こんにちは。LINEヤフーで音楽情報処理の研究開発をしている蓮実です。
私たちのチームでは、音楽推薦システムの研究開発を行っています。今回はこの技術の概要についてお伝えいたします。なお、本記事の詳細な内容は日本音響学会第151回(2024年春季)研究発表会でも発表済みです。
検証に使ったデモの紹介
私たちが開発している音楽推薦システムは、テキストと音楽の関係を学習する対照学習を用いています。システム内部では、テキスト情報と音楽特徴量をひもづける、クロスモーダルの埋め込み空間を構築するように学習されたモデルを使用しています。推薦時には、ユーザーが入力したテキストの意味に近い音響特徴量を持つ音楽を埋め込み空間から探し出し、提示します。
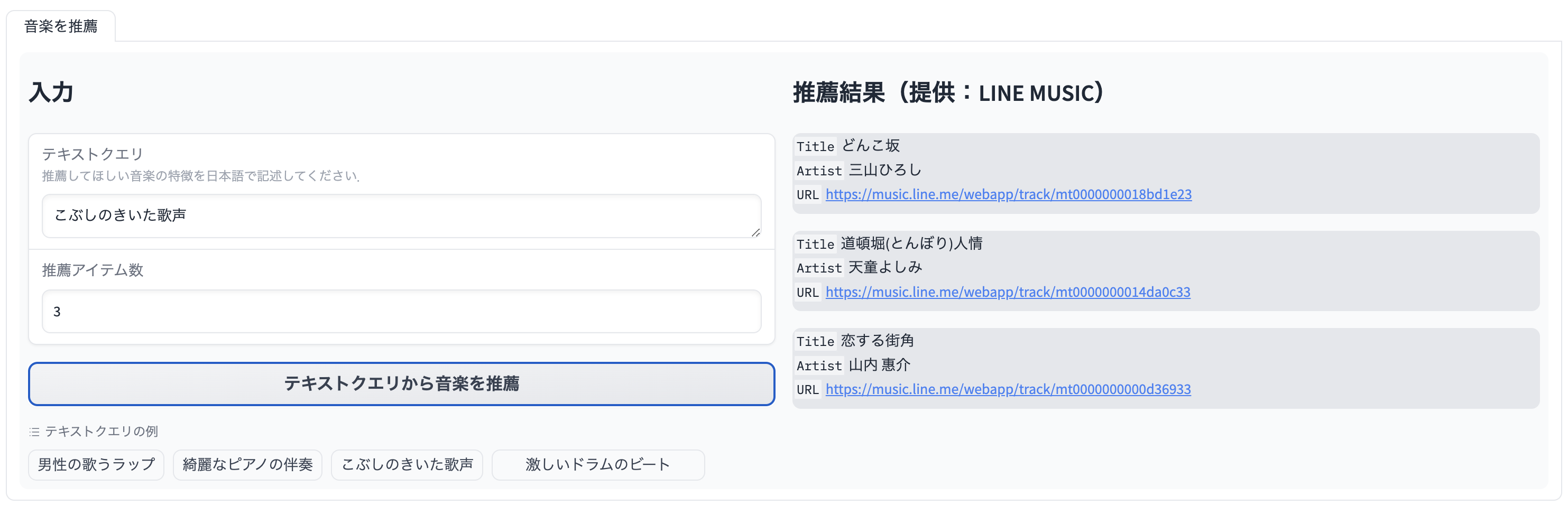
上に示す検証に使ったデモでは、LINE MUSICの2023年間ランキング総合TOP100と、第74回 NHK紅白歌合戦 2023年に含まれる149曲の中から、入力されたテキストの意味に類似した上位の曲を推薦します。例として、「こぶしのきいた歌声」というテキストを入力するとこぶしが多用される演歌の「どんこ坂(三山ひろし)」「道頓堀人情(天童よしみ)」などが推薦されます。他にも以下のような結果が実験的に得られています。
| テキスト入力の例 | 推薦される曲の例 |
|---|---|
| 男性の歌うラップ | CASE 143(Stray Kids) |
| 綺麗なピアノの伴奏 | ツキミソウ(Novelbright) |
| 激しいドラムのビート | コイコガレ(milet & MAN WITH A MISSION) |
デモの仕組み
次の図に、デモの大まかな流れと使用した技術スタックを示します。
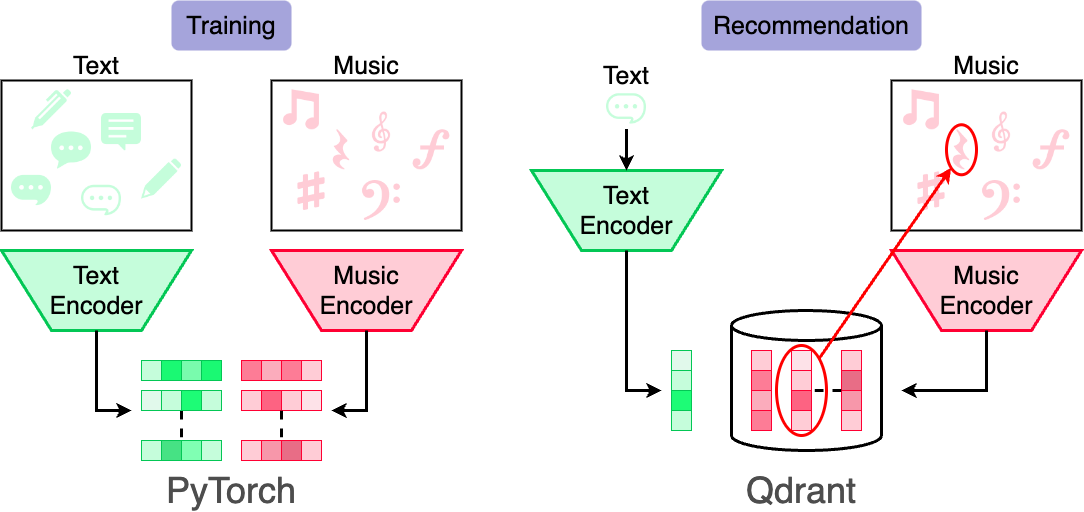
検証に使ったデモでは、あらかじめ抽出された音楽の特徴量をデータベースに格納しています。ユーザーがテキストを入力すると、システムは類似した音楽の特徴量をデータベース上から検索し、上位の曲を推薦リストとして提示します。特徴量を抽出するモジュールは、音楽とテキストの意味特徴量が一致するように、対照学習により学習されています。特徴量抽出モジュールの学習には深層学習ライブラリのPyTorchを使用し、特徴量の保存と検索にはベクトルDBのQdrantを採用しています。
本記事の以降のセクションでは、主にPyTorchで実装をした推薦モデル部分について説明をします。
テキストと音楽の対照学習
紹介した推薦システムの内部では、テキストの意味に基づいて音楽を推薦する技術が使用されています。この技術の先行研究である [1]や[2]では、いずれも英語テキストと音楽のデータを対象として、テキストの意味に基づいた音楽の推薦をしています。一方、私たちのチームでは、ユーザーの使用言語ごとの推薦モデルを学習させることでニーズにより適した推薦ができると考え、日本語テキストにより音楽を推薦するシステムの開発を行っています。
推薦システムは、先行研究 [1]や[2]と同様に、テキストと音楽の対照学習によって学習されます。次の図に、使用しているテキストと音楽の対照学習の概要を示します。
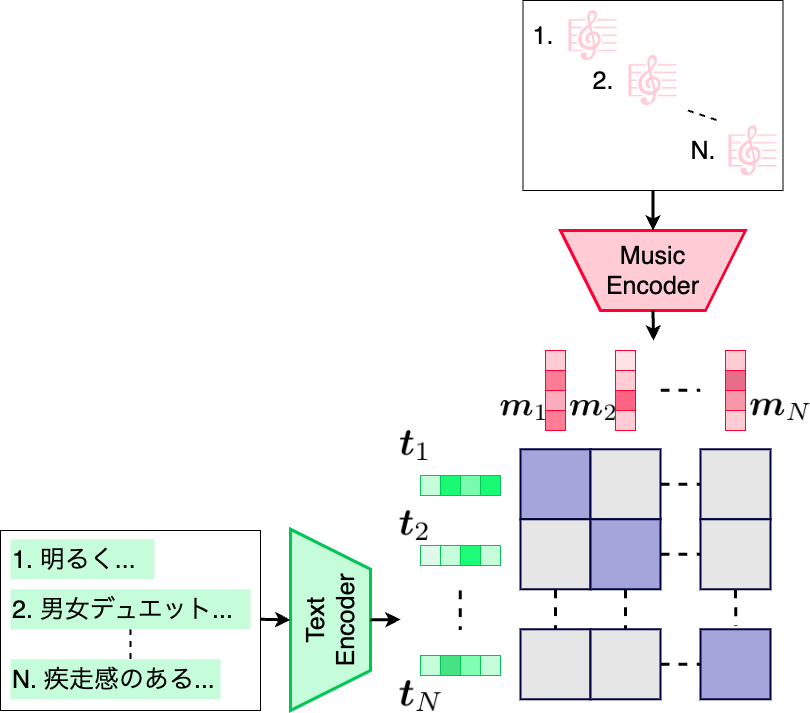
この学習の枠組みでは、音楽を音楽エンコーダ(music encoder)に、テキストをテキストエンコーダ(text encoder)へ入力することで、それぞれの特徴を集約した埋め込みとを抽出します。得られた埋め込みを用いて、次の式で計算されるcontrastive lossを最小化するように各エンコーダを学習させます。
ただし、は学習中のミニバッチのサイズであり、は学習可能な温度パラメータです。この学習により、音楽とそれに対応するコメントの埋め込みのcos類似度が大きくなり、異なる埋め込みとのcos類似度が小さくなるクロスモーダルの埋め込み空間が構築されます。
学習したモデルを用いて音楽を推薦する際の概要を次の図に示します。
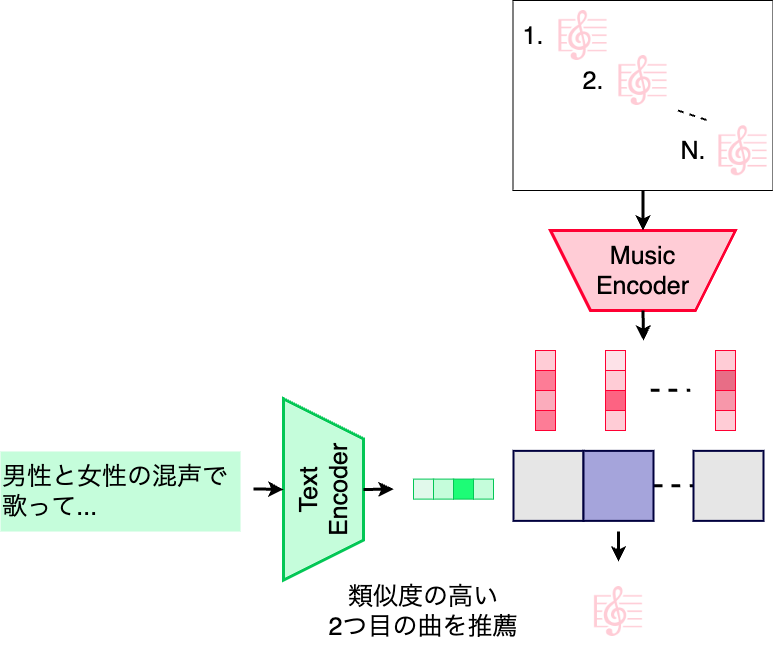
推薦時は、音楽データベースの各楽曲を音楽エンコーダに入力し、音楽の埋め込みを計算します。検証に使ったデモでは、この計算は事前に行い、埋め込みのみを保存しています。入力されたユーザーのテキストは、テキストエンコーダへ入力し、得られた埋め込みと各音楽の埋め込みを比較し、cos類似度が大きいものを推薦結果として提示します。
学習に使用したデータとモデル
テキストと音楽の対照学習の先行研究では、英語テキストと音楽で実験が行われています。そのため、英語テキストに基づく音楽推薦のデータセットについては、すでにいくつか整備がされています。しかし、日本語テキストにより音楽を推薦するデータセットは整備されていません。そこで、日本語テキストに基づく音楽推薦のために、独自のコーパスを作成しました。
特徴量を抽出するためのエンコーダは、各ドメインで事前学習されたモデルをファインチューニングさせました。本研究では、音楽エンコーダとしてaudio spectrogram transformer(AST)[3]を用いました。このモデルは先行研究 [1]でも用いられているモデルで、AudioSet [4]という音の大規模なデータセットを用いて事前学習されています。テキストエンコーダとしては、日本語を入力できるモデルを選択する必要があります。しかし、先行研究は英語を対象としていたため、日本語テキストで音楽推薦のための対照学習を行う場合、どのようなテキストエンコーダが適しているかは調査がされていません。そこで、私たちは、日本語の意味抽出能力の異なる2つのテキストエンコーダを比較して使用しました。1つ目は、東北大から公開されている日本語BERT(cl-tohoku/bert-base-japanese)です。このモデルは、日本語テキスト中のある単語を周囲の単語から予測するように学習された基本的な言語モデルです。もう1つは、pkshaから公開されているGLuCoSE(pkshatech/GLuCoSE-base-ja)です。GLuCoSEは、��複数の自然言語 処理タスクを組み合わせて学習された言語モデルであり、日本語の意味検索タスクで他の言語モデルよりも優れた性能を示しています。本研究ではこの2種類をテキストエンコーダとして比較しました。
性能の評価
学習した音楽推薦モデルの性能を評価するために、独自コーパスにおけるテキストから音楽を推薦した際のrecall@1,recall@5,recall@10,mean average precision@10(mAP@10),median rankの5つの指標を評価しました。いずれも推薦結果を評価するために用いられる代表的な手法です。次の表に、テキストエンコーダを変えた場合の推薦システムの評価結果を示します。また、ベースラインとして、ランダムに楽曲を推薦した場合の評価結果を示します。なお、評価セットには、学習セットと検証セットに含まれていない1687曲を使用しています。
| 推薦手法 | テキストエンコーダ | recall@1 ↑ | recall@5 ↑ | recall@10 ↑ | mAP@10 ↑ | median rank ↓ |
|---|---|---|---|---|---|---|
| クロスモーダル埋め込みの類似度により推薦 | 日本語BERT(cl-tohoku/bert-base-japanese) | 17.19 | 38.17 | 46.35 | 25.88 | 14 |
| GLuCoSE(pkshatech/GLuCoSE-base-ja) | 20.27 | 43.27 | 53.23 | 30.07 | 8 | |
| ランダムに推薦(ベースライン) | N/A | 0.06 | 0.30 | 0.59 | 0.17 | 844 |
まず、どのテキストエンコーダを使用した場合も、ランダムに推薦した場合と比較するといずれの推薦指標の値も大きく上回っています。日本語テキストと音楽の対照学習により、推薦に有用なクロスモーダル空間が構築されたことが示されます。次に、テキストエンコーダの違いを比較した場合、いずれの指標においても、GLuCoSEを用いた場合の推薦結果が日本語BERTの場合よりも上回っていることがわかります。したがって、テキスト中の意味情報を獲得する能力の高いエンコーダは、 音楽とテキストの対照学習にも有効であると考えられます。
テキストの違いに対する頑健性の課題
推薦モデルのテキスト内容の違いに対する頑健性を評価するために、別のデータセットでも評価を行いました。しかし、先述したように、日本語テキストと音楽の従来のデータセットは存在しません。そこで、英語テキストと音楽のデータセットであるMusicCaps [5]のテキストを日本語訳することで、疑似的に日本語テキストと音楽の外部評価セットを作成しました。外部評価セットはMusicCaps中の419曲を用いました。次の表に、独自コーパスで学習し、MusicCapsで評価した際のmedian rankを示します。また、同表に独自コーパスの3分の1程度のサイズであるMusicCapを英語で学習し、英語で評価した場合の結果を示します。なお、英語のテキストエンコーダとして、標準的なBERT(bert-base-uncased)を用いました。
| テキストエンコーダ | 学習データの種類と曲数 | 学習と評価の際の言語 | median rank ↓ |
|---|---|---|---|
| GLuCoSE(pkshatech/GLuCoSE-base-ja) | 独自コーパス(15467) | 日本語 | 137 |
| BERT(bert-base-uncased�) | MusicCaps(4955) | 英語 | 4 |
表で示した通り、評価セットをMusicCapsとした場合、推薦対象の楽曲数が独自コーパスの評価セットよりも少ないにもかかわらず、median rankが8から137へ大きく下がり、独自コーパスで評価していた際と比べ推薦性能が大きく低下することがわかりました。また、MusicCapsを英語で学習した推薦モデルと比較した場合、独自コーパスの学習データ数が多いにもかかわらず、推薦性能は大きく下回っています。この性能低下の要因として、学習時と評価時で入力されるテキストの内容が大きく異なることが挙げられます。
MusicCapsのテキストは、専門家が付与した楽曲の音響的な特徴を記述したテキストで構成されています。例えば、”A female singer sings this beautiful wedding song for the bride.”というテキストが含まれています。一方、独自コーパスはWeb上からしたテキストであり、音響的特徴だけでなくアーティスト名といった音楽に関するメタ情報が含まれています。例えば、「X(ボーカリストの名前)の力強いボーカルが印象的である。」といったテキストも含まれてしまっています。このような音楽のメタ情報は音楽表現ではないため、これらのテキストがノイズとなり、推薦モデルのテキストに対する頑健性を低下させていると考えられます。今後は、この課題の解決のために、テキストのフィルタリングなどを行うことで、汎化性能の向上を目指しています。
おわりに
本記事では、テキストの意味に�基づいて音楽を推薦するデモを紹介し、内部で使用している推薦システムの学習や評価の説明を行いました。推薦性能の向上のために、今後もチームで開発を続ける方針です。
また、LINEヤフーでは、音楽情報処理に限らず、音声認識・合成・強調といった音響信号処理に関するエンジニアの採用を積極的に行っています。この記事を読み、LINEヤフーでの音の研究に興味を持ってくださった方のエントリーをお待ちしています。
採用ページ:https://www.lycorp.co.jp/ja/recruit/
参考文献
[1] Q. Huang et al., “MuLan: A Joint Embedding of Music Audio and Natural Language”, ISMIR, 2022.
[2] S. Doh et al., “Toward Universal Text-To-Music Retrieval”, ICASSP, 2023.
[3] Y. Gong et al., “AST: Audio Spectrogram Transformer,” Interspeech, 2021.
[4] Jort F. Gemmeke et al., “Audio set: An ontology and human-labeled dataset for audio events,” ICASSP, 2017.
[5] A. Agostinelli et al., “MusicLM: Generating music from text,” arXiv, 2023.


