こんにちは。生成AI関連の開発をしている図左です。社内でRAGを使った生成AIサービスを開発していますが、ロジック変更のたびに毎回人手でテストするのは現実的ではありません。今回は、この品質評価を自動化したフローや手法を紹介します。
SeekAIとは
LINEヤフー株式会社では、社内の情報を効率的に検索するために、生成AIを活用したサービス SeekAI を内製展開しています。SeekAIではRAGという技術を使って一般的な知識だけでなく、社内規程・ルール・問い合わせ先、コーディング時の技術スタック、顧客や取引先とのコミュニケーション履歴などを効率的に把握できるため、社内の情報検索ツールとして活用されています。
RAGとは
生成AIに『学習済みではない知識』に関する回答を出力させるために、別途構築したデータベースから取得した情報と組み合わせて回答させる手法です。同じ目的を実現する手法として Fine-Tuning が検討されることがありますが、現在はコストや精度の観点からRAGの方が主流になっています。
SeekAI立ち上げ時の評価方法
SeekAIを立ち上げた当初は、生成AIの回答品質を確認するために、人手で回答を確認する方法を取っていました。広告事業のカスタマーサポート業務を担当している方々にご協力いただき、詳細に見ていただいたことが功を奏し、プレスリリースにも記載されている通り98%まで正答率を向上させることができました。正答率を向上させることができたため、晴れてPoCを終え、SeekAIは正式な社内サービスとして開発が進められることになりました。
RAGで生成した回答の評価に関する課題
なんとか正答率を上げることはできましたが、正答率が高くなると、その正答率を維持しなくてはいけないため回答に関わる部分のロジック変更が難しくなります。が、前述のような人手での確認やロジック変更時の確認には、以下のような課題がありました。
- 精度評価を正しく実施するためにはドメイン知識が必要で、一見文章として成立しているようでも誤った回答をしていることがあるため、ドメイン知識がないと判断が難しい(正しいと思ってしまうことがある)
- ロジック変更による出力への影響が未知数であり、一定規模のテストが必要
- 元のドキュメントの質によって回答の精度が左右されるため、特定のドキュメントでうまくいっても他のドキュメントではうまくいかないことがある
自動評価の必要性
上記のように、RAGにはまだ課題となる部分が多く、回答の品質を確認するためには人手での確認が必要です。しかし、回答ロジックを変更するたびに、毎回人手で回答品質をテストすることはあまり現実的ではありません。理由としてはいくつかありますが、主なものは以下の通りです。
- 品質をしっかりと確認するにはドメイン知識が必要になるが、業務部門に毎回依頼するわけにもいかず、厳密な確認ができない
- 人の目で確認を実施すると、長い時は数日の待ち時間が発生するため、スピーディに開発を進められない。
生成AIはほんの少しのプロンプトの変更でも生成AIの回答出力が大きく変わることがありますし、出力が一般的なプログラムのように一様になるわけではなく、入力内容によって大きく結果が異なるため、特定のパターンでうまくいっても、他のパターンではうまくいかなくなっていることがあります。そのため、なるべく多くのチェックを行い回答品質の変化を把握することが大事です。
LLM-as-a-Judge
そこで、人手での評価を自動化するために、SeekAIではLLMを利用して生成された回答の品質を評価する仕組みを構築しました。これは一般的には"LLM-as-a-Judge"と呼ばれています。
ただし、LLMはハルシネーションを起こすことがあるため、すべての評価が正しく行われているわけではないことに注意が必要です。この対策としては、以下のような取り組みを行っています。
- 性能の異なる複数のLLMモデルで生成した回答に対して評価を行う
- すでに高品質なことがわかっているドキュメントを用いて、高評価が出ることを確認する
LLMの性能が高いほどRAGの回答品質も向上する傾向があるため、複数のモデルを比較することで、評価が正しく行われているかどうか、傾向を確認しています。また、高品質なドキュメントを用いて評価を行うことで、LLMの評価の精度が低いかどうかを判断しています。LLM-as-a-Judgeは評価項目によって精度が大きく異なることがあり、うまく判定できる項目もあれば、そうでないものもあるので、評価結果を鵜呑みにするのではなく、詳細まで確認することと、一定数の評価を実行してみてどれくらいの割合で正しく判定できているかを確認することが大事です。
数値ではなく真偽値による評価の実施
各評価項目はBoolean(true/false)で出力されているものが多いです。こうすることで、具体的に何が原因で評価が低くなっているのかを特定できるようになります。数値スコアによる評価は何が原因でスコアが低いのかがわからないため、具体的な改善策を立てることが難しくなるため、いきなり総合評価をすることは避けています。
SeekAI で設定している評価指標(ICCG Framework)
SeekAIで実際に使用されている評価指標は以下のようなものがあります。
| 評価要素 | 説明 |
|---|---|
| 含有性(Inclusion) | あらかじめ想定されていた回答の内容が含まれているか? |
| 相反性(Contradiction) | あらかじめ想定されていた回答と相反する内容があるか? |
| 一致性(Consistency) | あらかじめ想定されていた回答と同じトピックについて回答しているか? |
| 案内性(Guidance) | 元情報のURLが案内されているか? |
評価にはRAG用のデータを作るために使ったデータを利用
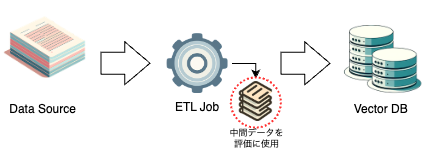
SeekAIでは、RAG用のデータを作るためにETLフローを構築していますが、その処理過程で作られる中間データを利用して評価を行っています。
処理フロー
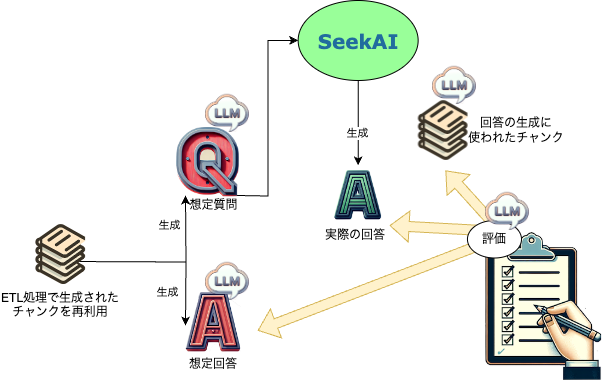
処理フローは、検証の対象となるデータを準備する『準備処理』と、そのデータを使って評価を行う『評価処理』に分かれます。準備処理と評価処理を明確に分けるのは、同じデータを使って繰り返し評価を行うことで、ロジック変更による評価結果の推移を正し�く把握するためです。各処理フローで実際に処理される内容は以下の通りです。
| 処理フロー | 処理内容 |
|---|---|
| 準備処理 | 評価対象となるデータ群をFIX |
| その中から、いくつかのチャンクをピックアップ | |
| チャンクから想定される質問と回答のペアを生成(LLM) | |
| 想定質問を使ってSeekAIから実際の回答を生成 | |
| 評価処理 | 準備処理で作成した内容を評価(想定質問、想定回答、使用されたチャンク) |
| レポートとして出力 |
実際の評価結果
そして、SeekAI 内で実際に評価した結果がこちらです。
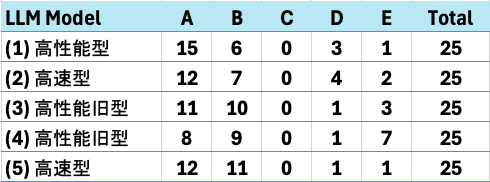
※ 評価はAが最高で、Eに近づくほど低くなります。モデル名は意図的に伏せております。
一般的に性能が高いと言われるモデルほど、良い結果になっているのがわかります(Cは現在の評価基準では出現しづらく、全モデルで0件となりました)。結論としては、やはり良い結果を得るためには、高性能なモデルを使用した方が良いということがわかります。ただ、SeekAIは(3)の頃に初期の評価を実施していることから、(2)や(5)の高速型を使用することで、コストを抑えつつある程度精度を持った回答を得ることもできることもわかります。
※ こちらの評価�結果は本記事掲載を目的として、公開されたドキュメントを使用して自動評価を実施した結果です。また、モデルの評価はパラメータやプロンプトの最適化によって変わることがあるため、LLMの性能を厳密に評価するものではありません。
おわりに
LINEヤフー株式会社では、社内での生成AI活用に精力的に取り組んでいます。SeekAI開発チームでは、今後もRAGの回答品質をさらに高め、社内業務の効率化に貢献していくことを目指しています。
※ 記事中の画像に使われているアイコン類は、生成AIを使用して作成されています。


