This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
When agents write the code
Coding agents iterate fast. At their pace, slow steps in the development loop, like CI roundtrips and environments that take an afternoon to provision, become the bottleneck.
The experience with agents can be hit or miss, too. It's great when they work, but they also get things wrong. In our case, they wrote code that wouldn't compile, referenced APIs that didn't exist, and made design decisions mid-implementation because no one had pinned them down.
This wasn't just us. The same prompt can produce different output on different runs[1]. Output is fragile in ways that make broad claims about agent capability hard to pin down[2]. Different developers report very different experiences with the same tools[3]. AI speeds up coding[4], but also generates code faster than developers can meaningfully review[5]. Even measuring what good agent output looks like is still an open research question[6], [7].
So how do we keep software reliable as AI contributes more to the code? We believe that the same things that have always supported reliable software will matter more. Most of all, developer expertise and attention to detail, but also tests, linters, fast local environments, and upfront design. Without them, agents stall on problems that should have surfaced earlier.
In this post, we share the practices we put in place to address these challenges, drawn from building Flava API Gateway.
Flava API Gateway
Ever since the merger of the former LINE Corporation and the former Yahoo Japan Corporation, we at LY Corporation have been building Flava, an internal private cloud. Flava API Gateway is one of the products in that ecosystem: it enables teams to create, publish, and monitor web APIs.
The diagram below illustrates the rough architecture. Kong[8] serves as the data plane. Our control plane provides a multi-tenant RESTful API, so teams can configure and deploy their APIs independently.
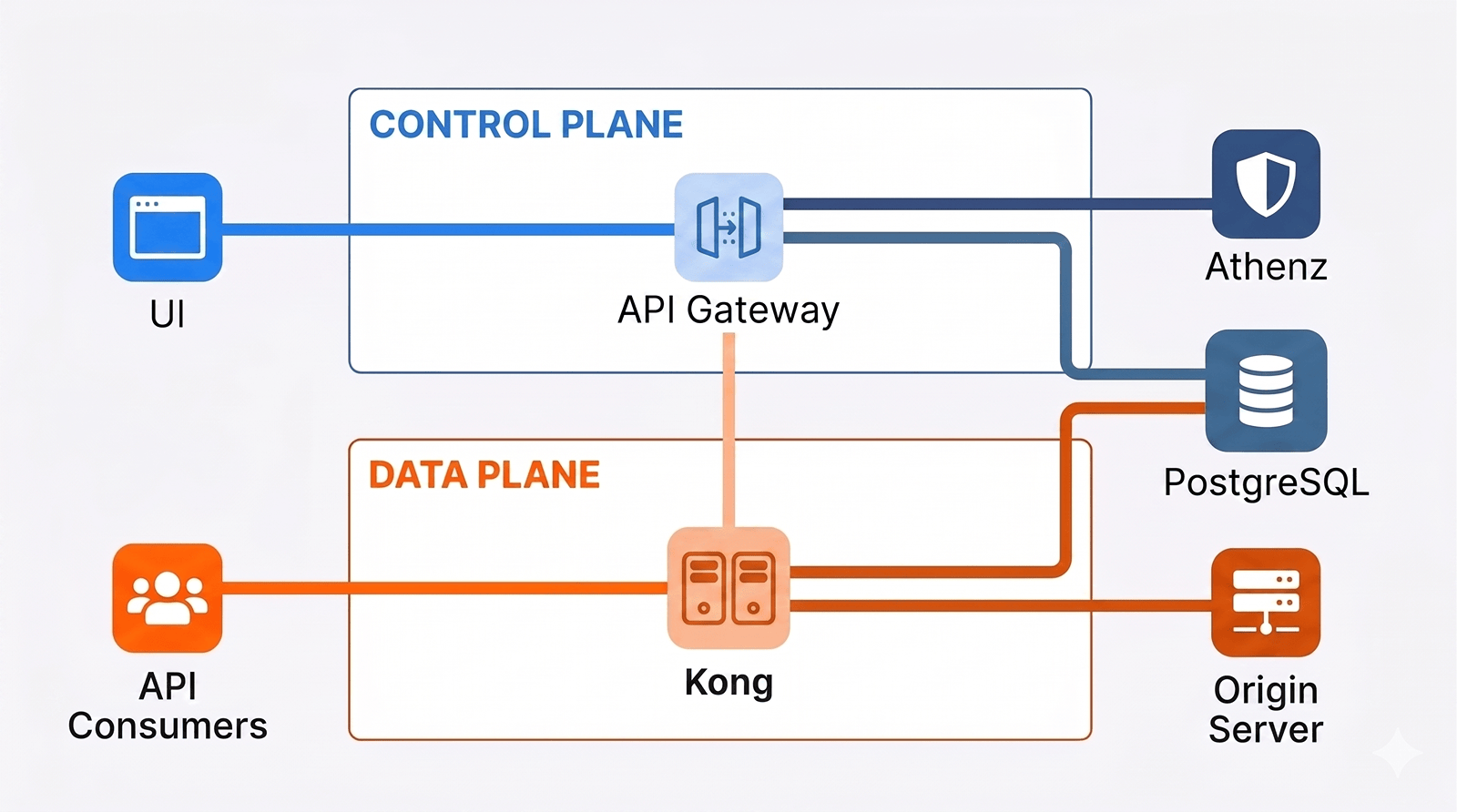
The Flava API Gateway team formed in mid-2025. At the time, agentic coding was quickly gaining traction within the company. As such, we considered how best to let the team benefit from AI without falling into its pitfalls. We landed on three practices that proved essential:
- Spec-driven development to keep agents aligned before they write a single line of code
- Automated verification so agents discover and fix their own mistakes incrementally
- A fast, hermetic local environment so the agent can run the full verification loop in seconds without waiting on CI
The sections below explain each in turn.
Align before the first line
As stated, a major challenge of agentic coding is the inconsistency in output quality. We felt this early on, where agents would start implementing before the design was settled, making their own design decisions and adding to non-determinism.
This is where spec-driven development comes in. It brings less ambiguity and more predictability to the output by explicitly laying out the design, approach, and the tasks for each change we want to make.
To go a bit deeper, let us explain how this process worked during the development of the control plane. We first started by writing the OpenAPI spec before any code, establishing the overall design upfront. We then broke it into smaller features, implementing each using OpenSpec[9], a tool that integrates with agents to assist with spec-driven development.
OpenAPI
OpenAPI[10] is the industry standard for describing REST APIs. We used it to define our control plane. The spec is what the agent is held against, giving us something concrete to catch when generated responses drift from the design. However, a spec that drifts out of sync is one that no longer holds agents to anything. Raw OpenAPI YAML is verbose and repetitive, and maintaining it by hand is a burden that lets specs fall behind in practice[11].
So rather than editing OpenAPI YAML directly, we used Nickel[12], a configuration language that's good at data validation and boilerplate reduction. With it, we wrote code to turn concise declarative descriptions of an API resource to a full set of CRUD endpoint specs. For example, the following snippet describes a path resource:
resources.path = {
description = "URL routes exposed by API Gateway.",
parent = "API",
editable = 'none, # no update endpoint: paths are created or deleted, not modified
timestamped = true, # auto-generates created_at & updated_at fields
properties = {
id = { schema = lib.uuid_for "path", sortable = true },
path = {
schema = lib.ref "#/components/schemas/PathTemplate",
create = 'required, # must be present in the POST request body
sortable = true, # enables ?sort=path in list queries
filterable = true, # enables ?path=<value> for exact-match filtering
filter_contains = true, # enables ?path.contains=<value> for substring filtering
},
},
}
From this, the CRUD generator produces the full set of endpoints: listPaths, createPath, getPath, deletePath. Each has pagination, sort and filter parameters, ETag headers for optimistic locking, and a consistent set of error responses.
A snippet of the generated spec:
/v1/projects/{project}/apis/{api_id}/paths:
get:
summary: List paths
operationId: listPaths
parameters:
- $ref: '#/components/parameters/Page'
- $ref: '#/components/parameters/Limit'
- $ref: '#/components/parameters/SortPaths'
- $ref: '#/components/parameters/Order'
- name: path
in: query
description: Filter by exact path
- name: path.contains
in: query
description: Filter by path (substring match)
responses:
'200':
description: Paths listed
'400':
$ref: '#/components/responses/BadRequest'
'401':
$ref: '#/components/responses/Unauthorized'
# ...
OpenSpec
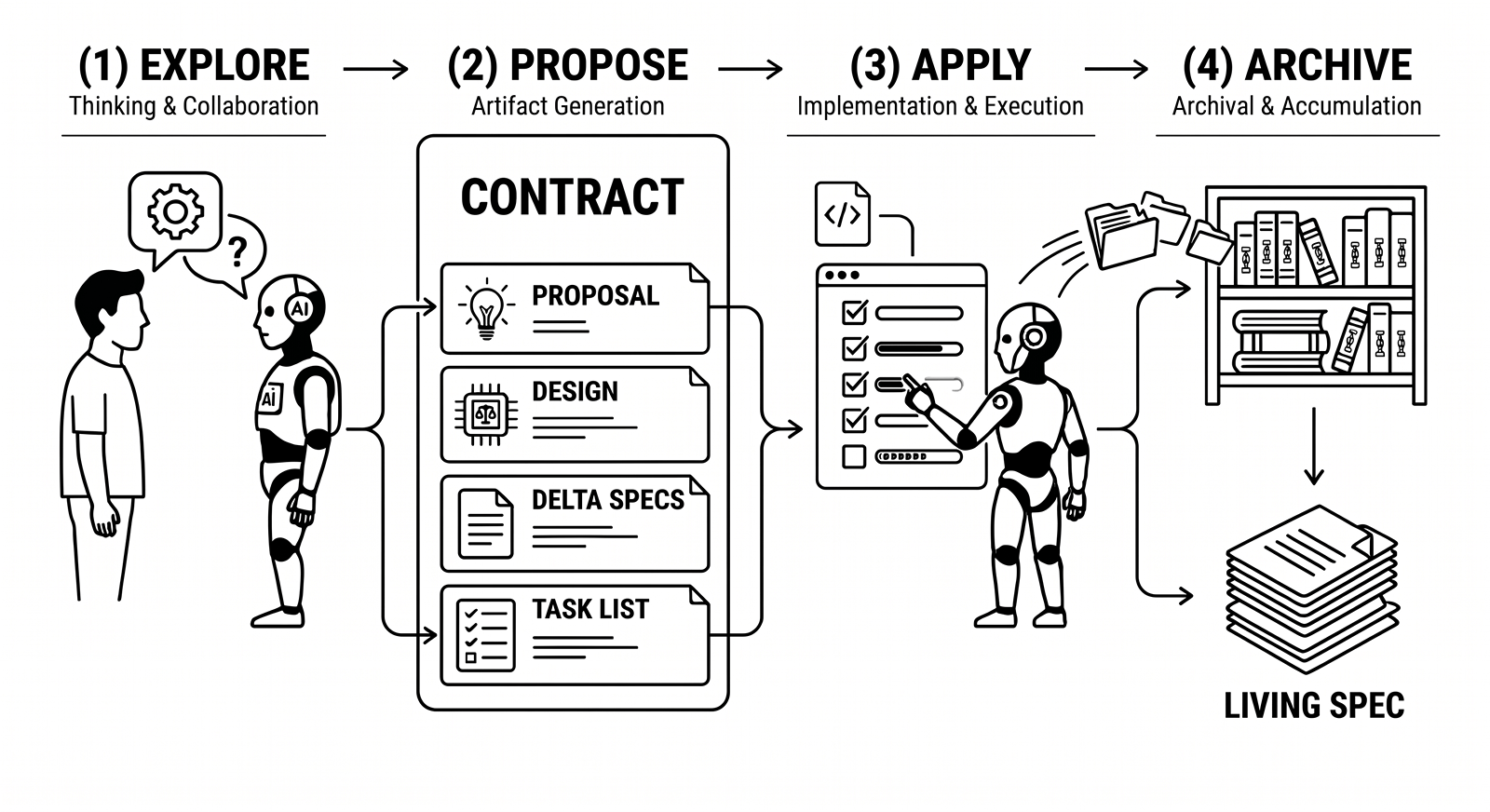
OpenSpec structures each feature change so the agent commits to a behavioral contract before writing any code. It does this through four artifacts:
- Proposal: The why and what
- Design: Technical decisions and trade-offs
- Delta specs: Per-change behavioral requirements written as Given-When-Then[13] scenarios
- Task list: Implementation steps broken down into a checklist
The workflow runs in four phases:
- The developer thinks through the feature with the agent. The agent guides the developer to surface underspecified details, edge cases, and design options.
- The agent generates all four artifacts.
- The agent works through the task list layer by layer, checking items off as it goes. This is when the implementation happens.
- Once all tasks are complete, the change is archived: delta specs are merged into the main spec library, creating a versioned record of the API's behavioral contracts. The delta specs accumulate over time into a living specification of the full system.
Let the agent catch its own mistakes
Coding agents often get things wrong on the first try. Code will not build and it can hallucinate APIs. Our initial instinct was to try to alleviate this somewhat by supplementing the prompt with a comprehensive list of pitfalls for agents to avoid. This was ineffective and likely made things worse. Studies show that as we add more constraints on the output, quality starts to break down[14]. What works instead is letting the agent discover and rectify mistakes on its own. The answer is verification.
When developing Flava API Gateway, we found automated tests and linters to be particularly well-suited to agentic coding. This is also echoed by research on applying TDD principles to LLM-based code generation[15]. Rather than front-loading all requirements onto the agent at once, tests and linters surface problems incrementally. When a test fails, it tells the agent exactly what broke and where. The agent fixes that specific problem, runs the tests again, and moves to the next failure. In this way, the agent receives just the right amount of feedback at the moment it is needed.
The same idea applies to how the agent invokes the loop. A single project skill bundles tests, linters, and formatters, and AGENTS.md[16] tells the agent when to load it. The skill's instructions reach the agent only when they apply, never on every turn.
Of course, the importance of automated testing and linting for code quality isn't anything new. But realistically, it's too often the first thing cut under deadline pressure. With agentic coding, we argue that they are no longer optional. During the course of development, it was a regular occurrence for the AI to run these checks and fail them during implementation. Finding these without the help of automated checks would've been more time consuming and likely negated productivity gains from AI use.
Historically, most of our previous projects relied on CI and shared testing environments for testing. Local provisioning of internal dependencies was too much work and tended to be fragile. When writing code by hand, this was friction we could live with. Developers were careful to minimize CI round-trips by getting code right before pushing. Agents cannot compensate in the same way. They iterate rapidly, and routing every attempt through a remote pipeline is unworkable. The wait is long, and agents lose context between attempts. Investing in a fully local environment eliminates both problems, with the agent getting immediate feedback and staying in a continuous loop without losing its place. Additionally, local dependencies make failures far easier to diagnose by making it possible to inspect logs and state directly.
Our full test suite of 2,754 tests spans three layers:
- Unit: Business logic in isolation
- Integration: Real PostgreSQL (constraints, triggers, soft-delete cascades, transactions), full in-process HTTP stack, OpenAPI spec conformance on every response
- End-to-end: Full system with real Athenz auth, Kong data plane, API key enforcement, multi-tenant isolation
For the agent to run it freely on every iteration, it needed to be fast. All of it completes in about 15 seconds on a developer machine. That speed required a conscious investment in parallelism, so we isolated test cases from each other as much as possible. For instance, rather than sharing and truncating DB tables between runs, each test package gets its own freshly created PostgreSQL schema with its own isolated set of tables.
Agent-generated code can diverge from the spec in subtle ways. To catch that, we wrapped every integration test server in a thin handler that runs spec conformance as part of the normal test pass. Here is a simplified version of the wrapper:
type specValidatingHandler struct {
t testing.TB // a reference to the running Go test
handler http.Handler
}
// ServeHTTP is invoked per request. It dispatches to the inner handler,
// forwards the recorded response to the caller, then validates it against
// the spec.
func (s *specValidatingHandler) ServeHTTP(w http.ResponseWriter, req *http.Request) {
rec := httptest.NewRecorder()
s.handler.ServeHTTP(rec, req)
// forward response to the real writer ...
validateSpecResponse(s.t, specRouter, req, rec.Code, rec.Header(), rec.Body.Bytes())
}
func validateSpecResponse(t testing.TB, router routers.Router,
req *http.Request, code int, header http.Header, body []byte) {
t.Helper()
route, pathParams, err := router.FindRoute(req)
if err != nil {
return // route not in spec; skip
}
err = openapi3filter.ValidateResponse(req.Context(), &openapi3filter.ResponseValidationInput{
RequestValidationInput: &openapi3filter.RequestValidationInput{
Request: req, PathParams: pathParams, Route: route,
},
Status: code,
Header: header,
Body: io.NopCloser(bytes.NewReader(body)),
Options: &openapi3filter.Options{IncludeResponseStatus: true}, // also fail on undeclared status codes
})
if err != nil {
t.Fatalf("response does not conform to OpenAPI spec: %v", err)
}
}
// setupTestServer is the constructor every integration test calls
// in setup to get an http.Handler. It always returns the wrapped one.
func setupTestServer(tb testing.TB /* , ... */) http.Handler {
appHandler := buildAppHandler(/* ... */)
return &specValidatingHandler{t: tb, handler: appHandler}
}
Each test calls setupTestServer in setup to build a request handler, http.Handler, then dispatches requests by calling ServeHTTP on it. Because the returned handler is the wrapper, every test response is validated against the OpenAPI spec, and any deviation in status code, headers, or body schema fails the test.
In addition to tests, linters take on greater importance in agentic workflows than in human ones. Human teams rely on informal conventions to enforce quality, such as code review culture, shared mental models, unwritten rules. However, coding agents have no access to any of those and will produce output inconsistent with the norms[17]. Explicit automated checks are the only conventions they can follow, so we put in as many as possible: Go linting via golangci-lint[18] with opt-out rather than opt-in rules, SQL and migration linting[19], [20], Semgrep[21] with builtin and custom rules. All of this ensures the agent gets feedback on these constraints as part of its normal loop.
Putting it together

Each change starts in the design phase. The developer explores the feature with the agent, surfacing edge cases and design options, and the agent generates the four OpenSpec artifacts. The Implementation phase then takes over with the agent working through the task list, running tests and linters after each change. Failures feed directly back into the next iteration. When everything passes, the delta spec is archived into the main spec library, leaving a permanent record of the behavioral contract. The result is a tight feedback loop where verification is part of every step.
Keeping the loop local
An important prerequisite for our approach to verification is the local developer environment. Comprehensive verification only stays in place if the environment that runs it is easy to set up and easy to change. A setup that takes too much effort to use will be skipped. One that is hard to modify falls out of date as the project evolves: new tools go missing, services fall out of sync, and developers start working around the environment rather than with it. In our case, running the full test suite locally requires PostgreSQL, a real Athenz auth service, and a set of linters and code generators, all at compatible versions wired together. We needed to make sure that the local developer environment managing all of this was as frictionless as possible.
Devenv[22], built on Nix[23], solves this. It provides a project-scoped shell where every developer and CI runner gets the same tools at the same versions with a single devenv shell command, on both macOS and Linux. Unlike a container or VM, the shell layers on top of the host environment rather than replacing it, so developers keep their usual editor, dotfiles, and workflows. Combined with direnv[24], the shell loads automatically whenever we enter the project directory.
What makes this particularly useful is that Nix serves as a single language for packages, services, and configuration (such as environment variables or generated files). For example, our control plane is written in Go. With Go projects, gopls[25] is the standard language server that editors and agents rely on for completion, navigation, and diagnostics. Each developer normally has to install and configure it for the tools they use. Devenv lets us do that once in the repo, so everyone gets the same setup.
The snippet below builds a gopls wrapper inline as a Nix package and plugs it directly into Devenv's languages.go module, which puts gopls on PATH in the dev shell. The wrapper feeds project-specific flags into the real gopls binary, so editors and agents pick up the right configuration without per-developer setup.
# A function that takes an existing gopls package as its argument and returns a
# wrapped gopls package that includes a custom gopls binary with -tags=extdep
# always injected.
wrapGopls = gopls: pkgs.runCommand gopls.name
{
nativeBuildInputs = [ pkgs.makeWrapper ];
# Not essential to the concept. Included so the wrapper works with
# languages.go's expectations.
passthru.override = lib.setFunctionArgs (args: wrapGopls (gopls.override args))
(lib.functionArgs gopls.override);
}
''
mkdir -p "$out/bin"
makeWrapper ${lib.getExe gopls} "$out/bin/gopls" \
--suffix GOFLAGS ' ' -tags=extdep
'';
languages.go.lsp.package = wrapGopls pkgs.gopls;
The configuration pieces can also reference each other. Our control plane server reads its runtime configuration from a YAML file generated by Devenv. See how the PostgreSQL port flows directly into the server's config:
providerCfg.database.port = config.services.postgres.settings.port;When the PostgreSQL service port changes, the generated YAML picks it up automatically.
Devenv draws on Nixpkgs[26], a repository of over 120,000 packages. Normally, adding a new tool means installing it separately on each developer's machine and in CI, with versions that tend to drift apart. With Nix and Nixpkgs, every package is pinned and reproducible. Adding a tool that works the same way everywhere was a single line:
packages = [
pkgs.openspec
pkgs.semgrep
pkgs.sqlc
pkgs.squawk
pkgs.yaml-language-server
# OpenAPI
pkgs.nickel
pkgs.nls
pkgs.redocly
json-schema-to-nickel
];The module system, where configuration is packaged into self-contained units, makes services easy to reuse, extend, and compose. Enabling PostgreSQL takes a handful of lines. Database creation, user setup, and startup are all handled:
services.postgres = {
enable = true;
initialDatabases = [
{ name = "flava-api-gateway"; user = "flava-api-gateway"; }
];
};Devenv ships modules for many common tools, so in most cases you only touch what differs from the defaults. Language modules, for example, provide the compiler, formatter, language server, and other standard tools for a given language. The only customization here is wiring in the gopls wrapper mentioned earlier:
languages = {
nix.enable = true;
go = {
enable = true;
lsp.package = wrapGopls pkgs.gopls;
};
};
That same principle extended to more complex services, like Athenz[27], the access control system we heavily depend on. Configuring it for local use took real effort. But because Devenv handled the environment plumbing and service dependencies, that effort went into understanding Athenz itself rather than fighting the surrounding infrastructure.
Running Athenz locally
Our end-to-end tests depend on real Athenz auth. Mocking it up would be impractical: Athenz has a complex auth model where services authenticate with certificates, and access is controlled through a hierarchy of domains, roles, and policies[28]. Building a faithful mock would require reimplementing significant logic, and it would only test our understanding of Athenz rather than Athenz itself. So it had to run locally.
The complete auth model is declared alongside the service. Service identities, the domain hierarchy, and roles and policies are all provisioned at startup:
services.athenz = {
enable = true;
provisionDomains = {
# Register Athenz services
devenv.services =
lib.genAttrs
["provider" "apiadminrw" "apiadminro"]
(svcName: {
pubkey = "${credentialsDir}/devenv/${svcName}.pub.pem";
key = "${credentialsDir}/devenv/${svcName}.key";
cert = "${credentialsDir}/devenv/${svcName}.cert.pem";
});
# Create Athenz TLD
flava-api-gateway.admins = [ "devenv.provider" ];
# Create Athenz subdomain
"flava-api-gateway.local" = {
admins = [ "devenv.provider" ];
roles = {
apigateway_admin = {
members = [ "devenv.apiadminrw" ];
policies.grant_api_admin = {
grant = "*";
on = "apigateway.api.*";
};
};
apigateway_readonly = {
members = [ "devenv.apiadminro" ];
policies = {
grant_readonly_1 = {
grant = "GET";
on = "apigateway.api.*";
};
grant_readonly_2 = {
grant = "GET";
on = "apigateway.api";
};
};
};
};
};
};
};Old practices, higher stakes
The speed benefits of AI-generated code only materialize when the output is stable enough to trust. Verification is what makes that possible. Getting there required some groundwork. We built a test suite that catches mistakes quickly, a local environment that makes running it frictionless, and a workflow that keeps the agent aligned before it writes a line of code.
Verification needs speed to be useful to an agent. Without a fast local environment, each check is a CI roundtrip. Verification without spec alignment produces code that passes tests but drifts from the design. Together, they form a feedback loop tight enough for an agent to navigate on its own.
For what it's worth, the QA team said they found fewer bugs than they expected for the system's complexity. We can't isolate the practices from other factors, but it lines up with how the development loop felt.
Many of these practices have always been useful. What changes is how much they matter. With them, AI raises quality. Without them, it amplifies every shortcut.
We're hiring
If this sounds like your kind of problem, we're hiring.
References
[1] Ouyang, S. et al. 2025. An Empirical Study of the Non-Determinism of ChatGPT in Code Generation. ACM Transactions on Software Engineering and Methodology. 34, 2 (Jan. 2025), 1–28. https://doi.org/10.1145/3697010.
[2] Larbi, M. et al. 2025. When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions. arXiv. https://doi.org/10.48550/arXiv.2507.20439.
[3] Tomaz, R. et al. 2026. Impacts of Generative AI on Agile Teams’ Productivity: A Multi-Case Longitudinal Study. arXiv. https://doi.org/10.48550/arXiv.2602.13766.
[4] Peng, S. et al. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv. https://doi.org/10.48550/arXiv.2302.06590.
[5] Afroz, S. et al. 2025. The Fast and Spurious: Developer Productivity with GenAI. arXiv. https://doi.org/10.48550/arXiv.2510.24265.
[6] METR. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. Retrieved from https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/.
[7] Wang, X. et al. 2025. CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation. arXiv. https://doi.org/10.48550/arXiv.2504.13472.
[8] Kong. Retrieved from https://github.com/Kong/kong.
[9] OpenSpec — A lightweight spec‑driven framework. Retrieved from https://openspec.dev.
[10] OpenAPI Initiative. Retrieved from https://www.openapis.org.
[11] Huang, R. et al. 2024. Generating REST API Specifications through Static Analysis. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. ACM. https://doi.org/10.1145/3597503.3639137.
[12] Nickel. Retrieved from https://nickel-lang.org.
[13] Given When Then. Retrieved from https://martinfowler.com/bliki/GivenWhenThen.html.
[14] Dente, F. et al. 2026. Constraint Decay: The Fragility of LLM Agents in Backend Code Generation. arXiv. https://doi.org/10.48550/arXiv.2605.06445.
[15] Mathews, N.S. and Nagappan, M. 2024. Test-Driven Development and LLM-based Code Generation. Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. ACM. https://doi.org/10.1145/3691620.3695527.
[16] AGENTS.md. Retrieved from https://agents.md.
[17] Wang, Y. et al. 2025. Beyond Functional Correctness: Investigating Coding Style Inconsistencies in Large Language Models. Proceedings of the ACM on Software Engineering. 2, FSE (June 2025), 690–712. https://doi.org/10.1145/3715749.
[18] Golangci-lint. Retrieved from https://golangci-lint.run.
[19] SQLFluff. Retrieved from https://www.sqlfluff.com.
[20] Squawk — a linter for Postgres migrations. Retrieved from https://squawkhq.com.
[21] Semgrep. Retrieved from https://semgrep.dev.
[22] devenv. Retrieved from https://devenv.sh.
[23] Nix & NixOS. Retrieved from https://nixos.org.
[24] direnv. Retrieved from https://direnv.net.
[25] Gopls: The language server for Go - The Go Programming Language. Retrieved from https://go.dev/gopls/.
[26] NixOS Search. Retrieved from https://search.nixos.org/packages.
[27] Athenz IO - Home. Retrieved from https://www.athenz.io.
[28] Athenz IO - Explore. Retrieved from https://www.athenz.io/explore.html#model.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


