Static site generator(이하 SSG)는 웹 문서나 간단한 웹사이트를 만들려는 사람이라면 한 번쯤 들어봤을 단어일 겁��니다. 소프트웨어 플랫폼이나 제품 사이트 중에도 SSG로 만든 것이 꽤 많습니다. React는 Gatsby를 쓰다가 2023년에 재단장하면서 Next.js로 갈아탔고, Kubernetes는 Hugo를 씁니다. LINE의 몇몇 기술 문서도 SSG로 만들었습니다. LINE Developers는 VuePress로 만들었고, LINE Blockchain Developers Docs는 Docusaurus로 만들었죠. LINE의 오픈 소스 Promgen은 Sphinx를 썼고요. 와, 여기까지만 해도 SSG가 6가지나 되네요. 하지만 이게 전부가 아닙니다. JamStack 사이트의 SSG 목록에는 무려 355개(2023년 12월 기준)나 있으니까요.
SSG로 기술 문서 사이트를 하나 만들어 보려다가도 저 많은 SSG를 보면 엄두가 나지 않을 것 같더군요. 그 막막함을 조금이나마 덜어보고자, 문서 엔지니어로서 팀 공용 SSG를 선정해 사용한 경험을 공유하려고 합니다.
이 글에 쓴 예시 중 일부는 실제로 사용한 방식이나 링크한 적용 화면과 다릅니다. 이해를 돕기 위해 예시를 간략하게 만든 경우도 있고, 대상 문서가 업데이트되면서 모양이 바뀐 경우도 있습니다.
팀 공용 SSG 선정
왜 팀 공용 SSG를 선정했는지를 이야기하려면 문서 엔지니어링을 소개하지 않을 수 없겠네요. 문서 엔지니어링이라는 단어만 보면 소프트웨어 엔지니어링과 비슷하게 느낄 텐데요. 예, 맞습니다. 소프트웨어 엔지니어링은 "소프트웨어 개발, 관리, 배포 비용을 낮추고 효율과 품질을 높이는 활동"인데, 여기서 "소프트웨어"를 "문서"로 바꾸면 곧 문서 엔지니어링이 됩니다. 문서를 효율적으로 작성, 관리, 배포하고 품질을 높이는 활동이죠.
LINE Plus Technical Content Strategy 팀은 꾸준히 문서 엔지니어링을 해왔는데요. 기술 문서 규모가 커지고 문서 사이트 기능이 다양해지면서 2023년부터 내부에 별도 파트를 만들어 문서 엔지니어링 영역을 넓히기로 했습니다. 그중에 팀 공용 기술 문서 작성 프로세스를 수립해 신규 기술 문서에 적용하는 활동도 있었는데요. 그때 팀 공용 SSG(static site generator)를 선정하게 됐습니다.
Docs as code와 SSG
문서 엔지니어는 보통 docs as code 방식으로 기술 문서를 작성합니다. Docs as code는 기술 문서를 소스 코드처럼 취급하고 관리하는 접근법으로, 가장 큰 특징은 Git을 이용한 버전 관리와 테스트, 빌드, 배포 자동화입니다. 개발자 친화적인 환경을 제공해 개발자와 협업하기 쉬운 데다, 버전 관리와 자동화 덕분에 다양한 버전을 동시에 작업하거나 배포할 때도 훨씬 안정적이죠. SSG, 특히 문서용 SSG는 자연스럽게 이 특징을 구현하기에 SSG를 사용하는 것이 곧 docs as code를 도입하는 지름길입니다.
Docs as code를 좀 더 자세히 알고 싶으면, Write the docs의 Docs as Code 페이지를 참고하세요.
다만, SSG가 워낙 다양해서 기술 문서마다 조직 성향이나 작성 시기에 따라 각기 다른 SSG를 쓰더군요. 문서 엔지니어링 파트의 목표는 문서 작업 중 불편한 점을 엔지니어링으로 해결하는 것인데, 똑같은 해결책을 SSG에 맞춰 각각 적용한다면 아무래도 작업 효율이 떨어질 수밖에 없습니다. 그래서 팀 공용 SSG를 선정하기로 결정했습니다.
왜 Docusaurus일까?
300개가 넘는 SSG 중에서 팀에서 함께 쓸 도구를 선택할 때 염두에 둔 기준은 두 가지였습니다.
- 웹 문서를 만들 때 필요한 기본 기능에 충실해야 한다.
- 새 기능을 자유롭게 더할 수 있어야 한다.
트리 메뉴 구조와 목차, 마크업 기반 문서 페이지, 다국어 처리 같은 기본 기능은 도구에 맡기되, 혹시 다른 기능을 넣고 싶으면 얼마든지 넣을 수 있도록 세운 기준입니다.
SSG 세상을 떠돈 지 수 년째, 비록 세상에 있는 SSG를 모두 써 보지는 못했지만 제법 많은 SSG를 손대 본 경험에 따라 나름의 기준으로 SSG를 분류해서 LINE DEV Meetup #12에서 소개한 적이 있는데요. 표로 간단히 요약하면 아래와 같습니다. 굵은 글씨는 앞서 말씀드린 기준에 해당하는 내용입니다.
| 분류 | 1세대 SSG | 2세대 SSG | 웹 프레임워크 |
|---|---|---|---|
| 대표 SSG | Jekyll, GitBook(오픈 소스 버전) | VuePress, Docusaurus, Hugo | Next.js, Gatsby, Nuxt, Astro |
| 용도 | 블로그 또는 기술 문서 작성 | 블로그 또는 기술 문서 작성 | 웹 사이트 개발 |
| 학습 난도 | 쉬움 | 쉽거나 어려움 | 어려움 |
| 커스터마이징 | 제약이 큼 | 거의 제약 없음 | 제약 없음 |
두 가지 기준을 모두 만족하는 도구는 2세대 SSG였습니다. Jekyll 같은 1세대 SSG는 사이트를 뚝딱 만들기는 쉽지만 기본적으로 블로그 형태이며 커스터마이징에 제한이 있습니다. Next.js 같은 웹 프레임워크는 웹 문서보다는 웹 사이트를 개발하는 용도로, 목차 자동 생성 같은 문서의 기본 기능조차 일일이 플러그인을 사용하거나 직접 구현해야 합니다.
2세대 SSG로 범위를 좁혔다고 해도 여전히 종류는 많습니다. 하지만 "자유롭게 새 기능을 더할 수 있어야 한다"는 기준을 생각해 볼 때 저에게 익숙한 프로그래밍 언어여야 보다 쉽게 구현할 수 있겠더군요. 그래서 주로 써온 JavaScript 기반 SSG 중에서 후보를 물색했습니다.
사실 프런트엔드에서 JavaScript를 선택한 순간 큰 분기는 둘뿐입니다. React냐 Vue냐. 물론 혜성같이 등장한 다른 프런트엔드 프레임워크도 있지만 SSG 쪽은 아직 React와 Vue가 양분하고 있습니다. 여기서부터는 순전히 개인 취향인데요, 저는 컴포넌트를 분리하고 관리하기 쉬우며 만에 하나 SSG를 바꾸더라도 선택의 폭이 넓은 React를 선택했습니다. React 기반 2세대 SSG라면, React와 만든 곳이 같은 Docusaurus가 최선이었죠. v2에서 MDX를 도입해 문서 페이지별로 유연하게 UI를 적용할 수 있게 된 것��도 Docusaurus를 선택한 중요한 이유였습니다.
VuePress도 자유롭게 커스터마이징할 수 있으니 Vue를 선호한다면 VuePress 역시 좋은 선택지입니다.
상황별 선택지
커스터마이징을 하고자 2세대 SSG 중 하나로 결정한다면 익숙한 언어로 고르는 편이 합당합니다. 문서용 SSG가 제공하는 문서 기본 기능은 거의 비슷하니, 부가 기능을 좀 더 쉽게 구현할 수 있는 쪽이 좋으니까요. 다만, 도구 자체의 기본 메커니즘(지원 마크업 언어나 파일 관리, i18n 처리 방식 등)은 쉽게 바꿀 수 없으니 최종 선택 전에 기본 메커니즘이 마음에 드는지 꼭 확인하세요.
손쉽게 깔끔한 문서를 만들고 싶다면 1세대인 Jekyll이나 GitBook을 추천합니다. 2세대인 VuePress나 VitePress도 기본 출력물이 깔끔하니 커스터마이징하지 않고 쓰기에 좋습니다. 개인적인 평가지만, Hugo는 기본 모양이나 테마가 깔끔하지 않아서 커스터마이징하지 않는다면 추천하지 않습니다.
문서 기본 기능이 꼭 필요하지 않고 틀에 박힌 레이아웃에서 벗어나 나만의 독특한 문서 사이트를 만들고 싶다면 Next.js 같은 웹 프레임워크를 선택하세요(담당 개발자가 있다면 금상첨화!).
기술 문서용 커스터마이징
기술 문서는 복잡한 레이아웃이나 데이터를 처리해야 할 때가 있습니다. 표 안에 목록이나 코드 블록을 써야 하거나, 여러 페이지에 똑같은 문장을 넣는 것이 그 예인데요. 이런 문제는 엔지니어링으로 풀어낼 수 있습니다. 문서 엔지니어가 있는 팀 내 프로젝트는 몇 년 전부터 Docusaurus를 커스터마이징해서 이런 작업을 해왔습��니다. 아래는 그중 대표 항목을 정리한 표입니다.
| 플러그인 / 컴포넌트 | 설명 |
|---|---|
| 줄 바꿈 테이블(예시) | Markdown 테이블 내에서 줄 바꿈을 쓰도록 만들어 줌 |
| 용어집(예시) | YAML로 작성한 용어 설명을 페이지 및 팝업으로 만들어 줌 |
| API 레퍼런스(예시) | YAML로 작성한 API 설명을 레퍼런스 페이지와 목록으로 만들어 줌 |
Docusaurus는 SSG가 흔히 제공하는 플러그인 방식으로도 기능을 더할 수 있고, 테마 기능이나 앞서 말한 MDX를 이용해서 콘텐츠 렌더링 형태를 손볼 수도 있습니다. 기능과 UI를 모두 커스터마이징할 수 있는 데다 둘을 서로 엮기도 쉽죠. 이제부터 각 항목을 왜, 어떻게 구현했는지 살펴보겠습니다.
줄 바꿈 테이블
줄 바꿈 테이블은 팀원들이 가장 원하던 기능입니다. Markdown으로 쓴 표는 읽기 쉽고 깔끔하지만 한계가 뚜렷합니다. 바로 한 셀에 한 줄만 입력할 수 있다는 점 때문이죠. 줄 바꿈도 안 되는 마당에 목록 같은 블록형 문법을 쓰는 건 언감생심, 조금이라도 복잡한 표를 그리려면 HTML로 한 땀 한 땀 써나가야 합니다. 그냥 줄 바꿈이라면 <br> 정도로 어떻게 해��보겠지만, 목록을 넣으려면 눈앞이 깜깜해지죠. 2단계 목록을 한 열 줄 정도 쓰다 보면 태그 하나 빠뜨리기 일쑤고요.
"AsciiDoc이나 reStructuredText를 쓰면 되잖아"라고 생각하겠지만, 그 마크업을 지원하는 SSG가 적을뿐더러 팀원 모두가 그 문법을 익혀야 하는 단점이 있습니다. 더구나 문법 자체가 Markdown만큼 쉽지도 않죠. 단순히 줄 바꿈하거나 목록 정도 넣는 목적이라면 새 마크업을 배우기보단 딱 저 기능만 처리할 새로운 문법을 추가하는 게 낫지 않을까요? (물론 그 후 다양한 요구사항으로 온갖 기능을 집어넣고 있지만, 그 사실은 잠시 잊겠습니다...)
기본 Markdown에 줄 바꿈 표기(여기서는 \)를 덧붙여 처리하려면 Docusaurus가 Markdown을 처리하기 전에 작업해야 하므로 두 가지 방법을 생각해 볼 수 있습니다.
- 기본 Markdown 파서를 가로채기
- 표 부분을 분리해 기본 Markdown 파서 사용하지 않고 처리하기
아쉽게도 Docusaurus의 Markdown 파서인 remark는 Markdown 텍스트를 가로챌 수 없고, 일단 표 안에서 줄 바꿈하면 줄 바꿈 이전까지만 표로 인식해서 AST(abstract syntax tree)로 만들기 때문에 1번 방법은 쓸 수가 없더군요. 하긴, 이게 가능했더라면 벌써 remark용 줄 바꿈 테이블 플러그인이 나왔겠죠.
그래서 2번 방법을 채택했습니다. 줄 바꿈 표기를 사용한 Markdown 텍스트를 MultilineTable이라는 컴포넌트로 감싸 기본 Markdown 파서 대신 이 컴포넌트가 표 문법을 처리하게 만드는 방법입니다.
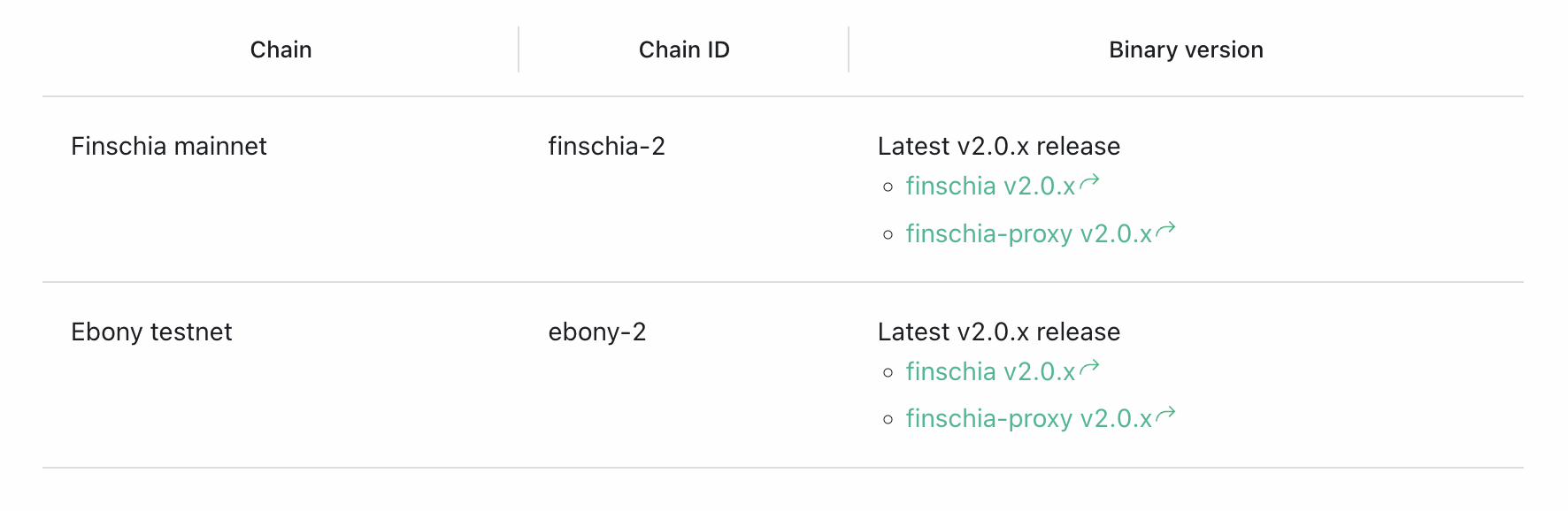
적용한 표를 하나 가져왔는데요, 앞뒤로 컴포넌트 태그가 들어간 걸 빼면 Markdown 문법과 크게 다르지 않죠.
<MultilineTable>
| Chain | Chain ID | Binary version |
|---|---|---|
| Finschia mainnet | finschia-2 | Latest v2.0.x release \
- [finschia v2.0.x](https://github.com/Finschia/finschia/releases/) \
- [finschia-proxy v2.0.x](https://github.com/Finschia/finschia-proxy/releases) |
| Ebony testnet | ebony-2 | Latest v2.0.x release \
- [finschia v2.0.x](https://github.com/Finschia/finschia/releases/) \
- [finschia-proxy v2.0.x](https://github.com/Finschia/finschia-proxy/releases) |
</MultilineTable>렌더링해 보면 줄 바꿈에 목록까지 잘 나타납니다.
 그럼, 2단계 목록도 잘 될까요? 위 예제에서 눈치챘겠지만, 안타깝게도 줄 바꿈 표기(
그럼, 2단계 목록도 잘 될까요? 위 예제에서 눈치챘겠지만, 안타깝게도 줄 바꿈 표기(\) 다음에 오는 줄은 들여쓰기를 얼마나 하던 의미가 없습니다. 첫 번째 목록 아래에 한 단계 더 들어간 "Great Finschia"를 넣는다고 가정해 보겠습니다.
<MultilineTable>
| Chain | Chain ID | Binary version |
|---|---|---|
| Finschia mainnet | finschia-2 | Latest v2.0.x release \
- [finschia v2.0.x](https://github.com/Finschia/finschia/releases/) \
- Great Finschia
- [finschia-proxy v2.0.x](https://github.com/Finschia/finschia-proxy/releases) |
...중략...
</MultilineTable>렌더링해 보면, 윗줄보다 두 칸 더 들여썼는데도 똑같이 1단계 목록처럼 나오죠.
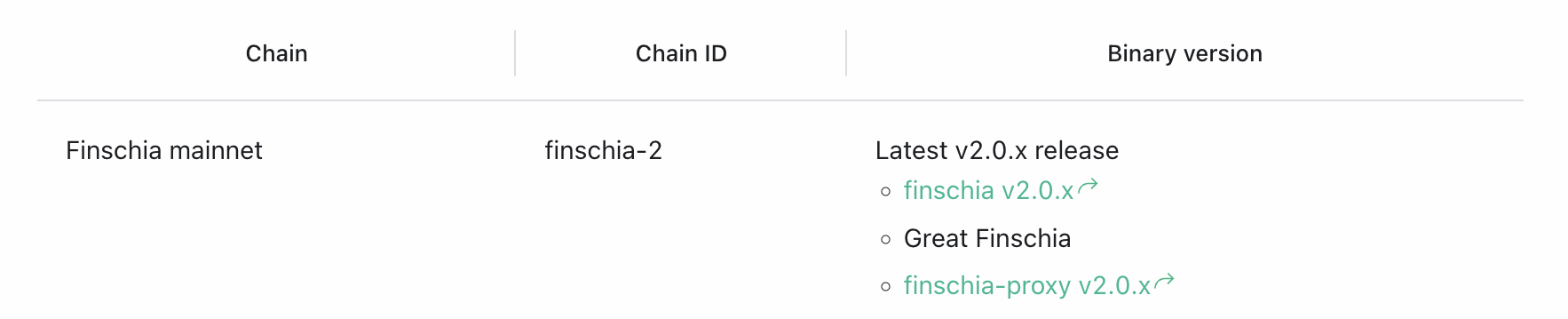
MDX가 컴포넌트에 내용물(children 속성)을 전달할 때 줄 바꿈과 들여쓰기 공백을 제거하기 때문입니다. 그렇다면 들여쓰기를 강제로 유지하거나 다른 방법으로 2단계 수준임을 알려주는 수밖에 없겠네요.
아래는 들여쓰기를 강제로 유지하는 방법입니다.
<MultilineTable children={`
| Chain | Chain ID | Binary version |
|---|---|---|
| Finschia mainnet | finschia-2 | Latest v2.0.x release \\
- [finschia v2.0.x](https://github.com/Finschia/finschia/releases/) \\
- Great Finschia \\
- [finschia-proxy v2.0.x](https://github.com/Finschia/finschia-proxy/releases) |
...중략...
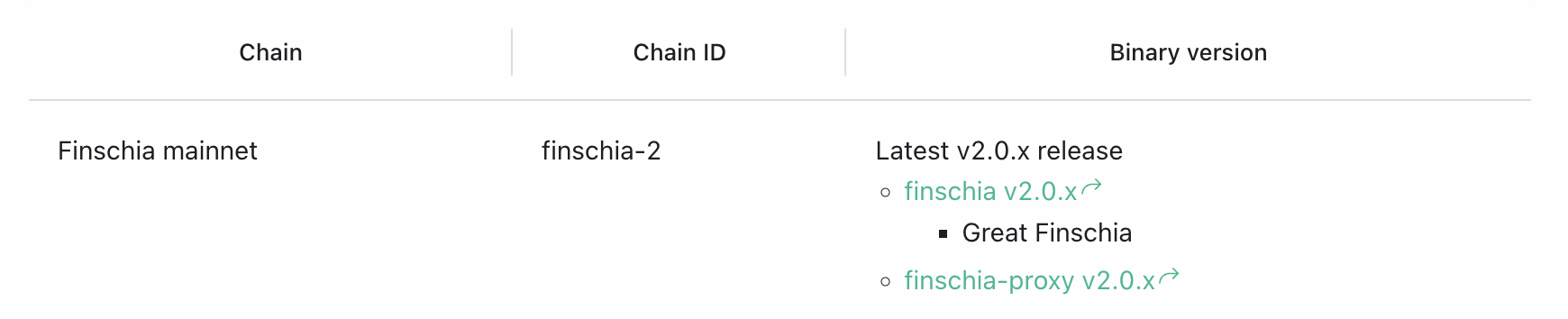
`}></MultilineTable>이 방법은 줄 바꿈 다음에 들여쓰기를 할 수 없으며, 줄 바꿈 표기를 \\로 바꿔야 하는 등 가지각색으로 불편한 점이 있습니다. 게다가 너무 코드 같아서 테크니컬 라이터에겐 눈엣가시로 보일 테죠. 그래서 이와는 별개로 2단계 수준임을 알려주는 표기법을 마련했습니다. 한 수준 더 들어가는 항목 앞에 -를 붙이는 겁니다.
<MultilineTable>
| Chain | Chain ID | Binary version |
|---|---|---|
| Finschia mainnet | finschia-2 | Latest v2.0.x release \
- [finschia v2.0.x](https://github.com/Finschia/finschia/releases/) \
- - Great Finschia \
- [finschia-proxy v2.0.x](https://github.com/Finschia/finschia-proxy/releases) |
...중략...
</MultilineTable>이렇게 하면 아래 그림처럼 2단계 목록도 잘 렌더링됩니다. 비록 Markdown 목록 문법과 똑같지는 않지만 건드릴 부분이 많은 첫 번째 방법보다는 낫겠죠? 이제 저희 팀은 <li></li> 지옥에서 벗어날 수 있게 됐습니다.
팁을 가장한 자랑! 몇 가지 기능을 더해 조금 더 복잡한 표도 Markdown으로 만들 수 있게 했습니다.
용어집 플러그인과 컴포넌트
기술 문서는 낯선 용어를 설명하는 용어집을 제공하기 마련입니다. 일반적으로 용어집 페이지에 간단한 설명과 함께 용어를 나열하고, 본문에 그 용어가 나오면 링크하는 방식을 주로 쓰는데요. 새로운 용어가 많이 나오는 문서에서는 한 문단에 링크가 서너 개씩 나와서 몹시 복잡해 보인다는 단점이 있습니다.
아래 그림에서 API key와 API secret은 용어 설명 링크, Request header는 참고 문서 링크입니다. 독자 입장에서는 그 링크가 무엇인지 알 길이 없으니 무의식적으로 눌러보게 될 텐데요. 한두 줄 설명만 보고 본래 페이지로 되돌아가기를 두 번 반복하면 귀찮아서 세 번째 링크는 눌러보고 싶지 않을지도 모릅니다.

이를 개선하기 위해 다음 두 가지 목표를 세웠습니다.
- 링크가 용어 설명 링크인지 아닌지 구분해 표기하자.
- 한두 줄 설명은 페이지를 이동하지 않고 볼 수 있게 하자.
1번은 CSS를 바꾸면 쉽게 될 일이지만, 2번은 조금 복잡합니다. 어느 페이지에서든 용어 이름과 설명을 읽을 수 있게 하려면 공용 데이터여야 하니까요. 용어 설명을 데이터처럼 다루려면 Markdown보다는 YAML이나 JSON을 사용하는 편이 낫겠죠. 아래는 YAML 형식으로 작성한 용어 설명입니다.
- term: Byzantine fault tolerance
alias: BFT
id: bft
description: |-
A consensus algorithm that allows the system to operate normally as long as it doesn't exceed 1/3 of the total, even if there is a failure
category: B
- term: Block
alias:
id: block
description: 'A unit that manages multiple transactions'
category: B필드는 자유롭게 정하면 되는데, 여기서는 용어 이름과 별칭, 링크할 때 사용할 앵커용 ID, 설명, 카테고리로 정했습니다. 영어만 있으면 카테고리 없이 알파벳으로 자동 분류해도 되지만, 한글과 일어를 함께 제공하기에 직접 입력했습니다.
이 YAML 파일을 읽어 Docusaurus의 전역 데이터(globalData)로 저장하는 것이 용어집 플러그인 역할입니다. 이 전역 데이터는 용어집을 보여주는 컴포넌트와 개별 용어 설명을 보여주는 컴포넌트가 사용합니다.
| 요소 | 설명 |
|---|---|
| 용어집 플러그인 | 용어집 YAML 파일을 읽어 정렬하고 가공해 전역 데이터로 저장 |
| 용어집 컴포넌트 | 전역 데이터를 이용해 용어 목록 표출 |
| 용어 설명 컴포넌트 | 각 페이지에서 용어에 마우스를 가져가면 설명 팝업 |
앞에서 본 링크 3개를 용어 2개와 링크 하나로 바꾼 결과입니다. 용어 설명 컴포넌트 덕분에 API secret에 마우스를 가져다 놓으면 페이지를 이동하지 않고도 설명을 볼 수 있습니다.

전체 용어 목록도 잘 나타납니다.
용어를 데이터로 관리하면 Markdown으로 직접 쓸 때보다 레이아웃이나 스타일 변화에 적응하기도 쉽습니다. 카테고리를 알파벳으로 분류하지 말고 기술 도메인으로 분류해달라는 요청이 왔다면 어떻게 될까요? Markdown으로 작성한 용어집은 용어 이름과 설명을 일일이 복사해서 재정렬해야 하지만, YAML로 작성한 용어는 category 값을 바꾸기만 하면 됩니다.
API 플러그인과 컴포넌트
API 플러그인과 컴포넌트는 순전히 귀찮음을 덜기 위해 만들었습니다. OpenAPI Specification(이하 OAS)를 알고 나서부터 맨땅에 헤딩하듯 API 문서 쓰는 것이 귀찮아서 OAS를 따라 쓰다가, 단순히 문서 작업용으로 만들기에는 OAS가 과하다는 것을 깨닫고 자체 형식을 만들어 사용하기 시작했습니다.
API 플러그인과 컴포넌트는 YAML로 작성한 REST API의 데이터를 수집하고 뷰를 만들어 출력해 줍니다. 프로젝트마다 API 설명 요소가 달라서 뷰를 조금씩 바꿀 수 있게 했고요. 용어집과 마찬가지로 이 역시 API 목록을 보여주는 컴포넌트를 제공하는데요. 항목이 많은 만큼 정렬, 필터링, 페이지네이션 기능도 들어있습니다.
용어집 커스터마이징에서도 언급했듯, Markdown으로 쓴 문서는 레이아웃과 스타일 변화에 취약해서 많은 데이터를 관리하기가 무척 불편합니다. 특히 API는 개수가 많고, 응답 데이터 기본 형식이 달라지거나 없던 예제를 추가하는 등 데이터 구조나 표출 형태가 바뀔 일도 많습니다. 수동으로 하다간 실수하기 십상이죠. 문서 엔지니어링과 API 문서화에서 말했다시피 뷰와 데이터를 분리하는 작업이 꼭 필요한 이유입니다.
| 뷰 / 데이터 합체 | 뷰 / 데이터 분리 |
|---|---|
 | 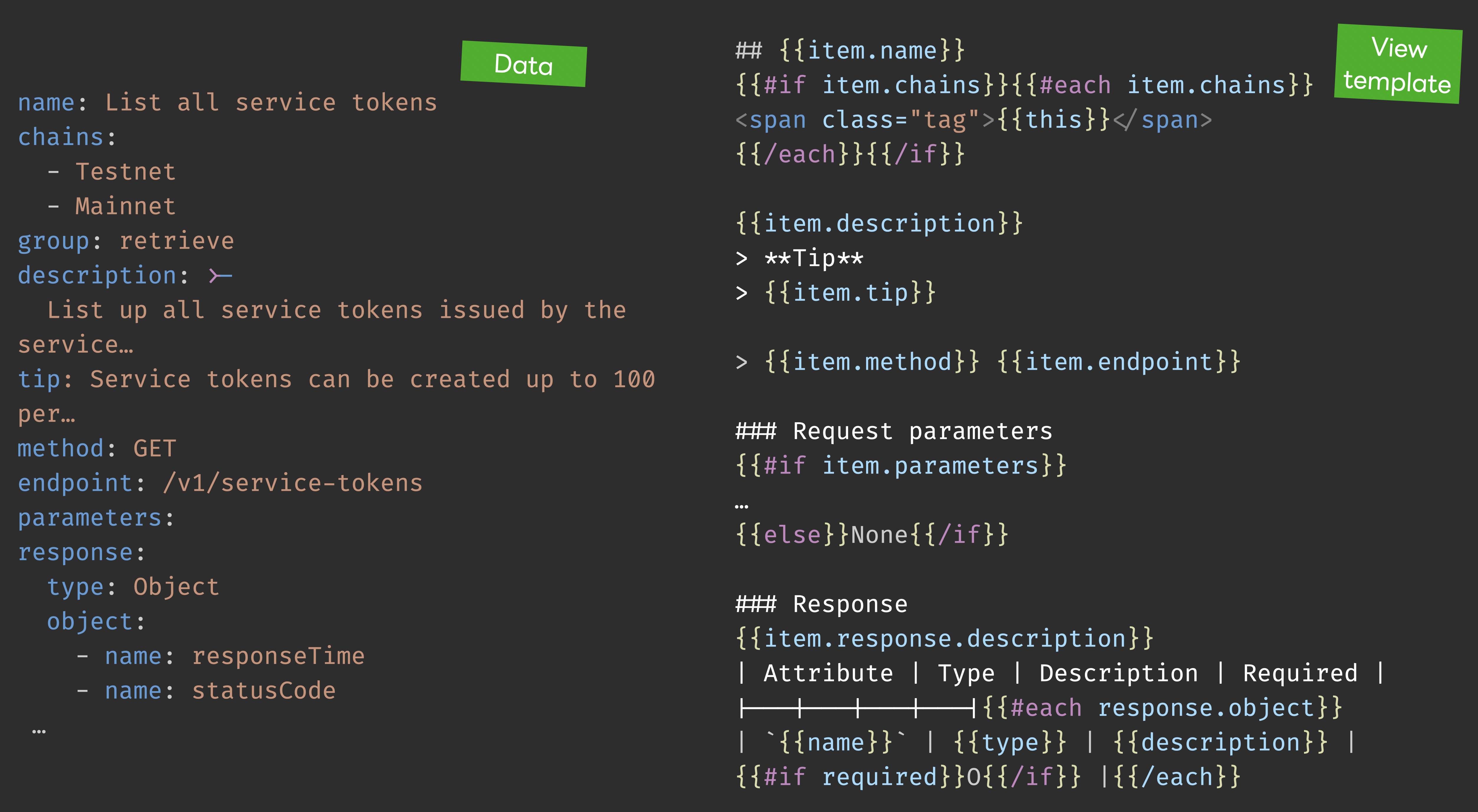 |
위 그림에서 초록색으로 표시한 부분은 Markdown에 들어있는 뷰 요소입니다. 아래 그림처럼 YAML 형식으로 뷰에서 데이터를 쏙 뽑아내고 템플릿으로 뷰를 만들면, 수동으로 처리할 부분이 크게 줄어들죠. API가 총 100개일 때 뷰에서 API 이름과 엔드포인트 위치를 바꾼다고 가정해 봅시다. Markdown만으로 쓰면 Markdown 파일 100개를 모두 고쳐야 하는데, 뷰를 분리한 방식에선 뷰 템플릿만 고치면 되니까 작업 시간이 100분의 1밖에 안 걸립니다. 이런 효율적인 방법을 쓰지 않을 이유가 있을까요?
앞으로는
이렇게 2023년 한 해 동안 팀 공용 SSG를 선정하고 커스터마이징해 문서 작성 효율을 높이고, 같은 방식으로 여러 프로젝트에 적용함으로써 초기 설정 시간과 관리 비용을 줄였습니다. 그래도 여전히 할 일이 남아 있습니다. 이 글에서 기술한 도구와 플러그인은 필요할 때마다 일일이 설치하고 설정하는 방식이라 Docusaurus 설정 작업에 익숙하지 않은 사람에겐 불편할 겁니다. 지금까지는 팀 내에서만 사용해서 별문제 없었지만, 다른 팀 동료도 사용하려면 좀 더 쉽게 시작하는 방법이 필요하겠죠. 누구나 복사해서 쓸 수 있는 기본 템플릿, 사용 안내서 등 사용자가 좀 더 편리하게 쓸 방법이 무엇인지 잘 생각해 본 후 진행하려고 합니다.
또, 공용 SSG를 선정했다고 해도 천년만년 고집할 생각은 아닙니다. 우후죽순 쏟아져 나오는 SSG 중에 더 적합한 것이 있다면 유연하게 갈아탈 수 있도록 앞으로도 SSG를 꾸준히 살펴보겠습니다.
