こんにちは。LINEヤフーでAIプラットフォームのネットワーク設計を担当している小林と深澤です。この記事ではRethinking AI Infrastructureの連載の第二弾として、LINEヤフーのAIプラ�ットフォームを支えるGPUクラスタネットワークの設計とその考え方について解説します。 この記事が普段GPUクラスタやデータセンターネットワークなどのインフラを扱っている方々に役立つと嬉しいです。
AIのためのネットワーク
GPUクラスタのためのネットワークの話をいきなりする前に、この数年の生成AIブームがネットワークインフラにどのような変化をもたらしたのかについて簡単に振り返りたいと思います。私たちはインフラを運用する部門に所属しており、ネットワーク技術の専門家として自社サービスの運営や事業課題の解決に必要な技術を選定・検証し、プロダクションに落とし込み安定運用することに責任を持って取り組んでいます。
LINEヤフーは自社サービスの運営に必要な基盤はデータセンターから自社で運用していますので、サーバー間やユーザー向けの通信を処理するネットワーク設備や回線も自前で運用しています。特にこの5〜7年はデータセンターネットワークのアーキテクチャも決まった形で安定運用されてきました。その間、次の3〜5年先のネットワークに何が必要になるのか、調査・検証を並行して実施してきました。
これは私見になりますが、ネットワークのアーキテクチャや基盤技術の大きな変化は、それ単体ではなく、環境や周辺システムの圧力によって生じると考えています。およそ8年前であれば、データセンターでプライベートクラウドの需要が高まり、コンテナ化やマイクロサービスアーキテクチャの採用によって、トラフィックパターンがNorth-SouthからEast-Westに大きく変化しました。同時に可用性が高く、スケール�アウトが可能で自動化を前提としたネットワークの需要が高まり、インターネットサービスのためのネットワークアーキテクチャが現在の基本形に刷新されました。
そして現在、再び新しいネットワークアーキテクチャと技術を再検討する転換期が来たと感じています。今回ネットワークに技術革新の進化圧をかけているのが生成AIに代表される計算機クラスタの需要です。具体的にはメモリ間アクセスのための技術と、ストレージがその本質だと考えています。
GPTなどの深層学習に代表されるTransformerモデルの発展で、大規模言語モデルの開発や各種サービスの提供が一気に進みました。それに合わせて、世界中でAI/ML, HPC利用のためのGPUクラスタの構築が加速しています。
私たちはネットワークの専門家でありAIの専門家ではないので、ネットワークの話に戻しますが、この生成AIブームでネットワークには大きく2つの変化があったと考えています。一つが通信パターンの変化、もう一つがNICの高速化が急激に進んだことです。同時にネットワークとコンピューティングの境界がより曖昧になり、データセンター全体のEnd-to-Endで一つの計算リソースになりつつあり、「ネットワーク」と「サーバー」のような技術と運用の単純な線引が難しくなったと感じています。
この話をするためには現在主流のGPU サーバーの内部アーキテクチャについての理解を最初にしなければなりません。下に示すのが現在世界中の多くの企業や研究機関などで導入されているH100 GPUサーバーの簡略図になります。
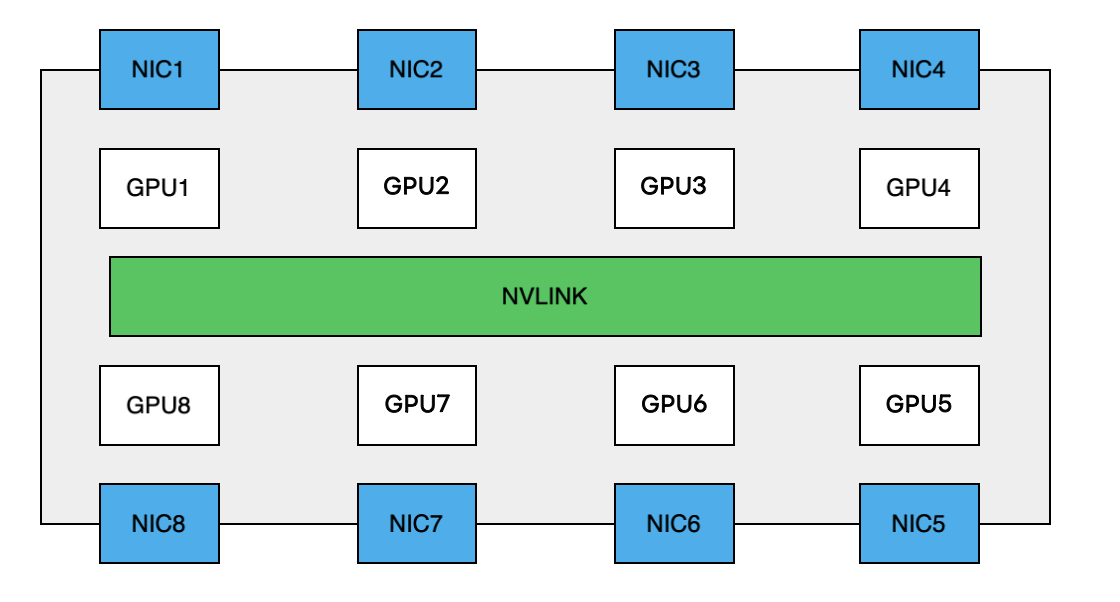
サーバー内にはその他にもPCIeなど数多くのコンポーネントがありますが、ここでは説明を簡単にするために重要な部分だけ示しています。内部のボード上には8つのGPU、8つのNIC、そしてGPUを相互接続する高速なバスがあります。このバスにより、これらのGPUは非常に大きな帯域幅で直接通信することができます。GPU間の通信がノード内に閉じている場合、このバスがボトルネックになることは原理的にありません。ノード内の論理トポロジに通信パターンが正しくマッピングされれば輻輳は発生しません。
問題は異なるGPUサーバー間でAll-Reduceなどの集団通信(Collective Communication)が発生する場合です。論理トポロジを一般的なRing-AllReduceだと仮定します。下の図がRing-AllReduceの論理パス(後述するRail)を表したものです。
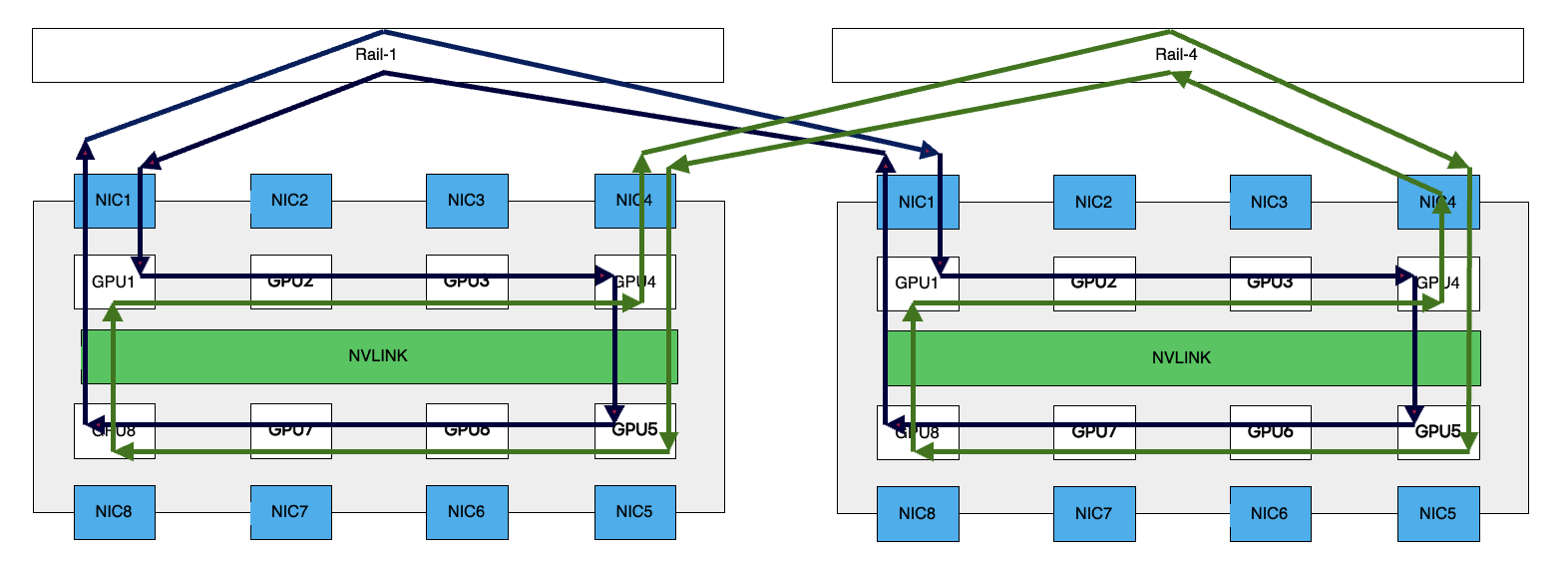
異なるGPUサーバー間でトラフィックが発生する場合、Reduce-ScatterやAll-Gatherを通じて、すべてのウェイトを合計する必要があります。この計算はすべてのGPUにわたって実行する必要があり、入出力に同じランクのNICを利用します。この論理トポロジはすべてNCCL(NVIDIA Collective Communications Library - 読み方はNickel)によって構築および維持されています。
これまでのインターネット(クラウド)サービスのためのデータセンターネットワークでは、サーバー同士の通信やサーバ��ーとインターネットの通信といった単純なトラフィックパターンが多数を占めていました。分散深層学習に代表されるGPU間の通信では、多対多のE-WトラフィックやP2Pのバースト的な通信が断続的に発生することになります。そして、LLMなど大規模なモデルの学習になると、学習の期間とそれに伴うトラフィック要求も増大します。
つまりサーバー内部のバスを外部まで延伸して相互接続する必要があるということです。
このような通信パターンと需要の変化が、NICの急激な高速化につながります。GPUサーバー内バスの帯域幅は非常に高速ですが、同じ帯域幅を現状のNICで実現することは困難になります。つまり内部の帯域に比べて外部向けの帯域がボトルネックになります。この高帯域の需要が、これまで最大100Gb/s程度だったサーバーインターフェースを200, 400, 800G、そして次世代の1.6Tb/sという速度まで急速に高速化を推し進めています。
今日時点で広く利用されているNICは400Gb/sです。400Gb/sと聞くととても高帯域に思えますが、内部バスの1/18の帯域幅しかありません。つまり、インターコネクトネットワークはまだまだ遅いのです。この内部バスの速度と外部インターフェースの速度の不均衡がネットワークエンジニアを悩ませるポイントの一つだと考えています。
このように、通信パターンの変化とNICが高速化したことによって、それを収容するデータセンターネットワークの設計も1から見直さなければなりませんでした。
GPUクラスタのためにデータセンターネットワーク全体をどのように再デザインする必要があるのかは、今年2月に電子情報通信学会で行われたワークショップで概要を話しましたので、細かな前段の内容はそちらを参照ください。
物理的な部分についてはPart 1で触れていますので、ここでは具体的なネットワークの設計の話をします。まずネットワークのトポロジをどのように決定したかという点から解説します。
ネットワークトポロジのデザインパターン
GPUクラスタのためのネットワークトポロジにはいくつかのリファレンスとなるデザインパターンがあります。
- Single構成
- ToR CLOS構成
- Pure-Rail構成
- Rail-Optimized構成
- その他の構成(Dragonflyなど)
要件や設計原則、予算などによってどれを選択するのか、またはしないのかが変わってきます。以下に各リファレンスデザインの特徴を簡単に紹介し、私たちがどれを選び、それがなぜなのかを解説します。
Single構成
最も単純な構成で、単一のスイッチでGPUサーバーを収容するものです。スイッチがシャーシ型かボックス型かでバッファ管理の方式など細かな違いが出ますが、そのスイッチのポート数が収容上限となります。構成はシンプルですが、スイッチ障害でクラスタ全停止となる単一障害点の大きさとメンテナンスコストのトレードオフが存在します。ビジネスインパクトと相談して導入することになります。
私たちは上記のトレードオフの観点と、GPUサーバーの増設の可能性があったことからこのデザインは選択しませんでした。
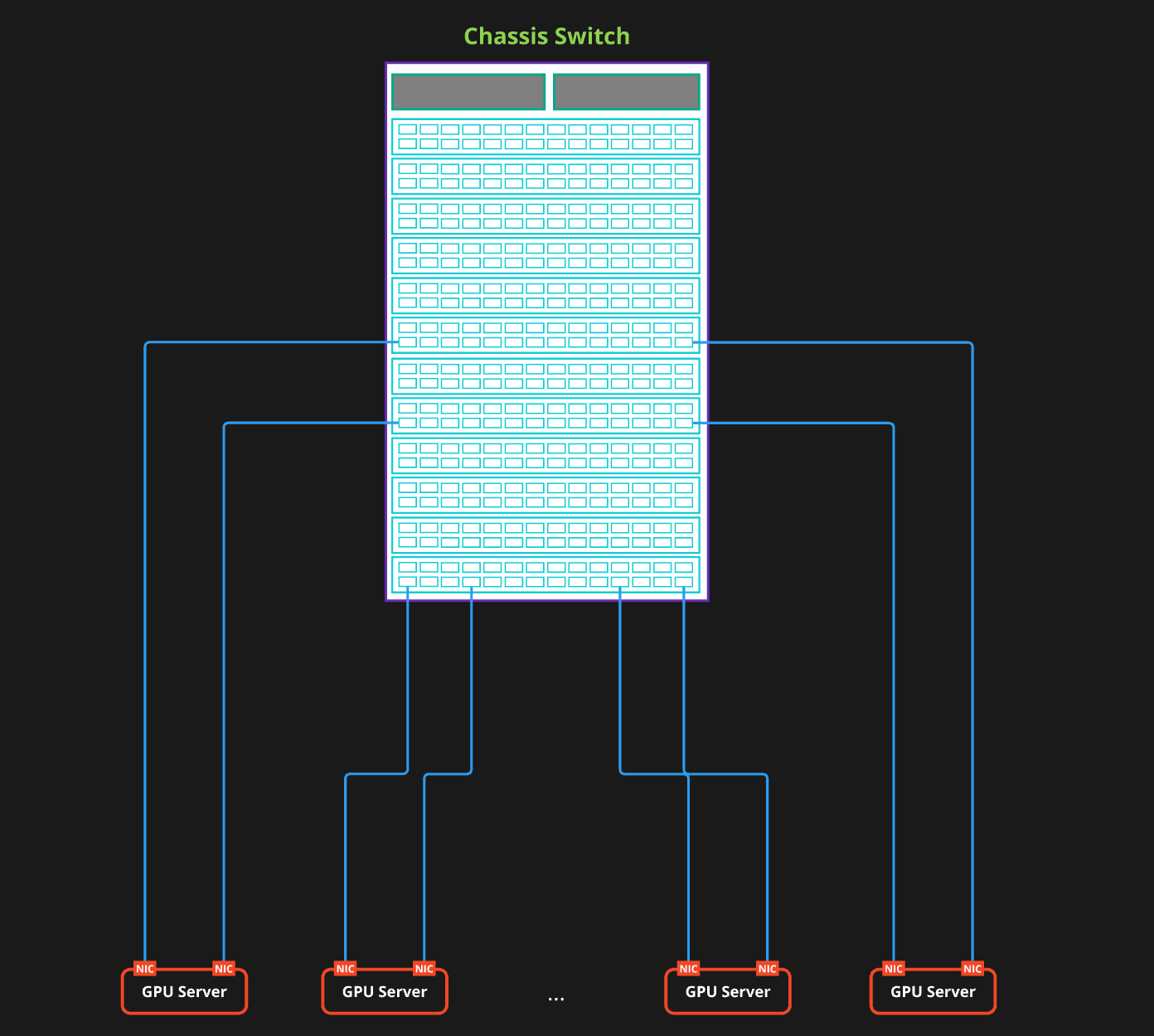
ToR CLOS構成
先に結論ですが、このトポロジは選ぶべきではありません。
これまでWeb-Scale Fabric(Front-End Fabric)で最も利用されてきた構成です。各ラックにToRとなるLeafスイッチを設置、そのラックのサーバーを収容します。インターネットデータセンターで一般的なCLOSネットワークの構成をそのまま採用する形になります。
この構成は実績もあり有益なように見えますが、GPUクラスタにおいてはそうではありません。GPUサーバーには8つのNICが搭載されていることを先に述べました。このデザインではGPUサーバーから伸びる8本のケーブルを同じToRスイッチに収容します。
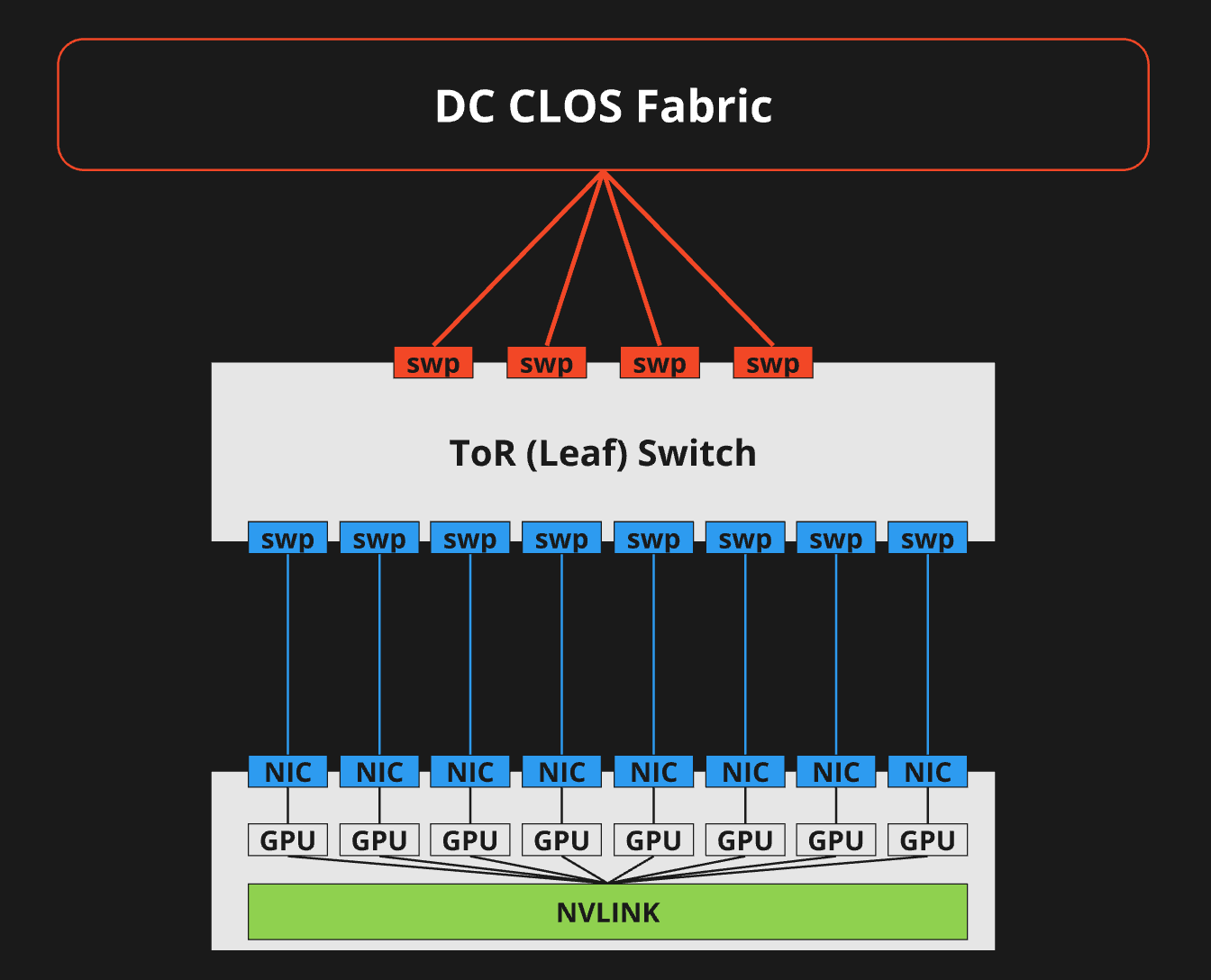
このとき、GPUサーバーから見てファーストホップ(最初のパケット転送先)となるToRスイッチまでは通信経路が”パラレル”です。GPUサーバーとToRスイッチの間では輻輳ポイントがありません。リンクが物理的に競合しないためです。しかしToRのアップリンクから事情が変わります。スイッチのアップリンクを冗長して複数本で上位レベルのSpineスイッチに接続することになります。このとき、このアップリンクは競合ポイントになります。GPUサーバーのNICとToRスイッチのダウンリンクの接続は、GPUランクで物理的に帯域が確保されていましたが、アップリンクは共有になります。スイッチのアップリンクに、ダウンリンクと同じ本数のケーブルがあったとしても、各GPUランクのワークロードは1:1で均等に割当されることはありません。パケットのエントロピーによって分散されます。つまり、帯域の使用率を考慮するようなインテリジェントなロードバランシングのメカニズムがない限り輻輳が発生するリスクがあります。
もう一つの非推奨の理由が、遅延です。ToR構成の場合、異なるToR配下のサーバーへの通信は必ず上位レベルのスイッチを経由(横断)せざるを得ません。特にCLOSを組むようなネットワークの規模が大きくなるほど、各スイッチのバッファでの遅延の累積値がワークロードのパフォーマンスに影響を与えることがあります。リングを閉じるまでに必要なホップ数が増える構成です。
特に理由がないのであれば避けたほうが良いと考えています。
私たちは通常のCLOS構成のネットワークの運用経験は豊富にありますが、上記の理由からGPUクラスタではこのデザインを選択しませんでした。
Pure-Rail (Rail-Only)構成
ToR CLOS構成に似ていますが、LeafスイッチをGPUサーバーのNIC(GPU) と同じだけの数用意して接続する構成です。LeafスイッチはRailスイッチとも呼ばれます。NICが8個であればLeafスイッチも8台になり、各GPUとNICに対応するスイッチに接続します。
ここで、Railという言葉が登場しました。RailとはGPU間通信におけるデータ転送のパスやリンクを指します。これには、物理的なリンク(ハードウェア)と論理的なパスが含まれます。GPUはサーバー内部のPCIeやNVLink、そしてインターコネクトNICを経由して論理的にRingやTreeの構成(アルゴリズム)でデータを転送します。サーバー内部のコンポーネントの接続構成やネットワークの帯域などを、集団通信を行うNCCLが計算し、最適なパスとアルゴリズムのパラメータを決定します。CCLはGPU間通信においてパフォーマンスに関わる重要な要素であるため、その仕様と物理ネットワークへマッピングした際の動作の理解が欠かせません。NCCLは、このGPU間の論理パス=Railが最短であることを前提として、最高のパフォーマンスを発揮するように作られています。
つまり、物理トポロジとしてGPU間が最短経路で最適化されたネットワークを構築する必要があるということになります。最短経路とは、GPUサーバー間に挟まるスイッチ(ホップ数)が少ないことを意味します。
この構成のメリットは、各サーバーのGPU間通信が最短ホップで実現できることです。基本的にLeafスイッチ折り返しで通信が完結します。
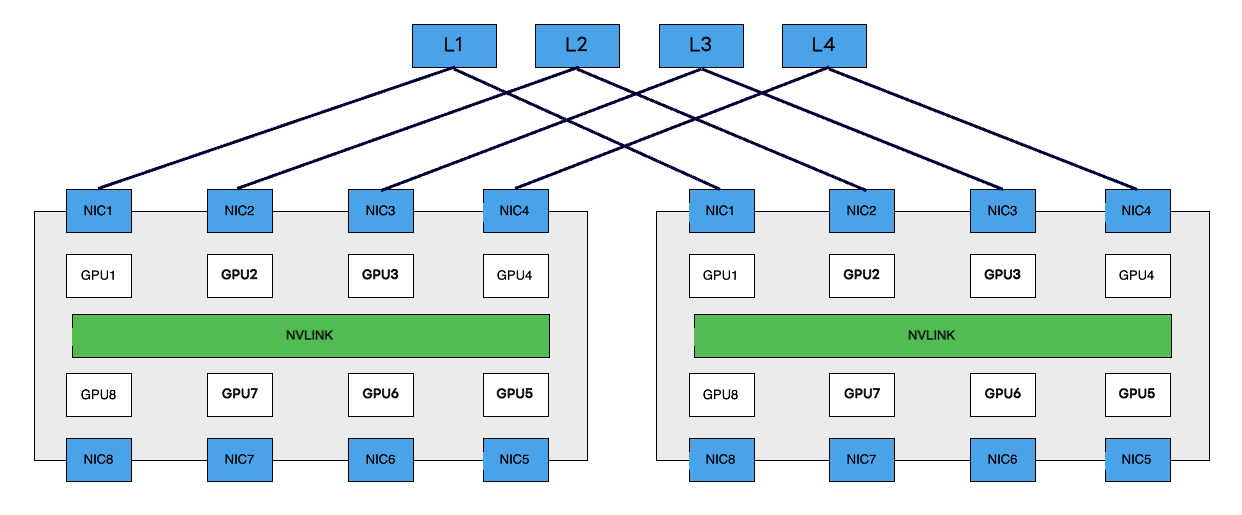
(図の便宜上、上半分のNICしか接続していませんが、実際には下半分のNICも対応するLeafに接続されます。)
Rail-Onlyという名前にもある通り、異なるGPUランク間の通信のパスをネットワークとして物理的に提供しません。この構成では、Railを横断する通信が完全にPXN(PCIe x NVLink)に依存します。
PXNは、通信先のGPUランクが同一Railでない場合、通信先と同一Rail上にあるサーバー内部のNICまで内部バスを経由してデータを転送してから通信する技術です。Railを横断するためにブリッジするSpineスイッチが物理的に存在しないため、送信側が内部トポロジをPXNで認識し��カバーする必要があります。詳細は以下の記事をご参照ください。
なので集団通信のアルゴリズムの種類やワークロードによっては最高のパフォーマンスを発揮できない可能性がある点に注意が必要です。その代わり、Rail Leafスイッチの上位に、各Rail専用のSpineを設置すればよりネットワークをスケールアウトすることが可能です。
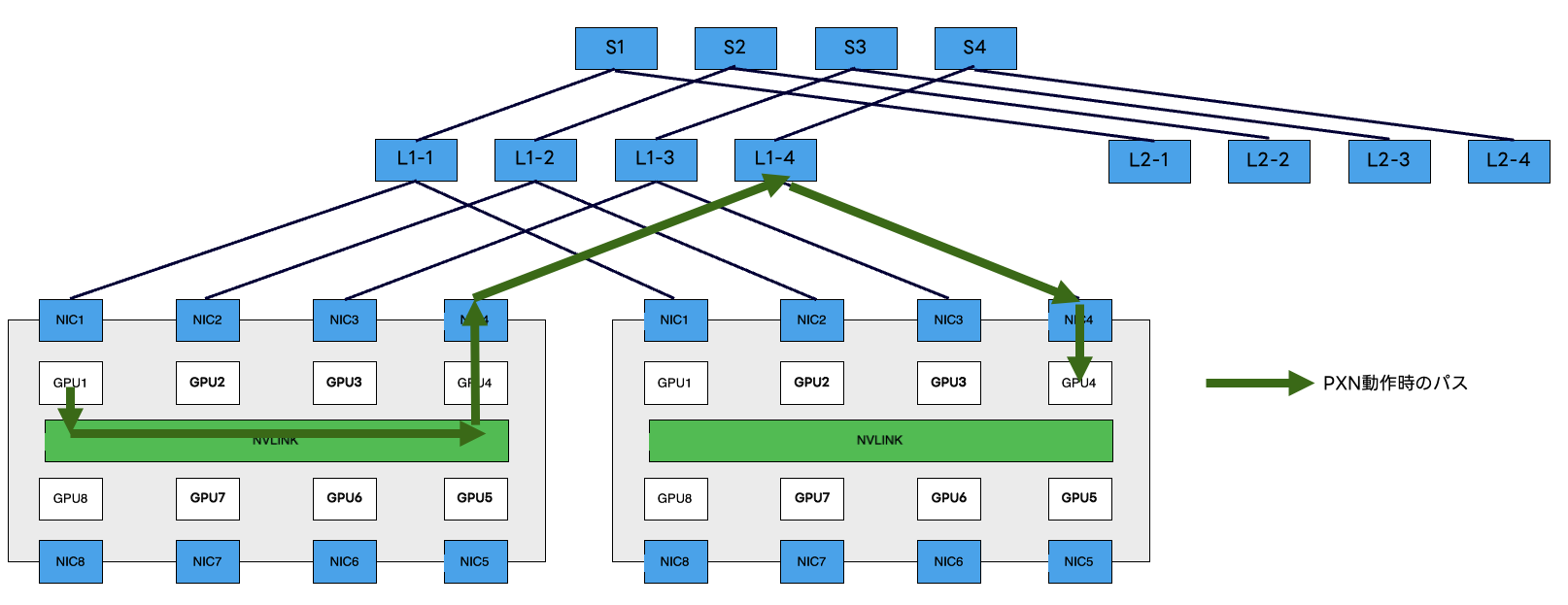
このデザインをプロダクションで導入している企業もありますし、関連論文も発表されて話題になるなど注目度が高い設計の一つです。
私たちはプロダクション環境でこの構成の検証を実施し、PXNを用いることで問題なくワークロードが完了することは確認しました。しかし、細かな技術上の調整や仮説の裏付けをする時間が取れなかったことから、今回はこのデザインは選択しませんでした。コスト効率の観点で有益な選択肢であるため、今後も検証を進めていく計画です。
Rail-Optimized構成
Pure-Rail構成のLeafスイッチの上位にRailをブリッジするためのCLOSネットワークを構成するものです。Pure-Rail構成のメリットを享受しつつ、Railを横断する通信も物理ネットワークで確保されるため、最高のパフォーマンスを発揮できる可能性が高いトポロジです。同時にネットワークのスケーラビリティも向上するため、大規模な構成に適しています。リファレンスアーキテクチャに採用されています。
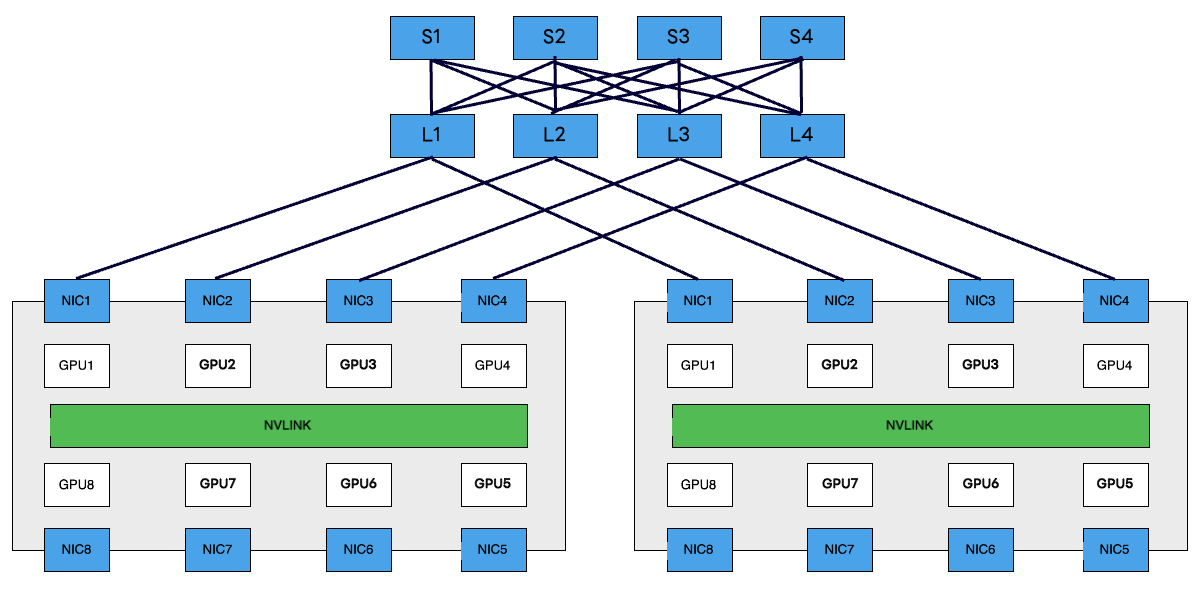
私たちは今回はじめて本格的なGPUクラスタのネットワークを構築したこともあり、このデザインを選択しました。
その他の構成
上記の構成の他にも計算機クラスタを接続するトポロジはさまざまあります。研究機関のHPCやスパコンの世界で利用されるインターコネクトトポロジや関連技術もキャッチアップはしていますが、現状では私たちのようなクラウドベースのサービスを提供する環境に適用可能なものは少ないです。後述する専用の規格やクラスタの増設を前提としないなど、私たちの既存のネットワークとの相互接続性や運用の親和性を考慮し、現在は標準化動向の注視とPoCに留めています。
Ethernet vs InfiniBand
GPUやストレージなど、高速・低遅延で信頼性の高い通信が求められる環境には専用の規格が採用されることが多々あります。その代表的な技術がInfiniBandであり、現在でもTOP500上位のスパコンをはじめ広く普及している実績のある規格になります。
GPUのインターコネクトを構築するにあたって、ネットワークトポロジの他にその通信規格をどうするのかという観点がありました。GPU間の通信はRDMAで行われますが、InfiniBandはRDMAのために作られたプロトコルですので、原理的にロスレスで非常に高い信頼性があります。
私たちが普段運用しているネットワークのほとんどがインターネットベースのEthernetになり、InfiniBandとはプロトコルスタックの設計が根本的に異なります。Ethernet上でRDMAの通信を行うには、RoCEv2(RDMA over Converged Ethernet)を利用することが一般的です。
現在はパフォーマンスの観点で、遅延を除きInfiniBandとRoCEv2に大差はないというデータもあり、どちらを選択するのかネットワークエンジニアにとって悩ましいポイントの一つです。
私たちのAIプラットフォームはLLMなどの大規模トレーニングや特定の用途専用というわけではありません。さまざまな社内ユーザーが汎用的に利用できる基盤である必要があります。それにはクラウドベースのマルチテナンシーも含まれます。特定の用途とユーザーに特化した環境であればInfiniBandが最適な選択肢だったかもしれません。
同時に、自前の技術でプラットフォームを内製する私たちにとって、技術がオープンな仕様であることも重要でした。Ethernetはインターネットベースの技術でその仕様は広く公開され実装がコモディティ化しています。InfiniBandはその高いパフォーマンスと信頼性の実現とトレードオフで、ネットワークのすべてを専用のハードウェアとソフトウェアで構成しなければなりません。またその仕様も業界団体で策定されメンバーのみアクセス可能です。
技術仕様と実装がオープンであることは、社内の人材育成の観点でもメリットがありました。私たちのミッションの一つに、AI時代のネットワークエンジニアを社内で育成するというものがあ��ります。ネットワークとコンピューティングの境界が曖昧になっていく世界で、旧態依然としたネットワーク設計・運用に囚われず、自分から技術、業界動向をキャッチアップし、先端技術を運用現場のプロダクションネットワークに現実的なレベルで落とし込むことができるエンジニアを育成するには、コミュニティと実装がオープンであることは重要でした。
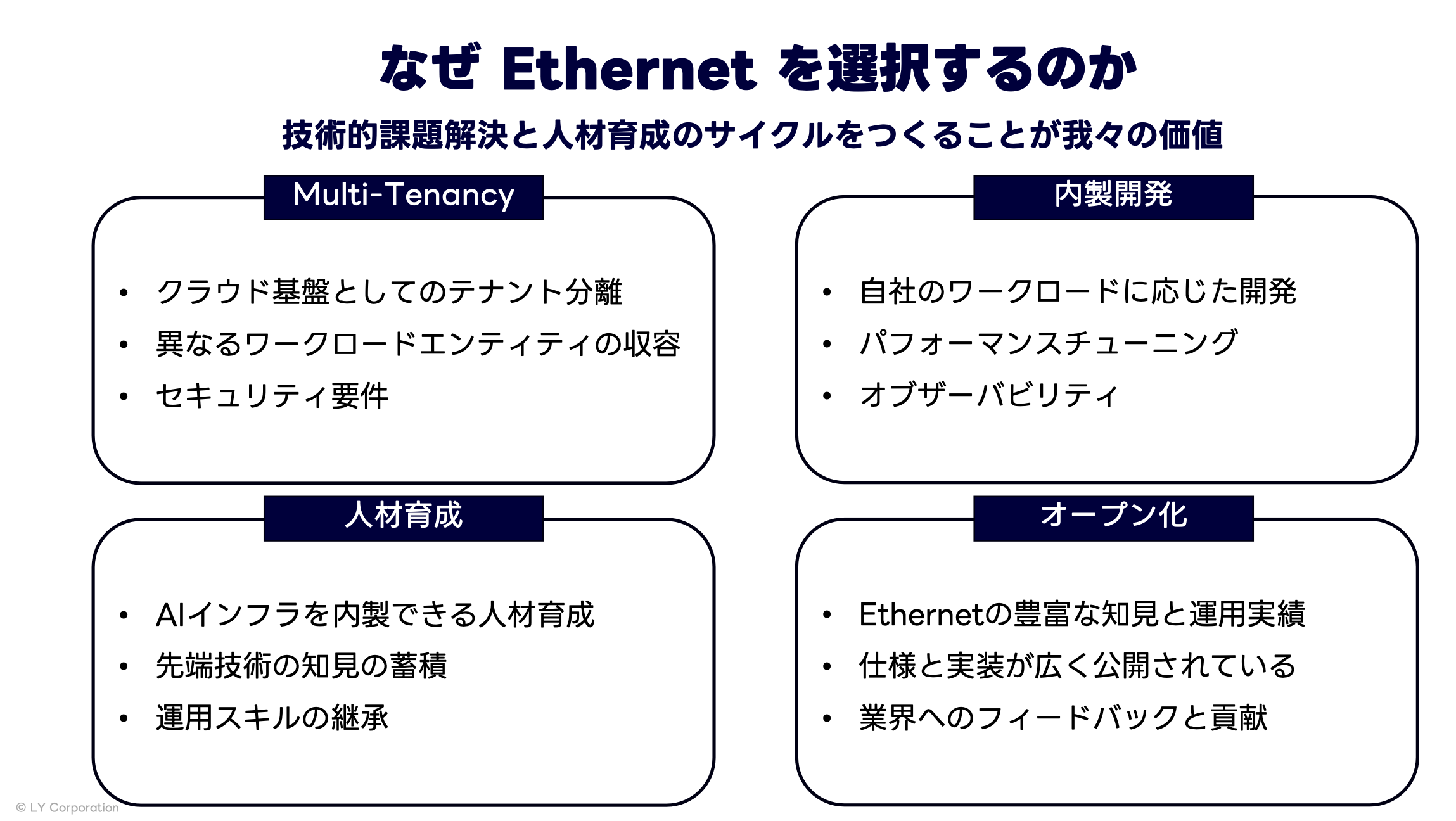
このような背景から私たちはインターコネクトにEthernetを選択しました。
Scheduled or Non-Scheduled Fabric
ネットワークトポロジにRail-Optimized構成を採用し、プロトコルにEthernet (RoCEv2) を採用することが決まりました。これで検討事項はすべてクリアになったかというと、そうではありません。私たちを悩ませるさらなるポイントは、ネットワークのインテリジェンスをどこで吸収するかという観点です。インテリジェンスというのは輻輳制御やパケットの順序制御などです。この観点でパケットを "Scheduled" にするかどうかという考慮ポイントがありました。
現在、AIのためのネットワーク技術は業界全体として過渡期にあります。上記に記載したワークショップ資料でも触れていますが、RoCEv2ではこれまでInfiniBandがプロトコルの仕様として実現していたロスレスの機能をEthernetで実現しなければなりません。そのために複数のバッファ管理の技術とロードバランシングの技術を組み合わせてロスレスイーサネットは実現されます。
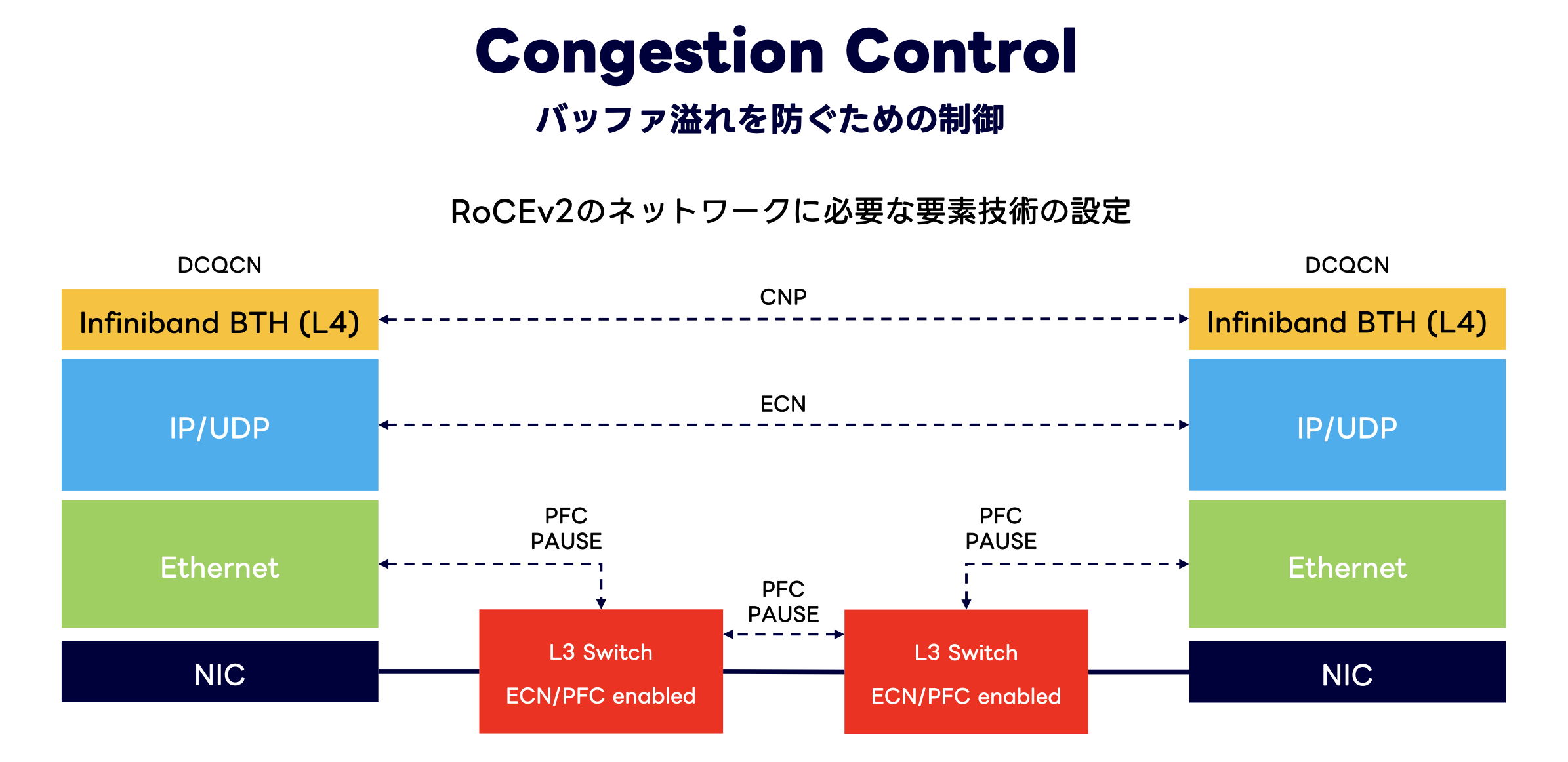
しかし、それら個別の技術はRDMAの通信のために開発された背景ではないため、今日のワークロードエンティティに対して機敏に対処できないという課題も抱えています。
そうした背景から、ネットワーク機器ベンダ各社は各自のソリューションでこれを解消しようとしています。この記事で詳細は触れませんが、業界団体でAI/HPCのための新たなネットワークプロトコルスタックの仕様策定を進めている動きもあります。
これらの注目すべき技術の一つにScheduled Fabricがあります。これはディープバッファ技術の一つであるVoQ(Virtual Output Queueing)のネットワークASICを搭載したスイッチを利用するソリューションです。基本的にバックプレーンファブリックを搭載するシャーシ型のスイッチを利用するものになり、クレジットベースのバックプレーンでパケットを均等に分散し、順不同になったパケットをバッファで吸収します。RoCEv2のトラフィックにはエントロピーが少ないためロードバランシングの観点で偏りが発生しやすいというのは先述の通りです。Scheduled Fabricはシャーシ内部でパケット単位で分散させるためロードバランシングの課題を解決できます。同時にディープバッファを利用して順序が入れ替わったパケットをスイッチ上で並び替えることができます。基本的にVoQのASICを搭載したシャーシ型のスイッチがもともと持っていた仕組��みを利用して実現する方式になりますので、Single構成を採用しない私たちの検討のスコープ外でした。
しかし、最近はこのScheduled Fabricを分散シャーシで実現しようという取り組みがあります。シャーシ型のスイッチのラインカードを分散配置してLeaf-SpineのCLOS構成を作るようなソリューションです。こうすることでシャーシ型スイッチの課題であったスケールアウトの課題を解決しようというものになります。今年のOCP Summitでもハイパースケーラーの導入事例が大々的に発表され注目されました。

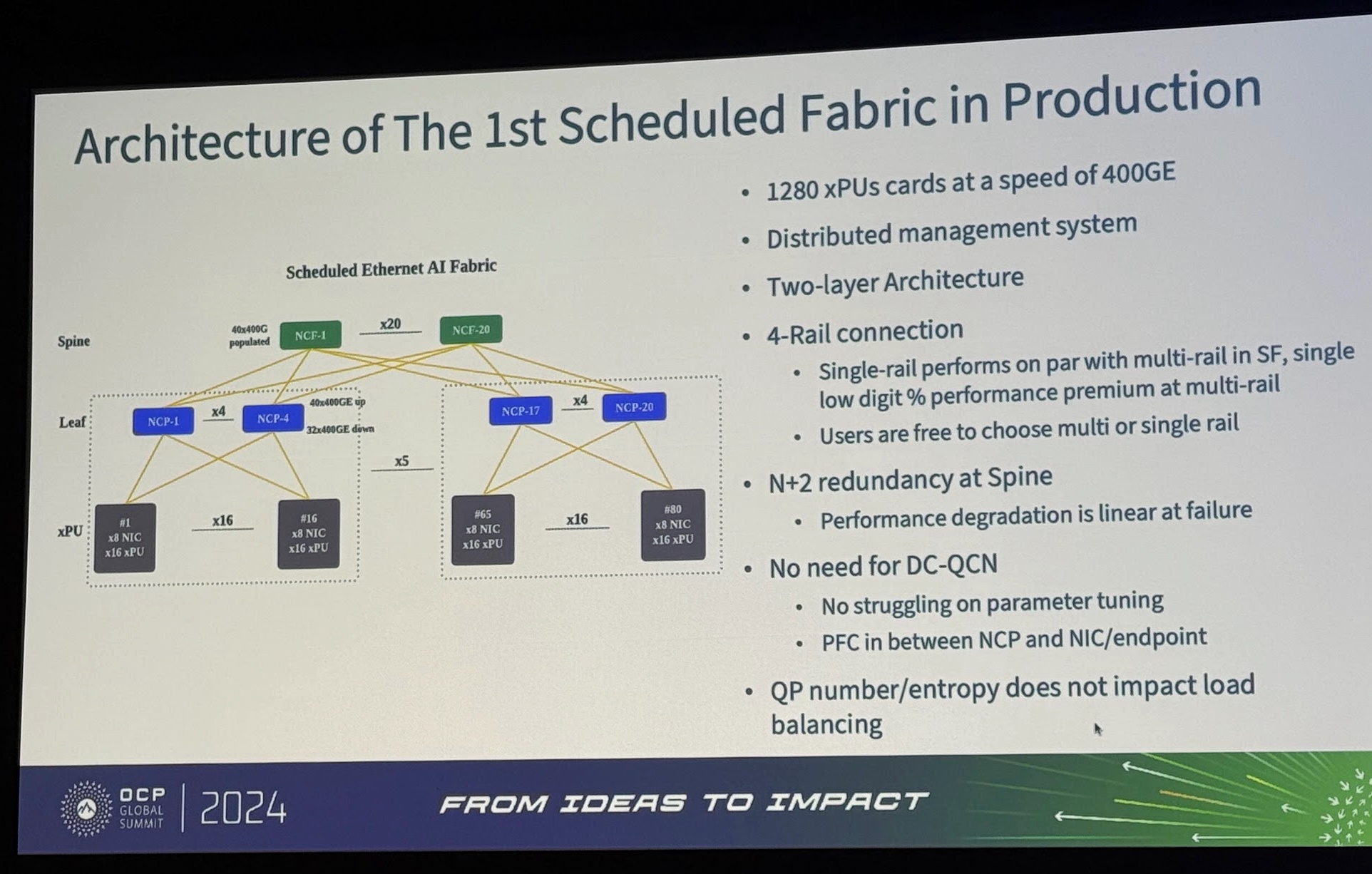
画像は以下の講演動画より抜粋:
Powering the AI Future Meta Vision for Open Systems for AI - presented by Meta
Insights from Production Scheduled Ethernet Fabric in Large AI Training Clusters
結論として、私たちはこのScheduled Fabricを採用しなかったのですが、その判断が適切だったのか自信を持って答えられませんでした。適切なタイミングで適切な技術選定を行う審美眼を持つためには、技術に対する深い造詣とその流れを見る視点が欠かせません。
そのため、実際にアメリカに行き当事者や有識者と直接議論をすることで、日本で情報を待っているだけでは見えてこない本質に迫ろうと考えました。
OCP Summitでの議論
今年の10月にサンノゼで開催されたOCP Summitで、さまざまな技術とそのユースケースについて議論を行うことができました。

議論の詳細を記載すると長くなってしまうので、簡単に一部だけ記載します。
Scheduled Fabricについて、複数の企業の有識者との議論内容:
-
分散Scheduled Fabricでは、パケットはクレジットベースの送信許可を待っている間、イングレスリーフスイッチでバッファリングされるが、必要なバッファのボリュームはスケールに比例して増加する
-
輻輳リンクを回避するために十分な出力バッファリングが必要になる
-
オンチップのSRAMバッファは限られているため、トラフィックが外部メモリに書き込まれ、ロスレスの実現と引き換えにテールレイテンシが増加する可能性がある
-
ディープバッファによってもたらされる追加のレイテンシは、全体的なパフォーマンスにとって重要になる
-
コントロールプレーンの複雑さが増してしまう → 標準化を進める予定と言及したセッションあり
-
実装はベンダ固有であり、ユーザーは特定の実装を理解する必要がある
- 機器間を流れるパケットがEthernetではなく、チ�ップベンダ固有のフレームになる
- ある意味で、形を変えたInfiniBandのようなクローズドベンダーソリューションであると言える
- UECの製品が市場に普及する未来があるとして、その頃に生き残っているかは非常に興味深い
など、各社がポジショントークに技術的に鋭い指摘を交えながら話すので、自分でファクトチェックを行いながら整理して考える必要があり、非常に有意義でした。
同時に会場のセッションや展示では一切言及はありませんでしたが、会場で立ち話をしたエンジニアが Scheduled Fabric について別のアプローチの実装が進んでいることも教えてくれました。このような最先端の取り組みに関する情報や有益なナレッジは、オフラインで直接会話しないと入手できないため、これだけでもアメリカに来た価値を感じられました。
実際の構成
前置きが長くなりましたが、われわれが今回構築したネットワークは以下のような構成になっています。
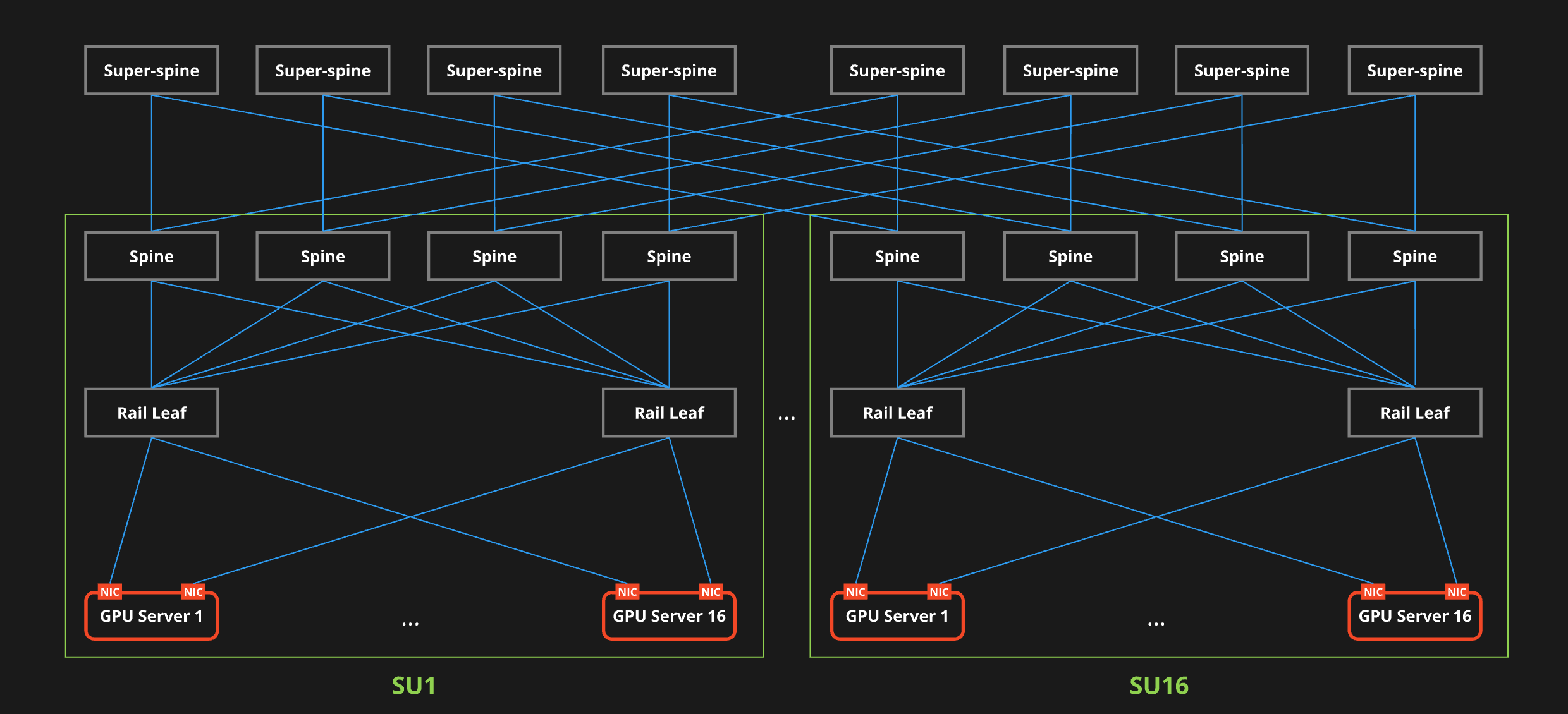
構成概要
- HGX H100 GPU Cluster
- 最大2,048GPUを収容可能
- 128GPUで1SU(Scalable Unit)を構成
- Rail-optimized Design
- 3-Tier CLOS Network
- 400GE
- ConnectX-7 NIC
- Spectrum SN4700 switch
- RoCEv2
- Adaptive Routing
3層の5-stage CLOSトポロジを基本とし、LeafをRail-Optimized構成にしま�した。GPUサーバーの増設計画があり、スケールアウトしやすくしたかったためです。Scalable Unit(SU)と呼ばれる単位のPodをSuper-Spineスイッチ経由で相互接続します。ネットワーク機器もGPUと同一ベンダで構成されていますが、トータルソリューションではなく、ネットワークを設計していた約2年前の時点で要件を満たす実装がこの組み合わせだったためです。現在であればEthernetベースの実装も普及してきましたので、この組み合わせにこだわる必要はありません。次の世代のGPUクラスタでは別のベンダの機器も採用しています。
Leaf switchのラックデザインにはEoR(End-of-Row)を採用しました。スイッチからGPUサーバーへのケーブルの長さが均等にならないことによる遅延の問題とトレードオフの構成ですが、私たちの環境では問題にならないと判断しました。ネットワークに集約することによって、GPUラックはサーバーのための設計に特化できます。写真でGPUラックの上部が空いているのは今後の拡張のためです。



構築したネットワークがLossless Ethernetとして問題なく稼働することを、単純なパケット印加試験だけでなく、GPUをエミュレートすることによるCollective Communication Library(CCL)を用いた集団通信テストをしています。このような試験には実際のGPUサーバーだけでなく、最新のテスターをベンダ協力の下、アメリカのDCに設置して実施しました。ご協力いただいた各社の皆様には感謝申し上げます。基本的にDCQCNベースのネットワークが問題なく稼働することを確認してユーザーにリリースしています。

私たちの構成で特徴的なのはGPUサーバーに搭載するNICの数を減らしていることです。この領域に詳しい方なら、上記の構成情報を見てGPUサーバーにNICが8個フルで搭載されていると実現できない設計だとお気づきと思います。

なぜこのような構成になっているのか、パフォーマンスに影響がないのかといった観点の疑問が当然あるかと思います。実際このようにしたことによって、良かった点と思いがけず苦労した点がありますので、実測値のデータを含めて詳細を解説したいのです��が、それにはこの記事は既に長すぎます。
詳細はJANOG55で
2025年1月22日のJANOG55 Day1 に、この取り組みについての技術的な詳細を話します。
https://www.janog.gr.jp/meeting/janog55/ai-infra/
ここで上記で述べた私たちの課題解決の方法が正解だったのか、実際のデータを交えて紹介します。配信もされますので、ぜひご覧になってください。登壇内容については次回の連載(Part 3)でも詳細を解説する予定です。
お楽しみに!
おわりに
今回は Rethinking AI Infrastructure シリーズの Part 2 として、私たちがアメリカデータセンターで運用しているGPUクラスタネットワークの設計と、その設計の背景にある技術的な考え方やアプローチについて紹介しました。私たちが目指すAIプラットフォームはまだ成長途中で、完成ではありませんので、まだまだ改善や新規開発が必要な部分が数多くあります。このような取り組みの一部を公開することで、業界全体で技術やそれを取り巻く環境に対する議論が活発になる一助になることを期待しています。


