This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Introduction
Hello. We are Hirayama, Numata, Ogasawara, and Ogawa, responsible for operating large-scale data platforms at LY Corporation.
At LY Corporation, we operate a large-scale data platform that supports a wide range of services such as search/portal, e-commerce, messenger, and advertising. The core of this platform, Hadoop distributed file system (HDFS), exceeds a total capacity of 1 exabyte (EB) when combining the major clusters from the former LINE Corporation and the former Yahoo Japan Corporation.
While operating HDFS at this scale, we have faced two major types of challenges.
The first is the operational challenges of running a large-scale data platform centered on HDFS. We summarize how we addressed scaling constraints and operational bottlenecks caused by data growth, and how configurations and usage patterns developed in the process.
The second is the interconnection of data platforms resulting from organizational integration. This is the challenge of how to connect data platforms built with different design philosophies and enable mutual data utilization.
These may appear to be separate issues at first glance. However, both are stories of how we accumulated designs and responses capable of withstanding production operation while taking into account the different origins, architectures, and usage patterns of the former LINE Corporation and the former Yahoo Japan Corporation.
In scaling-related operational challenges, these differences showed up as issues such as capacity management, NameNode load, and network impact. In integration-related collaboration, they appeared as challenges in designing connection endpoints, units of access control, and data transfer routes.
In the first half of this article, we introduce the configurations, usage patterns, and operational challenges of the large-scale data platforms of the former LINE Corporation and the former Yahoo Japan Corporation. In the second half, we explain how the two platforms were connected.
The table of contents is as follows.
- Part 1. HDFS platform architectures, usage patterns, and operational challenges in the former LINE Corporation and the former Yahoo Japan Corporation
- Part 2. Cross-platform data platform integration during organizational consolidation
- Outlook
Part 1. HDFS platform architectures, usage patterns, and operational challenges in former LINE Corporation and former Yahoo Japan Corporation
In this part, we first organize the differences in usage and operational models of the HDFS platforms in the former LINE Corporation and the former Yahoo Japan Corporation, and examine the HDFS configuration differences behind them. We then introduce the challenges actually faced in large-scale operations and how we addressed them.
1.1. Differences in usage and operational models
The former LINE Corporation and the former Yahoo Japan Corporation had different histories operating Apache Hadoop and provided different ranges of services. As a result, significant differences arose between the clusters they operated in terms of overall platform design philosophy and use cases, including data access, access control, and operational practices.
At the former LINE Corporation, multiple large-scale analytics environments were operated for a long time, and the environment currently in use was built in the Hadoop 3.x era to integrate them. The mission from the start was to support diverse cross-departmental data utilization needs and enable a smooth migration to the new environment.
Unifying many isolated datasets into a single platform: The path to building a data analytics platform (Available in Japanese only)
Therefore, instead of having users directly handle HDFS permissions or Apache Ranger, a web portal for managing permissions and the data catalog was developed. This allows users to safely utilize data through a role-based mechanism centered on DB/Table management units, enabling integrated permission requests and approvals without interacting with Hadoop internals. At the same time, various systems such as BI/reporting tools and ETL batch pipelines were put in place to support diverse usage. However, because they needed to support many different use cases and integrated existing clusters by importing namespaces as-is, cluster management complexity remained an operational challenge.
At the former Yahoo Japan Corporation, analytics platform construction and usage began from large-scale analysis for a limited purpose during the Hadoop 0.2 era. Over time, by accepting new use cases and consolidating and migrating individually operated Hadoop clusters, the platform evolved into a broadly used company-wide foundation and was organized into a configuration that is easier to operate stably.
The interface for users to access the Hadoop environment has been streamlined to the minimum necessary. While access methods impose certain constraints, narrowing the entry points makes it easier to provide stable system operation and user support.
However, the former Yahoo Japan Corporation historically operated a single HDFS namespace for a long time, and its scale increased. As a result, NameNode scaling became an issue, and they later introduced Router-based Federation (RBF) to move to a configuration that can handle divided namespaces. Regarding access control, they still use HDFS permissions (POSIX-like access control) due to historical reasons. This creates a gap with the flexible access control demanded by modern data management, becoming one of the constraints.
These differences also affected day-to-day operations. In the former LINE Corporation, it was necessary to design operations while always considering user flows and permission request mechanisms including systems not directly managed by the Hadoop operations team. In contrast, the former Yahoo Japan Corporation's design makes it easier to manage around storage locations and permission settings. Even when using the same HDFS, the way you organize considerations—such as where to store data, who handles it, how to structure permissions, and who and what are affected by changes in settings or policy—differs.
Below, we outline the differences in usage and operational models between the two environments. The former LINE Corporation and former Yahoo Japan Corporation differ in platform origins, user flows, access control, and the scope of impact when changes occur.
| Aspect | Former LINE Corporation | Former Yahoo Japan Corporation |
|---|---|---|
| Development history | Built as a platform to integrate multiple analytics environments | Evolved from large-scale analysis for limited purposes to a company-wide platform |
| User flow | Provides multiple entry points such as portals, data catalogs, BI, and ETL | Narrows access paths and standardizes usage and support |
| Access control | Role-based request and approval flows so users do not need to be aware of HDFS internals | Managed based on HDFS permissions |
| Unit of access control | DB/Table | HDFS Path |
| Namespace structure | Integrated by importing namespaces from existing environments | Transitioned from a single namespace to a split configuration using RBF |
| Considerations when changing | Need to check impact on user flows and integrated systems | Easier to organize the scope of impact on the platform side |
1.2. Differences in HDFS configurations
Both the former LINE Corporation and the former Yahoo Japan Corporation have operated Hadoop clusters for many years, but there are many differences in their development histories and design philosophies. A particularly large technical difference is how namespaces are handled in HDFS clusters.
By design, HDFS tends to have the NameNode—responsible for managing filesystem metadata—become a bottleneck as scale increases. Therefore, both the former LINE Corporation and the former Yahoo Japan Corporation adopted configurations that split namespaces into multiple units for scaling. In other words, both environments share the characteristic that storage is divided into multiple namespaces, and the NameNodes that manage each namespace are redundantly configured with 2–4 nodes.
Because data is stored across multiple namespaces, when accessing HDFS it is necessary to determine which namespace holds the target data and which NameNode to connect to. In addition, one must decide how to place and share the DataNodes that actually store the data. How to tie together multiple namespaces, configure redundancy, and determine the unit of DataNode allocation are major differences between the former LINE Corporation and the former Yahoo Japan Corporation.
The former LINE Corporation uses ViewFS, adopting a client-side configuration for handling multiple namespaces. In this approach, client-side mount tables are used by applications to rewrite actual paths, determine the namespace, and access the appropriate NameNode based on those settings. This is simple and flexible, but requires maintaining consistency of client-side configurations across many internal services and user environments, which is an important operational consideration.
The former LINE Corporation's cluster shares DataNodes across all namespaces. This configuration improves resource efficiency and makes scaling design easier, but it also increases cluster configuration complexity and operational overhead. Additionally, because the cluster was built while integrating multiple internal analytics platforms, differing NameNode and DataNode software versions coexist within the large cluster, further complicating the situation.
On the other hand, the former Yahoo Japan Corporation adopted a server-side approach using Router-based Federation (RBF) to aggregate multiple namespaces. In this setup, users access the Router, which forwards requests to the appropriate NameNode. While this makes handling multiple HDFS instances more transparent, it makes the availability and scaling design of the Router layer itself an important concern.
Moreover, the NameNode configuration includes Observer NameNodes to distribute read load. For details on RBF adoption, see the Yahoo! JAPAN Tech Blog article.
Upgrading HDFS to a major version and introducing Router-based Federation in production
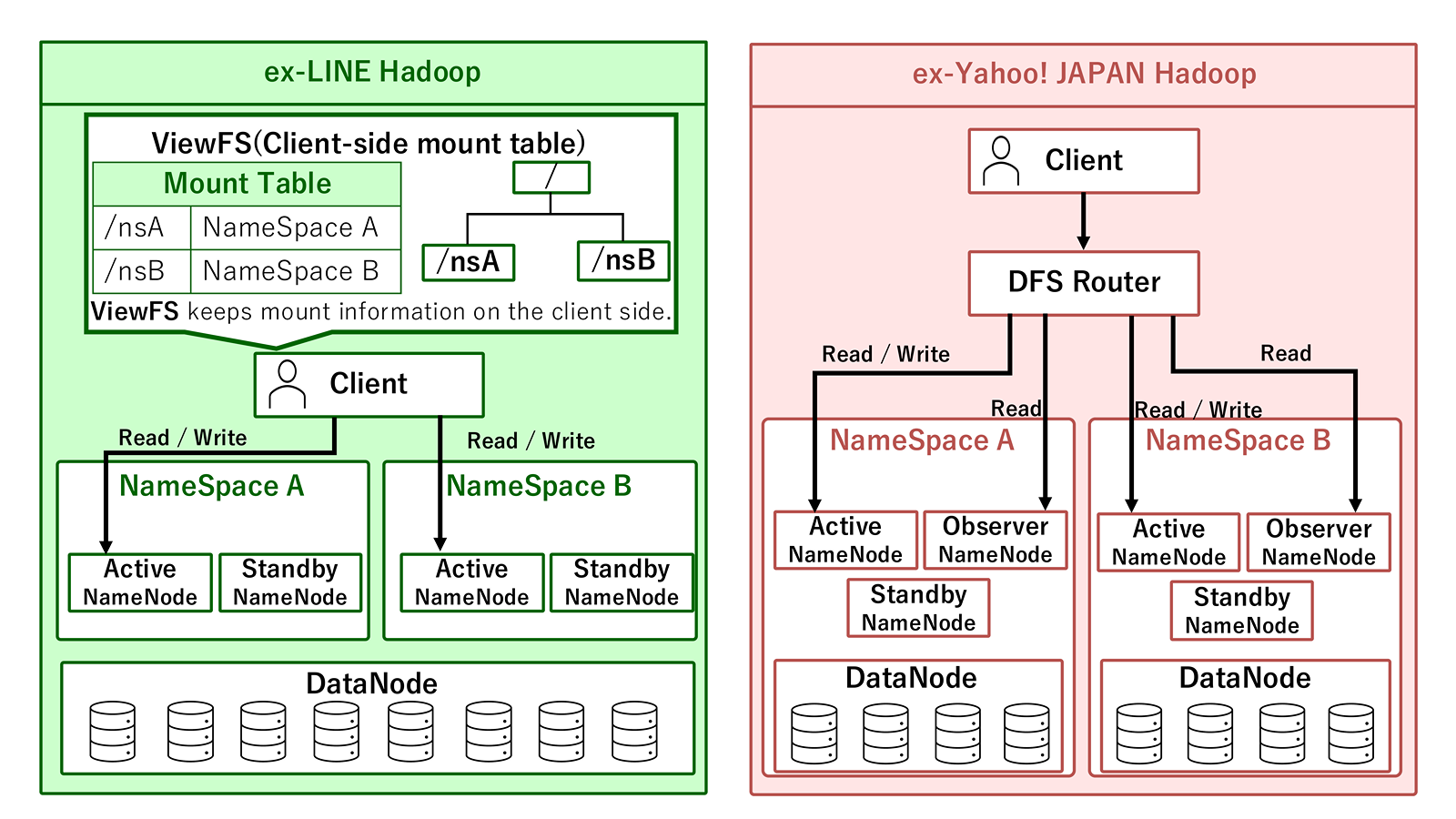
These differences are not limited to internal HDFS configuration. For cross-platform integration discussed later, it is important to determine which platform to access, from which entry point, and as which client configuration.
When namespaces are aggregated on the client side with ViewFS as in the former LINE Corporation, if the client-side mount tables are not distributed correctly, the expected namespace may not be reached. Conversely, when multiple namespaces are aggregated with RBF as in the former Yahoo Japan Corporation, users and jobs access through the Router, so the Router layer's availability, scalability, network reachability, and entry controls become important.
These differences affect cross-platform integration using DistCP covered in Part 2, as well as the design of connection routes, permissions, and operational flows.
1.3. Challenges encountered in large-scale operations
Operating such large and complex HDFS platforms presented a variety of challenges.
Here we describe the approaches used by the former LINE Corporation and the former Yahoo Japan Corporation to address the specific issues they encountered.
[Former LINE Corporation] various challenges encountered as HDFS scaled with growth
The former LINE Corporation's Hadoop cluster was built by integrating two existing Hadoop clusters to enable company-wide data utilization. Because existing clusters were incorporated as-is rather than being built from scratch, there was no sudden early-stage growth like a greenfield rollout. However, as the platform was widely rolled out across the company, usage exceeded forecasts from the start of operations, and responses to various resource shortages occurred at different times.
The first challenge in the initial phase was the rapid exhaustion of HDFS capacity. Although new servers were provisioned based on demand forecasts, data growth exceeded expectations and raised the risk that HDFS capacity could be exhausted before new servers arrived. As a result, older servers were temporarily reused and later replaced with new ones, leading to frequent server additions and removals.
Because the cluster was large, sudden increases or decreases in the number of nodes—such as adding new servers or removing temporarily added servers at once—triggered large amounts of traffic from block rebalancing and the HDFS Balancer. Network congestion could occur, so especially during the early operation period, it was necessary to coordinate with the network team and consider network topology while performing these operations.
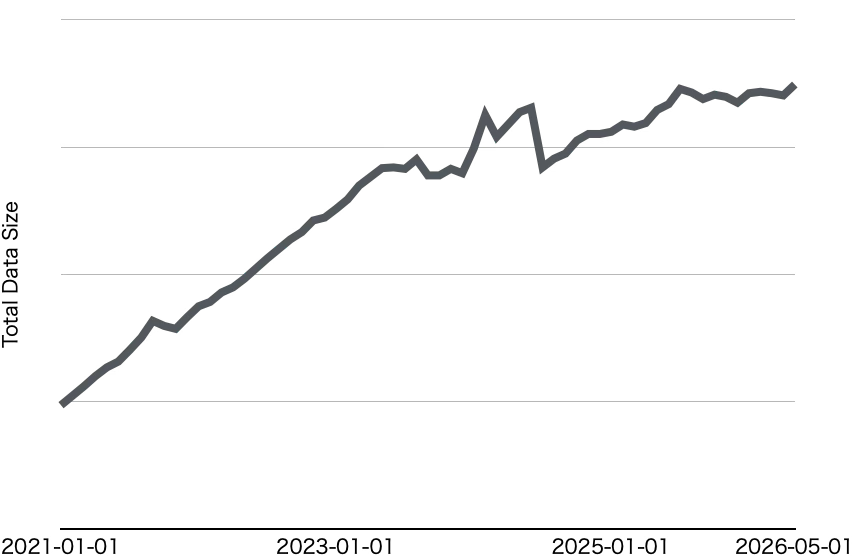
After capacity issues subsided, the next problem was the increase in NameNode heap usage due to the growing number of HDFS blocks. The NameNode manages metadata such as files, directories, and blocks for the entire namespace in memory. Therefore, an increase in file count and block count leads to higher heap usage and processing load on the NameNode. In addition to hardware memory limits per server, larger heaps increase garbage collection times, causing the NameNode to become slower and less stable.
To address this, we identified tables holding a large number of blocks and worked with users to reduce them. We periodically dump HDFS' FSImage and store it as a Hive table, so analysis of this data shows which users hold how many files, blocks, and how much data at which paths. From these targets, we focused on tables containing many small files where simply merging files could dramatically reduce block counts. This enabled relatively simple actions that did not require decisions about data deletion, partition design, or schema changes, allowing for rapid mitigation.
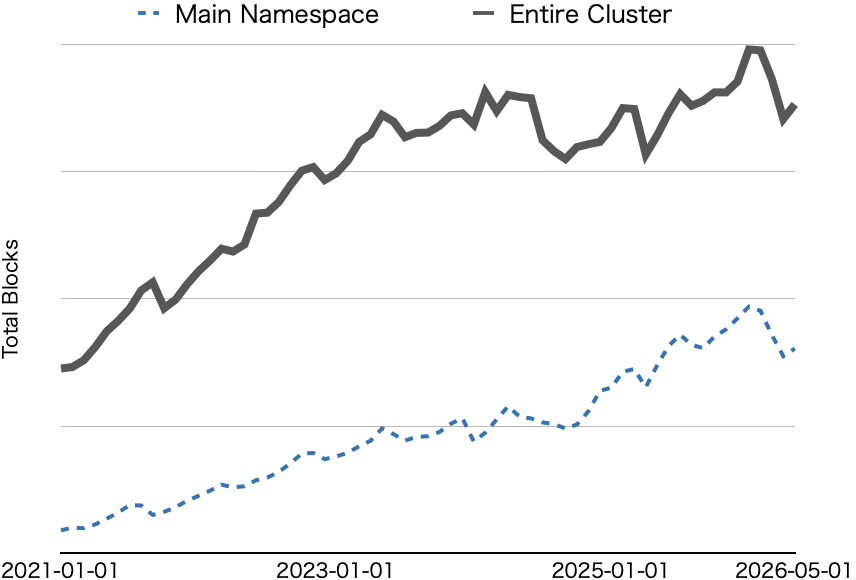
Overall increasing, but growth is restrained by periodic reductions
In addition to increased NameNode heap usage due to block growth, NameNode response time degradation was often problematic. In namespaces where most table data on HDFS is stored, constant high read/write activity can chronically degrade NameNode response times, affecting the runtime of jobs running on Hadoop. The file merging mentioned above for tables with many small files had a measurable effect on this issue. By reducing file and block counts, we reduced not only the metadata the NameNode needed to handle but also the number of HDFS operation requests.
On the other hand, how load manifests differs by namespace. For example, in a namespace that stores many temporary files, NameNode load is relatively calm under normal conditions, but when new DataNodes are added, load can spike dramatically due to the HDFS Balancer. In such namespaces, Apache Spark staging file creation and deletion frequently occurs in short bursts, causing continuous metadata updates that require write locks on the NameNode. During block movement by the HDFS Balancer, block info lookup processing increases and read locks can be held for longer. As a result, updates like file creation and deletion can be delayed, leading to HDFS response latency. We adjusted HDFS Balancer parallelism—initially set high—downward to a level that considered DataNode disk utilization headroom, balancing processing time and cluster impact.
Some of the challenges encountered during cluster growth might in hindsight have been handled more efficiently with more accurate demand forecasting or prior measures. However, in real operations, we had to continuously respond to unpredictable changes and issues such as sudden increases in data and block counts due to usage expansion, large amounts of traffic from adding/removing DataNodes, and differing load characteristics across namespaces.
What mattered in the process was not just looking at HDFS capacity and settings, but understanding how the cluster was actually used, how Hadoop components behaved internally, and how lower-layer infrastructure such as physical servers and networks would be affected. Operating large-scale Hadoop clusters requires a cross-cutting perspective beyond the internal Hadoop view.
[Former Yahoo Japan Corporation] HDFS latency with increasing user counts
In the former Yahoo Japan Corporation's data platform, HDFS-wide latency became apparent as data volume and user counts increased. In particular, the number of operation requests against HDFS has been increasing year over year, and client-observed response latency became non-negligible.
The following chart shows the trend in HDFS operation request counts from 2020 to 2025. For readability we show monthly averages, and it is clear that request counts increase over time.
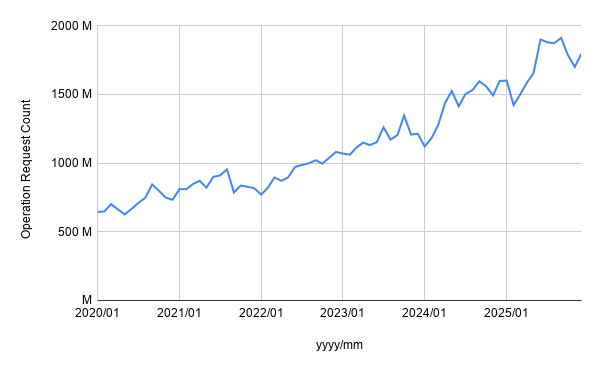
Initially, we thought the Router layer was the bottleneck.
In HDFS, write requests are aggregated to the Active NameNode, while read requests can be offloaded to Observer NameNodes. However, when the Active NameNode is heavily loaded, request processing can back up on the Router side as well, causing the Router's call queue to become congested.
Therefore, we expected that increasing the number of Routers to distribute request processing would make it easier to route read requests to Observer NameNodes even when write requests temporarily back up, improving overall throughput.
After scaling out Routers, call queue congestion was somewhat dispersed and some improvement was observed. However, the effect was not as large as expected.
Further investigation revealed that clients using Observer NameNodes were issuing a large number of msync requests. msync is the process by which a client checks the Active NameNode's update status before reading from an Observer NameNode. As the number of users grew, this check was executed more frequently and contributed to Active NameNode load.
In other words, even after adding Routers, read request processing was ultimately affected by waiting on msync to the Active NameNode, and the fundamental bottleneck remained.
We therefore analyzed Active NameNode load. We found that msync was being executed too frequently and adjusted its execution frequency within a range that did not affect read correctness.
This change significantly reduced Active NameNode load and, as a result, improved HDFS-wide latency.
The lesson from this case is the importance of correctly analyzing where processing waits occur. Superficially, Router call queue congestion appeared to be the problem, but the true bottleneck was the Active NameNode load behind it. Simple scale-out alone cannot solve such issues; it is important to understand internal system dependencies and load structure before taking measures.
1.4. Summary
The HDFS platforms of the former LINE Corporation and the former Yahoo Japan Corporation both evolved to support large-scale data utilization. However, they differed significantly in how namespaces are aggregated, how the platform is presented to users, units of access control, and operational responsibility boundaries.
In particular, the former LINE Corporation assumed a client-side namespace resolution using ViewFS, while the former Yahoo Japan Corporation assumed server-side resolution using RBF and Routers. The former LINE Corporation had a role-based access control system centered on DB/Table, whereas the former Yahoo Japan Corporation long used HDFS Path–based access control.
Therefore, after organizational integration, simply connecting networks and enabling data transfer was insufficient. It was necessary to align and clarify which entry points access HDFS, which units govern permissions, and who can transfer data along which routes according to each platform's assumptions.
The differences seen in Part 1 also affect the design challenges of cross-platform integration covered in Part 2, as follows.
| Differences seen in Part 1 | Design challenges in Part 2 |
|---|---|
| Differences in how namespaces are resolved and access routes, for example ViewFS vs RBF (HDFS) | How to organize destinations, path resolution, and client configuration for DistCP |
| Differences in units of access control (DB/Table vs HDFS Path) | In what unit should transferred data be managed and inventoried for permissions |
| Differences in user flows and surrounding systems | How much platform differences should be exposed to users |
| Differences in operational responsibility boundaries and impact scope during changes | How to design operational flows that include security, network, and legal considerations |
In Part 2, we describe how we designed access control models and data transfer methods to connect platforms with different assumptions in a safe and operationally viable way.
Part 2. Cross-platform data platform integration during organizational consolidation
2.1. Challenges for cross-platform integration revealed by organizational consolidation
With organizational consolidation, it became important to mutually leverage the data cultivated in each platform to create greater value.
While building a new unified data platform was an option, the existing data platforms were all running at large scale, and full integration was a medium to long-term project. Therefore, we first aimed to enable practical integration within the scope needed for operations while leveraging the characteristics of each platform.
However, each platform was designed and operated under different assumptions, so simply connecting them does not automatically enable cross-platform data utilization. Differences in data placement, access routes, access control, and operational rules must be considered to balance security and usability.
From the perspective of HDFS-centered cross-platform integration, two major challenges emerged.
The first is how to safely transfer and manage data between different platforms.
The two platforms have different access control mechanisms, and simply synchronizing those permissions is difficult. For users to safely utilize data, permission groups for data stored in each of the former LINE Corporation and former Yahoo Japan Corporation platforms need to be managed and operated according to each environment's mechanisms.
Due to historical reasons, the philosophies and designs of access control differ significantly across the platforms. When attempting to share and utilize data across both platforms, users must understand and handle the access control and operational procedures of both systems individually. This imposes a large cost on both users and operators. Reducing access control overhead while promoting safe cross-platform data use is therefore an unavoidable challenge.
The second challenge was improving the efficiency of methods for transferring data between platforms.
When platforms cannot directly exchange data, intermediate measures and multiple steps are required for each data transfer. This not only increases processing time but also raises operational overhead and costs. Moreover, if each routine data transfer requires ad-hoc handling, cross-platform integration itself becomes a bottleneck to data utilization.
Conducting appropriate reviews of transfer targets and reducing the cost of data preparation and transfer were important points for advancing cross-platform data use while maintaining safety.
Of course, the above challenges could be solved by building a unified data platform. However, fully and safely integrating platforms at this scale while considering different operational cultures and design philosophies would likely require significant cost and a long timeframe.
Therefore, rather than aiming first to merge platforms into a single system, this effort focused on establishing both the ability to operate under appropriate access control and the ability to link data across platforms.
Below we describe how we approached access control challenges and what mechanisms we established to address data transfer issues.
2.2. How to bring access control models closer between platforms
As noted in Part 1, the assumptions for data management and access control differ by platform, resulting in differences in operational rules and user experience.
These differences relate to the overall approach to data operations, such as "who is responsible for the data", "at what unit are view permissions granted", and "who approves requests".
Therefore, even if data can be exchanged across platforms, it is difficult to align post-transfer access control and inventory flows to a common model, and users must understand different procedures and access control concepts for each platform, which is a challenge.
Divergence in access control philosophies between the former LINE Corporation and the former Yahoo Japan Corporation
The first challenge in unifying access control was that the very approach to access control differed between the former LINE Corporation and the former Yahoo Japan Corporation.
Two major differences were especially notable:
- "Who accesses data and for what role or purpose"?
- "At what unit should data permissions be managed"?
These correspond to the two perspectives above.
At the former LINE Corporation, management units called Projects were created for each data utilization purpose, and permissions were managed at the DB/Table level through those Projects.
Users obtain permissions through Projects and roles, forming a role-based model that makes it easy to clarify "who accesses data in which role or for what purpose".
This approach is well suited to governance operations because it makes use cases and responsibilities easier to understand.
On the other hand, the former Yahoo Japan Corporation managed permissions at the HDFS Path level.
This allows services to place data in free structures according to their needs, which is flexible to operate, but as the number of managed objects increases, permission settings and inventory become increasingly complex.
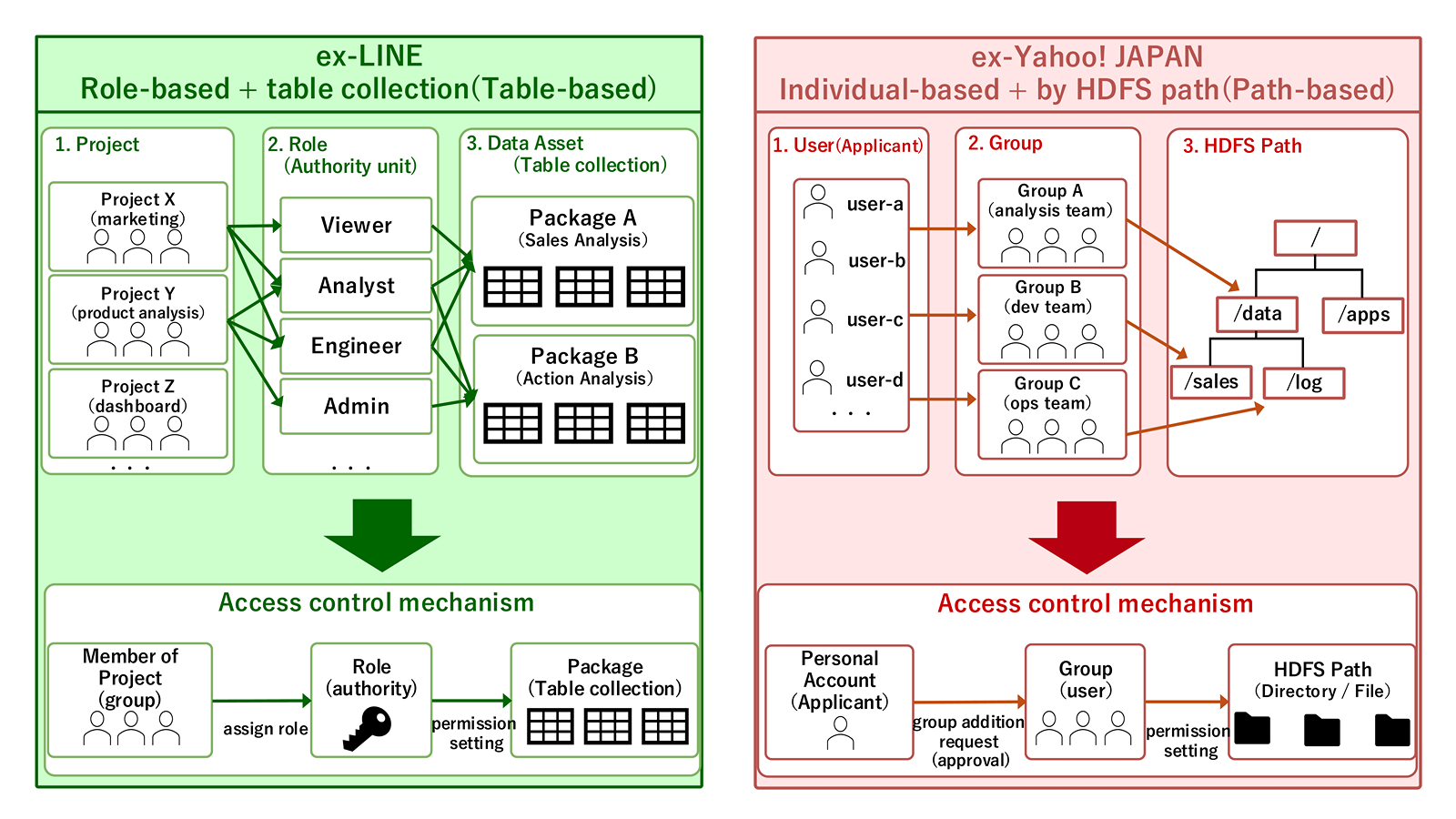
In other words, the platforms differed not only in the mechanisms they used but in the underlying assumptions about "who" should be granted access to "what".
Because a table-based management model treats access control and inventory in consistent units and pairs well with governance operations, there was motivation to move the former Yahoo Japan Corporation's data management toward a table-based model where possible.
However, migrating existing data in the former Yahoo Japan Corporation from an HDFS Path–based model to a table-based model is itself a major challenge. Much of the existing data was operated under the HDFS Path assumption, and moving to a table-based approach would require revisiting data placement, table schemas, jobs, and operational workflows.
Therefore, it was expected to be a very costly undertaking for both users and platform operators.
Migration approaches and design considerations
Given this background, how to introduce the former LINE Corporation's access control into the former Yahoo Japan Corporation's data platform had to be considered as a design challenge that also covered how to handle existing data structures.
The migration approaches we considered can be broadly categorized into two options.
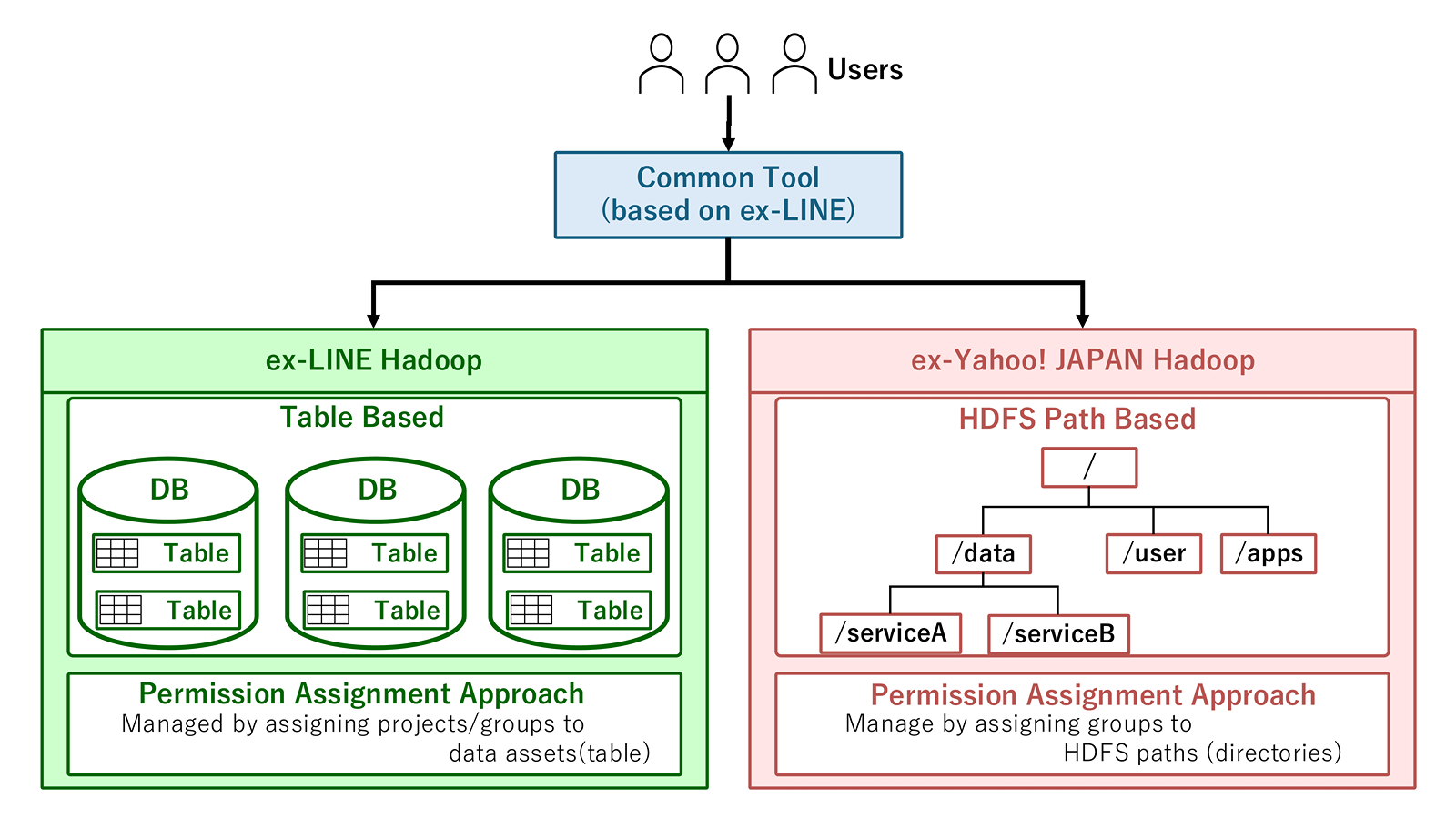
The first option is to adapt the former LINE Corporation's access control system while keeping the existing former Yahoo Japan Corporation structure as intact as possible.
In this option, as shown in the diagram, users would be able to manage permissions through a common tool and common flow after integration. By standardizing user groups and request flows, it is also possible to align toward a role-based management model that clarifies "who accesses data in which role or for what purpose".
However, this does not unify the fundamental unit of data management; internally, the former LINE Corporation's table-based management and the former Yahoo Japan Corporation's HDFS Path–based management would continue to coexist.
This can make it difficult to understand which data are managed at what granularity and under which rules, raising concerns that operational rules and user experience could become more complex over the long term.
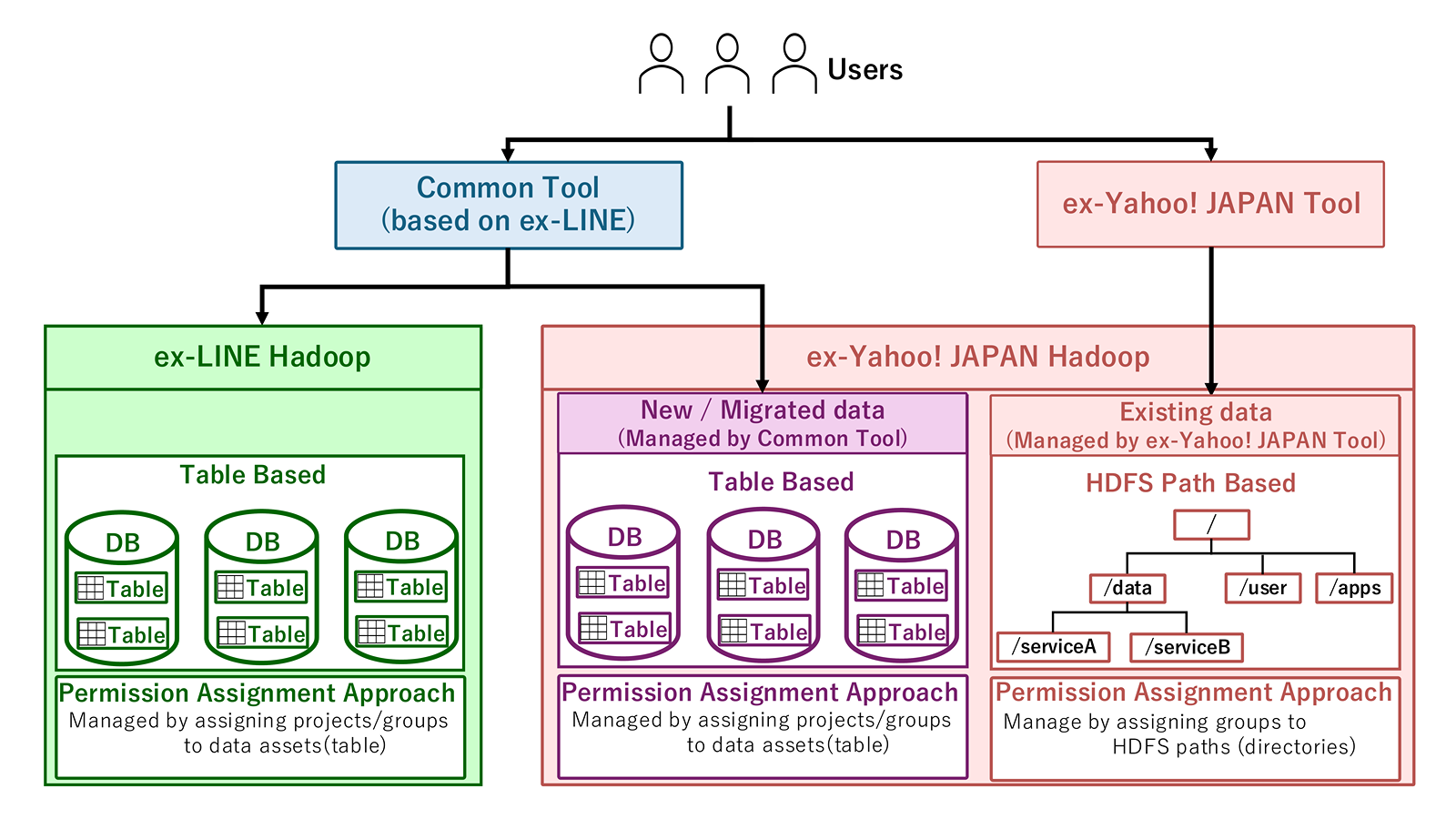
The second option is to create a new area on the former Yahoo Japan Corporation side aligned with the former LINE Corporation's management model.
In this option, a new area that is easy to manage at the DB/Table level is prepared and users migrate target data into the new area. This clearly separates the existing HDFS Path–based area from the new table-based area, as shown in the diagram.
In particular, aligning management at the table unit has the advantage of making governance operations consistently easier to handle. It also allows phased application starting with new data or items that require cross-platform transfers, enabling control over when migration burden falls on users.
On the other hand, users incur migration costs such as data migration and rebuilding tables.
Final design decision
Ultimately, we adopted Option 2 to minimize disruption to existing operations while making it easier to gradually unify the management model, including permission inventories and audit responses.
What mattered in this effort was not to apply a management model across the board all at once, but to establish both governance and practical operations while taking into account the different design philosophies of the former LINE Corporation and the former Yahoo Japan Corporation. This approach allowed us to build a foundation for managing permissions under the same concept when handling data across platforms without replacing existing operations all at once.
2.3. How to link data between platforms
The theme we tackled was how to link data between platforms with differing design philosophies and operational models in an efficient and operationally viable way, taking authentication, authorization, and operational governance into account.
Overview of data linkage
Until now, when linking data between the former LINE Corporation and the former Yahoo Japan Corporation platforms, we used a data exchange mechanism in a separate environment and transferred data through Amazon S3. While this approach kept the platforms loosely coupled, it had challenges in terms of onboarding procedures, operational coordination, and usage costs.
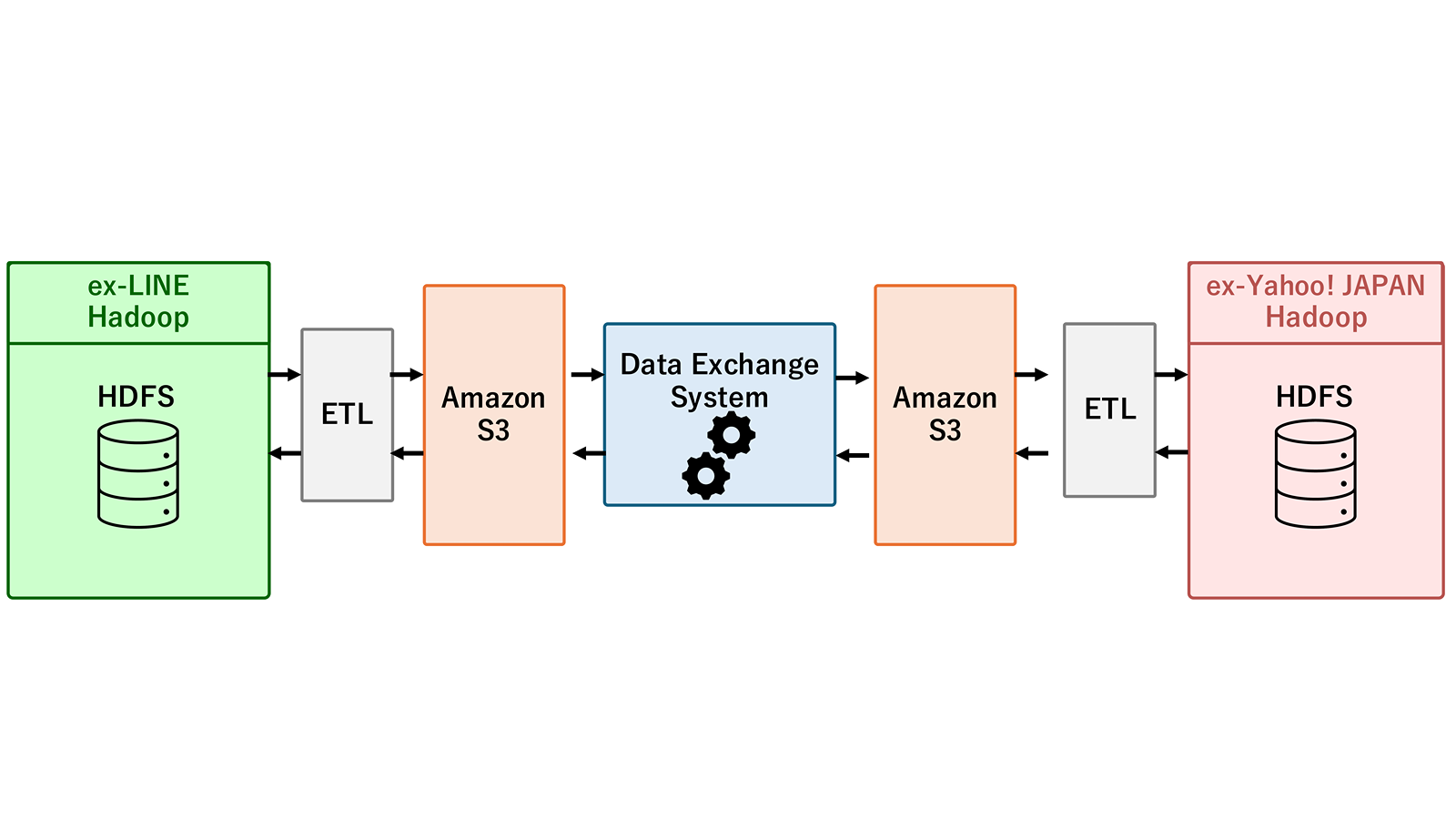
We considered leveraging DistCP as a simpler and faster data transfer method. DistCP is a standard mechanism for parallel distributed copying of large volumes of data between clusters in Hadoop environments.
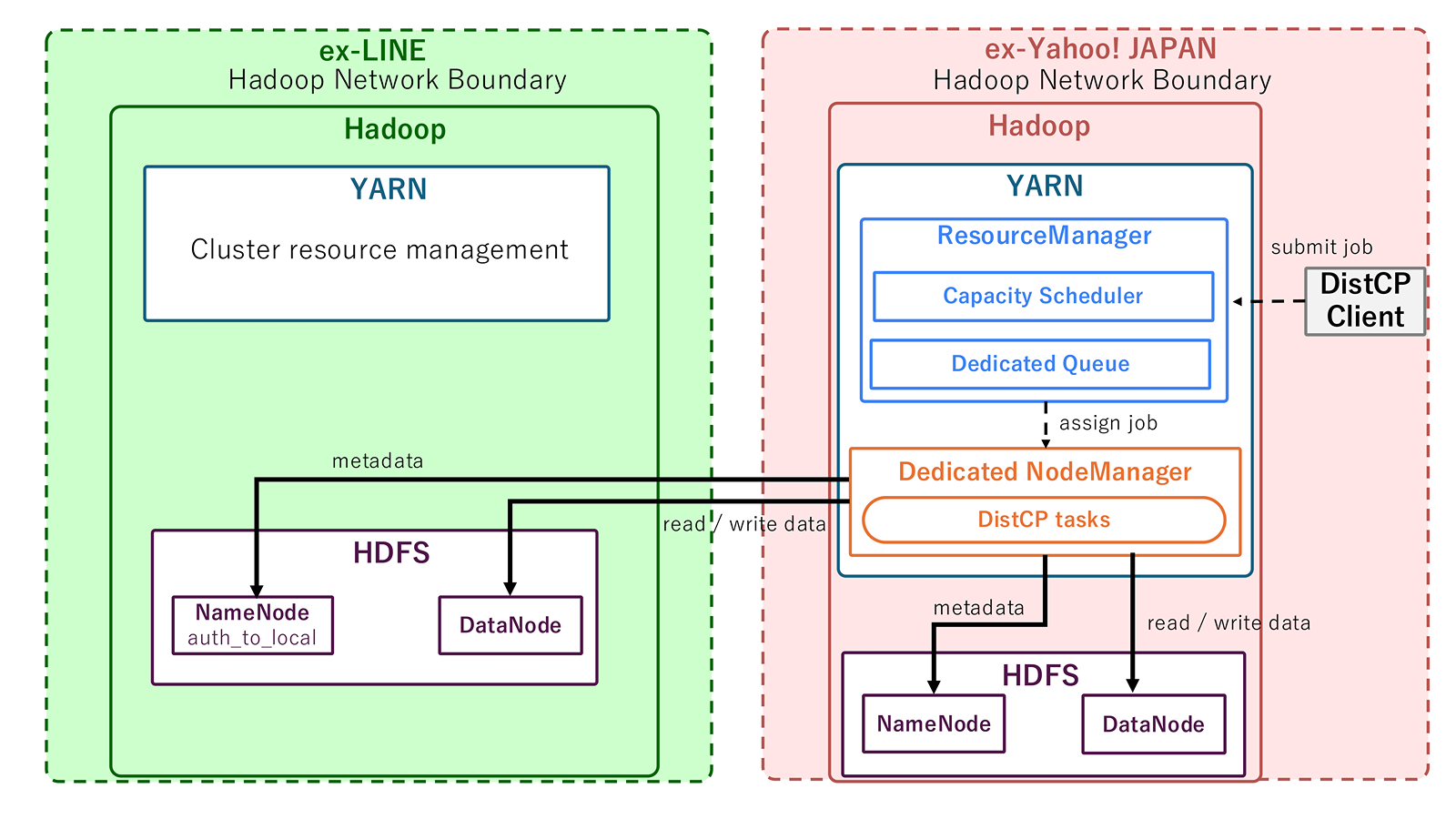
When directly connecting platforms using DistCP, in addition to opening transfer routes, it was necessary to organize authentication, authorization, operational governance, and technical details. Here, authentication means "verifying who the accessing principal is", and authorization means "determining what the verified principal is allowed to do".
Authentication and authorization
For authentication, both the former LINE Corporation and the former Yahoo Japan Corporation Hadoop clusters use Kerberos, so we assumed using each cluster's Kerberos KDC to identify who is accessing the system.
A key requirement was enabling authentication across different Kerberos realms. For this, we adopted a Cross-Realm configuration. The former LINE Corporation and the former Yahoo Japan Corporation each have independent Kerberos KDCs that handle authentication locally. To leverage this setup, their realms' authentication must be trusted and utilized. Kerberos provides a Cross-Realm mechanism for this purpose: By establishing trust relationships between KDCs, each realm can trust the other's authentication.
In addition, for accounts authorized to use DistCP, we unified the account names used in the former LINE Corporation and the former Yahoo Japan Corporation Hadoop environments. This reduces discrepancies in account names between clusters and makes it easier for surrounding Hadoop systems to treat them as the same principal.
For authorization, we designed a system that restricts execution to accounts allowed to transfer only company-approved data.
Specifically, we prepared a DistCP-dedicated queue in the CapacityScheduler that manages job execution and restricted which accounts can submit jobs to this queue. We also aligned account names using Kerberos auth_to_local so accounts map 1:1 between source and destination clusters.
Technical considerations
From a technical standpoint, connectivity and constraints across OSI Layers 1–7 and bandwidth management were key topics. We paid particular attention to Layer 4 and Layer 7.
At Layer 4, we prepared a dedicated NodeLabel tied to the DistCP-dedicated queue. If a DistCP job runs without the dedicated NodeLabel, the job executes on the same NodeManagers used by other Hadoop cluster users, causing the DistCP communication path to overlap with general cluster traffic and making it impossible to restrict the network path. We allowed only NodeManagers with the dedicated NodeLabel to be connected between clusters and blocked connections from other NodeManagers with network ACLs. This ensures that if an account not authorized to submit to the dedicated queue submits a DistCP job through another queue, Layer 4 network connections are blocked and the job fails.
At Layer 7, in addition to establishing Kerberos Cross-Realm, we paid attention to aligning points that could cause errors during DistCP between clusters (in our case, differences in minimum HDFS block size, for example). Since network rules and ACL approaches differ across interconnected environments, we inventoried required communications by layer and determined which connections needed to be opened.
During implementation, we found IP address collisions on the interconnect, so individual preparations were required—such as rebuilding KDCs in non-overlapping address spaces to avoid conflicts. Additionally, to make cross-platform linkage operationally viable, it was important to pre-inventory target Hadoop clusters, the servers to be interconnected between clusters, the network ACLs applied to those servers and how to change them, and the job submission and execution paths. Since the former LINE Corporation uses ViewFS, it was also necessary to correctly distribute client configuration files including mount tables and verify that transfer paths resolved to the expected namespaces.
By clarifying which production and test clusters to connect, what configuration differences DistCP requires, and where jobs can be submitted from, we were able to design an operationally viable arrangement rather than a simple "can connect / cannot connect" checklist.
Bandwidth management was also an important consideration. Because the former LINE Corporation and former Yahoo Japan Corporation Hadoop clusters are in different data centers, we adopted a small-start approach to avoid overloading WAN links, adjusting DistCP job parallelism and bandwidth caps and operating gradually at levels that do not affect normal traffic.
Operational governance
From a governance perspective, it was important not only to have the mechanism in place but also to prepare operational workflows up to the point of use.
In practice, DistCP onboarding consultations included discussions with security owners and network teams, and—when necessary—legal review regarding the purpose of transfer and privacy impacts. We established a flow to consolidate the various settings required for data transfers.
What matters in cross-platform linkage is not merely that data can be moved. It is essential to take a holistic view that includes authentication, authorization, operational governance, and network design to determine who can handle which data, with what permissions, and through which routes.
DistCP is powerful and simple, but to use it effectively between platforms with different backgrounds, you must design the surrounding constraints and operational workflows as part of the architecture to make it efficient and operationally viable.
2.4. Summary
In organizational consolidation, simply enabling data transfer between platforms was insufficient. In practice, it was important to prepare routes that allow safe and continuous cross-platform linkage and to determine how to align access control and governance on top of that.
In this initiative, we first prepared viable transfer routes and put them into operation under appropriate controls, making practical progress.
As a result, we were able to build a foundation for advancing cross-platform data utilization.
Outlook
In this article, we introduced operational challenges that accompany cluster growth and the issues of cross-platform linkage during organizational consolidation for the large-scale data platforms held by the former LINE Corporation and the former Yahoo Japan Corporation.
What they shared was that it was not enough to simply increase scale or create connection paths; we had to translate each requirement into forms that can withstand real operations.
Capacity, NameNode load, namespace structure, access control, authentication, networks, and operational flows may seem like independent concerns. In reality, they are interdependent design elements needed to ensure users can handle data safely. In this initiative, we organized these elements step by step and established a foundation that allows integration while leveraging the characteristics of existing platforms.
At the same time, challenges remain: Improving usability to further enable data utilization, enhancing mechanisms for safer and more reliable data linkage, and addressing scaling as data use expands.
Going forward, we will continue to aim for a state in which users can naturally and safely utilize needed data without being aware of platform differences. To achieve this, we will remove the remaining constraints in current cross-platform linkage one by one and move toward a more unified user experience. In the medium to long term, we will also aim to unify the platforms themselves while aligning operational and technical assumptions to build a more user-friendly and reliable data platform across the former LINE Corporation and the former Yahoo Japan Corporation.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


