こんにちは。LINEヤフーのFoundation Models開発担当、横尾と岡田と朱です。私たちのチームでは、画像と言語のマルチモーダル基盤モデルの研究開発を行って��います。
この記事では我々が開発した日本語マルチモーダル基盤モデル「clip-japanese-base」について紹介します。どなたでも使えますので、ぜひ試してみてください。
初めに
マルチモーダル基盤モデルは、画像やテキストなどを同時に解析し、これらの複数のモダリティ間の関係を評価する能力を持つモデルです。CLIPはその代表的な例であり、インターネットから集めた大量な画像とテキストを用いてモデルを学習し、多くの下流タスクにおけるゼロショット性能を向上させることが可能になりました。高い汎用性と拡張性を持つCLIPは、研究・実サービス問わずさまざまな場面にて使われています。一方で、英語に対応したCLIPは既に多数開発されていますが、日本語や日本固有のデータに適応したCLIPはまだ性能向上の余地があると考えられます。そこで、LINEヤフーは、超大規模かつ高品質な日本語学習データを活用し、高性能な基盤モデル「clip-japanese-base」を開発し公開することになりました。
- clip-japanese-baseモデル(商用利用可能なApache-2.0ライセンス)
- 評価用のImageNet-1Kの日本語クラス名(従来評価に用いられてきたImageNet-1Kの日本語クラス名のラベル誤りや、一般的でない呼称などを訂正したバージ��ョン)
clip-japanese-baseの特徴
今回公開したモデルの一つ大きな特徴としては、大規模かつ高品質な日本語データを用いた学習によって高性能を達成しました。日本語データを構築するために、データ収集とデータフィルタリングにおいてさまざまな工夫を行いました。
データ収集
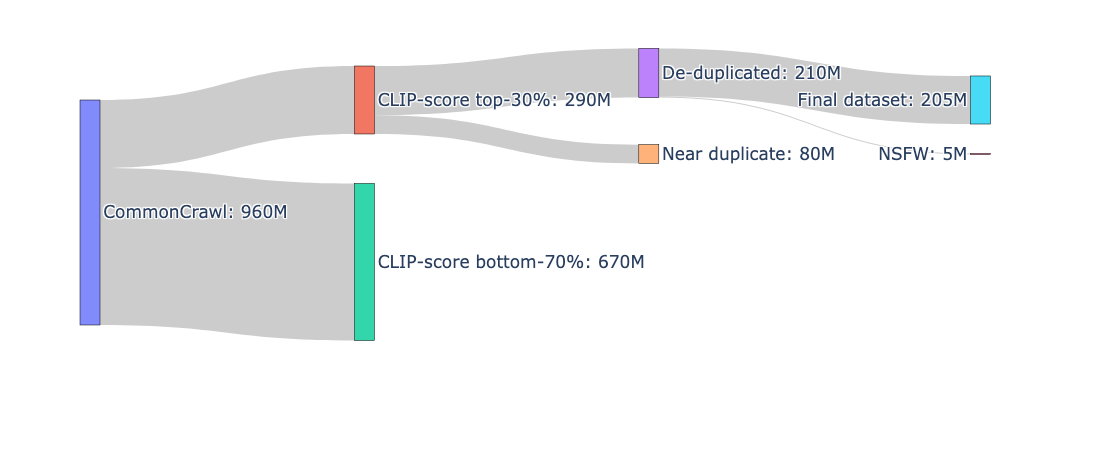
CLIPの学習には大規模な画像とテキストのペアデータが必要になる一方で、日本語の画像・テキストデータが少ない問題があります。そこで、まず大規模な日本語データの収集を試みました。データの詳細は以下の通りです。
- CommonCrawl:
- Webアーカイブデータから、日本語と判定された10億件の画像・テキスト(約50TB)を抽出しました。日本語の判定について、一文字でもひらがな・カタカナを含む場合は日本語データとしました。
- Conceptual Captions 12M (CC12M):
- 1200万の画像・テキストペアのオープンソースデータを日本語に翻訳しました(うち約300万件はDeepLで翻訳、残りはfugumtで翻訳)。
- YFCC100M:
- 日本ドメインかつ商用利用可能な画像を約50万件を抽出して、アノテーションを行いました。
データフィルタリング
Webから収集したデータの品質はさまざまです。低品質なデータは、モデルの学習においてノイズとなるため、高品質なデータを抽出する必要があります。私たちのチームはICCV2023が主催するData Centricコンペティション「DataComp」に参加し、そこで上位を獲得し��ました。また、データフィルタリングに関する多くの知見も得られました。その知見を活かして、以下の通り、収集したデータのフィルタリングを行いました。
- CLIP-score filtering:
- 画像とテキストが無関係なデータを除去するために、CLIP-scoreによるフィルタリングを行いました。CLIP-scoreはCLIPによって計算される画像とテキストの特徴量の類似度であり、画像とテキストの関連度を表す指標とみなすことができます。Webから収集したデータに対して、CLIP-scoreが上位30%のデータを残しました。CLIP-scoreの計算にはRinna-ja-cloobを使用しました。
- 重複除去:
- Webデータは大量な重複があるため、大規模スケールでも適用可能な効率的な重複除去手法SemDeDupを用いました。
- NSFW filtering:
- HojiCharを用いて有害なテキスト(アダルトワード、暴力的表現、差別的表現)を含むサンプルを除去しました。
最終的に約2億の画像・テキストペアが抽出され、これをモデルの学習に用いることで高い性能を達成しました。データ処理の全体像は以下の通りです。
clip-japanese-baseの性能
学習したモデルの性能評価として、ゼロショット画像分類と画像・テキスト検索タスクの性能を評価しました。既に公開されたLaion, StabilityAI, RinnaとHakuhodoの日本語対応CLIPとの比較を行いました。
- 評価データセット:
- 評価指標:
- STAIR Captionsはimage-to-text retrieval(I2T_R@1)とtext-to-image retrieval(T2I_R@1)で、その他は分類タスクのためaccuracy top 1(acc@1)で評価しました
- 評価結果:
- オープンソースになっている日本語対応CLIPモデルの中で、最も軽量かつ最も高い平均スコアを達成しています
| Model | Image Encoder Params | Text Encoder params | STAIR Captions | jafacility20 | jafood101 | jaflower30 | jalandmark10 | ImageNet-1K | |
|---|---|---|---|---|---|---|---|---|---|
| I2T_R@1 | T2I_R@1 | acc@1 | acc@1 | acc@1 | acc@1 | acc@1 | |||
|
clip-japanese-base |
86M | 100M (BERT) | 0.35 | 0.24 | 0.85 | 0.92 | 0.85 | 0.92 | 0.58 |
| Stable-ja-clip | 307M (ViT-L) | 100M (BERT) | 0.32 | 0.16 | 0.71 | 0.89 | 0.67 | 0.80 | 0.68 |
| Rinna-ja-clip | 86M (ViT-B) | 100M (BERT) | 0.16 | 0.10 | 0.65 | 0.59 | 0.30 | 0.64 | 0.56 |
| Laion-clip | 632M (ViT-H) | 561M (XLM-RoBERTa) | 0.37 | 0.22 | 0.83 | 0.87 | 0.71 | 0.91 | 0.58 |
| Hakuhodo-ja-clip | 632M (ViT-H) | 100M (BERT) | 0.24 | 0.18 | 0.83 | 0.86 | 0.71 | 0.88 | 0.46 |
おわりに
今回公開しました日本語マルチモーダル基盤モデル「clip-japanese-base」を皆様に広くご利用いただき、ご意見やご感想をお寄せいただけますと幸いです。
LINEヤフーは今後も構築したモデルの一部を継続的に公開しますので、どうか楽しみにお待ちください。


