들어가며
안녕하세요. LINE NEXT DevOps 팀에서 일하고 있는 이동원입니다. 저는 쿠버네티스 기반 인프라 운영과 CI/CD 구축, 모니터링 및 장애 대응 등 인프라 운영 관리 전반의 업무를 담당하고 있으며, 최근에는 AI를 활용한 개발 생산성 향상과 자동화에 깊은 관심을 두고 관련 학습과 실험을 병행하고 있습니다. 다양한 AI 모델과 도구를 테스트하며, 어떻게 하면 AI를 팀 전체의 개발 프로세스에 자연스럽게 통합할 수 있을지 고민하고 있습니다.
이번 글에서는 LINE NEXT에서 AI 기반 코드 리뷰 도구인 Claude Code를 GitHub Actions에 통합하고, 이를 플랫폼 관점에서 표준화하여 조직 단위로 적용한 경험을 공유하고자 합니다. AI 기반 코드 리뷰 도구가 단순히 개인이 사용하는 도구에서 멈추는 것이 아니라 조직 전체에서 함께 사용하며 일관된 개발 경험과 품질을 보장하는 표준 코드 리뷰 구성 요소로 자리 잡은 과정에 초점을 맞추고 공유하겠습니다.
AI 코드 리뷰 플랫폼화 배경
LINE NEXT는 매년 새로운 서비스가 지속적으로 출시되는 환경으로, DevOps 팀은 각 서비스 팀이 개발에만 집중할 수 있도록 공통 인프라와 개발 환경을 제공합니다. 저희와 같이 서비스와 리포지터리 수가 빠르게 증가하는 상황에서는 개발 환경 및 품질 기준 설정 시 개별 팀이나 개인의 기준이나 방식에 의존하기보다는 조직 차원에서 일관적인 기준과 방식을 제공하는 것이 더 좋습니다.
이 글에서 AI 기반 코드 리뷰 도구를 다루며 중요하게 고려할 두 가지 관점이 바로 '성장하는 조직이 마주하는 코드 리뷰 품질 편차'와 '각 개인이 개별로 코드 리뷰에 AI 도구를 활용할 때 �발생하는 한계'입니다. 이 두 가지 관점을 이해하면 왜 DevOps 팀이 Claude Code를 조직 표준 코드 리뷰 구성 요소로 재정의했는지 파악할 수 있습니다.
성장하는 조직이 마주하는 코드 리뷰 품질 편차
LINE NEXT는 개발 조직의 규모가 커지고 프로젝트 수가 늘어나면서 코드 리뷰가 품질 관리를 위한 필수 프로세스로 자리잡았습니다. 하지만 모든 변경 사항을 항상 동일한 기준과 깊이로 리뷰하는 것은 현실적으로 쉽지 않습니다. 리뷰의 관점과 수준은 리뷰어 개인의 경험과 성향에 따라 달라질 수밖에 없으며, 이러한 차이는 자연스럽게 리뷰 품질의 편차로 이어지기 때문입니다. 이 편차는 조직이 성장할수록 누적되면서 개발 경험과 코드 품질 모두에 영향을 미칩니다.
각 개인이 개별로 코드 리뷰에 AI를 활용할 때 발생할 수 있는 한계
최근 저희 회사에는 AI를 활용한 개발 문화가 확산되면서 많은 개발자가 Claude Code를 각자 나름의 방식으로 활용해 코드 변경 사항을 검토하고 개선점을 찾고 있습니다. 이와 같이 개별적으로 활용하는 방식은 로컬 환경에서 빠르게 피드백을 받을 수 있다는 점에서 개인 생산성을 올려준다는 장점이 있지만, 한편으로는 '개인 생산성 도구'로만 활용되면서 다음과 같은 한계도 드러냈습니다.
- 리뷰 기준이 상이함: 각자 다른 방식으로 도구를 사용하다 보니 리뷰 기준 및 관점이 통일되지 않았습니다.
- 조직 차원의 일관성 부재: 각자 로컬 환경을 중심으로 활용하다보니 품질 프로세스를 팀 전체로 하나로 묶기가 어려웠습니다.
- 프로세스의 단절: 리뷰 결과가 PR(pull request) 워크플로에 자연스럽게 녹아들지 못했습니다.
- 온보딩의 어려움: 신규 구성원에게 동일한 수준의 리뷰 경험을 즉시 제공하기 어려웠습니다.
이와 같은 한계는 DevOps 관점에서 보면 단순히 도구 활용의 문제를 넘어 품질 프로세스가 개인 단위로 분산되고 있다는 신호였습니다. 이러한 문제 의식 속에서 저는 Claude Code를 단순히 개인 생산성을 높이는 도구로 두는 대신에 개발 프로세스에 자연스럽게 녹아드는 ‘표준 코드 리뷰 구성 요소’로 재정의하고자 했습니다.
GitHub Actions 기반 Claude Code를 선택한 이유
제가 새로운 도구를 도입할 때 가장 중요하게 고려하는 기준 중 하나가 '기존 개발 흐름을 해치지 않으면서 조직 단위로 확산 가능한가'입니다. LINE NEXT에서는 소스 코드 관리 플랫폼으로 GitHub를 사용하며, 대부분의 서비스 리포지터리에서 CI/CD와 다양한 자동화의 기반으로 GitHub Actions를 활용하고 있습니다. 따라서 GitHub Actions는 기존 개발 흐름을 해치지 않으면서 리포지터리 단위로 손쉽게 적용할 수 있고, 공통 워크플로를 통해 표준화한 사용 방식을 제공할 수 있다는 점에서 여러 서비스 팀이 공존하는 저희 환경에서 조직 단위로 확산할 수 있는 딱 맞는 선택지였습니다. 특히 DevOps 팀 입장에서는 실행 환경이나 운영 요소를 각 서비스마다 구성하지 않고 중앙에서 관리하며 자동화하고 확장할 수 있다는 게 큰 장점이었습니다.
또한 사내에는 이미 Claude Code를 공식적으로 사용할 수 있는 환경이 마련돼 있었고, Claude에서는 GitHub Actions와 연동할 수 있는 공식 Action을 오픈소스로 제공하고 있었습니다(참고: Claude Code Action). Claude Code Action은 단순히 AI 호출을 자동화하는 것을 넘어 PR 중심의 개발 흐름에 자연스럽게 통합될 수 있도록 설계돼 있습니다. PR을 분석해 코드 리뷰와 개선 사항을 제안할 수 있고, 제안 사항을 GitHub 댓글이나 PR 리뷰 형태로 바로 남길 수 있으며, 개발자는 UI 등을 별도로 학습할 필요 없이 기존에 사용하던 GitHub 환경에서 AI의 피드백을 즉시 확인할 수 있습니다.
실행 환경 측면에서도 장점이 있었습니다. Claude Code Action는 GitHub Actions에서 작동하며, DevOps 팀에서는 이를 위해 조직 공통의 GitHub App Runner 환경을 사전에 구성해 놓았습니다. 각 서비스 리포지터리에서 이 공통 Runner를 사용하도록 연동하면 실행 환경과 권한 모델을 중앙에서 통제할 수 있었고, 서비스 팀 입장에서는 추가 인프라를 구성하거나 운영할 필요 없이 바로 AI 기반 코드 리뷰를 사용할 수 있는 구조를 만들 수 있었습니다. 즉 DevOps팀이 공통 실행 환경을 플랫폼 형태로 제공하면 개별 서비스 팀에서는 GitHub Actions 설정만으로 Claude Code를 사용할 수 있는 상태가 된 것입니다. 이 방식은 운영 복잡도를 증가시키지 않으면서도, 조직 전체에 일관된 실행 환경과 보안 기준을 적용할 수 있다는 중요한 장점이 있습니다.
종합해 보면, Claude Code GitHub Action은 다음과 같은 장점이 있습니다.
- PR 기반 코드 리뷰 및 피드백 제공
- GitHub 댓글 및 리뷰와 자연스럽게 통합
- DevOps 팀이 제공하는 공통 GitHub App Runner 환경에서 실행 가능
- 공통 실행 환경 제공 후 서비스 팀 단위의 추가 인프라 구성 불필요
이와 같은 장점 때문에 DevOps 팀에서는 이를 조직 공통으로 재사용 가능한 자동화 구성 요소로 판단했으며, 각 서비스 팀이 최소한의 설정만으로 AI 기반 코드 리뷰를 기존 개발 프로세스에 포함할 수 있도록 플랫폼 관점에서 도입하기로 결정했습니다.
Claude Code Action을 표준화하기 위한 구조 설계
Claude Code Action을 사용하기로 결정한 다음에는 Claude Code Action을 표준화하기 위한 구조를 설계했습니다. 설계 과정에서 제가 어느 포인트에 주안점을 뒀는지 말씀드리겠습니다.
AI 코드 리뷰를 ‘시스템’으로 만들기 위한 접근
“어떻게 하면 수십 개의 프로젝트에 동일한 품질의 AI 코드 리뷰를 안정적으로 제공할 수 있을까?”
Claude Code Actions 도입을 검토하며 제가 가장 깊이 고민했던 질문입니다. 문제의 본질은 단순히 GitHub Actions에서 AI를 실행하는 방법이 아니었습니다. '리뷰 기준과 결과의 일관성을 조직 차원에서 어떻게 보장할 것인가' 이것이 핵심 과제였습니다.
각 리포지터리마다 AI 설정과 프롬프트를 개별적으로 관리하는 방식은 초기 도입은 빠를 수 있지만, 프로젝트 수가 늘어날수록 확산 속도와 운영 안정성 측면에서 명확한 한계를 드러냅니다. 프롬프트 수정이나 정책 변경이 발생할 때마다 모든 리포지터리를 직접 수정해야 하고, 그 과정에서 다시 리뷰 품질의 편차가 발생하기 쉽기 때문입니다. 이에 저는 방향을 아래와 같이 명확히 정했습니다.
- 리뷰 기준과 실행 로직은 중앙에서 통제하고 각 서비스 리포지터리에는 ‘호출'만 남기는 구조를 만든다.
호출은 단순하게, 책임은 중앙으로(caller-executor 구조)
설계한 구조의 핵심은 역할을 엄격하게 분리하는 데 있습니다. AI 리뷰를 어디서 호출할 것인가(caller)와 어떻게 실행할 것인가(executor)를 분리해 복잡도를 중앙으로 수렴시켰습니다.
- 서비스 리포지토리(caller): AI 코드 리뷰의 진입점 역할만 수행합니다. 표준 워크플로를 호출하며 서비스명과 리뷰 타입만 전달하는 단순한 구조를 유지합니다.
- 중앙 리포지토리(executor): DevOps 팀이 관리하는 이 영역은 프롬프트 관리, 리뷰 정책, 권한 위임, 실행 로직까지 모든 책임을 집약합니다.
이 구조를 통해 AI 코드 리뷰는 개별 프로젝트마다 설정해야 하는 기능이 아니라 조직 차원에서 제공하는 공통 플랫폼 기능으로 작동합니다.
Claude Code Action은 다음과 같은 흐름으로 구성됩니다.
- 태그 기반 트리거: PR에
@claude멘션 시 GitHub Actions가 변경 사항을 감지 - 페르소나 기반 리뷰 실행: 중앙에서 정의한 리뷰 페르소나와 프롬프트를 기준으로 분석 수행
- 개발 흐름과의 통합: 별도 도구 전환 없이 PR 내 댓글 및 리뷰 형태로 결과 제공
아래 다이어그램은 개발 팀이 관리하는 서비스 리포지터리와 DevOps 팀이 관리하는 중앙 Claude Code Action 리포지터리 간의 상호작용을 나타냅니다.
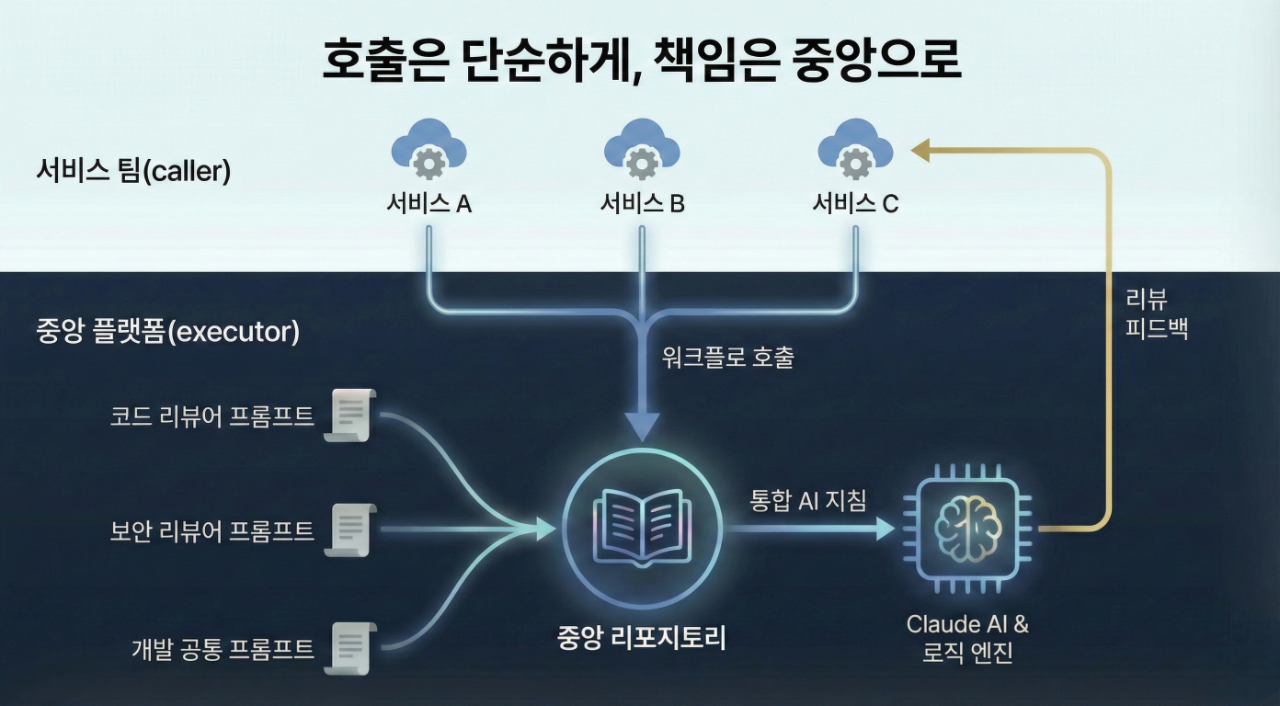
이 구조의 �핵심은 ‘실행의 호출(caller)’과 ‘실행의 주체(executor)’를 분리했다는 점입니다. 개발 팀은 내부 구현을 알 필요 없이 표준화된 리뷰 프로세스를 호출하기만 하면 되고, 실제 분석 로직과 정책 변경의 책임은 중앙으로 수렴됩니다. 그 결과 각 서비스 리포지터리는 단순한 진입점 역할만 수행하고, 복잡성과 운영 책임은 DevOps 팀이 관리하는 중앙 영역으로 집중시킬 수 있었습니다.
중앙화된 제어로 확보한 품질, 확산성, 그리고 질서
이와 같이 구조를 변경함으로써 AI 코드 리뷰는 개별 리포지터리 설정 작업에서 중앙에서 관리하는 조직 공통 시스템이 되었습니다. 이런 변화는 단순히 관리의 편의뿐 아니라 다음과 같은 세 가지 핵심 가치를 제공합니다.
- 리뷰 품질의 일관성 보장 : 리뷰 페르소나와 프롬프트를 중앙 저장소에서 관리함으로써 어떤 서비스 리포지터리에서도 동일한 기준과 관점으로 리뷰가 수행됩니다. 리뷰의 톤과 깊이, 지적해야 할 우선순위, 보안 및 안정성 관점의 필수 체크 포인트는 모두 코드가 아닌 설정과 프롬프트로 정의되며, 중앙에서 수정하면 즉시 전체에 반영됩니다.
- 가속화된 확산 속도 : 서비스 리포지터리에서 표준 GitHub Actions 워크플로를 추가하고 서비스 이름과 리뷰 타입만 지정하면 바로 공통 리뷰 파이프라인에 연결됩니다. 이를 통해 새로운 프로젝트가 추가되더라도 DevOps 팀의 개별 개입 없이 빠르게 온보딩할 수 있고, 조직 전체로 확산되는 비용을 최소화할 수 있습니다.
- 보안 및 거버넌스 강화: AI 호출과 외부 통신, 권한 위�임, 실행 환경을 모두 중앙에서 관리합니다. GitHub Apps 기반 인증과 Secrets 중앙 관리, 공통 GitHub App Runner 운영을 통해 실행 주체와 해당 주체의 접근 권한을 명확히 파악할 수 있고, 결과적으로 '누가, 어떤 권한으로, 어떤 코드에 접근했는가'를 항상 추적할 수 있는 상태를 유지할 수 있습니다.
설계 과정에서 마주한 한계와 이를 극복하기 위해 구조에 반영한 결정들
표준화하는 과정에서 Claude Code Action을 공식 저장소에 있는 그대로 쓰기에는 조직 운영 환경에서 몇 가지 한계가 있는 것으로 나타났습니다. 이 한계를 극복하기 위해 진행한 핵심 커스터마이징 사례를 공유합니다.
사례 1: 포크(fork) 기반 PR 환경에서 드러난 Claude Code Action 실행 구조의 한계
첫 번째 사례는 포크에서 생성된 PR을 제대로 처리하지 못하는 것을 발견하고 그 원인을 파악한 후 구조적으로 개선한 사례입니다.
[마주한 한계] 외부 기여를 가로막는 브랜치 인식 오류
가장 먼저 확인된 문제는 외부 포크 기반 PR(remote branch PR) 환경에서 변경 코드를 정상적으로 인식하지 못하는 이슈였습니다. 공식 Claude Code Action은 변경 코드가 로컬 저장소에 존재하는 브랜치를 기준으로 처리한다는 전제가 있었고, 이로 인해 포크에서 생성된 PR의 경우 차이(diff)를 정확히 가져오지 못하는 상황이 발생했습니다.
- 현상: 공식 Claude Code Action 실행 시
couldn't find remote ref에러와 함께 프로세스��가 중단됐습니다. - 원인: Claude Code Action은 PR에서 전달된 브랜치 이름을 기준으로 단순히
origin에서 해당 브랜치를fetch하도록 구현돼 있었습니다. Claude Code Action 저장소 이슈 #233에서도 확인할 수 있듯 이는 도구 자체의 제약이었습니다. - 플랫폼 관점에서의 영향: 단순한 에러를 넘어 외부 기여자나 협업 저장소와의 연동을 차단하는 구조적 제약이었습니다.
아래는 실제 테스트할 때 오류가 발생했던 상황입니다.
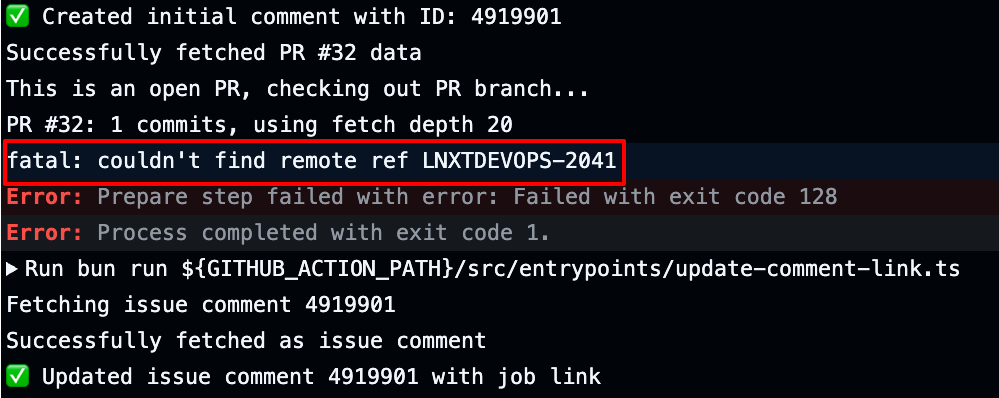
이 문제는 조직 단위로 확산되는 코드 리뷰 시스템을 설계하는 관점에서는 단순히 특정 옵션을 보완해서 해결할 수 있는 문제가 아니라 반드시 해소해야 할 구조적 제약이었습니다. LINE NEXT의 개발 환경에서는 외부 기여자나 협업 리포지터리를 통한 PR이 자연스럽게 발생하기 때문입니다.
[해결 과정] GitHub의 ‘비밀 통로’, 전용 ref 활용
먼저 문제가 발생한 코드의 실행 구조는 매우 단순했습니다. PR 이벤트에서 전달된 브랜치 이름을 기준으로 origin 저장소에서 해당 브랜치를 fetch하고 checkout하는 방식입니다.
// Claude Code Actions 원본 구조
await $`git fetch origin --depth=${fetchDepth} ${branchName}`;
await $`git checkout ${branchName} --`;그런데 이 실행 구조에는 다음과 같은 전제가 존재합니다.
- PR 브랜치는 반드시
origin저장소에 존재한다. - 포크 저장소에서 생성된 PR은 고려하지 않는다.
포크 PR의 경우 브랜치가 베이스 저장소(origin)가 아니라 외부 저장소에 존재하기 때문에 이 전제를 만족할 수 없어 실행 실패로 이어졌습니다. 앞서 말씀드렸듯 이는 조직 내/외부 기여를 모두 포괄해야 하는 플랫폼 관점에서는 치명적인 구조적 제약이었습니다. 따라서 문제를 해결할 때 '포크 PR을 예외 처리한다'는 수준으로 접근하지 않았습니다. 대신 GitHub이 PR을 어떻게 관리하고 있는지를 다시 살펴보면서 '예외 처리'가 아닌 '실행 흐름을 재설계'하는 방향으로 접근했습니다.
저는 GitHub이 모든 PR(포크 포함)에 대해 저희 저장소(origin)에 refs/pull/<PR 번호>/head라는 특수한 참조(ref)를 자동으로 생성한다는 점을 이용했습니다. 즉, 상대방의 포크 저장소에 직접 접근하지 않더라도 GitHub이 이미 저희 쪽(origin)에 PR 코드를 미러링해 두고 있다는 것에 기반해 실행 흐름을 재설계했습니다.
재설계한 실행 흐름은 다음과 같습니다.
- 재설계 소스 코드:
src/github/operations/branch.ts
- PR 출처 판별 로직 추가: 먼저 GitHub API 데이터를 통해 해당 PR이 내부 브랜치인지 외부 포크 저장소인지 판별합니다.
// PR 데이터로부터 Fork 여부 판별 const headOwner = prData.headRepositoryOwner?.login || prData.headRepository?.owner?.login; const isFork = prData.isCrossRepository || (headOwner && headOwner !== owner); - 코드
fetch방식 고도화: 브랜치 이름 대신 PR 번호 기반의 전용 ref를 사용하여 코드를checkout하도록 로직을 수정했습니다.
if (isFork) { # [Fork PR 방식] GitHub이 생성한 비밀 통로(pull/${entityNumber}/head)에서 코드를 가져옴 await $`git fetch origin --depth=${fetchDepth} pull/${entityNumber}/head:${branchName}`; await $`git checkout ${branchName}`; } else { # [일반 PR 방식] 기존처럼 직접 브랜치 체크아웃 await $`git fetch origin --depth=${fetchDepth} ${branchName}`; await $`git checkout ${branchName} --`; }pull/${entityNumber}/head: 이것이 앞서 소개한 '비밀 통로'로,entityNumber는 PR 번호(예: PR #42)를 말합니다. GitHub은 PR이 생성되면 자동으로refs/pull/42/head라는 위치에 해당 코드를 복사해 둡니다.:${branchName}: 위 비밀 통로에서 가져온 코드를 로컬 환경에서 부를 이름을 뜻합니다. 여기에 입력한 이름으로 부르겠다는 뜻입니다.
[도입 효과] 어떤 출처의 코드라도 수용하는 안정성
재설계 전과 후의 차이와 특징은 다음과 같습니다.
| 구분 | 대상 위치(원격) | 로컬 저장 방식 | 특징 |
|---|---|---|---|
| 기존(에러 발생) | origin/${branchName} | checkout 실패 | 포크 브랜치는 origin에 없어서 ��못 찾음 |
| 변경(일반 PR) | origin/${branchName} | 직접 checkout | 우리 팀 브랜치이므로 바로 가져옴 |
| 변경(포크 PR) | origin/pull/${PR번호}/head | 이름 붙여서 가져오기 | 상대방 저장소에 갈 필요 없이 origin에서 해결 |
이 커스터마이징을 통해 얻은 이점은 단순히 '에러가 사라졌다'는 수준을 넘습니다.
- 포크 PR을 비롯한 외부 기여와 내부 협업을 모두 포괄하는 실행 안정성 확보
- PR 출처에 관계없이 동일한 코드 리뷰 파이프라인 유지
무엇보다 중요한 점은 이 변경이 개별 프로젝트의 편의 개선이 아니라 Claude Code Action을 조직 단위로 확장 가능한 플랫폼으로 만들기 위한 설계 결정이었다는 것입니다.
사례 2: 일관적인 응답을 받기 위해 프롬프트 구조 재정의
두 번째 사례는 AI 코드 리뷰 도구가 일관적인 응답을 하도록 프롬프트 구조를 재정의한 사례입니다.
[마주한 한계] 사용자 입력에 따라 변동되는 리뷰 품질
GitHub PR에서 @claude를 호출하면 AI가 코드 리뷰를 수행하는 GitHub Action을 운영하면서, 다음과 같은 현상이 반복적으로 나타나는 것을 관측할 수 있었습니다.
- 현상: 사용자마다
@claude 보안 검토해줘,@claude review this,@claude 성능 체크처럼 요청 방식이 달랐고, 결과 형식도 매번 달라졌습니다. - 원인: 기존 코드 구조에서는 사용자가
@claude뒤에 남기는trigger_comment가 최우선 지시 사항으로 처리됐습니다. 즉,trigger_comment가 주 지시 사항이 되고, 워크플로에 설정된 프롬프트(custom_instructions)는 단순 참고용 컨텍스트로 취급됐습니다. - 플랫폼 관점에서의 영향: 출력 형식이 가변적이면 후속 프로세스(데이터 파싱, 지표화)가 불가능해지며, 조직 차원에서 합의된 최소 품질 가이드라인을 강제할 수 없습니다.
[해결 과정] '무엇을(what)'과 '어떻게(how)'의 위계 정립
저는 프롬프트의 역할을 사용자의 의도(what)와 시스템 가드레일(how)로 엄격히 분리해 AI에게 명확한 '법'을 제시했습니다.
| 구분 | 역할 | 담당 주체 |
|---|---|---|
| 무엇을(what) | 어떤 부분에 집중해 분석할 것인가 | 사용자 코멘트(trigger_comment) |
| 어떻게(how) | 어떤 페르소나와 형식으로 응답할 것인가 | 워크플로 설정(custom_instructions) |
- 지시 사항의 위계 정립: 시스템이 정한 출력 형식이 사용자의 코멘트보다 상위의 명령임을 AI에게 명시적으로 주입합니다.
- 재설계 소스 코드:
src/create-prompt/index.ts - AI에게 어떤 지침이 '법'이고 어떤 지침이 '가이드'인지 명확히 선을 그어줍니다.
// Before: 사용자 코멘트가 최우선 - Only follow the instructions in the trigger comment. // After: 시스템 가이드라인(포맷)이 최우선 + CRITICAL: The trigger comment tells you WHAT to focus on. + CRITICAL: The <custom_instructions> section defines the MANDATORY output format. + You MUST apply the format from <custom_instructions> regardless of what the trigger comment requests.
- 재설계 소스 코드:
- 구조적 가드레일 설치: 사용자 입력에 휘둘리지 않도록 아예 시스템 프롬프트 섹션 자체를 강제 조항으로 래핑(wrapping)합니다.
- 재설계 소스 코드 :
src/modes/tag/index.ts - 사용자 입력에 변동되지 않도록
custom_instructions섹션 자체에 강제 조항을 래핑했습니다.
<custom_instructions> IMPORTANT: The following instructions define the MANDATORY structure, format, and guidelines for your response. The trigger comment specifies WHAT to focus on (e.g., "review security", "check performance"). These custom instructions specify HOW to structure your response and WHAT categories to include. If the trigger comment asks for specific focus areas, you should emphasize those areas, but you MUST still provide analysis using the complete structure and format defined below. For example: - Trigger comment: "review security" → Focus on security but report using full format - Trigger comment: "code review" → Comprehensive review following all guidelines ${context.githubContext.inputs.prompt} // 실제 사용자가 설정한 워크플로 템플릿 </custom_instructions>
- 재설계 소스 코드 :
[최종 프롬프트 구성 시각화]
사용자가 @claude 코드 리뷰 해줘라고 호출했을 때 시스템 내부에서 조합되는 최종 프롬프트의 구조는 다음과 같습니다.

[도입 효과] 데이터 활용이 가능한 ‘예측 가능한 AI’
이 변경을 통해 AI는 단순히 사용자 명령을 그대로 수행하는 단계를 넘어 공통화/표준화된 리뷰 품질과 형식을 유지하는 가드레일 기반의 플랫폼 구성 요소로 진화했습니다.
- 완전히 일관적인 응답 형식 확보
- 자동화 및 데이터 활용 가능
- 사용자의 의도는 유연하게 반영하면서 조직의 품질 가드레일을 유지
이는 단순한 프롬프트 튜닝이 아니라, AI 코드 리뷰를 플랫폼 자산으로 다루기 위한 핵심 설계 결정이었습니다.
| 비교 항목 | 기존 | 커스텀 변경 후 |
|---|---|---|
| 우선순위 | 사용자 입력 > 시스템 템플릿 | 시스템 템플릿 > 사용자 입력 |
| 응답 형태 | 가변적(사용자 요청에 따라 변함) | 고정적(정해진 섹션 모두 포함) |
| AI의 태도 | 시키는 것만 수행함 | 맥락을 반영하되 보고서 형식을 준수함 |
| 데이터 활용 | 자동화/파싱이 어려움 | 일관된 형식으로 후속 처리 용이 |
위와 같은 변경이 어떻게 작동하는지 아래 예시 시나리오와 함께 살펴보겠습니다.
# 실제 코멘트
@claude 코드 리뷰해줘.
# Claude가 받는 최종 프롬프트는 다음과 같은 구조로 조합
<trigger_comment>
@claude 코드 리뷰해줘.
</trigger_comment>
<custom_instructions>
IMPORTANT: 아래 지침은 응답의 필수 구조, 포맷, 가이드라인을 정의합니다.
트리거 코멘트가 무엇을 요청하든, 반드시 아래 모든 지침을 따라야 합니다.
예시:
- 트리거 코멘트: "코드 리뷰해줘" → 아래 분류 체계와 포맷에 따라 전체 리뷰 수행
## 📋 Review Outcome Classification
- **🚫 Blocking Issues**: 반드시 수정이 필요한 항목 (보안, 버그, 아키텍처 위반)
- **⚠️ Recommended Changes**: 권장 개선 사항 (성능, 가독성, 베스트 프랙티스)
- **💡 Suggestions**: 선택적 개선 아이디어 (리팩토링, 최적화 기회)
- **📝 Tech Debt**: 향후 개선이 필요한 기술 부채
## 🎯 Common Review Areas
### 1. Code Quality & Design Principles
- 단일 책임 원칙 (SRP), DRY, KISS 준수 여부
- 함수/변수 네이밍, 중첩 깊이, 매직 넘버 사용
### 2. Error Handling & Null Safety
- Null/Undefined 참조 가능성
- 예외 처리의 적절성
### 3. Security Best Practices
- Input Validation, SQL Injection, XSS 방어
- 민감 정보 노출 여부
## 📝 각 이슈별 출력 포맷
1. **📍 위치**: 파일명과 라인 번호
2. **🔍 문제 설명**: 이슈가 무엇인지 명확히 설명
3. **❌ 문제 코드**: 해당 코드 인용
4. **✅ 권장 수정**: 개선된 코드 예시
5. **💡 이유**: 왜 이 변경이 코드를 개선하는지 설명
## 📊 리뷰 요약 테이블
| 분류 | 건수 |
|------|------|
| 🚫 Blocking Issues | N건 |
| ⚠️ Recommended Changes | N건 |
| 💡 Suggestions | N건 |
| 📝 Tech Debt | N건 |
⚠️ **모든 리뷰 결과는 반드시 한국어로 작성해주세요.**
</custom_instructions>이 예시 시나리오를 Claude는 다음과 같이 해석합니다.
| 구분 | 내용 |
|---|---|
무엇을(trigger_comment) | "코드 리뷰해줘" → PR 전체 코드 리뷰 수행 |
어떻게(custom_instructions) | 조직에서 정의한 분류 체계, 출력 형식, 분석 기준 적용 |
다음은 예시 시나리오의 결과물입니다.
## 📊 리뷰 요약
| 분류 | 건수 |
|------|------|
| 🚫 Blocking Issues | 1건 |
| ⚠️ Recommended Changes | 1건 |
| 💡 Suggestions | 0건 |
| 📝 Tech Debt | 0건 |
---
## 🚫 Blocking Issues
### [Null Safety] OrderService.kt:12
- **📍 위치**: `OrderService.kt:12`
- **🔍 문제 설명**: `!!` 연산자 사용으로 NPE 발생 가능
- **❌ 문제 코드**:
```kotlin
val order = orderRepository.findById(orderId)!!
- ✅ 권장 수정:
val order = orderRepository.findById(orderId)
?: throw OrderNotFoundException("주문을 찾을 수 없습니다: $orderId")
- 💡 이유: !! 연산자는 null일 경우 의미 없는 NPE를 발생시킵니다.
Elvis 연산자와 커스텀 예외를 사용하면 명확한 에러 처리가 가능합니다.
---
⚠️ Recommended Changes
[N+1 Problem] OrderService.kt:13
- 📍 위치: OrderService.kt:13
- 🔍 문제 설명: Lazy Loading으로 인한 N+1 쿼리 발생 가능
- ❌ 문제 코드:
val items = order.items
- ✅ 권장 수정:
@Query("SELECT o FROM Order o JOIN FETCH o.items WHERE o.id = :id")
fun findByIdWithItems(id: Long): Order?
- 💡 이유: JOIN FETCH를 사용하면 단일 쿼리로 연관 데이터를
함께 조회하여 성능을 개선할 수 있습니다.
이러한 프롬프트 구조화는 단순한 튜닝을 넘어 AI 코드 리뷰를 '플랫폼 구성 요소'로써 다루기 위한 핵심 설계 결정이었습니다. 이를 통해 개발자의 개별 의도는 유연하게 반영하면서 조직의 품질 가드레일은 단단하게 유지하는 '예측 가능한 AI' 환경을 구축할 수 있었습니다.
앞서 살펴본 두 가지 사례는 단순한 예외 처리나 기능 보완의 결과가 아니라 Claude Code Action을 개별 도구가 아닌 조직 공통의 시스템으로 만들기 위한 설계 과정에서 자연스럽게 도출된 결정들이었습니다. 이러한 구조 덕분에 개별 서비스 리포지터리를 직접 수정하지 않더라도 중앙에서 정책과 프롬프트를 개선하면 그 변화가 조직 전체에 즉시 반영되는 구조를 확보할 수 있었습니다.
아키텍처 상세: PR부터 AI 리뷰까지
지금까지 Claude Code Action을 표준화하기 위한 전체 구조와 설계 원칙을 살펴봤습니다. 이번 장에서는 이 구조가 실제로 어떻게 작동하는지 PR 이벤트가 발생한 순간부터 AI 리뷰 코멘트가 남겨지기까지의 흐름을 단계별로 정리해 보겠습니다. 이 장의 핵심은 단순합니다.
"서비스 리포지터리는 호출자(caller)로서의 역할만 수행하고, 실제 정책 설정과 판단 및 실행은 중앙(executor)에서 책임진다."
이를 염두에 두고 아래 흐름을 따라가면 전체 구조가 한 번에 이해될 것입니다.
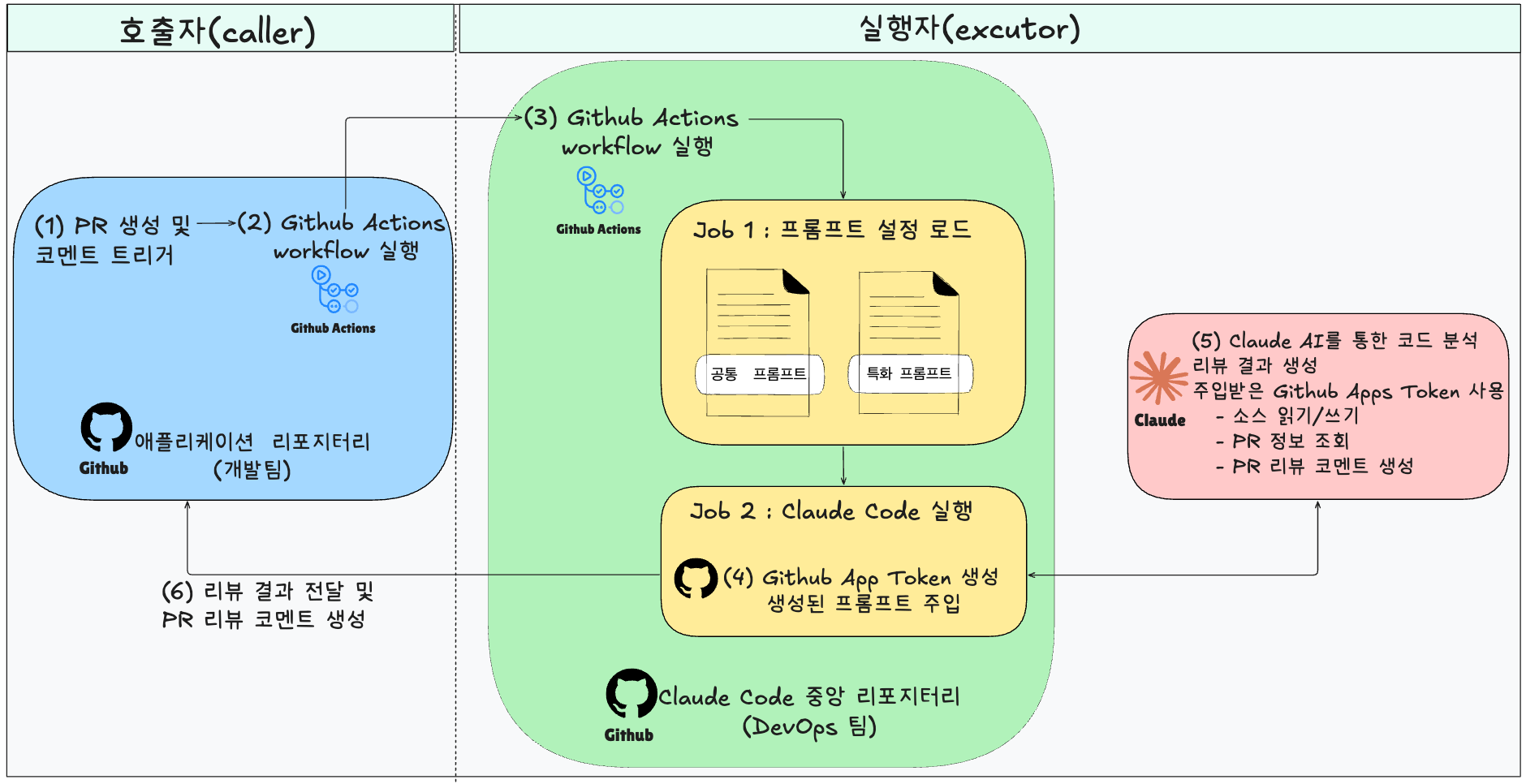
전체 실행 흐름을 한눈에 볼 수 있도록 표로 정리하면 다음과 같습니다.
| 단계 | 주요 작업 | 주체(responsibility) | 설명 |
|---|---|---|---|
| 1단계 | PR 생성 또는 @claude 코멘트 트리거 | caller(서비스 리포지토리) | PR 생성 또는 @claude 코멘트 및 Excutor 호출 |
| 2단계 | 중앙 재사용 워크플로 호출 및 컨텍스트 구성 | caller → excutor | 재사용할 수 있는 워크플로 호출 |
| 3단계 | 공통 및 서비스별 프롬프트 로드 및 병합 | executor(중앙 리포지토리) | 공통 + 서비스별 설정 조합 |
| 4단계 | 최종 프롬프트 주입 및 Claude Code Action 실행 | executor(중앙 리포지토리) | 코드 checkout 및 분석 준비 |
| 5단계 | GitHub 앱 인증 및 Amazon Bedrock(AI) 호출 | executor(중앙 리포지토리) | GitHub 앱 + Amazon Bedrock Claude |
| 6단계 | 분석 결과 가공 및 PR 피드백 피드백 반환 | executor → caller | PR 코멘트 / 리뷰 등록 |
1단계: PR 이벤트 트리거 및 워크플로 시작
Claude Code Actions는 PR 생성 시점 또는 PR 내에 @claude 코멘트가 작성되었을 때 워크플로우가 실행되도록 설계되어 있습니다.
개발자는 별도의 도구나 설정 없이, 평소처럼 PR을 생성하거나 필요할 때 원하는 시점에 코멘트를 남기는 것만으로 온디맨드 형태의 AI 코드 리뷰를 요청할 수 있습니다.
이 단계에서 사용자의 코멘트는 이후 단계에서 리뷰의 범위(WHAT)를 결정하는 입력값으로 전달되며, 실제 실행 책임은 중앙 워크플로우가 담당합니다.
2단계: 중앙 재사용 워크플로 호출 및 컨텍스트 구성
서비스 리포지터리에서 감지된 PR 이벤트는 중앙 리포지터리에 정의된 재사용 워크플로를 호출하며, 이때 실행에 필요한 최소한의 컨텍스트를 함께 전달합니다. 이 컨텍스트는 이후 모든 분석 단계의 기준점이 되며, 중앙 워크플로는 이를 바탕으로 동일한 실행 흐름을 재현합니다.
대표적으로 전달되는 실행 컨텍스트는 다음과 같습니다.
service_name: 어떤 서비스에서 호출되었는지 식별하기 위한 값analysis_type: 코드 리뷰, 보안 분석 등 분석 목적을 명시runner_type: 실행 환경 선택(예: self-hosted, github-hosted)
# 개발팀 리포지토리(Caller)의 워크플로 트리거 설정
# PR 내에서 "@claude" 등 특정 키워드로 댓글을 남길 때 수동 트리거
name: Claude Code Review
...
jobs:
# 코드 리뷰 (PR과 @claude 댓글에서 실행, security/performance 제외)
code-review:
if: |
(github.event_name == 'issue_comment' && contains(github.event.comment.body, '@claude') && !contains(github.event.comment.body, 'security') && !contains(github.event.comment.body, 'performance')) ||
(github.event_name == 'workflow_dispatch' && github.event.inputs.run_type == 'code-review')
# 중앙 저장소의 표준 워크플로를 호출 (Caller 역할)
uses: BlockchainLab/devops-git-actions/.github/workflows/reusable-claude-analysis.yml@main
with:
service_name: "next-market" # 서비스 식별자
analysis_type: "code-review" # 분석 타입 지정
runner_type: "self-hosted"
secrets:
LINENEXT_CLAUDE_APP_ID: ${{ secrets.LINENEXT_CLAUDE_APP_ID }}
LINENEXT_CLAUDE_PRIVATE_KEY: ${{ secrets.LINENEXT_CLAUDE_PRIVATE_KEY }}
AWS_SESSION_TOKEN: ${{ secrets.AWS_SESSION_TOKEN }}여기서 중요한 점은 이 워크플로는 코드를 직접 분석하지 않는다는 것입니다. 서비스 리포지터리는 오직 '어떤 서비스에서, 어떤 타입의 분석을 요청하는지'만 전달합니다.
3단계: 공통 및 서비스별 프롬프트 로드 및 병합
3단계에서는 중앙 리포지토리(executor)가 AI 코드 리뷰에 사용할 프롬프트를 로드하고 조합합니다. 조직 공통의 리뷰 기준과 응답 포맷을 정의한 공통 프롬프트에, 서비스별 특성을 반영한 프롬프트를 결합하는 구조입니다.
이 과정에서 service_name, analysis_type과 같은 실행 컨텍스트를 기준으로 적절한 프롬프트 세트가 선택되며, 서비스마다 맥락은 달라도 조직 전체의 리뷰 기준과 형식은 일관되게 유지됩니다.
- 공통 프롬프트 (
common/{analysis_type}.yml): 모든 조직에 적용되는 코드 스타일과 명명 규칙, 일반적인 안티 패턴 등을 정의합니다. - 서비스 프롬프트 (
{service_name}/code-review.yml): 특정 언어(Go, TypeScript 등)나 도메인(결제, 인증 등)에 특화된 심층 리뷰 관점을 정의합니다.
프롬프트는 다음과 같은 구조로 중앙 리포지터리에서 관리합니다.
devops-git-actions/
├── .github/workflows/
│ └── reusable-claude-analysis.yml # 재사용 가능한 워크플로
└── configs/
├── common/
│ ├── common.yml # 서비스 기본 설정(공통 설정)
│ ├── code-review.yml # 이미 존재 (공통 프롬프트)
│ └── security-check.yml # 이미 존재 (공통 프롬프트)
├── next-market/ # 예시 서비스
│ ├── code-review.yml # 코드 리뷰 설정
│ └── security-check.yml # 보안 체크 설정
└── your-service/ # 새로운 서비스
└── ...다음은 공통 프롬프트의 일부를 발췌한 것입니다.
# 개발 공통 프롬프트의 일부 발췌
common_prompt: |
## 📋 Review Outcome Classification
Please categorize your findings as:
- **🚫 Blocking Issues**: 반드시 수정이 필요한 항목(보안, 버그, 아키텍처 위반)
- **⚠️ Recommended Changes**: 권장 개선 사항(성능, 가독성, 베스트 프랙티스)
- **💡 Suggestions**: 선택적 개선 아이디어(리팩토링, 최적화 기회)
- **📝 Tech Debt**: 향후 개선이 필요한 기술 부채
## 🎯 Common Review Areas (Language-Agnostic)
### 1. Code Quality & Design Principles
- **Single Responsibility Principle (SRP)**: 각 모듈/함수가 하나의 명확한 책임만 가지는가?
- **DRY (Don't Repeat Yourself)**: 중복 코드가 없고 재사용 가능한 추상화가 있는가?
- **KISS (Keep It Simple)**: 불필요한 복잡성 없이 단순하고 명확한가?
### 2. Code Readability & Maintainability
- **Naming Conventions**: 변수명, 함수명, 클래스명이 의미를 명확히 전달하는가?
- **Function Length**: 함수가 적절한 길이인가?(한 화면에 표시 가능한 수준)
- **Magic Numbers/Strings**: 하드코딩된 값이 상수나 설정으로 추출되었는가?
### 5. Security Best Practices
- **Input Validation**: 모든 입력값에 대한 검증이 충분한가?
- **Sensitive Data Protection**: 민감 정보(패스워드, 토큰 등)가 로그나 응답에 노출되지 않는가?
- **SQL Injection & XSS**: 보안 취약점(Injection, XSS 등)이 없는가?
## 📝 Feedback Guidelines
Please provide **specific, actionable feedback** with:
1. **Code Location**: 파일명과 라인 번호를 명시
2. **Issue Description**: 문제가 무엇인지 명확히 설명
3. **Recommended Solution**: 개선된 코드 예시 제공
4. **Priority**: 각 항목의 우선순위(🚫/⚠️/💡/📝) 명시
**모든 코드 리뷰 결과는 반드시 한국어로 작성해주세요.**다음은 서비스 특화 프롬프트의 일부를 발췌해 온 것입니다.
# 서비스 특화 프롬프트의 일부 발췌
custom_prompt: |
🎯 **Kotlin/Spring Boot Specialized Code Review**
## 1. 🏗️ Kotlin/Spring Boot Architecture & Layered Structure
### Layer Separation (Layered Architecture)
- **Controller Layer**: HTTP 요청/응답 처리만 담당하는가? 비즈니스 로직이 섞이지 않았는가?
- **Service Layer**: 비즈니스 로직의 주요 구현체인가? 트랜잭션 경계가 명확한가?
- **Repository Layer**: 데이터 접근만 담당하는가? JPA Repository 활용이 적절한가?
## 2. 🔤 Kotlin Language Best Practices
### Null-Safety (Kotlin's Core Feature)
- **Avoid !! Operator**: `!!` 사용을 최소화하고 `?.let { }`, [?:](cci:7://file:///Users/al03142943/%EC%97%85%EB%AC%B4/1_%EA%B0%9C%EB%B0%9C/01_workspace/devops-claude-code-action/LICENSE:0:0-0:0) 등 안전한 대안을 사용했는가?
- **Elvis Operator**: [?:](cci:7://file:///Users/al03142943/%EC%97%85%EB%AC%B4/1_%EA%B0%9C%EB%B0%9C/01_workspace/devops-claude-code-action/LICENSE:0:0-0:0) 연산자를 활용해 default 값을 명확히 처리했는가?
### Kotlin Idioms & Collections
- **Scope Functions**: `let`, `apply`, [run](cci:1://file:///Users/al03142943/%EC%97%85%EB%AC%B4/1_%EA%B0%9C%EB%B0%9C/01_workspace/devops-claude-code-action/src/entrypoints/prepare.ts:16:0-97:1), `also`, `with` 사용이 의도를 명확히 표현하는가?
- `let`: nullable 처리, 변환
- `apply`: 객체 초기화/설정
- `also`: 부수 효과(로깅 등)
## 3. 🍃 Spring Boot Framework Best Practices
### Dependency Injection
- **Constructor Injection 우선**: `@Autowired` 필드/세터 주입 대신 생성자 주입을 사용하는가?
- **Immutable Dependencies**: 의존성을 `val`로 선언하여 불변성을 보장하는가?
### Transaction Management
- **readOnly 옵션**: 조회 메서드에 `@Transactional(readOnly = true)` 적용으로 성능 최적화했는가?
- **Exception Rollback**: 체크 예외에 대한 롤백 전략(`rollbackFor`)이 명시되었는가?
## 5. ⚡ Performance & Efficiency (JPA/Hibernate Tuning)
### Database Performance
- **N+1 Problem**: `@EntityGraph`, `fetch join`, `@BatchSize`로 N+1 문제를 방지했는가?
- **Fetch Strategy**: `@OneToMany`, `@ManyToOne`의 fetch 전략이 적절한가? (LAZY vs EAGER)
- **Pagination**: 대량 데이터 조회 시 Pageable을 활용한 페이징이 적용되었는가?
### Caching Strategy
- **@Cacheable**: 반복적으로 조회되는 데이터에 캐싱이 적용되었는가?
- **Cache Eviction**: `@CacheEvict`를 활용한 캐시 무효화 전략이 있는가?
**Note**: 이 프롬프트는 `common_prompt`와 결합되어 실행됩니다.이 두 프롬프트는 실행 시 하나로 병합돼 해당 서비스에 최적화된 '단일 페르소나'를 형성하는 단일 최종 프롬프트로 Claude에 전달됩니다. 이와 같은 구조를 통해 리뷰의 일관성과 유연성을 동시에 확보할 수 있습니다.
4단계: Claude Code Action 실행
3단계에서 병합된 최종 프롬프트와 실행 컨텍스트는 실제 분석 엔진인 Claude Code Action으로 전달됩니다. 이 단계에서 AI는 단순한 자연어 응답자가 아니라, 조직에서 정의한 페르소나와 규칙을 따르는 코드 리뷰 실행자로 동작합니다. 즉, 무엇을 분석할지(WHAT)는 사용자 요청을 따르되, 어떤 기준과 형식으로 응답할지(HOW)는 중앙에서 정의한 프롬프트에 의해 통제된 상태로 분석이 수행됩니다.
- name: Load service configuration
id: config
run: |
...중간 생략....
① configs/common/{analysis_type}.yml # 개발 공통 프롬프트
② configs/{service_name}/{analysis_type}.yml # 서비스 특화 프롬프트
.............
# Handle multiline final_prompt with delimiter
{
echo "custom_prompt<<EOF"
echo "$FINAL_PROMPT"
echo "EOF"
} >> $GITHUB_OUTPUT
- name: Claude Code Action
uses: BlockchainLab/devops-claude-code-action@main
with:
github_token: ${{ steps.app-token.outputs.token }}
use_bedrock: 'true'
track_progress: true
prompt: |
${{ needs.load-config.outputs.custom_prompt }} # 병합된 최종 프롬프트
As a senior code reviewer, please provide a comprehensive analysis for this ${{ inputs.analysis_type }} focusing on the requirements specified above.
Please provide specific, actionable feedback with code examples where applicable. Focus on identifying potential issues and providing clear recommendations.
claude_args: |
--model ${{ needs.load-config.outputs.anthropic_model }}이 시점에서 비로소 AI에게 무엇을 어떻게 분석해달라고 할지, 어떤 관점으로 코드를 리뷰해 달라고 할지가 완전히 결정됩니다.
5단계: 안전한 권한 위임과 AI 호출
이 단계는 준비된 프롬프트가 실제로 Claude 모델에 전달되어 코드 리뷰가 수행되는 핵심 실행 구간입니다. Claude Code Action은 이전 단계에서 구성된 최종 프롬프트와 코드 변경 컨텍스트를 바탕으로, 외부 AI 모델(Claude)과 통신해 분석 결과를 생성합니다.
이 과정에서 가장 중요한 고려사항은 권한과 보안입니다. 타 리포지터리의 코드를 읽고, PR에 리뷰 코멘트를 남기기 위해서는 강력한 GitHub 권한이 필요하지만, 개인 토큰(PAT)을 사용하는 방식은 유출 시 조직 전체에 영향을 줄 수 있는 구조적 위험을 내포하고 있습니다.
이를 해결하기 위해 저는 GitHub App 기반 인증 구조를 선택했습니다.
- 실시간 권한 획득
DevOps 팀이 관리하는 GitHub App으로부터 해당 PR에만 유효한 단기 엑세스 토큰을 발급받습니다. 이 토큰은Claude Code Action이 리포지토리의 소스 코드를 안전하게 읽고 코멘트를 작성할 수 있는 신분증이 됩니다. - 중앙 권한 통제
DevOps 팀이 관리하는 GitHub App을 통해 필요한 최소 권한만 부여하고, 모든 리포지터리는 이 앱을 통해서만 코드 접근 및 코멘트 작성이 이루어지도록 설계했습니다. 이를 통해 권한 관리와 회수를 중앙에서 일관되게 통제할 수 있습니다. - 안전한 AI 호출 경로
Claude Code Action은 GitHub App으로 발급받은 단기 토큰을 사용해 PR 컨텍스트를 읽은 뒤, 사내 프록시를 경유하여 AWS Bedrock 상의 Claude 모델을 호출합니다. 이 구조를 통해 프롬프트와 코드 데이터의 흐름을 명확히 추적할 수 있으며, 외부로의 직접 노출 없이 투명한 데이터 경로를 유지합니다.
결과적으로 이 단계에서 Claude는 조직이 정의한 페르소나와 가드레일을 적용받은 상태로 변경된 코드에 대한 분석과 리뷰를 수행하게 되며, 그 결과는 다시 중앙 워크플로우로 반환됩니다.
이 모든 과정은 GitHub App 기반의 권한 위임과 중앙 통제를 통해 최소 권한 원칙 하에서 수행되어, 리뷰 자동화와 보안을 동시에 책임지는 구조로 설계되었습니다.
6단계: 분석 결과 처리 및 PR 피드백 제공
AI의 분석 결과는 다시 서비스 리포지토리의 PR 화면으로 돌아옵니다. 개발자는 별도의 도구를 켤 필요 없이 늘 보던 GitHub PR 댓글 창에서 AI의 제안을 확인하고 즉시 코드에 반영할 수 있습니다.
이와 같은 6단계 구조로 설계함으로써 저는 다음과 같은 가치를 얻었습니다.
- 서비스 리포지터리의 경량화: 개발 팀은 복잡한 설정 없이 호출 인터페이스만 관리하면 되기 때문에 서비스 리포지터리를 경량으로 유지할 수 있습니다.
- 정책을 즉시 적용: DevOps 팀이 중앙 저장소에서 프롬프트를 수정하면 그 즉시 전사의 모든 프로젝트에 새로운 리뷰 기준이 적용됩니다.
- 예측 가능한 품질: 설정 기반의 관리를 통해 AI의 응답 품질을 조직 차원에서 통제할 수 있습니다.
이제 이 구조를 실제 서비스 팀에서 어떻게 활용하고 있는지, 도입 이후 저희 조직에 어떤 변화가 생겼는지 살펴보겠습니다.
개발 팀을 위한 적용 가이드: 표준 위에서의 자율성
앞선 장에��서는 Claude Code Action을 조직 공통 시스템으로 설계한 배경과 아키텍처를 살펴봤습니다. 이제 개발 팀 입장에서 이 AI 코드 리뷰 도구를 도입하기 위해 무엇을 준비해야 하고 어떻게 사용하면 되는지 살펴보겠습니다.
개발 팀에서 준비해야 할 것은 단 두 가지
DevOps 팀은 AI 코드 리뷰 도구를 단순히 '잘 만든 자동화 도구'를 넘어 '누구나 바로 사용할 수 있는 플랫폼의 기능'으로 제공하고 싶었습니다. 개발 팀에서 복잡하게 무언가를 설정해야 하거나 내부 구조를 이해하지 않아도 되도록 가능한 한 많은 책임을 플랫폼 영역으로 끌어올리는 방향을 선택했습니다. 플랫폼 기반의 표준화 덕분에 개발 팀이 AI 리뷰어를 초대하기 위해 거쳐야 할 단계는 매우 단순합니다.
- 호출자 워크플로 추가: 제공된 표준 템플릿을 서비스 리포지터리에 복사합니다.
- 토큰 설정: 조직 단위에서 공유되는 시크릿 권한을 확인합니다.
위 두 가지만 준비하면, 이후 PR에서 @claude 코멘트를 남기는 것만으로 DevOps 팀이 미리 구성해 둔 전용 GitHub App Runner가 즉시 작동합니다. 개발 팀에서 실행 환경이나 네트워크 접근 제어, 리소스 제약 등을 고민할 필요가 전혀 없습니다.
보이지 않는 곳에서의 통제: 보안과 권한 관리
개발 팀이 쉽고 편하게 사용할 수 있는 이면에는 DevOps 팀의 정교한 보안 설계가 자리 잡고 있습니다.
- 중앙 집중형 GitHub App: 개인용 토큰 대신 조직 단위의 GitHub 앱으로 권한을 제어하기 때문에 누가, 어떤 코드에 접근했는지를 완벽히 추적할 수 있습니다.
- 관리의 일원화: ��시크릿과 실행 로직을 중앙에서 관리하므로 보안 정책을 변경해야 할 때 각 팀의 리포지터리를 수정할 필요 없이 중앙에서 즉시 일괄 적용할 수 있습니다.
또한 리뷰 기준과 프롬프트 역시 중앙 저장소에서 관리합니다. 공통 리뷰 기준은 물론 서비스 특성에 맞는 커스텀 프롬프트까지 DevOps 팀이 관리함으로써 리뷰의 관점과 출력 형식을 코드가 아닌 설정으로 통제할 수 있도록 만들었습니다. 이는 단순한 편의성을 넘어, 조직이 합의한 개발·리뷰 기준을 문서가 아닌 코드와 설정의 형태로 중앙에서 관리하고, PR 이벤트마다 시스템이 자동으로 적용하도록 만들기 위한 선택이었습니다.
사용 사례
실제 개발 팀에서는 아래와 같이 Claude Code를 일상적인 코드 리뷰 흐름 속에서 자연스럽게 사용하고 있습니다. PR에서 간단히 멘션하는 것만으로 항상 동일한 구조와 형식의 리뷰 결과가 제공됩니다.
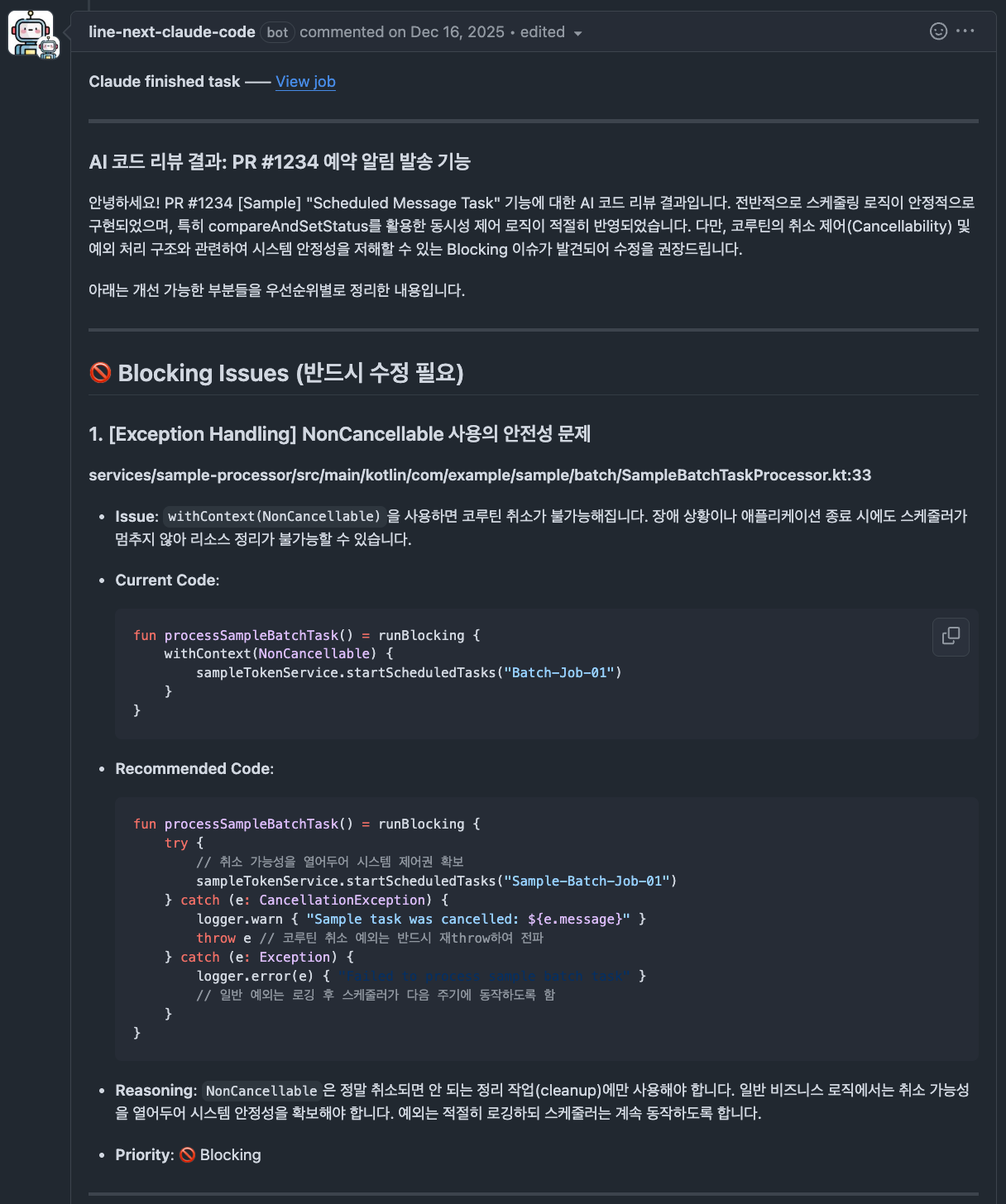
AI 코드 리뷰는 Blocking Issues, Recommended Changes, Suggestions, Tech Debt와 같이 개선 관점별로 결과가 구조화되어 제공됩니다. 반면 보안 리뷰는 코드 개선보다는 위험 관리에 초점을 두기 때문에, 심각도 수준(Critical, High, Medium, Low)별로 이슈를 분류하여 제공합니다.
- 아래 리뷰 결과는 실제 운영 환경에서 사용 중인 Claude Code Actions의 출력 형식을 설명하기 위해 샘플 소스코드를 기반으로 재구성한 예시입니다.
| 일반적인 코드 리뷰 |
|---|
|
|

| 보안 관점 리뷰 |
|---|
|
|

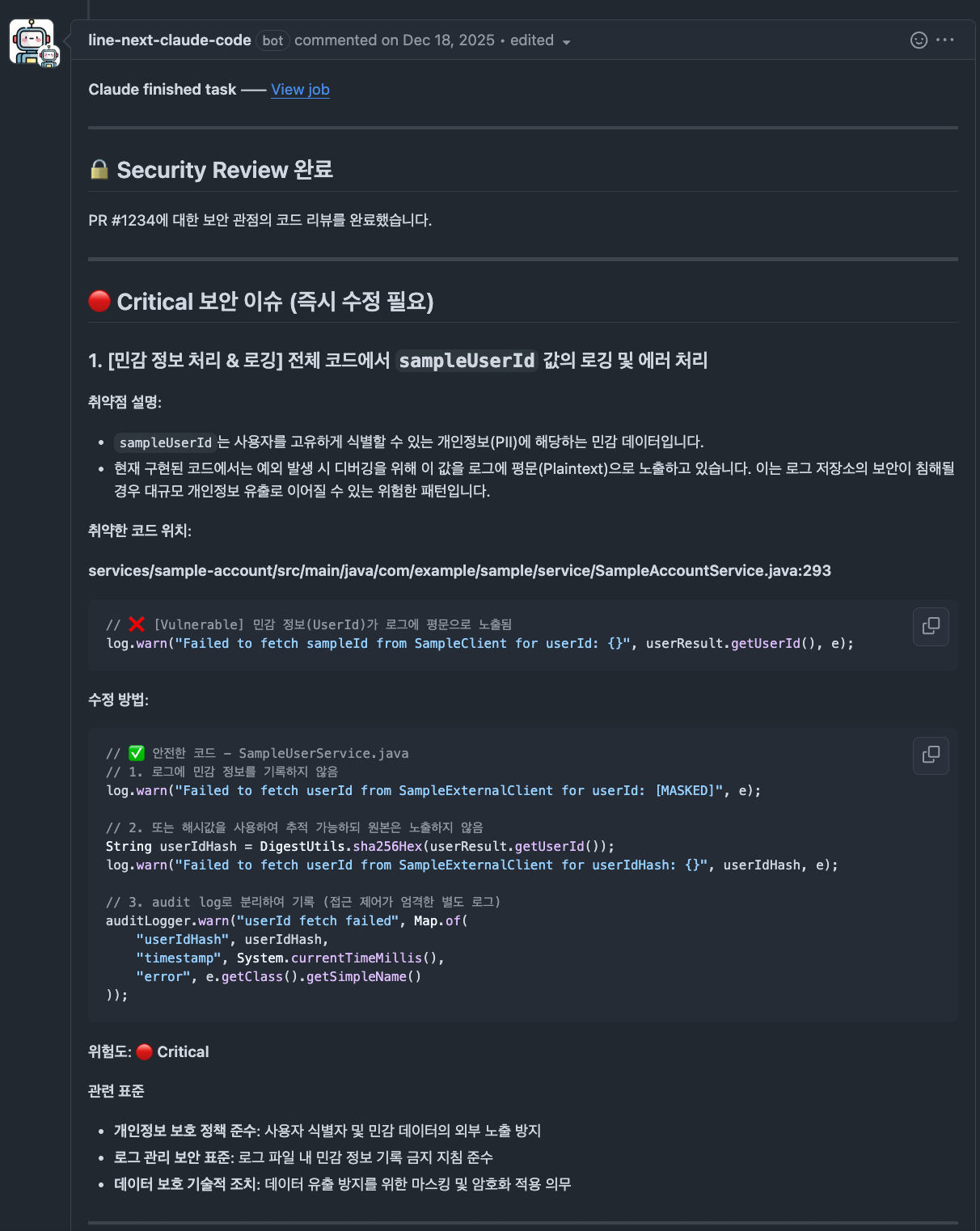
DevOps 관점에서 보면 이와 같은 AI 코드 리뷰 시스템의 구조는 단순한 자동화 이상의 의미가 있습니다. DevOps 팀이 플랫폼 차원에서 설계와 운영 복잡성을 대부분 흡수함으로써 개발 팀은 별도의 초기 설정이나 추가 공수 없이 PR 단계에서 바로 AI 코드 리뷰를 활용할 수 있습니다. 결과적으로 호출 측은 단순한 인터페이스만 사용하고, 복잡성은 내부로 추상화된 구조입니다.
이와 같이 일관적인 형식은 리뷰 내용을 빠르게 파악하고 우선순위를 정하는 데 큰 도움이 됩니다. 무엇보다 리뷰 결과��가 사람마다 달라지는 것이 아니라 조직이 정의한 기준에 따라 동일한 관점으로 제공된다는 점에서 의미가 있습니다. 이 시스템에서 Claude Code는 자유롭게 말하는 AI가 아니라 조직의 기준을 따르는 리뷰어로 작동합니다.
결국 이 구조의 핵심은 표준화와 자율성을 대립되는 개념으로 보지 않는 데 있습니다. 표준화된 플랫폼에서 개발 팀은 더 적은 부담으로, 더 빠르게, 더 일관적인 품질의 리뷰를 받을 수 있습니다. 이것이 DevOps 팀이 Claude Code Action을 플랫폼 관점에서 설계한 이유이기도 합니다.
다음 장에서는 이러한 구조가 실제로 조직과 개발 흐름에 어떤 변화를 만들어냈는지 지표와 함께 살펴보겠습니다.
도입 이후 조직의 개발 흐름에 발생한 변화
이제 Claude Code Action을 이용한 AI 코드 리뷰 시스템을 도입한 후 실제 조직의 개발 흐름에 어떤 변화가 발생했는지 살펴보겠습니다.
데이터 기반의 관측 가능성: DORA(DevOps research & assessment) 대시보드와의 통합
DevOps 팀은 Claude Code Action을 실제 서비스 리포지터리에 적용한 후 이 도구가 조직의 개발 흐름에 어떤 변화를 만들어 내고 있는지를 관측 가능한 지표로 확인하고자 했습니다. 단순히 '개발자들이 잘 쓰고 있을 것'이라고 추측하는 게 아니라 얼마나 자주 호출되고, 얼마나 안정적으로 작동하며, 실제 개발 흐름 속 어디에서 사용되고 있는지를 수치로 확인하고자 했습니다. 이를 위해 Claude Code Action의 실행 주체인 GitHub 앱을 중심으로 사용량과 실행 정보를 수집해 모니터링했습니다.
구체적으로 살펴보겠습니다. Claude Code Action은 GitHub 앱 기반으로 작동합니다. 이 구조를 활용해 GitHub 앱에서 발생하는 웹훅 이벤트를 수집하고, 사내 프라이빗 클라우드 서비스에서 제공하는 기능을 이용해 다음 지표를 수집했습니다.
- 리포지터리별 Claude Code Action 호출 횟수
- PR 기준 엔드투엔드 수행 시간
- 실행 성공 및 실패 여부
놀랍게도 수집된 데이터는 제 예상을 뛰어넘는 흥미로운 결과를 보여줬습니다. 2025년 12월 중순부터 2026년 1월 초순까지 약 한 달간, 별도의 복잡한 온보딩 과정 없이 총 32개의 리포지토리로 빠르게 확산됐습니다. 호출 데이터를 분석한 결과 총 344회의 AI 리뷰가 수행되었음을 확인했습니다. 특히 주목할 점은 사용 형태였습니다. 대부분의 호출이 PR이 생성된 직후에 집중돼 있었으며, 다수의 리포지터 리에서 지속적이고 반복적으로 호출하는 패턴이 관측됐습니다.
저는 이 지표들을 사내 DORA 대시보드의 'Build 섹션'에 포함했습니다. AI 리뷰를 빌드 생산성의 핵심 요소로 정의한 것입니다(DORA 대시보드의 상세 구축 과정은 향후 별도 포스팅으로 다룰 예정입니다).
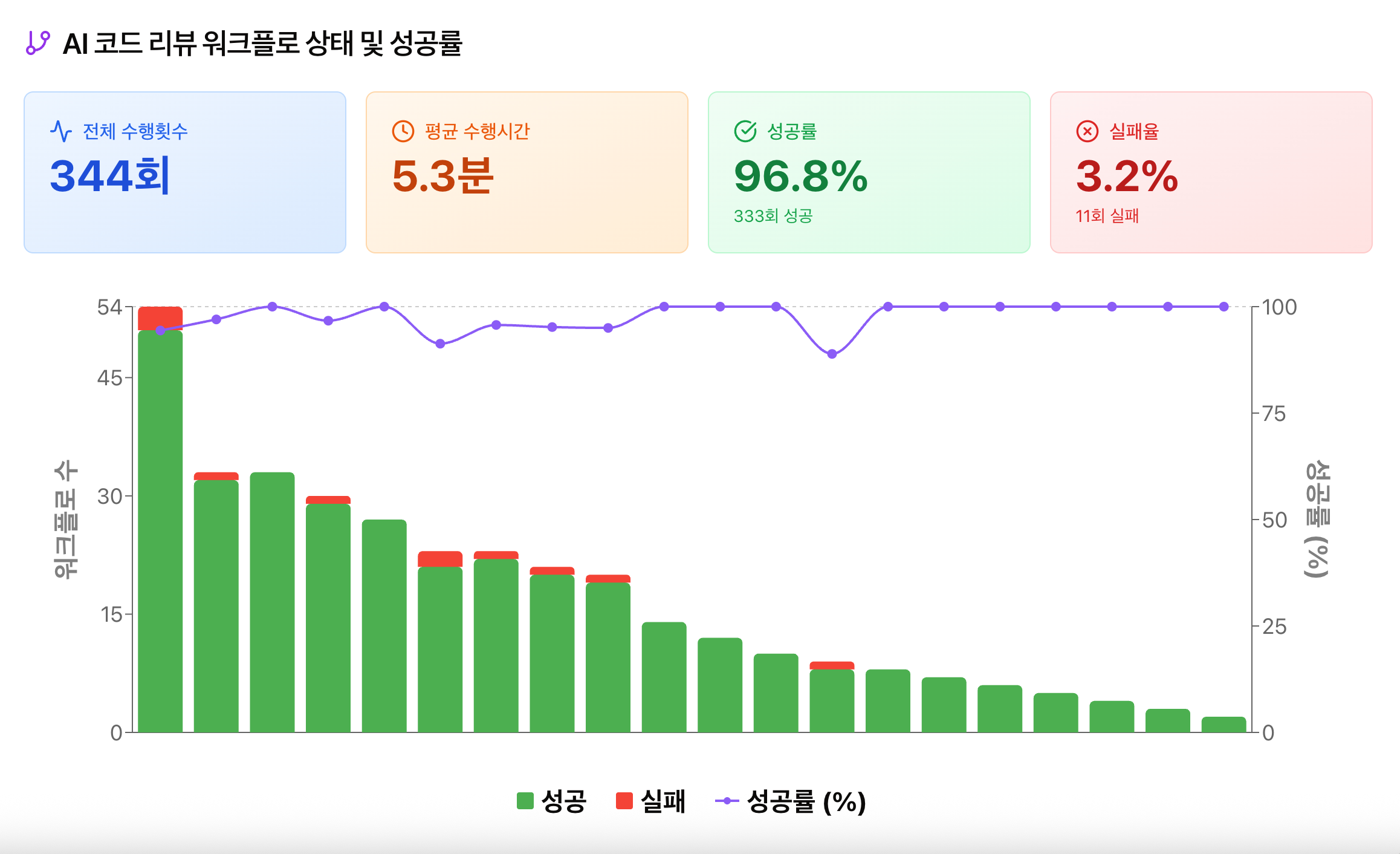
이는 개발자들이 Claude Code를 단순한 호기심으로 사용하는 것이 아니라, 초기 코드 품질을 검증하는 신뢰할 수 있는 동료로 인�식하고 있음을 시사합니다. 사람이 직접 리뷰를 시작하기 전, AI가 1차적으로 가드레일을 쳐줌으로써 개발 생산성에 실질적으로 기여하고 있다는 확신을 가질 수 있었습니다.
플랫폼 형태로 제공하는 방식이 가져온 쉽고 빠른 확산
Claude Code를 개별 리포지터리 단위로 도입하는 게 아니라 중앙에서 관리하는 GitHub Actions 형태로 제공함으로써 다음과 같은 구조적 이점을 확보할 수 있었습니다.
- 신규 리포지터리에도 동일한 방식으로 즉시 적용 가능
- 서비스별 설정 편차 최소화
- DevOps 팀의 개입 없이도 자율적 확산 가능
이 방식 덕분에 Claude Code는 단순한 개인용 도구를 넘어, 조직 공통의 코드 리뷰 파이프라인으로 자리 잡을 수 있었고, 조직 전반에서 동일한 품질로 재사용 가능한 구성 요소가 되었습니다.
PR 단계에서의 피드백 타이밍 변화
Claude Code Action은 PR 생성 시점에 자동으로 실행되며, 다음과 같은 항목들을 중심으로 초기 피드백을 제공합니다.
- 명확한 버그 가능성
- 보안 및 안정성 관점의 위험 요소
- 반복적으로 발생하는 코드 패턴 문제
이를 통해 개발자는 PR을 생성하자마자 1차 피드백을 즉시 확인할 수 있고, 사람 리뷰어는 논의가 필요한 영역에 집중할 수 있습니다. AI가 일관된 기준으로 분석 결과를 제공함에 따라 리뷰 내용의 편차는 줄어들고, PR 초기 품질은 일정 수준 이상으로 유지됩니다. 또한 리뷰 과정에서의 대기 시간이 단축되면서 개발 팀 전체의 생산성과 안정성 모두에 긍정적인 영향을 미치고 있습니다.
마치며: AI 도구를 ‘플랫폼 자산’으로 다룬다는 것
지금까지 Claude Code Action을 도입하며 겪었던 기술적 여정과 그 이면에 있는 설계 원칙들을 살펴보았습니다. 이 글을 통해 제가 정말로 전하고 싶었던 메시지는, AI가 코딩을 보조하거나 코드 리뷰를 자동화해 줘서 '편해졌다'는 기능 관점의 개선에 있지 않습니다. 진정한 핵심은 AI를 개별 개발자의 생산성 도구로 소비하는 수준에 머무르지 않고 DevOps와 결합해, 조직의 생산성을 구조적으로 가속하는 ‘플랫폼 자산’으로 재정의했다는 점에 있습니다.
AI를 플랫폼 형태로 제공했을 때 얻을 수 있는 기술적 이점은 분명합니다. 파편화된 개인별 도구 사용을 중앙 집중형 시스템으로 전환함으로써 기술 거버넌스와 운영 효율이라는 두 가지 목표를 동시에 달성할 수 있었습니다. 표준화된 플랫폼에서는 리뷰 기준과 관점을 점진적으로 확장하고 정교화할 수 있으며, 한 번의 개선이 전사 모든 리포지터리에 즉시 반영되는 강력한 확산성을 확보할 수 있습니다. 이는 단순한 자동화가 아니라, 조직 전체의 개발 품질을 제어 가능한 시스템으로 끌어올리는 과정입니다.
무엇보다 중요한 변화는 지식의 흐름입니다. Claude의 리뷰 페르소나와 프롬프트를 중앙에서 관리함으로써, 조직이 합의한 기술 기준과 시니어 엔지니어들의 판단 기준, 코드 리뷰 노하우가 시간이 지날수록 AI 에이전트에 축적됩니다. 이는 휘발되기 쉬운 개인의 경험과 감각을 조직의 ‘지속 가능한 시스템’으로 내재화하는 일이며, 결과적으로 개발 역량의 편차를 줄이고 조직 전체의 기술 수준을 상향 평준화하는 기반이 됩니다.특히 AI 활용 경험이나 숙련도와 관계없이 동일한 품질의 AI 피드백을 반복적으로 접할 수 있게 되면서, 조직 전체의 AI 활용 능력 또한 자연스럽게 상향 평준화되는 효과를 확인할 수 있었습니다.
결국 플랫폼 엔지니어링 관점에서 AI를 다룬다는 것은, 새로운 도구를 하나 더 도입하는 문제가 아닙니다. 누구나 최고의 도구를 가장 낮은 비용으로, 가장 일관된 방식으로 사용하여 가치를 만들어낼 수 있는 환경을 구축하는 일입니다. 이번 Claude Code Action 표준화 설계는 조직 내의 생산성을 개선하기 위한 시도로 시작되었지만, 이 모델이 전사적으로 확산된다면 그 파급력은 단순한 효율 개선을 훨씬 넘어설 것입니다.
표준화는 끝이 아니라 시작입니다. 표준화된 AI 리뷰 시스템이 전사의 개발 문화로 자리 잡을 때, 개별 프로젝트의 경계를 넘어 회사 전체의 기술 역량이 체계적으로 강화되며 진정한 의미의 ‘AI 가속화’를 실현할 수 있을 것입니다. LINE NEXT DevOps 팀은 앞으로도 AI와 플랫폼의 시너지를 통해 개발자가 더 가치 있는 문제에 집중할 수 있는 환경을 만들어 나가고자 합니다. 이 작은 시발점이 만들어 낼 변화가, 여러분의 조직에도 하나의 영감이 되기를 바랍니다.


