LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
はじめに
こんにちは。LINEヤフー株式会社のDBaaS DevOpsチームで働いている朴政武(パク・ジョンム)です。
LINEヤフー株式会社は大規模なプライベートクラウドを自社で開発・運用しており、プライベートクラウド環境ではデータベースをDBaaS(Database as a Service)として提供しています。現在、我々は旧LINE株式会社で使われていた「Verda」と旧ヤフー株式会社で使われていた「YNW」という二つの大規模クラウドを次世代クラウドであるFlavaに統合していく過程にあります。本稿ではFlava DBaaSの設計と仕様を紹介し、マイグレーション戦略と今後Flava DBaaSが進化すべき方向について説明します。
Flava DBaaSの設計
オペレーター・パターン
Flavaが提供するDBaaSはKubernetes上で動作するオペレーター・パターンを基盤としています。
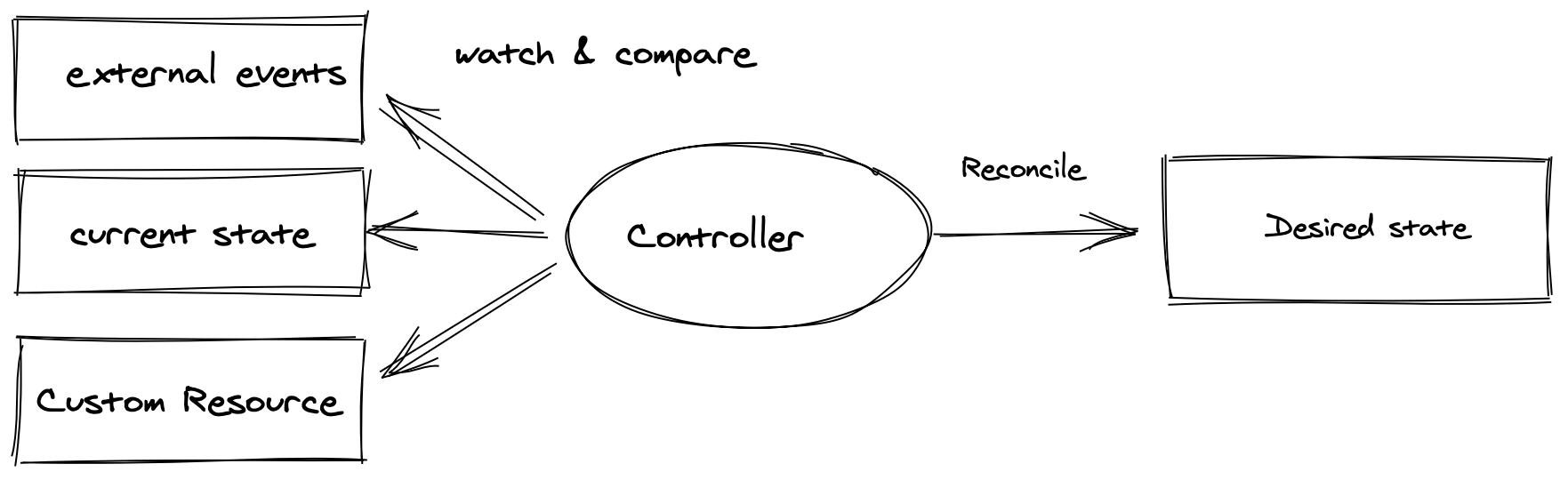
オペレーター・パターンは、オペレーターがドメイン知識に基づいて行っていた操作をコントローラーとしてコード化し、Kubernetesの宣言的APIモデルを用いて自動的に動作させる設計手法です。ユーザーは「こういう状態のDBが欲しい」と意図を宣言するだけで、オペレーターのドメイン知識を反映したコントローラーが、その宣言された状態に到達する手順を継続的に実行します。
宣言的に動作するオペレーター・パターンで構成したDBaaSは、実装難易度は高くなりますが、手続き指向で構成したアーキテクチャに比べて運用・管理が容易です。運用中に問題が発生した際には、宣言されたカスタムリソースの仕様と状態を比較し、コントローラーのログを確認するだけで原因を特定しやすくなります。またイベント駆動で動作するコントローラーは大規模なデータベースインフラ環境でも大きな負荷をかけずに動作します。CI/CDの構築や権限管理など、Kubernetesエコシステムが提供する多くの機能を利用できる点も利点です。
IaaS管理とインフラ・オペレーター
DBaaSのようなPaaS(Platform as a Service)はIaaS(Infra as a Service)上で動作するため、IaaSを効率的に制御できる設計が必要です。IaaSでデータベースクラスターを1つ構成するには、複数のVM、ストレージ、ドメインなどIaaS側が提供するリソースを生成・管理する必要があります。そのため、DBaaSレイヤーでIaaSのAPIを直接扱うと、DBの運用・管理のためのビジネスロジックとインフラ制御ロジックが混在してしまいます。
この点を改善するため、Flava DBaaSではIaaSリソースを扱う層を別のインフラ・オペレーター(infra operator)として抽象化しています。インフラ・オペレーターはIaaSリソースをKubernetesリソースの形で扱えるようにするプラットフォームで、IaaSのAPI呼び出しを直接実行するのではなく、Kubernetesの宣言的APIモデルをそのままインフラリソースに適用できるようにします。例えば、データベースをインストールするVMを作成するには、以下のように宣言的にserver.yamlを定義します。
name: testserver
namespace: testnamespace
spec:
availabilityZone: az3
image: Rocky Linux 8.10
serverType: 4vCPU-8GiB
その後、次のようにserver.yamlを使ってカスタムリソースを作成します。
kubectl create -f server.yaml
このようにインフラ・オペレーターを用いることで、宣言的にVMを作成できます。DBaaS側はIaaS側のAPIや呼び出し手順を知る必要がなく、server.yamlに必要事項を宣言するだけでKubernetesリソースだけでIaaSを扱えます。
インフラ・オペレーターを導入したFlava DBaaSのレイヤ構成は次の通りです。
+-----------------+
| DBaaS | ← Focus on database business logic
+-----------------+
| Infra operator | ← Abstracting IaaS as Kubernetes resources
+-----------------+
| IaaS | ← Provide compute, network, storage
+-----------------+
インフラ・オペレーターを使用することで各レイヤの責任範囲が明確に分離されます。これによりIaaSが提供するリソースを複数のDBMSで同じ方法で扱えるようになり、各DBaaS商品開発者はDBMSに依存したビジネスロジックに集中できます。
カスタムリソースとAPIサーバ、マネージャ、エージェント
インフラ・オペレーターがIaaSリソースをカスタムリソースとして表現するように、各DBMSではデータベースクラスターを次のような1つのカスタムリソースで表現します。
name: testmysql
namespace: testnamespace
spec:
version: mysql-8.0.45
serverType: Cx.4vCPU_16GiB_100GiB
storage:
type: nvme_dev
size: 200GiB
replication:
member: 1
このカスタムリソースはユーザーが望む状態のデータベースを表現しています。プライマリをレプリケートするメンバーを1つ構成し、VMのスペックは4 vCPU、16GiBメモリ、100GiBディスクを使用し、別途200GiBのブロックストレージを使用する、という形で記述されています。カスタムリソースはYAMLの形でKubernetesのetcdに保存され、Kubernetesが提供するAPIを使って参照・作成・修正・削除できます。
DBaaSはこのようなカスタムリソースを参照する三つのコンポーネントで構成されています。
- APIサーバ: ユーザーに提供する操作方法を提供するREST APIです。宣言的に定義されたカスタムリソースの作成・変更・削除を担います。FlavaのUIやIaCツールからこのAPIが呼ばれます。
- マネージャ: カスタムリソースの変更に応じて仕様と状態を一致させるために継続的に調整(reconcile)するコントローラープロセスです。データベースクラスターの現在状態を確認し、必要なコマンドを実行するなどの作業を総括します。
- エージェント: データベースプロセスが動作するVM上で共に動作し、カスタムリソースの変更に応じてOSやデータベース上で実行すべきコマンドを実行するプロセスです。ローカルでしか動作しない操作やプロビジョニングのロジックに深く関与します。
カスタムリソースとAPIサーバ、マネージャ、エージェントがどのように動作するかを、MySQLクラスターを作成するシナリオを例にして見てみます。
ユーザーが構成したいデータベースクラスターの情報をAPIに送ると、APIサーバがユーザーの要求に合わせたMySQLカスタムリソースを作成します。これにより、レプリケーション構成やMySQLを構成するサーバスペックなど、MySQLクラスターを構築するために必要な情報がカスタムリソースの仕様に記録され、Kubernetesのetcdに保存されます。
API Server -> kubectl create mysqlservice -f mysqlservice.yaml
- mysqlservice.yaml
name: testmysql
namespace: testnamespace
spec:
version: mysql-8.0.45
serverType: Cx.4vCPU_16GiB_100GiB
storage:
type: nvme_dev
size: 200GiB
replication:
member: 1
マネージャは作成されたカスタムリソースの生成や変更を検知し、カスタムリソース仕様に定義された状態と一致させるための手順を実行し始めます。仕様に定義されたVMを作成するために、インフラ・オペレーターで提供されるserverというカスタムリソースを作成し、VM作成が完了した後にエージェントがレプリケーションを設定するための命令を実行する、という流れです。
エージェントはVM作成時にVM内部にインストールされて動作し、カスタムリソースの仕様を確認してその状態に到達するためにOSコマンドやデータベースコマンドを実行します。
このように各DBMSはAPIサーバ、マネージャ、エージェントの三つのコンポーネントで分離して構成され、それぞれのプロセスの役割を明確に分けています。
Flava DBaaSで改善した点
DBaaSではプラットフォームレベルでプロビジョニング、高可用性(high availability)、バックアップとリカバリ、スケーラビリティ(scalability)、モニタリングなどの基本機能を提供する必要があります。既存のVerdaやYNWといったクラウドサービスでもこれらの機能は提供されており、Flavaも同様に提供しています。さらに、これまで多くの開発者が要望していた点を改善して提供するために取り組んでいます。どの点を改善したかを順に見ていきます。
対応するDBMSの拡充
Flavaでは旧VerdaやYNWで提供していたDBMSを統合し、さらに多くのDBMSを提供しています。
追加したサポート機能
既存クラウドサービスで行ったユーザー満足度調査の結果に基づき、Flava DBaaSに新機能を追加しました。
より柔軟なスケーラビリティ
ユーザーは必要に応じて100GiB単位で柔軟にストレージを構成できます。またブロックストレージを使用するDBMSでは使用可能なストレージ容量を最大5TiBまで増やしました。
従来のクラウドではVMのローカルディスクを使用していたため、DBMSが使用できるストレージ容量はハイパーバイザが提供するVMのスペックに依存していました。しかしFlavaではVM作成時にカスタムインスタンスタイプをサポートし、DBMSがブロックストレージを使用することでストレージ構成が柔軟になり、ストレージ最大容量も5TiBに拡大しました。ブロックストレージ自体は5TiB以上でも利用可能でしたが、既存クラウドの��利用実績を分析した結果、5TiBでほとんどの要件をカバーでき、ブロックストレージ側のサーバ断片化を防ぐために最大サイズを5TiBに設定しました。
従来のクラウドでは単一VMのストレージ容量の制限によりシャーディングなどの代替を検討する必要があるケースがありました。Flava DBaaSでは最大ストレージ容量が増えたため、そのような検討が不要になる場合があります。
統一されたユーザー体験の提供
Flavaが提供するDBaaSはすべて統一されたアーキテクチャとUIに基づき、統一されたユーザー体験を提供します。ユーザーはDBMSごとに操作方法を変える必要がありません。例えばMySQLでサーバスペックを変更した経験があれば、その操作経験をもとにRedisのサーバスペックを変更できます。またApache Cassandraのモニタリングアラームを設定した経験をもとにMySQLのモニタリングアラームも設定できます。同一のUI/UXを提供するため、ユーザーはDBMSごとに別々に使い方を習得する必要がありません。
セキュリティ機能の強化
Flavaが提供するDBaaSは、TDE(transparent data encryption)やTLS(transport layer security)のようなセキュリティ機能をDBaaSレベルで標準提供しています。
利便性機能の追加
Flava DBaaSではユーザー体験を改善するためにいくつかの利便性機能を提供しています。
- 「Custom DB Role」機能: ユーザーは必要な権限レベルを持ったデータベースユーザーを柔軟に作成・管理でき、再利用も可能です。
- 「Database Parameter Group」機能: 任意のデータベースパラメータを制御でき、これを再利用できます。
- 「Restore backup」機能: 特定のバックアップを基に新しいデータベースクラスターを作成できます。この機能を使えば障害発生時にバックアップから復旧したり、パフォーマンステストのために本番と同じデータが入ったデータベースをUI上で素早く作成できます。
まだ上記機能を提供していないDBaaSについても、これらの機能を提供するために準備中です。
既存クラウドサービスの運用過程で得たユーザーの声を基に、Flavaではより良いDBaaSを提供するために多くの機能改善を行い、その結果社内のユーザー満足度調査で高い評価を得ました。
マイグレーションにおけるDBaaSの役割
新しいDBaaSを開発してユーザーに提供するだけでマイグレーションの役割が完了するわけではありません。既存プラットフォームから容易かつ簡便にマイグレーションできる手段を提供することまでが新しいDBaaSプラットフォームの責務です。既存プラットフォームからFlava DBaaSへ移行するために我々がどのような取り組みをしているかを説明します。
同一DBMS間のマイグレーション方法
Flava DBaaSが提供する方法を説明する前に、同一DBMS間でのマイグレーション方法を見てみます。異機種ではない同種のDBMS間でのマイグレーションは大きく三つに分けられます。
ダンプ&リストア(dump & restore)
ソースデータベースでバックアップを取り、ターゲットのデータベースにリストアする方式です。最も単純なマイグレーション方式ですが、データ整合性を保証するためにはアプリケーションを停止する必要があります。
レプリケーション(replication)
DBMSが提供するレプリケーション機�能を利用する方式です。まずソースDBからターゲットDBへのリアルタイムレプリケーションを構成し、レプリケーションが追いついたらフェイルオーバーを行ってプライマリをターゲット側に切り替え、ソースDBを削除する流れです。
この方式ではデータ整合性はDBMS自身が提供するレプリケーション機構に依存します。またプライマリのフェイルオーバー時に最小限のアプリケーション停止が発生する可能性があり、フェイルオーバー前にアプリケーションで使っているデータベースのエンドポイント等を変更する作業が必要になるため、ダンプ&リストア方式に比べて手順が複雑で時間がかかる場合があります。無停止でのマイグレーションを目指す際には一般的に選択される方法です。
変更データキャプチャ(change data capture)
Apache Kafkaのような別のシステムを構築してデータベース間のデータを論理的にコピーする方式です。論理的マイグレーションであるため、同種のDBMS間であってもトポロジーの制約を超えた移行が可能です。例えば6シャードで構成されたRedisクラスターを3シャード構成のRedisに移行することもできます。別途システムを構築して運用・管理する必要があるため複雑さは増しますが、ほぼ無停止でのマイグレーションが可能です。
Flava DBaaSが提供するマイグレーションツール
マイグレーションはデータベースを運用する運用者とそれを利用する開発者が緊密に協力して進める作業です。大規模データベースの運用担当者が単独ですべてを移行するのはほぼ不可能です。最善の方法は、データベースを使用する開発者が特別な知識な��しに簡単に使えるよう、使い勝手の良いツールとマニュアルを提供することです。
現在はMySQL向けにDMB(data migration bridge)という名前で、開発者が直接使えるマイグレーションツールを提供しています。2026年第2四半期までにFlavaが提供するすべてのDBMSを対象に、開発者が直接使える形のマイグレーションツールを提供することを目標としています。DBMSごとにワークロードや特性が異なるため、マイグレーションツールが提供する方式はDBMSごとに異なる可能性がありますが、ユーザーが移行のための専門知識を持たずともUIの指示に従うだけで簡単に移行できることを共通目標としています。
Flava DBaaSの将来
ここまでで現在のFlava DBaaSの姿を紹介しました。次に一歩先の未来、明日のFlava DBaaSがどのようになっているかを見てみます。
既存クラウドで提供していたDBMSのサポート
既存のYNWで提供していたFractalDBや、DBA支援で利用していたHBaseなどのデータベースもDBaaSの形で提供できるよう準備しています。
セキュリティ環境のサポート
LINEヤフー株式会社は社会インフラとしてサービスを提供しているため、厳格なセキュリティレベルの維持が求められます。Flava DBaaSもこれらの要求に応える機能を提供する必要があります。
Flavaは、社内の厳格なデータガバナンスおよびセキュリティ基準に基づき、データをセキュリティレベルごとに隔離して保存・処理するアーキテクチャとして設計されています。Flava DBaaSも同様に、取り扱うデータの重要度や性質に応じた高度な分離管理環境を段階的に拡充し、適用しています。セキュリティが厳格に整備された後、重要なのは使いやすさです。 Flava DBaaSでは、データのセキュリティレベルによって使い勝手が変わることはなく、すべてのセキュリティレベルにおいて迅速かつ便利にデータベース環境を構築できるよう準備を進めています。
サーバーレスDBaaS
独立したデータベースクラスターの形で提供されるDBaaSは安定したデータベース運用環境を提供できますが、プラットフォーム全体の観点では独立した冗長化などの理由で自然とリソース利用率が低くなります。Flava DBaaSはこの問題を解決するためにサーバーレスDBaaSを準備しています。
サーバーレスDBaaSは、複数のユーザーがマルチテナント形式で共通インフラを効率的に利用できるように設計されています。DBaaSの運用者は全体的な観点からリソース利用率を高め、バージョンアップやバックアップなどの運用作業を標準化して運用コストを下げることができます。ユーザーはクラスター構成やサーバー仕様を気にする必要はなく、必要なリソースを即座に自由に利用でき、その費用は使用した分だけ請求されます。サーバーレスDBaaSではよく知られたノイジーネイバー(noisy neighbor)のような問題が発生する可能性があります。これを解決するためにテナント間のリソース隔離なども導入して検証しています。
サーバーレスDBaaSがすべてのワークロードに適しているわけではありません。高いレベルの性能や専用インフラ構成が必要なワークロードの場合は、独立したクラスター基盤のDBaaSの方が適しています。Flava DBaaSはワークロードの特性に応じてサーバーレスDBaaSと専用クラスター基盤サービスを併せて提供し、多様な要求を受け入れる計画です。
現在はまずMySQL互換のTiDBサーバーレスデータベースとサーバーレス検索(Serverless OpenSearch)を準備しています。これにより増加するデータベース需要を積極的に受け入れ、インフラリソースを効率的に利用する方法を検討しています。
インテリジェントDBaaS
Flava DBaaSがAI時代に向けて進むべき方向の中で最も挑戦的なのはインテリジェントクラウド(intelligent cloud)です。
DBA as a Service
DBAは長年にわたりDB運用の要を担ってきました。アラート発生時に原因を調査して対応し、遅いクエリを分析してチューニングし、利用者に適切な運用ガイドを提供するなど、安定して動作するデータベースの裏側には常にDBAが存在してきました。DBA as a ServiceはこれらのDBAの役割をAIエージェントの形で提供するものです。
ユーザーはDBAとやり取りしていた相談等をSlackボットを通じてサービスの形で受け取ることができます。
- アラート分析: アラート発生時に指標とログを分析して現在発生しているアラートの原因を特定し、検証結果に基づいて対処の提案を行います。
- 課題対応: 「13:05からdb-prod-01のクエリ遅延が増加しているのはなぜですか?」と質問すると、Slackボットが指標とログを照会して回答します。回答後の追加質問にも適切に答えるため、まるでDBAとやり取りしているかのように問題の原因を分析できます。
- 問い合わせ対応: データベース仕様の算定、クラスター構成の選定、バックアップポリシーの設定などに関するアド��バイスを提供します。想定QPSやデータ量などの情報、データの性質、サービス概要を提供すると、適切な構成を提案します。
Slackボットだけでなく、Flavaコンソール(Web UI)でもレポートタブを提供します。レポートタブではDBaaSをより良く利用するための改善提案をレポート形式で受け取ることができます。
- 日単位または特定時間単位のDB使用パターンを確認し、バックアップ時間がバッチ実行と重なる場合はバックアップ時間の変更を推奨したり、リソース使用率を確認してリソース削減の可能性を判断して提案します。
- 遅いクエリのパターンを分析してクエリチューニングの方法を提案したり、適切なインデックスを推奨します。
- 保管されているデータの中に個人情報と判断されるものがあれば報告の上で暗号化を提案します。
オートスケーリング
DBMSリソースをいかに効率的に使うかは、すべての運用者が常に悩む点です。リソースを過剰に割り当てればコストが無駄になり、不足すれば性能低下や障害を引き起こす可能性があるためです。
Flava DBaaSはこの問題を解決するためにオートスケーリング機能を提供します。ユーザーはCPU、メモリ、ストレージ、コネクションなどの指標に基づいてポリシーを設定でき、ポリシーに基づいて必要なリソースを自動的に拡張または縮小します。例えば深夜に大規模なバッチ処理が予定されている場合、DBaaSは事前にリードレプリカを作成して読み取り負荷を分散し、処理終了後にレプリカを返却してコストを最適化します。別の例として、データ増加によりディスク使用率が閾値に達した場合、ストレージを20%増やしたノードにVM仕様を変更することができます。
このようなオートスケーリング機能をDBA as a Serviceと連携させれば、より知的で安定したオートスケーリングを提供できるでしょう。AIエージェントはデータベースの使用パターンやリソース使用履歴を分析し、現在設定されているオートスケーリングポリシーが適切かを検討して改善案を提案できます。例えば特定の時間帯に繰り返し発生するトラフィック増加のパターンを分析してオートスケーリングの閾値調整を推奨したり、データ増加の傾向に基づいて事前増強ポリシーを提案することができます。これによりユーザーは複雑なポリシー設計を悩む必要なく、リソースが効率的に使われる体験を得られます。
おわりに
ここまででFlava DBaaSのアーキテクチャと仕様、既存プラットフォームからのマイグレーションのために提供するツール、そして今後Flava DBaaSがどのように進化していくかを確認しました。Flava DBaaSは既存プラットフォームの運用経験に基づき、より改善された形で安定的で使いやすいDBaaSを提供するために努めており、AI時代に合わせてDBaaSをどのように提供すべきかの答えを模索しています。
今後Flava DBaaSがもたらす変化にぜひご注目ください。お読みいただきありがとうございました。
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の�挑戦や積み重ねてきた知識を共有します。
YouTube LIVEでの配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


