LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
はじめに
こんにちは。LINEヤフーで大規模データ基盤の運用を担当している平山、沼田、小笠原、小川です。
LINEヤフーでは、検索・ポータル、eコマース、メッセンジャー、広告など幅広いサービスを支えるため、大規模なデータ基盤を運用しています。その中核となるHDFS(Hadoop Distributed File System)は、旧LINEと旧ヤフーそれぞれの主要なクラスタを合わせて、総容量1エクサバイト(EB)を超える規模に達しています。
このような規模のHDFSを運用する中で、私たちは大きく2つのテーマに向き合ってきました。
1つ目は、HDFSを中心とした大規模データ基盤の運用における課題です。
データ増加に伴うスケーリング上の制約や、運用上のボトルネックに対してどのように対応してきたのか、またその過程でどのような構成や利用形態が形成されてきたのかを整理します。
2つ目は、組織統合に伴うデータ基盤の連携です。
異なる設計思想で構築されたデータ基盤をどのように接続し、データの相互利活用を実現するかという課題です。
��これらは一見すると別々の問題に見えます。しかし、どちらも、旧LINEと旧ヤフーで異なる基盤の成り立ちや構成、利用形態を踏まえながら、実運用に耐えられる設計や対応を積み重ねてきた話です。
大規模化に伴う運用課題では、こうした違いが容量管理、NameNode負荷、ネットワーク影響といった形で現れました。組織統合に伴う連携では、接続先、権限管理の単位、データ転送の経路をどう設計するかという課題として現れました。
本記事の前半では、旧LINEと旧ヤフーそれぞれの大規模データ基盤について、構成や利用形態の違い、運用上の課題を紹介します。後半では、両者のデータ基盤の連携について説明します。
目次は次のとおりです。
Part 1. 旧LINEと旧ヤフーにおけるHDFS基盤の構成・利用形態と運用課題
本パートでは、まず旧LINEと旧ヤフーにおけるHDFS基盤の利用・運用モデルの違いを整理し、その背景にあるHDFS構成の違いを見ていきます。そのうえで、大規模運用の中で実際に直面した課題と、その対応について紹介します。
1.1. 利用・運用モデルの違い
旧LINEと旧ヤフーは、Apache Hadoopを運用してきた歴史の長さも、提供してきたサービスの幅も異なる会社でした。そのため、それぞれで運用されているクラスタの間には、データアクセス、権限管理、運用方法といった観点で、データ基盤全体の設計思想やユースケースに大きな違いが生まれています。
旧LINEでは、複数の大規模な分析環境が長く運用されており、現在使われている��環境はそれらを統合するためにHadoop 3系の時代になって構築されたものです。部門をまたぐ多様なデータ利活用ニーズに対応し、新環境へスムーズに移行することが、当初からの使命でした。
分断された多数のデータをひとつのプラットフォームに統合。データ分析基盤構築の道のり
そのため、HDFS PermissionやApache Rangerを利用者が直接扱うのではなく、権限やデータカタログを管理するWebポータルが整備されました。これにより、利用者はHadoop内部の細かい仕組みに触れずとも、DB/Tableを中心とした管理単位のもとで、権限申請や承認が統合されたロールベースの仕組みを通じて、安全にデータを利活用できるようになりました。それと同時に、多様な使い方を支えるBI・レポーティングツールやETLバッチパイプラインなどさまざまなシステムが整備されました。その一方で、多種多様なユースケースに対応する必要があったことや、既存クラスタをシームレスに統合するためにNamespaceごとそのまま取り込んだことから、クラスタ管理の複雑さが運用上の課題として残っています。
旧ヤフーでは、Hadoop 0.2系の時代から、限られた目的での大規模分析を起点に分析基盤の構築・活用が始まりました。その後、新規ユースケースの受け入れや個別運用されていたHadoopクラスタの集約・移行を通じて、全社で幅広く活用される基盤へと発展し、安定運用しやすい構成へ整理されてきました。
利用者がHadoop環境にアクセスするためのインターフェースは、必要最小限に整理されています。アクセス方法には一定の��制約がありますが、入口を絞ることで、システムとして安定した提供や利用者サポートを行いやすい構成になっています。
しかし、旧ヤフーでは単一のHDFS Namespaceを長く運用し、その規模が拡大してきた経緯があります。その結果、NameNodeのスケーリングが課題となり、後からRouter-based Federation(RBF)を導入することで、Namespaceを分割して扱える構成へ移行しました。権限管理についても、歴史的な経緯から現在もHDFS Permission(POSIXライクな権限管理)によるアクセス制御を用いています。そのため、現在のデータ管理で求められる柔軟な権限管理との間にはギャップがあり、制約の一つとなっています。
この違いは、日々の運用にも影響していました。旧LINEでは、Hadoopの運用チームが直接管理していないシステムまで含めて利用者の導線や権限申請の仕組みを常に考慮して運用を設計する必要があります。一方の旧ヤフーでは、保存先や権限設定を軸に管理しやすい設計になっています。同じHDFSを使っていても、どこにデータを置くか、誰がそのデータを扱うのか、権限をどう整備するのか、そして設定や方針の変更が誰にどのような影響を与えるのか、といった観点の整理方法が異なっています。
以下に、両環境の利用・運用モデルの違いを整理します。旧LINEと旧ヤフーでは、基盤の成り立ち、利用者導線、権限管理や変更時の影響範囲に、次のような違いがあります。
| 観点 | 旧LINE | 旧ヤフー |
|---|---|---|
| 発展経緯 | 複数の分析環境を統合する基盤として構築 | 限定用途の大規模分析から全社基盤へ発展 |
| 利用者導線 | ポータル、データカタログ、BI、ETLなど複数導線を提供 | アクセス経路を絞り、利用・サポートを標準化 |
| 権限管理 | HDFS自体を意識しなくてよい、ロールベースによる申請・承認フロー | HDFS Permissionを基準に管理 |
| 権限管理の単位 | DB/Table | HDFS Path |
| Namespace構成 | 既存環境のNamespaceを取り込みながら統合 | 単一NamespaceからRBFによる分割構成へ移行 |
| 変更時の考慮点 | 利用者導線や連携システムへの影響確認が必要 | 基盤側で影響範囲を整理しやすい |
1.2. HDFS構成の違い
旧LINEと旧ヤフーはいずれも長年にわたってHadoopクラスタを運用してきましたが、その発展の経緯や設計思想には多くの違いがありました。特に技術的な面での大きな違いは、HDFSクラスタにおけるNamespaceの扱い方です。
HDFSはその仕組み上、規模が大きくなるにつれてファイルシステムのメタデータを管理するNameNodeがボトルネックになりやすくなります。そのため、旧LINEと旧ヤフーのいずれも、スケーリングのためにNamespaceを複数に分割した構成になっています。つまり、両環境とも、ストレージ全体が複数のNamespaceに分かれ、各Namespaceを管理するNameNodeが、2〜4台で冗長化されている点は共通しています。
データは複数のNamespaceにまたがって保管されているため、HDFSにアクセスする際は、対象データがどのNamespaceに保存されているのか、どのNameNodeへ接続する必要があるのかを判断する必要があります。加えて、実際のデータを保管するDataNodeをどの単位で配置・共有するのかも判断が必要です。この複数のNamespaceをどのように束ね、冗長化をどう構成するか、そして実際のデータが保存されるDataNodeをどの単位で持つかが、旧LINEと旧ヤフーの大きな違いです。
旧LINEではViewFSを用いており、クライアント側で複数のNamespaceを扱う構成を採用しています。この方式では、クライアントに設定されたマウントテーブルをもとに、プログラムが実際のパスを読み替えてNamespaceを判別し、設定内容に基づいてNameNodeへアクセスします。これはシンプルで柔軟性が高い反面、各利用者側のクライアント設定の整合性を保つ必要があるため、社内に多く存在するサービスや利用者側での設定反映の考慮が運用上の重要な観点になります。
また、旧LINEのクラスタはすべてのNamespaceでDataNodeを共有する構成となっています。この構成はリソース効率を高めやすく、スケール時の設計もしやすい一方で、クラスタ構成が複雑になり、運用上考慮すべき観点や手間が増える要因にもなります。加えて、社内に複数あったデータ分析基盤を統合しつつ構築した経緯から、1つの大きなクラスタの中でNameNodeとDataNodeのバージョンが混在していることも状況をより複雑にしています。
一方の旧ヤフーでは、RBFを用いて、複数のNamespaceをサーバ側で束ねる構成を採用していました。この構成では、利用者はRouterにアクセスすればよく、Routerがリクエストを適切なNameNodeへ振り分けます。複数のHDFSを透過的に扱いやすくなる一方で、Router層そのものの可用性やスケール設計が重要になります。
また、NameNode構成にはObserver NameNodeも含まれており、読み取り負荷の分散も意識した設計になっています。RBF導入時の詳細は、Yahoo! JAPAN Tech Blogの記事をご覧ください。
HDFSをメジャーバージョンアップして新機能のRouter-based Federationを本番導入してみた
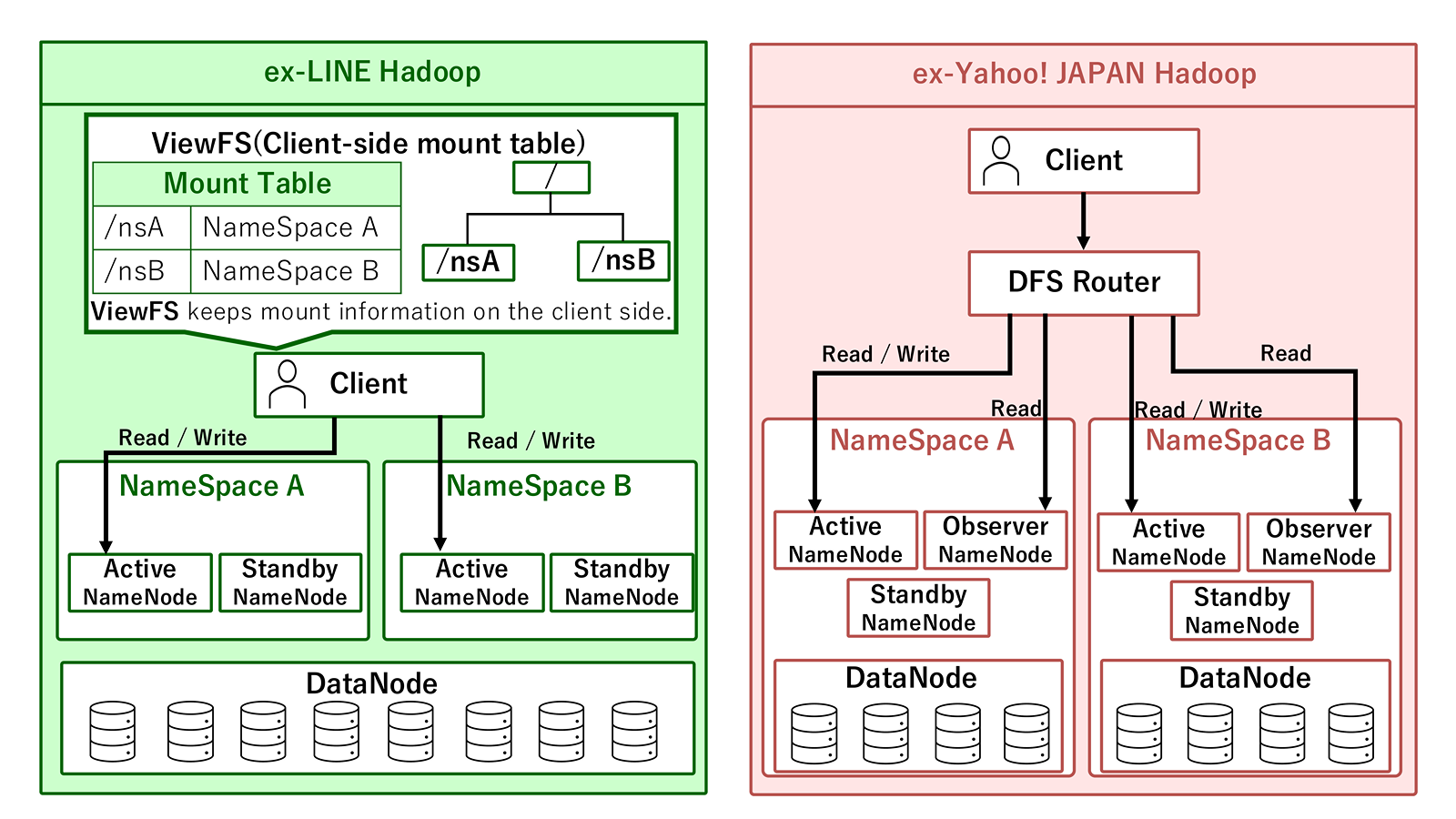
この違いは、単なるHDFS内部構成の違いにとどまりません。後述する基盤間連携では、どちらの基盤へ、どの入口から、どの設定を持ったクライアントとしてアクセスするかが重要になります。
旧LINEのようにViewFSで複数Namespaceを束ねている場合、クライアント側のマウントテーブルが正しく配布されていなければ、期待したNamespaceへ到達できません。一方、旧ヤフーのようにRBFで複数Namespaceを束ねている場合、利用者やジョブはRouterを入口としてアクセスするため、Router層の可用性、スケール、ネットワーク到達性、入口としての制御が重要になります。
この差分は、Part 2で説明するDistCPによる基盤間連携や、接続経路・権限・運用フローの整理にも影響します。
1.3. 大規模運用で直面した課題
このような大規模かつ複雑なHDFS基盤を運用していく中で、さまざまな課題に直面してきました。
ここでは、旧LINEと旧ヤフーそれぞれで直面した課題に対してどのようなアプローチで対応したかを紹介します。
[旧LINE]成長に伴うHDFSの大規模化で直面したさまざまな課題
旧LINEのHadoopクラスタは、もともと存在した2つのHadoopクラスタを統合し全社でデータを利活用するために構築されたクラスタです。既存のクラスタをそのまま取り込んでいることからゼロから立ち上げた場合のような初期段階での急激な増加はありませんでしたが、全社に広く展開されたことでクラスタの運用開始当初から予測を上回る利用があり、時期によりさまざまなリソースの逼迫への対応が発生していました。
最初期の段階で課題となっていたのはHDFS容量の急速な逼迫でした。需要予測に基づいたサーバの増設は行っているものの、想定を上回るデータ量の増加により新しいサーバの納品よりも前にHDFS容量が枯渇する可能性が高くなったため、古いサーバを一時的に再利用し、後で新しいサーバに入れ替えるなど、頻繁なサーバの追加・撤去が発生することになりました。
このとき、クラスタの規模が大きいため、新規サーバの追加や一時的に追加したサーバの一斉撤去などでノード数が急に増減すると、ブロックの再配置やHDFS Balancerにより非常に大きなトラフィックが発生します。ネットワーク側に輻輳が発生することもあるため、特に運用開始当初はネットワークチームとも連携を取りながら、ネットワーク構成も考慮しながら作業��を進める必要がありました。
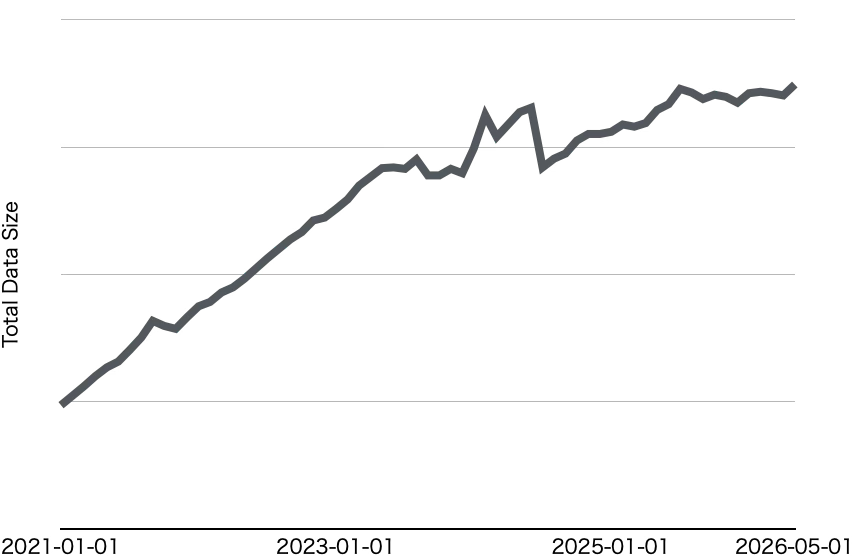
容量の問題が落ち着いた後、次に問題になったのはHDFSのブロック数の増加によるNameNodeのヒープ利用量の増加でした。NameNodeはNamespace全体のファイル、ディレクトリ、ブロックなどのメタデータをメモリ上で管理します。そのため、ファイル数・ブロック数が増えるとNameNodeのヒープ利用量や処理負荷増加につながります。1台のサーバが搭載できるメモリには限界があるだけでなく、ヒープが大きくなればその分GCにかかる時間も延びるため、NameNodeは動作が遅く不安定になっていきます。
その解決のため、大量のブロックを抱えているテーブルを特定し、利用者と連携して削減を進めていきました。HDFSのFSImageを定期的にダンプしHiveテーブルとして保存しているため、これを分析することで、どの利用者がどのパスに、どれだけのファイル数・ブロック数・データ量を保持しているかがわかります。その対象として、大量のスモールファイルを抱えるテーブルのうち、ファイルマージだけでブロック数を大幅に削減できるものに絞りました。これにより、データ削除の可否やパーティション設計を含むスキーマ変更などの判断を伴わず、比較的単純な操作で迅速な対応につなげることができました。
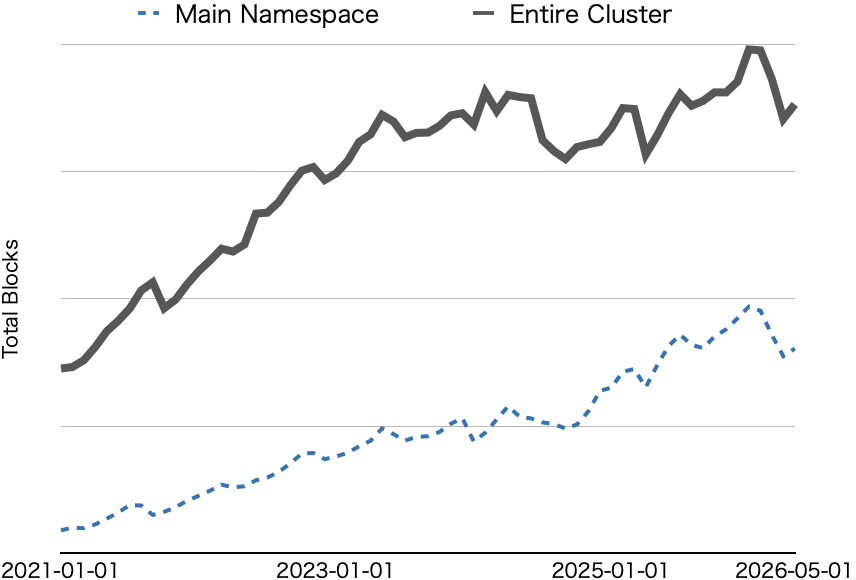
全体的に増加傾向だが定期的な削減により増加が抑制されている
ブロック数の増加によるNameNodeのヒープ利用量に加えて、NameNodeの応答速度の低下もしばしば問題になりました。特にHDFS上のテーブルデータの大半が保存されているNamespaceでは常に大量の読み書きが発生しているため、慢性的にNameNodeの応答速度が低下しやすく、それがHadoopで実行されているジョブの実行速度にも影響します。この問題についても、前述した大量のスモールファイルを抱えるテーブルのファイルマージが一定の効果を持ちました。ファイル数やブロック数を削減することで、NameNodeが処理するメタデータの量だけでなく、HDFSに対する操作リクエスト数も減らすことができるためです。
一方で、負荷の現れ方はNamespaceごとに異なります。たとえば、一時ファイルが多く保存されるNamespaceでは、通常時のNameNode負荷は比較的落ち着いているものの、新規DataNode追加時はHDFS Balancerにより急激に負荷が増加することがありました。このNamespaceでは、Apache Sparkのステージングファイルの作成・削除が短時間で頻繁に発生するため、NameNode上でwrite lockを必要とするメタデータ更新が継続的に発生していました。一方、HDFS Balancerによるブロック移動時にはブロック情報の参照処理が増加し、read lockが長く保持されることがあります。その結果、ファイル作成・削除などの更新処理が待たされ、HDFSの応答遅延につながりやすい状態でした。当初HDFS Balancerの並列度を高めに設定していたものを、DataNodeのディスク�使用量の余裕を考慮し、支障が出ない範囲まで並列度を下げ、処理時間とクラスタへの影響のバランスを取る形で対応しました。
これまでのクラスタの成長に伴う課題の中には、後から振り返ればより正確な需要予測や事前対策によって効率的に対処できたものもあったかもしれません。しかし実際の運用では、利用拡大に伴うデータ量やブロック数の急増、DataNodeの追加・撤去に伴う大量のトラフィック、そしてNamespaceごとに異なる負荷特性など、予測しきれない変化と課題に継続的に対応する必要がありました。
その過程で重要だったのは、HDFSの容量や設定だけを見るのではなく、クラスタが実際にどのように使われているのか、Hadoopの各コンポーネントが内部でどのように振る舞うのか、そして物理サーバやネットワークといった低レイヤーのインフラにどのような影響を与えるのかを含めて把握することでした。大規模Hadoopクラスタの運用では、Hadoop内部にとどまらずこれらを横断する視点が重要でした。
[旧ヤフー]利用者増加に伴うHDFS遅延
旧ヤフーのデータ基盤では、データ量や利用者の増加に伴い、HDFS全体の遅延が顕在化していきました。特に、HDFSに対する操作リクエスト数は年々増加しており、クライアントから見た応答遅延も無視できない状態になっていました。
以下のグラフは、2020年から2025年までのHDFSに対する操作リクエスト数の推移を表しています。見やすさのため月次平均で集計していますが、時間の経過とともにリクエスト数が増加していることがわかります。
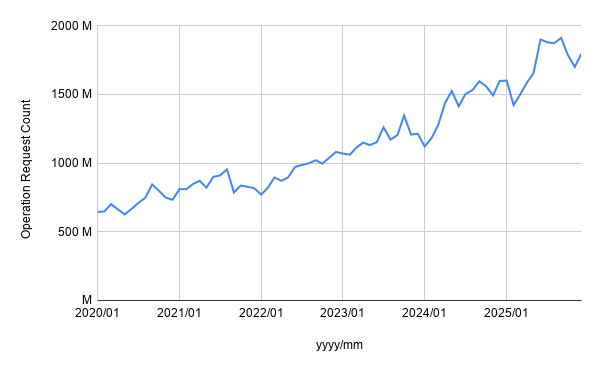
当初は、Router層がボトルネックになっていると考えました。
HDFSでは書き込みリクエストがActive NameNodeに集約されます。一方で読み取りリクエストはObserver NameNodeへオフロードできます。しかし、Active NameNodeの負荷が高い状態ではRouter側でもリクエスト処理が滞留し、リクエストの待ち行列であるCallQueueが詰まりやすくなります。
そのため、Routerを増やしてリクエスト処理を分散すれば、書き込みリクエストが一時的に滞留しても、読み取りリクエストをObserver NameNodeへ流しやすくなり、全体のスループット改善につながると考えました。
実際にRouterを増強した結果、CallQueueの滞留はある程度分散され、一定の改善は見られました。しかし、期待していたほど大きな効果は得られませんでした。
調査を進めたところ、Observer NameNodeを利用するクライアントから msync リクエストが大量に発行されていることがわかりました。msync は、Observer NameNodeから読み取る前に、クライアントがActive NameNode側の更新状況を確認するための処理です。利用者の増加に伴ってこの処理の実行回数が増え、Active NameNodeの負荷要因となっていました。
つまり、Routerを増やしても、読み取りリクエストの処理は最終的にActive NameNodeへの msync 待ちの影響を受けており、根本的なボトルネックは解消されていなかったのです。
そこで、Active NameNode側の負��荷分析を進めました。その結果、msync の頻度が高すぎることがわかり、読み取り結果に影響が出ない範囲で実行頻度を見直しました。
この対応により、Active NameNodeの負荷が大きく低下し、結果としてHDFS全体のレイテンシも改善しました。
この事例から得られた教訓は、「どこで処理待ちが発生しているか」を正しく分析する重要性です。表面的にはRouterのCallQueue滞留が問題に見えていましたが、実際にはその背後にあるActive NameNodeの負荷が本質的なボトルネックでした。単純なスケールアウトだけでは解決できず、システム内部の依存関係や負荷構造を把握したうえで対策することが重要でした。
1.4. まとめ
旧LINEと旧ヤフーのHDFS基盤は、いずれも大規模なデータ利活用を支えるために発展してきました。しかし、Namespaceの束ね方、利用者への見せ方、権限管理の単位、運用上の責任分界には大きな違いがありました。
特に、旧LINEではViewFSを前提にクライアント側でNamespaceを解決する構成であり、旧ヤフーではRBFを前提にRouter側でNamespaceを解決する構成でした。また、旧LINEではDB/Tableを中心としたロールベースの権限管理が整備されていた一方で、旧ヤフーではHDFS Pathを中心とした権限管理が長く使われていました。
このため、組織統合後に両基盤を連携させるには、単にネットワークを接続してデータを転送できるようにするだけでは不十分でした。どの入口からHDFSへアクセスするのか、どの単位で権限を管理するのか、誰がどの経路でデータを転送できるのかを、両基盤の前提に合わせて整理する必要がありました。
Part 1で見てきた違いは、Part 2で扱う基盤間連携の設計にも次のように影響します。
| Part 1で見えた違い | Part 2での設計課題 |
|---|---|
| ViewFS/RBFなど、Namespaceの解決方法やHDFSへのアクセス経路の違い | DistCP時に、接続先、パス解決、クライアント設定をどう整理するか |
| DB/Table単位、HDFS Path単位という権限管理単位の違い | 転送後のデータをどの単位で権限管理・棚卸しするか |
| 利用者導線や周辺システムの違い | 利用者にどこまで基盤差分を意識させるか |
| 運用上の責任分界や変更時の影響範囲の違い | セキュリティ、ネットワーク、法務を含む運用フローをどう設計するか |
Part 2では、こうした異なる前提を持つデータ基盤同士を、安全かつ実運用可能な形で連携させるために、権限管理モデルとデータ転送方式をどのように設計したのかを紹介します。
Part 2. 組織統合におけるデータ基盤間連携
2.1. 組織統合で見えてきたデータ基盤間連携の課題
組織統合に伴い、それぞれの基盤で培ってきたデータを相互に利活用し、より大きな価値創出につなげていくことが重要になりました。
統合データ基盤を新たに構築する選択肢もありましたが、既存のデータ基盤はいずれも大規模に運用されており、全面的な統合は中長期的に取り組むべき��テーマです。そのため、まずはそれぞれの基盤の特性を生かしながら、実務上必要な範囲で連携できる状態を整えることを目指しました。
一方で、各基盤は異なる前提のもとで設計・運用されているため、単に接続するだけで横断的なデータ利活用が実現できるわけではありません。データの配置、利用経路、権限管理、運用ルールなどの違いを踏まえ、安全性と利便性の両立を図る必要があります。
このとき、HDFSを中心としたデータ基盤間連携の観点では、大きな課題が2つありました。
1つ目は異なる基盤間で、どのように安全にデータ転送・管理を行うことができるかという課題です。
両基盤は異なる権限管理の仕組みを持っており、その権限を単純に同期することは困難でした。利用者がデータを安全に利活用するには、旧LINEと旧ヤフーの各基盤に保存されたデータに対して、各環境の仕組みに沿って権限グループを管理・運用する必要がありました。
各基盤はこれまでの歴史的経緯もあり、そもそも権限管理の思想・設計自体が異なる部分も多い状況です。両基盤をまたいでデータを連携・利活用しようとすると、利用者は双方の権限管理・運用を理解し、個別に対応しなければなりません。これは利用者にとっても運用者にとっても大きなコストになります。データの相互利活用促進と安全性を両立するという意味で、権限管理コストをどう抑えるかは避けて通れない課題でした。
2つ目は基盤間でデータを連携する手法の効率化です。
基盤同士が直接データをやり取りできない状態では、データ連携のたびに中間的な手段や複数の手順が必要になります。これは、�処理に時間がかかるというだけでなく、運用負荷やコストの増加にもつながります。さらに、日常的なデータ連携のたびに個別対応が必要になると、データ基盤間連携そのものが利活用のボトルネックになります。
転送対象に対する適切なレビューを行ったうえで、データ準備や転送にかかるコストを下げることは、安全性を保ちながらデータの相互利活用を進めるうえで重要なポイントでした。
上記の課題は、もちろん統合データ基盤を構築していくことでも解決可能でした。しかし、この規模の基盤を、異なる運用文化や設計思想を踏まえながら完全かつ安全に統合するには、大きなコストと長い期間が必要になることが予想されます。
そのため、この取り組みでは、基盤を1つにまとめることを先に目指すのではなく、
適切な権限管理のもとで運用できること、基盤間でデータを連携できることを、併せて整備していく必要がありました。
以降では、権限管理の課題にどのように向き合ったのか、データ連携の課題に対してどのような仕組みを整えたのかを整理します。
2.2. 基盤間の権限管理モデルをどう近づけるか
Part 1でも述べたとおり、基盤ごとにデータ管理や権限管理の前提が異なっており、運用ルールや利用者体験にも差がありました。
この違いは、「誰がデータの責任を持つのか」「どの単位で閲覧権限を付与するのか」「誰が申請を承認するのか」といった、データ運用全体の考え方に関わります。
そのため、基盤間でデータをやり取りできても、データ交換後に同じ考え方に基づく権限管理・棚�卸しフローへ寄せることが難しく、利用者にとっても基盤ごとに異なる手続きや権限管理の考え方を理解しなければならないという課題がありました。
旧LINEと旧ヤフーの権限管理思想の乖離
権限管理を統一するうえでまず課題になったのは、旧LINEと旧ヤフーで、権限管理の考え方そのものが異なっていたことでした。
特に大きな違いは、
- 「誰が、どの役割・用途でデータへアクセスするのか」
- 「どの単位でデータ権限を管理するのか」
という2つの考え方にありました。
旧LINEでは、データ利活用の目的ごとにProjectという管理単位を作り、そのProjectを介してDB/Table単位で権限を管理していました。
利用者はProjectやロールを通して権限を得る構造になっており、「誰が、どの役割・用途でデータを参照するのか」を整理しやすい、ロールベースのモデルでした。
この方式は、利用用途や責任範囲を把握しやすく、ガバナンス運用と相性の良い構造でした。
一方、旧ヤフーでは、HDFS Path単位で権限を管理していました。
各サービスが用途に応じて自由な構造でデータを配置できるため柔軟に運用しやすい一方で、管理対象が増えるほど、権限設定や棚卸しは複雑になりやすい構造でした。
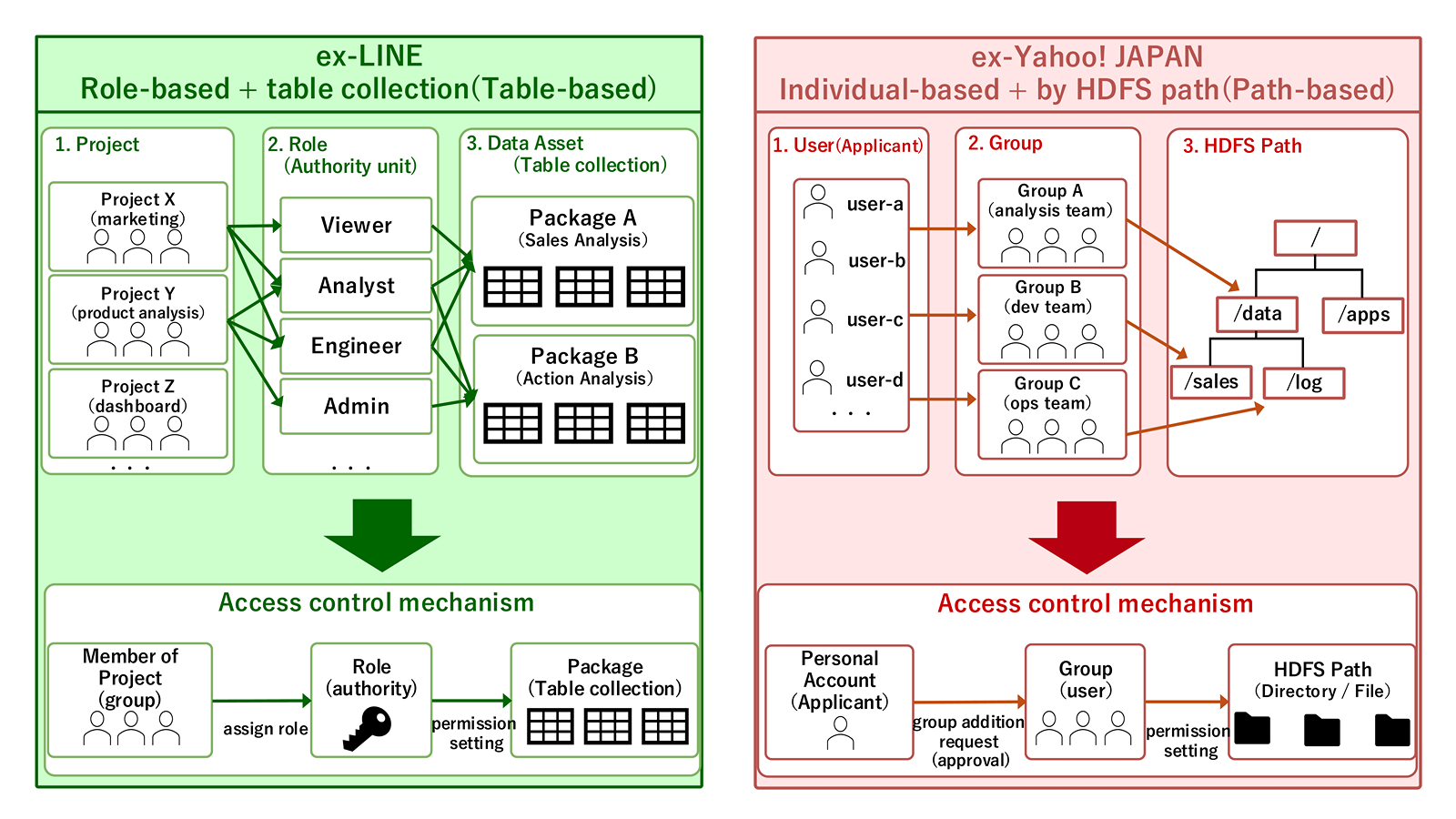
つまり、両者は単に利用している仕組みが異なっていたのではなく、「誰に」「何に」権限�を付与するかという前提そのものが異なっていました。
また、Tableベースの管理モデルは、権限管理や棚卸しを一貫した単位で扱いやすく、ガバナンス運用とも相性が良かったため、旧ヤフーのデータ管理も可能であればTableベースの権限管理モデルへ寄せていきたいというモチベーションがありました。
しかし、すでに保存・運用されている旧ヤフーのデータを、HDFS Pathベースの管理からTableベースの管理へ移行すること自体が大きな課題でした。既存データの多くはHDFS Path前提で運用されており、Tableベースへ移行するには、データ配置、テーブル構造、ジョブ、運用フローの見直しが必要でした。
そのため、利用者側・基盤側の双方にとって非常にコストの高い取り組みになると想定されました。
移行方法と設計の検討
こうした背景があったため、旧ヤフーのデータ基盤に旧LINEの権限管理をどう導入するかは、既存データ構造をどう扱うかも含めた設計課題として検討する必要がありました。
検討した移行方法は、大きく2つに整理できました。
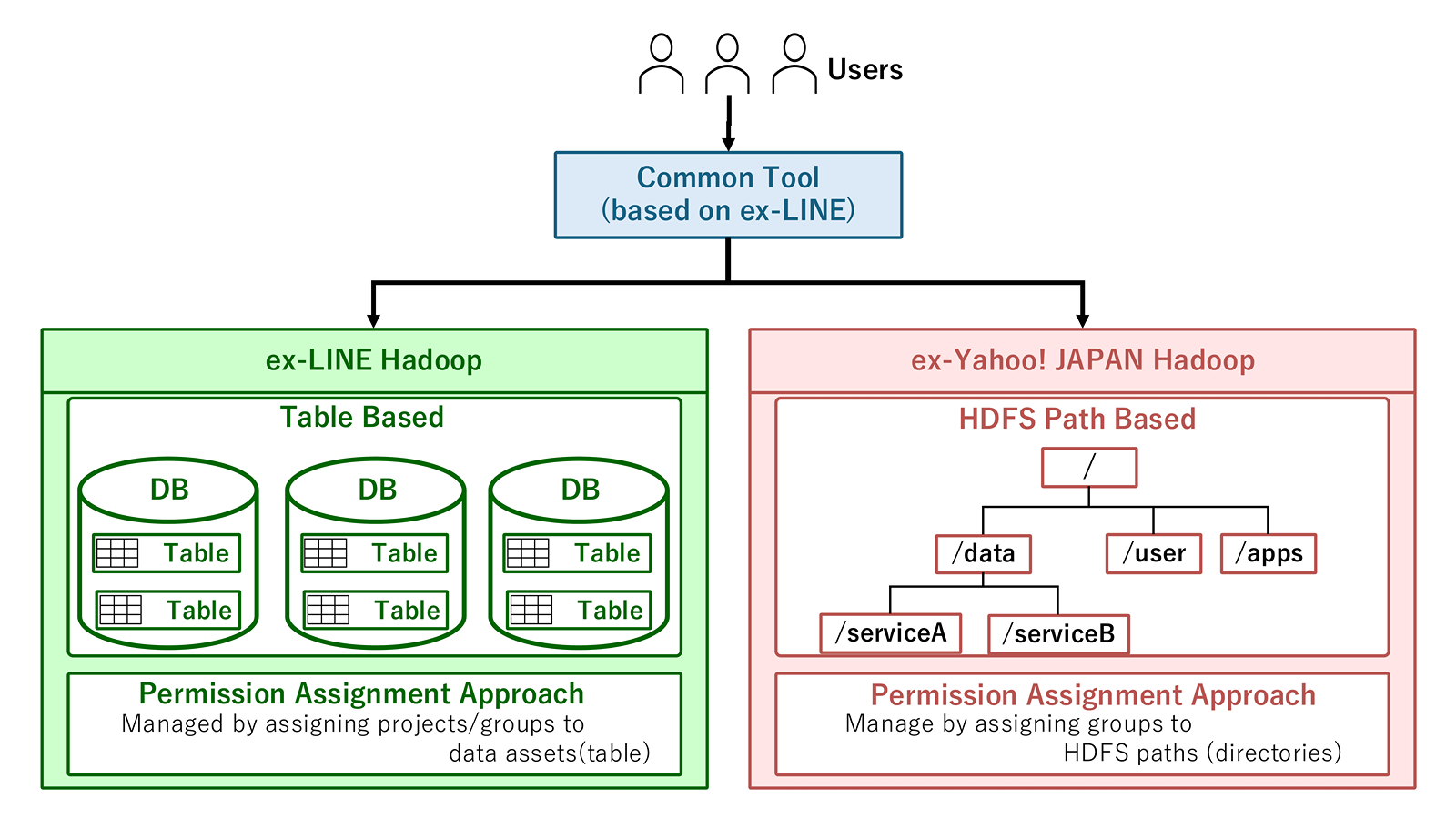
1つ目は、既存の旧ヤフー側の構造をできるだけ維持したまま、旧LINE側の権限管理システムへ対応させる方法です。
この案では、図に示すように、利用者から見ると、統合後の共通ツール・共通フローで権限管理できるようになります。また、利用者グループや申請フローを共通化することで、「誰が、どの役割・用途でデータへアクセスするのか」というロールベースの管理モデルへ合わせていくことも可能です。
ただし、データ管理単位そのものを統一するわけではありません。内部的には、旧LINE側のTableベース管理と、旧ヤフー側のHDFS Pathベース管理が混在したままになるためです。
また、どのデータがどの粒度・どのルールで管理されているのかがわかりにくくなり、長期的には運用ルールや利用者体験が複雑化しやすいという懸念がありました。
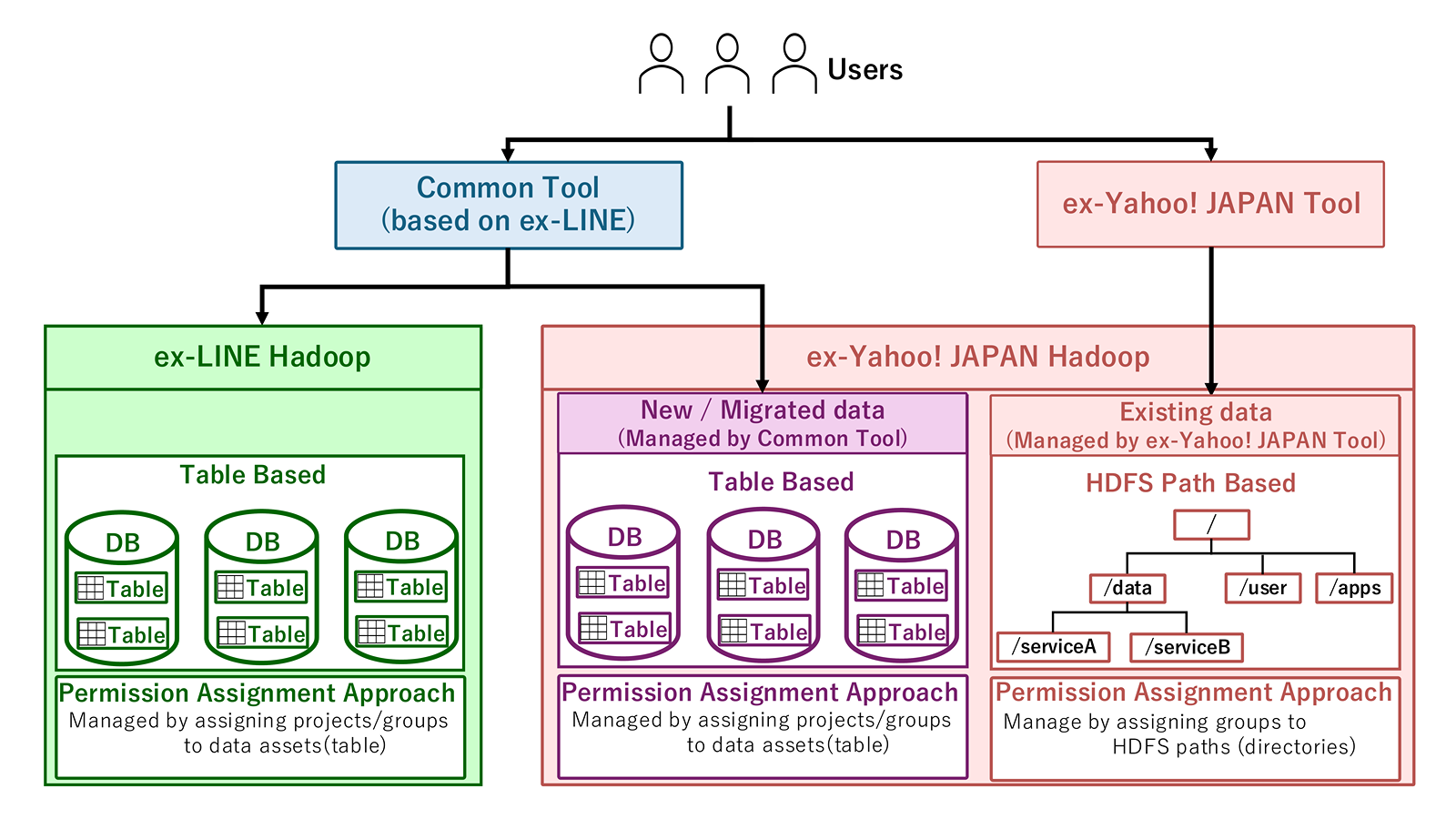
2つ目は、旧LINEの管理モデルに合わせた新しい領域を、旧ヤフー側に新設する方法です。
この案では、DB/Table単位で管理しやすい新領域を用意し、利用者は対象データを新領域へ移行します。これにより、図に示すように、HDFS Pathベースの既存領域と、Tableベースの新領域を明確に分離できます。
特に、Table単位へ管理方式を揃えることで、ガバナンス運用を一貫した形で扱いやすくなるメリットがありました。また、新規データや、基盤間でデータ連携が必要なものから先行して段階的に適用できるため、利用者側で移行負荷が発生するタイミングをコントロールできる点もメリットでした。
一方で、利用者側には、データ移行やTableの作り直しなどの移行負荷が発生します。
最終的な設計判断
最終的には、既存運用への影響を抑えつつ、権限棚卸しや監査対応を含む管理モデルを段階的に統一しやすくするため、案2を採用しました。
今回の取り組みで重要だったのは、管理モデルを一斉に全体へ適用することではなく、旧LINEと旧ヤフーの設計思想の違いを踏まえたうえで、ガバナンスと現実的な運用の両方を成立させることでした。これにより、既存運用を一斉に置き換えることなく、基盤をまたいでデータを扱う場合でも同じ考え方で権限を管理できる土台を築くことができました。
2.3. 基盤間でデータをどう連携するか
今回私たちが取り組んだテーマは、異なる設計思想や運用モデルを持つデータ基盤間で、認証・認可や運用統制を踏まえつつ、効率的かつ実運用可能な形でデータ連携する方法です。
データ連携の概観
これまで、旧LINEと旧ヤフーの基盤間でデータを連携する際には、データ基盤とは別の環境に用意したデータ交換機構とAmazon S3を介してデータを受け渡す構成を採っていました。この方式は、基盤同士を疎結合に保てる一方で、利用手続きや運用調整、利用コストの面で課題を持っていました。
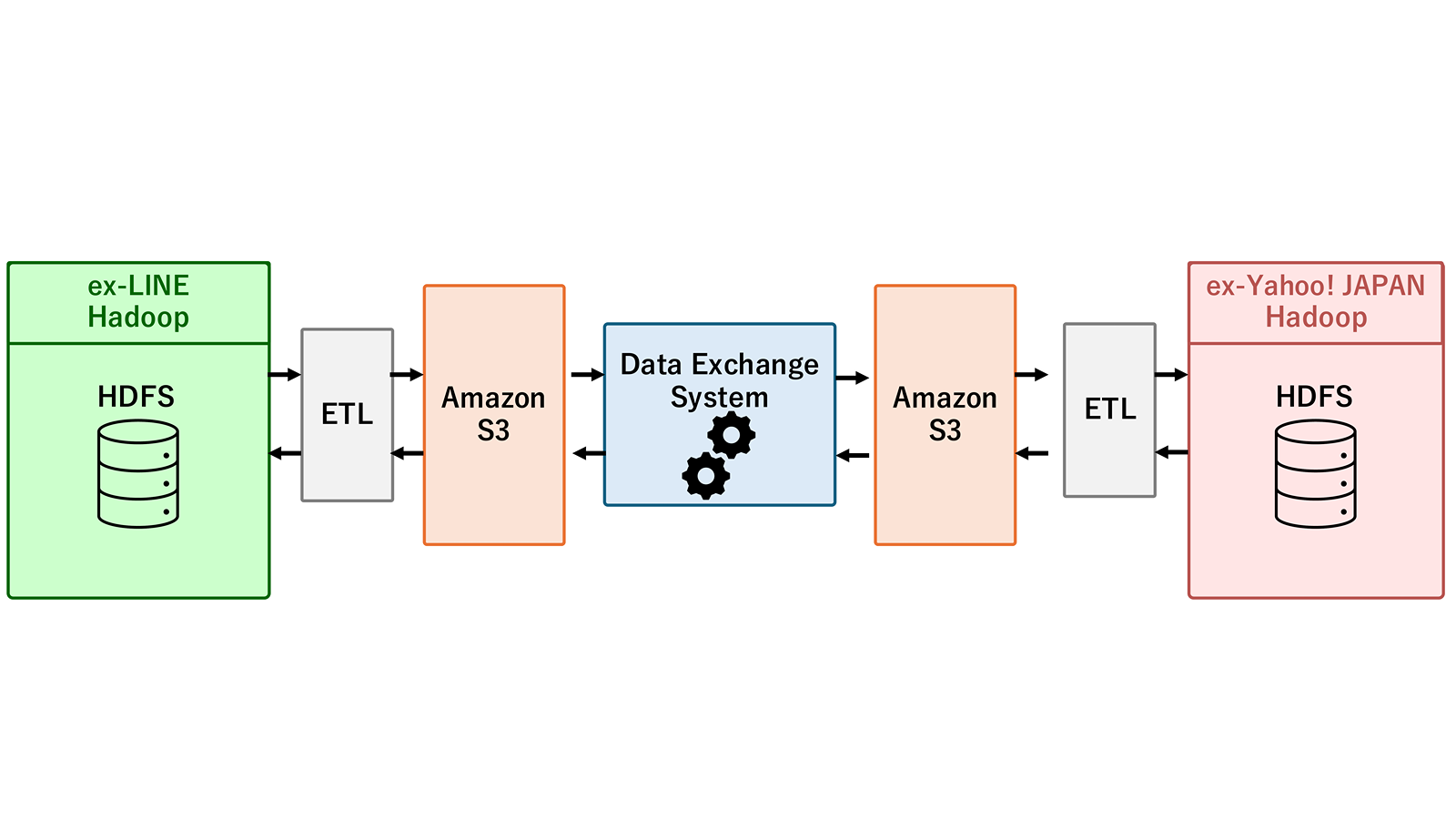
私たちは、よりシンプルで迅速なデータ転送方式としてDistCPの活用を検討しました。DistCPは、Hadoop環境で大容量データをクラスタ間に並列分散コピーするための標準的な仕組みです。
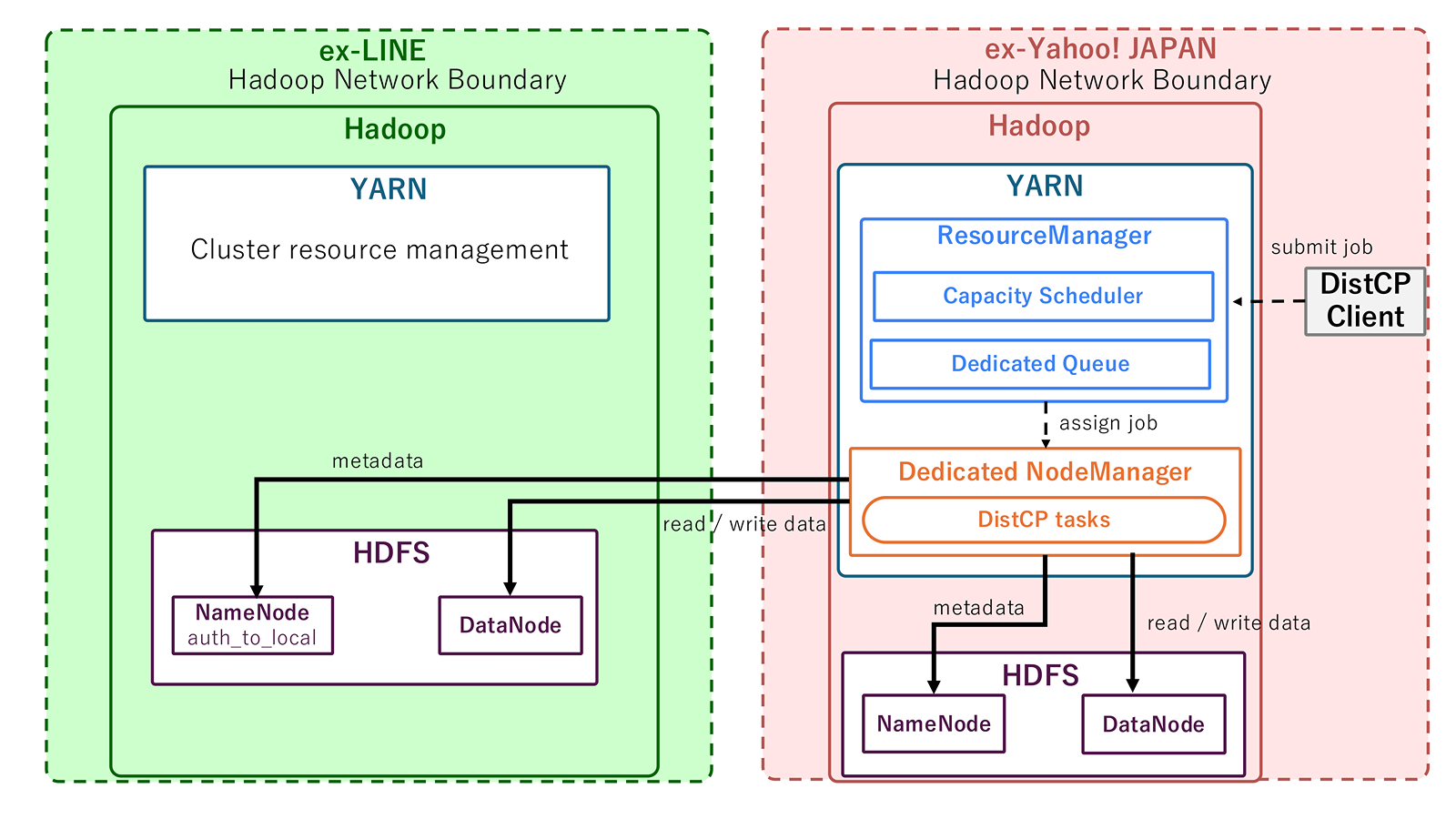
今回、DistCPを使って基盤間を直接接続する際には、転送経路を開通させることに加え、認証・認可や運用統制、そして技術面の整理を行うことが必要でした。ここでいう認証とは「アクセスしてきた主体が誰かを確認すること」、認可とは「確認された主体に何を許可するかを定めること」です。
認証・認可について
認証については、旧LINEと旧ヤフーそれぞれのHadoopクラスタでKerberosによる認証を行っていることから、それぞれのクラスタにあるKerberos KDCの認証機構をそのまま使い、誰としてアクセスしているかを特定することを前提にしました。
今回、特に重要だったのは、異なるKerberos Realmをまたいで認証を成立させることでした。このため、Cross-Realmを前提とした構成を採用しました。旧LINEと旧ヤフーはそれぞれ独立したKerberos KDCを持っており、それぞれで認証を行っています。この仕組みを生かすため、それぞれのRealmの認証を信頼して活用する必要があります。Kerberosには、この目的のためにCross-Realmという仕組みがあります。KDC同士が信頼関係を結ぶことで、お互いのRealmを信頼できるようにするものです。
加えて、DistCPの利用を許可されたアカウントについては、旧LINEと旧ヤフーのHadoop環境で利用するアカウント名を同一に揃える対応を行いました。これはクラスタ間のアカウント名のずれを抑えるだけでなく、Hadoopの周辺システムでも同じ主体として扱いやすくするための前提を整えました。
認可については、会社として許可されたデータのみを転送するポリシーに基づき、実行可能なアカウントを絞る設計を採りました。
具体的には、ジョブの実行を管理するCapacitySchedulerにDistCP専用のキューを用意し、このキューにジョブを投入できるアカウントを制限しています。また、DistCP元のクラスタとDistCP先のクラスタでアカウントが1:1対応になるように、Kerberosのauth_to_localを用いてアカウント名を揃える対応を行いました。
技術面での整理
技術面では、OSI参照モデルのLayer 1〜Layer 7の接続性と制約、帯域管理が論点になりました。特に注意したのはLayer 4とLayer 7です。
Layer 4では、DistCP専用キューにひもづく専用のNodeLabelを用意しました。専用のNodeLabelがない状態でDistCPジョブを実行した場合、他のHadoopクラスタ利用者と同じNodeManager上でジョブが実行されます。DistCP実行時の通信経路がクラスタ利用者全体と重なるため、通信経路を限定することができません。専用のNodeLabelが付与されたNodeManagerのみをクラスタ間で接続可能にして、他のNodeManagerはネットワークACLで接続を遮断しました。これにより、専用キューへのジョブ投入を許可されていないアカウントが他のキューでDistCPジョブを投入しても、通信がLayer 4で遮断��され、ジョブが失敗します。
Layer 7では、KerberosのCross-Realmを成立させることに加え、クラスタ間のDistCP時にエラーになるポイント(今回の場合は、HDFSの最低ブロックサイズの差異など)を揃えるように注意しました。また、相互接続する環境ごとにネットワークルールやACLの考え方が異なるため、必要な通信をレイヤーごとに洗い出し、どの通信を開通させる必要があるかを整理しました。
実際に構築を行う中で、相互ネットワーク上で同じIPアドレスが使われている箇所も見つかり、衝突を避けるためにIPアドレスが重ならない場所にKDCを再構築するなど個別の準備も必要でした。加えて、データ基盤間連携を現実に動かすには、事前に対象のHadoopクラスタ、クラスタ間で相互接続されるサーバ、サーバに適用されるネットワークACLおよびその変更方法、ジョブの投入および実行経路などを具体的に棚卸ししておくことが重要でした。また、旧LINEではViewFSを用いているため、マウントテーブルを含むクライアント設定ファイルを正しく配布し、転送対象のパスが期待するNamespaceへ解決されることを確認する必要がありました。
本番環境と検証環境のどのクラスタ同士を接続対象にするのか、DistCPに必要な設定差分は何か、どこからジョブを投入できるのかを整理していくことで、単なる「接続できる・接続できない」ではなく、実際に運用できる構成に落とし込むことができました。
また、帯域管理も重要な観点です。旧LINEと旧ヤフーのHadoopクラスタは異なるデータセンターにあるため、WAN回線に過度な負荷をかけないよう、スモールスタートを基本方針に置き、DistCPジョブの並列度や帯域上限を調整しながら、通常トラフィックに影響を与えない水準で段階的に運用できるようにしました。
運用面での整理
統制の観点では、仕組みだけでなく利用開始までの運用フロー整備も重要でした。
実運用では、DistCP導入相談の中でセキュリティ責任者やネットワーク担当者への相談に加え、転送対象データの利用目的やプライバシーへの影響といった観点から、必要に応じて法務担当者にも確認することとし、データ転送に必要な各種設定をまとめて行うフローを整備しました。
データ基盤間連携で重要なのは、単に「データを運べること」ではないという点です。誰が、どの権限で、どの経路を通って、どの範囲のデータを扱えるのかを、認証・認可・運用統制・ネットワーク設計まで含めて俯瞰することが欠かせません。
DistCPは強力でシンプルな仕組みですが、異なる背景を持つデータ基盤間で生かすには、その周囲にある制約や運用フローまで含めて設計して初めて、効率的かつ実運用可能なアーキテクチャになります。
2.4. まとめ
組織統合におけるデータ基盤間連携では、単にデータを運べるようにするだけでは不十分でした。実際には、基盤間で安全かつ継続的に連携できる経路を整備し、そのうえで権限管理やガバナンスをどう整えていくかが重要でした。
今回の取り組みでは、まずは連携可能な経路を整え、その利用を適切な統制のもとで運用できるようにすることで、現実的な前進を図りました。
その結果、基盤間のデータ利活用を進めるための土台を築くことができました。
未来への展望
今回は、旧LINEと旧ヤフーがそれぞれ持つ大規模なデータ基盤について、クラスタの規模増大に伴う運用課題と、組織統合に伴う基盤間連携の課題を紹介しました。
どちらにも共通していたのは、単に規模を大きくすることや、単に接続経路を作ることではなく、実運用に耐えられる形へ一つずつ落とし込む必要があったという点です。
容量、NameNode負荷、Namespace構成、権限管理、認証、ネットワーク、運用フローは、それぞれ独立した論点に見えます。しかし実際には、利用者が安全にデータを扱える状態を作るために、互いに影響し合う設計要素でした。今回の取り組みでは、それらを段階的に整理し、まずは既存基盤の特性を生かしながら連携できる土台を整えました。
一方で、データ利活用をさらに進めるための利便性向上、より安全かつ安心してデータ連携できる仕組みの改善、データ利活用の拡大に伴うスケーリングへの対応など、私たちのチャレンジはまだまだあります。
今後も、利用者が基盤の違いを意識せず、必要なデータを安全かつ自然に利活用できる状態を目指します。そのために、現在のデータ基盤間連携に残る制約を一つひとつ解きほぐし、より一体的な利用体験へ近づけていきます。さらに中長期的には、運用や技術の前提を揃えながら、基盤そのものも統合し、LINEヤフー全体としてより使いやすく信頼できるデータ基盤を目指します。
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記��事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の挑戦や積み重ねてきた知識を共有します。
YouTube LIVEでの配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


