こんにちは。データグループデータサービス統括本部の井上と小出です。
本記事では、前回こちらの記事にてご紹介した機械学習モデル開発の品質評価の計測について、その後の状況をご紹介します。
前回の振り返り
ヤフー株式会社(現LINEヤフー株式会社)にて2021年からMLOpsを推進する組織を立ち上げ、サイエンス組織とプラットフォームを提供する組織の間をつなぐ役割としての活動を行ってきました。
その取り組みの一環として行ってきたのが、社内でMLOpsScoreと呼ばれている機械学習モデル開発の品質の計測です。
MLOpsScoreの概要
MLOpsScoreはGoogleが2017年に論文として投稿した機械学習システムの信頼性を数値化する仕組みであるML Test Scoreを、社内のプラットフォームやプロダクトに合わせてローカライズしたものです。具体的には、下記の4つの領域について、それぞれ7つの項目に答えていきます。
- TESTS FOR FEATURES AND DATA(以後、特徴量・データ領域)
- TESTS FOR MODEL DEVELOPMENT(以後、モデル開発領域)
- TESTS FOR ML INFRASTRUCTURE(以後、インフラ領域)
- MONITORING TESTS FOR ML(以後、モニタリング領域)
質問例を下記に示します。
| 領域 | 質問内容 |
|---|---|
| 特徴量・データ領域 | 新しい特徴量は素早く追加可能か |
| モデル開発領域 | 全てのモデルはハイパーパラメータチューニングされているか |
| インフラ領域 | モデルは、安全かつ高速に前のバージョンに戻せるか |
| モニタリング領域 | モデルは極端に古い状態ではないか |
質問内容に対して、手動で実行しその結果をドキュメントに残していれば0.5、CIなどに組み込まれ自動実行されている場合には1.0、どちらにも該当しない場合には0といった形で回答し、各領域においてスコアを合算し、そのスコアの最小値が最終的なMLOpsScoreです。
前回報告した際の、合併前のヤフー株式会社のプロダクトにおける MLOpsScoreの結果は以下の通りでした。
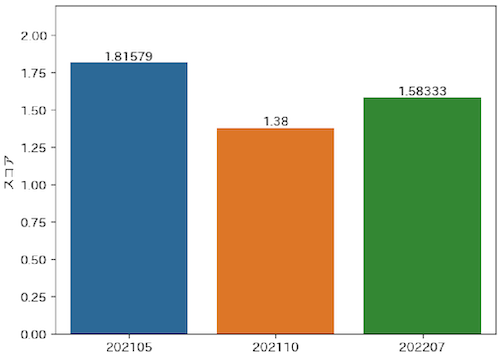
元論文の判定基準に当てはめると、現行のスコアは「基礎的なプロジェクトの要求事項は通過した。しかし、信頼性向上のためのさらなる投資が必要とされる」という判定です。当初はこのスコアが2を超える、「適切なテストがされているが、さらに自動化の余地が残っている」を達成することをいったんの目標としていました。
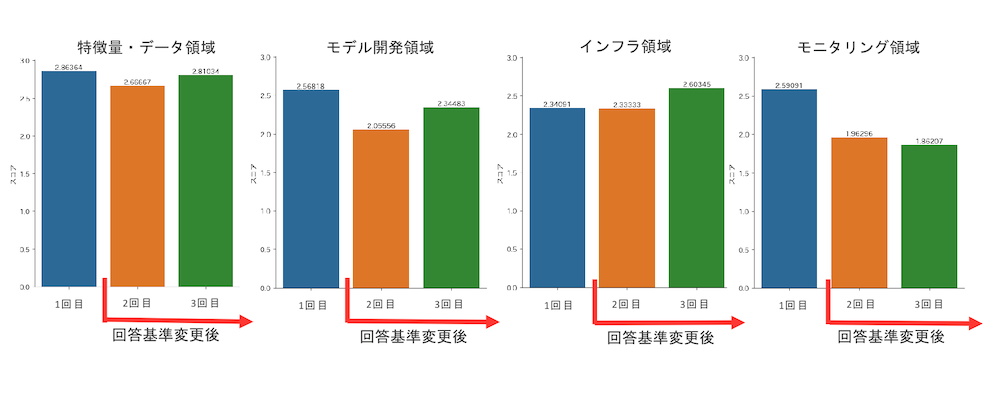
また、各カテゴリごとに分解して見てみると、特にモニタリングの領域について課題がありそうなことがわかります。
取り組んできたこと
前回のMLOpsScoreの結果をさらに向上させるために、MLOps推進チームならびに関連チームが取り組んできたことをご紹介します。
MLOpsプロダクトの強化
機械学習パイプライン
前回のTech Blogでは、機械学習パイプラインの構築における利用技術を共通化するために、Apache Airflow、Argo Workflowsといったツールの提供を開始したことを報告しました。
その後Apache Airflowについては社内にてマ�ネージドサービスとしての提供を開始(社内ではManaged Airflowと呼ばれています)し、Airflowクラスタ自体の構築やバージョンアップなどの継続的な運用の負担を大きく削減することに成功しました。
現在では機械学習パイプライン構築において他の選択肢を利用したり、独自にAirflowサーバーを立てたりする事例はほとんどなく、Managed Airflowを利用することがデファクトスタンダートとなりました。
このように多くのユーザーが利用するプロダクトを選定し、それをマネージドサービスとして提供することを繰り返すことによって、自然と仕組みが共通化されていくような流れを作り出すことを意識してきました。
モニタリング
モニタリング強化にあたり、モニタリングを容易に実現するための仕組みづくりが必要になります。
ヤフー株式会社(現LINEヤフー株式会社)では以前より開発済みであったモデルモニタリングのプロダクトであるDronachがありました。既に活用の実績はあったものの、さらに広く活用を推し進めるための啓発活用や、プロダクトの品質を高めるための機能面のフィードバックや、それに対応したプロダクトの改善を行ってきました。
また、モデルだけでなくデータの品質を管理するための仕組みについても提供が開始されました。このプロダクトはACP Data Qualityと呼ばれており、DQMLと呼ばれるデータ品質モデルの定義に特化した独自のDSL(Domain Specific Language:ドメイン固有言語)でデータ品質を管理できます。
これらのプロダクトの提供や機能強化によってモニタリングの強化を推進してきました。
モニタリングガイドラインの制定
先述のモニタリングのためのプロダクトをリリースにしたことによって、モニタリングを効率よく行うための基盤の整備が進みました。
一方で、サイエンス組織におけるメインミッションは、データサイエンスを活用して事業への直接的貢献を行うことであり、モデルの開発や改善にほとんどの時間が費やされます。その結果、モニタリングに投資できる時間は相対的に少なくなりがちです。また、モニタリングの主目的はインシデントの防止であり、それ自体が直接的な利益を生むものではないため、どうしても後回しにされてしまいがちな領域になってしまいます。
そこで、プロダクション環境にリリースする際に最低限担保されるべきモニタリング項目、ならびにその設定方法をガイドラインとして作成することにしました。
具体的なガイドラインの事例です。
オンライン または オフライン評価メトリクス
- 取得メトリクス
- オンライン または オフライン評価メトリクス
- 用途
- モデルの一般的な性能を把握するため
- 対象者
- 本番サービスで動く機械学習モデルを開発しているプロダクト
- 対象範囲
- 以下のいずれかを取得している
- モデル学習・評価時のオフライン評価メトリクス(recall等)
- モデル推論・ABテスト時のオンライン評価メトリクス(KPI/独自設定した評価指標等)
- 以下のいずれかを取得している
- 必須要件
- モデル学習に利用するオフラインorオンライン評価メトリクスが、各モデルの各バージョンごとに取得され保存されている
- オフラインメトリクス
- 更新時(モデルの学習時)に取得される
- 時系列的に保存されている必要がある
- オンラインメトリクス
- 定期的に取得される
- 時系列的に保存されている必要がある
- 上記メトリクスはモデルの性能比較に利用可能であること
- 推奨要件
- オンラインとオフライン両方ともメトリクス取得をしている
- 評価メトリクスが可視化されていて、性能の推移がわかる
- 評価メトリクスにしきい値が設定されており、しきい値を考慮した自動デプロイの仕組みが整っている
当初、リリース時の必須項目とすることや、リリース済みのプロダクトについても一定期間内に本ガイドラインの項目に対応することを検討しました。しかし事業貢献の都合も考慮し、推奨項目として活用されることになりました。
MLOpsCommunityの継続した活動
技術的な取り組み以外に、MLOpsに関するナレッジ共有の場として、MLOpsCommunityを立ち上げ活動を続けています。2022年の6月に始動して以降、延べ20回のイベントを開催し、数多くのMLOpsの取り組みが紹介されてきました。
イベントを開催する際、可能な限り発表のテーマを決めた上で発表者の自薦、他薦の募集をするようにしています。そうすることで、MLOpsの初学者の方に対しても聞きやすくすること、社内外のトレンドにフォーカスした内容を紹介できることが期待できると考えています。
実際に社内でモニタリング強化への課題感が上がって以降、モニタリングに関連するテーマでの発表を増やし、多くの方にモニタリングに関するナレッジが共有されるよう意識的に取り組んできました。
MLOpsScoreのアップデート
MLOpsScoreについては、記入者のフィードバックを受けて継続的に項目のアップデートを行っています。前回の紹介記事では、曖昧だった回答基準を社内のコンディションに合わせて明確にすることで、回答のブレを小さくした取り組みをご紹介しました。その後の回答者のフィードバックとして、モデリングのタスクによっては一部の質問について回答のしようがないものがあるという指摘をもらっており、こちらについても検討の上、一部の質問についてはタスクによって回答対象外として集計に含めないような対応を行うことにしました。
具体的な質問例については下記になります。
- 質問A:
- 質問内容
- 全ての特徴量は予測に対して有用か
- 新回答基準
- 0:何もしていない
- 0.5:実験の際にどの特徴量が有用かどうかを毎回手動で確認している
- 1.0:実験の際にどの特徴量が有用かどうかを自動で確認できる仕組みができている、定常的な学習においても同様の仕組みで性能の検証がパイプラインに組み込まれている
- 対象外:画像処理や自然言語処理の分野等において、今後特徴量追加する予定がない場合
- 質問内容
- 質問B:
- 質問内容
- 全ての特徴量生成コードはテストされているか
- 新回答基準
- 0:テストをしていない、もしくは手動で単体テストを実施している
- 0.5:CI/CDパイプラインで特徴量生成コードに対して単体テストを実行しているが、テストカバレッジは不十分である(行レベルで80%未満)
- 1.0:CI/CDパイプラインで特徴量生成コードに対して単体テストを実行しており、テストカバレッジも高い(行レベルで80%以上)
- 対象外:生データを直接入力に入れるなど、データの加工を一切行っていない場合
- 質問内容
こういった取り組みを継続的に行うことで、MLOpsScoreの改善を目指してきました。
最新の計測結果
これらの取り組みの結果、MLOpsScoreをどの程度向上させることができたでしょうか。
以降2024年1月まで、半年間隔で計測をしてきたMLOpsScoreの結果を実際に見てみましょう。
全体スコア
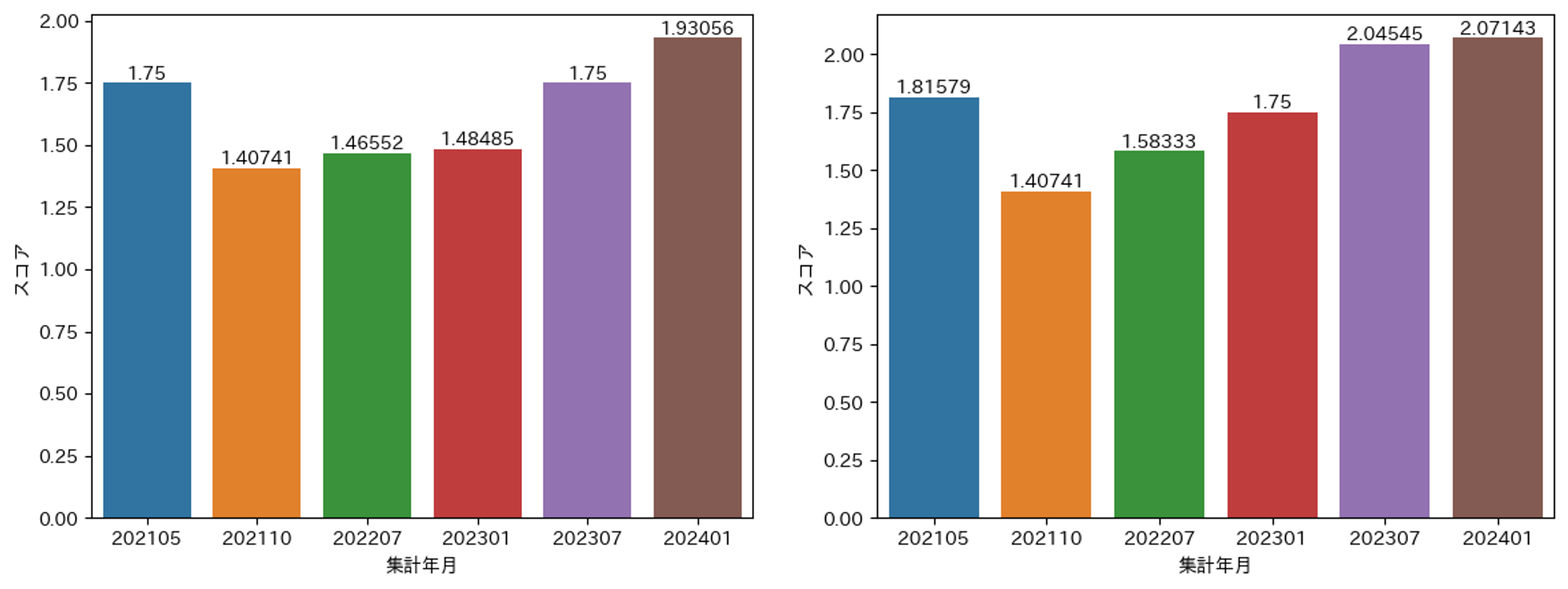
上記は計測回ごとのMLOpsScoreの推移です。左図は、機械学習システムを持つ全プロダクトを対象としたMLOpsScoreの推移です。基本的には右肩上がりとなっていますが、特に2023年あたりから急速にスコアが向上していることがわかります。
右図は計測の初回である202110の計測時から存在する、継続的なMLOpsの改善が行われている見込みのあるプロダクトを抽出したものです。こちらについても基本的なMLOpsScoreの傾向は、全プロダクトと変わらず右肩上がりの傾向になっており、特に最新の結果ではわれわれが1つの目標としていた2.0というスコアを超えることが�できました。
領域別スコア
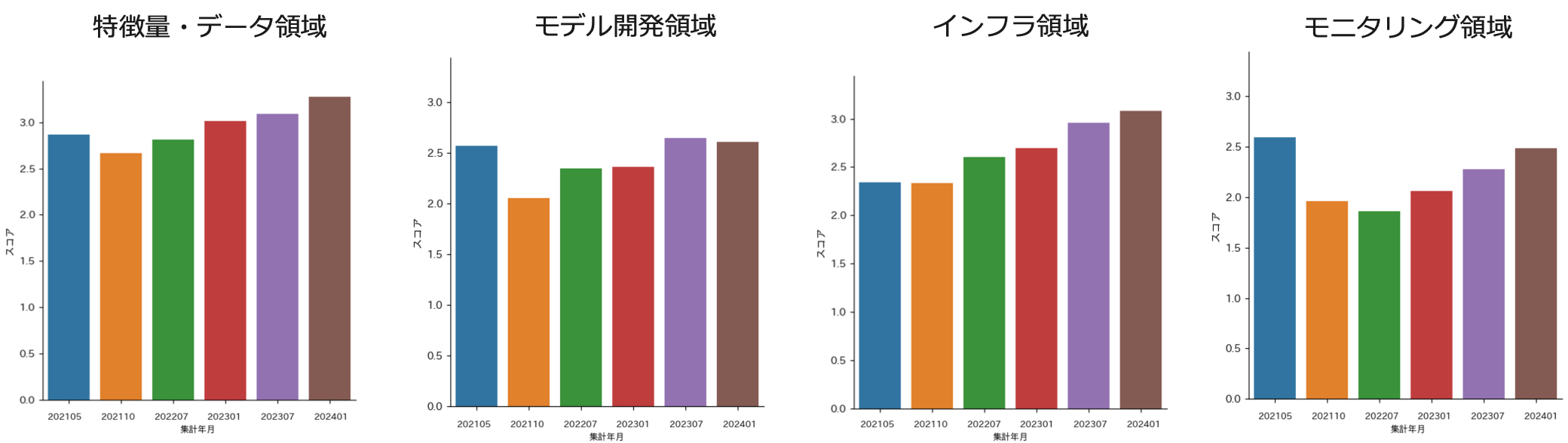
次に、全体スコアを領域別に分解した結果を参照しつつ、全体スコアの成長要因を紐解いていきます。
全体スコア向上に最も貢献しているのがモニタリング領域です。もともとは全領域中で飛び抜けて低いスコアでしたが、成長を続けた結果モデル開発領域と同水準に達しています。MLOpsScoreの計測では最低スコアが最終スコアとして採用されますが、その最低スコアが底上げされたことで全体スコアも伸びたという結果となっています。
モニタリング領域とインフラ領域は前項で示した通り特に力を入れましたが、どちらも右肩上がりとなっており、このことから
- 共通PF提供による導入コスト軽減
- コミュニティ形成によるサポート体制強化
- ガイドライン整備による動機づけ強化
といった一連の取り組みは一定の成果を上げたと言えそうです。
また、データ領域についても上記2者ほどではありませんが成長を続けています。要因については特定が難しいため想像の範囲ではありますが、本活動開始時から現在までの3年間で組織内における機械学習システムに対する理解度は変化しており、その結果として自然に伸びたものと考えられます。
モデル領域についてはいったん成長を見せたものの直近ではほぼ横ばいとなっています。こちらについてはFairnessなどの実現の難しい質問が含まれており、結果としてスコアが伸びない要因になっているのではないかと考えています。
終わりに
今回は過去に投稿したMLOpsScoreに関する取り組みについて、その後スコアの向上のために実施した内容を紹介しました。また、その結果MLOpsScoreが着実に向上していることを確認できました。
今後も引き続き社内のMLOps環境をより良くするための取り組みを進めていきたいと考えています。特にLINEヤフー株式会社として統合したことにより、技術的な連携が可能になったことを活かしていきたいです。
例えば合併前の旧LINE株式会社では、機械学習モデルを効率よく開発するためのプラットフォームやライブラリを継続して開発していました。
(詳細はこちらのプレゼンテーションをご覧ください)
現在こういったプロダクトを旧ヤフー株式会社の環境でも利用できるように整備を進めています。優れたプロダクトを広く活用することで、高品質なMLOps環境を効率的に構築できる世界を実現していきたいと思います。
最後まで読んでくださりありがとうございました!


