LINEヤフー Advent Calendar 2023の2日目の記事です。
こんにちは、LINEヤフー株式会社のManagedValdチームです。
本記事では、OpenAI Embeddings APIと近似近傍ベクトル検索エンジンValdを使って類似文章を検索をする例を紹介したあと、なぜValdのようなベクトル検索エンジンを使う必要があるのか、実際の検証結果と合わせて説明していきます。
はじめに
近年、GPTなどの生成AIの人気が急上昇しており、これらを活用したサービスが増えています。
しかし生成AIは「Hallucination(幻覚)」と呼ばれる最もらしいうそをつくことがあるため、サービスへの採用が難しいという場面が少なくないかと思います。
生成AIはざっくりと説明すると次の2ステップで構成されます。
- 入力された文章などを理解しベクトル化
- 確率の高い次の文章などを生成
Hallucinationは、2番目のステップによって発生します。したがって、1番目のステップで処理を停止し、このベクトルを効果的に活用することで回避できます。
この回避方法として、最近では生成AIとベクトル検索を組み合わせた、Retrieval Augmented Generation(RAG)という手法がよく用いられます。
本記事では、1番目のステップで得られたベクトルを効果的に活用する例として、OpenAI Embeddings APIとValdを使って類似した文章を検索する方法を紹介します。
ベクトルを作るのが難しいことからベクトル検索を諦めていた方も、今回紹介する方法で簡単に使えるようになるかと思います。
文章からベクトルを得る方法
入力された文章を理解しベクトル化する技術は、生成AIが人気になる前から存在する技術ですが、以前はサイエンティストがいないとこのベクトル化は難しいものでした。その後、OpenAIが提供するEmbeddings APIを使うことで、HTTPのリクエストを送るだけで入力文章のベクトルを得られるようになりました。若干難易度は上がりますが、sentence-transformersを使うことでも簡単にベクトルを得ることができます。
入力文章と類似した文章を検索してみよう
ここからは実際にコードを用いて類似文章を検索する方法を説明をしていきます。
今回の検索対象の文章にはどなたでもお試しできるようにlivedoor ニュースコーパスのタイトルを使います。
入力した文章がlivedoor ニュースのどのタイトルに類似しているかを検索する、というシステムを作りたいと仮定し実装していきます。
なお、livedoor ニュースの記事は以下ライセンスに基づき改変せず使用します。
https://creativecommons.org/licenses/by-nd/2.1/jp/
(このようなデータを公開していただいているのは本当にありがたいです)
データの加工
まずlivedoor ニュースのデータを扱いやすいよう1つのファイルにまとめてpandasのDataFrame(以下、df)にします。
wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
tar -xvf ./ldcc-20140209.tar.gzimport glob
import pandas as pd
def clean_text(text):
return "".join(text.split()) # 改行や空白などを削除
def get_contents(path):
with open(path) as f:
lines = f.readlines()
lines = [clean_text(l) for l in lines]
lines = [l for l in lines if l != ""]
_, time, title, *body = lines
body = "".join(body)
return time, title, body
def get_category(path):
return path.split("/")[-2]
data = []
paths = glob.glob("./text/**/[!LICENSE]*.txt")
for path in paths:
time, title, body = get_contents(path)
category = get_category(path)
data.append([category, time, title, body])
df = pd.DataFrame(data, columns=["category", "time", "title", "body"])
df.to_csv("./livedoor-news.csv", index=False)| category | time | title | body | |
|---|---|---|---|---|
| 0 | dokujo-tsushin | 2010-05-22… | 友人代表のスピーチ… | もうすぐジューン・ブライドと呼ばれる6月… |
| 1 | dokujo-tsushin | 2010-05-21… | ネットで断ち切れない… | 携帯電話が普及する以前… |
| 2 | … | … | … | … |
ベクトルの準備
次にタイトル文章をベクトル化していきます。
OpenAIのアカウントを作成し、こちらからAPIキーを取得し、それを環境変数OPENAI_API_KEYに設定した後、次のコードを実行するだけで、入力文章のベクトルを取得できます。
import os
import openai
openai.api_key = os.environ["OPENAI_API_KEY"]
client = openai.OpenAI()
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
get_embedding("入力したい文章")成功したら、検索対象とするために全てのニュースタイトルのベクトルを取得します。
df["title_embedding"] = df["title"].apply(lambda x: get_embedding(x))Valdクラスタの準備
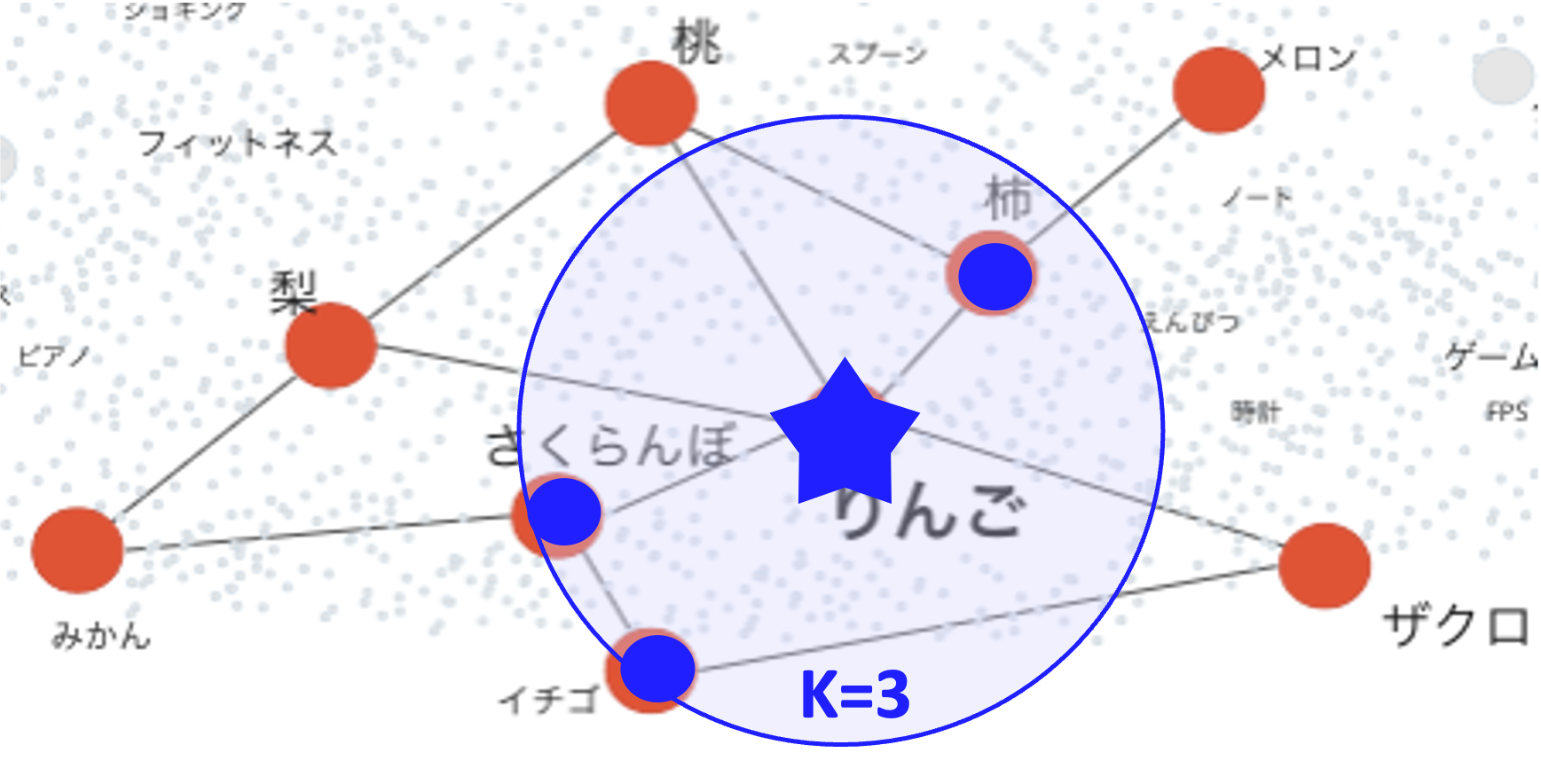
Valdとは、Cloud Native LandscapeやLF AI & Data Landscapeにも掲載されている、非常に高速かつ可用性の高いOSSの近似近傍ベクトル検索エンジンです。すでに格納済みのベクトル群の中から、クエリとして与えたベクトルの近くのk個のベクトルを高速に検索できます。
この図を例にすると、”りんご”のベクトルをクエリとして与えた場合、近傍の”柿”、”さくらんぼ”、”イチゴ”のidとクエリベクトルとの距離が返ってくるイメージです。
こちらの”Vald clusterの構築”を参考に準備を行います。
values.yamlのagent.ngt.dimensionには挿入するベクトルの次元数の1536、agent.ngt.distance_typeには今回はl2を設定してください。
その後、Valdにつなげるか確認していきます。
import numpy as np
import grpc
from vald.v1.payload import payload_pb2
from vald.v1.vald import upsert_pb2_grpc
from vald.v1.vald import search_pb2_grpc
host = "localhost:80"
dimension = 1536
channel = grpc.insecure_channel(host)ベクトルの挿入は以下のように行います。
usstub = upsert_pb2_grpc.UpsertStub(channel)
vec = payload_pb2.Object.Vector(id="0", vector=df["title_embedding"][0])
uscfg = payload_pb2.Upsert.Config(skip_strict_exist_check=True)
usstub.Upsert(payload_pb2.Upsert.Request(vector=vec, config=uscfg))このような表示が出たら成功です。
name: "vald-agent-ngt-0"
uuid: "0"
ips: "127.0.0.1"挿入したベクトルが検索できるかも試してみます。データ挿入後、Vald側でのindex作成が終わらないと検索結果に反映されないので、数分待ってから実行してください。
sstub = search_pb2_grpc.SearchStub(channel)
svec = np.array([0.01] * dimension, dtype="float32") # クエリ用のテストベクトル
scfg = payload_pb2.Search.Config(num=10, radius=-1.0, epsilon=0.01, timeout=3000000000)
sstub.Search(payload_pb2.Search.Request(vector=svec, config=scfg))結果に格納されているdistanceは、クエリのベクトルと検索結果のベクトルとの距離を示しています。この距離が小さいほど、意味が近いことを示しています。
results {
id: "0"
distance: 1.08456945
}検索結果
ニュースの全タイトルベクトルを挿入して検索対象とした後、任意のクエリ文章を使って類似したニュースタイトルを検索してみます。
ニュースの全タイトルをValdに挿入
from tqdm import tqdm
for row in tqdm(df.itertuples(), total=len(df)):
vec = payload_pb2.Object.Vector(id=str(row.Index), vector=row.title_embedding)
uscfg = payload_pb2.Upsert.Config(skip_strict_exist_check=True)
usstub.Upsert(payload_pb2.Upsert.Request(vector=vec, config=uscfg))
text = "携帯の使い方が難しい"
display_results_top_k(text, model, k=3)任意のクエリに類似したニュースタイトルを検索
def get_search_response(text, model, k):
qvec = get_embedding(text, model)
scfg = payload_pb2.Search.Config(
num=k, radius=-1.0, epsilon=0.01, timeout=3000000000
)
return sstub.Search(payload_pb2.Search.Request(vector=qvec, config=scfg))
def display_results_top_k(text, model, k):
response = get_search_response(text, model, k=k)
for result in response.results:
rtitle = df["title"][int(result.id)]
rdistance = result.distance
print(f"title: {rtitle}, distance: {rdistance}")
text = "携帯の使い方が難しい"
display_results_top_k(text, model, k=3)クエリ文章: 携帯の使い方が難しい
title: 携帯の英字入力で「たかはし」と打つと「GAME」になる, distance: 0.5004885196685791
title: やっぱり使いにくい!スマホからガラケーに戻す人が多いらしい!?【話題】, distance: 0.5063361525535583
title: スマートフォンを使う上での最低限のマナーとは, distance: 0.51236987113952641番の結果では、”携帯の英字入力で「たかはし」と打つと「GAME」になる”というテキストが示されており、パッと見でわかるネガティブな単語に反応したのではなく、文章全体の意味を考慮して “携帯の使い方が難しい” という文の類似文章と判断していることがわかります。
なおsentence-transformersで多言語モデルparaphrase-multilingual-mpnet-base-v2を使った時の結果は、下記のようになりました。こちらだと、単純にネガティブな単語に反応しているように見えるので、深い意味を理解する力はOpenAI Embeddings APIの方が高そうです。
title: やっぱり使いにくい!スマホからガラケーに戻す人が多いらしい!?【話題】, distance: 1.1814465522766113
title: 通話機能にしか使わないなら無駄なスマートフォ��ン【デジ通】, distance: 1.4821256399154663
title: 何をしたらいいのかわからない!スマホのセキュリティ対策をしない理由【話題】, distance: 1.5818582773208618なぜベクトル検索エンジンを使うのか
中には、アプリケーション内でベクトルの距離計算をすれば、ベクトル検索エンジンは不要かもしれないという意見もあるかと思います。
正確な計算結果が必要な場合や、検索対象のデータ数が少ない場合はそれでも良いのですが、データ数が増えるとベクトル検索エンジンを使う利点が大きくなります。
実際の検証結果を元に説明します。
精度と速度に関連するValdのパラメータは、agent.ngt.creation_edge_size=20、agent.ngt.search_edge_size=40を設定しています。
また高速化のため、OpenAI Embeddings APIではなくsentence-transformersで得られたベクトルを使いました。これにより次元数が768に変わっています。
精度
Valdは近似近傍ベクトル検索エンジンなので、ベクトル距離の計算結果には若干の誤差があります。
しかし、設定やベクトル分布にもよりますが、結果の順序が大きく変わるほどの誤差が出ることは少ないです。
実際にnumpyを使った、近似ではない正確な計算結果と比較してみます。
def get_indexes_top_k_with_numpy(insert_features, query_feature, k):
distances = np.linalg.norm(query_feature - insert_features, axis=1) # distance_type=L2と等価
distance_indexes = np.argsort(distances)[:k]
return distance_indexesベクトル間の距離を示すdistanceの結果は以下の通りです。
| Vald | numpy | |
|---|---|---|
| 携帯の英字入力で… | 0.5004885196685791 | 0.5004885569201721 |
| やっぱり使いにくい!… | 0.5063361525535583 | 0.5063361694492042 |
| スマートフォンを使う上での… | 0.5123698711395264 | 0.5123698822775186 |
小数点第7位までは同じ値となりました。
速度
検索対象となるデータ数を変えて、検索した時の速度をnumpyを使った場合と比較してみます。
Valdの結果は、リモートのValdクラスタを使ったためネットワークレイテンシを含んでいます。また、1回目はコネクション確立の時間が含まれるため、実際の状況に近い2回目の速度を計測しています。1回目と2回目で検索するベクトルは変えています。
結果は以下の通りです。各項目は3回の平均値で、単位はすべてミリ秒 (ms) です。
| データ数 | Vald | numpy |
|---|---|---|
| 1万 | 107 | 19 |
| 10万 | 107 | 183 |
| 97万 | 105 | 2380 |
Valdはデータ数が増えてもほとんど検索速度は変わりませんが、numpyを使った場合は線形増加していることがわかるかと思います。
データ数が10万件以上の場合は、ネットワークレイテンシを加味した上でもValdの方が高速で、データ数が増えるほどその差が顕著になりました。
実際に社内で運用しているManagedValdでは、検索対象のデータ数が1000万を超えているクラスタでも、検索速度の99%ile値は200ms以下となっています。
おわりに
本記事はいかがでしたか。少しでも皆様のお役に立てる内容があれば幸い��です。
Valdはこれからも精力的に開発を続けていきますので、皆様のご利用やフィードバックを心からお待ちしております。
最後まで読んでいただきありがとうございました。


