LINEヤフーでは、最新の知見を業務に取り入れるべく論文の社内共有会や社外研究会への参加などを積極的に行っています。
その一環として、業務に関連するトピックを扱う海外カンファレンスに社員が会社負担で参加できる制度があります。
その制度を利用して、2024年8月25日〜29日にバルセロナ(スペイン)で開催された国際会議KDD2024に聴講参加してきましたので、その内容について報告します。
目次
- KDDの概要:高濱
- 気になった論文・セッションの紹介
- 推薦システムへのLLM活用:山口
- 推薦システムの多様性やバイアスの改善:高濱
- 推薦システム研究の動向と新アプローチ:田邊
- サービス横断のデータや特徴量:松井
- 広告関連技術とA/Bテストの新たな視点:小川
- まとめ
- Appendix(学会の雰囲気)
KDDの概要
KDDは "ACM SIGKDD Conference on Knowledge Discovery and Data Mining" の略で、機械学習やデータマイニングをテーマとした論文の発表を行う国際会議です。
KDDでは推薦や広告など企業活動に関連したトピックも多く、実際にビジネス面での貢献にフォーカスしたセッション等もあり、LINEヤフーでの業務にも関連が深いです。
2024年は第30回目となり、スペインのバルセロナで開催されました。
基本的な情報
- 開催日程
- Workshop:8/25, 8/26
- 本会議:8/27 ~ 8/29
- 会場:Centre de Convencions Internacional de Barcelona
- 参加者数:2,312人
- スポンサー数:33
- プラチナスポンサーはZhipu AI(中国)
- そのほかにはAlibaba Cloud, Apple, Google, Bloomberg, Amazon science, Baidu, Pinterestなど
- 採択率
- Research Track:提出数2,046、採択数411(採択率20.1%)
- Applied Data Science Track:提出数738、採択数151(採択率20.5%)
ビジネスへの適用を念頭に置いた論文が多い印象で、発表者と聴講者ともに企業に所属する参加者が目立っていました。
発表者やスポンサーに関しては特に中国系の企業・研究者が多かったと感じました。
会場はバルセロナの中心地から少し離れたエリアにあり、比較的治安も良くてショッピングモールや海が近かったので非常に良い立地でした。

各セッションについて
本会議のセッションに関しては大きく2種類に分かれているのが特徴です。
- Research Track
- 理論的な研究や、新規性のあるモデル、アルゴリズムの提案に関する論文
- Applied Data Science Track (ADS)
- 機械学習やデータサイエンスの実応用に関するシステム設計や実装に関する論文
- 実際にビジネスに適用されて成果を出したり重要な知見が得られていることが重視される(とOpening Sessionで言われていました)
Research Trackに関するWord Cloudでは「Graph」「Recommendation」「Time-series」「Efficient」「Federated」などのワードが目立っていました。
聴講していても、生成AI系の発表とGraphを使ったNNモデルの発表が多かったと感じました。

また、KDDでは採��択された論文全てにOral発表の機会が与えられているのが特徴でした。
一方で採択論文のポスターセッションもあり、そこで著者に直接話を聞くこともできました。
Workshopではさまざまなトピックの多様なセッションが開催されています。
1つのworkshopは4時間ほどで、Keynote(招待公演)やpanel discussion、数件の論文発表が行われます。
有名なものだとAdKDDであったり、近年の傾向を反映してLLM関連のWorkshopも複数開催されていました。
他にも例えばFragile Earthという、持続可能な社会の実現にMLを活用するという挑戦的なworkshopもあり興味深かったです。
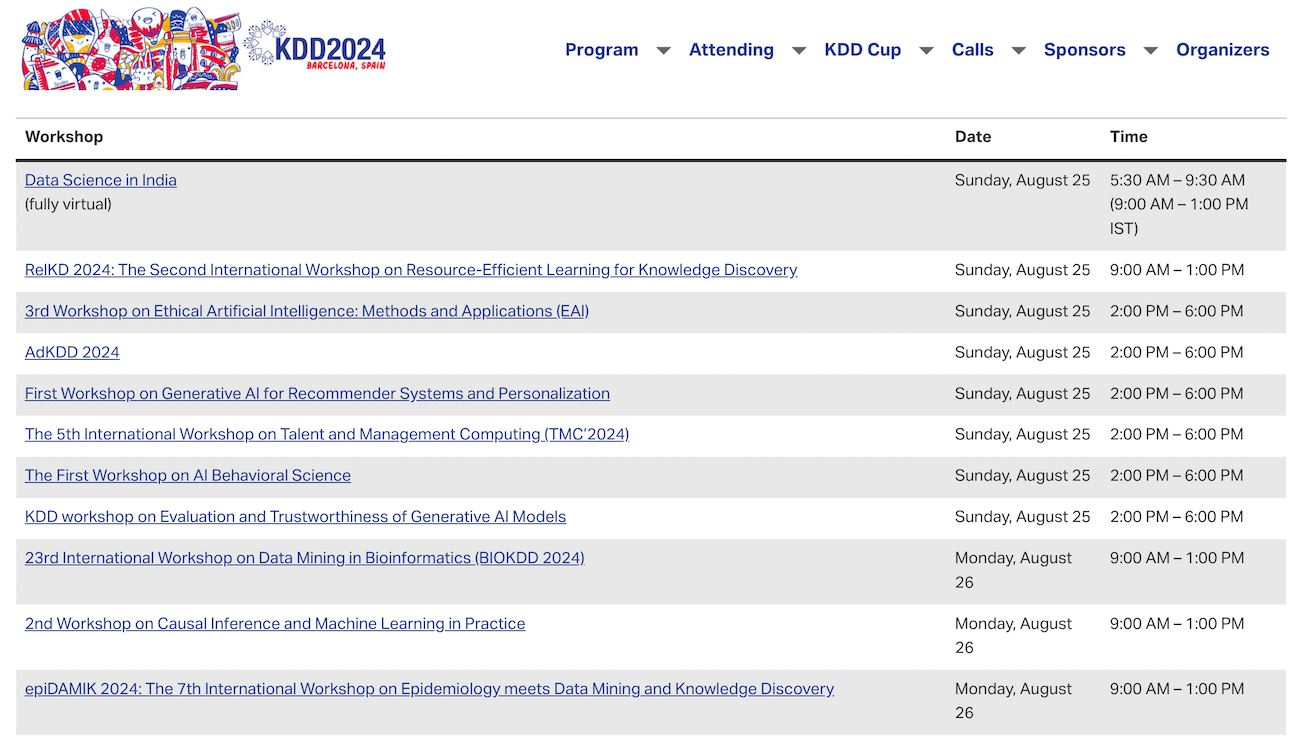
さらに、付随するコンペティションチャレンジであるKDD Cupも有名で、今年は3種類のタスクがありました。
- OAG-challenge: 学術データに対する知識グラフ構築のタスク。誤った情報の訂正やQuestion Answeringを含む。
- Meta : RAGシステムを使った質問応答の性能を競う。
- Amazon : LLMを使ったオンラインショッピングの支援。
本会議やWorkshopは10個前後のセッションが並行して開催されており、これ以外にもさまざまなプログラムがあったため、特に興味のあるものを選んで聴講する必要がありました。
これ以降では、参加した社員それぞれの視点から、印象に残った論文やセッションをテーマごとに絞って紹介します。
Topic: 推薦システムへのLLM活用
機械学習エンジニアの山口です。業務ではコマース向けの推薦システムを開発しています。今回の聴講では、言語モデルを活用した推薦の発表が多くありました。個人的に発表を聞いて面白かったものをピックアップして紹介します。
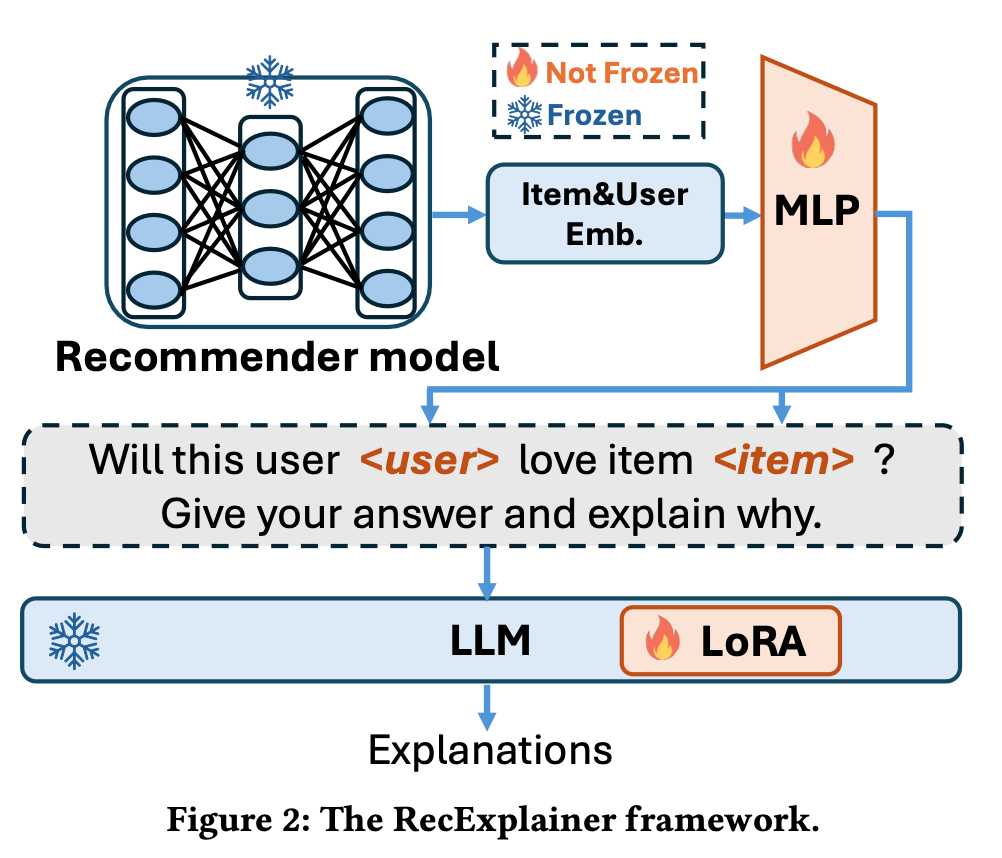
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models
背景
近年の推薦システムでは、ItemやUserのEmbeddingから推薦を生成していますが、その推論根拠はブラックボックスでした。
本研究では、LLMの理解と推論能力を活用し、推論根拠を自然言語で生成するタスクに取り組んでいます。
提案手法
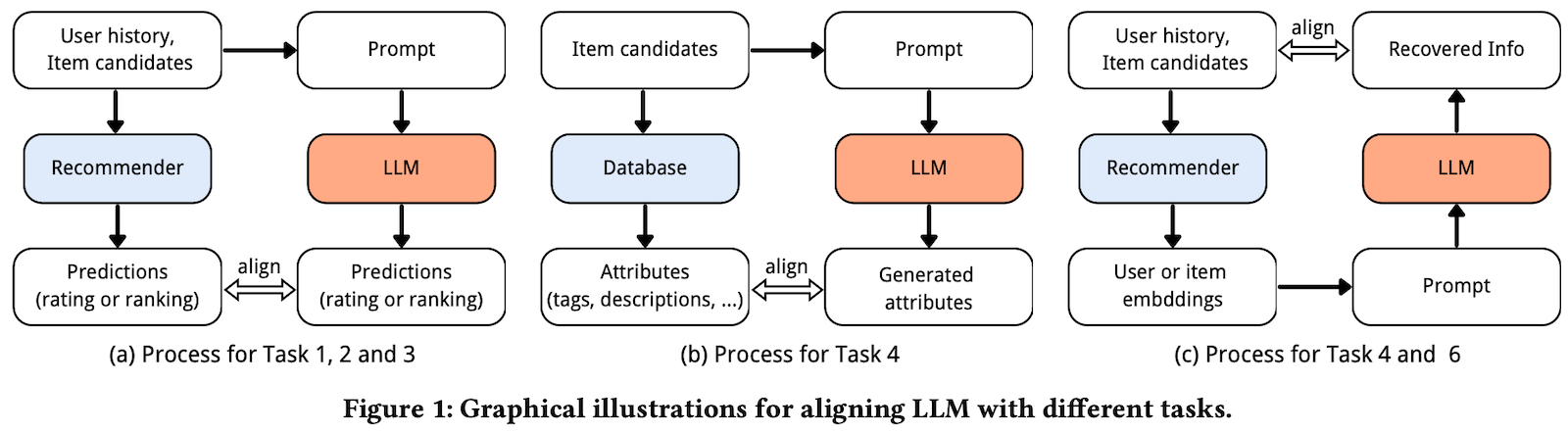
本研究では、RecExplainerというフレームワークを提案しています。この手法の特徴は、ブラックボックスな推薦モデルの出力を模倣するようにLLMをアライメントすることです。具体的には、以下の3つのアライメント方法を提案しています。
-
Behavior alignment: ターゲット推薦モデルの入出力結果をエミュレートするようにLLMをアライメントします。主にRetrieval、Rankingアライメントを行います。
-
Intention alignment: ターゲット推薦モデルの内部状態(Embedding, Hidden-states)を直接参照し、LLM�はEmbeddingを直接解釈できるようにアライメントします。Item, Userの入力はTextではなく、Embeddingに変わります。アライメントでは、Item, User EmbeddingをTokenへ変換するMLPを追加で学習します。
-
Hybrid alignment: BehaviorとIntentionの両方のアライメントを行います。入力にテキスト情報と推薦モデルのEmbedding両方を与えることで表現力を高めます。
実験
実験は、Video Games(Amazon)、Movies & TV(Amazon)、Steamの3つのデータセットを使用し、LLMはvicuna-v1.3-7bを用いて行われました。アライメントを行わない場合やIn-context learning(ICL)と比較しています。
- Alignment Effect: Hit ratio、NDCGの指標を比較すると、RecExplainerが最も性能が高く、オリジナルの推薦モデルを模倣できていること、アライメントの重要性を示しています。
- Explanation Generation Ability: RecExplainer Hybridが最良の説明品質を持ち、Intention alignmentのみでは性能が下がるものの、Hybridにすることで性能向上が確認されました。
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
背景
BERTやLLMを用いた推薦システムは多く提案されていますが、従来の強調フィルタリング(CF; Collaborative Filtering)ベースの手法がログが十分に集まっている(Warm Item)場合に依然として高性能であり、LLMはCold Item (ログが十分に落ちていないitem)でしか効果的に活用できないという問題がありました。
提案手法
本研究では、CFで得られた知識を用いてLLMをアライメントし、Warm ItemとCold Itemの両方に対応できる推薦システムを提案しています。この手法は、CFモデリングの手法によらず実装可能であり(Model-agnostic)、LLMのファインチューニングも不要で、比較的低コストで実現できます。
提案手法は2段階のLLMアライメントを採用しています。
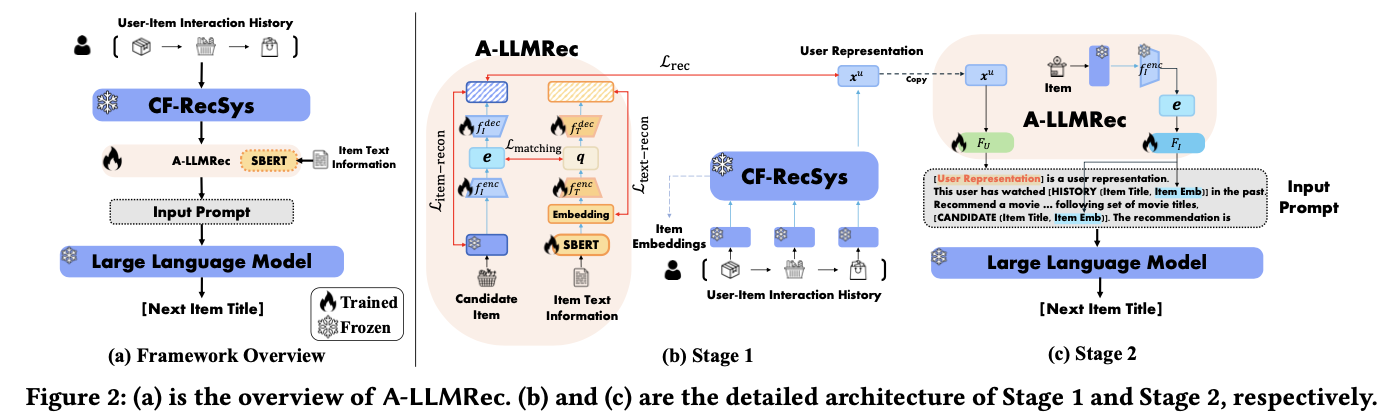
- Stage-1: CFで作成したItem EmbeddingとItem TextをSBERTでエンコードし、Auto-Encoderで潜在空間にマッピングしてJoint Embeddingを獲得します。
- Stage-2: Stage-1で得たJoint EmbeddingをMLPでLLMのToken空間に変換し、CF情報を活用するためのプロンプト設計を行います。
実験
実験は、AmazonのMovies and TV、Video Games、Beauty、Toysのデータセットを用い、LLMとしてopt-6.7b、CF-RecSysモデルとしてSASRecを使用して行われました。
- 性能比較: LLM-OnlyやTALLRecといったLLMベースの手法がCFベースに比べてスコアを落としている中、提案手法(A-LLMRec)はスコアを向上させ、CF知識でアライメントを行う本手法の有用性が確認されました。
- Cold/Warm Item での評価: Cold Itemでは大幅にスコアを改善し、Warm ItemでもCF(SASRec)と同等以上のスコアを達成。どちらの条件でも高性能を示し、LLM活用によるCold Itemの改善とCFが強いWarm Itemの推薦を両立できていることが示されました。
感想
1つ目の研究について、モデリング手法は LLM as a surrogate model ��としての利用や、Intention alignment が Vision Language Model のようなマルチモーダルモデルと同様に解釈でき、面白い試みだと思いました。
2つ目の研究について、強調フィルタリング (CF) の知識を LLM へアライメントすることで、LLM の推薦性能を向上できており、とても興味深いトピックでした。また、アライメントも Prompt Tuning や Auto-Encoder の学習のみで良いため、低コストで実現可能なのも特徴的だと思います。
私の業務で取り組んでいるコマースにおける推薦システムの課題として、ユーザごとにニーズが異なることや、商品数やユーザ規模が大規模であるため、十分なパーソナライズの提供が難しい点があります。例えば、あるユーザは値段比較を重視する一方で、別のユーザは商品の探索に重点を置くことがあります。このような多様なニーズに対応するために、パーソナライズされた推薦が重要であると考えています。
本記事で紹介したLLMによる推薦モデリング手法では、LLMの得意とするパーソナライズ・説明能力だけでなく、課題であった推薦精度も高く維持されていることが示されています。
推薦向けのLLMを構築することで、推薦リストの生成や説明の付与だけでなく、対話形式での推薦への応用も視野に入るのではないかと思います。
運用面に関しては、今回紹介した論文ではどちらも7Bクラスであり、推薦に限定すれば実現可能性は高いのではないかと考えています。
今後もこのトピックに関して動向を注視し、可能であれば、実サービスへの活用を検討していきたいと思います。
Topic: 推薦システムの多様�性やバイアスの改善
機械学習エンジニアの高濱です。私は業務で推薦システムの実装に携わっており、特に推薦の多様性やバイアスの除去といったテーマに関心があります。
推薦システムはユーザーの興味に近いアイテムを提示してより良い体験を提供できる魅力的なツールである反面、提示するアイテムが人気なものや一部のカテゴリに偏っていると、逆にユーザーの満足度を下げてしまったり、誤った印象を与えてしまったりするおそれがあります。
ここではそういった問題を解決するための研究で気になったものをいくつか紹介します。
Trinity: Syncretizing Multi-/Long-Tail/Long-Term Interests All in One
背景
中国国内でのTikTokにあたるアプリ「Douyin」の推薦システムを対象とした、ByteDanceによる発表です。
一般に大規模推薦システムでは、人気のあるアイテムはもちろん、それ以外に以下の3パターンを提示できることが求められます。
- Multi Interest:ユーザーが興味を持つ複数のトピック
- Long-tail Interest:少数のユーザーだけが興味を持つマイナーなトピック
- Long-term Interest:ユーザーの長期的、継続的な興味に関連するトピック
Douyinはオンラインの推薦モデルを採用していますが、直近の履歴を重視し過ぎて過去の履歴を忘却しやすい(Interest Amnesia Problem)という問題点があり、上の3パターンをうまく提示できていませんでした。
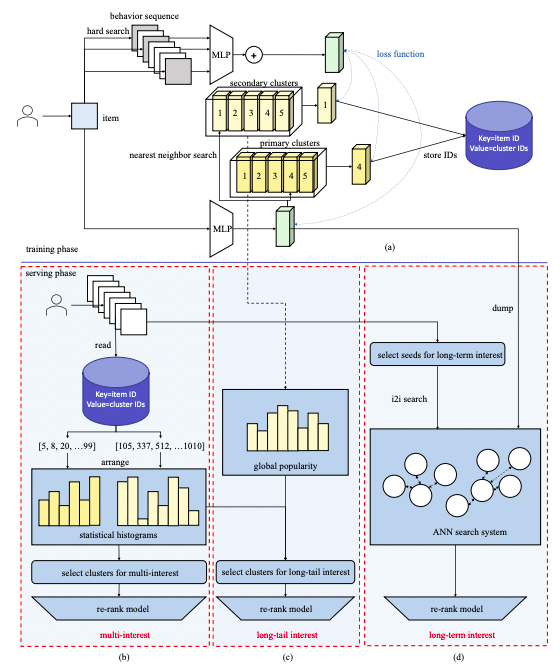
この研究では、アイテムの多様性を重視した"Trinity"というモデルを別途作成し、現行のオンラインモデルを補完することを提案しました。
提案手法
提案手法"Trinity"では、ユーザーログを使ってアイテムのcluster IDを学習します。この際、大分類と小分類の2段階のクラスタラベルを付けます。
インタラクションログをcluster IDごとに数え上げると、ユーザーごとにヒストグラムが出来上がります。
同じ大クラスターから一つしか選ばないという制約のもとで小クラスタを複数選び取り、それに属するアイテムを後段のre-rankingモデルに追加します。これによってMulti-interestを考慮できます。
さらに、globalなヒストグラムからまずログの少ないクラスターを特定し、それらにユーザーが興味を持っているならアイテムを追加します。これによりLong-tail interestも考慮できます。
またヒストグラムを集計するのは非常に軽量なため、長期間のログを考慮でき、Long-term interestも考慮できるのです。
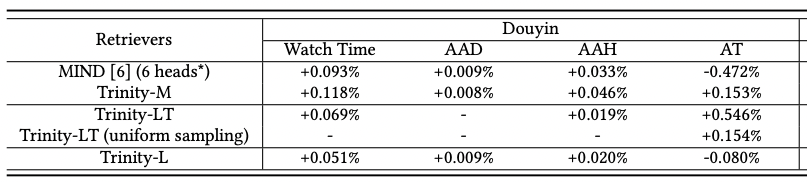
実験
Douyinでのオンラインテストでは、AAH(Average Active Hours)、AT(Average Tags / 消費されたユニークタグ数)などを評価し、視聴時間と多様性の指標がどちらも向上しました。
特に、Multi-interestモジュールがヘビーユーザーの指標を特に改善することがわかりました。
感想
いわゆるバズっている人気アイテムだけが推薦に表示されて個々人の興味が反映されない、というのは非常に身近な課題でどの推薦サービスにも無関係ではないと思います。
この研究では「何を反映させたいか」という3種類の課題を明示してそれぞれに対処しており明快でした。
ヒストグラム集計をベースにした比較的シンプルな手法で、既存の推薦モデルを持っている場合でも導入しやすいメリットがあると感じます。
Popularity-Aware Alignment and Contrast for Mitigating Popularity Bias
背景
一般に推薦システムはユーザーやアイテムのEmbeddingを作ってスコアリングに活用します。
しかし、あまり人気のないLong-tailなアイテムについては、教師情報が少ないこともあって性能の良いEmbeddingを作成するのが難しいです。
例えば、マイナーアイテムは一部のユーザーのログにしか含まれないため、そのユーザーのembeddingに適応し過ぎて過学習する恐れがあります。
また、学習が進むにつれて人気アイテムはユーザーembeddingの近くに、マイナーアイテムは遠くに配置されてしまい、分布が分かれてしまう問題が考えられます。
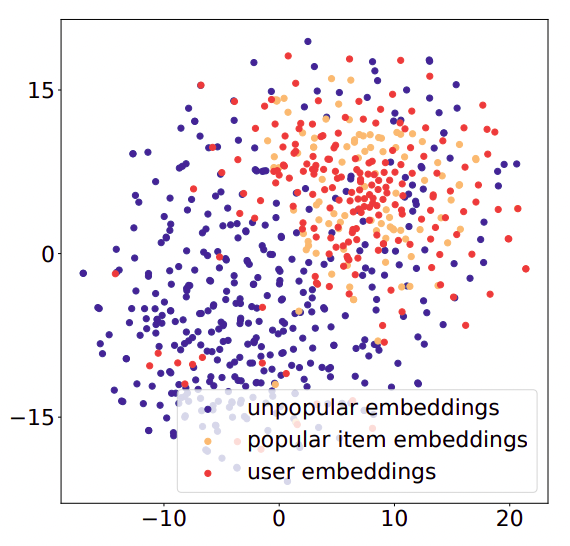
Contrastive Learning(対照学習)は、positive sampleとnegative sampleの距離を大きくする損失(InfoNCE lossなど)によって学習しますが、一様あるいは人気度で重み付けしたnegative samplingを使うと、やはりpopular/unpopularアイテムの分離を引き起こしてしまうことが指摘されています。
提案手法
提案手法のPAACでは、Popularity Biasを軽減する改善��を加えたContrastive Learning手法を提案しています。
- Supervised Alignment Module: Long-tailアイテムの学習データを増やすために、同じユーザーのログにあるpopular-unpopular itemのembeddingが近くなるようにする損失を追加しています。
- Re-weighting Contrast Module: popular/unpopularアイテムが分離してしまうのを防ぐため、バッチ内で両者を分離してそれぞれで対照学習の損失を計算します。
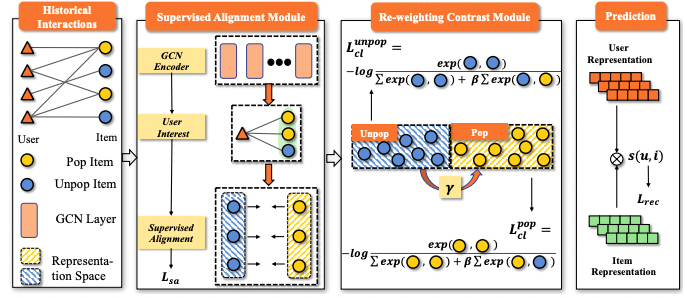
実験
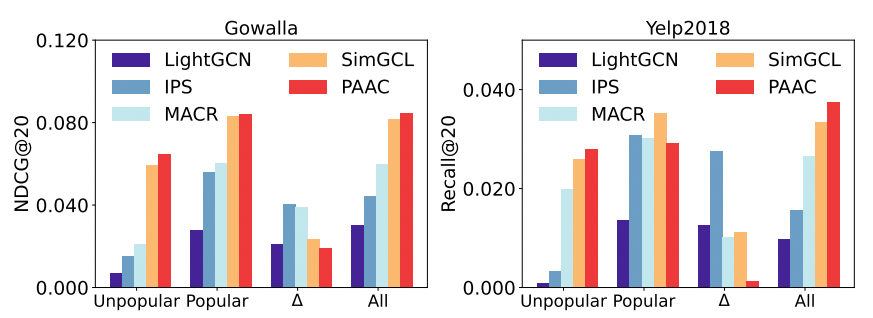
実験ではAmazon-bookやYelp2028などいくつかの公開データセットでの評価でrecallやndcgが向上しました。
また比較手法と比べて、Long-tailなアイテムに対する性能の劣化(図のΔの部分)も小さくなり、特にマイナーアイテムに対する性能改善が達成されていました。
感想
Contrastive Learningにおいてlong-tailなアイテムの性能が十分に考慮されていない課題に取り組んでおり、こちらも推薦の品質に影響する問題です。
実験では実際にlong-tailなアイテムの性能劣化が抑えられていることが示されていてよかったですが、実サービスのオンラインテストでもどの程度の効果があるのかは気になります。
Contextual Distillation Model for Diversified Recommendation
背景
中国の動画配信サービスを運営している快手による�発表です。
推薦リストに含まれるアイテムの多様性は、ユーザーの満足度を高めたり新たな発見を提供したりするために重要です。
アイテム同士の類似度を計算し多様性を高めるリランキング手法として、MMR(Maximal Marginal Relevance)やDPP(Determinantal Point Process)などが知られています。
ただしこれらはアイテム数が増えると計算量が増大する課題があります(通常のMMRでは、N個の候補からK個を選ぶとき計算量はO(N K^2) になります)。
これを高速化することで、候補アイテム数が多い推薦システム前段にも多様性モジュールを追加し、推薦性能を上げたいというのがモチベーションです。
提案手法
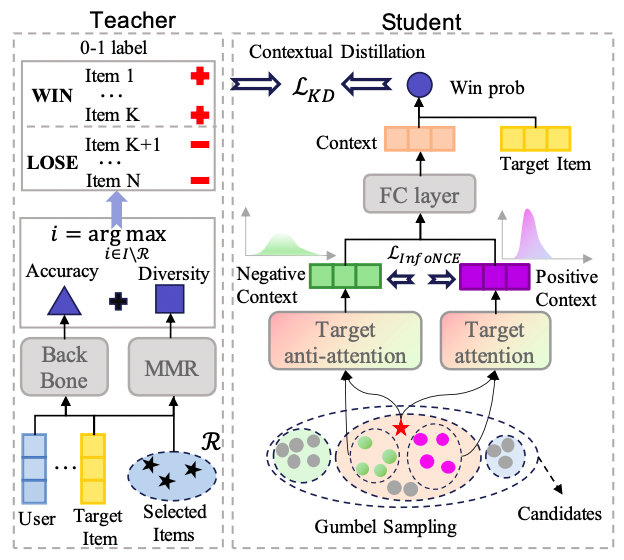
提案手法CDMは蒸留フレームワークです。
Teacherモデルは通常のMMRで、入力として候補アイテムの集合、出力としてrerankの結果選ばれたアイテムのセットを提供します。
Studentモデルは、targetアイテムとcontext(他の候補アイテム集合)を入力とし、それがrerankで選ばれる確率を出力するモデルです。
候補アイテム数が多い場合全てを入力するのは現実的ではないため、候補アイテムの分布を見てtargetに近いアイテムセットと遠いアイテムセットをそれぞれサンプリングしてcontextとします。
それらについてattentionモデルとInfoNCE lossを使ってcontext embeddingを得たあと、targetアイテムのembeddingと内積を取ってモデルの予測スコアとします。
モデルの複雑さにもよりますが、計算量は単にアイテム数に比例するのでスケーラブルです。
また、MMR以外の他の多様化アルゴリズム(DPPなど)にも使えるメリットもあります。
実験
オンラインのA/B testでは、快手の2つのアプリケーションの推薦ページで比較し、多様性モジュールがない場合と比較して視聴時間とコンテンツのカテゴリ多様性が両方増加しました。

感想
MMRやDPPは多様性を改善できる一方計算量が大きいことが知られており、高速化のための既存研究もありますが、蒸留を使って再現する手法は興味深かったです。
MMRの結果を再現することが保証されているわけではないので、どの程度制度良いStudentモデルができるのか、計算時間が実際どの程度かかるのかは気になるところです。
Topic: 推薦システム研究の動向と新アプローチ
機械学習エンジニアの田邊です。私は普段、ML Batch APIという旧LINEに関連するサービスで広く使われているレコメンドシステムの開発やLINEスタンプのレコメンドに関する開発を行っています。
ここでは、KDD 2024のResearch Trackで採択されていた推薦システム関連の研究を紹介していきます。
まず最初に、Best Student Paper Awardを獲得したDataset Regeneration for Sequential Recommendationという論文を紹介します。
続いて、AdKDDというWorkshopで発表された Trigger Relevancy and Diversity Inefficiency with Dual-Phase Synergistic Attention in Shopee Recommendation Ads System を紹介します。
最後に、参加した推薦系のセッションについてサマリーして紹介します。
Dataset Regeneration for Sequential Recommendation
背景
この研究では、Sequential Recommendationの文脈において、理想的な学習データセットを構築するためのフレームワークを提案、実験によってレコメンドの研究でよく利用されている4つのデータセットにおいて性能が大幅に向上することを確認しています。
従来までのSequential Recommendationの研究では固定されたデータセットに基づいて効果的なモデルを開発する(モデル中心のパラダイム)のが一般的ですが、このような方法ではデータに内在する潜在的な品質問題や欠陥を見落としている可能性があります。
この研究では、元のデータセットを使用して情報に富んだ汎用性の高いデータセットを再生成します(データ中心のパラダイム)。具体的には、元のデータセット が与えられた時に、従来の方法では、 を満たすターゲットモデルを学習することを目指していますが、この研究では、 を満たす情報に富んだ一般化可能なデータセット を学習することを目指しています。ここでは、 に基づくターゲットモデル は に基づく よりも学習しやすいものになります。
提案手法
学習データ開発の問題に対処するためにDR4SRというフレームワークを提案しています。このフレームワークは、事前学習タスク、多様性推進リジェネレータ、ハイブリッドな推論戦略の3つのコンポーネントによって構成されています。
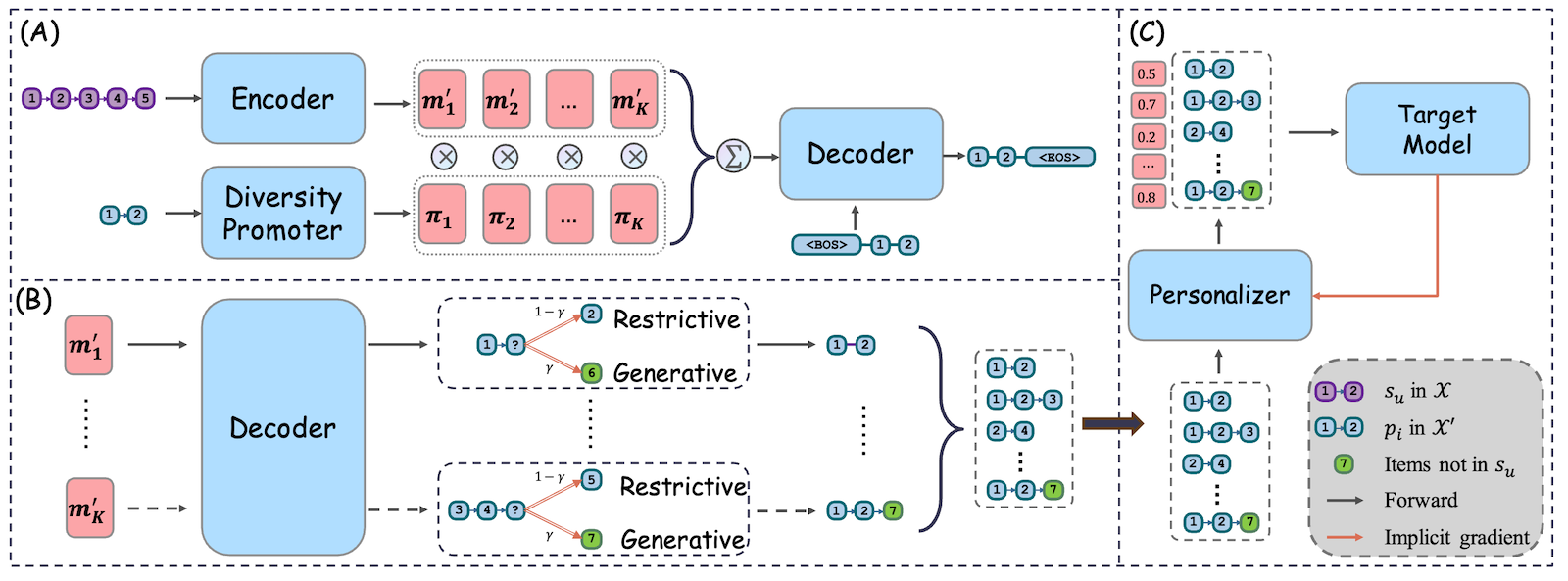
- 事前学習タスク:この後に説明する多様性推進理ジェネレータの学習のガイドするために定義されます。
- 多様性推進リジェネレータ:オリジナルのデータセット内のシーケンスの表現を取得するエンコーダ、エンコーダからのシーケンス表現を元にデータパターンを再生成するデコーダ、一対多のマッピング関係を捉えるdiversity promoterの3つのモジュールによって構成されています。
- ハイブリッドな推論戦略:リジェネレータを使用して新しいデータセットを再生成します。
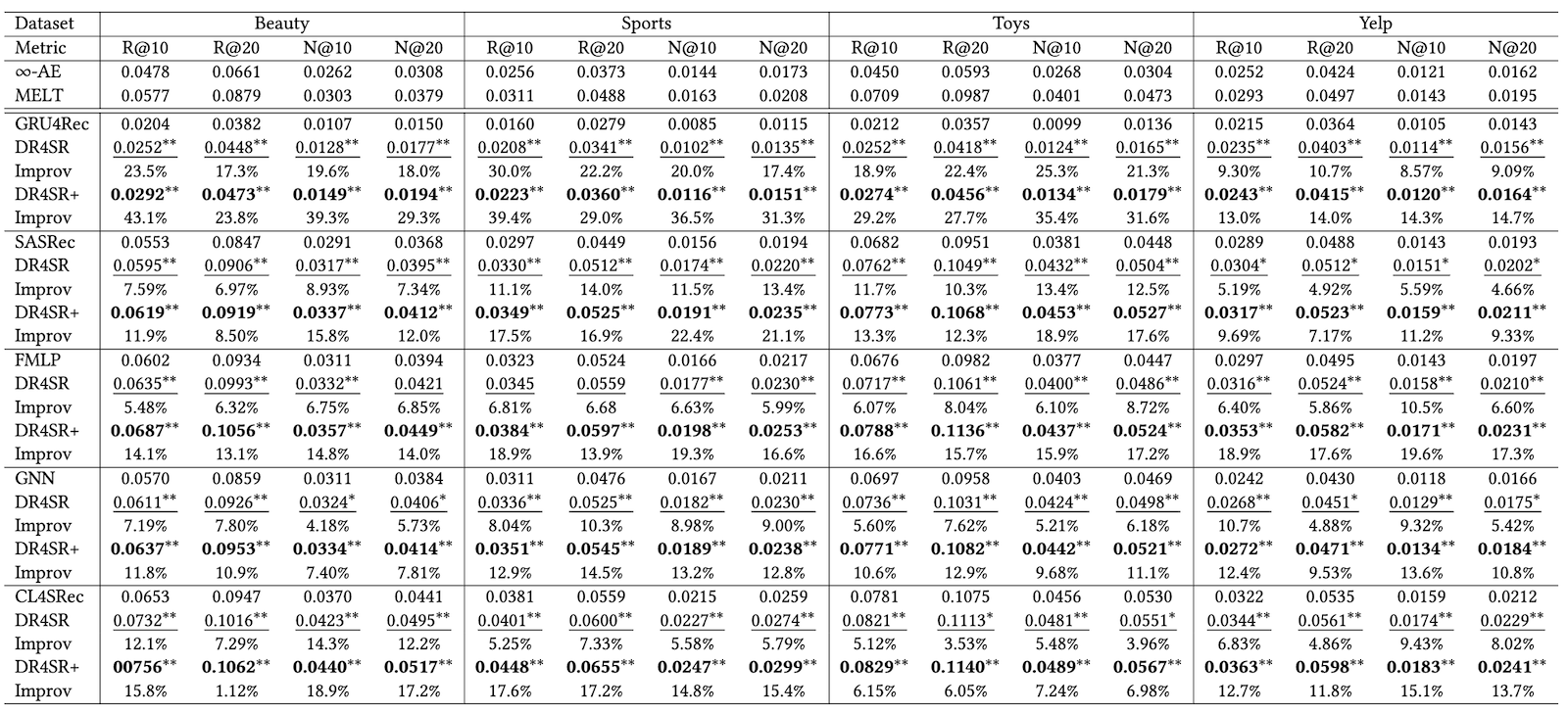
上の表は各ターゲットモデルのパフォーマンスを提案手法であるDR4SR、DR4SR+のバリアントと比較したものです。
これによると、全てのデータセットとターゲットモデルにおいて、DR4SRはかなりの性能向上をしていることからDR4SRは情報量が多く一般化可能なデータセットを再生成できることを示しています。さらに、この結果によってデータ中心のパラダイムとモデル中心の��パラダイムに補完性があることがわかります。
感想
データセットに何らかの処理を加える手法は画像データなどの文脈では一般的ですが、この研究が扱っているような推薦データセットを対象としている研究は珍しいと思いました。実装はかなり複雑になってしまいそうですが、コンペティションなどの精度の向上を重視したいシチュエーションなどで利用してみたいと思いました。
Trigger Relevancy and Diversity Inefficiency with Dual-Phase Synergistic Attention in Shopee Recommendation Ads System
この論文はAdKDDという広告に関するworkshopで発表された、ECプラットフォームを運営しているShopeeによる研究です。広告以外の推薦にも使用することができ、着眼点が非常に面白いものであったため紹介したいと思います。
Trigger-Induced Recommendation (TIR)というシナリオにおいて、従来まではトリガーアイテムに関連するアイテムを表示することが一般的でしたが、トリガーアイテムに関連しないアイテムも多くユーザーが興味を持っていることを発見し、トリガーアイテムに関連するアイテムに加えてトリガーアイテムに関連しないアイテムを混ぜてパーソナライズすることでCTRや収益の向上を実現させました。
背景
TIRは、任意のアイテムカード(トリガーアイテム)をユーザーがクリックすると、ユーザーはそのアイテムの詳細情報が表示されるページ(PDP: Product Detail Page)に移動、PDPページの中にYMAL (You May Also Like)という広告推薦セクションがあり、YMALにあるアイテムをユーザーがクリック/購入することで収益をもたら��すという最近業界や研究分野から注目を集めている推薦シナリオになります。
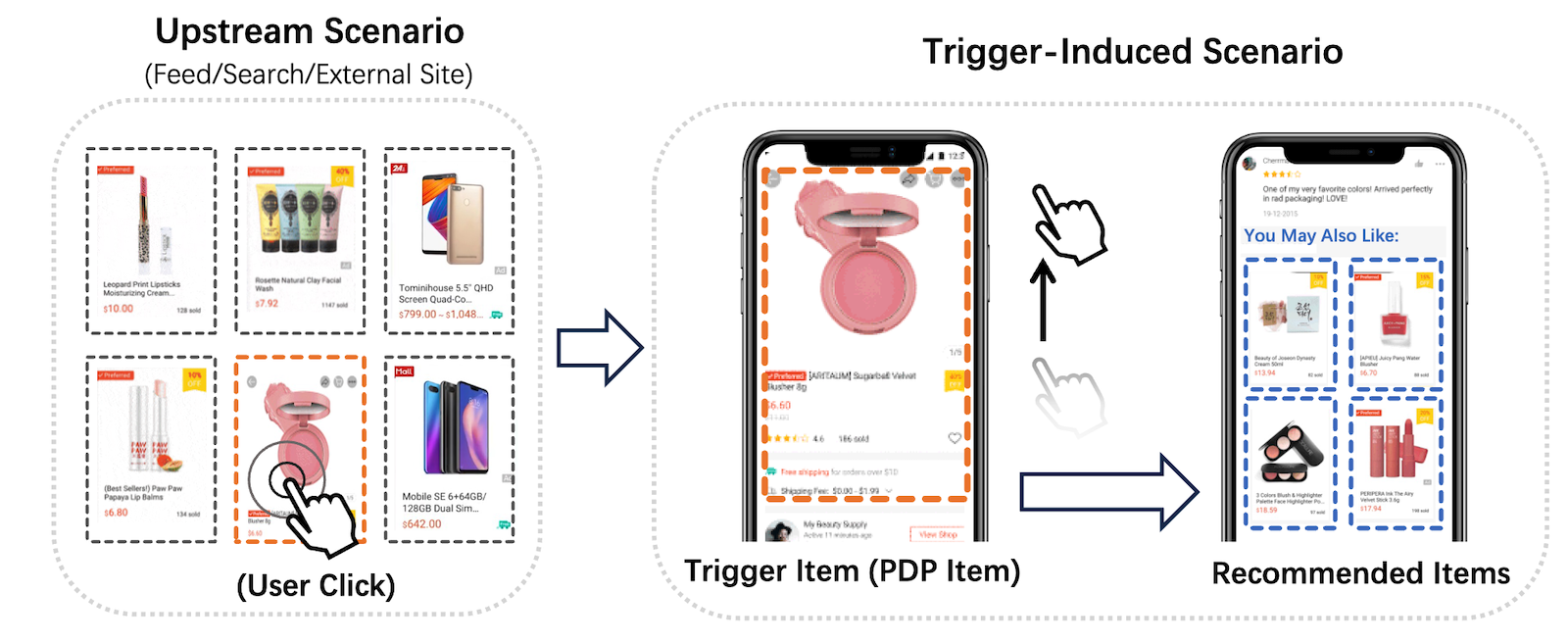
従来のTIRシナリオでは、YMALセクションにトリガーアイテムに関連するものだけを出すのが一般的でした。しかし、ログを分析すると、トリガーアイテムに関連しないアイテム(人気アイテムやユーザーが過去に興味を持ったアイテムの関連アイテム)にもユーザーが興味を示していることがわかりました。この論文では、トリガーアイテムに関連するアイテムをtrigger-relevantアイテム、トリガーアイテムに関連しないアイテムをtrigger-diverseアイテムと表記しています。
ユーザーはtrigger-diverseアイテムに興味を示すことがあるため、従来手法のようなYMALセクションにtrigger-relevantアイテムだけを出す方法には非効率性があることがわかります。この研究ではこのような非効率性をTRDI (Trigger-Relevancy and Trigger-Diversity Imbalance)と定義しています。
提案手法
個々のユーザーごとのTRDIに対処するアテンションフェーズと個々のトリガーアイテムごとのTRDIに対処するアテンションフェーズの2つのフェーズからなる手法であるDPSA (Dual-Phase Synergistic Attention)を提案しています。
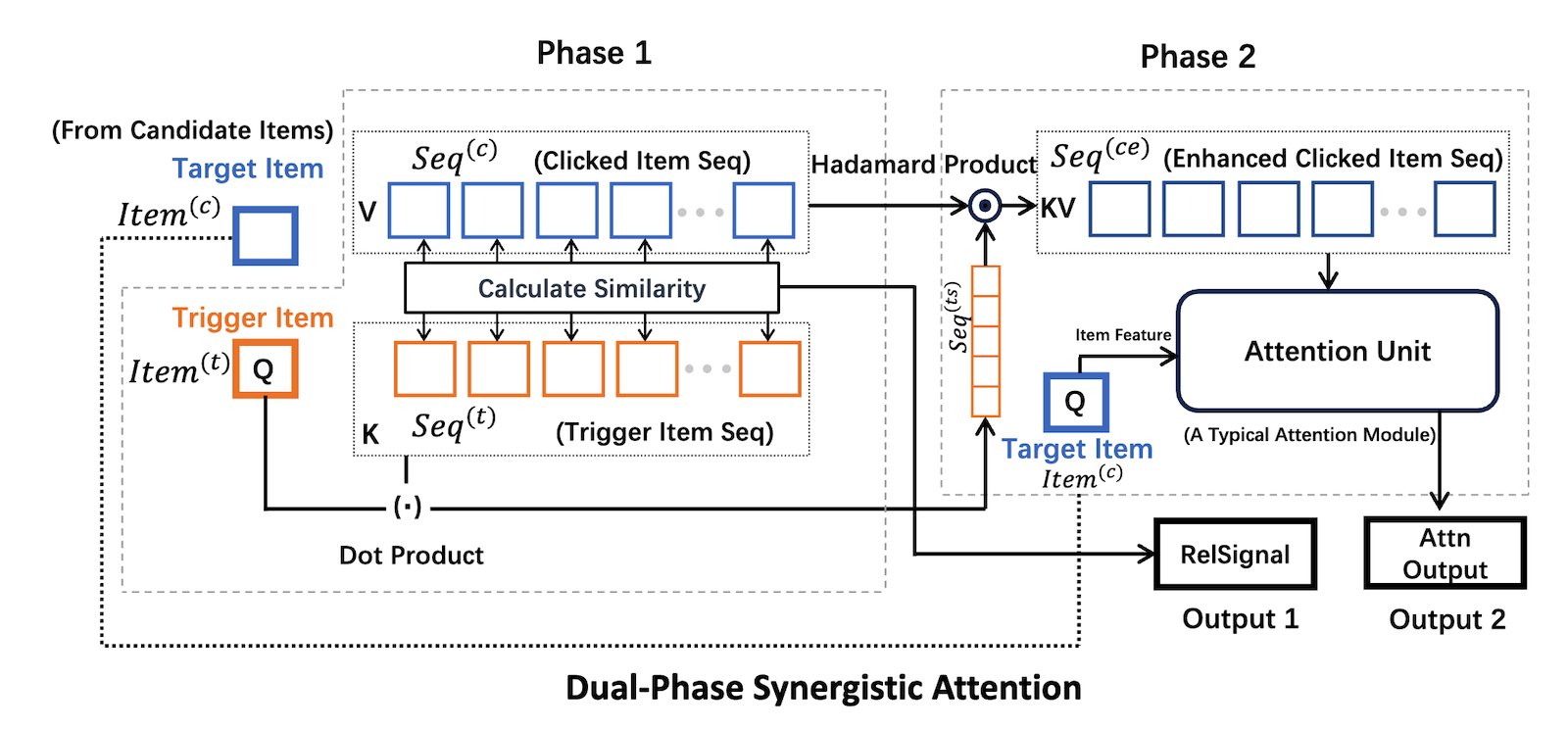
この手法ではフェーズ1にてユーザーごとのTRDIに対処し、フェーズ2にてトリガーアイテムごとのTRDIに対処しています。
フェーズ1では、クリックされたアイテムシーケンスとそのトリガーアイテムのシーケンスから、trigger-relevant / trigger-diverseに対するユーザーの好みの度合いを表すRelSignalを求めます。
フェーズ2では、強化したユーザーのクリックシーケンスと候補アイテムを用いてユーザーが次にクリックする可能性の高いアイテムを予測するためのAttention Outputを計算します。
実験
提案手法の検証はOffline test、Online A/B test for 7-days、Online Post Analysisの3種類の環境で行われました。ここではOnline A/B testの結果を紹介します。

上の表はOnline A/B testの結果を表しています。この表からすべての主要な指標でベースラインを大幅に上回っていることがわかります。特に、GMVがRevenueよりも大幅に改善されたために販売者のROIが大幅に向上、これによりShopeeの広告サービスが販売者にとってより効率的になり、プラットフォームの成長と拡大に貢献する好循環を生み出す可能性が高いことが示されています。
感想
この研究は広告推薦をテーマにしてましたが、別の推薦問題にも発生しうる問題だと思いました。例えば、一般的な推薦問題の一つであるitem to itemレコメンドなどでもそのアイテムに関連したアイテムを推薦するのが一般的ですが、ここに関連アイテム以外のアイテムを入れることも有効になると考えています。ただし、バッチ推薦システムで適用しようとするとユーザー数 x アイテム数分の推薦を行う必要があり計��算量的に現実的ではないためオンライン推薦の分野に適用するのがいいと思いました。
KDD 2024のResearch Trackで発表された研究を見ていくことで、推薦システムに関する多様な研究が発表されており、新たな問題に取り組んでいる研究もあることがわかりました。推薦システムは私たちの生活に非常に身近なものであり、生活を便利にするための重要な要素です。引き続き、最新の研究動向を追いながら、LINEヤフーの実際のサービスにどのように応用できるかを考えていきたいと思います。
推薦関連セッションのサマリー
KDD 2024のResearch Trackは研究分野ごとにセッションが分かれており、推薦システムに関する研究は、Rec Sys 1, Rec Sys 2, Sequential Recommendation, Fair & Safe Recommendation, LLM + Semantics, Recommendation with Graphなどのセッションで行われていました。
Sequential Recommendation、Fair & Safe Recommendation, LLM + Semantics, Recommendation with Graphなどはその問題設定に特化したセッションになっており、これらの問題設定がKDD 2024では盛んに研究されていたことがわかります。
Sequential Recommendationセッションは、従来の推薦システムとは異なり、ユーザーの行動の時間的順序を考慮して、逐次的推薦を行う問題設定です。この問題設定は、ストリーミングやeコマースなどのイベントの順序が重要なドメインにおいて使われています。このセクションでは、最初に紹介したDataset Regeneration for Sequential Recommendationを含む8件の研究が発表されました。
Fair & Safe Recommendationセッションは、ユーザーのデータのプライバシー保護に関するものや、推薦システムに対するポイズニング攻撃、人気度に対して公平なアイテム露出の最適化手法など、推薦システムの安全性や公平性に関する研究が発表されていました。具体的には、ユーザーの位置情報に対するプライバシー保護に関する研究 (Where have you been? A Study of Privacy Risk for Point-of-Interest Recommendation)やコンストラスト学習に基づく推薦システムに対するポイズニングについての研究 (Unveiling Vulnerabilities of Contrastive Recommender Systems to Poisoning Attacks)、CTRの最大化と有害性の軽減のトレードオフを獲得するための手法に関する研究 (Harm Mitigation in Recommender Systems under User Preference Dynamics)などがありました。
LLM + Semanticsセッションでは、LLMを使用した推薦に関する研究や、ユーザーの過去の行動や評価結果ではなく、アイテムの属性やコンテキスト、意味的な関係を使用して推薦を行うsemantic recommendationに関する研究が発表されていました。LLMを使用した研究として、ここではLarge Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender Systemを簡単に紹介します。この研究では、cold-start問題に対処するために、LLMを使用してユーザーやアイテムの情報を活用する問題に取り組んでいます。従来のLLMを使用した推薦システムでもcold-start問題に対しては有用な手法でしたが、情報がある程度そろったwarm scenarioに対しては従来の強調フィルタリングベースのモデルよりも性能が下回ってしまうという問題がありました。それに対して、cold scenarioだけで�なく、warm scenarioでも優れた性能を示すLLMベースのレコメンドシステムであるA-LLMRecを提案しています。
また、Rec Sys 1, Rec Sys2セッションなどで発表された研究についてどのようなものがあったのか一部を以下の表にまとめました。漏れなどがある可能性がありますがご了承ください。
これを�見ると、Rec Sys 1、Rec Sys 2などでは、評価指標に関する研究からモバイル端末内で行われる推薦、Cold-start問題への対処に関するものなど幅広い推薦システムに関する研究が発表されていました。
多くの研究は既存の手法の問題点を発見、その問題を解決する手法を提案するような研究でしたが、On (Normalised) Discounted Cumulative Gain as an Off-Policy Evaluation Metric for Top- Recommendationでは推薦問題で一般的に使用されているnDCGがどの程度オンライン実験の結果を近似できるのかを調査し、DCG指標がオフライン実験/オンライン実験に対して不偏となる状況でもnDCGは手法の相対順位が変動する可能性があることを示していました。
DIET: Customized Slimming for Incompatible Networks in Sequential Recommendationは、頻繁なモバイルからのリクエストによって引き起こされるネットワークの混雑を緩和させるために、モバイル端末上でモデルを動かすことを考えています。従来までの手法では、エッジ側にあるリアルタイムデータを利用して、エッジ固有のモデルを作成するためにモデルを微調整していましたが、この手法では、エッジ上での計算資源を多く使ってしまったり、モデルを最新の状態に保��つために頻繁なネットワーク転送が必要でした。この研究では、各エッジに特化したサブネットを生成することでネットワークの帯域幅の使用とストレージ消費を最小限に抑えています。
User Welfare Optimization in Recommender Systems with Competing Content Creatorsは、推薦問題の一般的な設定であるプラットフォーム側がユーザーに対してアイテムなどを推薦するものではなく、コンテンツクリエイター同士が競い合うプラットフォーム上において、クリエイター間の競争がユーザーの福祉を最適化する上で障害となることがあり、プラットフォーム側がユーザーの好みの分布に基づいてクリエイターに適切なシグナルを送ることがユーザーの長期的な福祉のために重要であることを指摘しています。
Topic: サービス横断のデータや特徴量
機械学習エンジニアの松井です。私は普段業務で、全社のさまざまなサービスのユーザーの行動ログから作成するユーザー表現ベクトルの開発に従事しています。この業務では、サービスを横断するデータをどのように活かすのか、どのようにユーザーの興味や行動の傾向を反映しかつさまざまなタスクに汎用的に使えるユーザー表現ベクトルを作るか、がポイントになっています。そのため、クロスドメインデータ活用、ユーザー表現ベクトルをテーマに学会では聴講セッションを選んでいました。ここではその中からいくつか気になった発表を紹介させていただきます。
DDCDR: A Disentangle-based Distillation Framework for Cross-Domain Recommendation
概要
Ant Group による発表です。
- クロスドメインレコメンデーションにおいて、新しいフレームワーク DDCDR を提案し、ネガティブトランスファー(不要な情報がターゲットのドメインに悪影響を与える現象)を軽減することを目指した研究。
- 知識蒸留(教師モデルから生徒モデルへの知識の伝達)に基づいており、共有ドメインと特定ドメインの特徴を分離して学習を行う。
- オフライン評価で他のベースラインモデルを上回り、またオンラインA/Bテストでも優れた結果が確認された。
この研究の貢献ポイントは以下になります。
- DDCDRフレームワークの提案によるネガティブトランスファーの軽減
ソースドメインとターゲットドメインの情報を分離し、不要な情報の影響を軽減。ソースドメインの共有知識は教師モデルで抽出され、ターゲットドメイン固有の情報は生徒モデルで強化。 - 知識蒸留と対照学習の統合
教師モデルから生徒モデルに共有知識を移転し、対照学習でターゲットドメイン固有の特徴を強化。このアプローチにより、データ不足のドメインでも高い推薦精度を達成。 - ビジネス面での有効性
オンラインA/Bテストを実施、UVCVR (Unique Visitor Conversion Rate) と UVCTR (Unique Visitor Click-Through Rate) がそれぞれ 0.33%、0.45%向上。特に、データの少ない非活動的なユーザーや新規ユーザーに対する効果が大きめ。
提案手法
DDCDR は大きく分けて教師モデルと生徒モデルの二段階で構成されます。教師モデルは、ソースドメインとターゲットドメインの両方のデータを用いてドメイン共有の特徴を学習します(図中(1))。生徒モデルは、その教師モデルから共有知識を学ぶことでターゲットドメインの性能を向上させます(図中(2))。
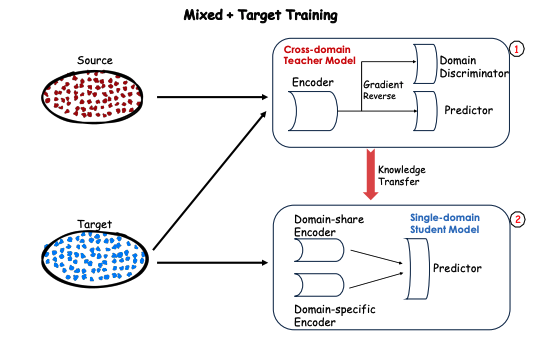
技術詳細 - クロスドメイン教師モデル
教師モデルは、エンコーダーと予測器から構成され、ソースドメインとターゲットドメインの両方を使って学習します。また、ドメイン識別器を用いて逆勾配法を組み込み、エンコーダーが「ドメイン識別器がドメインラベルを予測できない」ような特徴、つまり異なるドメイン間で共有されるような特徴を抽出するように学習します。
技術詳細 - 分離型生徒モデル
教師モデルから学習した後、生徒モデルをターゲットドメインでの学習に用います。生徒モデルは、ターゲットドメインをドメイン共有の特徴とドメイン固有の特徴に分類するモジュール(図中(1))、ドメイン共有の埋め込み表現を強化するモジュール(図中(2))、ドメイン固有の埋め込み表現を対照学習によって強化するモジュール(図中(3))から構成されています。
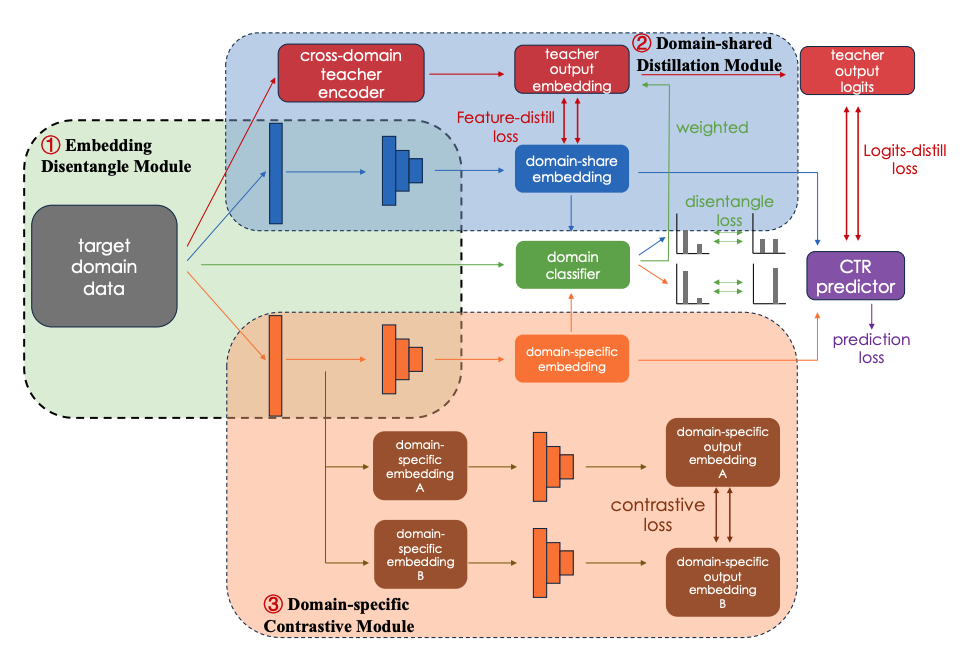
実験
提案手法 DDCDR は全てのデータセットにおいて他の全てのベースラインモデルを上回る結果を示しました。
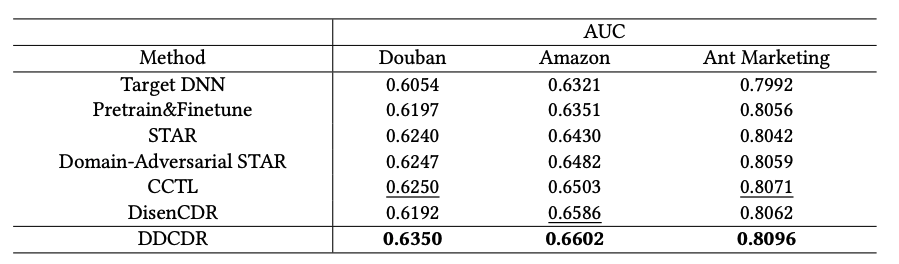
アブレーションスタディでは、提案手法中の全てのモジュールを組み合わせた場合に最も高い AUC を示し、各モジュールが提案手法の性能に寄与していることが示されました。
Alipay の実環境で オンラインのA/B テストを実施し、UVCVR が0.33%、UVCTR が 0.45%向上しました。特にデータが少ないユーザー層での大幅な性能向上が確認されました。
感想
サービス横断的なデータは特にデータの少ないドメインや新規ユーザーに対してうまく活用したいものですが、実際のところクロスドメインデータから役に立つ知識だけを抽出して特定のドメインで利用するのはうまくいかないことも多いです。このような課題に対し、この論文で紹介された手法は参考になる知見を多く含んでいます。
Cross-Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
概要
Tencent による発表です。
- クロスドメイン生涯シーケンシャルモデリング(LSM)に基づくオンライン CTR 予測を改善するため、Lifelong Cross Network (LCN) を提案。
- LCN は、CRP(対照学習を用いてドメイン間のアイテム埋め込みを強化するモジュール)と LAP(3段階の Attention メカニズムでユーザーの興味を抽出するモジュール)を組み合わせた手法。
- WeChat Channels のデータセットを用いた実験により、LCN が既存の手法より高精度で CTR 予測を行うことを確認。
この研究の貢献ポイントは以下です。
- クロスドメイン埋め込みの強化
Cross Representation Production (CRP) モジュールは、対照学習によってドメインを跨いだアイテム埋め込みを学習し、類似するアイテム間の関係をより適切に捉えられるように強化。 - Lifelong Attention Pyramid (LAP) モジュールの導入
3つの異なる Attention レベルを持つ LAP モジュールによってユーザーの興味を抽出し、行動シーケンスのノイズを効果的に除去。 - ビジネス面での有効性
WeChat Channels プラットフォームのオンライン A/B テストで、CTR が +2.93%、視聴時間が +3.27%増加。
提案手法
LCN は CRP と LAP の2つの主要モジュールで構成されており、CRP が埋め込み学習を担当し、LAP がユーザーの行動シーケンスから興味を抽出します。CRP によって学習されたアイテム埋め込みが LAP 内で使用されることで、クロスドメイン間でのユーザー興味の抽出がより効果的になります。
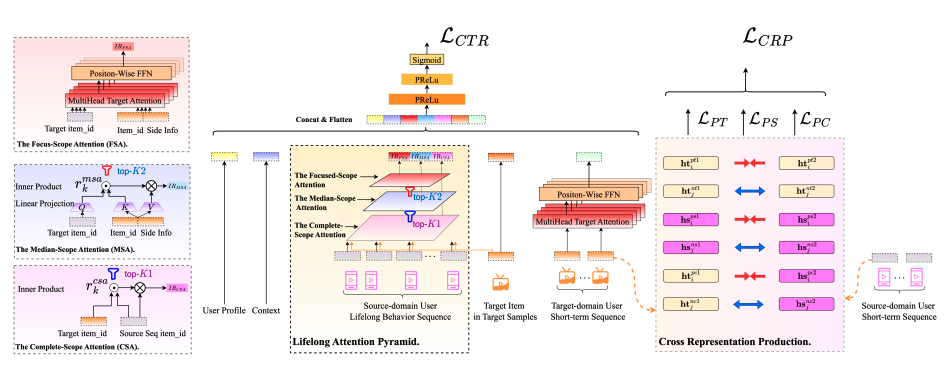
技術詳細 - CRP モジュール
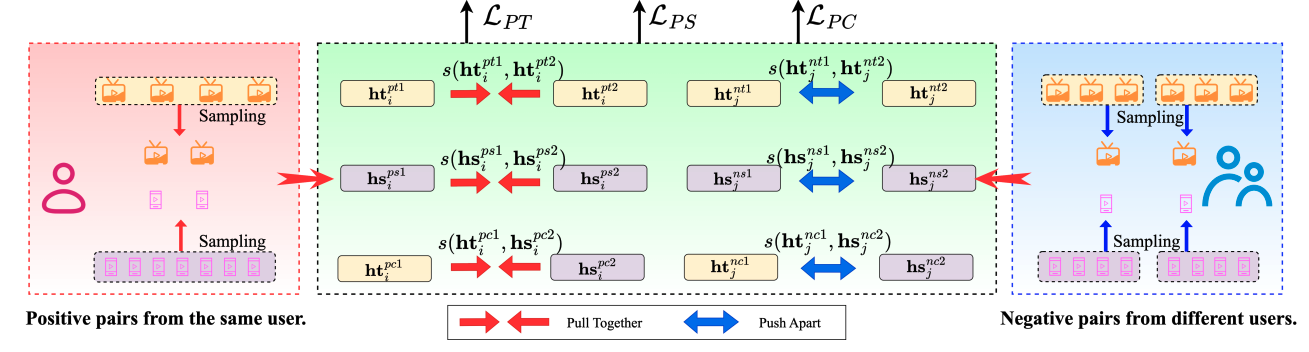
対照学習によって、ユーザーの短期的な行動シーケンスからポジティブおよびネガティブペアを選択して、アイテム間の関係を学習します。
技術詳細 - LAP モジュール
3つの段階的な Attention(Complete-Scope Attention、Median-Scope Attention、Focused-Scope Attention)を通じてユーザーの興味のある項目を段階的に絞り込み、ノイズを効果的に除去しながら埋め込み表現の非線形性を高めます。
実験
提案手法 LCN は他のすべてのベースライン手法を上回る結果を示しました。
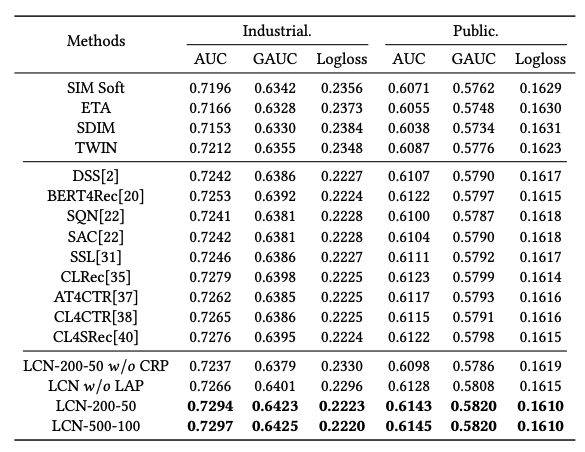
また、CRP モジュールを導入することで特に AUC の改善が見られました(+0.003 から +0.005の増加)。また埋め込みの可視化結果からも、CRP モジュールがソースドメインにおけるアイテムのクラスタリングをより効果的に行うことが確認されました。
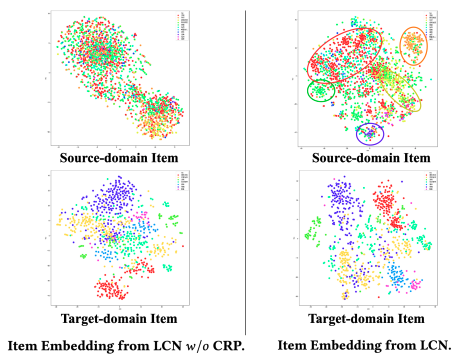
さらに、LAP モジュールによってより高い一貫性を持つ Attention が得られ、全体の性能向上に貢献することが分かりました。特に、MSA(Median-Scope Attention)レベルを追加することでモデルの一貫性とパフォーマンスが向上し、FSA(Focused-Scope Attention)レベルでの最終出力が安定しました。
WeChat Channels プラットフォームでオンラインA/Bテストを実施した結果として、提案手法 LCN を導入したグループでは CTR が +2.93%、ユーザーの滞在時間が +3.27%増加しました。
感想
長期間 × クロスドメインのユーザー行動ログを入力としているという点が私が業務で担当しているプロダクトと共通しています。特に CRP モジュールの対照学習を用いた埋め込み強化手法に注目していま��す。
Topic: 広告技術とA/Bテストの新たな視点
データサイエンティストの小川です。インターネット広告業界は、プライバシー保護の厳格化、LLMを始めとするAI技術の台頭、広告ビジネス自体の変化などの課題に直面し、従来の常識を覆す変化が訪れようとしています。
KDD2024でも、広告関連技術に関する最前線の研究が数多く発表され、特にA/Bテストの精度向上やプライバシー保護に関する新しいアプローチが注目を集めました。
本セクションでは、KDD2024で発表された論文を通じて、業界における最新の技術革新とその実務への応用可能性について探ります。
まず、A/Btestについて新たな視点をもたらす論文について解説し、その後に広告関連セッションで気になった論文をまとめて紹介します。
False Positives in A/B Tests
背景
私は普段、LINE関連サービスの広告関連のデータ分析を行っています。
わずかなUIの変更や機械学習ロジックの変更が大きな収益インパクトをもたらす広告分野では、日々サービス改善のためA/Bテストが実施されています。
この論文は、私たちが日々行っているA/Bテストの結果をどう解釈すべきか、そして実験設計をどのように改善できるかについて、新しい視点を提供しています。
実験
この論文では、業界慣例として用いられている有意水準α=0.1とした検定(片側検定の場合α=0.05)をした場合、有意となった結果の1/3以上のテストが偽陽性であるという衝撃的な事実を示しています。
重要なポイントは、A/Bテス��トにおける「偽陽性リスク(False Positive Risk, FPR)」です。FPRとは、統計的に有意な結果が得られたにもかかわらず、実際には効果がない(または無視できるほど小さい)確率のことです。
著者らによると、多くの企業でA/Bテストの成功率は10-20%程度だそうです。この低い成功率の場合、一般的な有意水準α=0.05(両側検定)を使用すると、実際のFPRは予想以上に高くなる可能性があります。(Figure 1参照)
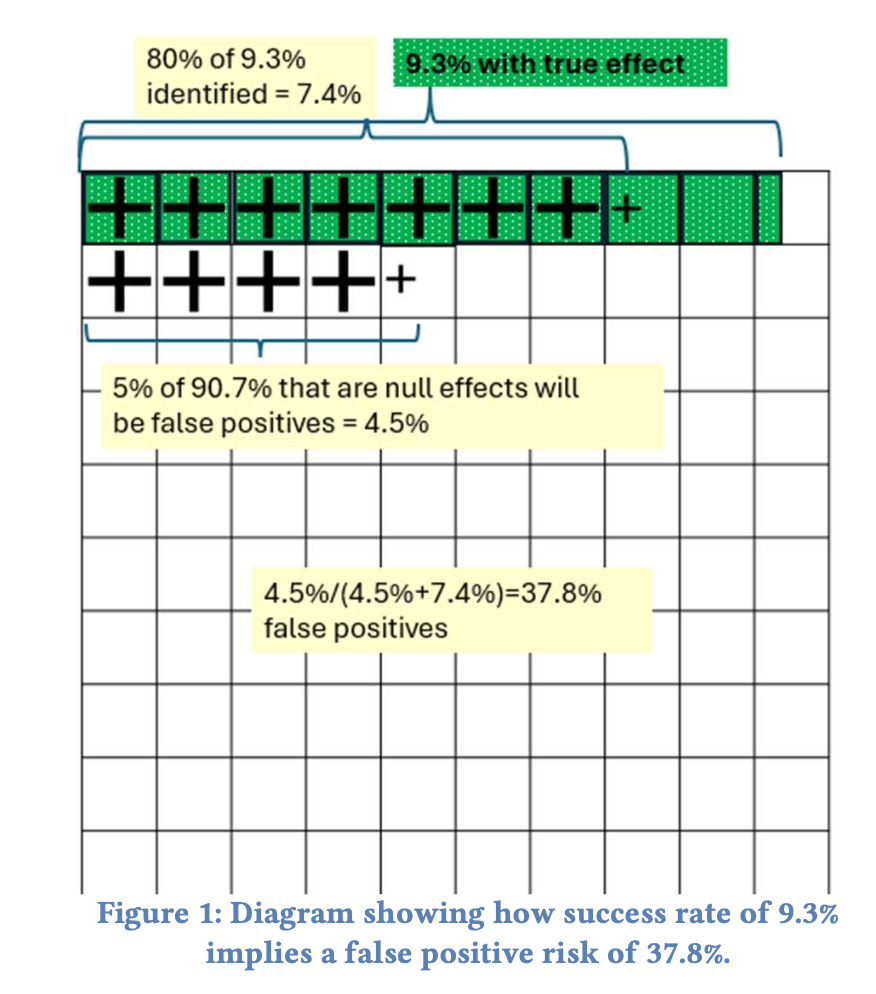
実際のデータ分析から、観測された成功率が12%の場合、真の成功率は約9.3%と推定され、FPRは37.8%にもなることが分かりました。
αの選択
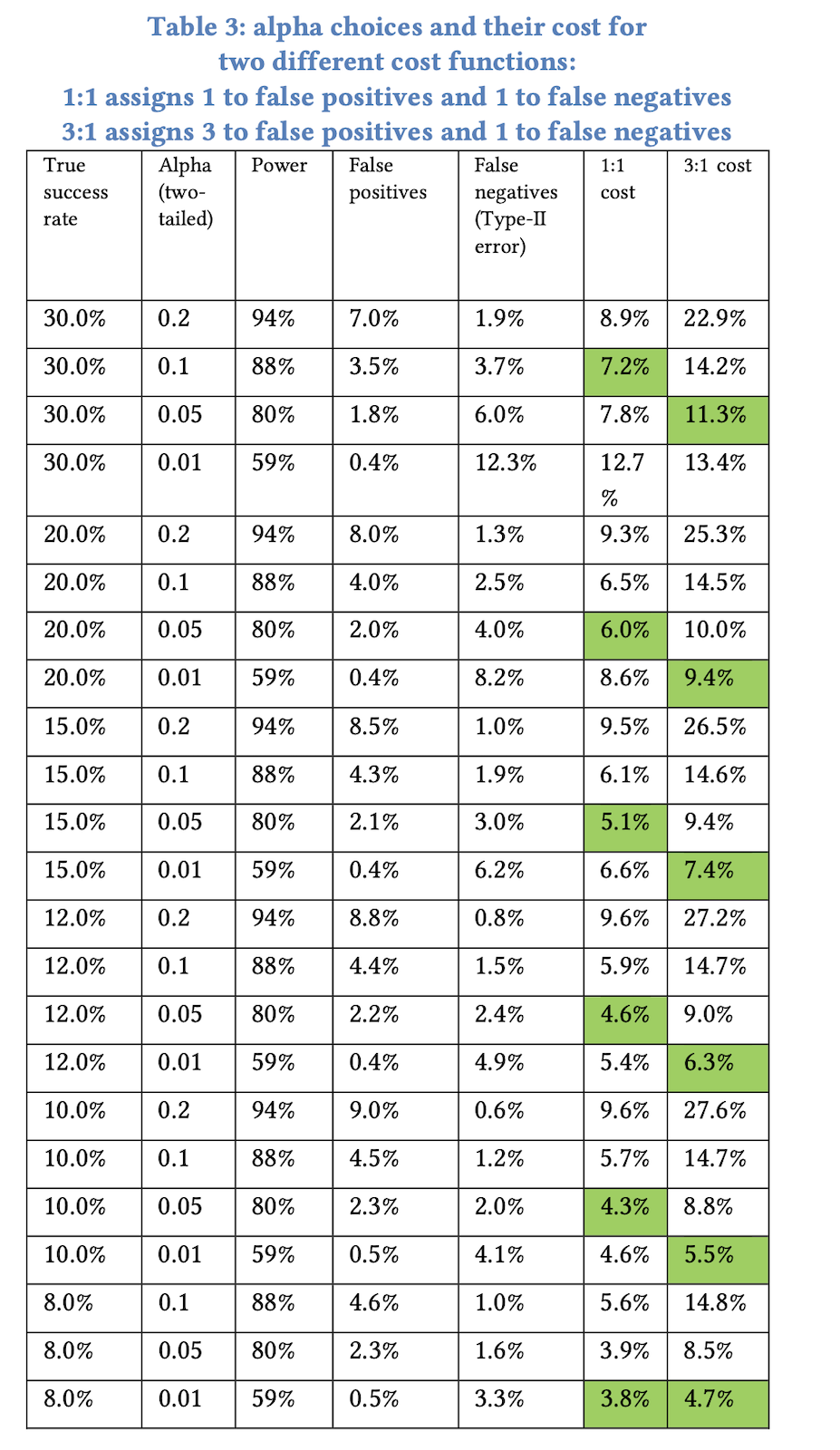
FPRの推定結果など踏まえ、著者らはαを0.05より低く設定することを推奨しています。
また、偽陽性のコストが偽陰性より高いと主張し、αの選択には両者のコストバランスを考慮する必要があるとしています。
例えば、偽陽性のコストが偽陰性の3倍である場合、αを0.01に設定することで、全体的なコストを最小化できる可能性があります。
FRPの低減
著者らは、p値が境界値に近い場合(例:0.01〜0.05)、FPRを低減させるために
- 実験を延長
- 実験の繰り返し
- グループ逐次検定
を3つを推奨しています。
これらの手法は実務でも実践可能で、とても面白いアプローチ�であるため興味のある方は論文を確認してみてください!
感想
この論文発表後の質疑応答は大変盛り上がっており
- 頻度論的なA/Bテストは辞め、ベイズ的なA/Bを採用すべきではないか?
- テストを中断・再実行する場合に、対照群・処置群のユーザーをシャッフルするか否かの判断基準をどこに設けるか?
などの質問が寄せられており、多くのデータサイエンティストがA/Bテストに頭を悩ませているようでした。
改めてこの論文は、私たちが日々行うA/Bテストの結果解釈と実験設計に大きな影響を与える可能性があります。
1/3以上のテストが偽陽性である可能性があるという事実は、A/Bテストへの姿勢を再考させるものです。今後も関連研究から目が離せません。
広告関連論文のサマリー
KDD2024では広告関連の研究が多くの注目を集めており、例年通りAd KDDという広告関連のトピックに特化したワークショップも開催されました。
Ad KDDの論文や発表資料はこちらのリンクから誰でもアクセスができるようになっており、ワークショップ終了後も関連情報にアクセスが可能となっています。(https://www.adkdd.org/papers)
ここではKDD2024で発表された広告関連論文をトピック毎での研究成果・トレンドを紹介します。各論文へのリンクをまとめたので、興味のある論文へぜひアクセスしてみてください。
普段の業務に関連する研究を深掘りすることで、新たなアイデアを得ることができるかもしれません。ぜひ、積極的に活用してみてください。
| 研究トピッ��ク | 概要 | 論文タイトル・リンク |
|---|---|---|
| CTR予測 | CTR予測の分野では、ユーザー興味の変化を考慮したモデルや、マルチフィールドでのPost-hoc Calibrationなどが注目を集めました。 また、スパースなユーザーフィードバックを扱うランキングロスの理解や、クロスドメインでのLTV(Life Time Value)予測など、より複雑な予測タスクへの取り組みも見られました。 |
|
| オークション・自動入札 | オークションと自動入札 オークションと自動入札の分野では、ロバストな自動入札戦略や、コスト最適化の理論的分析が行われました。 特に、条件付き拡散モデルを用いた生成的自動入札や、オフライン強化学習を用いた入札ポリシーの最適化など、先進的な機械学習技術の応用が目立ちました。 |
|
| 予算最適化 | マルチタスク学習とバンディットアルゴリズムの融合が新たなブレイクスルーをもたらしています。ベイジアン階層モデルを用いたアプローチは、キャンペーン間で情報を効果的に共有し、限られたデータでも効率的に学習できる点が革新的です。 | |
| コールドスタート | 因果推論の考え方を取り入れた新しいアプローチが登場しています。操作変数を活用したCTR予測手法や、二段階バンディットフレームワークを用いた広告選択の改善手法が、新規広告や新規ユーザーに対するパフォーマンスを向上させています。 | |
| プライバシー保護 | プライバシー保護は引き続き重要なテーマであり、差分プライバシー(DP)を用いた新しい手法が提案されています。特に注目すべきは、半機密特徴量を持つ広告予測モデルのDPトレーニング手法です。ユーザーのプライバシーを保護しつつ、高精度の予測モデルを構築すること手法が提案されています。 また、プライバシーに配慮した入札最適化手法も登場しており、規制強化の流れの中でも効果的な広告運用を可能にします。これらの技術は、GDPRを始めとする規制に対応しつつ、効果的な広告配信を実現する上で重要な役割を果たすでしょう。 | |
| レコメンド・多様性 | 関連性と多様性のバランスを取る研究が進展しています。トリガー誘発型レコメンデーションにおける新しい注意メカニズムや、大規模言語モデルを活用した広告文生成により、よりパーソナライズされた、かつ多様な広告レコメンデーションが可能になりつつあります。 |
まとめ
KDDに現地参加したことによって、機械学習のビジネス応用研究の最前線を肌で感じることができ、新たな発見が多くありました。
来年はトロントで開催されることが決定しているため、そちらにも注目していきたいと思います。
LINEヤフーでは2024/10/17にKDD2024論文読み会を主催予定(今回で3年連続開催!)で、現地参加メンバーが登壇する予定ですのでぜひこちらもご覧ください。
またLINEヤフーでは機械学習エンジニア、データサイエンティスト、プロダクトマネージャーなどを積極的に募集しています。ご興味のある方はぜひ応募をご検討ください。
Appendix: 学会の雰囲気
最後に学会の雰囲気をいくつか写真で紹介します。
Annual Sessionなどが行われるメイン会場

各発表セッションなどが行われる会場
一部人気のWorkshopなどでは入場制限がかかる場合もあった

ポスターセッション会場
食べ物や飲み物を片手に気軽に議論することができた

ポスターセッションと同じ会場に設けられた企業ブース

学会会場の隣にあるショッピングモール
ランチや学会後のmeet upもここで行われることが多かった

学会会場裏手にあるビーチ
参加者コミュニティーでは即席で泳ぎに行く会が開かれていたといううわさも



