こんにちは、LINEヤフー株式会社の曾田です。普段はYahoo!マップの新アプリ向けバックエンド開発やスクラムマスターを担当しつつ、Orchestration Development Workshopのギルドメンバーとして、社内のAI活用推進にも取り組んでい��ます。
このLINEヤフー Tech Blogでは、Orchestration Development Workshop #9で開催した「AI × Slack 問い合わせ対応ワークフロー」の内容を紹介します。Slackに届く問い合わせに対して、AIがコードやドキュメントを横断調査し、根拠付きの1次回答を自動生成する仕組みを、Codex CLIのスキル機能を使って実現しました。
日常の業務の多くを占める問い合わせ対応
開発チームで働いていると、以下のような問い合わせがSlackで日常的に届きます。
- 「この仕様どうなってますか?」
- 「この不具合の原因を教えてほしい」
- 「このコードって何をしてるんですか?」
問い合わせ対応は多くの開発組織で発生する共通の業務です。ドメイン知識が求められ、リポジトリを横断して調べたり、過去ナレッジを参照したりと、1つの質問に回答するだけでも多くの時間と労力がかかります。
問い合わせ対応の何が大変か
問い合わせ対応の課題を整理すると、大きく3つに分類できます。
| 課題 | 詳細 |
|---|---|
| 突発的に来る | 集中して作業している最中に割り込みが入り、作業が中断される |
| 調査に時間がかかる | コード・Confluence・Slackを横断して調べる必要がある |
| 属人化しやすい | 特定の人に負荷が集中し、その人が不在だと対応が滞る |
筆者のチームでもこれらの課題を感じており、今回のワークショップではAIを活用してこれらの課題を軽減するアプローチを紹介しまし�た。
今回のワークショップのゴール
Slackの問い合わせに対して、AIがコードや過去ナレッジを調査し、根拠付きの1次回答を返すことを今回のワークショップのゴールとして設定しました。
AIが1次回答を用意することで、突発的な割り込みでも調査の手間が減り、特定の人に頼らずとも対応しやすくなることが期待できます。最終的な判断は人が行いますが、「ゼロから調べる」と「叩き台を確認する」では負担は大きく異なります。
ホップ・ステップ・ジャンプで進める導入ステップ
今回のワークショップでは、問い合わせ対応の自動化を3つのステップで段階的に進める構成にしました。
- ホップ(ハンズオン): ローカルのCodex CLIで問い合わせ対応スキルの仕組みを体験する
- ステップ: 各組織のデータソースで同じ仕組みを構築する
- ジャンプ(デモ): プライベートクラウド環境でクラウド化し、ナレッジを活用した自動の問い合わせ対応を実現する
まずはホップとして実際に体験し、その後ステップ・ジャンプの展望を示す構成としました。いきなりクラウド化を目指すのではなく、まずローカルで仕組みを理解し、段階的にスケールさせていく設計にしています。
ホップ:ローカル環境で問い合わせ対応を実現する
想定シナリオ
ワークショップでは、「レシピ公開サービス」の開発メンバーが、Slackの問い合わせチャンネルでプロダクトマネージャー(PdM)から以下の質問を受けた、というシナリオで進めました。
私たちが開発しているレシピ公開サービスについて質問です。
レシピの公開までの流れを教えてください。
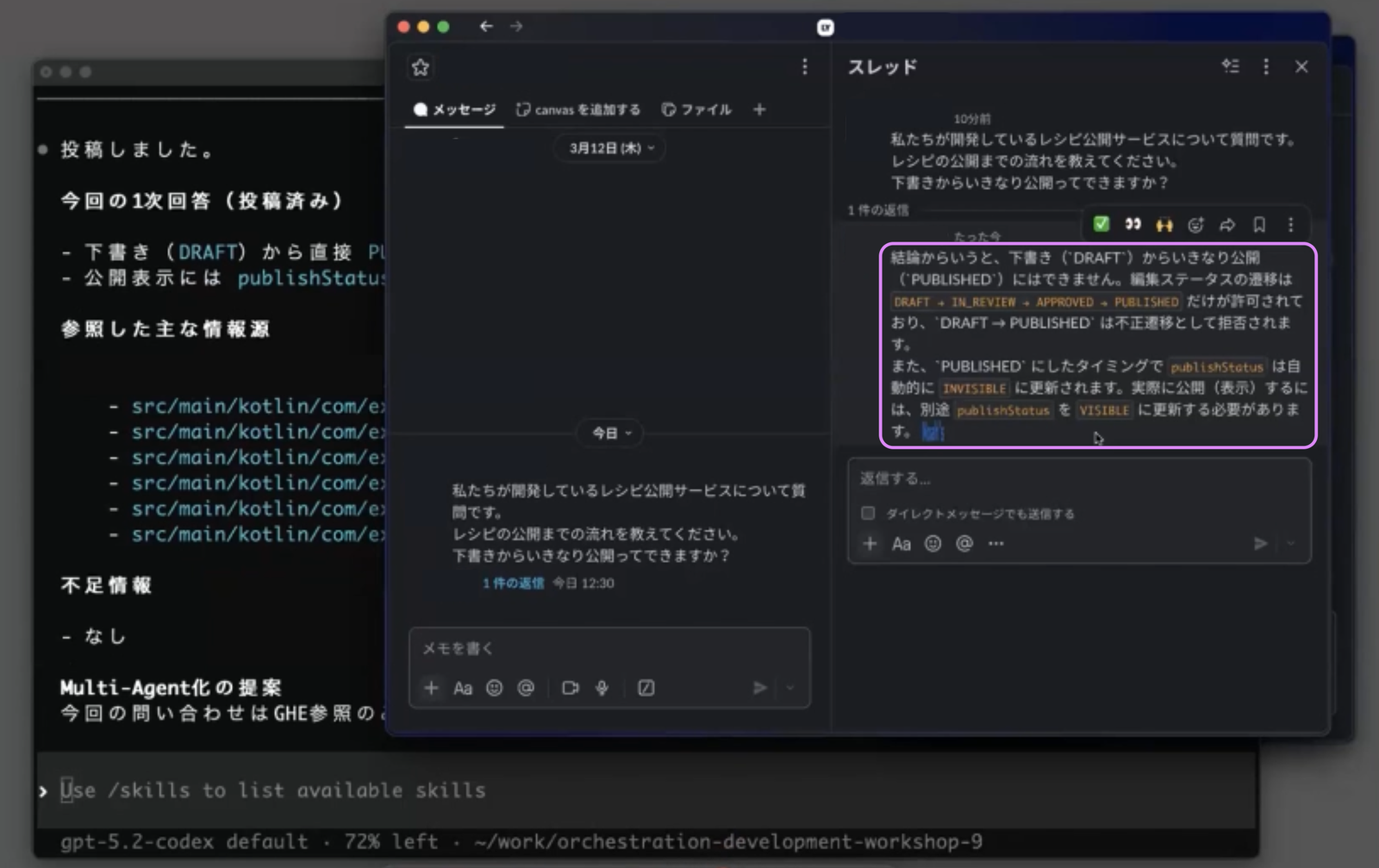
下書きからいきなり公開ってできますか?この問い合わせに対して、Codex CLIのスキル機能がフロントエンドとバックエンドの2つのリポジトリを横断的に調査し、1次回答を生成します。
AIが生成した1次回答
実際にCodex CLIが生成した1次回答は以下の通りです。
公開までの基本フローは、実装上は次の2軸です。
1. 編集ステータス遷移DRAFT -> IN_REVIEW -> APPROVED -> PUBLISHED(この遷移はバックエンドでバリデーションされています)
2. 公開ステータス切替INVISIBLE <-> VISIBLE(公開/非公開の切替APIは編集ステータスとの整合チェックをしていません)
そのため、質問の「下書きからいきなり公開できるか?」については、現状のAPI実装上は可能です。(publish-status 更新に編集ステータス制約がないため)
補足として、編集ステータスを PUBLISHED にしたタイミングでは、publishStatus は一度 INVISIBLEに設定される実装になっています。なので運用意図としては「編集完了後に公開ON」という流れが想定です。
注目すべき点は、単に「できる/できない」という表面的な回答ではなく、コードの実装を根拠にした技術的な説明になっていることです。編集ステータスと公開ステータスの2軸という設計上の構造を把握した上で、「API上は可能だが、運用意図としては段階的なフローが想定されている」という、開発者が求める粒度の情報を回答しています。
1次回答の確認と投稿
今回のスキルでは、回答を生成した後、Slackへの投稿前にユーザーへ確認を求めるようにしています。
この1次回答を投稿してよいですか? (Y/N)- Y → Slackの元スレッドに回答を投稿
- N → 追加調査して回答を改訂
人が最終判断を行う設計にすることで、AIが誤った情報を投稿してしまうリスクを抑える狙いがあります。
$answer-slackスキルの仕組み
動作フロー
$answer-slackスキルは、以下の6つのステップで動作します。
| Step | 内容 | 詳細 |
|---|---|---|
| Step 0 | ナレッジソース確認・登録 | 調査に使う情報源(リポジトリ、Confluence等)を確認・追加 |
| Step 1 | 問い合わせの把握 | Slack MCPでメッセージとスレッドを取得し、質問内容を理解 |
| Step 2 | ナレッジ検索 | 登録済みナレッジソースを横断検索し、関連情報を収集 |
| Step 3 | 1次回答の作成 | 検索結果をもとに、根拠付きの回答を作成 |
| Step 4 | 1次回答の確認・投稿 | ユーザーの承認を得てSlackスレッドに投稿 |
| Step 5〜6 | 振り返り・Multi Agents化提案 | セッションを振り返り、次回の効率化を提案 |
スキル定義の概要
$answer-slackスキルの中核となるのは、ナレッジソースの管理とステップごとの実行フローです。以下は、社外公開用に一部内容を調整したスキル定義の概要です。
# answer-slack
Slackの問い合わせに対し、ナレッジソースを検索して1次回答を作成・投稿するスキル。
## ナレッジソース
ナレッジソースは YAML ファイルで管理する。
対応するソースの種類は以下の通り:
- GHEリポジトリ(repos)
- Confluenceページ(confluence)
- Jiraプロジェクト / ボード(jira)
- Slackスレッド / チャンネル(slack_threads / slack_channels)
- Google Driveファイル(drive_items)
## ナレッジソース定義の例
repos:
- repo: https://ghe.example.com/owner/api-server
description: APIサーバー本体
confluence:
- page_id: "123456789"
space_key: TEAM
description: 運用手順ページ
jira:
- scope: project
project_key: TEAM
description: 参照対象プロジェクト
slack_channels:
- channel_id: C01234567
channel_name: team-help
description: 問い合わせの主要ナレッジチャンネル
## 実行フロー
### ナレッジソースが未登録の場合 → 初期設定
関連する情報源URLを箇条書きで受け取り、種別を自動判定して登録する。
### ナレッジソースが登録済みの場合 → 回答モード
Step 0: 利用可能な情報源を提示し、不足がないか確認
Step 1: Slack MCPでメッセージを取得し、問い合わせ内容を把握
Step 2: 登録済みナレッジソースを横断検索
Step 3: 検索結果をもとに1次回答を作成(参照情報源も記録)
Step 4: ユーザー確認後、Slackスレッドに投稿
Step 5: セッション振り返り
Step 6: Multi Agents化の提案(リポジトリごとのexplorerエージェント生成)設計上のポイント
このスキルの設計で特に工夫した点は以下の3つです。
- ナレッジソースの外部管理: スキル定義本体にデータソースを埋め込まず、YAMLファイルで分離管理することで、チームや案件ごとに情報源を柔軟に差し替えられる
ghコマンドによるリモート調査: リポジトリをgit cloneせず、ghコマンド経由で必要な情報だけを取得することで、コンテキストの無駄を抑えられる- 段階的な確認フロー: 各ステップでユーザーの確認を挟み、AIが独走しない設計にしている
Multi Agentsによるコンテキスト最適化
Single Agentの課題
1つのAgentで複数リポジトリを順番に調査すると、調査ログがすべてMain Agentのコンテキストに蓄積されます。
Main Agent
├── 背景理解
├── 調査ログ(リポジトリA)
├── 調査ログ(リポジトリB)
└── 結果の要約コンテキストが肥大化すると、重要な情報が押し出され、回答精度が低下するリスクがあります。
Multi Agentsによる解決
$answer-slackスキルには、セッション終了後にリポジトリごとのexplorerエージェントを自動提案する機能が組み込まれています。
これらの agent を作成して登録しますか?承認すると、次回以降はリポジトリごとに専用のSub Agentが並列で調査を行い、調査ログがMain Agentに蓄積されにくい構成に切り替わります。
Main Agent
├── 背景理解
├── 要約A ←── Agent A(リポジトリA専用)
├── 要約B ←── Agent B(リポジトリB専用)
└── 結果の要約Main Agentが受け取るのは各Sub Agentの最終要約が中心となります。これにより、コンテキストの肥大化を抑えつつ、複数リポジトリの並列調査による効率化も期待できます。
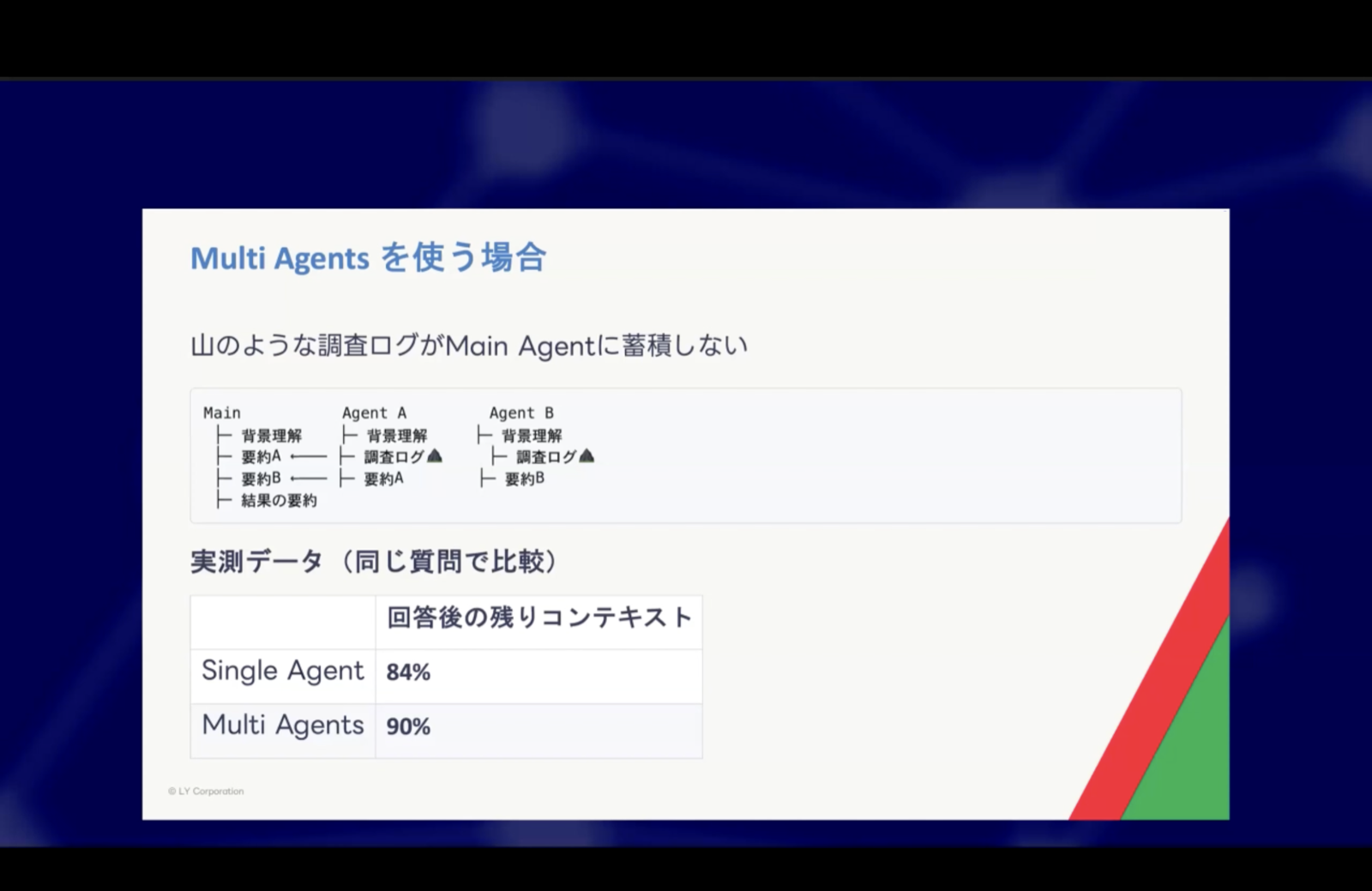
実測データ
ハンズオンで使用した「レシピの公開までの流れを教えてください」という問い合わせを、Single Agent構成とMulti Agents構成のそれぞれで処理した結果、回答後の残りコンテキストに以下の差が見られました。
| 構成 | 回答後の残りコンテキスト |
|---|---|
| Single Agent | 84% |
| Multi Agents | 90% |
Multi Agents構成の方が6ポイント多くコンテキストを残せていることがわかります。問い合わせ対応が重なる場面や、追加質問が続くケースでは、この差が回答精度の維持に影響すると考えています。
Multi Agentsの注意点
Multi Agents構成にはトレードオフもあります。MainとSubのAgentを合計した全体のトークン消費量は若干増加します。
増加の主な要因は以下の2点です。
- 背景の複製: 背景理解がエージェント数分複製される
- 要約の多重発生: 各Sub Agentの要約 + Main Agentでの統合要約
Main Agentのコンテキストを抑え��ることで回答精度を維持するか、全体のトークン効率を優先するかは、タスクの性質に応じて判断する必要があります。
ローカル環境の強みとスキルの活用
ローカル環境ならではのメリット
Codex CLIによるローカルでの問い合わせ対応について紹介しましたが、ローカル環境には以下のような強みがあります。
- 複数ツールの横断が可能: Google Drive、Jira、Confluence、Git、Slackを1つのCLIセッションから横断的にアクセスできる
- カスタマイズが柔軟: スキル定義やエージェント設定を用途に合わせて調整できる
- すぐに試せる: 問い合わせが来たら、その場でスキルを実行して対応できる
スキルの作成と共有
Codex CLIでは、スキルを作成・評価するための仕組みも利用できます。
# 新規スキルの作成
$skill-creator [作りたいスキルの内容を伝える]
# 既存スキルの評価・洗練
$skill-creator$answer-slack を評価してチーム内でスキルを共有することで、個人の知見がチーム全体のナレッジとなり、問い合わせ対応の品質向上につながることが期待できます。
ステップ・ジャンプ:クラウドへの展開
ローカルからクラウドへ
ここまではローカルのCodex CLIでの体験を中心に紹介しました。これをクラウド上で自動的に実行できる仕組みについても検討しました。それを実現するのがプライベートクラウド上のサ�ーバーレス実行環境と社内RAGツールの組み合わせです。
社内RAGツールの活用
ワークショップのデモでは、社内で提供されているRAGツールを活用しました。主な特徴は以下の通りです。
- ConfluenceやGitHubなどの社内データソースを登録し、RAGで回答を生成できる
- MCPとして利用可能で、既存のAIエージェントとの連携がしやすい
プライベートクラウド + 社内RAGツールで実現する自動化
プライベートクラウドのサーバーレス実行環境と社内RAGツールを組み合わせることで、以下の自動化を実現しました。
- Slackのメッセージを自動検知: 問い合わせチャンネルへの投稿をトリガーに処理を開始
- 社内RAGツールを参照して回答を生成: 事前に登録されたConfluenceやGitHubのナレッジを検索・参照
- クラウド上で24時間稼働: 人手を介さず自動で1次回答を返す
ローカルでのCodex CLIによる体験をそのままクラウドに持ち上げる形で、各組織のデータソースに差し替えれば同様の仕組みを構築しやすいのが特徴です。
ConfluenceのRAG化という共通課題
クラウド展開を進める中で見えてきたのが、ConfluenceのRAG化に課題を感じている組織があるということです。Confluenceに蓄積されたナレッジをうまくAIに参照させられず、回答精度が上がらないという声がありました。
社内RAGツールはこの課題に対する1つのアプローチです。ConfluenceもGitHubもまとめてRAG化でき、問い合わせに対して関連するナレッジを自動で検索・参照して回答を生成します。ConfluenceのRAG化は多くの組織で共通する課題であり、こうしたツールの活用は有効な選択肢の1つと考えています。
この取り組みから得た学び
AIと人の役割分担
今回のワークショップで最も重視したのは、AIは1次回答を生成し、人が最終判断を下すという役割分担です。$answer-slackスキルが投稿前にユーザーへ確認を求める設計にしているのは、この考え方に基づいています。
AIが得意なのは、複数のデータソースを高速に横断検索し、関連情報を集約することです。一方で、回答の妥当性判断やニュアンスの調整は、ドメイン知識を持つ人が行うべき領域です。
段階的な導入の重要性
ホップ・ステップ・ジャンプの構成で示したように、いきなり完全自動化を目指す必要はありません。まずはローカルで実際に仕組みを体験し、自チームのデータソースで試し、効果を確認してからクラウド化を検討する。この段階的なアプローチが、導入のハードルを下げ、定着率を高めるポイントだと考えています。
おわりに
問い合わせ対応は、多くの開発組織で発生する重要な業務です。今回のワークショップには約600人の方にリアルタイムで参加いただき、Codex CLIのスキル機能を使ってSlackの問い合わせにAIが根拠付きの1次回答を生成する仕組みを体験していただきました。
ローカルでの体験からクラウドでの自動化まで、段階的に進められる設計にしたことで、参加者の皆さんには「まず自チームで試��してみよう」という具体的なアクションを持ち帰っていただけたのではないかと感じています。
また、今回のデモで活用した社内RAGツールは、パイロット版として社内リリースされていたものの、アピールの機会がなく社内ではほとんど知られていない状態でした。筆者自身も、社内のプラットフォームに詳しいメンバーからの情報で存在を知りました。今回のワークショップを通じて参加者にこのツールを紹介できたことは、ワークショップの価値を高める結果にもつながりました。実際、デモの後には社内でこのRAGツールが話題に上がるようになり、組織横断の場がツールの発掘・共有を促進する効果を実感しました。
なお、ワークショップのハンズオンではCodex CLIの/experimental設定からMulti Agentsをオンにする手順を案内していましたが、まさにハンズオン直前のタイミングでMulti Agents機能がGA(General Availability、正式リリース)に昇格していました。最新版にアップデート済みの参加者は設定不要で最初から有効になっており、筆者自身もこの変更を把握できておらず、混乱する場面がありました。AI領域の変化の速さを身をもって体感した出来事です。
今後もOrchestration Development Workshopを通じて、AI Agent活用の実践知識を社内外に共有していきたいと考えています。本記事の内容が、皆様の問い合わせ対応の改善につながれば幸いです。


