Motivation
Zookeeper 是一個開源的分散式協調服務,它為分散式應用提供了一種集中管理的方式。Zookeeper 允許各種服務進行資料同步,維持 configuration 資訊,以及執行分散式 lock 和 queue 等操作。這對於維護分佈式系統的狀態一致性和可靠性是非常重要的。
在 cloud native 的架構中,Zookeeper 的穩定性直接影響著依賴它進行協調的各項服務。為了保證 Zookeeper 可以在不同的情況下穩定運作,尤其是在 Cloud 環境下重新部署(deploy)時,我們必須確保它能夠準確地與 K8s assign 的新 IP 進行綁定。我們發現這個過程有時會遇到問題,意即在進行服務發現(DNS 查詢)的過程中可能會出現 Race Condition 導致 Zookeeper pod 沒有辦法正常重啟。
深入了解後,我們發現問題是出自於 K8s 在執行 pod deletion 這個操作時牽涉了兩個非同步的事件,而只要兩個事件的互動順序不同,就會導致 Race Condition 發生預期之外的行為(在這個 case 就是重啟 Zoookeeper 後,new pod 沒辦法 bind 到正確的 IP 上)。
為了解決這個問題,我們探索現有的解法(workaround),並探究如何使用 Kubernetes 中的 graceful shutdown 策略來提高 Zookeeper 重啟時的穩定性,透過實驗我們也驗證了這個方法的有效性。
在這篇文章中,我們將探討造成 Zookeeper 沒辦法 bind 到正確(newly created) IP 的根本原因、介紹現有的workaround 及新的(本文想嘗試的)方法(K8s graceful shutdown approach),並透過實驗了解這個方法的有效性。
Root Cause
Potential Race Condition When Deleting a Pod in K8s
這篇文章詳細地介紹了 K8s 在 delete 一個 pod 時的步驟及 overall 的 process。值得一提的是,當 deletion request 送到 API server 時,會 trigger 兩個平行的事件,DNS Update & Process Termination。
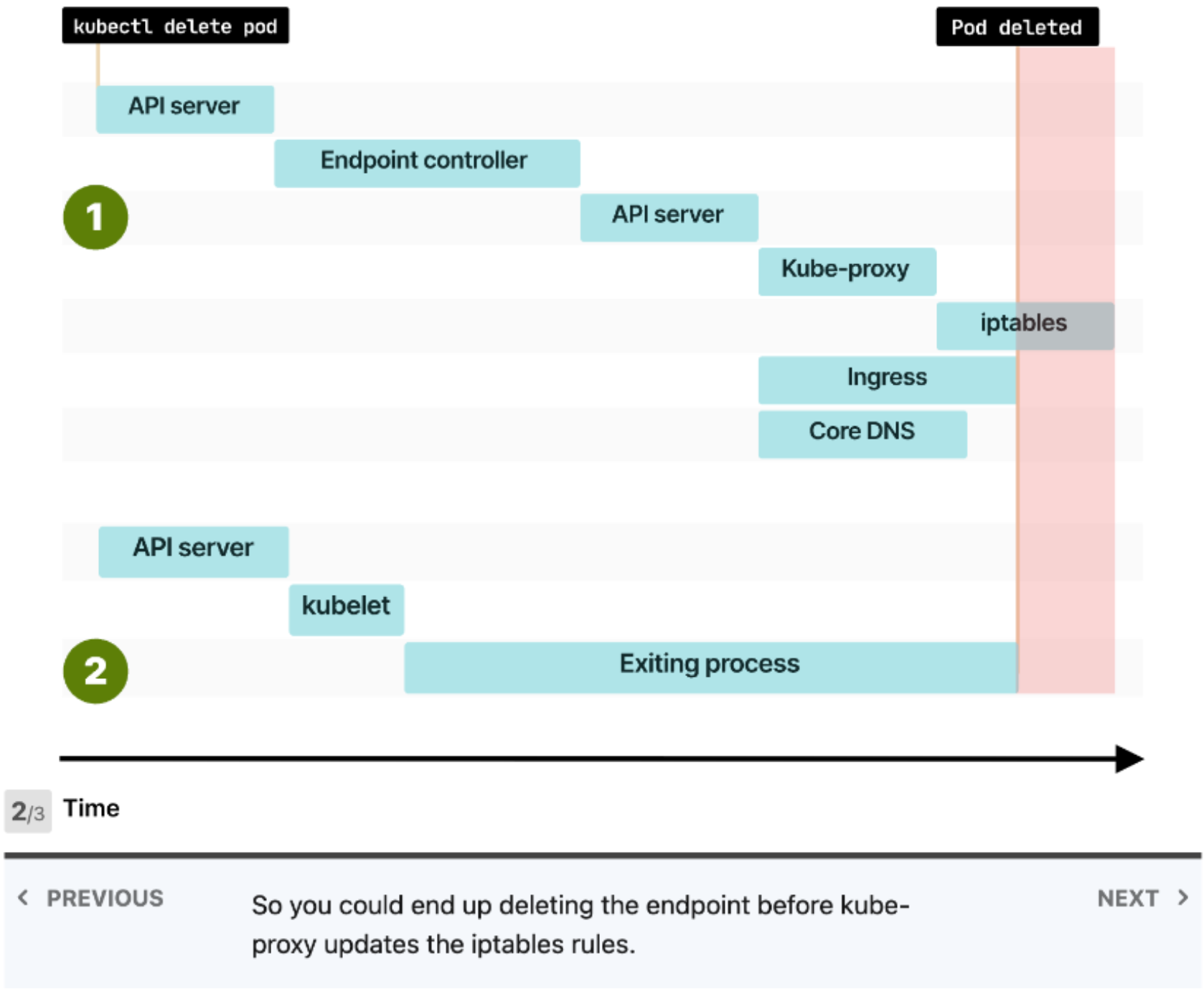

(Deleting the endpoint and deleting the Pod happen at the same time)
其中 DNS Update(上圖的 Event 1)就是負責 notify 監聽 endpoint 的 components (Kube-proxy, Ingress, Core DNS, ...) endpoint 有發生變動(因為 pod 被 delete 了),因此需要去更新他們 maintain 的 iptables;至於 Process Termination(上圖的 Event 2)就是透過 kubelet 去將指定的 application 結束,通常就是送 SIGTERM 給 application。
而當 Event 2 比 Event 1 早做完的話(上圖的 case),其實會面臨一個狀況,就是在 Kube-proxy 及相關的 components 在還沒更新成正確的 iptables 時就結束了 application,這樣就會造成 ingress, Core DNS 將 requests 繼續導到已經不存在的 IP (old IP),發生 downtime issue。
對應 Zookeeper 的狀況,則是 Zookeeper instance 在被 delete 完(Event 2)並重新啟動時,cluster 內的 Core DNS 還沒完成更新(Event 1��),造成 Zookeeper 在問 IP 時問到錯的(已經不存在的)IP 而沒有辦法 bind 到新的 IP。
Current Workaround and K8s Graceful Shutdown Approach
Current Workaround - Startup Probe Approach
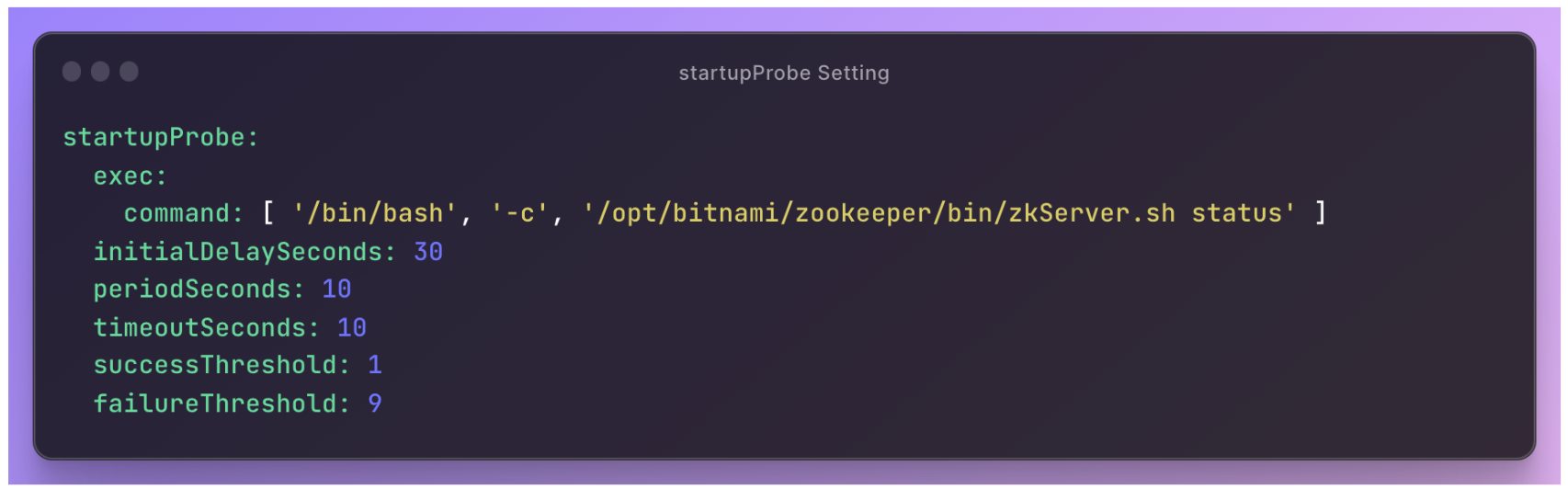
因為意識到問題在於發生了 race condition,因此如果我們在發生 race condition 時重新來過呢?這就是目前的一個 workaround,概念是在一個 pod 起來時,透過 start up probe 與 Zookeeper container shell 互動,執行其中的 status check script 判斷此 Zookeeper instance 的 status,確認其是否正確 bind 並加入集群。當 startup probe 失敗數次後,就會砍掉 pod 重新來過,期望 DNS update 能夠在新的 pod 詢問 IP 前做完,如此就不會發生上述 race condition 所造成的問題。下圖是一個使用 startupProbe 作為解法的範例:

Kubernetes Graceful Shutdown Approach - PreStop Hook
上面的方法確實能夠解決這個問題,也就是透過不斷嘗試,期望在某一次的 pod relaunch 時,能��夠經歷正確的 pod deletion 順序。除了這個方法,在前面介紹的文章中,提到了另一種方法,也就是透過設定 PreStop Hook,讓 application 在收到 SIGTERM 前先執行 sleep 等延長時間的操作,不讓 application 馬上 delete。這樣就能夠讓 DNS Update 做更新的同時 halt 住 application 的 termination process。概念上就是期望透過這樣的 trick 延長 Pod Termination 的時間,解決 race condition 的 issue。

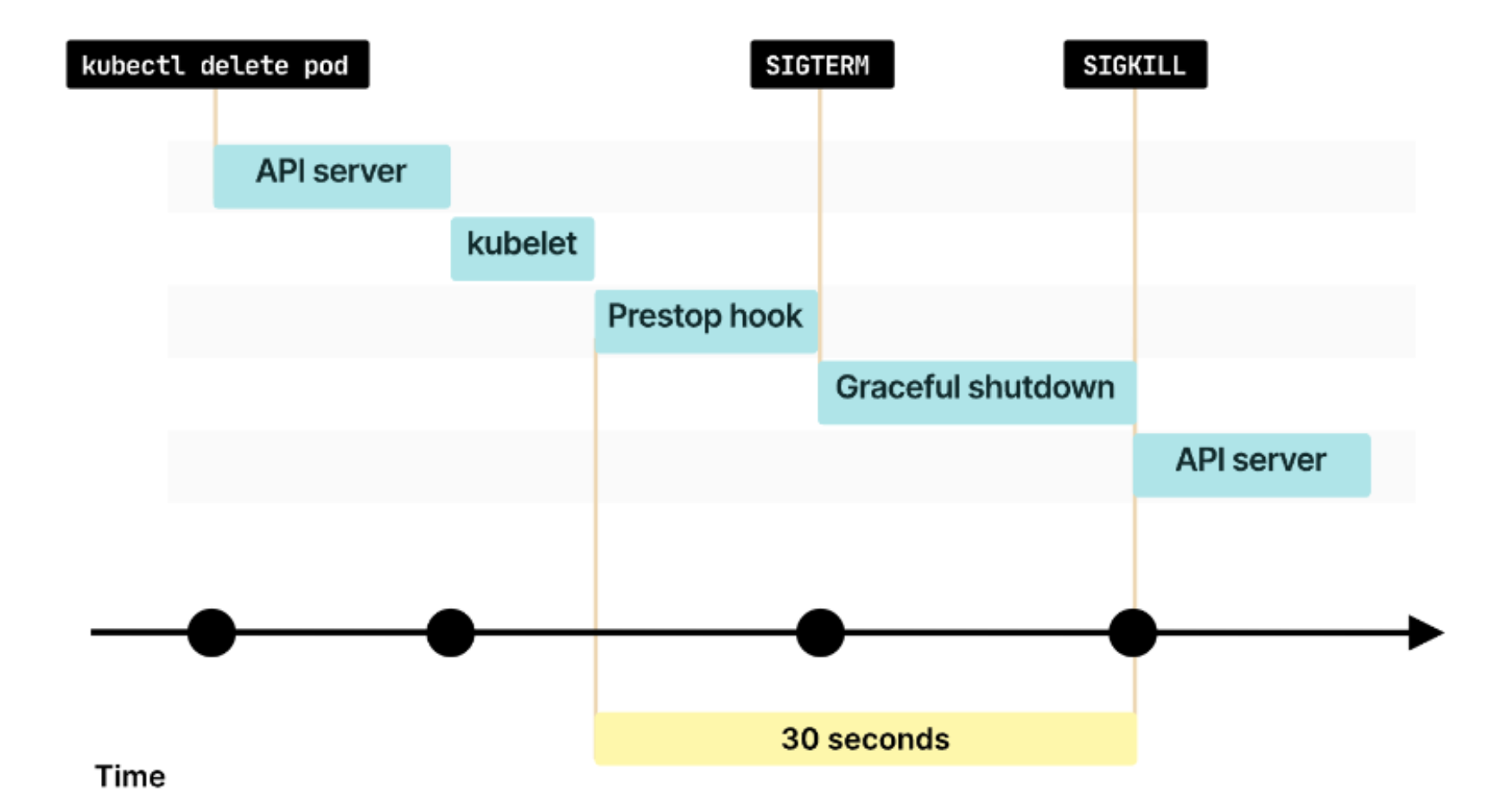
但要注意的是,這個方法還是不能保證順序的正確性,因為無法掌控 DNS Update 的時間,因此即便已經設了延長 30 秒,還是有可能會發生 DNS 還沒 update 完的問題。而在接下來的文章,我們將透過實驗驗證這個方法的有效性成功的機率。
Experiment
Setup
我們首先設定 Zookeeper 的 deployment & service、並加入了 PreStop Hook 的設定,專注測試 PreStop Hook 方法的有效性。

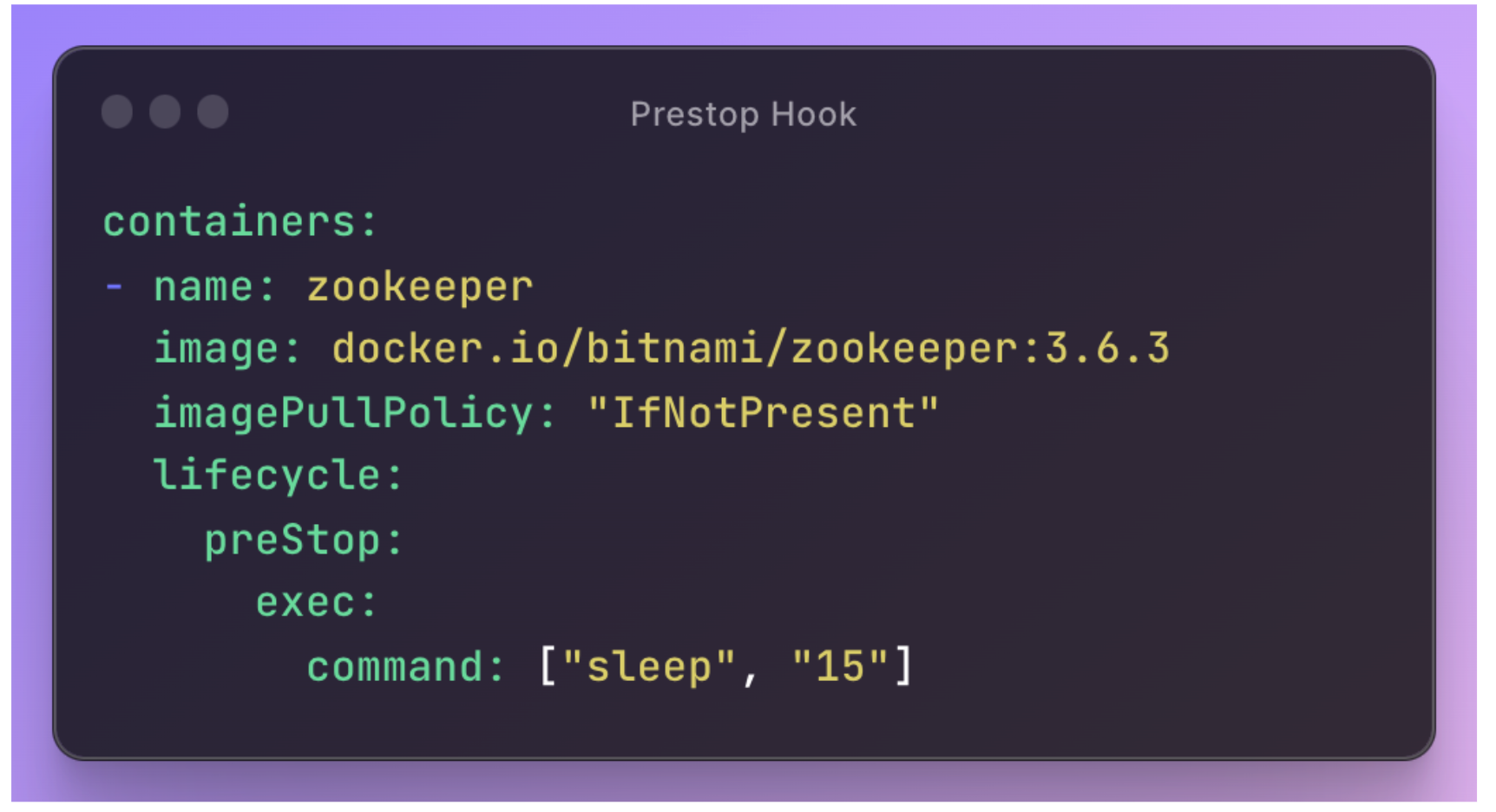
(詳細的 Zookeeper Deployment & Service 設定請參照 Supplementary)
在實驗中,我們設定 3 台 Zookeeper instances 以利觀察 Zookeeper 的 Election 機制。因此在 apply 設定檔到 cluster 上後,應該會觀察到 3 個 Pods:


Process
Check Who Is The Leader and Who Are The Followers
前面有提到可以透過 Zookeeper instance 內提供的 status check script 了解一個 Zookeeper instance 的 role (follower / leader)。因此第一步就是透過進入各個 shell 去逐一確認每個 pod 的 role:
status check script
/opt/bitnami/zookeeper/bin/zkServer.sh status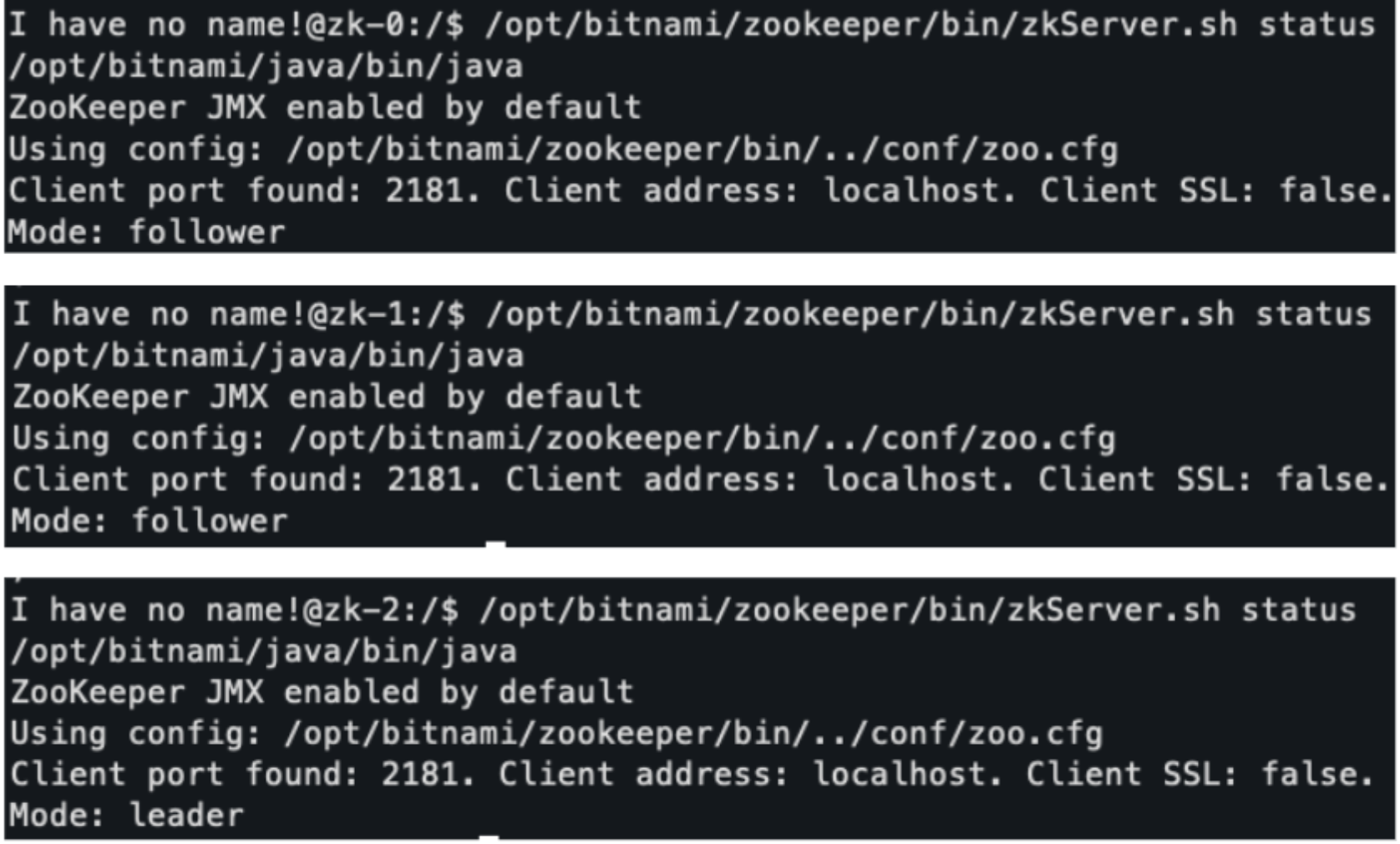

以上圖為例,就可以知道 zk-2 是 Leader,其餘兩個 instances 則為 followers。
Deleting the Leader
我們可以透過 K9s 直接對 pod 下 delete request(下圖假設 zk-0 是 leader):

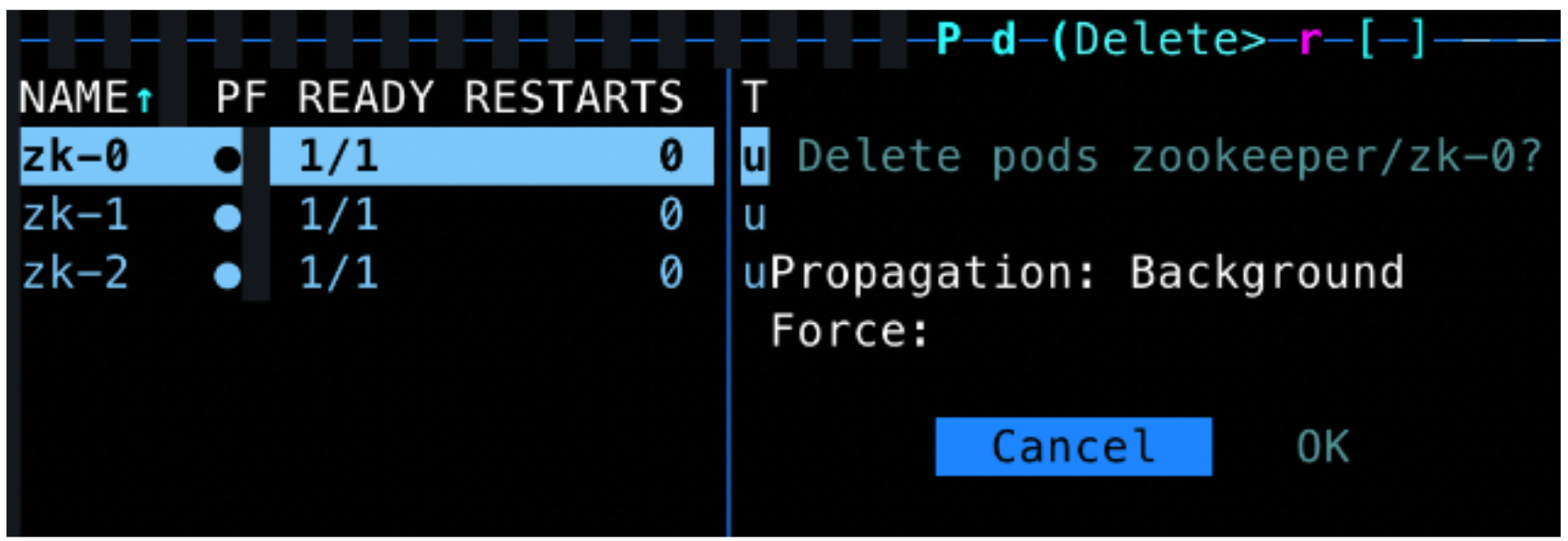
如此就可以觀察 pod 是否成功長回來並能夠參與 Election Process
Check Whether The Restarted Pod Can Join The Quorum
最後一步就是 check Zookeeper Pod 是否成功復原(recover)。如果被 delete 的 pod 在長回來後,能夠重新加入 Zookeeper Server 集群並參與 election process,我們就稱這次的 Zookeeper 有成功復原;如這個 pod 持續呈現 binding error,我們就稱這個 pod 沒有成功 recover。以下是成功 recover 的範例:


以上圖 zk-2 的 log 為例,因為我們在前一步(deleting the leader)將 zk-0 delete 掉,所以可以觀察到 zk-2 跳出無法與第一個 channel,也就是 zk-0 建立連線的 error message。


成功的 recovery 代表 zk-0 重新長出來後能夠 bind 到新的 IP,而不是 fall into old IP。因此如果成功 recover,就能觀察到 zk-0 送 connection request 給 zk-2 希望能夠重新建立連線加入集群。
而如果持續無法 bind 到正確 IP,就會跳出 binding error 的 error message:
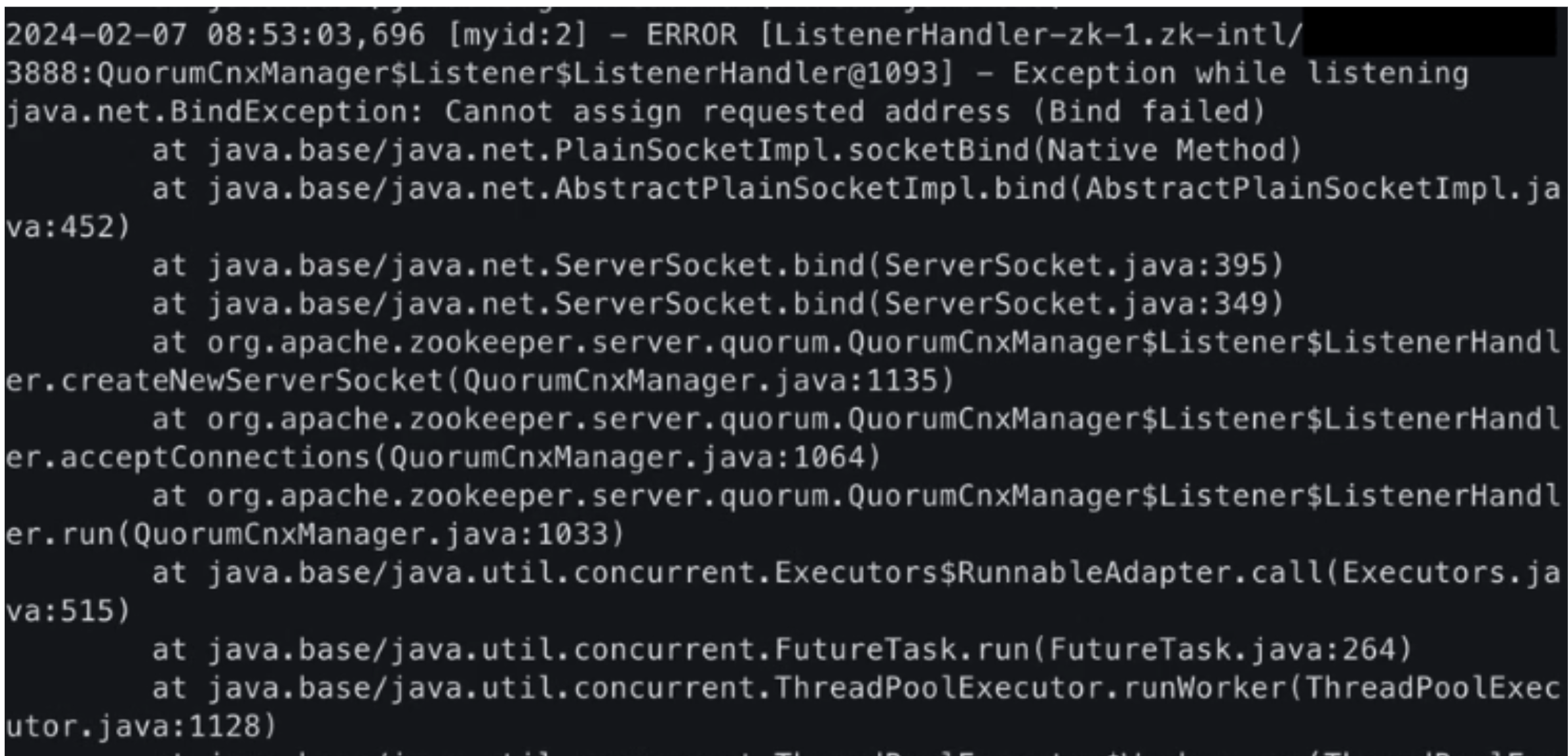
Result Analysis
我們先以 sleep 15s 測試,做了 10 次實驗,發現成功 recover 了 6 次,計算 recovery percentage 為 60%。我們認為原因可能是 sleep 的秒數不夠,DNS Update 還沒更新完全。未來會繼續補做 sleep 20s 以及更長(最多到 30s )的測試,期望能夠得到更好的結果。
Conclusion
在本文中,我們深入探討了Zookeeper在雲端環境下重啟過程中所面臨的挑戰,及解決這些挑戰的可能方法。我們了解到,Kubernetes 環境中進行 Pod 重啟時,可能會遇到因 Race Condition 引發的問題,導致 Zookeeper instance 無法正確綁定新的 IP address。
為了解決這一問題,我們介紹並探討了兩種方法:使用 Startup Probe 進行狀態檢查、每次失敗就砍掉重來的Workaround,以及透過設定 PreStop Hook 實現的 Kubernetes graceful shutdown 策略。透過實驗,我們發現透過延長 Pod termination 的整個過程,我們可以在一定程度上減少由 Race Condition 引起的問題,提高 Zookeeper 重啟時的穩定性。儘管成功機率仍有提升空間,但未來我們可以基於這個發現發想更多實驗來優化現有的解決方案,並開發完善的機制確保 Zookeeper 及相關應用在 cloud 環境上的穩定性。
References
- https://xie.infoq.cn/article/d7cb531aa198e1e8a6750273f
- https://www.runoob.com/w3cnote/zookeeper-tutorial.html
- https://learnk8s.io/graceful-shutdown
Supplementary
Zookeeper Deployment & Service YAML setting
---
# svc-headless
apiVersion: v1
kind: Service
metadata:
name: zk-headless
spec:
type: ClusterIP
clusterIP: None
publishNotReadyAddresses: true
selector:
app: zk
ports:
- name: follower
port: 2888
targetPort: follower
- name: election
port: 3888
targetPort: election
---
# svc
apiVersion: v1
kind: Service
metadata:
name: zk
spec:
selector:
app: zk
ports:
- name: client
port: 2181
targetPort: client
---
# statefulset
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
serviceName: zk-headless
replicas: 3
selector:
matchLabels:
app: zk
revisionHistoryLimit: 0
podManagementPolicy: Parallel
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: zk
spec:
serviceAccountName: default
securityContext:
fsGroup: 1001
initContainers:
- name: volume-permissions
image: busybox
command: ['sh', '-c', 'chown -R 1001:1001 /bitnami/zookeeper']
volumeMounts:
- name: data
mountPath: /bitnami/zookeeper
containers:
- name: zookeeper
image: docker.io/bitnami/zookeeper:3.6.3
imagePullPolicy: "IfNotPresent"
lifecycle:
preStop:
exec:
command: ["sleep", "15"]
securityContext:
runAsUser: 1001
command:
- bash
- -ec
- |
# Custom logic for setting ZOO_SERVER_ID based on hostname
exec /entrypoint.sh /run.sh
resources:
requests:
cpu: 250m
memory: 2000Mi
limits:
cpu: 500m
memory: 2000Mi
env:
- name: ZOO_SERVERS
value: zk-0.zk-headless:2888:3888 zk-1.zk-headless:2888:3888 zk-2.zk-headless:2888:3888
# Other environment variables...
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
ports:
- name: client
containerPort: 2181
- name: follower
containerPort: 2888
- name: election
containerPort: 3888
livenessProbe:
exec:
command: [ '/bin/bash', '-c', 'echo "ruok" | nc localhost 2181 | grep imok' ]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 6
readinessProbe:
exec:
command: [ '/bin/bash', '-c', 'echo "ruok" | nc localhost 2181 | grep imok' ]
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 6
volumeMounts:
- name: data
mountPath: /bitnami/zookeeper
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "1Gi"