こんにちは。ManagedValdチームです。
こ��の記事では、ベクトル検索を利用したい人に向けて、データセットを使った検証を通じて、最適な検索エンジンの選定基準を考察します。
(注)本記事では、「検索手法」と「検索エンジン」を以下のように使い分けています。
- 検索手法: データをどのように検索するかという方法やアルゴリズム(例:ベクトル検索、全文検索、ハイブリッドサーチ)
- 検索エンジン: 検索手法を実装し、実際に検索を行うためのソフトウェアやシステム(例:OpenSearch、Vald)
はじめに
データが溢れる現代において、良い検索システムを提供することは重要です。
一方で、Baymard Instituteの調査によると、ECサイトの61%がユーザーの意図しない検索結果を表示しているそうです。実際に検索システム改善の必要性を感じている方も多いのではないでしょうか。
しかし、検索領域は日々進化しており、最適な技術選定は簡単ではありません。
まずは近年の検索領域のトピックを通じて、技術選定を複雑にしている要因を紐解いていきましょう。
1. ベクトル検索の利用拡大
ベクトル検索とは、非構造データ(画像・テキストなど)を数値ベクトルに変換し、その類似度に基づいて検索を行う手法です。
データをベクトル化(Embedding)すればあらゆるデータに対して利用可能であり、例えば、Yahoo!ショッピングの類似画像検索などに利用されています。
ベクトル化のためのモデル作成には高度な専門性が必要ですが、近年では汎用的で高性能な事前学習済みモデルやAPIが公開されているため、ベクトル化自体のハードルは下がり、活用事例もさらに増えています。
2. 全文検索エンジンの進化
全文検索とは、テキストデータからキーワードの索引を作成し、高速にキーワード検索を行う手法です。
ベクトル検索よりも長い歴史を持ち、主にテキスト検索に使われてきました。基本的には文章におけるクエリ単語の出現頻度から算出されるBM25というスコアを元にランキング結果を返します。
ベクトル検索の利用拡大の中で全文検索エンジンも進化し、ベクトルを利用した検索がプラグインでサポートされてきています。
3. ハイブリッドサーチの台頭
ハイブリッドサーチとは、ベクトル検索での意味検索と全文検索でのキーワード検索を組み合わせる方法です。
特徴の違う両者のメリットを組み合わせるので、高精度であると言われています。
ベクトル検索の結果と全文検索エンジンの結果を独自に組み合わせることもできますが、近年は多くの全文検索エンジンの標準プラグインとしてサポートしており、簡単に利用できるようになってきています。
検索エンジン選定の難しさ
情報検索領域での選択肢の拡大について述べてきましたが、次は検索エンジンの選定について考えてみます。
検索エンジンは、ベクトル検索に特化したベクトル検索エンジンと主に全文検索を提供する全文検索エンジンの2つに分類できます。(多くの全文検索エンジンも、現在はベクトル検索をプラグインなどで利用可能です)
- �ベクトル検索エンジン: Vald、Milvus、Vertex AI Vector Search など
- 全文検索エンジン: Elasticsearch、Solr、OpenSearch、Vespa など
検索エンジンの選定には、まずは検索エンジンができることを理解し、その上でユースケースに合った検索手法を選定する必要があります。
例えば、本記事で使用するValdとOpenSearchの各種手法への対応状況は、以下の通りです。
| 検索エンジン | 全文検索 | ベクトル検索 | ハイブリッドサーチ |
|---|---|---|---|
| Vald | 非対応 | 対応 | 単体での利用はできない |
| OpenSearch | 対応 | 標準プラグインで利用可能 | 標準プラグインで利用可能 |
上記の表では、各検索手法の対応可否しか比較しておらず、実際には検索精度、速度、運用コストなども考慮する必要があります。
また、ユースケースに合わせてどの検索手法を使うべきなのかについても明らかにする必要があります。
この後は、以下2つの検証を行います。
- (検証1)各検索手法の比較
- ベクトル検索、全文検索、ハイブリッドサーチといった各検索手法を検証します。
- (検証2)ベクトル検索のパフォーマンス検証
- ベクトル検索をするときの速度・精度のパフォーマンスを検索エンジン間で比較します。
最終的には、ユースケース別に、ベクトル検索エンジン、全文検索エンジンといった検索エンジン自体の選定基準について考察します。
(検証1)各検索手法の比較
各検索手法(全文検索・ベクトル検索・ハイブリッドサーチ)が、実際のデータセットでどの程度の精度が出るのかを比較します。
検証には、LINEヤフーが開発サポートしているベクトル検索エンジンのValdと、全文検索エンジンのOpenSearchを利用します。
使用するデータセット
データセットは、グラスゴー大学提供の CISI (a dataset for Information Retrieval)を利用します。
検索する際の正解データとして、関連ドキュメントIDが提供されているため、検索精度を定量的に評価できます。
データの概要
ドキュメント(Documents): 1,460件
内容: 各ドキュメントは概要文(Abstract)とそれに対応するIDを持ちます。
補足: 元のデータセットには、著者名、タイトル、他のドキュメントの引用リストなども含まれていますが、今回の検証では概要文とIDのみを使用します。
例:
- ドキュメントID: 1
- 概要文:
18 Editions of the Dewey Decimal Classifications Comaromi, J.P. The present study is a history of the DEWEY Decimal Classification. The first edition of the DDC was published in 1876, the eighteenth edition in 1971, and future editions will continue to appear as needed. In spite of the DDC's long and healthy life, however, its full story has never been told. There have been biographies of Dewey that briefly describe his system, but this is the first attempt to provide a detailed history of the work that more than any other has spurred the growth of librarianship in this country and abroad. "
クエリ(Queries): 112件
内容: 各クエ�リは質問文とIDを持ちます。(36件のクエリについては関連ドキュメントIDがないため、検証時には関連ドキュメントIDが存在する76件を対象とします)
例:
- クエリID: 1
- 質問文:
What problems and concerns are there in making up descriptive titles? What difficulties are involved in automatically retrieving articles from approximate titles? What is the usual relevance of the content of articles to their titles?
関連ドキュメントID(Relevance Judgments):76件
内容: 各クエリに対して、関連するドキュメントのIDがリストとして提供されています。このIDを正解として評価を行います。
例:
- ID: 2
- クエリID 2 に関連するドキュメントID:
[29, 68, 197, 213, 214, 309, 319, 324, 429, 499, 636, 669, 670, 674, 690, 692, 695, 700, 704, 709, 720, 731, 733, 738, 740, 1136]
使用するモデル
テキストからベクトルへの変換が容易にできるsentence-transformersというライブラリで使える、all-mpnet-base-v2モデルを利用します。
検証方法
各検索手法で検索し、上位20件の結果から精度を算出します。
精度の評価
精度の評価には、Mean Reciprocal Rank(MRR)を利用します。
MRRとは、各クエリに対して、最初に出現する関連ドキュメントの順位の逆数を平均したものです。
ここで、 はクエリセットを表し、 はクエリ の検索結果に対して正しい答えが何番目に出てくるかを示しています。
MRRが大きいと、関連ドキュメントが上位に表示されており、検索精度が高いことを示します。
検索クエリの設定
全文検索(OpenSearch)
今回使うデータセットでは、クエリが長文であるため、完全一致での検索は困難です。そこで、minimum_should_match を30%に設定し、クエリ内の単語のうち30%以上が一致するドキュメントを対象とします。
検索クエリには改善の余地がありますが、今回は比較のためにデフォルトに近いシンプルなクエリを用いることにします。
search_query = {
"size": 20, # 最大20件取得
"query": {
"match": {
"text": {
"query": query_text,
"minimum_should_match": "30%"
}
}
}
}ベクトル検索(OpenSearch)
ベクトル検索では、Embeddingを事前に計算しておき、検索時にそのベクトルを指定します。
search_query = {
"size": 20, # 最大20件取得
"query": {
"knn": {
"passage_embedding": {
"vector": vector,
"k": 20
}
}
}
}ハイブリッドサーチ(OpenSearch)
ハイブリッドサーチでは、キーワード検索(matchクエリ)とベクトル検索(knnクエリ)を組み合わせます。内部ではnormalization_processorを使用し、それぞれのクエリの検索結果を正規化してリランキングをしています。
search_query = {
"size": 20, # 最大20件取得
"query": {
"hybrid": {
"queries": [
{
"match": {
"text": {
"query": query_text,
"minimum_should_match": "30%"
}
}
},
{
"knn": {
"passage_embedding": {
"vector": vector,
"k": 20
}
}
}
]
}
}
}ベクトル検索(Vald)
Valdでは以下のように検索設定をします。radiusとepsilonは検索精度を調整するパラメータです。
searchConfig = payload_pb2.Search.Config(
num=20, # 最大20件取得
radius=-1.0,
epsilon=0.2
)結果
検証結果を比較します。
| 検索手法 | 検索エンジン | 90 %ile (ms) | 99 %ile (ms) | Embedding Time (ms) | MRR |
|---|---|---|---|---|---|
| 全文検索 | OpenSearch | 10.42 | 23.79 | - | 0.605 |
| ハイブリッドサーチ | OpenSearch | 21.56 | 28.823 | (100) | 0.661 |
| ベクトル検索 | OpenSearch | 9.60 | 11.87 | (100) | 0.619 |
| ベクトル検索 | Vald | 1.93 | 2.363 | (100) | 0.615 |
※ Embedding TimeはLocalでの計測値です。環境によって大きく変わるため、参考値として載せています。
検索手法の比較
全文検索とベクトル検索を比較すると、ベクトル検索の方が高いMRRでした。これは、今回用いたドキュメントやクエリ�では、単純なキーワード検索よりも意味検索が有効であったことを示唆しています。
また、全体でハイブリッドサーチが最も高いMRR(0.661)を示しました。これは、全文検索のキーワード検索とベクトル検索の意味検索を組み合わせることで、関連ドキュメントを上位に表示できたためと考えられます。
ハイブリッドサーチには、今回試したクエリ以外にも以下のようなバリエーションがあります:
- 全文検索でのランキング結果上位N件に対し、ベクトル検索結果でリランキングする方法
- LTR(Learning to Rank)プラグイン等で、BM25等の特徴量に加えてベクトルの類似度も特徴量に組み込んでリランキングする方法
今回はシンプルなクエリを使いましたが、さまざまな方法を検証し最適化することで、さらなる精度向上が期待できます。
ハイブリッドサーチの実装コスト
ハイブリッドサーチは、今回はクライアント側でEmbeddingをしましたが、OpenSearchのSearchパイプラインにモデルを登録しておけば、テキストを渡すだけで登録や検索ができます。今回利用したall-mpnet-base-v2モデルはOpenSearchにデフォルトで登録済みであり、実装の難易度はより低くなります。ただし、Embeddingの速度についてはTritonのような推論サーバーを使う場合と比べ遅くなる可能性があります。
一方、ベクトル検索部分にValdを使ってハイブリッドサーチを行う場合は、OpenSearchとValdでそれぞれ結果を得た後に、マージしてリランキングするという処理をバックエンドサーバー等で実装する必要があります。これは実装が煩雑ですしネットワークコストもかかります。
全文検索エンジンでベクトル検索の要件を満たせる場合は、全文検索エンジンだけでハイブリッドサーチを行った方が運用コストが低そうです。
ベクトル検索をしたときの検索エンジン間の比較
今回はValdとOpenSearchの両方でベクトル検索を行いましたが、Valdの方がOpenSearchに比べて、検索時間が短いことが分かりました。一方で、精度はValdよりもOpenSearchがやや高い結果となりました。OpenSearchでは、データ数が少ないときには近似最近傍探索(ANN)を行わずに全探索を行うロジックが組み込まれており、精度が高くなることがあります。
また、検索エンジン自体のパラメータ設定によって、検索の精度と速度は大きく変わります。この検証結果だけでは、ベクトル検索機能の比較としては不十分です。
(検証2)ベクトル検索のパフォーマンス検証
各検索エンジンでベクトル検索をするときの速度と精度を比較します。
検証環境については、記事の最後のAppendixに記載しています。
データセット
テキスト検索の精度を測定したデータセットはデータ数が1,460件と小規模であるため、検索エンジンのANNのパフォーマンスを測定するにはデータ量が不十分です。
そのため、100万件のSIFTベクトルデータセットを利用します。近傍100件のIDがデータセットに含まれているので、検索結果の精度を測定できます。
検証方法
- Trainデータ(100万件)をValdとOpenSearchに登録します
- Testデータ(1万件)を1件ずつ検索(検索結果は10件に指定)し、検索時間と精度を計測します
ANN Benchmarksを参考に精度パラメータを複数設定し、それ以外は、基本的にはデフォルトの設定を使用しました。
今回は簡易的な検証のため、専用のロードテストツールではなくJupyter Notebook上で検証を行いました。同一クラスタで実施したためネットワークレイテンシはほぼありません。
精度の評価
Vertex AI ベクトル検索で紹介されているRecallを精度指標とします。このRecallは、検索結果の中で実際に正しい近傍データであるものの割合です。例えば、10個の検索結果を得るクエリを実行して9個の正解の最近傍を返した場合に、Recallは9/10 = 0.9になります。
このリコールの値は0から1の範囲をとり、1に近いほど、関連するドキュメントを検索できていることを示します。
結果
パラメータを変えた際の精度と速度(90%ileと99%ile)の結果をグラフにしました。
ValdとOpenSearchの両方で、精度と速度のトレードオフが見られました。
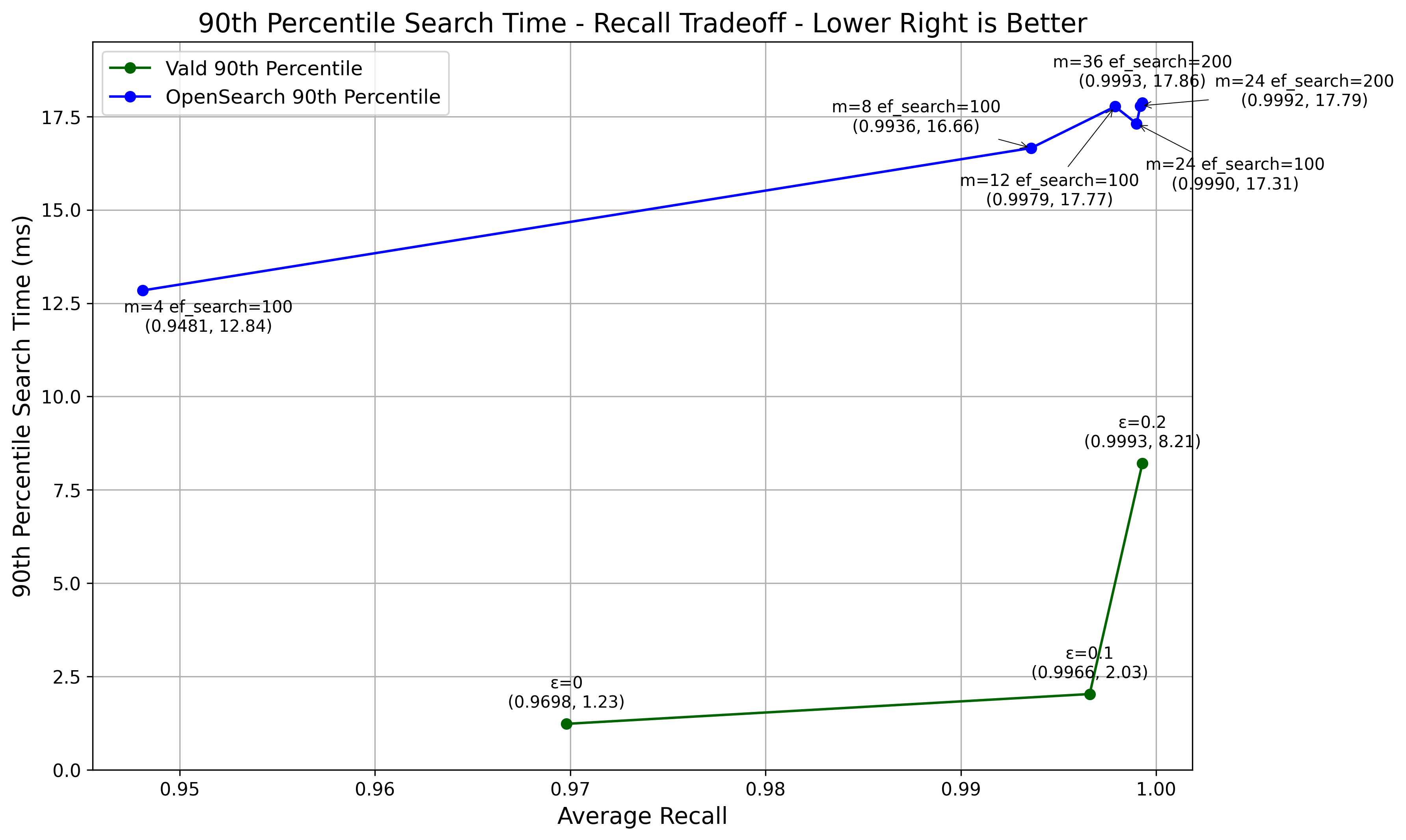
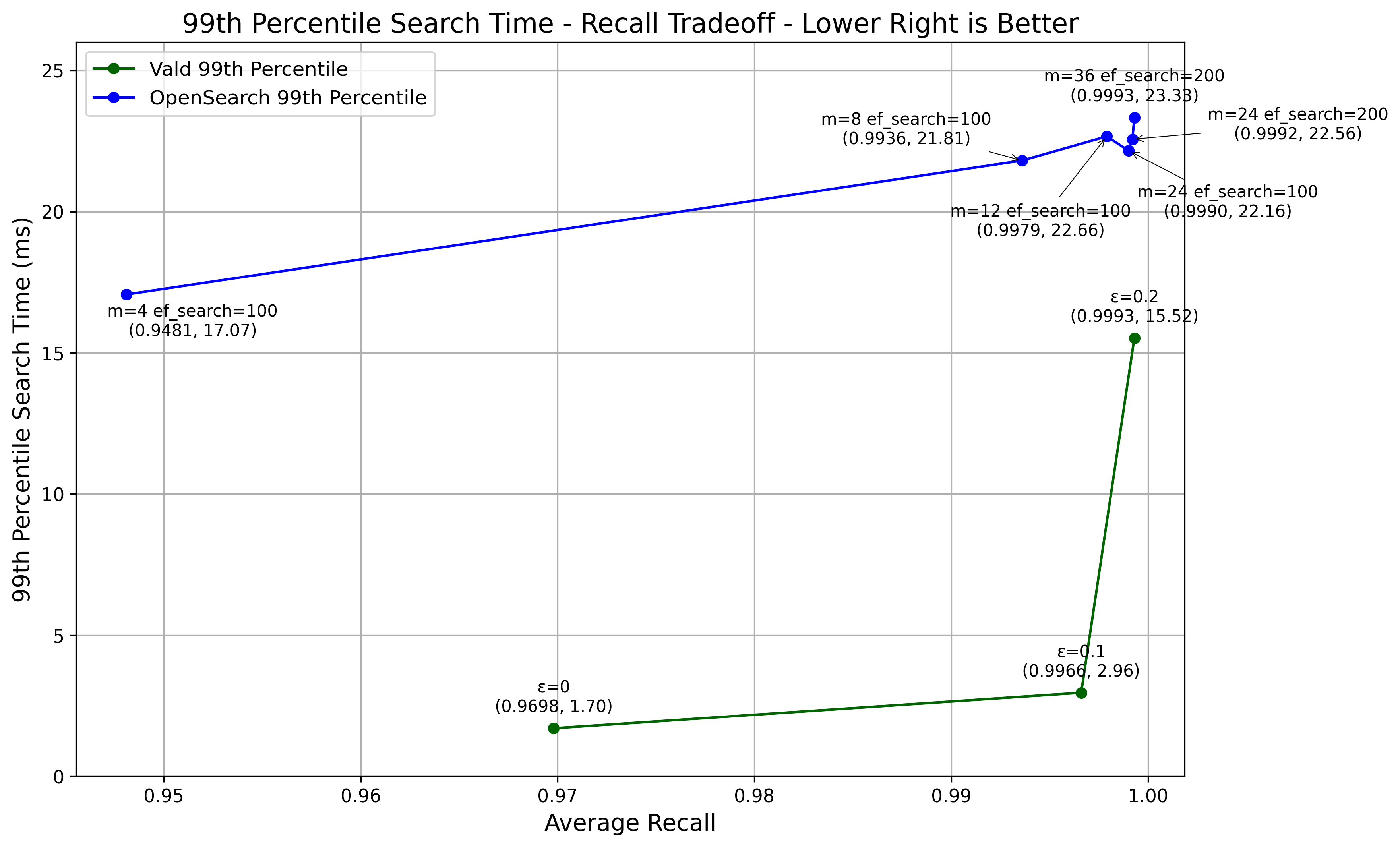
Valdの方がOpenSearchに比べて、同等の精度を出す場合の検索速度が速いことが分かりました。
これは、Valdがベクトル検索に特化して最適化されていることや、gRPC通信を利用していることが影響していると考えられます。
OpenSearchのような全文検索エンジンでもベクトル検索はできますが、高精度でベクトル検索のみをする場合は、Valdなどのベクトル検索エンジンが有利だと言えそうです。
ただし、データセットによっては結果が異なることもあるので注意が必要です。
まとめ
各検索手法の特徴
これまでの内容を踏まえ、まずは検索手法ごとの特徴を整理します。
| 検索手法 | 特徴 |
|---|---|
| ベクトル検索 | 非構造化データでもベクトル化すれば検索可能 - 画像、音声、動画などの検索やレコ��メンデーションの分野に適用可能 直感的に類似性を扱える - テキストを意味ベクトルとして扱うことで、意味を考慮した曖昧検索にも対応可能 - あるユーザーに対し、似たユーザーが購入した商品を推薦するレコメンドにも適用可能 |
| 全文検索 | 正確なキーワード検索に強い - 商品番号やフレーズの完全一致検索で高いパフォーマンス 意味を考慮しない曖昧検索が可能 - タイプミス補正や部分一致の検索などにも対応可能 |
| ハイブリッドサーチ | 多様な検索ニーズに対応可能 - 正確なキーワード検索と意味理解が両立しており、多くのケースで高精度 |
各検索エンジンのユースケース
上記を踏まえ、検索エンジン別にユースケースをまとめたいと思います。
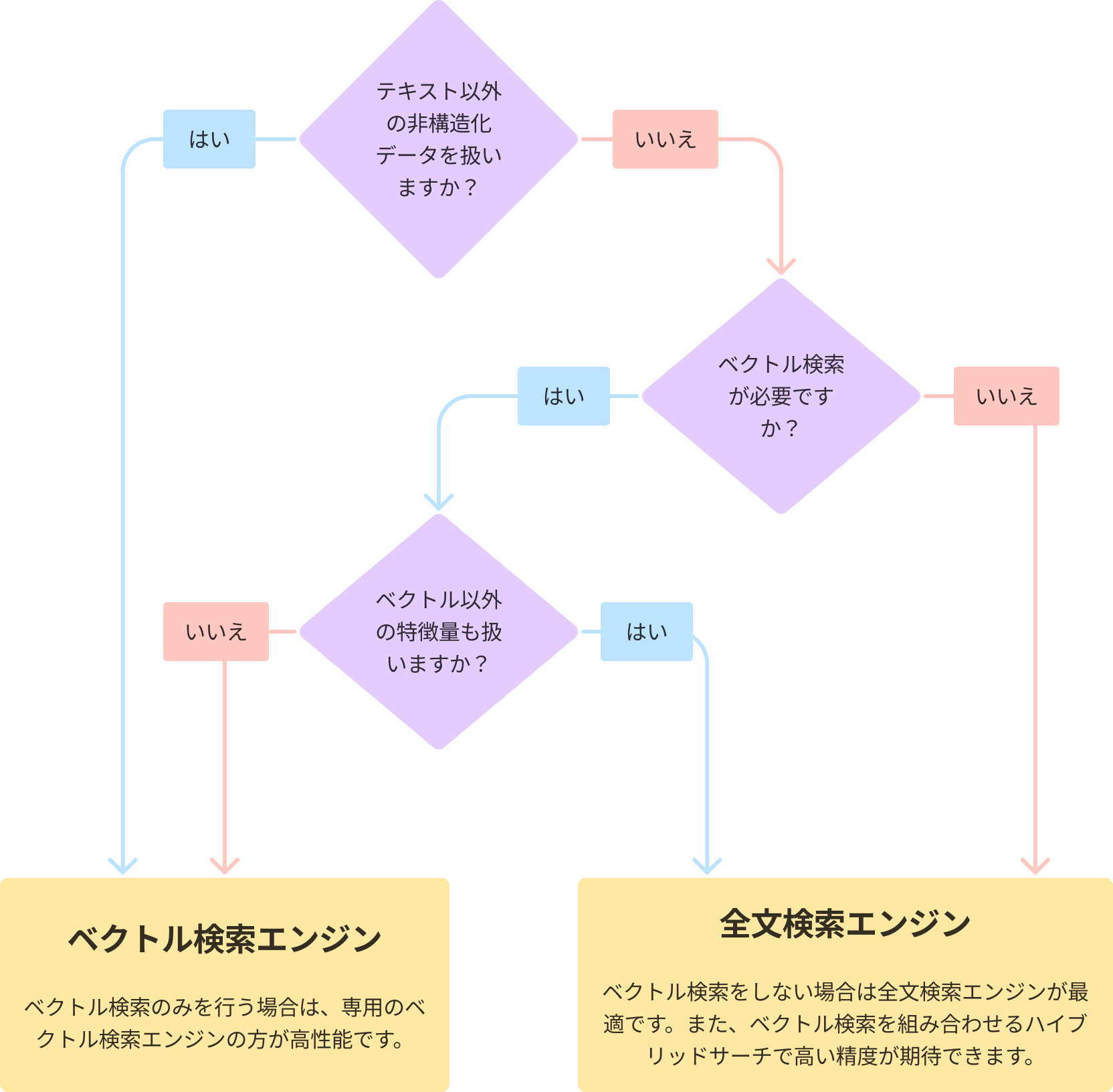
ベクトル検索エンジンが適したケース
- ベクトル検索のみで精度要件を満たせる場合
- 画像、音声、動画などの非構造化データを扱うときは、専用のベクトル検索エンジンが適しています
- 全文検索エンジンでベクトル検索をするのと比較すると、精度と速度を両立しやすく高性能です
全文検索エンジンが適したケース
- ��ベクトル検索が不要で、テキスト検索のみをする場合
- 商品番号や特定のフレーズの完全一致検索を重視するケースなどが該当します
- クエリを柔軟に変更することで全文検索のさまざまな機能を使うことができます
- テキスト検索で、全文検索と意味的な類似度検索の両方が有効な場合
- 全文検索とベクトル検索を組み合わせることで、高い精度が期待できます
- ハイブリッドサーチがプラグインとしてサポートされている全文検索エンジンを使うことで、簡単に実装できます
- 全文検索エンジンのさまざまな機能やハイブリッドサーチの方法を最適化することで、さらに精度を改善していくことができます
補足にはなりますが、全文検索エンジンだけで要件を満たせない場合は、全文検索エンジンとベクトル検索エンジンを併用するという選択肢もあります。
また、Milvusではベクトル検索エンジンだけでハイブリッドサーチをサポートするなど、これも新たな選択肢となるかもしれません。
本記事では、データセットを用いて検証を行い、各検索エンジンのユースケースをまとめました。
実際の技術選定はデータの特性やシステム要件に大きく依存します。そのため、これらを整理した上で、適切な検索手法と検索エンジンを選定することが重要です。
また、具体的な検索エンジンの選定をする際には、ANN Benchmarksなどのベンチマークを参考にすることが有用です。ただし、ベンチマークの数値は、実際の運用で得られる数値とは異なる可能性があることに注意が必要です。検索システム全体としての速度や、実際に利用するデータで同様の精度が得られるかどうかを考慮することが重要です。
したがって、これらの数値はあくまで参考値として捉え、実際に運用する構成に近い形で検証を行う必要があります。
最後に
本記事はいかがでしたか。何かお役に立てる内容があれば嬉しいです。
Valdはこれからも精力的に開発を続けていきますので、皆様のご利用やフィードバックを心からお待ちしております。
最後まで読んでいただき、ありがとうございました。
Appendix
パフォーマンス検証環境
- Vald: Kubernetes環境
- OpenSearch: Kubernetes環境
両環境は十分大きなNodeフレーバーを利用しており、同一Nodeに構築しています。データは3つのReplicaに分散させています
クラスタ構築に利用したManifestsは以下の通りです。
- Vald(v1.7.14)
kind: ValdRelease
apiVersion: vald.vdaas.org/v1
metadata:
name: vald-cluster
spec:
agent:
ngt:
dimension: 128
creation_edge_size: 20
search_edge_size: 60
minReplicas: 3
maxReplicas: 3
manager:
index:
indexer:
auto_index_duration_limit: 1m- OpenSearch(v2.18.0)
kind: OpenSearchCluster
apiVersion: opensearch.opster.io/v1
metadata:
name: my-third-cluster
spec:
security:
tls:
http:
generate: true
transport:
generate: true
perNode: true
general:
serviceName: my-third-cluster
version: 2.18.0
dashboards:
version: 2.18.0
replicas: 1
nodePools:
- component: nodes
replicas: 3
roles:
- "cluster_manager"
- "data"
persistence:
emptyDir: {}OpenSearchのIndex作成時の設定の一例は以下の通りです。ef_constructionはANN Benchmarksを参考に400に固定し、parametersのmは複数変えて検証しています。
{
"settings": {
"index": {
"knn": true,
"number_of_shards": 3,
"number_of_replicas": 3,
"refresh_interval": "1m"
}
},
"mappings": {
"properties": {
"vector": {
"type": "knn_vector",
"dimension": 128,
"space_type": "l2",
"method": {
"name": "hnsw",
"engine": "nmslib",
"parameters": {
"m": 24,
"ef_construction": 400
}
}
}
}
}
}検索時のクエリの一例は以下の通りです。ef_searchは複数変えて検証しています。
search_query = {
"size": 10,
"query": {
"knn": {
"vector": {
"vector": vector,
"k": 10,
"method_parameters": {
"ef_search": 200
}
}
}
}
}

