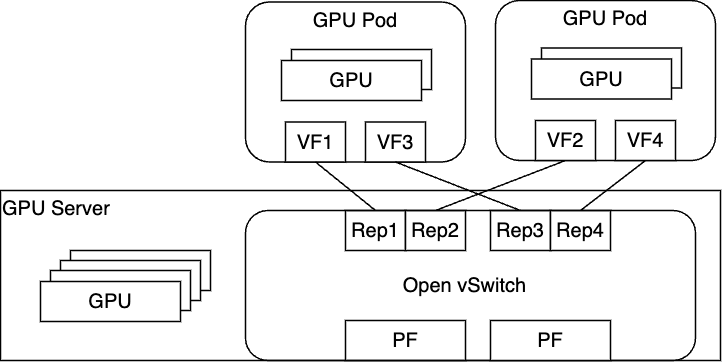
仮想化レイヤがなくなったことで、物理サーバ上に直接Podがデプロイされることになるため、ネットワークの設定を行う仕組みを考えることが容易になります。
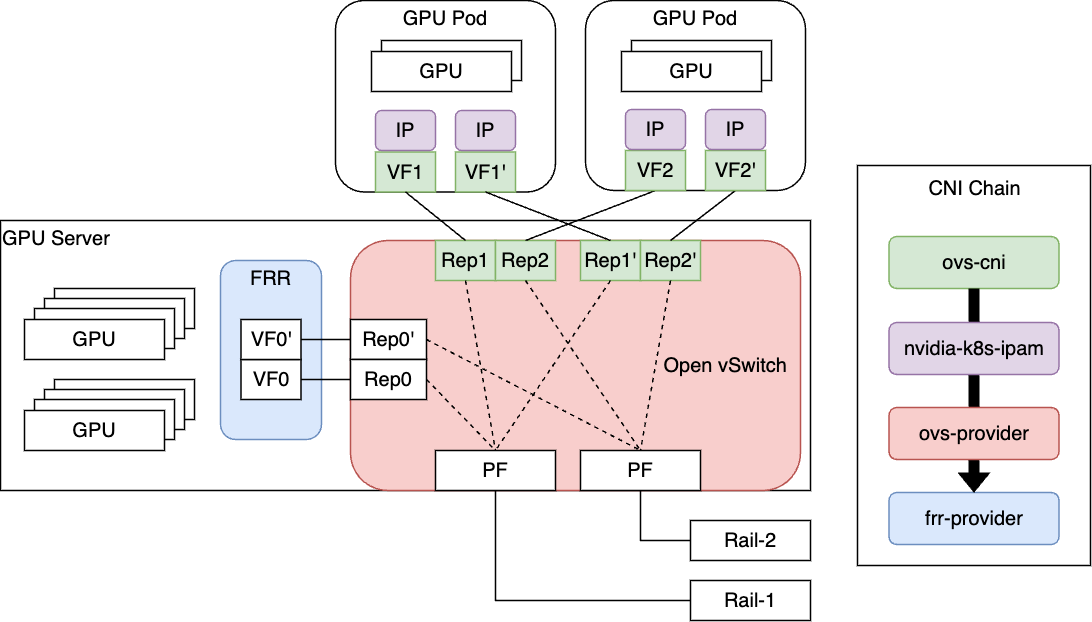
われわれはこの構成をベースとし、Pod間の疎通性をBGPによって成立させる次のような構成を採用することに決定しました。
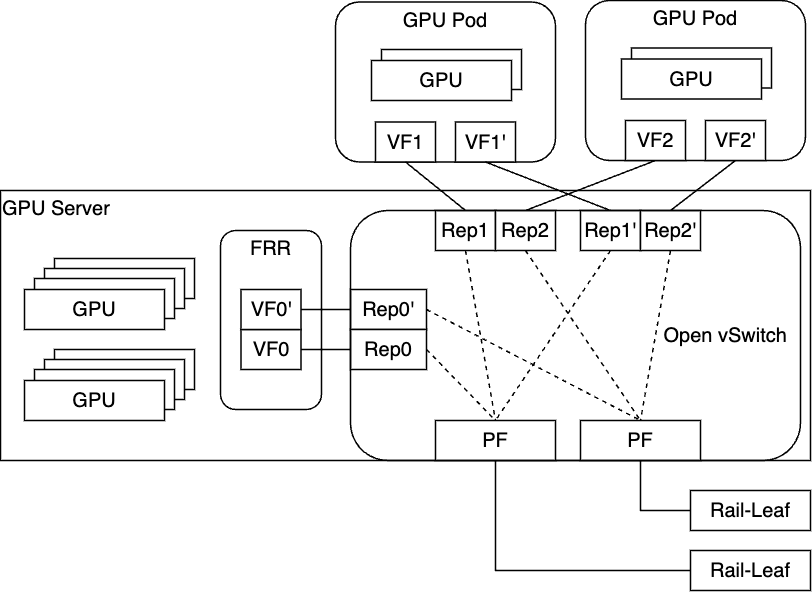
FRRというソフトウェアを利�用し、サーバ内にBGPデーモンを起動させ、Podに割り当てたVFが持つIPアドレスを各Rail Leafに対して広報するような形をとっています。
この後、サーバ上で稼働するFRRやOpen vSwitchをどのように設定するかなどのより詳細な実装についても説明をしていきますが、その前にこれまでの議論で詳細に踏み込んでいなかったOpen vSwitchとHardware Offloadについて説明していきます。
GPU NWにおける柔軟なネットワーク機能の実現を目指して
GPU NWにおける柔軟なネットワーク機能の実現の難しさ
一般的に利用されるTCP/IPのような通信方式では、カーネルに実装されている技術やソフトウェアを利用することにより柔軟なネットワーク機能を実現することができます。一方で、Part2でも述べたように弊社のGPU NWでは、基本的な通信形式はRoCEv2と呼ばれるEthernet上でRDMAの通信を取り扱うもので、カーネルの機能をバイパスすることで高速化を実現しています。RoCEv2の場合、通信のために必要なカーネルの処理(パケットのヘッダ付与など)は、基本的にNICのハードウェアが処理を担当するため、カーネルの機能を利用した柔軟なネットワークの実現は難しい項目の一つとなっています。
今回、われわれはこの点をうまく解消する一つの方法として、NVIDIA社のConnect-XシリーズのNICに存在している、Open vSwitch Hardware Offloadの機能を利用することを考えました。これを理解するには、Open vSwitchというソフトウェアと、Hardware OffloadというNICの機能について理解�する必要があるので、それぞれ解説していきます。
Open vSwitch
Open vSwitchとはオープンソースのソフトウェアであり、サーバ内に仮想スイッチを作成することができるものです。標準的な管理インターフェイスやプロトコルをサポートし、特に仮想化環境などでの利用実績の多いソフトウェアです。弊社のIaaSチームでもOpen vSwitchは長く実績のあるソフトウェアであり、広く利用しているものでした。
Open vSwitchで作成した仮想スイッチには、サーバ上で認識しているインターフェイスを繋ぐことができ、仮想スイッチに対してフロールールを設定することで、インターフェイス間の通信に柔軟なポリシーを設定することができます。例えば仮想環境の場合、特定のVMの間の通信を遮ることで疎通性をなくし、特定の宛先への通信をブロックするようなポリシーを作成することができます。
このソフトウェア自体は大変強力で自由度の高いものではありますが、仮想スイッチはソフトウェア的に処理を行うスイッチになるため、当然ながらGPU NWのような高性能なネットワーク通信が求められる環境ではそのまま利用することはできません。 ここで登場するのが、Hardware Offloadという仕組みです。
Hardware Offloadとは
Hardware Offloadとはその名の通り、本来CPUが処理を行うソフトウェア的な処理を、特別なハードウェアに処理させる仕組みです。CPUの処理を肩代わりするためCPUの負荷を削減することができ、何よりハードウェアの処理というのは非常に高速なのでCPUが行う場合に比べて高速に処理を行うことができます。
NVIDIA��社のNICであるConnectXシリーズでは従来、前述したOpen vSwitchのオフロード機能が搭載されており、われわれが仮想スイッチに設定したフロールールをNICに搭載されているEmbedded Switch(eSwitch)が処理してくれます。

図にある通り、フロールールを記述する際には、PFとVF Representorの間のルールを記述することになります。これがオフロードされることによって、PFとVFの間のフロールール、VF間のフロールールがハードウェアで処理されることになります。これにより、GPU NWのような高帯域な通信に関してもOpen vSwitchで作成し自由にルールを付与した仮想スイッチ上で処理することができるようになります。弊社の仮想環境の中でも、特に高性能なNWが求められる環境ではこの組み合わせが運用されており、当時のNICのワイヤーレートである100Gbpsの性能も問題なく出すことができていました。
もともとサーバとしてもConnectXシリーズの新しい製品であるConnectX-7のNICを搭載しており、今回のGPU NWでもこの仕組みが利用できるのではないかと考え検証を行ったところ、問題なく性能が出ることが確認できたのでこれを採用する形にしました。
Hardware Offloadにおけるキャッシュと分散学習の通信との相性
上記で説明したHardware Offloadですが、フロールールを仮想スイッチに設定するだけではオフロードされません。��実際このフロールールのオフロードは、パケットの評価が行われ、マッチしたルールがハードウェア上のキャッシュに乗ることで、次回以降の同様のパケットについてそのフロールールの評価がハードウェアで行われるという仕組みになります。そのため、ファーストパケットについてはオフロードされず、またキャッシュから消えたルールについては再度評価されないとオフロードされない性質があります。
一方で、分散学習の通信は、実際の学習通信が発生する前に、まず通信対象同士のネゴシエーションフェーズが存在します。ファーストパケットの評価はこのネゴシエーションのタイミングで行われ、学習通信が発生するタイミングではすでにその通信はハードウェアのキャッシュにヒットする形になります。
また、一般的に分散学習の場合、パケットのエントロピーが大きくならないという性質があります。これはECMPなどのパケット分散との相性が悪いことはよく知られていますが、逆にこのハードウェアオフロードの場合は新しいルールがキャッシュに乗りにくくなるため、キャッシュに載っている既存のルールが追い出されにくくなります。
この点から、実は分散学習における通信の特性と、Hardware Offloadの性質は相性が良いと考えることができます。
どのようにサーバ内ネットワークを構築するか: GPUネットワークの設定とKubernetesの統合
ACP上で実行されるJobの特性とGPU NWの設定方法の検討
GPU NWのサーバ内部の設計に��ついてやその背景について話してきましたが、ここからはどのようにサーバに設定するかという話に移ります。
前述した通り、ACPはKubernetesをベースとした基盤になっています。社内のさまざまなユーザやテナントを受け入れており、これらのテナントの分離はKubernetesにおけるNamespaceの機能で実現していました。
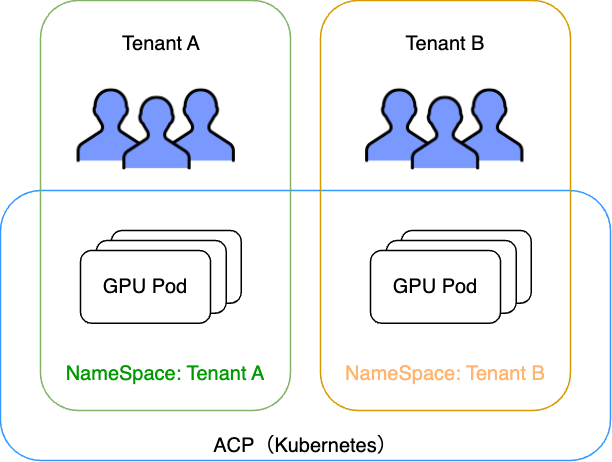
ユーザはこのACP Kubernetesに対して、機械学習のタスクをJob Podの形で起動し実行するのが基本的な方式です。ユーザのジョブが完了した後は、そのPodは削除され、GPUやNICなどのリソースが回収され、次のユーザのジョブにこれらのリソースが回されることになります。また、分散学習を必要とするか否かについてもユーザが実行するジョブの内容に依存します。 社内のGPU利用者は現状すべてのユーザが分散学習ほどの規模のジョブを実行しているわけではありません。
このように、ACPでは「多様なリソース需要」のジョブを「複数のユーザ、テナント」が「一定期間スケジュールして実行」するという特性があります。
この特性に鑑みた上で、GPU NWをどのようにサーバに設定していくかを考えた際、静的に設定を行うのではなく、ユーザのリクエストに合わせて動的に設定するのが良いと判断しました。
- 多様なリソース需要 → ユーザリクエストの中にGPU NWを必要とするか否かを含めてもらうことで、必要に応じてそのPod�向けにGPU NWの設定を行う。
- 複数のユーザ、テナント → 将来的にこのユーザ、テナント間での分離する必要が出てくる可能性を考慮し、機能を拡張できるような形で設計する。
- 一定時間スケジュールして実行 → Job Podの実行直前に必要な設定を入れ、Job Podの実行完了後は設定を削除するような挙動にする。
このように、Job Podのリソースリクエストに対してネットワーク設定の判断を行ったり、Job Podのライフタイムに合わせてネットワークの設定を投入・削除するような特性を考慮し、われわれはKubernetesのCNIの形でネットワーク機能の実装できないか検討を進めました。
一方で、われわれのニーズにかなうようなCNIプラグインは存在していなかったため、必要な機能を提供するCNIを自作する方針になりました。
GPU NW向けのCNIの設計と実装
今回のように、Podに対して追加でインターフェイスを割り当てる際に利用できるソフトウェアとして、現時点でのデファクトスタンダードとなっているMultus CNIがありました。Multus CNIでは、NetworkAttachmentDefinitionというCustom Resourceを作成し、そのリソース名をPodのAnnotationに追記することで、Pod起動時にAnnotationに記載されているCustom Resourceの内容に従ってCNIを呼び出し、追加のインターフェイスの設定を行います。
さらに、KubernetesのCNIにはChainと呼ばれる仕組みが定義されています。 この仕組みと、NetworkAttachmentDefinitionの設定を合わせることで、Pod起動時に追加のインターフェイスに対して複数のCNI Pluginの呼び出しを行うことができます。NetworkAttachmentDefinitionの例とユーザマニフェストの例を以下に示します。
Network Attachment Definitionの例
{
"cniVersion": "0.4.0",
"name": "sriov_pf1_vf",
"plugins": [
{
"cniVersion": "0.4.0",
"type": "ovs", # ovs-cniのCLIバイナリ
...
"ipam": {
"type": "nv-ipam", # nvidia-k8s-ipamのCLIバイナリ
...
}
},
{
"type": "ovs-provider-cli", # ovs-providerのCLIバイナリ
...
},
{
"type": "frr-provider-cli", # frr-providerのCLIバイナリ
...
}
]
}ユーザマニフェストの例
---
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
namespace: tenant1
annotations:
k8s.v1.cni.cncf.io/networks: sriov_pf1_vf,sriov_pf2_vf # ユーザ追記部分
spec:
...
containers:
...
resources:
requests:
nvidia.com/gpu: 8
nvidia.com/mlnx_sriov_pf1_vf: 1 # ユーザ追記部分
nvidia.com/mlnx_sriov_pf2_vf: 1 # ユーザ追記部分
...NetworkAttachmentDefinitionを見ると、チェインして呼び出したいCNIプラグインが、リスト形式で記載してあることがわかります。今回のわれわれの構成では、Open vSwitchへの設定とFRRへの設定を行ってくれるようなCNIプラグインを作成し、このようにチェインして呼び出すような形にすれば良いということになります。
次に具体的にチェインさせるべきCNIプラグインを決定します。 Open vSwitchとFRRに対して設定を行うようなCNIは存在していなかったため、自作して上記の通りチェインする形にしました。一方でそれらのCNIをチェインする前段として、Podに対してインターフェイスを割り当てるCNIプラグインや、そのインターフェイスに対してIPアドレスを付与するIPAM機能を持つプラグインなども必要になります。
幸い、これらのプラグインはオープンソースで公開されているものがありました。今回われわれはインターフェイスを準備する役割を持つCNIとして k8snetworkplumbingwg/ovs-cni を、IPAM機能を持つプラグインとして、NVIDIA/nvidia-k8s-ipam をそれぞれ採用することにしました。前者の採用理由は、PodにVFをアサインするだけでなく、サーバ側の設定としてVF RepresentorをOpen vSwitchの仮想スイッチに設定する機能を持っていたためです。 当時、調べた限りではこのCNIしかこの機能を実現しているものはありませんでした。後者の採用理由は、IPAM機能を持つプラグインとしてよく知られる、k8snetworkplumbingwg/whereabouts と比較し、実装方針などの側面からこちらのIPAMプラグインがふさわしいと判断したためです。
以上を総括して、われわれのGPU NWは以下のようなCNI Chainingによって実現する方針としました。
実装面についても簡単に触れようと思います。
CNIは入力と出力に対して形式が決まっているため、この形式に従ってCLIを設計します。一方で、CLIの実行内容については基本的には自由です。 今回の設計では以下のように、CLIをClient、各GPUノードで稼働するDaemonSetのPodがServerとなるような、gRPCベースのClient / Serverアプリケーションの形で実装しています。 この構成自体は近年のCNIの実装ではおそらく一般的な方式だと思います。
CLIバイナリはCNIの仕組みの上で呼び出され、その呼び出し方式(ADD、DEL、CHECKなど)に従って、Serverアプリケーションに対してgRPCリクエストを発行します。それを受け取ったServerアプリケーションが、それぞれのノード上で必要な処理を実行するという仕組みです。
CNIをChainする場合はこれが順番に実行されるため、おおむね以下のような呼び出しの流れになります。
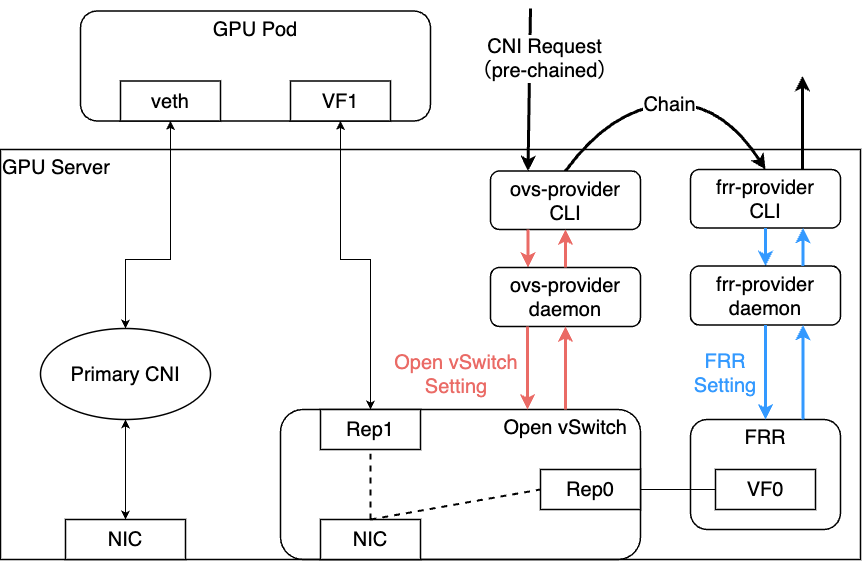
これによって、Pod作成リクエストに合わせて、そのPodがGPU NWを利用する上で必要になる設定をサーバ上の各種コンポーネントに設定します。
GPU NWのテナント分離への展望
改めて、われわれの環境ではGPU NWに柔軟なネットワーク機能を付加できるよう、Open vSwitchを採用しています。具体的なネットワーク機能の実現例として考えているものに、テナント間のGPU NW分離機能があるため紹介いたします。
前述した通り、ACPのKubernetesではNamespaceベースでテナント分離が行われています。 しかしこの場合、適切にネットワークの分離が行われていないと、条件次第では別のテナントのGPU Podを巻き込んで分散学習を行うことが可能です。これを防ぐためには、Namespaceを意識したテナント間でのネットワーク分離が必要になります。 一方でわれわれの構成ではこの「Namespace単位」というのをOpen vSwitchのフローに落とし込むことができれば実現ができます。
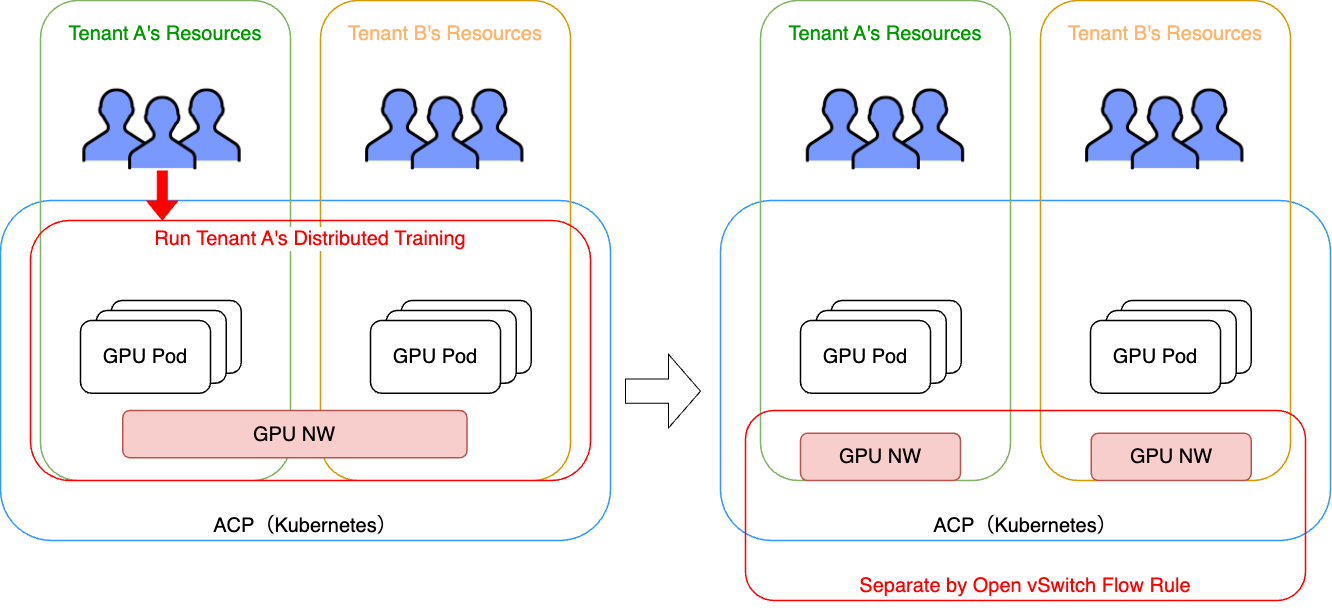
前述した通り、今回われわれはネットワークの設定をCNIから実施するように設計しましたが、実はCNI RequestにはPodが起動するNamespaceの情報が含まれます。そのため、CNIリクエストを受け取ったプラグインのロジックとして、Namespaceの情報を利用したロジックを記載することができるようになります。
具体的な設計や実装は今後の課題ですが、カスタムリソースなどのKubernetesのエコシステムと連携するなど、実装の幅は広いと考えています。
GPU NWを利用した分散学習のパフォーマンス検証結果
今回構築した分散学習基盤ではNICの枚数を戦略的に減らし、またOpen vSwitchなどの仕組みを取り入れています。いずれも分散学習実行時のネットワーク性能に影響を与える可能性があるため、パフォーマンス測定を行いました。以降では、われわれが実際に行ったパフォーマンス測定とその結果について、実際の測定データを利用しながら共有いたします。
期待性能についての整理とパフォーマンス測定の環境について
今回の構成は400GbEのNICが2枚のため、理論的な最大の通信帯域は800Gbpsということになります。
一方で前述した通り、サーバ内PCIeトポロジーとしてみると、8GPUのうち、2GPUのみしかGPU Direct RDMAが実行できない構成になるため、これによる性能への影響がないかを確認する必要があります。
また、Open vSwitchのHardware Offloadによって、どの程度の性能を保ったままネットワークの柔軟性が確保できるかについても確認する必要があります。
前者については難しいネットワークの設定なしで、純粋にサーバ同士を繋ぎ、GPUを利用した通信の性能を測定することで確認し(構成1)、後者についてはわれわれの決めたアーキテクチャに従った構成で測定した性能結果と(構成2)、前者の性能を比較することで確認することにしました。
性能検証における構成
| 構成1. 基本構成 | 構成2. 新規ACP構成 |
|---|---|
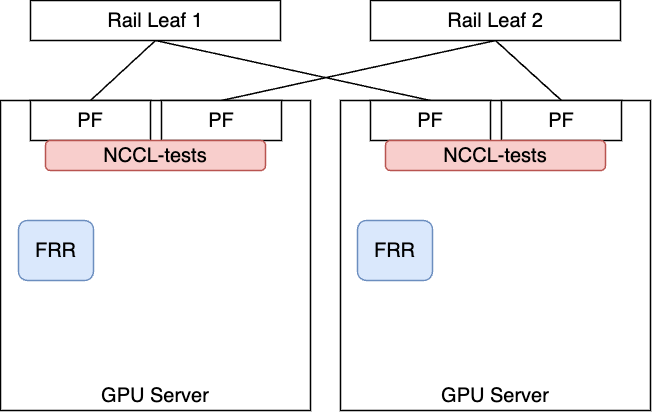 | 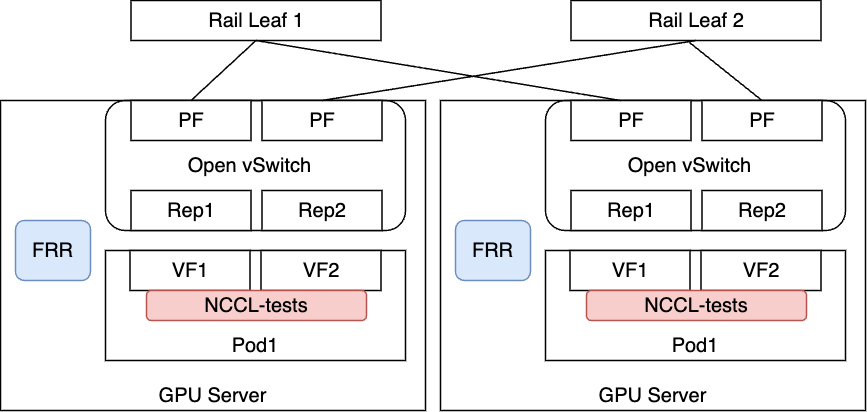 |
性能検証のツールとしては、NVIDIA/NCCL-testsというソフトウェアを利用します。これはNVIDIA社のCollective Operation LibraryであるNCCLを利��用して、各種集団通信の実行性能を測定することができるツールです。NCCLは分散学習フレームワークで広く利用されており、NCCLを利用した集団通信で十分な性能が出ていることが裏付けられれば、基本的には多くの分散学習フレームワークで良い性能が保証されることになります。
測定結果
まずは、今回測定した集団通信とその測定結果について以下の表にまとめます。
構成1で測定したものが、「pf_」から始まるデータであり、構成2で測定したものが「switchdev_」から始まるデータです。それぞれ実行サーバ数は2台のため「n2」であり、今回の測定ではRing Algorithmを利用しているため「ring」とついています。 これについては性能結果の考察部分で軽く紹介します。algbwは実際に達成された有効な帯域幅であり、busbwはバスを流れた実行帯域幅を論理的に算出したものに対応します。これらのデータについての詳細は「Performance reporeted by NCCL tests」を参照してください。
今回は、NICの枚数変更や中間経路にOpen vSwitchを挟んだことによる実行帯域幅の性能を確認したいため、注目すべき値としてはbusbwということになります。
| Performance Result | |
|---|---|
| All Reduce (Collective Communication) | 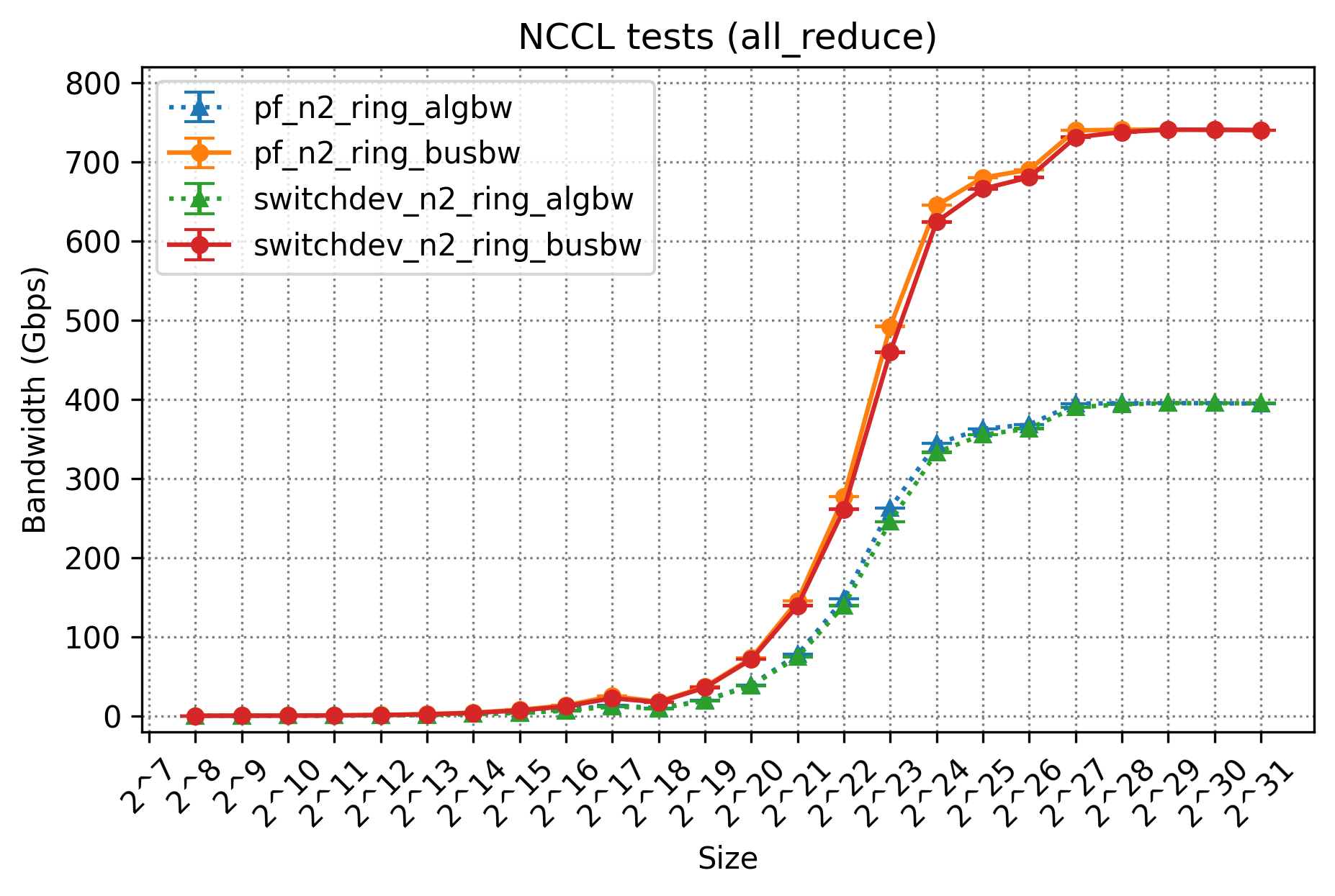 |
| All Gather (Collective Communication) | 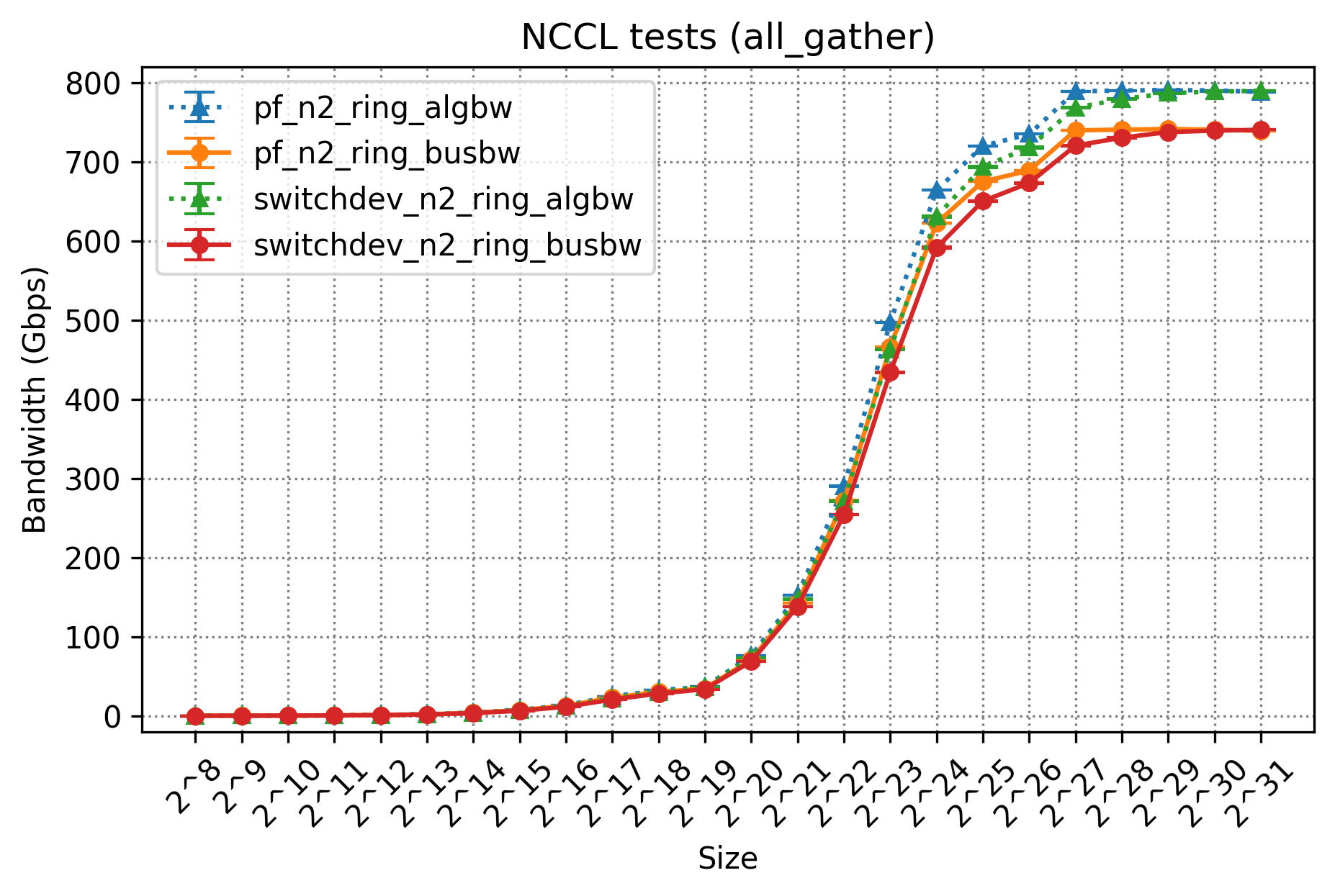 |
| Reduce Scatter (Collective Communication) | 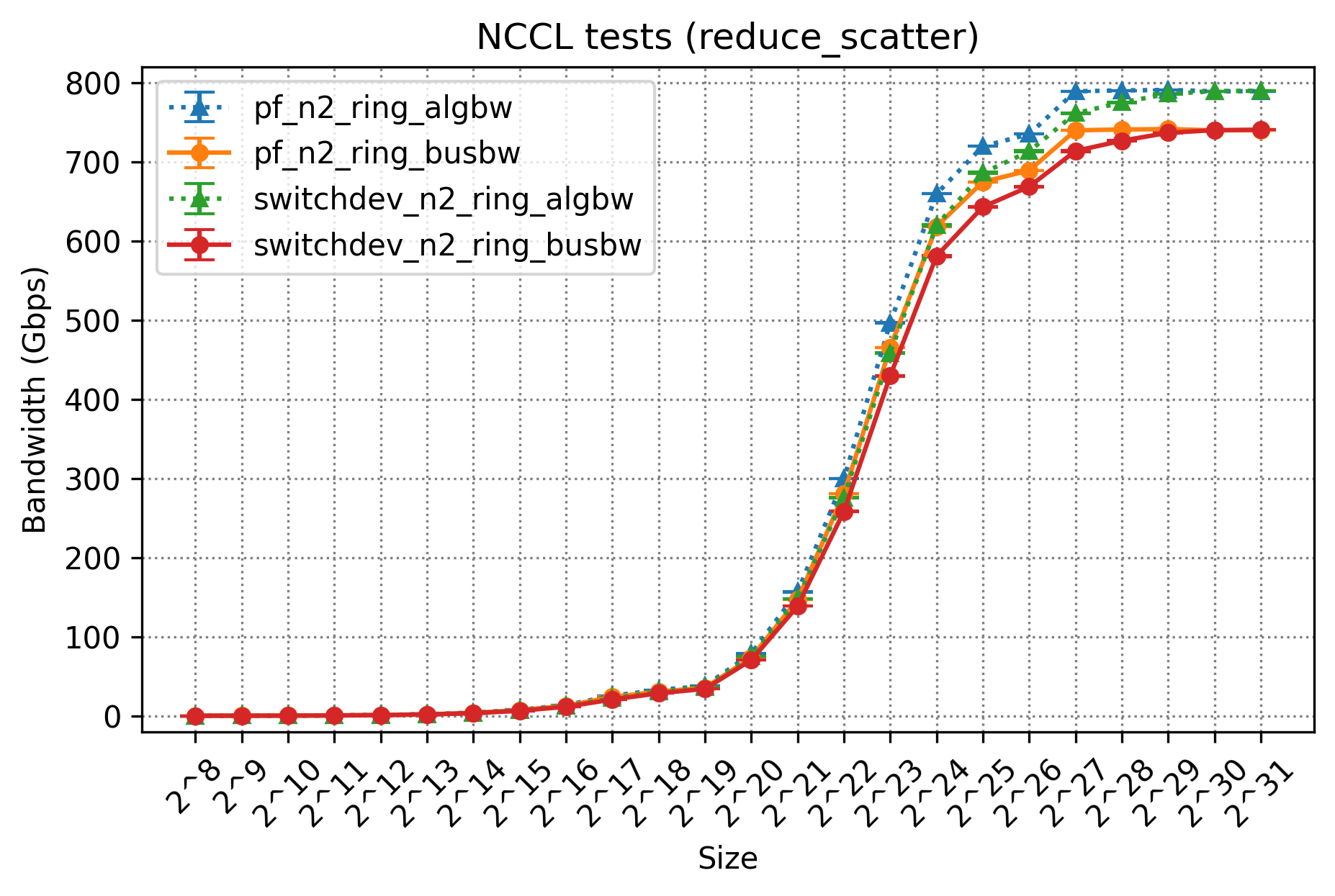 |
| All-to-All (Point To Point Communication) | 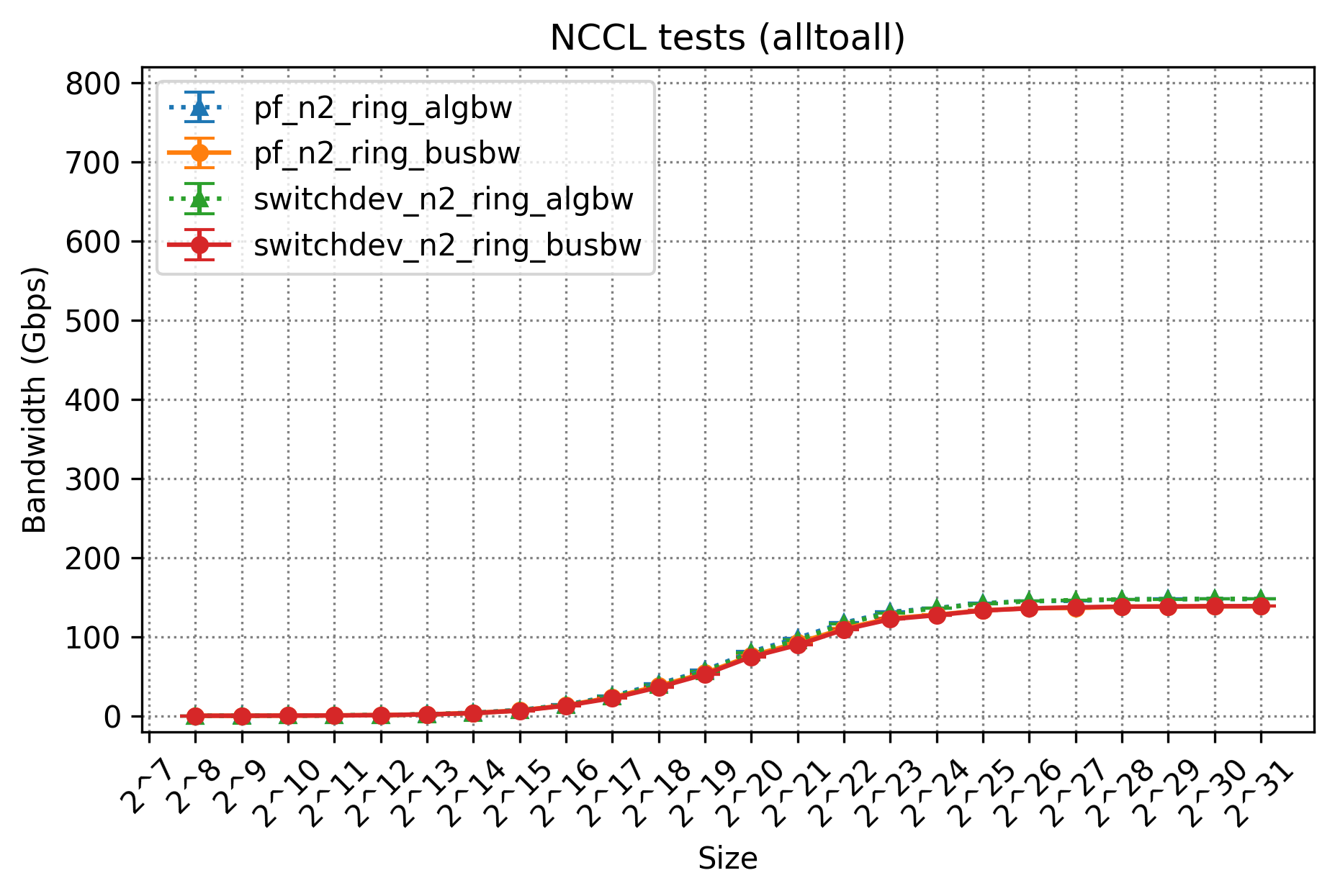 |
All Reduce、All Gather、Reduce Scatterはそれぞれ理想的な性能である800Gbpsが出ていることがわかります。今回はRing Algorithmを指定しているため、Collective Communicationの場合は基本的にこのアルゴリズムに従うような形になります。RingアルゴリズムはすべてのGPUを数珠上に繋ぐ形で論理パスを構築するものです。 実際にAll Reduceの実行ログから詳細をたどってみると、われわれの構成では以下のような2つのパスが選択されていました。
All Reduceのログから確認したRing Algorithmのパス
| Ring1 | Ring2 |
|---|---|
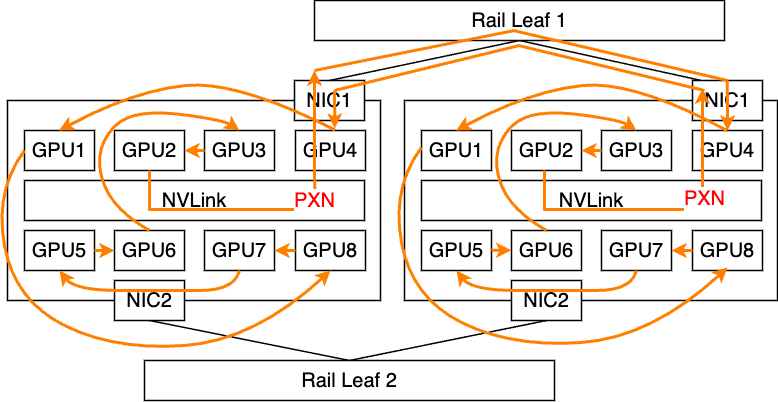 | 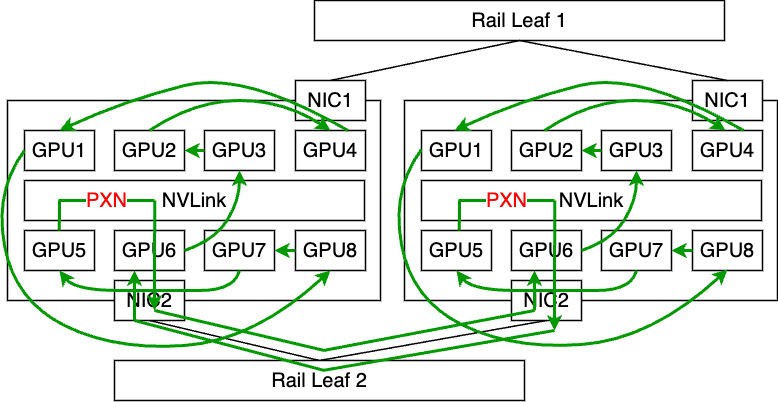 |
Ringの経路中にはPXNも利用しており、論理的な通信パスが物理的なパスと適切に噛み合う形で導出できているため、2枚のNICを送�受信ともに無駄なく利用でき、理想的な帯域性能を達成できています。
この性能結果から、All ReduceやAll Gather、Reduce ScatterなどのCollective Communicationについては、われわれのサーバ構成でも問題なく性能が出ることを確認できました。一方で、All-to-Allのbusbwの性能は芳しくないため、こちらに関しては追加の検証を行うことにしました。
PCIeトポロジーの変更とAll-to-Allの性能最適化
All-to-Allは、特定のデバイスから、すべてのデバイスに対して通信を発生させる形になります。それぞれの通信ではPoint-to-Pointな通信形式となるため、Ring Algorithmのような論理マッピングによる通信パス最適化は機能しないことになりますが、NCCLにおいてはPXNによってAll-to-Allのような通信においても最適化が図られます。しかし、このPXNですが、ノード内部の高速バスを経由させることができるのは、現在のNCCLの実装では送信側のみという制約があります。
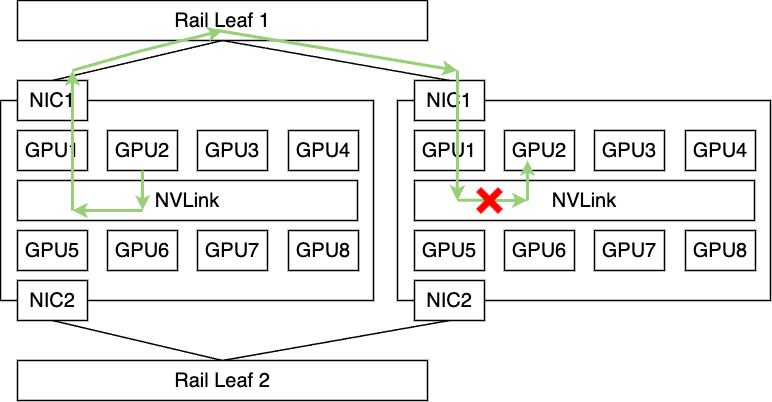
8個のGPUと8枚のNICを搭載したサーバにおいては、受信側ではGPUに対応するNICが必ず存在するため、PXNの機能は送信側のみで十分です。一方で、今回のわれわれのようなNICを減らした構成の場合、受信側におけるメモリ転送ではCPUを介した処理が発生してしまうため、性能のボトルネックになってしまうことが考えられます。今回のAll-to-Allの性能のボトルネックはこれが主要因になっているのではない�かと考え、追加で以下のような検証を行い、仮説の確認を行いました。
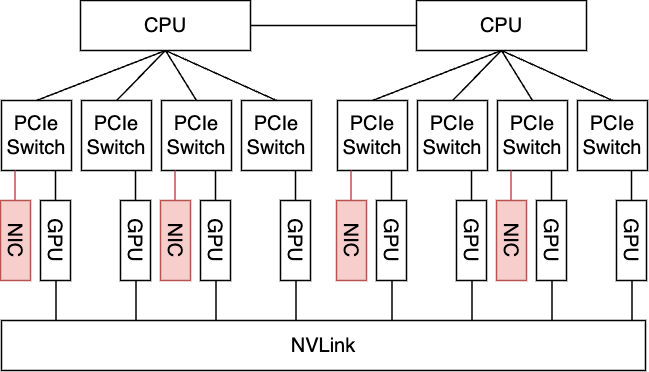
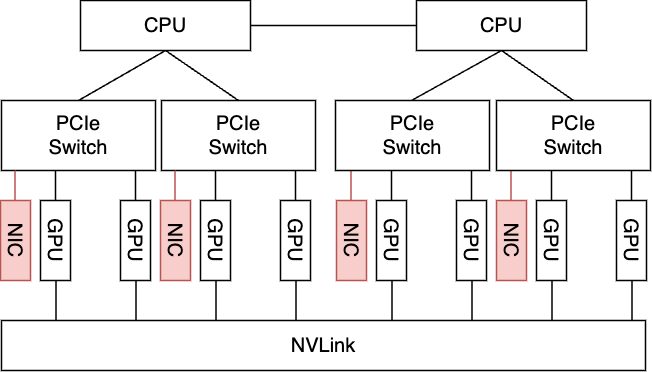
まず、サーバに搭載するNICを2枚から4枚へ変更します(下図、構成1)。これだけではNIC2枚の状況と同様に不十分ではありますが、この状況でPCIeトポロジーを変更することによって、すべてのGPUがNICと直接通信できるようにした構成をとることができます(下図、構成2)。この構成1と構成2の両方で再度All-to-Allの性能測定を行い、それを比較することによって、上記の仮説を検証できます。
トポロジーの変更については、サーバベンダーと協力して検証用に特別なファームウェアをいただき適用することによって実現しています。 現時点でこのファームウェアは検証でのみ利用しています。
All-to-Allの性能の最適化検証のための構成
| 構成1. 通常構成+NICを2枚追加 | 構成2. 通常構成+NICを2枚追加+PCIeトポロジーを変更 |
|---|---|
 |  |
実際、それぞれの構成でAll-to-Allの性能を測定した結果は以下のようになりました。
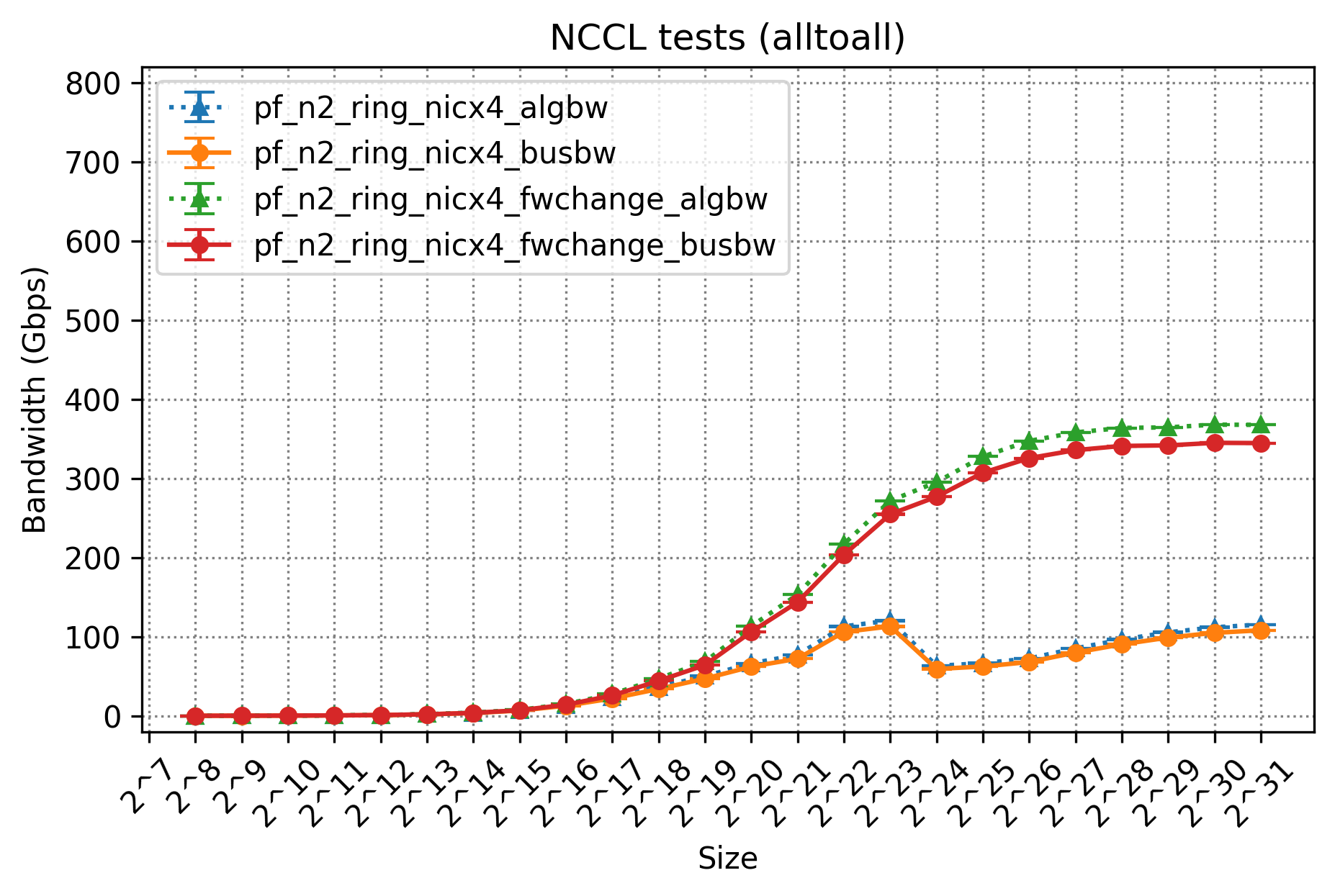
上記の図において、「fwchange」と記載ないプロットが構成1、記載のあるプロットが構成2であり、algbwとbusbwをそれぞれプロットしています。結果をみると明らかな通り、構成2は構成1から大きく改善しており、busbwは400Gbps程度にまで改善していることがわかります。
この結果から、われわれの仮説通り、NICを減らした状態で複数GPUノード間のPoint To Point通信を行う場合、性能が低下してしまう特性があるということを確認しました。
一方でこの400Gbpsという値は妥当でしょうか? 残念ながら今回、弊社の環境ではリリースの都合などによりこれ以上の詳細調査ができず、確証を持った内容をお伝えすることができない形となってしまいました。今後チャンスがあれば詳細に確認してみたいと考えています。
性能検証の結果とユーザ影響の考察
上記の性能検証から、われわれの環境では広く利用されるAll ReduceのようなCollective Communicationでは想定している理論性能に近い値が出ることがわかります。一方で、Point To Point Communicationのような通信の場合は、十分な帯域性能が達成できないという特性があります。
実際のユーザアプリケーションにどの程度影響があるかを考えてみると、どの通信パターンを利用するかはユーザアプリケーションの実装依存になるため、All Reduceなどを利用した実装であれば問題ないですし、All-to-Allのような通信を利用した実装であれば十分な性能は出ない、ということになります。
ただ朗報なことに、NVIDIA社の公開する分散学習フレームワークやライブラリを利用する場合は、All Reduceを利用する��ように実装されているケースが多いという話を伺いました。そのため、これらのライブラリを利用する多くの場合においては問題ないことが予想されますが、すべての実装において最適な形になっていないということは把握しておくべき事項でしょう。
まとめ : 分散学習基盤のサーバ内アーキテクチャの全容
最後に、これまでの議論とPart2の内容を踏まえて、改めてわれわれの分散学習基盤のサーバ内アーキテクチャの全容を示し、重要なポイントについて要約します。
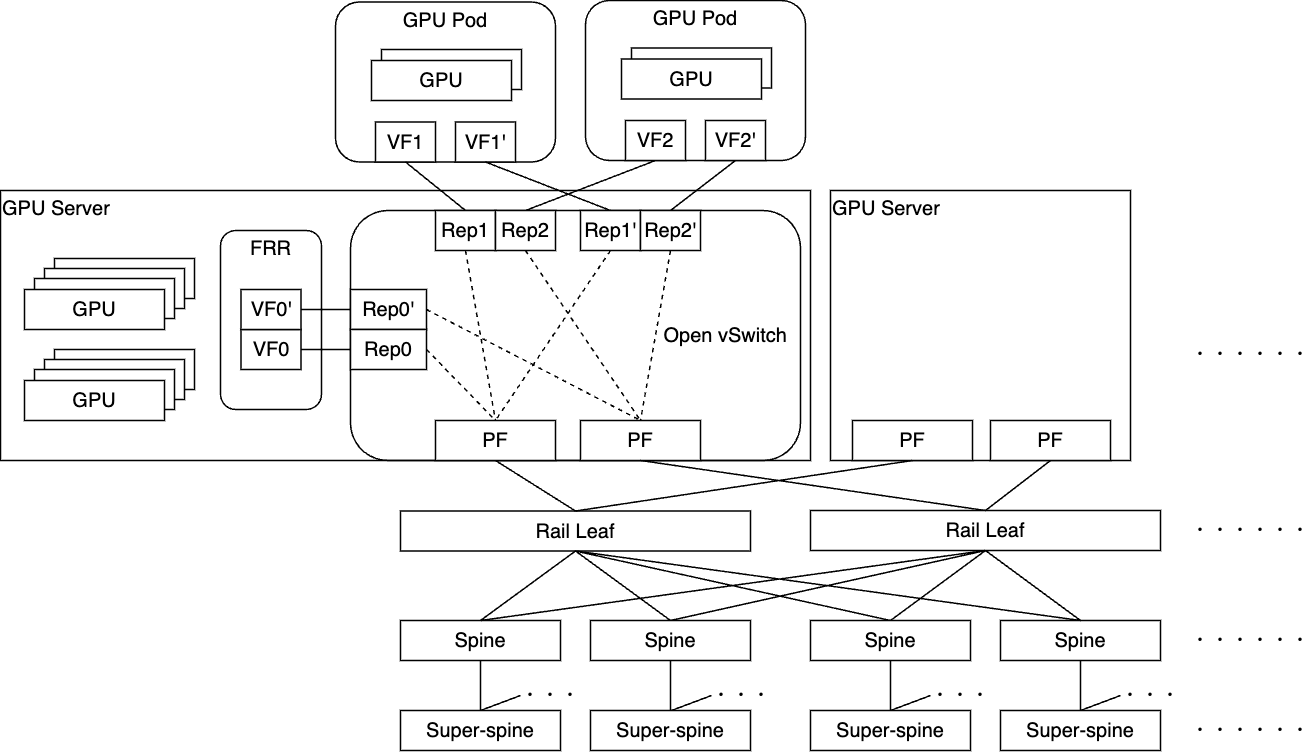
ACPの分散学習基盤の全容(Part2とは異なり、LeafやSpineを図の下に位置付けているので注意してください)
ユーザのPodは、GPU NW向けのインターフェイスを、Podのマニフェストを一部変更することにより利用できます。Pod起動時には、CNIがFRRとOpen vSwitchのフロールールを適切に設定し、Open vSwitchではHardware Offloadによって通信性能を保証します。
このOpen vSwitchの採用によって柔軟性が飛躍的に向上し、GPU NWの領域におけるテナント同士の通信の分離や、そのほかのネットワーク機能の実現に関しても可能性を示しています。
さらに、サーバのNICの枚数は2枚まで縮小することでコストを抑えており、懸念点となる性能特性についても、Point To Point Communicationを除いて、広く一般的に利用されるCollective Communicationでは十分な帯域性能が実現できていることを実際に測定することで確認しました。
おわりに
今回はRethinking AI Infrastructure シリーズの Part 3 として、私たちの構築したGPUインフラの特にサーバ内部の設計について、背景にある技術的な考え方やアプローチについて紹介しました。私たちの目指すAIプラットフォームはまだまだ成長途中であり、まだまだ改善項目や新規開発項目などが数多く存在します。今回このブログでは、われわれの技術的な挑戦を公開することで、業界全体での議論がより活発になる一助になればと考えています。