はじめに
LINEヤフーで大規模データ処理基盤の開発を担当している浅沼と楊です。この記事では、秒間数万リクエストを処理する社内の HDFS(Hadoop Distributed File System)に Observer NameNode を導入し、クラスタの安定運用に大きく貢献した取り組みを紹介します。導入にあたっては RBF(Router-based Federation)との統合、Stale READ 問題への対応、msync 頻度のチューニングなど、いくつかの技術的課題を乗り越える必要がありました。本記事では、これらの課題と対応についても解説します。(社内 HDFS 基盤の全体像や基盤間連携については、こちらの記事をご覧ください。)
背景
LINEヤフーでは、全社共通の大規模な Apache Hadoop クラスタを運用しています。運用開始以来、データ量とリクエスト数は増加し続けており、規模の拡大に伴ってそれまで表面化していなかったさまざまな問題にも直面するようになりました。2022年末頃には、HDFS の管理サーバである NameNode に対するリクエスト数が秒間3万件を超えることもあり、クラスタ全体で遅延が発生する現象がたびたび見られるようになりました。この問題への対策の1つとして、Observer NameNode の導入検討を開始しました。
Observer NameNode とは
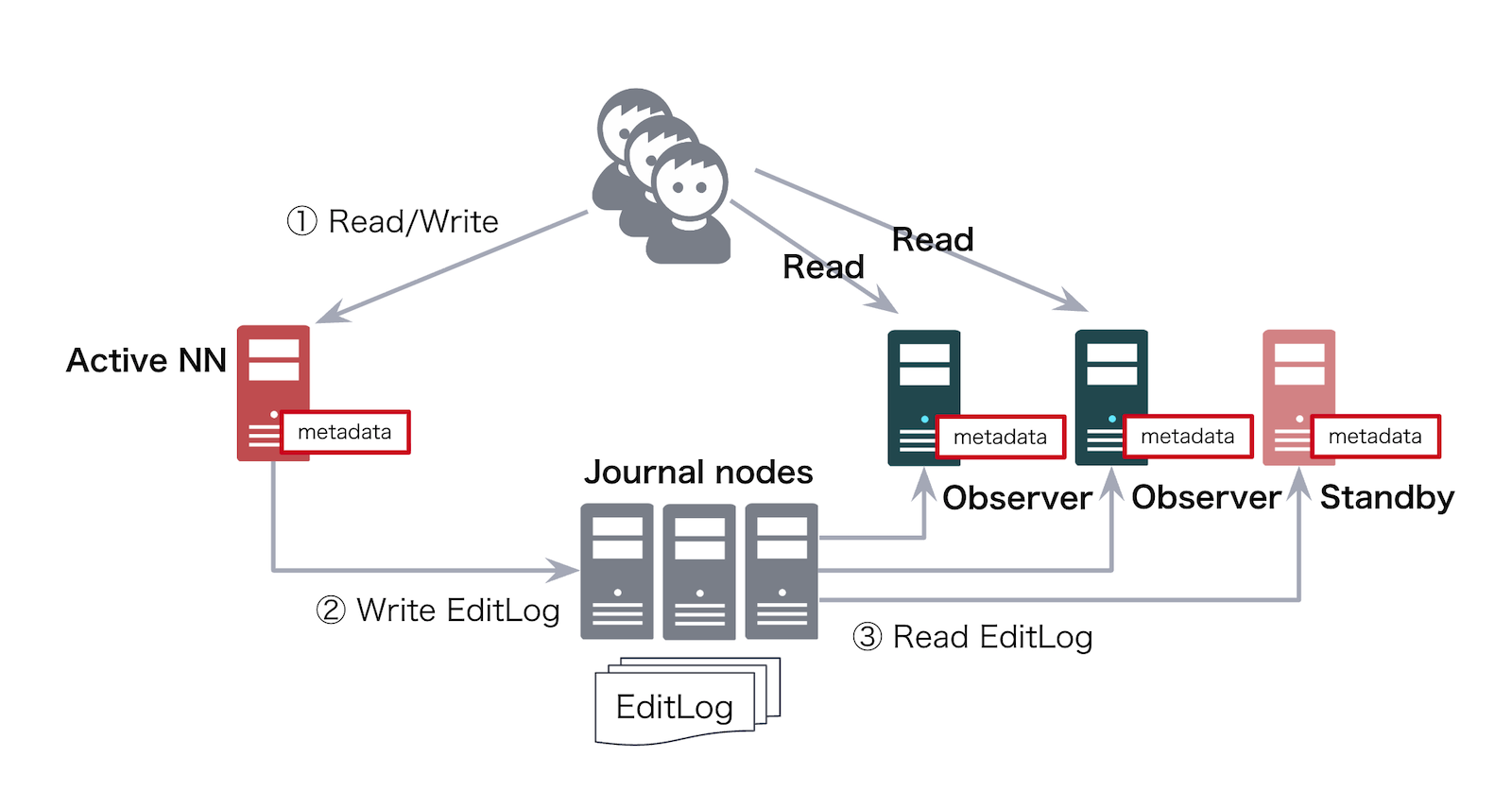
HDFS の管理サーバである NameNode は、Active 1台と Standby 複数台による HA 構成を組むことができます。Standby NameNode は Active NameNode のジャーナルログを読み続けることでメタデータを同期しています。Active NameNode がダウンした場合には、Standby NameNode のうち1台が Active NameNode に昇格することで高可用性を担保します。
一方で、Standby NameNode はクライアントからのリクエストには応答できません。すべてのリクエストは Active NameNode が受け取って処理するため、リクエスト数が増加すると Active NameNode がボトルネックになります。
そこで登場したのが Observer NameNode です。Observer NameNode は、2019年頃に Hadoop コミュニティで開発されました。Standby NameNode と同様に Active NameNode のジャーナルログを読み取り続け、Active NameNode と同じメタデータを保持します。
Standby NameNode との違いは、Observer NameNode はクライアントからの READ リクエストに応答できる点です。一般的なワークロードでは READ が大半を占めるため、READ リクエストだけでも Observer NameNode が受信して処理できれば、Active NameNode の負荷を大きく緩和できます。
RBF (Router-based Federation) と Observer NameNode の統合
社内の Hadoop クラスタには、2020年に RBF (Router-based Federation) を導入しました(解説記事)。RBF は Router というコンポーネントが複数の NameNode(HDFS)を束ねることで、ユーザーからは1つの巨大な HDFS クラスタに見せる機能です。社内の HDFS へのアクセスは Router 経由が前提となっているため、Observer NameNode を導入するには、Router 経由で Observer NameNode にアクセスする必要があります。
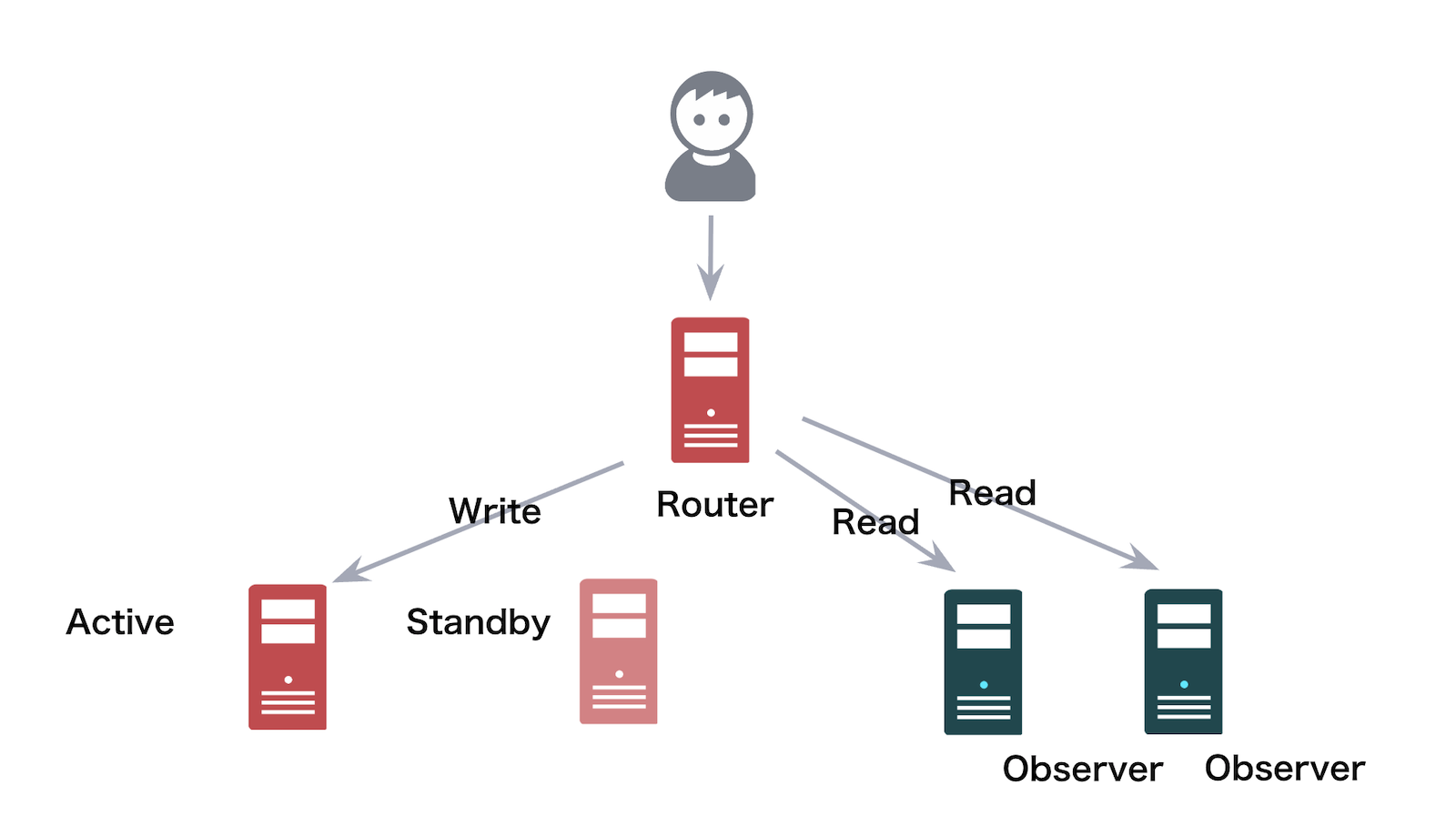
しかし当初は Router と Observer NameNode を組み合わせて利用することができず、導入は見送っていました。その後、2022年末頃に Hadoop コミュニティで Router 経由で Observer NameNode を参照できる機能の開発が始まりました。これに合わせて、社内でもこの機能を導入し、関連するパッチをすべてバックポートする方針をとりました。(主要な JIRA は HDFS-13522 と HDFS-16767 です。設計に関するディスカッションや資料を見ることができます。)
なお、Router 経由で Observer NameNode に READ リクエストを行うためには、クライアント側のライブラリもアップグレードする必要があります。社内には複数の Hadoop クライアントが混在しており、すべてを一度に対応させるのは困難だったため、特に READ リクエストの多い Trino と、今後ユーザー増加が見込まれる Spark3(Hadoop3)系クライアントのみを優先してアップデートする方針にしました。(アップデートしなかった Hadoop クライアントは、従来どおり Active NameNode に READ リクエストを送ります。)
Stale READ 問題の対応
2023年末に本番導入したところ、想定どおり Active NameNode の負荷が落ち着きましたが、その一方で、Observer NameNode 特有の問題である Stale READ にたびたび遭遇するようになりました。Stale READ とは、Active NameNode のジャーナルログが Observer NameNode に反映・同期される前に、クライアントが Observer NameNode に対して READ リクエストを送信し、古いメタデータを参照してしまう問題です。Stale READ が発生するとジョブの結果にデータ欠損などの不整合が生じ、クライアント側で再実行や不整合箇所の特定が必要になります。
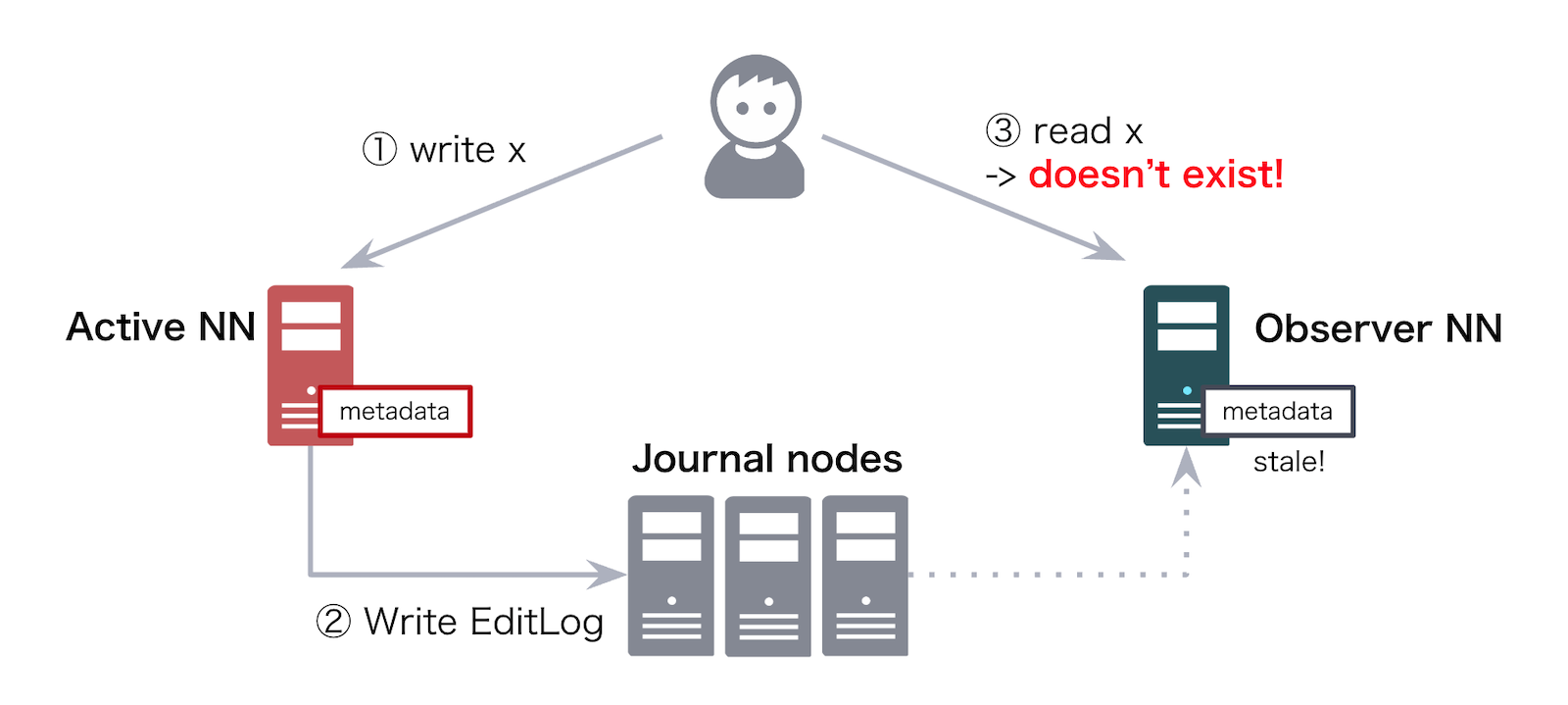
この Stale READ 問題を回避するために、HDFS には msync という API が実装されています。
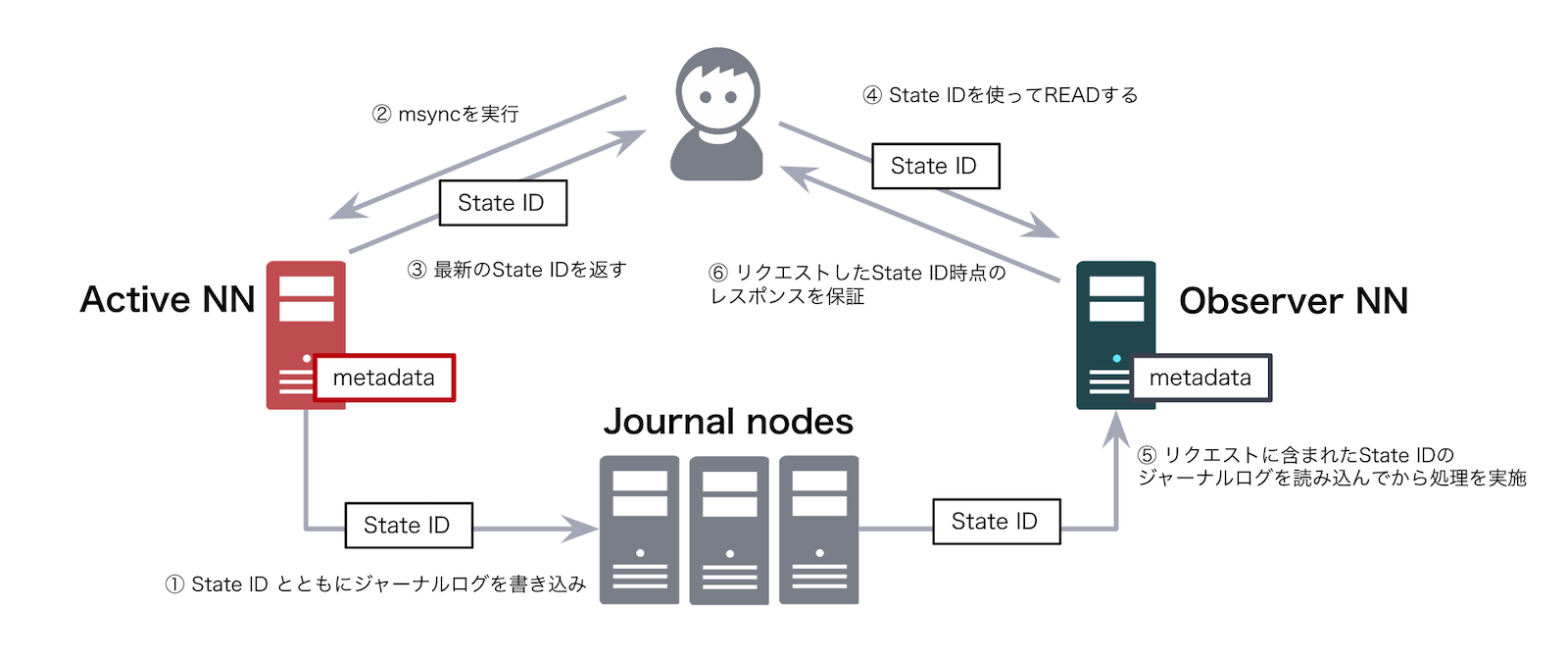
- Active NameNode は何らかの操作が行われるたびに、ジャーナルログとその ID である State ID を記録しています。
- まず、クライアントが Active NameNode に対して msync を実行します。
- Active NameNode は最新の State ID を返します。
- クライアントはその State ID を付与して Observer NameNode に READ リクエストを送信します。
- Observer NameNode は自身のメタデータがその State ID に到達するまで待機します。
- これにより、その State ID 以降の状態に基づくレスポンスが保証され、Stale READ を回避できます。
(※ 実際の構成には Router が含まれますが、上の図では単純化のため省略しています。)
Stale READ のパターン1
msync 自体は最新の State ID を返すだけの軽量な処理ですが、Active NameNode へのリクエストが必要です。Active NameNode の負荷を軽減するために、導入当初のデフォルト設定では msync を無効化していました。msync をいつ実行するかはアプリケーション側の実装に委ねられますが、Trino や Spark は msync を考慮した実装になっておらず、どちらのジョブでも Stale READ に遭遇しました。
Trino も Spark も、ジョブの実行結果を一時ディレクトリに書き込み、最後のコミット時に一時ディレクトリ内のファイルをリストアップして最終的な出力先へ rename します。このリストアップのタイミングで Stale READ が起きると、本来対象となるはずのファイルがリストから漏れ、最終ディレクトリへ移動されず、その結果データ欠損が発生します。
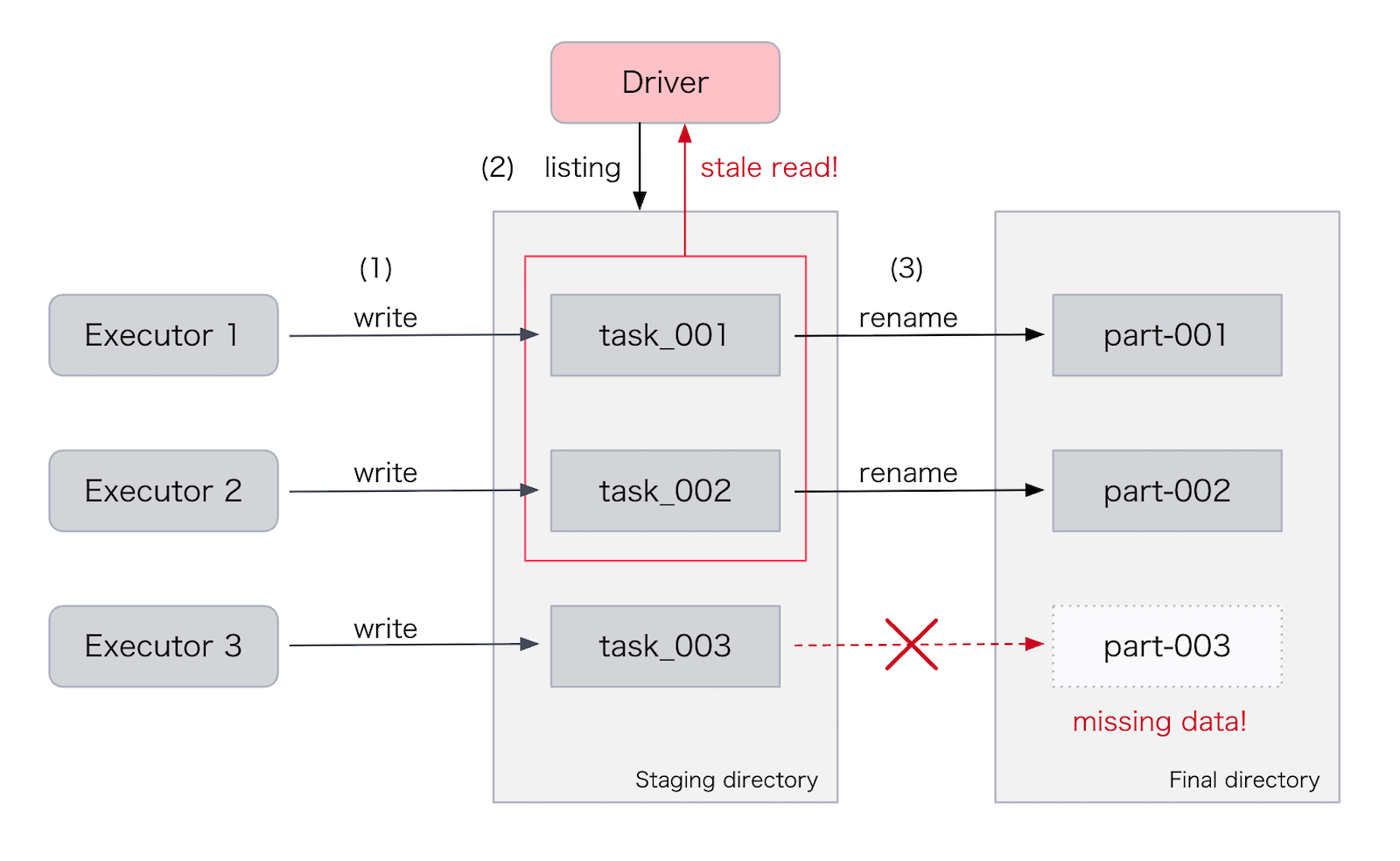
そこで msync の設定を見直し、すべての READ リクエストの直前に必ず msync を実行するようにしました。具体的には msync を実行する間隔を決める dfs.client.failover.observer.auto-msync-period.<nameservice> を 0 に設定しました。
Stale READ のパターン2
設定見直し後も、極めてまれではあるものの、Stale READ が発生することがありました。さらに原因を調査した結果、Hadoop クライアントの基盤である Client.java において、RPC 処理の順序に問題があることがわかりました。このバグにより、次の2パターンの不具合が発生していました。
- Router が Active NameNode から最新の State ID を受け取っているにもかかわらず、それより古い State ID をクライアントに返してしまう
- クライアントが Router から最新の State ID を受け取っているにもかかわらず、それより古い State ID を使って次のリクエストを実行してしまう
Client.java における RPC の処理順序を見直したことで、常に新しい State ID が正しく転送されるようになり、整合性を保て��るようになりました。この問題は HDFS-17156 としてコミュニティにも報告し、修正パッチをコントリビュートしました。
msync 頻度のチューニング
2025年に入ると再び NameNode の遅延が発生するようになりました。1日あたりのリクエスト総数で見ると、2020年から2025年にかけて約4倍に増加しており、高負荷時には秒間7万リクエストに達することもありました。調査の結果、HDFS に対するリクエストの待ち行列である CallQueue に、msync のリクエストが大量に蓄積していることがわかりました。前述のとおり READ ごとに msync を実行するようにしていたことに加え、社内クラスタ統合の影響などでユーザー数も増加していたため、Active NameNode に対する msync リクエスト数が急増し、再び処理しきれない状態になっていました。
そこで Spark/Trino における msync の設定を改めて見直したところ、ジョブの前段にあたる Spark Executor / Trino Worker については頻繁に msync を実行しなくても整合性を保てるケースが多く、msync 頻度をかなり緩和できることがわかりました。一方、最終的なジョブコミットを行う Spark Driver / Trino Coordinator は厳密な整合性が必要であり、そのタイミングで確実に最新状態を参照できれば十分です。
下記に社内のクラスタに反映した設定値を示します。hdfs-site.xml で msync 頻度の値を変数化しておき spark-defaults.conf の defaultJavaOptions でその変数を上書きします。
| 設定ファイル | 設定項目 | 設定値 | 補足 |
|---|---|---|---|
hdfs-site.xml | dfs.client.failover.observer.auto-msync-period.<nameservice> | ${msync.period} | msync の実行間隔を変数化 |
hdfs-site.xml | msync.period | 0 | 変数のデフォルト値 |
spark-defaults.conf | spark.driver.defaultJavaOptions | -Dmsync.period=0 | Driver ではすべての READ の直前に msync を実行 |
spark-defaults.conf | spark.executor.defaultJavaOptions | -Dmsync.period=1000ms | Executor では State ID が1秒以上古ければ msync を実行 |
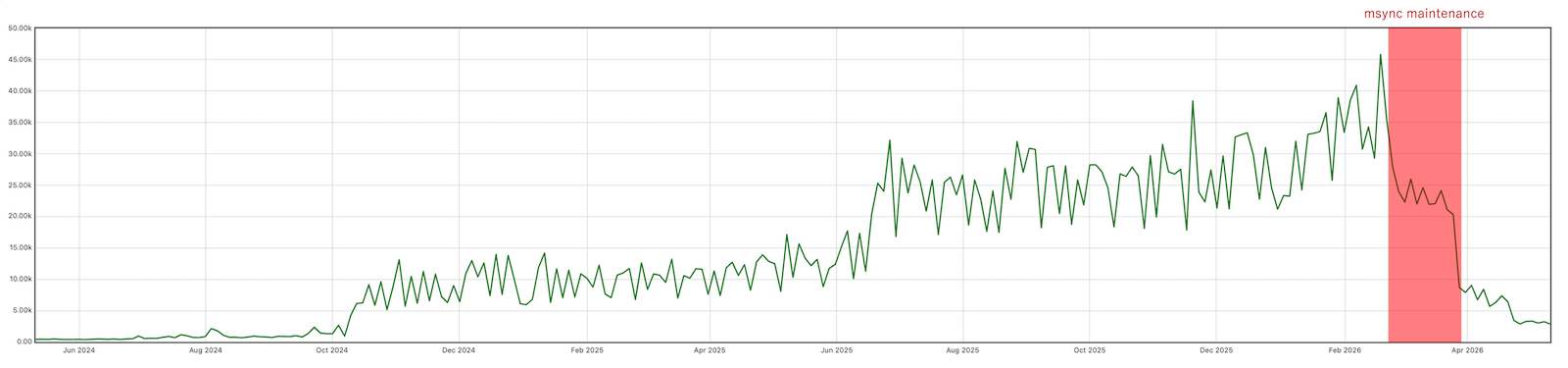
下の図は過去2年間における1秒あたりの msync 数を示したグラフです(見やすくするため24時間平均で表示しています)。2025年は msync 数が増加し続けていましたが、このチューニングにより整合性を保ちながら約80%削減できました。
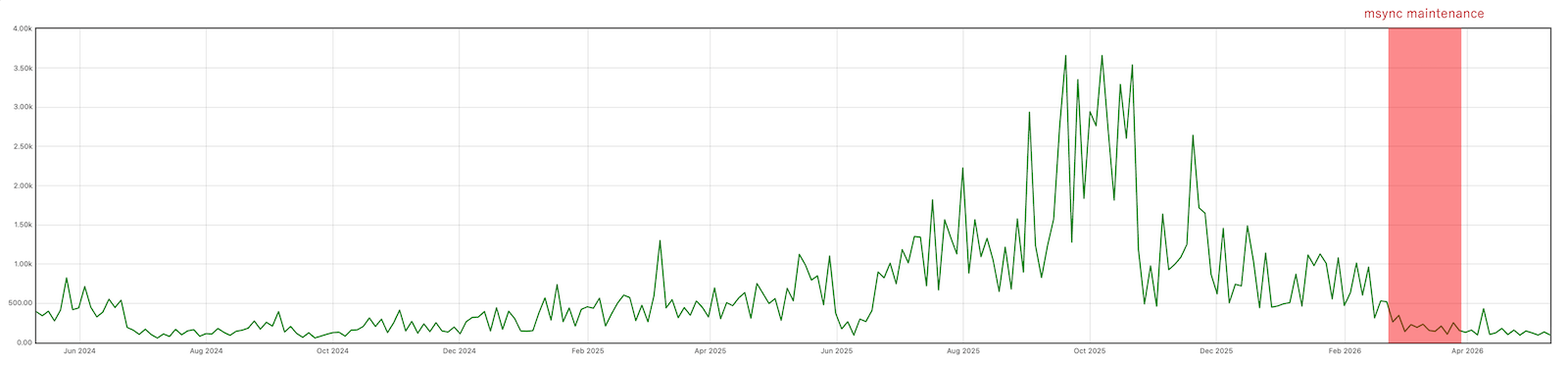
次の図は Router における RPC リクエストのキュー待ち時間(90パーセンタイル)をミリ秒で示したグラフです(こちらも24時間平均で表示しています)。msync 数の増加に伴ってキュー待ち時間も伸びており、特に2025年の中旬以降は HDFS が顕著に遅延していたことがわかります。msync 数の減少に伴ってキュー待ち時間も落ち着き、安定していた2024年頃の状�態にまで回復しました。
おわりに
社内の大規模 Hadoop クラスタにおいて、Observer NameNode の導入は Active NameNode の READ 負荷軽減に大きく貢献しました。導入後はさまざまなトラブルにも遭遇しましたが、着実な原因調査、バグ修正、そして適切な設定値のチューニングにより、最終的には高い安定性と性能を備えたストレージサービスを提供できるようになりました。
ただし、現在でもまれに WRITE 負荷が高いジョブが集中すると Active NameNode がボトルネックとなり、クラスタ全体の遅延につながることがあります。Observer NameNode は READ リクエストを分散する機能なので、WRITE 負荷に対しては根本的な解決にはなりません。
この課題に対して、2026年4月にリリースされた Hadoop 3.5.0 には NameNode 自体の性能を改善するいくつかの新機能が含まれています。
- Finer-grained Locking : NameNode のロック機構をより細かい粒度に分割することで、Active NameNode 自体のスループットを向上させる機能です。3段階の実装が予定されており、Hadoop 3.5.0 の時点では第1段階の実装まで完了しています(詳しくは HDFS-17366 を参照)。
- Java 17 対応 : Hadoop 3.5.0 では Java 17 の対応が完了し、Java 8 のサポートは廃止されました。Java 17 では ZGC や Shenandoah GC などのより高機能な GC アルゴリズムが利用可能であり、Active NameNode のレイテンシの改善や長時間のGCの回避が期待できます。
Hadoop 3.5.0 の導入も見据え、LINEヤフーでは引き続き OSS コミュニティと連携を取りながら、安定した大規模データ基盤を運用していきます。


