This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Hello, I'm Jungmu Park from LY Corporation's DBaaS DevOps team.
LY Corporation develops and operates a large private cloud platform and provides databases in that environment as database as a service (DBaaS). We are currently consolidating two large legacy clouds — the former LINE Corporation's "Verda" and the former Yahoo Japan Corporation's "YNW" — into the next-generation cloud platform called Flava. This article describes the design and specifications of Flava DBaaS, outlines our migration strategy, and discusses what's in store for the service in the future.
Flava DBaaS design
Operator pattern
The DBaaS provided by Flava is built on the Operator pattern running on Kubernetes.
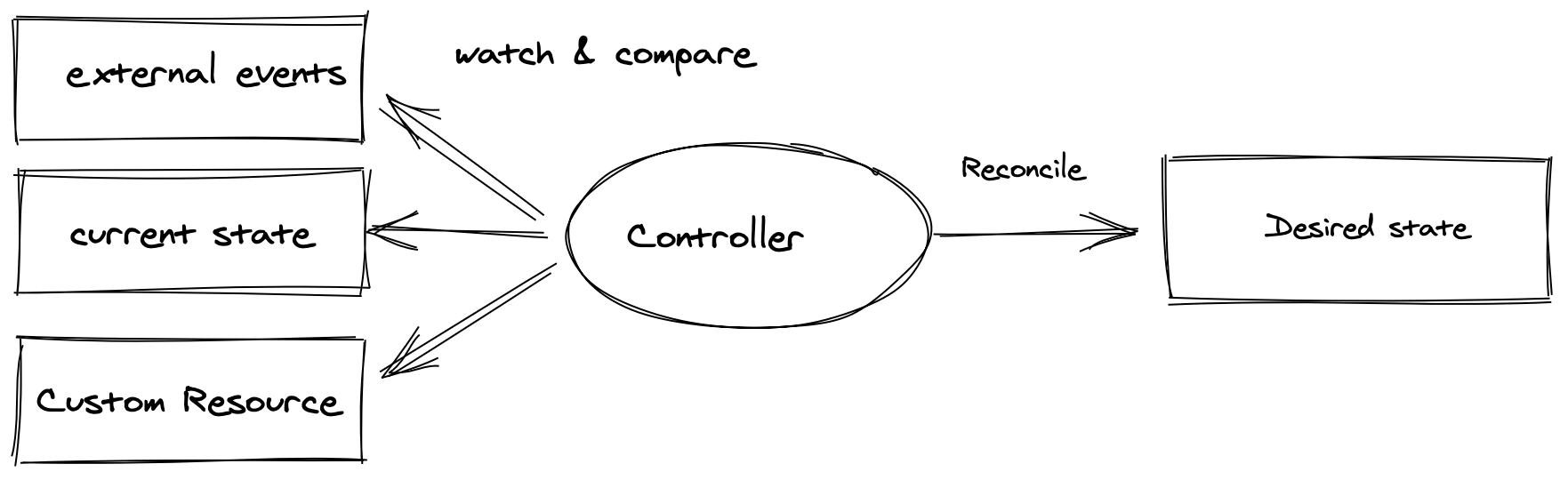
The Operator pattern codifies the operational knowledge of human operators into controller code that runs automatically using Kubernetes' declarative API model. When a user declares an intent such as "I want a database with this configuration", a controller implemented with operator knowledge continuously runs the procedures necessary to converge the cluster to that desired state.
Although building DBaaS using a declarative Operator pattern increases implementation complexity, it is easier to operate and manage than a purely procedural architecture. When incidents occur, you can often discover the cause by inspecting the declared CustomResource spec and its status and by checking controller logs. Controllers implemented as event-driven processes also operate efficiently at large scale. Another benefit is easy integration with Kubernetes ecosystem features for CI/CD, RBAC, and other platform capabilities.
IaaS management and infra operator
A platform as a service (PaaS) runs on top of an infrastructure as a service (IaaS) much like a DBaaS does, so it must be designed to control IaaS resources efficiently. Building a database cluster in infrastructure as a service requires creating and managing many resources such as multiple VMs, storage volumes, and DNS entries. If DBaaS code directly calls IaaS APIs, much of the DBaaS implementation becomes infrastructure control logic mixed with database business logic.
To address this, Flava DBaaS abstracts the IaaS control layer into a separate infra operator. The infra operator provides a platform that exposes IaaS resources as Kubernetes-style resources, letting you use Kubernetes' declarative model instead of making raw IaaS API calls. For example, to create a VM to host a database, you define a declarative server.yaml like:
name: testserver
namespace: testnamespace
spec:
availabilityZone: az3
image: Rocky Linux 8.10
serverType: 4 vCPU-8 GiB
Then create the corresponding CustomResource:
kubectl create -f server.yaml
Using an infra operator you can provision VMs declaratively. From the DBaaS perspective, you don't need to know the details of the IaaS API — you only declare the desired state in server.yaml and work with Kubernetes resources.
The layered architecture of Flava DBaaS with an infra operator looks like this:
+-----------------+
| DBaaS | ← Focus on database business logic
+-----------------+
| Infra operator | ← Abstracting IaaS as Kubernetes resources
+-----------------+
| IaaS | ← Provide compute, network, storage
+-----------------+
Using an infra operator cleanly separates responsibilities between layers, enabling multiple DBMS implementations to consume IaaS resources in a unified way while letting DBaaS product developers focus on DBMS-specific business logic.
Custom resources: API server, manager, and agent
Just as infra operators represent IaaS resources as CustomResources, each DBMS exposes a database cluster as a single CustomResource, for example:
name: testmysql
namespace: testnamespace
spec:
version: mysql-8.0.45
serverType: Cx.4 vCPU_16 GiB_100 GiB
storage:
type: nvme_dev
size: 200 GiB
replication:
member: 1
This CustomResource expresses the desired state of the user's database: a primary with one replica, VM flavor with 4 vCPUs, 16 GiB RAM and 100 GiB disk, and a separate 200 GiB block-storage volume. The CustomResource is stored in Kubernetes' etcd as YAML and can be created, read, updated, and deleted via Kubernetes APIs.
A DBaaS typically consists of three components that operate on such CustomResources:
- API server: a REST API exposed to users. It handles creation, modification, and deletion of declarative CustomResources and is called by the Flava UI or IaC tools.
- Manager: a controller process that continuously reconciles CustomResources to match their spec and status. The manager orchestrates actions to realize the desired cluster state.
- Agent: runs on VMs where the database process executes. Agents perform OS-level and DB-specific commands required to reach the desired state. They handle local-only actions such as provisioning and deep configuration tasks.
Below is an example scenario that shows how a CustomResource, API server, manager, and agent work together when creating a MySQL cluster.
When a user submits cluster information through the API, the API server creates a MySQL CustomResource reflecting the desired configuration — replication settings, VM specs, storage requirements, and so on. The CustomResource is persisted to Kubernetes' etcd.
API Server -> kubectl create mysqlservice -f mysqlservice.yaml
- mysqlservice.yaml
name: testmysql
namespace: testnamespace
spec:
version: mysql-8.0.45
serverType: Cx.4 vCPU_16 GiB_100 GiB
storage:
type: nvme_dev
size: 200 GiB
replication:
member: 1
The manager detects creation and changes to the CustomResource and starts executing steps required to reach the desired state. To create the VMs described in the spec, it creates server CustomResources provided by the infra operator; once VM provisioning completes, the agent runs replication commands to configure replication.
The agent runs inside the VM after provisioning, reads the CustomResource spec, and executes OS or database commands required to reach the target state.
By separating API server, manager, and agent, each process's role is clearly isolated, simplifying operation and maintenance.
Improvements in Flava DBaaS
A DBaaS must provide core platform features such as provisioning, high availability, backup & restore, scalability, and monitoring. Legacy services like Verda and YNW already offered these features, and Flava continues to provide them while introducing improvements requested by many developers. Let's walk through the key enhancements.
Expanded DBMS support
Flava consolidates DBMS offerings from Verda and YNW and provides broader DBMS support.
Added capabilities
Based on user satisfaction surveys from prior cloud services, Flava DBaaS introduces several new features.
More flexible scaling
Users can provision storage in flexible increments of 100 GiB, and DBMSs using block storage can be allocated up to 5 TiB of storage.
Previously, DBMS storage depended on VM local disks constrained by hypervisor VM specifications. Flava supports custom instance types and block storage for DBMSs, making storage configurations more flexible and raising the practical maximum to 5 TiB. While block storage can exceed 5 TiB, analysis of historical use cases showed that 5 TiB covers the vast majority of needs and helps avoid server-side fragmentation, so it was chosen as an upper bound.
Because single-VM storage limits previously forced consideration of sharding, increasing the maximum storage in Flava DBaaS reduces the need for such alternatives in many cases.
Unified user experience
All DBaaS offerings on Flava share a consistent architecture and UI, providing a unified user experience. Users don't need to learn different control mechanisms for each DBMS. For example, changing server specs in MySQL yields the same workflow for Redis; configuring monitoring alerts for Cassandra informs how one would configure alerts for MySQL. A single UI/UX reduces the learning curve across DBMS types.
Enhanced security features
Flava DBaaS provides platform-level security features such as transparent data encryption (TDE) and transport layer security (TLS) by default.
Convenience features
Flava DBaaS includes several features to improve usability:
- Custom DB role: Create and manage reusable database users with custom permission sets.
- Database parameter group: Manage and reuse database parameter configurations.
- Restore backup: Create a new cluster from a specific backup. This enables quick recovery after incidents and fast provisioning of production-like datasets for performance testing via the UI.
We are working to bring these features to DBaaS products that don't yet support them.
Based on feedback collected during operation of legacy cloud services, Flava has improved many features, resulting in high scores in internal user satisfaction surveys.
DBaaS role through migration
Delivering a new DBaaS is not enough — the platform must also provide easy and reliable migration paths from legacy platforms. Here we explain efforts to enable migration from existing platforms to Flava DBaaS.
Migration between identical DBMS
Before describing Flava's migration tools, let's review common approaches for migrating between like-for-like DBMS instances. There are three primary methods.
Dump & restore
Take a backup from the source and restore it into the destination. This is the simplest migration approach but typically requires application downtime to ensure data consistency.
Replication
Use the DBMS's native replication to stream data from source to destination. After replication catches up, fail over to the destination primary and decommission the source.
Data consistency depends on the DBMS's replication guarantees. A small application interruption may occur during primary failover, and endpoint changes are typically required. Although more complex than dump & restore, this approach is often chosen for near-zero-downtime migrations.
Change data capture (CDC)
A method that uses a separate system such as Kafka to logically replicate data between databases. Logical migration can overcome topology constraints — for example, migrating a 6-shard Redis cluster into a 3-shard Redis cluster. CDC increases operational complexity because it requires additional infrastructure, but it enables near-continuous migration with minimal downtime.
Migration tools provided by Flava DBaaS
Migration is a collaborative effort between DB operators and application developers; it's impractical for operators alone to migrate every large database. The best approach is to provide polished tools and documentation so developers can migrate easily without deep specialist knowledge.
We currently provide a developer-facing migration tool for MySQL called data migration bridge (DMB). Our goal is to offer developer-friendly migration tools for all DBMS supported by Flava around Q2 2026. Because workload characteristics differ across DBMSs, the migration approach may vary, but the common goal is to enable users to migrate by following UI guidance without requiring deep domain expertise.
The future of Flava DBaaS
We've described Flava DBaaS today. Let's look ahead at where Flava DBaaS is heading.
Support for DBMS from legacy clouds
We are preparing to offer DBaaS forms of databases previously available on YNW — such as Fractal DB — and systems historically used via DBA support, such as HBase.
Security posture
As LY Corporation provides services considered social infrastructure, strict security controls are required. Flava DBaaS must meet these demands and provide appropriate controls.
Flava is designed with an architecture that isolates, stores, and processes data according to security classifications, in accordance with our strict internal data governance and security standards. Similarly, Flava DBaaS is progressively expanding and implementing a highly segregated management environment tailored to the importance and nature of the data it handles. Once security is strictly in place, usability becomes the key priority. Flava DBaaS is designed to allow you to quickly and conveniently set up a database environment across all security levels without compromising usability, regardless of the data’s security classification.
Serverless DBaaS
Provisioning DBaaS as independent database clusters provides stable operation, but from a platform perspective it can lower overall resource utilization due to isolated redundancy. Flava DBaaS is preparing a serverless DBaaS option to address this inefficiency.
Serverless DBaaS is designed for multi-tenant use of shared infrastructure. Operators can increase utilization, standardize operations such as upgrades and backups, and reduce operating costs. Users can consume resources on demand without managing cluster configuration, paying only for what they use. Known issues such as the noisy-neighbor effect can arise in serverless environments; we are validating tenant isolation and other mitigations to address them.
Serverless DBaaS is not suitable for every workload. Workloads requiring high performance or dedicated infrastructure are better served by dedicated cluster-based DBaaS. Flava plans to offer both serverless and dedicated cluster options depending on workload characteristics.
We are initially prioritizing a serverless TiDB-compatible MySQL offering and serverless search (Serverless Opensearch) to accommodate growing demand while improving infrastructure efficiency.
Intelligent DBaaS
One of the most ambitious directions for Flava DBaaS in the AI era is building an intelligent cloud.
DBA as a Service
DBAs have long been responsible for the core of database operations: investigating alerts, tuning slow queries, and providing operational guidance. DBA as a Service seeks to encapsulate these DBA functions as AI agents.
Users can receive the kinds of DBA consultations they historically received via Slack bot interfaces.
- Alert analysis: Analyze metrics and logs to determine the cause of an alert and propose verified remediation steps.
- Issue response: Ask "Why did query latency increase on db-prod-01 from 13:05?" and the Slack bot will inspect metrics and logs and answer interactively, simulating a conversation with a DBA.
- Advisory: Provide recommendations for sizing, cluster topology, and backup policies. Given inputs such as expected QPS, data size, and service characteristics, the agent suggests appropriate configurations.
In addition to the Slack bot, the Flava console (web UI) offers a Reports tab that provides actionable suggestions to improve DBaaS usage.
- Identify daily or time-window usage patterns and recommend moving backup windows or adjusting schedules if they conflict with batch jobs; suggest opportunities to reduce resources based on utilization.
- Analyze slow-query patterns and propose query-tuning strategies or index recommendations.
- Detect stored data that appears to be personal data and recommend encryption or other protections.
Auto-scaling
Operators constantly struggle to allocate DBMS resources efficiently: overprovisioning wastes cost, while underprovisioning can harm performance and cause outages.
Flava DBaaS provides auto-scaling capabilities based on policies defined over metrics such as CPU, memory, storage, and connections. For example, if a large batch job is scheduled overnight, DBaaS can proactively create read replicas to distribute load and then remove them after the job to optimize cost. Another example is increasing node storage by 20% and migrating the VM spec when disk usage crosses a threshold.
Coupling auto-scaling with DBA as a Service enables more intelligent and reliable scaling: AI agents can analyze usage patterns and historical resource consumption to evaluate policies and suggest improvements. For example, they can recommend tuning thresholds for recurring traffic spikes or propose pre-scaling plans based on data growth trends — letting users benefit from efficient resource use without designing complex policies themselves.
Conclusion
We have reviewed Flava DBaaS's architecture and specifications, the migration tools provided to move from legacy platforms, and the future directions of Flava DBaaS. Drawing on experience operating legacy platforms, Flava aims to deliver a more polished, reliable DBaaS and explore how to provide DBaaS in the AI era.
We appreciate your interest in Flava DBaaS's future. Thank you for reading.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


