Web バックエンドエンジニアの早坂です。本稿は、2025年11月に開催された JJUG CCC 2025 Fall における登壇「Virtual Thread Deep Dive」を記事としてまとめたものです。以下では、Java の Virtual Thread について、その内部実装や利用時の注意点を解説します。発表スライドは Speaker Deck からご覧いただけます。
Virtual Thread の基本概念
Virtual Thread は Java 21 で正式導入された軽量スレッドであり、「I/O待ち時間を有効活用してスループットが向上する」「軽量なので大量に生成できる」といった特徴がよく知られています。例えば、次のような図を見たことがある方も多いのではないでしょうか。
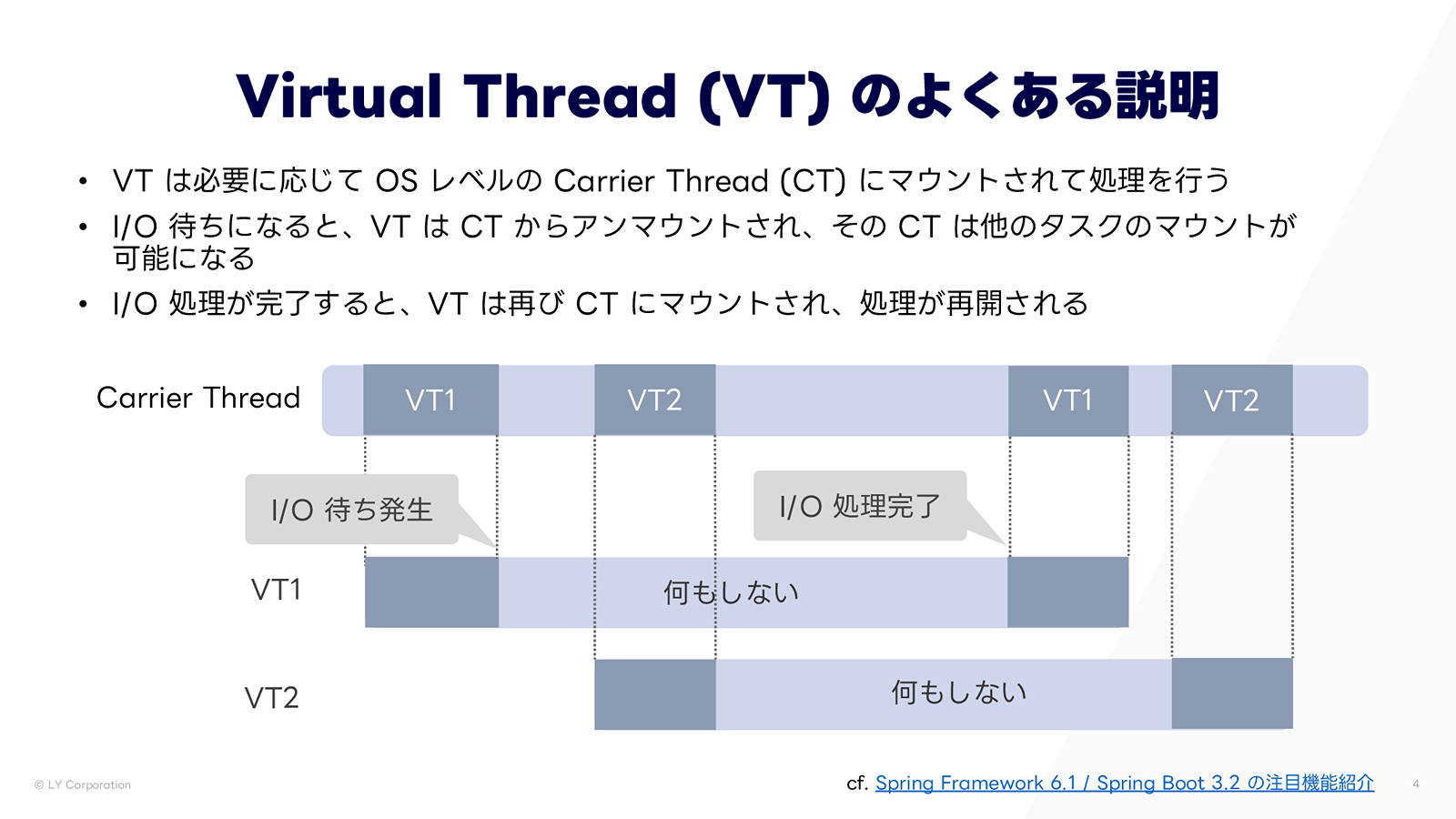
Virtual Thread(VT)は、必要に応じてOSレベルの Carrier Thread(CT)にマウントされて処理を行います。I/O 待ちが発生すると、まずVTはCTからアンマウントされます。アンマウント中、CT は他の VT をマウントできるため、待ち時間中もリソースを有効活用できます。I/O 処理完了後、VT は再び CT にマウントされ、処理を再開します。
しかし、この仕組みがどのように実装されているのか、どのように I/O 待ちを検知しているのか、スタックの保存・復元がどのように行われているのかといった内部の詳細は、あまり知られていません。そこで、本記事では、Deep Dive として次のような疑問に答える形で解説を進めます。
- 大量に生成した場合のメモリ消費は問題ないのか?
- 中断した処理をどのように再開しているのか?
- Virtual Thread はどのように I/O 待ちを検知しているのか?
- Carrier Thread は何本くらいあるのか?
- Carrier Thread に張り付いて剥がれなくなることはないのか?
- ThreadLocal は使えるのか?
Virtual Thread の Mount/Unmount 機構
Java のメモリ空間について復習
「大量に生成した場合のメモリ消費は問題ないのか?」の答えを知るためには、まず Java のメモリ空間を理解する必要があります。
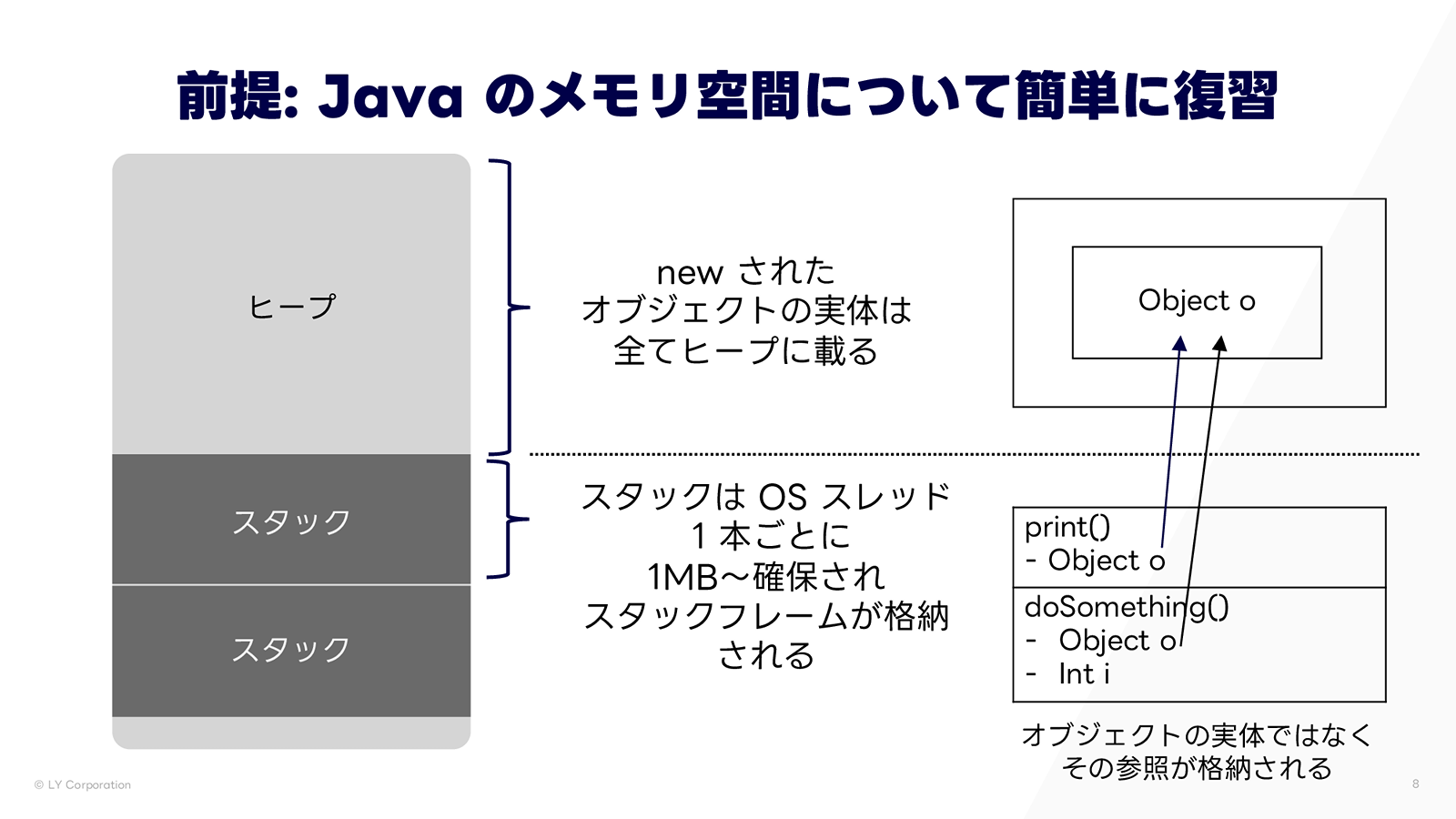
Java のメモリ空間は大まかにヒープ領域とスタック領域に分かれます。ヒープ領域には、new されたオブジェクトの実体が格納されます。一方、スタック領域は OS スレッド1本ごとにデフォルトで 1MB 確保され、内部にはスタックフレームが格納されます。
Platform Thread のメモリ利用
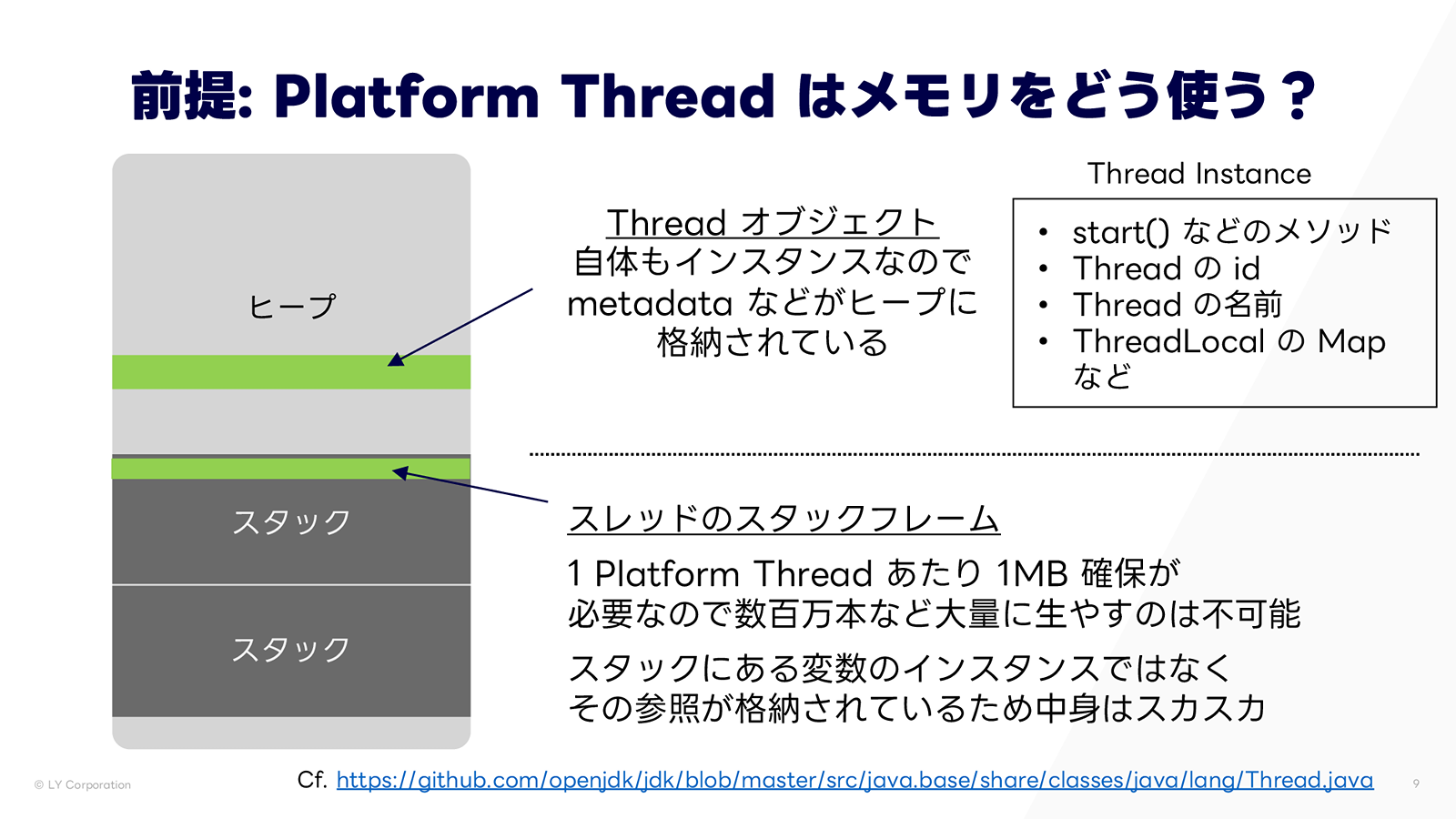
続いて、従来の Platform Thread(OS スレッド)がどのようにメモリを使用するかを見ていきましょう。1つの OS スレッドには、対応する Thread クラスのインスタンスがあり、これ自体はヒープに存在します。このインスタンスには、start() などのメソッド、スレッド ID や名前などのメタデータ、ThreadLocal の Map などが含まれます。一方、スタック領域には、先述の通り OS スレッドのスタックフレームが格納されます。
1 スレッドあたり 1MB のスタック領域を確保するため、Platform Thread を数百万本生成するのは非現実的であることがわかります。また、スタックにはオブジェクトの実体ではなく参照のみが格納されるため、スタック領域の実際の使用率は低く、1MB 確保しても大部分は未使用となることが多いです。そのため、メモリの利用効率は良くありません。
Virtual Thread のメモリ利用
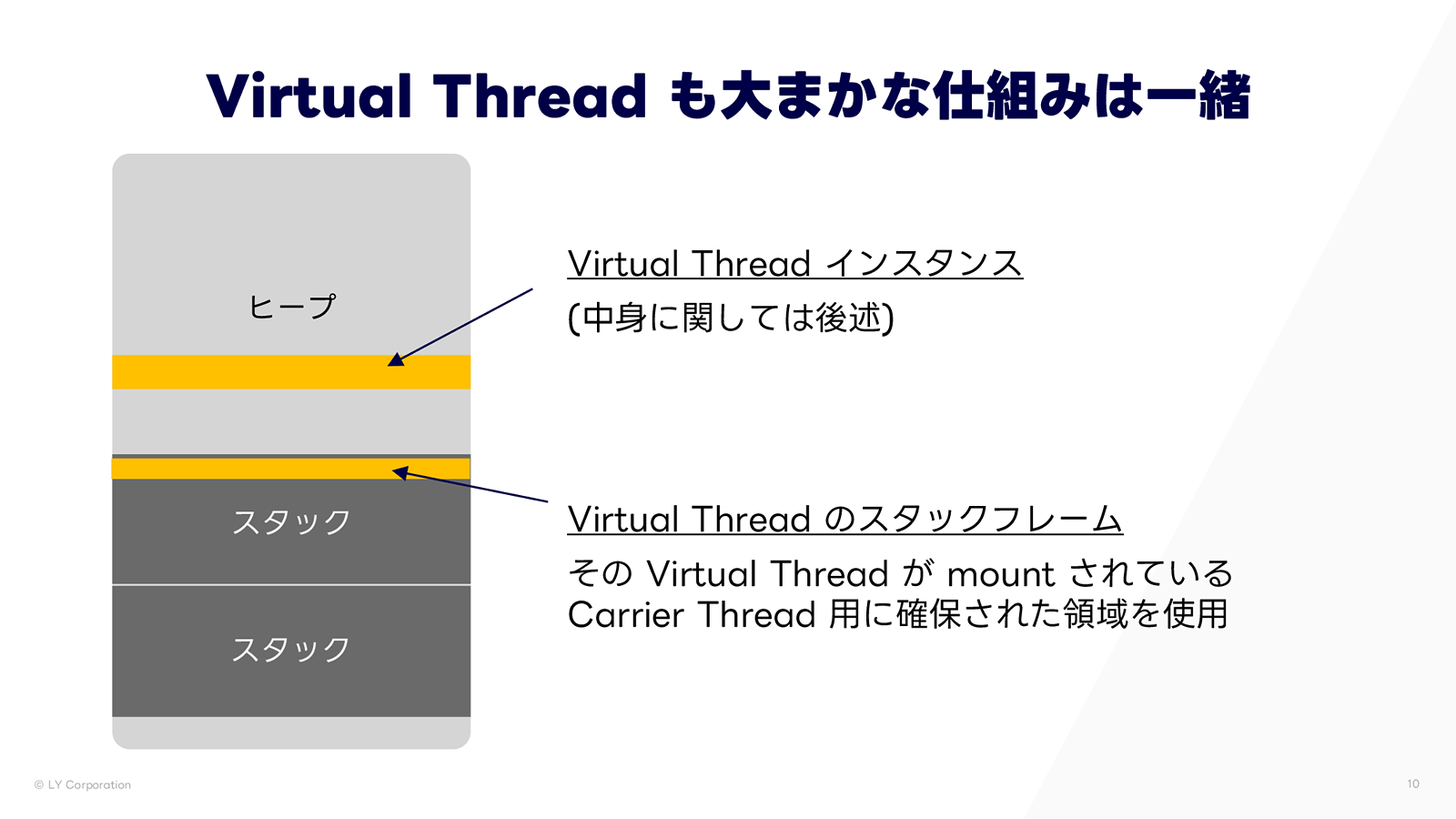
一方、Virtual Thread はどうでしょうか。上図は、Virtual Thread が Carrier Thread にマウントされている状態を示しています。Platform Thread と同様に、ヒープ上に Virtual Thread のインスタンスが存在し、スタックフレームがスタック領域に格納されます。Virtual Thread のスタックフレームは、Carrier Thread にマウントされている間は、その Carrier Thread 用に確保されたスタック領域を自分の領域として利用します。
Unmount 時のスタック保存
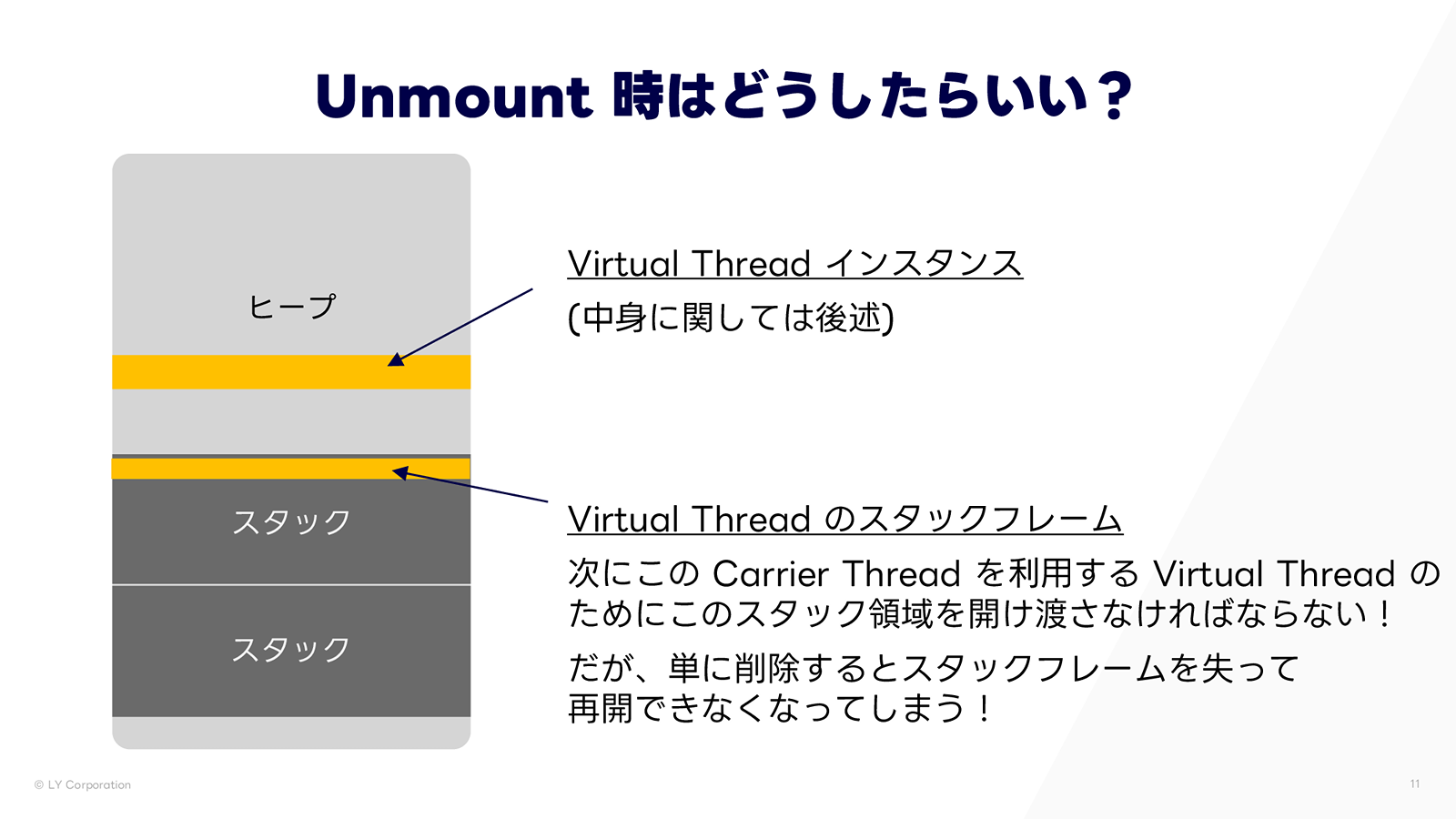
では、I/O待ちが発生して Virtual Thread がアンマウントされる場面を考えてみましょう。次の Virtual Thread が同じ Carrier Thread を利用する可能性があるため、その前に現在のスタック領域を空ける必要があります。しかし、単にこのスタック領域をクリアすると、実行時のスタックフレームが失われ、I/O 完了後に元の Virtual Thread を再開できなくなってしまいます。では、どのようにしたらいいでしょうか?
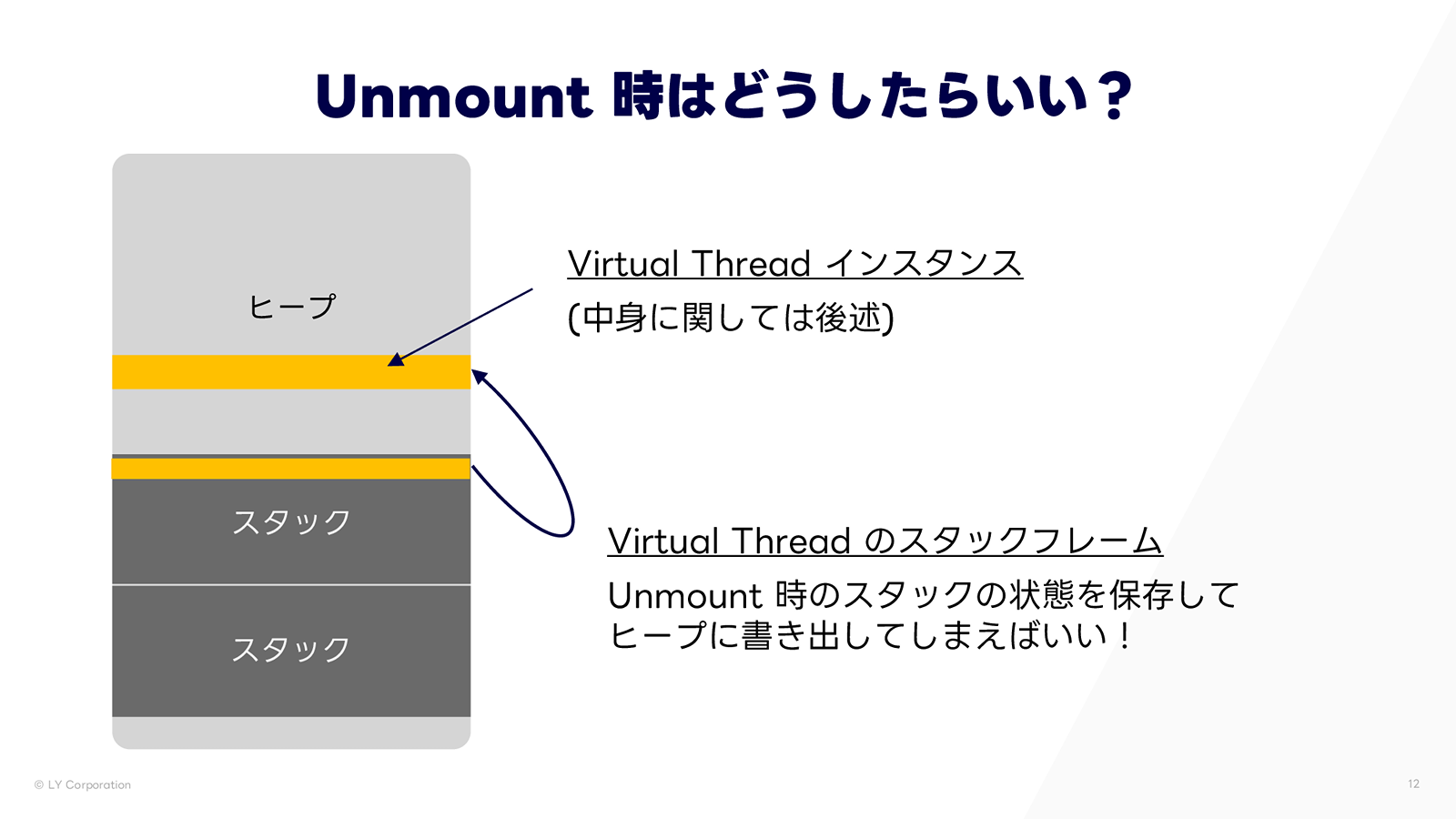
この問題の解決策として考えられたのが、「アンマウント時のスタックの状態をヒープに保存する」という方法です。上図のように、スタックの内容をヒープ上の Virtual Thread インスタンスに退避します。
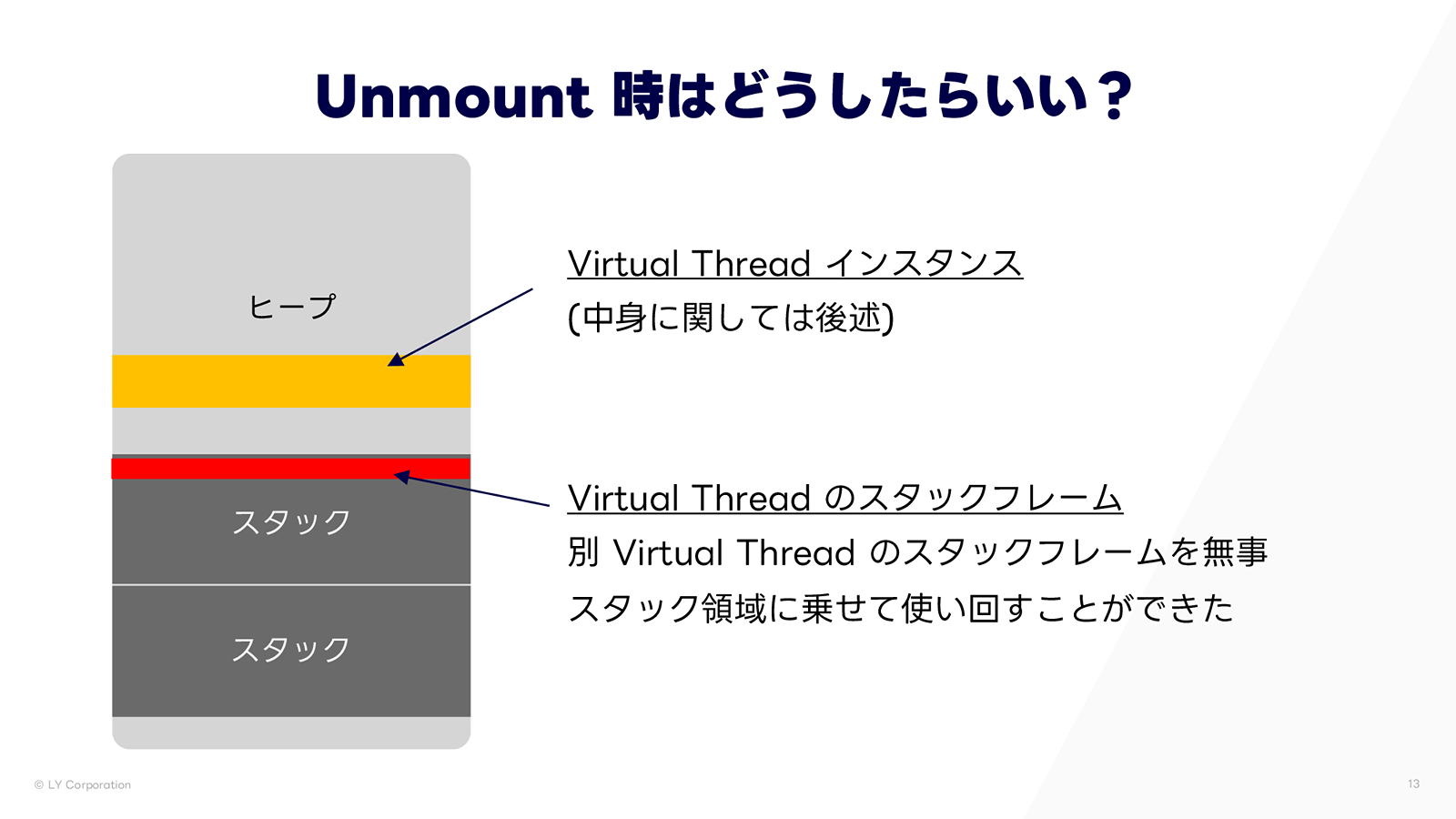
こうすれば、退避完了後、別の Virtual Thread のスタックフレームを同じスタック領域に載せて再利用できます。
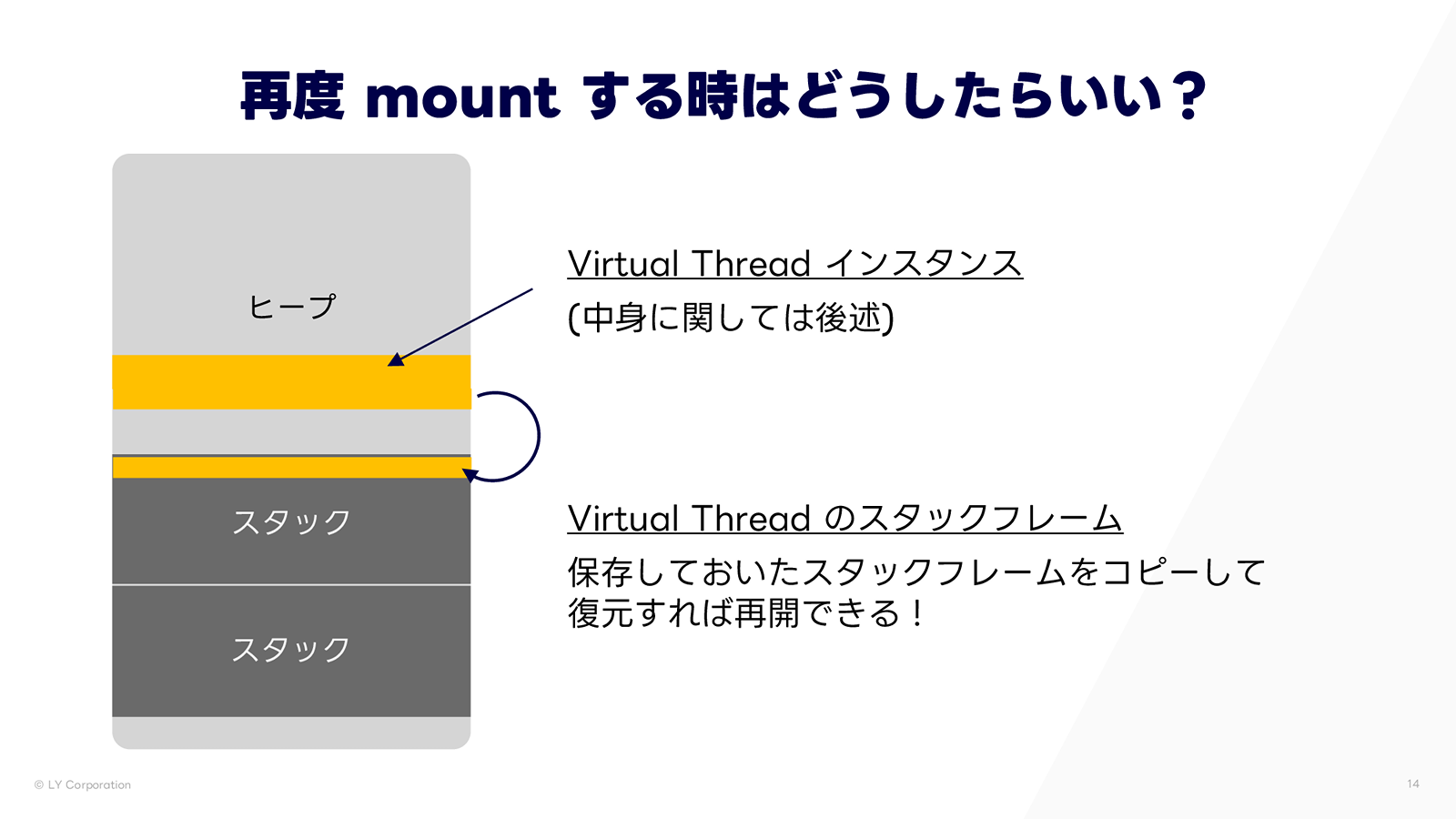
I/O の結果が返り、元の Virtual Thread を再びマウントする際は、ヒープに退避しておいたスタックを Carrier Thread のスタック領域にコピーして復元することで、処理を再開できるのです。
Continuation によるスタック管理
ここまでは図を使って説明してきましたが、せっかくなので、Deep Dive として実際の JDK のソースコードを見ていきましょう。Virtual Threadのクラス定義 の抜粋を示します。
final class VirtualThread extends BaseVirtualThread {
// 中略
private final Executor scheduler;
// 中略
private volatile int state;
// 中略
private final Continuation cont;
}Virtual Thread クラスはThreadクラスを継承しているため、Thread が持っているメンバ変数、例えばThreadLocalMapなどのメンバ変数も保持しています。そのメンバ変数の1つにContinuation があります。これは一体なんでしょうか? 実際に 実装 をみてみましょう。
public class Continuation {
// 中略
private StackChunk tail;
// 中略
private volatile boolean mounted;
// 中略
private Object[] scopedValueCache;
}実は、この Continuation が、先ほどの説明で登場した「スタックフレームを保存して書き出したもの」の正体です。このクラスの StackChunk というメンバ変数が実際のスタックデータを保持しています。さらに StackChunk の 実装 を追ってみましょう。
public final class StackChunk {
// 中略
private StackChunk parent;
// 実際のスタックデータも保持する
}コードからわかる通り、これは Linked List の構造をしています。つまり、StackChunk の実装では、スタック全体を一度にメモリに書き出すのではなく、小さい単位の chunk に分割して Linked List とし�て保持します。Continuation は Linked List の末尾への参照を保持することで、スタック情報を管理します。この実装により、最小限のメモリを確保し、必要に応じて動的に拡張できるように工夫されているのです。
冒頭で述べた、1本あたり1MBを一括確保するPlatform Threadと比較すると、この方式は非常に効率的であることがわかります。
ヒープ圧迫の懸念について
Virtual Thread は専用の巨大なスタック領域を確保せず、必要に応じてヒープに Continuation を保存します。ここで「Continuation の保存によりヒープが圧迫されるのではないか」と思う方がいるかもしれません。しかし、冒頭のメモリ空間の話で述べた通り、スタックの中身はオブジェクトの参照であり、サイズは小さいです。そのため、1000〜数百万個の Virtual Thread を生成してそのスタックをヒープに保持しても、メモリ消費増加は大きな問題にはなりません。ただし、ThreadLocal の扱いには注意が必要なので、後述します。
Virtual Thread のスケジューリング
次は、「Virtual Thread はどのようにして I/O 待ちを検知しているのか?」という疑問について解説します。
Platform Thread での I/O 処理

Virtual Thread の話をする前に、まず前提知識の確認から入ります。Virtual Thread を利用せず、Platform Thread で I/O を行う場合について考えてみます。リアクティブプログラミングのフレームワークなどを使っていない限り、I/O時にソケットはブロッキングモードで利用されます。そうすると、read(2) の結果が返ってくる、つまり I/O が完了するまで Platform Thread はブロックされ続け、その間別のタスクを実行することはできません。これがいわゆるブロッキング I/O であり、リソースの無駄遣いといえます。
Virtual Thread の I/O 処理
では本題の Virtual Thread をみていきましょう。
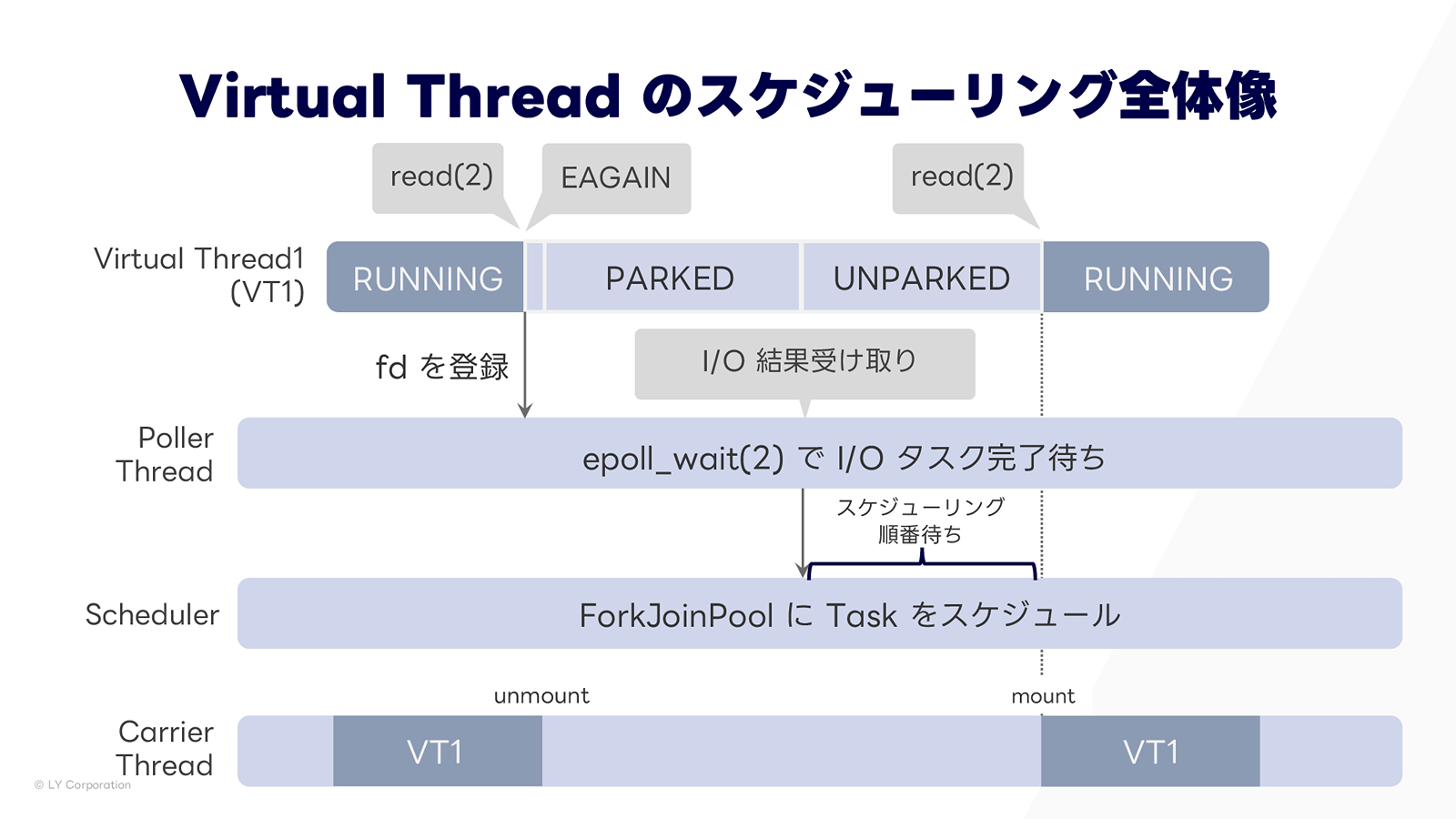
全体像を上に示しますが、分かりづらいと思うので順を追って説明していきます。

Virtual Thread を利用する場合、ソケットはブロッキングモードではなく、ノンブロッキングモードで利用されます。これにより、先ほどは read(2) の結果が返ってくるまでブロックされ続けていたのが、今度は、結果がすぐに得られない場合は即座にEAGAINが返却されます。
このEAGAINの返却は、時間のかかるI/O処理が開始されたことを意味します。そのため、イベントループ用のスレッド(Poller Thread)にI/O処理を登録し、結果通知を受け取れるようにします。このタイミングで Virtual Thread はunmountされ、スタックがContinuationへ退避された状態(PARKED)になりま�す。このような流れで、Carrier Thread を解放できます。
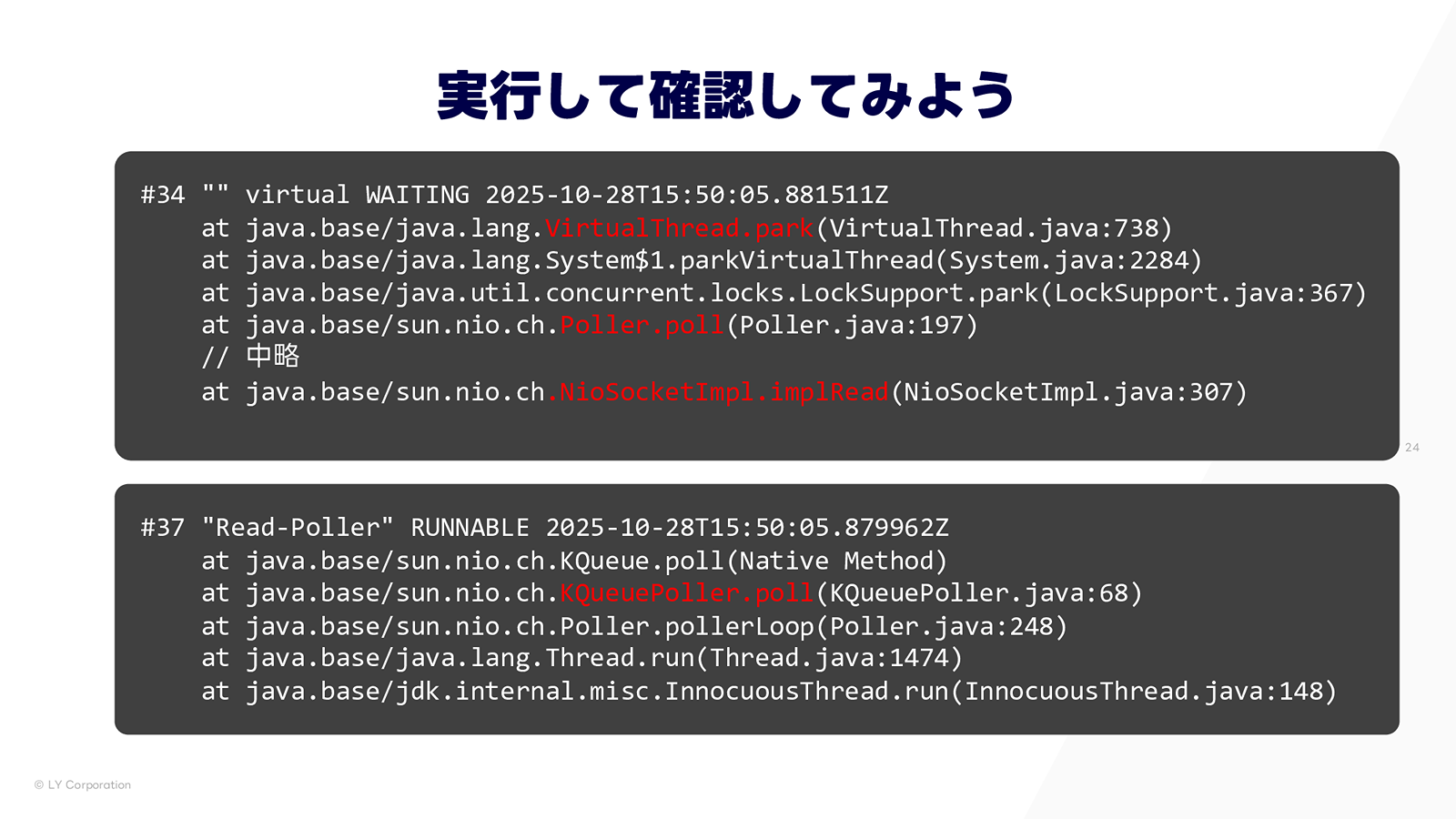
実際にブロッキング I/O を発生させた時のスタックトレースを上に示します。Virtual Thread のトレースでは read 呼び出し後に poller を呼び出し、その後 park していることが確認できます。また、Poller スレッドのトレースでは、到着待ちの処理が実行されていることがわかります。
I/O 完了時の処理
では、ここまでアンマウント時の挙動をみてきましたが、I/O 結果が返ってきた時はどのような挙動になるでしょうか?
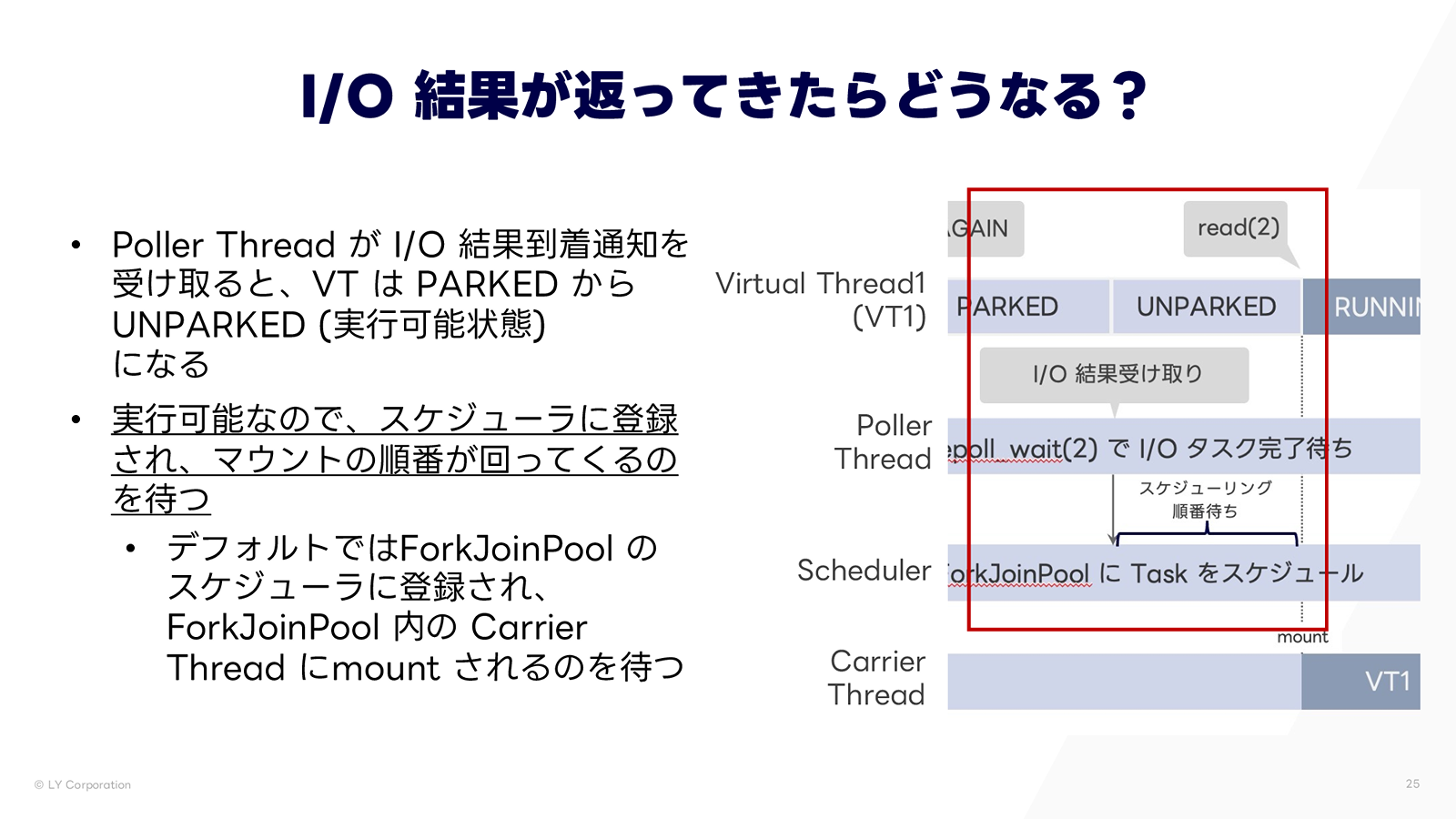
I/O 結果到着通知を受け取るのは、待ち受けていた Poller Thread です。結果が到着すると、Virtual Thread は再開可能となり、PARKEDからUNPARKED(実行可能状態)に遷移します。ただし、空いている Carrier Thread がないと実行できないため、順番待ちとなります。デフォルトではForkJoinPoolという Carrier Thread プールのスケジューラに登録され、プール内の Carrier Thread にマウントされるのを待ちます。

ForkJoinPool について少し補足です。ForkJoinPool は Platform Thread のプールであり、Virtual Thread はデフォルトでこのプール内のスレッド上にマウントされます。プール内のスレッドはデフォルトで CPU コア数と同程度しかないため、Carrier Thread はせいぜい CPU コア数くらいの本数しかないことになります。これが「Carrier Thread は何本くらいあるのか?」の答えです。
この ForkJoinPool はスケジューリングについて面白い挙動があるのでさらに補足しておきます。ForkJoinPool はワークスティーリングアルゴリズムを採用しています。このアルゴリズムでは、タスクキューは各 Platform Thread ごとに存在し、自身のキューが空の場合、他のスレッドからタスクを取得できます。これにより、特定のスレッドにタスクが集中することなく、効率的な処理が可能になります。
マウント後の処理再開

では、順番待ちが終わり、マウントの順番が回ってきた後の処理を見ていきます。まず、マウントされると Virtual Thread の状態はRUNNINGになります。スタックもContinuationからスタック領域へ復元されています。この状態でreadを再実行すると、結果はすでに到着しているため、即座にI/O結果が得られます。
以上のような流れで、Virtual Thread は I/O 待ちを検知し、Carrier Thread を効率的に利用しながら処理を行うことができます。
JDK24 以前の問題点とその解決
ここまでは仕組みについて見てき�ましたが、ここからはより実践的な話に移ります。まず、JDK 24 以前に存在した問題点を見ていきます。
Pinning 問題
JDK21(JEP444)では、本来 unmount されるべき Virtual Thread が Carrier Thread に固定されてしまう「Pinning」問題が報告されていました。特に、synchronizedロックでブロッキング操作を行った場合に unmount できなくなって張り付いてしまう現象が問題となっていました。
Pinning 発生の背景を説明しておきます。synchronizedロックは、オブジェクトのモニタの所有者情報として Platform Thread を記録します。ここで、Platform Thread の上で Virtual Thread が動いている時のことを考えてみてください。その VT が unmount されたり別の VT が mount されたりしても、所有者は Platform Thread に紐づいたままです。そのため、VT の mount や unmount に伴って、モニタの所有者が不在になったり、所有者が変更されたりしてしまう可能性があります。これを防ぐために、JDK21 ではやむを得ず synchronizedロック取得中の Platform Thread では Virtual Thread の unmount を禁止する対応が取られていたのです。
Pinning によるデッドロック
性能低下だけでなく、デッドロックが発生するケースも報告されていました。ReentrantLockとsynchronizedを併用したコード例 の抜粋を見てみましょう。
final ReentrantLock lock = new ReentrantLock(true);
lock.lock();
// 中略
Thread unpinnedThread =
Thread.ofVirtual().name("unpinned").start(takeLock);
// 中略
List<Thread> pinnedThreads = IntStream.range(0,
Runtime.getRuntime().availableProcessors())
.mapToObj(i -> Thread.ofVirtual().start(() -> {
synchronized (new Object()) {
takeLock.run();
}})).toList();
// 中略
lock.unlock();ReentrantLock を使用する Virtual Thread は、いち早く lock を取得しますが、Platform Thread に mount できないため待機します。一方、synchronized を使用する Virtual Thread は、Platform Thread を mount していますが ReentrantLock のロックを取得できないため待機します。これによりデッドロックが発生してしまいます。
JEP491 による改善
JDK24 以降では、JEP491 により、synchronizedブロック内の pinning 問題が解消されました。具体的には、JVM のモニタ実装が見直され、所有者が Platform Thread ではなく Virtual Thread に紐付くようになりました。これにより、ロックの実装は ReentrantLock ではなく synchronized を用いても問題なくなりました。ただし、pinning 問題が解消されただけで、ロック取得待ち自体の時間は変わらない点に注意が必要です。
JDK24以降でもpinningが発生する例外的なケースは存在しますが、ネイティブ連携などを行わない限り、問題になることはほとんどありません。具体的には、シンボル解決の待ち中の間のブロッキング操作、クラス初期化の待ち中の間のブロッキング、JNIやネイティブコード呼び出しによるブロッキングなどが該当します。詳細は JEP 491 をご参照ください。
Virtual Thread 利用上の注意点
本節からは、Virtual Thread を利用する際の注意点について解説します。
アンチパターン
アンチパターンの 1 つめは、Virtual Thread を CPU bound な処理で利用し、性能向上を期待することです。アンマウントされる余地のない処理では、Virtual Thread の恩恵はありません。
2つめは、Virtual Thread を pooling することです。Virtual Thread は Platform Thread と違って高価ではなく、タスクごとに大量生成・大量破棄する設計思想であるため、pooling は推奨されません。同時実行数を制限する意図でプールを使いたい場合は、semaphore の使用が推奨されています。興味のある方は JEP 491 をご覧ください。
ThreadLocal の取り扱い
最後に注意すべき点として、ThreadLocal の取り扱いについて言及しておきます。Virtual Thread は Thread を継承しているため、各 Virtual Thread について固有の ThreadLocal を保持できます。しかし、同時に大量の Virtual Thread を起動した場合、その数と同じだけの ThreadLocal が初期化され、ヒープに載り、さらに VT の終了に伴って全て破棄されます。この挙動は、ThreadLocal の使い方によっては問題となります。

問題にならないケースとして、MDC(Mapped Diagnostic Contexts)などの軽量な context の保持があります。軽量なため、大量に生成・破棄しても問題になりません。また、1リクエストごとに1VTを立ち上げるような状況では、リクエストの寿命と VT の寿命が一致しています。
一方、問題になるケースとして、Cipher など、生成コス�トが高い、かつスレッドセーフでないリソースの保持があります。VTを大量に生成すると、まず大量のオブジェクトが生成され、それぞれの Virtual Thread 上で一度だけ利用された後、VT と共に大量に破棄されます。結果としてヒープを圧迫する上、非常に無駄が多くなります。このようなケースでは、そのようなリソースのプールを作成し、それを static に、あるいは JDK25 で正式版となった ScopedValue で保持することが推奨されます。
その他のアドバイス
Virtual Thread 導入により、利用するメモリの領域が変わる可能性があります。冒頭で述べたように、従来は Platform Thread を生やしてプール化し、Stack 領域を大量に確保していました。一方、Virtual Thread の場合、VT が利用する Stack 領域は ForkJoinPool 分のみで、代わりにヒープ利用が大きくなる可能性があります。場合によっては、ヒープに割り当てるメモリの上限などを変更した方が良いケースもあります。いずれにしろ、Virtual Thread の状況監視のため、Micrometer の Virtual Thread Metrics を監視対象に加えておくと良いでしょう。
まとめ

以上、Virtual Thread の内部実装とその仕組みについて詳しく解説しました。Take Home Message は「Virtual Thread を正しく知って正しく使おう」です。導入時のトラブルシューティングの観点からも、利用するメモリ領域など、内部の仕組みを把握しておくことは重�要です。本記事がみなさまの Virtual Thread 導入の一助になれば幸いです。


