はじめに
こんにちは、筑波大学大学院情報理工学位プログラム修士1年の齊藤啓太と申します。私は2023年夏にLINE株式会社(現LINEヤフー株式会社)の就業型インターンシ�ップに参加し、MLのプライバシー等を扱っているMachine Learning Privacy & Trustチームにて大規模言語モデル(Large Language Model, LLM)の研究をしました。具体的には、LLMの自動評価時のバイアス、特に冗長バイアスについて調査をしていました。本記事ではその内容について書いていきたいと思います。
本研究は、NeurIPS 2023 併設のワークショップである Workshop on Instruction Tuning and Instruction Following に採択され発表予定です。すでに arXiv にてプレプリントを公開しておりますので、詳細についてご興味のある方はご覧いただけると幸いです。
- Saito, K., Wachi, A., Wataoka, K., & Akimoto, Y. (2023). Verbosity Bias in Preference Labeling by Large Language Models. Link: https://arxiv.org/abs/2310.10076
背景
自然言語処理の分野でLLMは革新的な成果を次々生み出しており、多くの企業でアプリケーションへの応用が進んでいます。チャットボットや検索エンジン、文章要約等の従来の用途に留まらず、ビジネスアプリ等にも組み込まれ始めており、我々の生活に密接に結びついたものになることが予想されます。
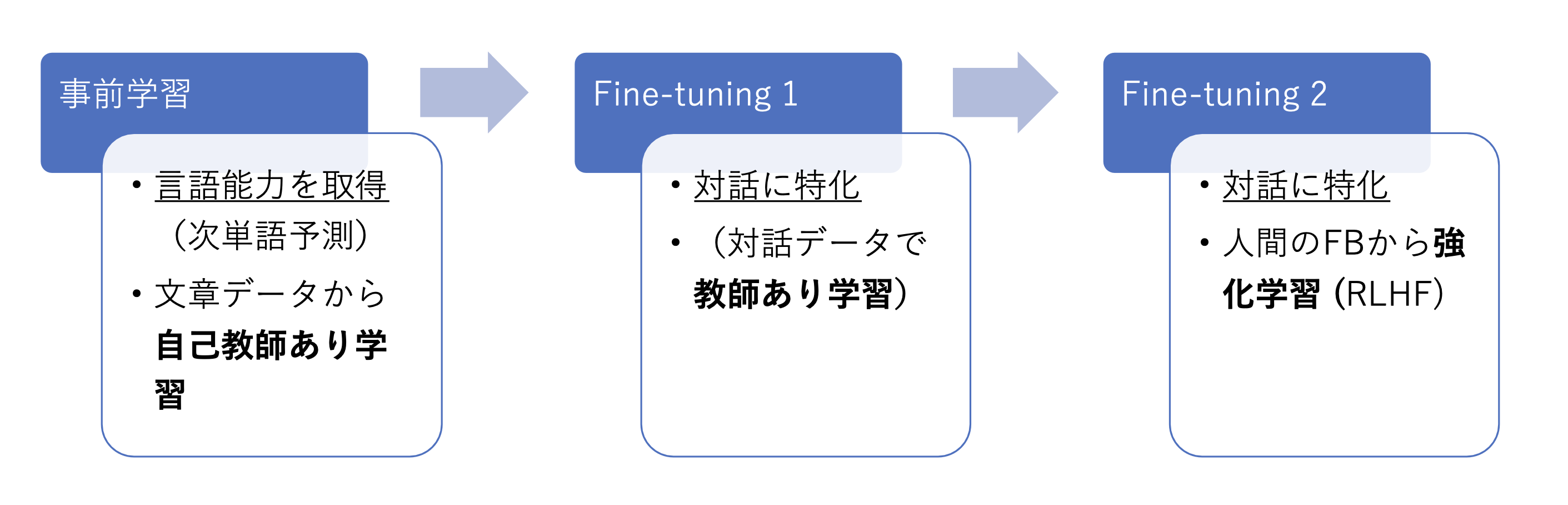
様々なタスクへの応用がされているLLMですが、複数の機械学習手法を組み合わせており、大きく分けて2段階の学習をしています。
まず、第一段階として言語能力を取得してある程度自然言語が話せるようにします。ランダムな出力をする、ランダムなネットワークパラメータを持つ状態から、教師データをもとに次単語予測の精度をあげる形で自己教師あり学習をしていきます。この段階である程度意味の通る文章を生成できるようになっています。
これで一旦言葉を話せるようにはなったので、次にLLMをどのようなタスクに使いたいかに応じてfine-tuning(調整)していきます。今回に関しては対話型のLLMを扱うため、ユーザの投げかけに対して適切な返答をするというタスクをできるようにfine-tuningしていきます。こちらに関しては、2つの方法があります。
1つ目は、エキスパート(見本)データがある場合に、それを真似するように教師あり学習するケースです。この方法はChatGPTなどで使われており、特にVicuna [1]というモデルに関してはこれだけで良い性能を発揮できています。ただエキスパートデータがある場合が少なかったり、データの作成にコストがかかるのが難点です。
2つ目は、人間のフィードバックをもとに強化学習をする方法(RLHF: Reinforcement Learning from Human Feedback) です。RLHFではLLMが生成した文章に対して人間が評価し、この評価の情報をもとに強化学習をします。こちらは一つ目の方法のエキスパートデータがなかったり、さらにfine-tuningしていきたい場合に使われます(ChatGPTは両方使用しています)。RLHFに関しては詳しく後述しますが、人間のフィードバックは人件費が高かったり、社会的に問題がある雇用がされている等の問題が指摘されています[2]。
2つ目の手法の課題に対し、フィードバックを人間の代わりに他のLLMにさせる手法(RLAIF: Reinforcement Learning from AI Feedback)[3][4]が提案されています。LLMにフィードバックをさせればコストも削減できるし不当な雇用も起きません。
といっても、もちろんLLMにフィードバックをさせることに困難さはあります。自明に答えが存在する数学の問題などはともかく、「物語を生成して」や「ブログを書いて」と言った質問への答えの評価は難しく、バイアスが生じたりします。ここでバイアスの一つに、冗長バイアスと呼ばれる「LLMは長い文章を好みがち」なバイアスがあります。今回のインターンではこの冗長バイアスについて調査し、
- 人間とLLMで、文章の長さに受ける影響の差の実験的確認
- 冗長バイアスの定量化
の二点を行いました。
RLHF/RLAIF
本研究はRLAIFの分野の研究なので、まずRLAIFの元となったRLHFの説明になります。RLHFの手順は以下のようになっています。
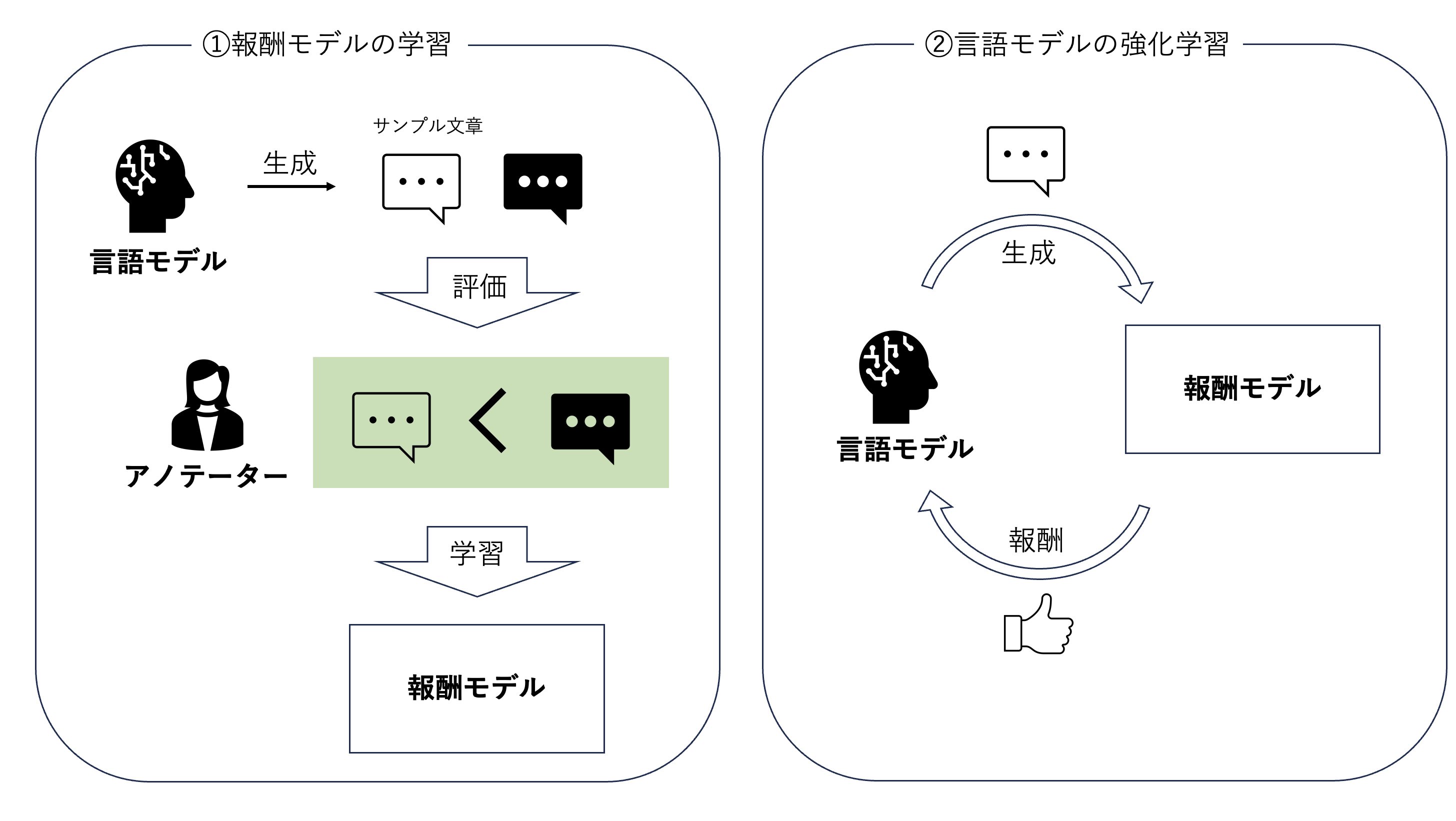
人間のフィードバックによる強化学習と言っても、直接LLMの生成文章(行動)を人間が評価するわけではありません。強化学習でいうActor-Criticモデルのように、人間の好みを近似する報酬モデルを挟んでいます。(報酬モデル:生成文章を入力にとりその評価値(数値)を出力する)
まず①で、生成文章を人間が評価したフィードバックのデータセットをもとに、報酬モデルが人間の好みと合致するような数値を出力するよう学習します。人間が文章1の方が文章2より良いというフィードバックをした場合に、報酬モデルによる文章1の評価�値が文章2の評価値に比べ大きくなるよう調整するということをしています。
その次の②では、学習した報酬モデルをもとに、より良い文章を生成するようにLLMを強化学習しています。LLMが文章を生成し、それに対して①で学習した報酬モデルで計算される報酬を最大化するようにLLMを調整します。
ここで問題となるのが、報酬モデルの学習に多くの人間のフィードバックが必要となり、その分コストがかかる点です。そこで人間の代わりにLLMを使ってフィードバックを得よう、というのがRLAIFになります。RLAIFでは図のアノテーターが人間の代わりにLLMに入れ替わる形になります。
実際にLLMに生成文章の評価をさせるときは、以下のようにテンプレートに生成文章を当てはめて評価させます。返答も特定のフォーマットにさせることで必要な部分の抽出も簡単になります

(数値を出力させる場合はそのような指示をします)
バイアスの種類
フィードバックをLLMにさせることで安価に学習ができるわけですが、LLMが文章の評価をする際、様々なバイアスが生じてきます[5]。
- 位置バイアス:二つ文章を比較評価させるような場合、一つ目の文章を好みがち。位置を入れ替えて2回評価することで対処可能。
- 冗長バイアス:長い文章を好みがち。
- 自己推進バイアス:評価するモデルと同じモデルが生成した文章を好みがち。当てはまる問題設定が限られる。
中でも冗長バイアスについては、放��っておいてはLLMが不必要に長い文章を生成するようになってしまうにも関わらず、十分に調査がされていません。よって本研究ではこの冗長バイアスについての調査・実験をしています。
人間に比べLLMは文章の長さに影響を受けやすいのか?
そもそもこの研究の背景には「RLHFの人間のフィードバックをRLAIFでLLMのフィードバックに置き換えたい」というモチベーションがあったため、LLMに人間と似た評価をさせることが目的になっています。なので、LLM自体に評価のバイアスがあっても、それが人間の評価にも見られるようなバイアスであれば本研究の文脈であれば問題ない、ということになります。
よって次の実験ではLLMと人間で、文章の長さによる判断への影響に差があるのか、を確認します。
実験設定
生成文章の組を人間に比較させているデータセット(hh-rlhfデータセット[6])があるのでそれを用います。このデータセットに含まれる文章の組みについて、それぞれ人間がどちらを好んだかがわかります。同じ組に対してLLMに文章を選ばせ、人間との判断の一致率を見ます。
実験結果
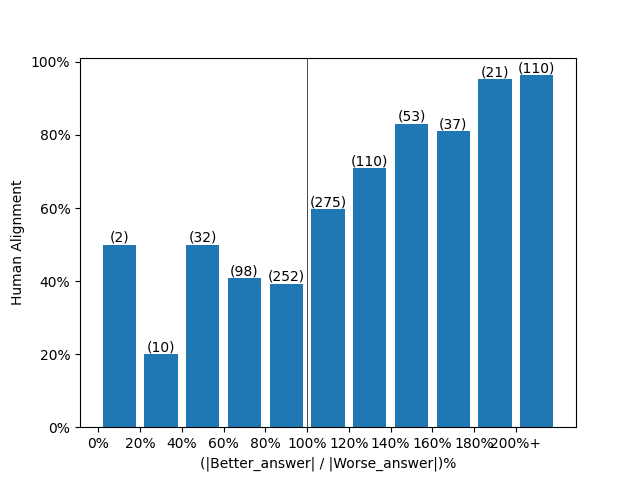
実験結果から文章の組のうち人間の選んだ文章の方が単語数が多いと人間とLLMの判断の一致率が高いことが分かります。逆に、単語数が少ない方を人間が選んでいる時、LLMと人間の判断の一致率が低くなっています。
つまり人�間が内容を見て単語数が少ない方を選んでいる時も、LLMは単語数が大きい方を選んでしまっており、単語数の大小と人間とLLMの判断一致率に相関が見られます。
理想としては単語数の大小に関わらず人間との判断の一致率が高くあってほしいところ、単語数の大小によってバイアスが生じてしまっていることがわかります。
冗長バイアスの定量化
実験ではバイアスをグラフで確認しましたが、モデル間で冗長バイアスの度合いの比較をする際にバイアスを定量化して比較できると便利なので、冗長バイアスの定量化を考えます。
参考になりそうな指標として、機械学習でバイアスを扱う時の指標にequal opportunityがあります。これはある予測モデルが予測をする際、センシティブ属性ごとに正解率が等しいかを測る指標になります。
例えばある人物が将来犯罪を犯しそうかを予想するモデルであれば、センシティブ属性である人種や性別によって正解率が等しくあってほしい、ということを表した指標になります。
公平性の文脈では、正解ラベルをY、予測ラベルをY'、センシティブ属性をSとして以下の式を満たす時にequal opportunityを満たすと定義されています。
(ここではtrue positive rateではなくfalse positive rateを使用しています。)
この式は、正解ラベルがY=0の時、予測がY'=1となるfalse positive rateがセンシティブ属性によらず等しいことを意味しています。当然両辺が等しくなることはほとんどないため、equal opportunityの度合いを以下の式で表現します。
この式が0に等しければequal opportunityが満たされていて、大きい値であるほどセンシティブ属性についてのバイアスがあるということになります。
実際に今回扱っている冗長バイアスをこの指標に当てはめていきます。センシティブ属性Sの定義を
正解・予測ラベルは
とします。
つまり、
- は一つ目の文章の方が短い文章、かつ人間が一つ目の文章を選ぶ時、LLMが間違えて二つ目の文章の方がいいと判断してしまう確率
- は二つ目の文章の方が短い文章、かつ人間が一つ目の文章を選ぶ時、LLMが間違えて二つ目の文章の方がいいと判断してしまう確率
であり、これらの差が小さければ単語数の大小によるバイアスがない、と言えます。逆に第二項が大きく差が大きいと、LLMは単語数の大小に引っ張られて間違った判断をしてしまっていることになります。
この指標をGPT-3.5とGPT-4で実際に測ってみた結果が以下になります。
| EO_value | |
|---|---|
| GPT-4 | 0.328 |
| GPT-3.5 | 0.428 |
冗長バイアスがGPT-4で多少改善されているようですが、依然バイアスがないとは言えません。
このようにモデルの冗長バイアスについての定量的評価が可能になります。
最後に
冗長バイアスは一般的に「長い文章をLLMは好みがち」とされていますが、人間と比べてその傾向が強いかどうかについて実験を行いました。その結果、二つの文章の比較評価の際単語数の大小と人間との判断一致率に相関が生まれてしまっている、ということを確認しました。最後にこのバイアスの定量化も行い、GPT-3.5とGPT-4冗長バイアスの定量評価を行いました。
インターンを振り返って
インターンの六週間を通して、普段の大学での研究とは違って社会実装との距離が近い環境で様々な知見を得ることができました。研究の分野に関し��ても、今後重要になってくる技術にインターンシップでの研究の形で触れることができたのも大変貴重な経験になりました。
最後になりますが、メンターの和地さんには毎日のMTGなど色々とサポートしていただき大変お世話になりました。ありがとうございました。
また、マネージャーの竹之内さん、議論していただいた綿岡さん、並びに多くのフィードバックを下さったPrivacy & Trust チームの方々に感謝を申し上げます。
1 Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality: https://lmsys.org/blog/2023-03-30-vicuna/
2 Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic: https://time.com/6247678/openai-chatgpt-kenya-workers/
3 Lee, Harrison, et al. "RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback." arXiv preprint arXiv:2309.00267 (2023).
4 Bai, Yuntao, et al. "Constitutional ai: Harmlessness from ai feedback." arXiv preprint arXiv:2212.08073 (2022).
5 Zheng, Lianmin, et al. "Judging LLM-as-a-judge with MT-Bench and Chatbot Arena." arXiv preprint arXiv:2306.05685 (2023).
6 Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022).


