LINEヤフー Advent Calendar 2023の25日目の記事です。
こんにちは。AIプラットフォーム部でMLOpsエンジニアや��プロダクトオーナーを担当している古川新です。
この記事では、AIプラットフォームで提供しているデータ品質管理システム「ACP Data Quality」と、その中核機能であるデータ品質モデル言語「DQML」によるデータ品質管理の取り組みについてご紹介します。
データ品質管理システム「ACP Data Quality」
AIプラットフォームでは、「ACP Data Quality」というデータ品質管理システムを提供しています。「ACP」と呼ばれるAIに特化したKubernetes環境で提供されており、利用者はWeb UIまたはKubernetesカスタムリソースを通じて、データ品質管理プロセスを実行できます。
データ品質管理とは
データ品質とは、「データが目的にどのくらい適しているかの度合い」のことです。
国際標準の規格では、以下のように定義されています。
指定された状況で使用するとき、明示されたニーズおよび暗黙のニーズをデータの特性が満足する度合い。
(参考文献1「JIS X 25012:2013 (ISO/IEC 25012:2008) ソフトウェア製品の品質要求および評価(SQuaRE)− データ品質モデル」より引用)
データが目的に適していない場合(たとえばデータにミスがある、データが取得できない状態になっている)、データを消費しているシステムにも影響が出てきます。そのような場合に備えてデータが「良い」か「悪い」かを測るための基準がデータ品質です。
データ品質管理は、データが正確で信頼性があり適切に利用できる状態を維持するために、データ品質を確保・維持するためのプロセスや活動のことです。データ品質管理には、データの収集、保存、整理、分析、利用に関わるさまざまな段階での品質管理が含まれます。一般的にデータ品質管理はデータ品質の計画、制御、保証、改善のプロセスの継続的なサイクルです。
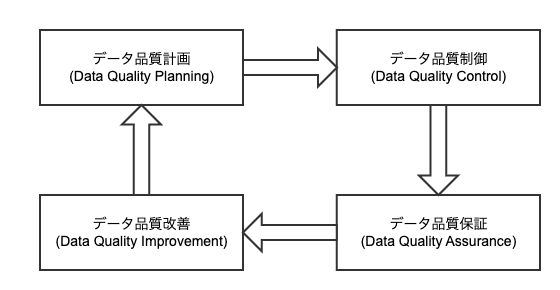
(参考文献2「ISO 8000-61:2016 Data quality — Part 61: Data quality management: Process reference model」を簡略化した図)
データの品質が悪化してデータを消費しているシステムに影響が出ると、ビジネスにもリスクが波及します。サービス品質の管理、およびビジネス上のリスク管理という観点からも、データに強く依存する機械学習などのシステムを正しく運用するために適切なデータの品質管理が不可欠です。
ACP Data Qualityは、これらのデータ品質管理プロセスを包括的に構築し、継続的に実施するためのさまざまな機能を提供しています。
AI活用特有のデータ品質管理の課題
ACP Data Qualityを開発した背景には、AI活用特有の原因に関連するいくつかの課題があります。
- データ品質の管理責任の所在が不明になりがち
- データ品質を定義するのが難しい
- サイエンティストと運用者のコミュニケーションロス
- データ品質を測定するシステムづくりのコストが大きい
1.データ品質の管理責任の所在が不明になりがち
構造的な課題として、データ品質を誰が管理するべきなのかが明確でないという問題があります。一体誰がデータ品質に責任を持ち、管理するのが良いでしょうか。
データ品質とは、「目的にどの程度適しているかの度合い」です。ポイントは、品質は「目的」によって決まるということです。同じデータでも、利用する目的ごとに品質は異なる場合があります。
たとえば、組織内で複数の機械学習モデルが共通のデータを使用することは一般的です。あるモデルは共通データのXという列に強く依存していて、この列が欠損している場合は性能を発揮できないかもしれません。一方で、別のあるモデルはこの列が欠損していても、性能に影響がないかもしれません。このような場合、Xが欠損しているデータの品質が「良い」か「悪い」かは、モデル(目的)によって異なると言えます。
意外かもしれませんが、データの品質を決めるのが目的である以上、データの品質を決めるのはデータの提供者ではなく、データの消費者です。このことからデータ消費者がデータ品質を管理する方が良いということが言えます。
機械学習モデルの開発であれば、データ品質を定義、管理するのはデータを提供しているチームではなく、実際にデータを消費するサイエンティストやそのモデルを運用するエンジニアが管理する方がうまくいくのです。
2.データ品質を定義するのが難しい
いざデータ品質を定義しようと思っても、それが意外と難しいという問題もあります�。
機械学習モデルに使われる特徴量は数百個にもなる場合があります。一般的なシステムで使われるデータに比べて依存するデータが多く、網羅的に管理するのは困難です。手法にもよりますが、どの特徴量が重要であるかを決定するのが難しいことが多いです。重要なデータだけを効率的に管理するのが難しく、どこから手をつければよいかわからない状態に陥りやすいです。
また、ブラックボックスモデルでは、入力データのパターンを網羅的にテストすることが困難です。どういったデータなら正常に動作するのか、データの要求を把握・判断すること自体に高い技術が要求されます。説明可能なモデルにおいても、データの要求の定義には専門性の高い知識が必要となることが多いです。そのため、サイエンティストしかデータの要求がわからないという状態が発生しやすいです。
3.サイエンティストと運用者のコミュニケーションロス
データ品質を定義しても、品質の監視や保証が運用まで一貫して実施されなければ意味がありません。
残念ながら、モデルを開発するサイエンティストと、モデルの運用担当者の間で、データ品質要件がうまく共有されていないことがよくあります。データに問題が起きたとき、運用者はどのデータが異常なのか判断できず、データに起因する事故が発生すると解決にサイエンティストが必要になります。結果として事故の対応が遅れ、損失が大きくなるという事態が起こります。
原因としては、機械学習のような専門性の高さ・領域の違いにより、コミュニケーショ�ンが難しいという問題があります。口頭ベースや文書ベースでのコミュニケーションを行ったところで、専門的なデータのチェックを運用担当者ができないのです。
4.データ品質を測定するシステムづくりのコストが大きい
データ品質を監視・保証するには、システム的にデータを検証するのが一番です。
社内ではこれまでもOSSを活用したデータバリデーションの取り組みが行われています。しかし、各プロジェクトで品質管理のための仕組みを構築する場合、データバリデーション以外にもデータの連携を行ったり、パイプラインを構築したり、リソースを確保したりと、データバリデーション以外にも意外と多くのコストがかかります。また、チーム間でやり方が違うと運用負荷にもつながります。
データ品質モデル言語「DQML」
ACP Data Qualityは、これらのAI活用におけるデータ品質管理を行うための課題を解決するために開発されました。
今回は、ACP Data Qualityの中でも中核を担う機能であるデータ品質モデル言語 DQML(Data Quality Model Language)を紹介します。
DQMLは、データ品質モデルの定義に特化した独自のDSL(Domain Specific Language:ドメイン固有言語) です。ここでデータ品質モデルとは、特定の目的におけるデータ品質要件の集合です。
データ品質は「データが目的にどのくらい適しているかの度合い」であり、これを管理するためにはまず特定の目的下において、データが満たすべき要求を要件として整理する必要があります。
例1:「あるモデルXの学習に使うデータは、有効な学習結果を得るために1000件数のデータがなければならない」という要求があるとします。
| 対象 | データA |
| 目的 | モデルXの学習用データ |
|---|---|
| 要求 | あるモデルXの学習に使うデータAは、有効な学習結果を得るために1,000件以上のデータがなければならない |
この要求を整理すると、たとえば以下のようなデータ品質要件が考えられます。
| 測定関数 | データAの件数 |
| 測定基準 | 1,000件より多くなければならない |
|---|
DQMLでは、このデータ品質要件を以下のように記述できます。
Count must be >1000ACP Data Qualityでは、DQMLを使ったデータ品質モデルをJSONやYAMLで定義できます。
apiVersion: data-quality.yahoo.co.jp/v1alpha1
kind: DataQualityModel
metadata:
name: example-1
spec:
requirements:
- code: Count must be >1000このDataQualityModelは、ACPで利用可能なKubernetesカスタムリソースです。
ACP Data Qualityは、DataQualityEvaluationというリソースが作成されると、DataQualityModelで定義された要件をすべて測定・評価します。
apiVersion: data-quality.yahoo.co.jp/v1alpha1
kind: DataQualityEvaluation
metadata:
generateName: example-1-eval-
spec:
modelRef:
name: example-1DQMLはデータソースに合わせて自動的に適切なエンジンを使った集計に変換されます。たとえばTrino(分散SQLエンジン)のテーブルからデータを取得するように設定した場合、自動的にTrinoクエリを生成・実行し、クエリ結果から測定値が基準に適合しているかを評価します。
結果は自動的に記録され、Slackなどのコミュニケーションツールに通知されます。Web UIからも履歴をグラフで閲覧可能になります。
いくつか他の例もみてみましょう。
例2:「教師データのうち、日本出身のデータに関して、ageが20歳以上80歳未満のデータが80%以上である必要がある」という要求があるとします。
データ品質要件は、以下の通りです。
| 測定関数 | A / B |
| 測定量要素A | 日本出身のうち20歳以上80歳未満のデータ件数 |
|---|---|
| 測定量要素B | 日本出身のデータ件数 |
| 測定基準 | 0.8以上でなければならない |
DQMLでは以下のように記述できます。
Proportion of .age is >=20 & <80 where .from is "Japan" must be >=0.8測定結果には、最終的な測定量A / Bの値、各測定量要素の値(AとB)などが記録されます。
例3:「推論結果のAカテゴリとBカテゴリのscoreの平均値が20以上離れていなければならない」という要求があるとします。
データ品質要件は、以下の通りです。
| 測定関数 | A - B |
| 測定量要素A | Aカテゴリーのscoreの平均値 |
|---|---|
| 測定量要素B | Bカテゴリ�ーのscoreの平均値 |
| 測定基準 | 20以上でなければならない |
DQMLでは以下のように記述できます。
let A = Mean of .score where .category is "A",
let B = Mean of .score where .category is "B",
A - B must be >=20測定結果には、最終的な測定量A - Bの値、各測定量要素の値(AとB)などが記録されます。
DQMLの特徴
Data Quality as Code
データ品質モデルの利点は、コード上で直接データ品質を管理し、品質要件に対するデータセットの整合性を自動的に評価する能力にあります。これにより、データ品質の保証と向上に必要なリソースと労力を削減しながら、信頼性の高いデータを確保できます。
データ品質要件がコード化されることで、バージョン管理システムで管理できるようになり、データ品質の一貫性を保てます。データ品質管理における改善プロセスにおいても、バージョン管理とコードレビューシステムを活用できます。GitOpsなどのテクノロジーを活用することでさらに一貫性を高められます。
モデル駆動
DQMLを使うために、具体的なデータの処理方法を理解する必要はありません。どのように測定されるかを気にすることなく、本質的なデータ品質の管理に集中できます。モデルに特化した言語は、異なるシステムで構築されるチーム間においてもコミュニケーションツールとして利用できます。これはあらゆるステークホルダーがデータ品質の管理に直接関われることを意味しています。
ドメインに特化した情報は、たとえば異なる組織のデータサイエンティストや、異なるプロジェクトのエンジニアが違うフレームワークでシステムを構築している場合でも理解しやすく、要件の漏れや伝達ミスを防ぎ、コミュニケーションロスを減らすことにつながります。
CSVファイルを参照する場合でも、クエリエンジンでテーブルを参照する場合でも、データの件数の測定量はCountで定義できます。利用者はデータ処理のプログラムを書く必要はなく、実際にデータが分散処理エンジンで集計されるのかどうかを意識する必要もありません。SQLやApache Sparkなどのエンジンを使用して同等の集計を行うプログラムと比較したとき、DQMLで書かれたコードは短く、データ品質モデルというセマンティックとコンテキストが明らかであり、保守性に優れています。
ACP Data Qualityの特徴
Serverless
DQMLによる定義に基づき、ACP Data Qualityはマネージドな環境でデータの測定と評価を自動化します。これはサーバーレスな定常監視と評価を可能にし、利用者はデータ品質の定義と維持に必要な作業に集中できます。
Declarative & Sustainable
品質管理プロセスにおいては継続的な定義の管理と改善が重要になります。ACP Data Qualityは、Kubernetesカスタムリソースによってモデルを管理することで、宣言的で継続的な管理とプロセスの自動化を支援しています。
柔軟なシステム連携
Kubernetesカスタムリソースによる評価は、任意のワークフローエンジンと統合可能です。たとえばACPではArgo Workflowsがデフォルトで全ユ��ーザーに提供されており、学習ワークフローの一部としてデータ品質を評価したり、デイリーで定期的にデータ品質の評価を行うなどが簡単にできます。結果に基づいてワークフローを分岐することも可能です。
# Argo Workflowsで定期実行する例
apiVersion: argoproj.io/v1alpha1
kind: CronWorkflow
metadata:
name: daily-eval
spec:
schedule: "@daily"
workflowSpec:
entrypoint: evaluation
templates:
- name: evaluation
resource:
action: create
manifest: |
apiVersion: data-quality.yahoo.co.jp/v1alpha1
kind: DataQualityEvaluation
metadata:
generateName: {{workflow.name}}-
namespace: {{workflow.namespace}}
spec:
modelRef:
name: example-1もちろんこれはArgo Workflowsに限定されるものではなく、Kubenertesのリソースを通してあらゆるシステムにデータ品質の評価を組み込めます。
まとめ
今回は、社内で活用しているデータ品質管理の課題を解決するためのACP Data Qualityおよび中核機能であるDQMLを紹介しました。
AIプラットフォームでは、今後も信頼できる機械学習モデルの運用のため、データ品質管理の取り組みを強化していきます。
最後まで読んでくださり、ありがとうございました。
参考文献
- 1: JIS X 25012:2013 (ISO/IEC 25012:2008) ソフトウェア製品の品質要求及び評価(SQuaRE)− データ品質モデル Software engineering-Software product Quality Requirements and Evaluation (SQuaRE)-Data quality model
- 2: ISO 8000-61:2016 Data quality — Part 61: Data quality management: Process reference model


