こんにちは。Site Operation本部の深澤と小林です。普段は同じチームのメンバーとしてデータセンターネットワークの運用などを担当しています。
2024年1月17日(水) ~ 19日(金) に開催された JANOG53 Meeting IN HAKATA にて「データセンターネットワークでの輻輳対策どうしてる?」というタイトルで登壇をしました。
この登壇では、データセンターネットワークの輻輳に関する技術や課題、実際にHadoopを用いて行った輻輳制御の検証結果をお話しさせていただきました。
今回は、登壇の内容や質疑応答を書き起こし記事としてレポートしたいと思います。
また、質疑応答でいただいたものを参考に追加検証を行いましたので、そちらの結果を共有もいたします。
1.1. データセンターネットワークと輻輳制御
最初に、この発表を行った背景について解説します。
LINEヤフーは大規模なインフラをオンプレで運用する企業です。
さまざまなサービスを提供するためのアプリケーションやミドルウェアを含むシステムが、データセンターの共通の物理ネットワーク上で通信しています。
これまでのデータセンターネットワークは、クラウドサービスために帯域・拡張性・可用性を追求しアプリケーションのパフォーマンスを最大化する目的で設計されてきました。

アプリケーションのパフォーマンスを決定づけるネットワークの重要な要素は3つあると私たちは考えています。
- Topology
- Routing
- Flow/Congestion Control
まずネットワークのトポロジーで、そのネットワーク全体での転送容量(キャパシティ)と拡張性が決まります。
次にルーティングプロトコルによって、そのトポロジー上の伝送路(パス)をどのように効率的に利用し、冗長性を担保するかが決まり、
最後にフロー制御・輻輳制御(ここではまとめて輻輳制御と記載します)によってパケットロスと再送を発生させない頑強なパケット転送を実現します。
私たちはこの3つの要素を適切に設計することで、アプリケーションのパフォーマンスを最大化できると考えています。
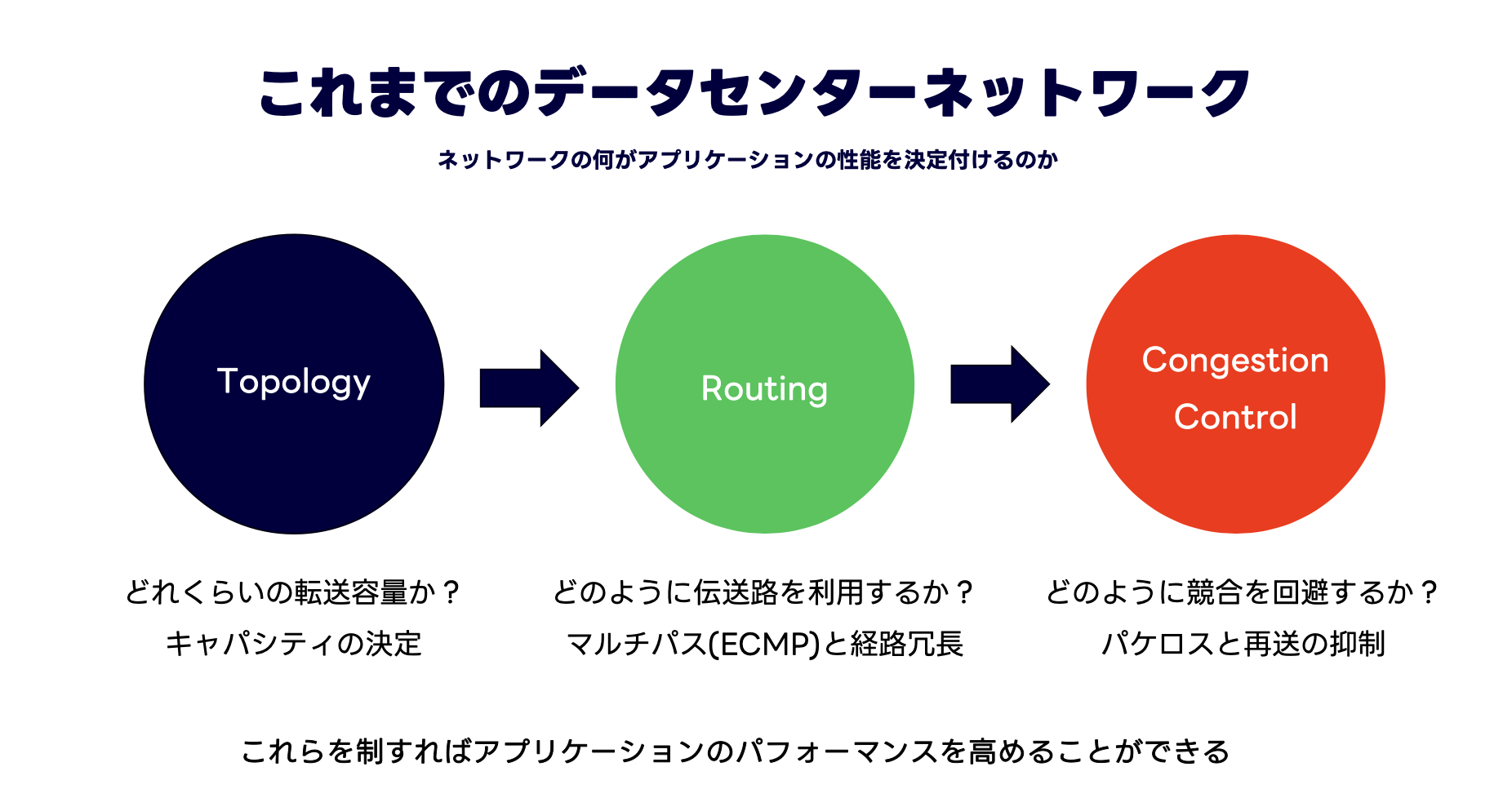
トポロジーとルーティングについては、ClosトポロジーとBGP in DC(RFC7938)が課題を解決してきました。
最後の輻輳制御が現在最もホットな課題になっています。
データセンターネットワークの輻輳と対策について語る上で、最初にデータセンターネットワーク上のどこでどのような輻輳が発生するのかについて説明します。
データセンター上での輻輳ポイントは大きく3つに分類されます。
- In-cast Congestion
- 複数の送信元が1つの宛先にデータを同時に送信する多対⼀の通信
- 受信側バッファでtail dropが発⽣する
- 現在のデータセンターネットワークで問題になりやすい
- Out-cast Congestion
- 特定の出⼒キューが総リンク帯域幅を超える速度でデータを送信するときに発⽣する
- 送信元が特定されるため対応は⽐較的容易
- Fabric Congestion
- 不均衡なトラフィック分散やフローの偏り によってファブリック内のバッファでパケットロスが発⽣する
- パケットヘッダのハッシュに依存しない分散方式での対策が推奨される
- (スイッチファブリックモジュール内の輻輳もありますが、ここでは機器間のリンクの偏りをFabric Congestionと記載します)
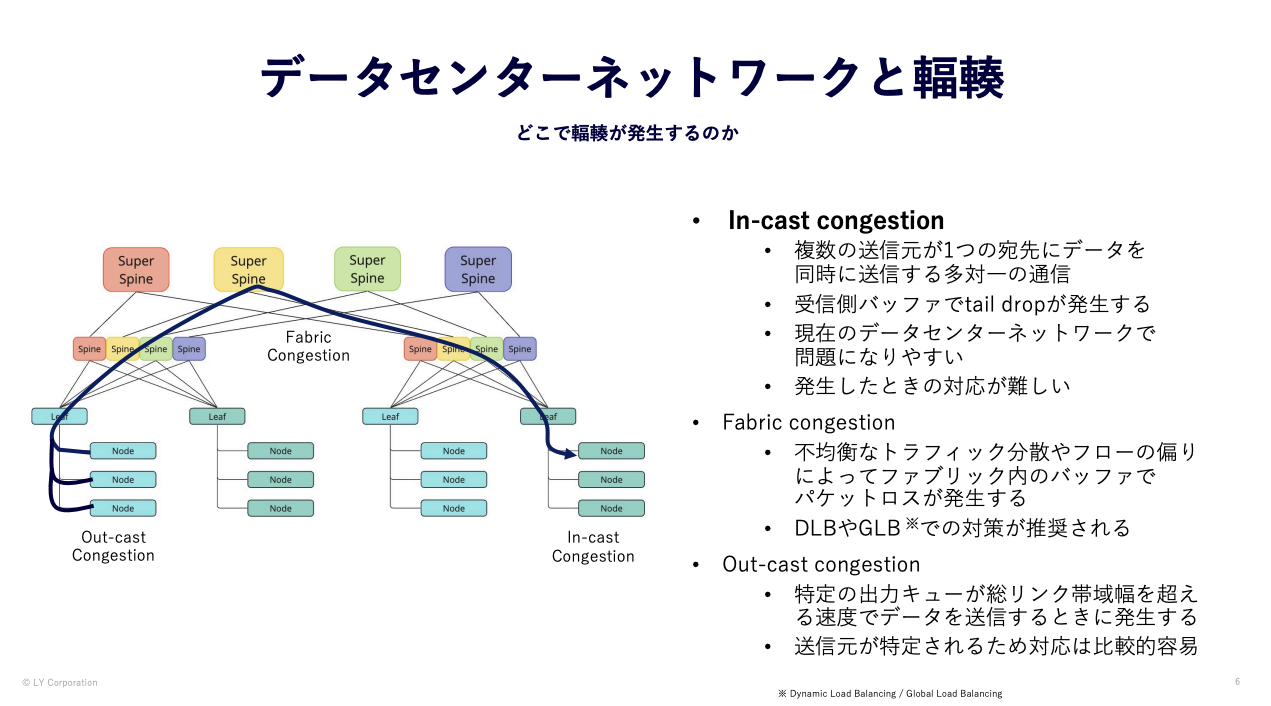
特に問題になりやすく同時に対策が難しいのが、In-castの問題です。
In-castは複数のサーバから特定のサーバへのMany-to-One(多対一)の通信によって競合が発生する問題で、これはデータセンターネットワークの通信の特性上、発生そのものを防ぐことは困難です。
LINEヤフーのデータセンターネットワークでもIn-castは日常的に発生しています。
もう1つの観点に、どのようなフローが輻輳を起こすのかというものがあります。
データセンタートラフィックには二峰性のあるフローが存在します。
- Mice Flow
- 存続期間が短く低レートな通信
- データセンターのフローの⼤部分を占めるが、総トラフィック量の1~2割程度
- 遅延の影響を受けやすく、クエリや制御メッセージで構成される
- アプリケーションの性能低下を防ぐため、パケットロスを最⼩限またはゼロにする必要がある
- Elephant Flow
- 存続期間が⻑く⾼レートな通信
- データセンターの総トラフィック量のほとんどが少数のElephant Flow
- バックアップや分散処理などの⼤規模なデータ転送が該当し、⾼いスループットを必要とする
データセンターネットワークでの輻輳は、このElephant Flowが占有するリンクやバッファに先述のIn-castの通信が競合することで発生します。
そのため、ネットワーク運用者としてさまざまなアプリケーションのワークロードに対して最大のスループットを公平に提供する必要があります。
つまり輻輳対策にはEnd-to-Endのホストでの輻輳制御アルゴリズムの調整、もしくはそれに連動するスイッチ側でのバッファ制御が必要です。
私たちのワークロードで現在この輻輳を起こす通信の代表的なものにHadoopがあります。Hadoopの通信の特性上、In-castは避けることはできません。
利用可能な帯域を最大限活用して並列処理を行う思想で設計されているためです。
そういった背景から、Hadoopクラスタのネットワークにはバッファサイズの大きい機器を採用した専用ネットワークを通常のクラウド基盤のネットワークとは別に構築してきました。
スイッチ上のバッファでIn-castをある程度吸収することで、ホスト側やスイッチに追加の設定を行わずに運用負荷を下げる目的でのこの戦略はこれまではうまく機能していました。
しかしクラスタが大規模になるにつれてネットワークにも追加の投資が必要になり、他と異なる構成のネットワークのサイズが大きくなる問題が浮上しました。
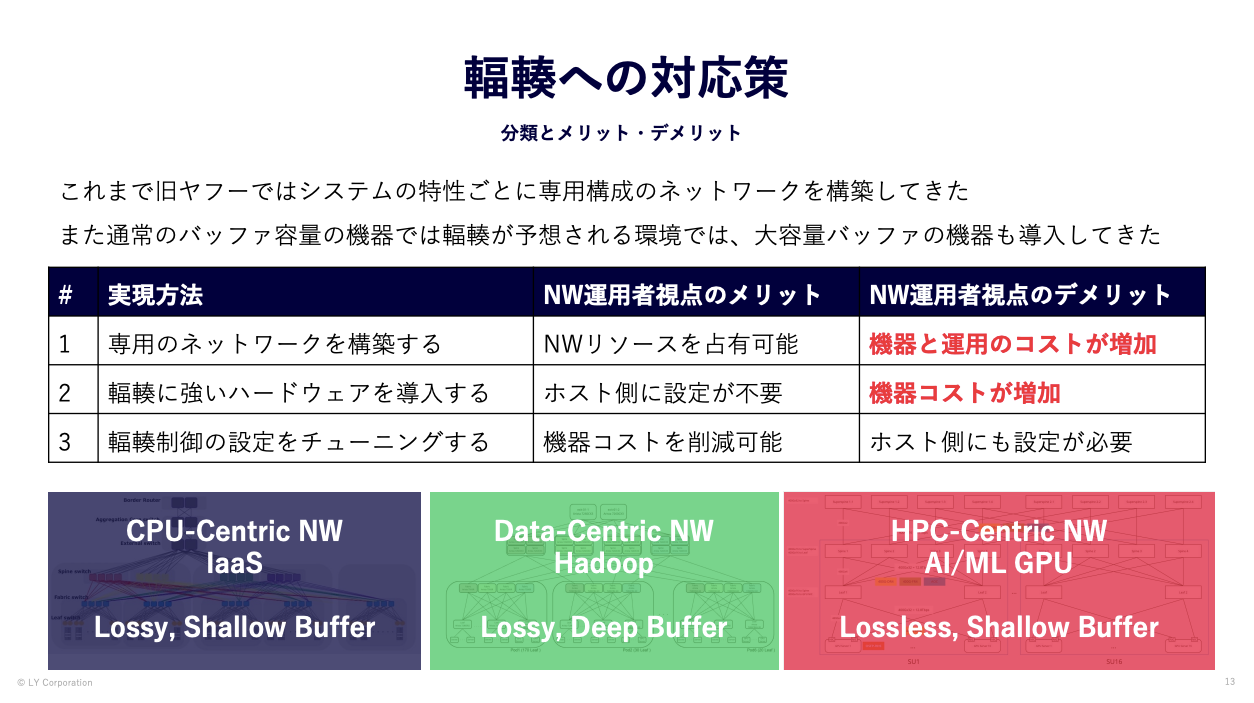
私たちのモチベーションとして、
- ハードウェアや構成・設定のバリエーションを増やしたくない
- 可能な限り構築・運⽤のコストパフォーマンスの⾼い標準構成を定義したい
- 今後の機種選定やconfiguration, コスト算出の根拠となるデータが欲しい
があります。理想は単一の標準構成とハードウェアであらゆるワークロードを収容し、ジョブ完了時間を短縮することです。
そのために、まずは今運用しているネットワークで何が起きていて、どのような選択肢があるのかを検証を通して可視化することにしました。
検証を通してデータセンターネットワークの輻輳制御について再考することで、これからのデータセンターネットワークをより強固かつコストパフォーマンス高いものにしたいというのがこのプログラムの背景です。
輻輳制御の検証をするにあたって、各手法を整理します。
私たちはスイッチ側のバッファ管理の観点で輻輳制御を下記のように分類しました。
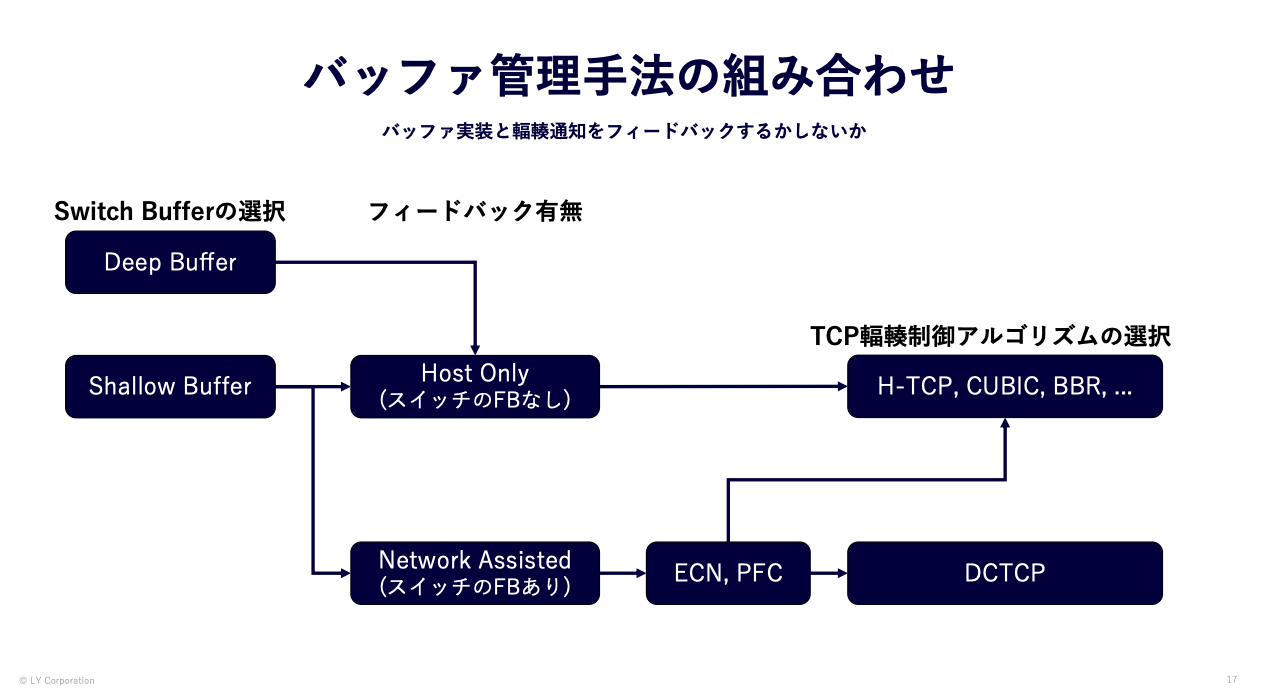
スイッチ内部のバッファ制御の話と外部の制御の話がありますが、
- スイッチのバッファ実装の選択
- スイッチからホストへの輻輳フィードバックの有無
- ホストのTCP輻輳制御アルゴリズムの選択
で分類しています。
1つ目がスイッチのバッファ容量の選択でDeep Buffer のモデルか Shallow Bufferのモデルかです。この選択によって、その後の組み合わせが変わると仮定しました。
2つ目がスイッチのバッファ輻輳をホストに通知するNetwork Assistを行うかどうかです。何もしない場合はそのままホストの輻輳制御に任せる形です。ネットワーク側がアシストする場合は、ECNなどを用いてホストと連携するものです。これは一般的にバックプレッシャと呼ばれる仕組みです。
3つ目がホストのTCP輻輳制御アルゴリズムで、この違いで差が出るかどうかという点です。標準的な輻輳制御アルゴリズムと、データセンター向けに開発されたアルゴリズムで差が出るかどうかを確認することにしました。
Deep Bufferの機器でもECNなどネットワークアシストの機能を設定できますが、一般的にそのような設定をしないためにDeep Bufferを現場では導入していると理解しているためこのような形になっています。なので、Deep Bufferとバッファのチューニングを実施したShallow Bufferの機器でのアプリケーションパフォーマンス(ジョブ完了時間)を比較することにしました。

個別の技術について深く解説するにはこのTech Blogは既に長すぎますので発表の動画をご覧になっていただくか、各自で調べていただけると理解が深まると思います。
1.2. Hadoopを⽤いた検証
輻輳制御の検証をするにあたり実際のHadoop環境を利用して検証を行いました。
なお、検証では
- ベンダー依存の機能を用いた比較
- Lossless が要求されるネットワーク
に関しては検証を行っていませんのでご了承ください。
まず、Hadoop とはオープンソースの大規模な分散ソフトウェアです。(参考:Apache Hadoop)
Hadoopを用いて輻輳制御の検証を行った理由としては、実際のHadoopの環境でTCP In-castが発生しているためです。
実際の環境で、サーバポートで定常的に20MBを超えるBufferが使われており、ときには100MB近く使用されています。
また、赤枠のIngress部分を見ていただけるとわかる通り、複数の送信元ポートから1つのポート対して通信をしているのがわかります。

これはHadoop上でMapReduceという分散フレームワークの処理が行われているためです。
MapReduceの処理の過程で多対一の通信が発生しており、TCP In‐cast が発生しうる通信が行われています。
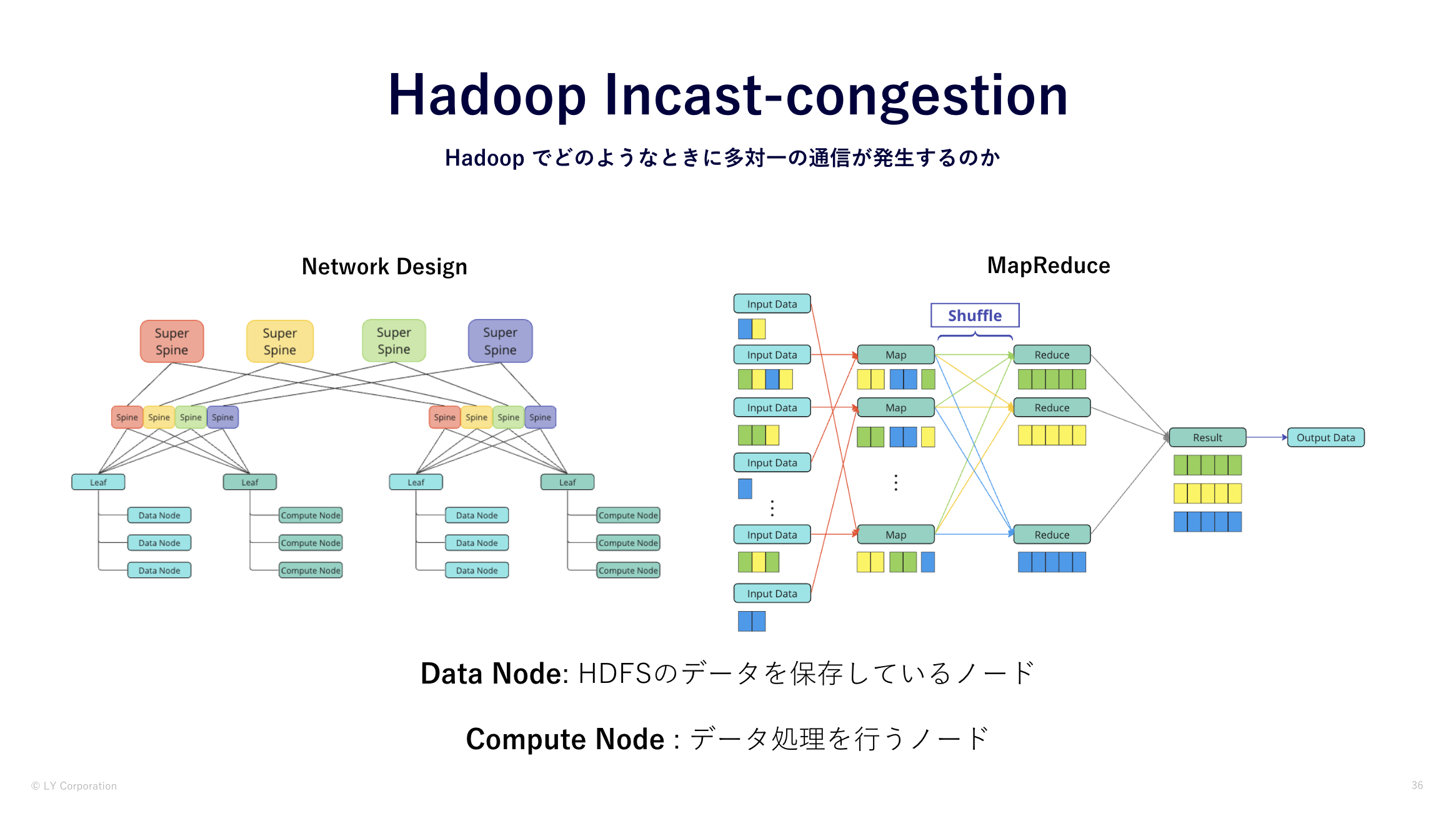
1.3. 検証構成
検証では、弊社のHadoopチームが利用している検証用のHadoopクラスタを利用しました。
この検証環境は商用環境とサーバ・ネットワークともに同じハードウェアで構成されており、 設定に関しても商用環境とほぼ同じの設定になっています。
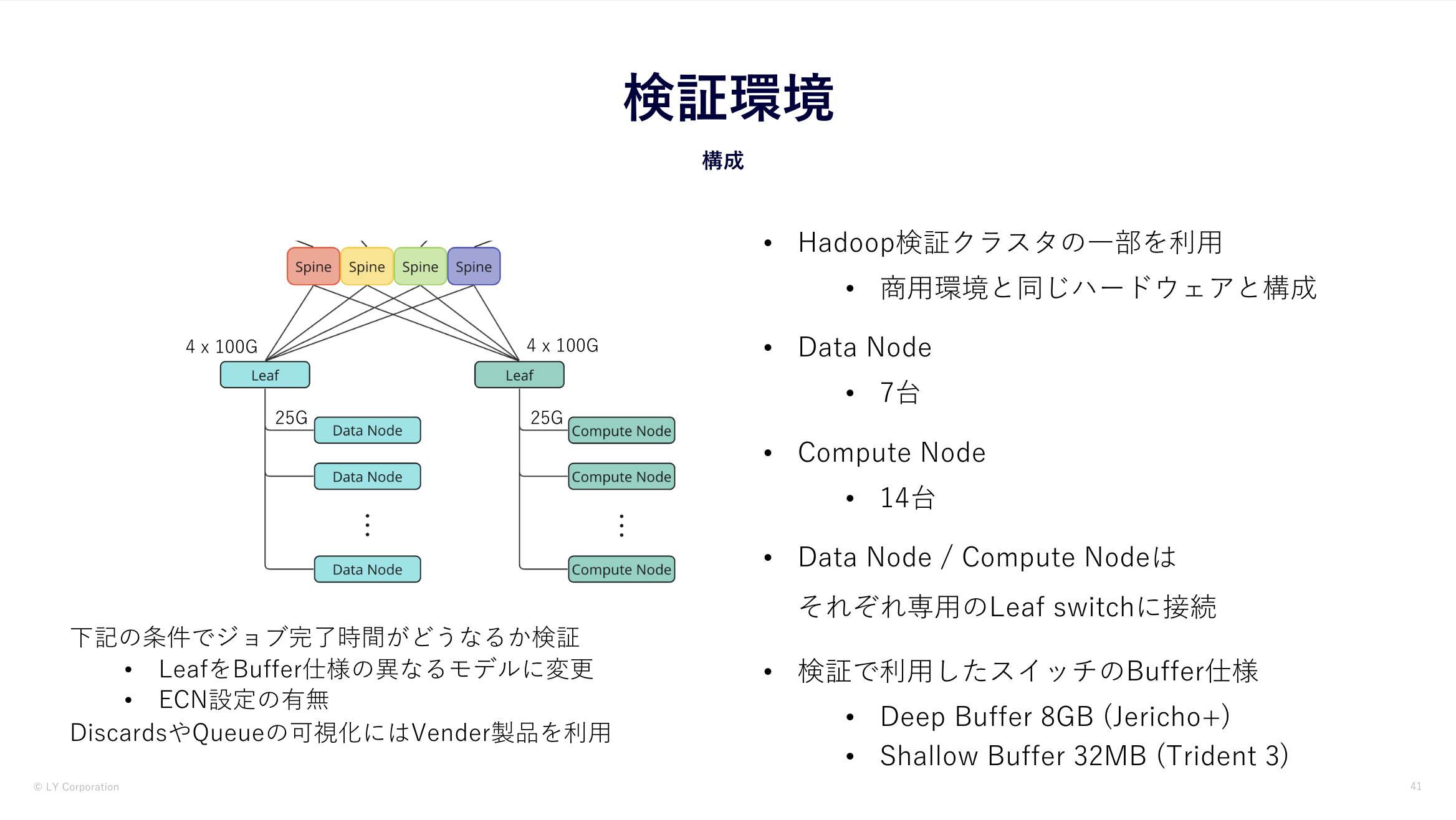
検証環境でTerasortというHadoopに標準搭載されているHadoopのベンチマークのジョブの実行をしました。
また、Hadoopのジョブの実行時は
- 処理フレームワーク
- MapReduce
- Tez (MapReduceに比べてIn-castの通信が少ない)
- データサイズ
- 10GB (低負荷)
- 200GB (高負荷)
- 実行環境
- トラフィック負荷なし
- キューの競合のない状態で完了時間がどの程度か確認するためジョブのみ実行
- トラフィック負荷あり - Compute Node間でトラフィック(10~25Gbps)を流しながら実行
- 実際の環境で複数のジョブが実行されている状況を想定し計測
- トラフィック負荷なし
といった条件に加えて、4つの検証パターンでHadoopのジョブの完了時間を比較しました。
- Deep BufferとShallow Bufferの単純比較 (ECNの設定なし)
- Network AssistがないHost Onlyな輻輳制御でDeep BufferとShallow Bufferのパフォーマンス検証
- ECN 設定の有無の比較
- Network AssistとしてShallow BufferでECNを設定した場合の輻輳制御の効果を検証
- ECN+PFC と PFCのみ の比較
- Network AssistとしてShallow BufferでECNに加えてPFCの設定の必要性を検証
- サーバの輻輳制御アルゴリズムの違いの比較
- サーバ側の輻輳制御アルゴリズムをNetwork Assist(ECN)と密接に連携させた場合の効果を検証
- この検証では、サーバのECNの設定をH-TCPとDCTCPで性能比較を実施
- H-TCPはHadoopチームが過去に検証し採用した設定
- DCTCP は高いスループットを出すことを目的にしているため比較対象として採用
1.4. 検証結果
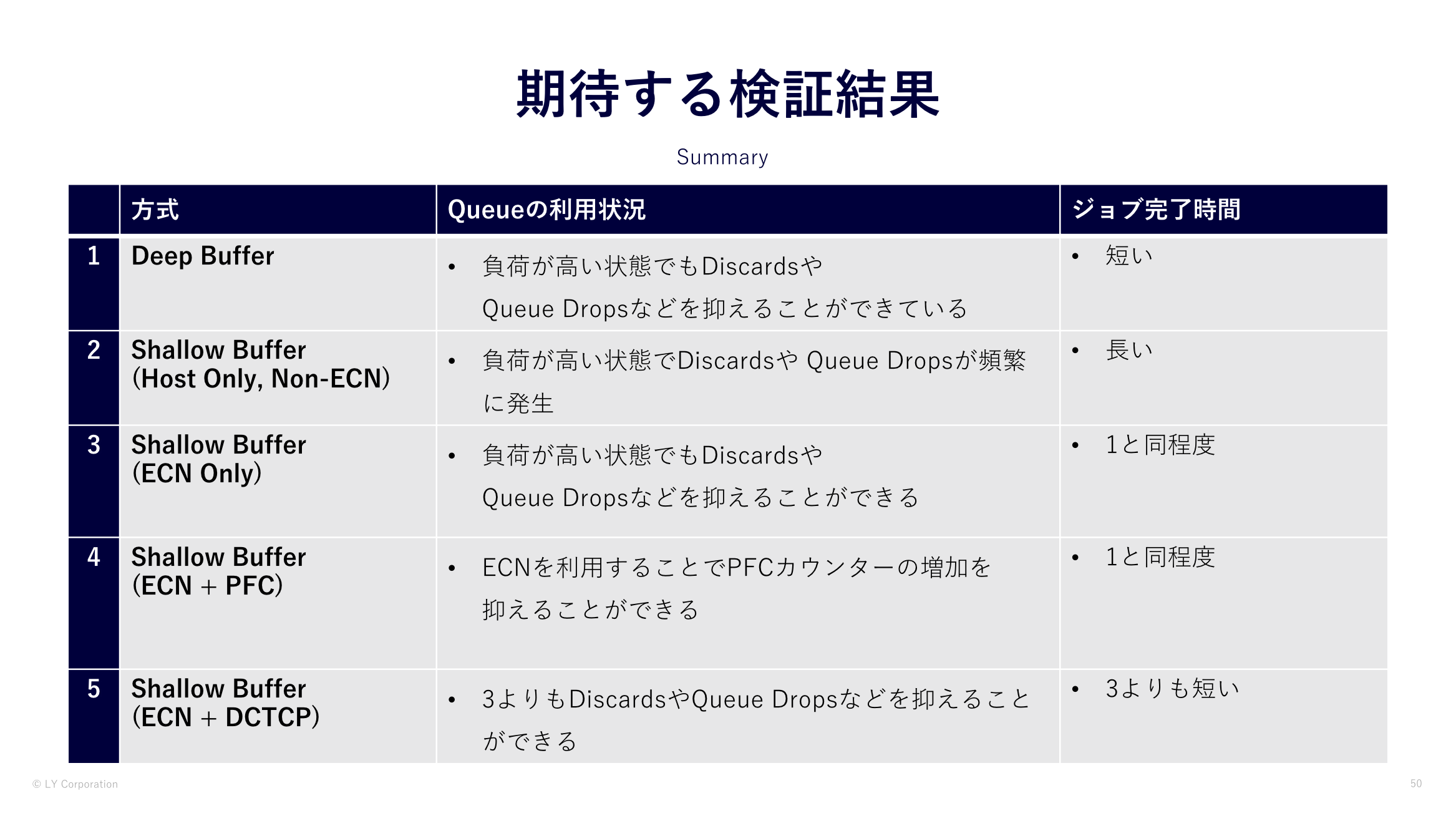
まず検証前に私たちはこのような結果を期待しました。
- Hadoopのジョブの実行時間は Deep Bufferが最も完了時間が短くなり、なおかつDiscardsや輻輳が抑えられる
- Shallow BufferはDeep BufferよりもHadoopのジョブの実行時間が長くなってしまい、ECNの設定をすることでDiscardsや輻輳が抑えられるよう
- Shallow BufferでECNの設定をすることで、Discardsや輻輳が抑えられるようになり、Deep Bufferの結果に近づく
- DCTCPはH-TCPよりも完了時間が短い結果になる
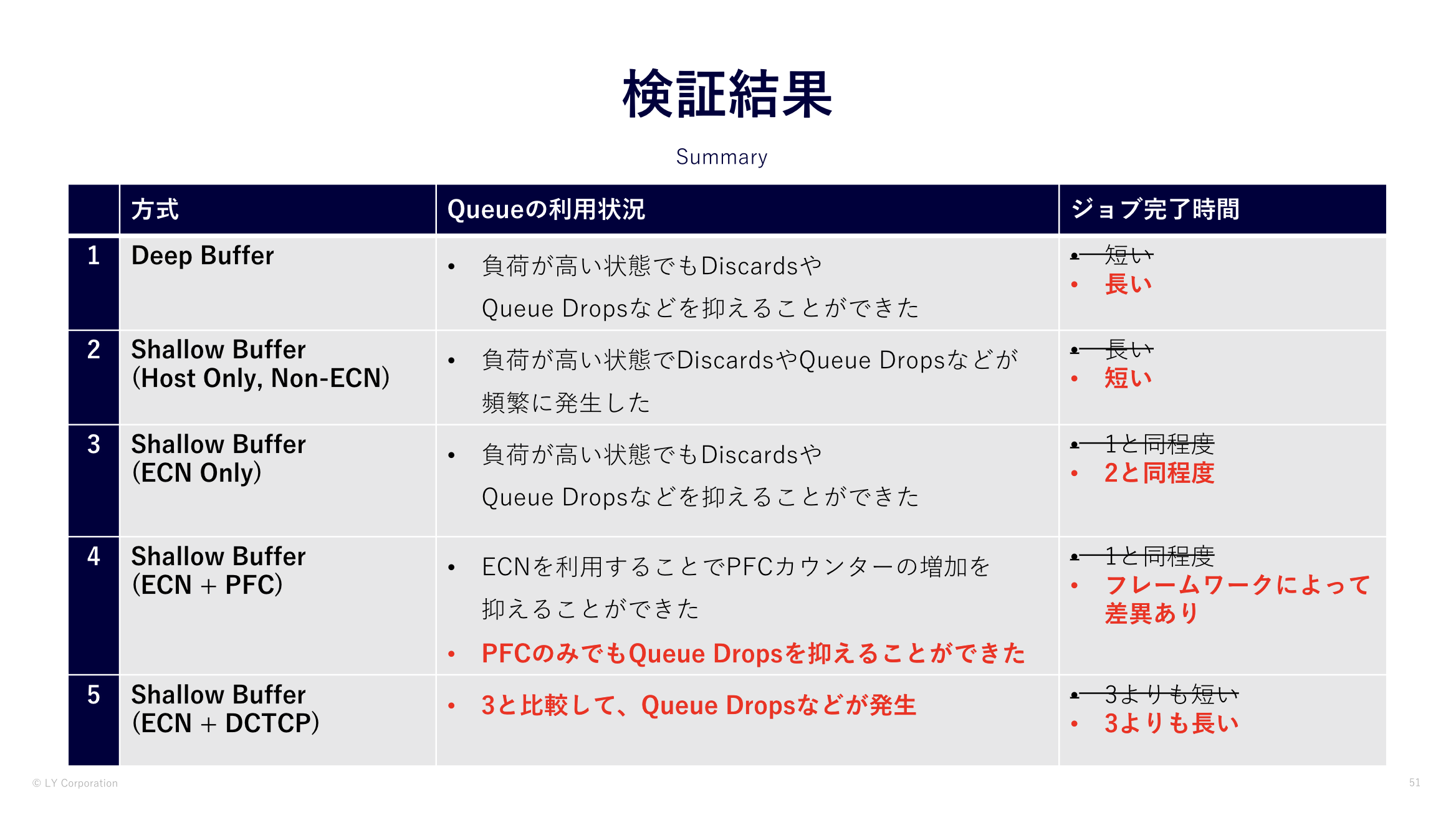
しかし、検証の結果は私たちの予想を大きく違うものになりました。
- Deep Bufferは設定などしなくてもShallow BufferよりもDiscardsや輻輳が抑えられる
- Hadoopのジョブの完了時間はShallow Bufferが最も短くなり、Deep Bufferが長い
- Hadoopのジョブの完了時間が長くなるのは、バーストが吸収された反面、キューイングの遅延が発生しているのが原因と考えられる
- Shallow BufferはECNの設定をすることで、Discardsや輻輳が抑えられるようになり、設定によるHadoopのジョブの完了時間に影響はほぼない
- DCTCPとH-TCPの比較では、H-TCPの方がジョブの完了時間が短い
- H-TCP が私たちのHadoopでより適している可能性、もしくは今回のECN設定の対象ではない管理系のノードとの通信が影響している可能性がある
各検証パターンのHadoopのジョブの完了時間や考察の詳細については、発表の動画をご覧いただければと思います。
1.5. 考察
検証結果から、Shallow BufferではECNの設定の有無にかかわらず、Deep Bufferと比較してHadoopのジョブの完了時間が短くなりました。
しかし、ShallowではECNの設定をしない場合は、Discardsや輻輳が発生してしまうため、ECNを設定することが望ましいと考えられます。
ただし、ECNの設定をするためにサーバのECNの設定を選択したり、閾値の検討などチューニングを必要とします。

この結果は私たちの
- ハードウェアや構成・設定のバリエーションを増やしたくない
- 可能な限り構築・運⽤のコストパフォーマンスの⾼い標準構成を定義したい
- 今後の機種選定やconfiguration, コスト算出の根拠となるデータが欲しい
というモチベーションに対�して
- 特定用途向けのハードウェアを選択せずに、ハードウェアを標準化できる可能性が高い
- その場合、トレードオフとして特定用途向けの設定が必要になる
- Frontend Fabricの構成について今後標準化していける
と考えています。
1.6. 質疑応答
会場でいただいた質問は以下のとおりです。
Q. ECN・PFC の導入に困っている。メーカーごとにデフォルト設定・閾値が違い、適切なパラメータ設定は悩んでいる。Deep Buffer でソフトウェアリミットをしたか。
A: さまざまなワークロードに対して設定するべき閾値は変わってくる。決めるべき値の根拠がわからない。根拠のために可視化をしたいが SNMPはないと思っている。
Q: 流しているトラフィックとは。
A: 実際の Hadoop のジョブを想定してHadoop上で分散シェルを実行し、In/Out の両方でトラフィックをかけた。実環境よりも負荷をかけていた。
Q: Shallow Buffer だと Queue Drops が起きていたが TCP で再送している?
A: 基本的には再送している。再送すると Hadoop 側でもログが出る。どれくらい出ていたかまでは見きれていない。
Q: ロスの用語の説明とそれぞれの違いを教えてほしい
A: Queue Dropsはバッファで救えなくて漏れている。輻輳はバッファを扱っている。
Q: In Discards と Queue Drops の違いは何か
A: パケットドロップという点は同じ。Queue Drops は Queue から溢れたものが明確なもの。In Discards は I/F から漏れたもの。
Q: サ��ーバ・NIC による違いによって結果が変わると思う。知見を貯めるのが大変。銀の弾丸はないと思うがどうやって調整するか。
A: NW・サーバなどの線引きがなくなってきていて難しい。そのような点が今回のような問題の解決に時間がかかってしまう点。
NW だけではなく NIC などもよく知っている必要がある。うちはこれでうまくやれていますということはない。
Q: 複数のワークロードが乗ったら急に解決が難しくなってくる
A: アプリ側と協力してやっていくことが大事。
Q: データセンターのスイッチ機器で QoS は今までやっていたか
A: やっていない。センターセンタースイッチは単なる土管。
Q: buffer bloat が本当に原因だと決め打ちするためには何を見ればいいか。
A: Deep Bufferの Queue の設定を全てoff にして何か結果が変わるかを見られるとわかるのではと考えている。
Q: Queueに関する設定はできないか。
A: VOQの設定をoffにしたらという点を考えていた。
1.7. 追加検証
質疑応答でいただいたものの中で、「Deep Buffer でソフトウェアリミットをしたか」という質問をいただきました。
これについては私たちも検証している段階でDeep Bufferの機器でソフトウェアリミットないし、バッファやキューに関する設定変更を
することでHadoopのジョブの完了時間に影響するのかを検証したいと考えていました。
特定の設定を変更し、Hadoopのジョブの実行時間に影響があれば、何が影響を与えているかが判��明すると考えていたからです。
そのため、追加検証としてDeep Bufferの機器でキューに関する設定変更を行い、Hadoopのジョブの完了時間への影響を調査しました。
この追加検証では、下記の2パターンを実施しました。
- Fair Adaptive Dynamic Thresholds (FADT) の無効化
- 最大遅延時間の閾値設定の変更
なお、その他の条件にこれまでの検証と比較するため、以下のとおりにしました。
- ジョブのフレームワーク・データサイズ・トラフィック負荷の条件に変更なし
- ECNの設定
- ネットワーク機器は無効化
- サーバはHadoopチームが設定したデフォルト値
- Compute Nodeに接続されているDeep BufferのLeaf switchのみ設定を変更
1.7.1. Fair Adaptive Dynamic Thresholds (FADT)の無効化
Fair Adaptive Dynamic Thresholds (FADT) はバッファの効率的な割り当てを行う機能です。
この機能により、空き状況に基づいてバッファの割り当てをよしなに行ってくれます。
ですので、この機能をオフにすることでジョブの完了時間に何らかの影響があると考えました。
実際の設定は以下のとおりです。
no platform sand voq tail-drop fadt詳しくは BCM88800 Traffic Management Architecture を参照ください。
1.7.2. キューの最大遅延時間の閾値設定の変更
Deep Bufferの機器ではキューを保持する時間の設定を変更できます。
この保持する時間はどれくらい通信が遅延するのを許容するかと同義です。
つまり、この最大遅延時間の閾値を変更することによりジョブの完了時間に影響があると考えました。
今回は、最大遅延時間の閾値をShallow Bufferの機器と同じ値に設定し検証を行いました。
具体的にはデフォルト値の39msから1.875msに変更しました。
実際の設定は以下のとおりです。検証対象のサーバが接続されているポートとUplinkのポートに設定をしました。
tx-queue 1
latency maximum 1875 microseconds1.7.3. 各設定変更による想定される結果
設定変更によるHadoopのジョブの完了時間への影響は下記のように考えました。
- Fair Adaptive Dynamic Thresholds (FADT)の無効化
- バッファの割り当ての機能が動作しないため、ジョブの完了時間が長くなる
- Queue Dropsや輻輳については有効な状態よりも悪化する
- 最大遅延時間の閾値設定の変更
- 遅延時間の閾値をShallow Bufferと同程度に短くしたため、ジョブの完了時間が短くなる
- 短くしたため、Queue Dropsや輻輳が発生する可能性があるが、バッファが深いためShallow Bufferの機種よりも発生しない
1.7.4. 検証結果
まず、Fair Adaptive Dynamic Thresholds (FADT)の無効化です。
トラフィックを流している状態では、200GBのMapReduceおよびTezで何も設定していない状態よりもHadoopのジョブの完了時間が長い結果になりました。
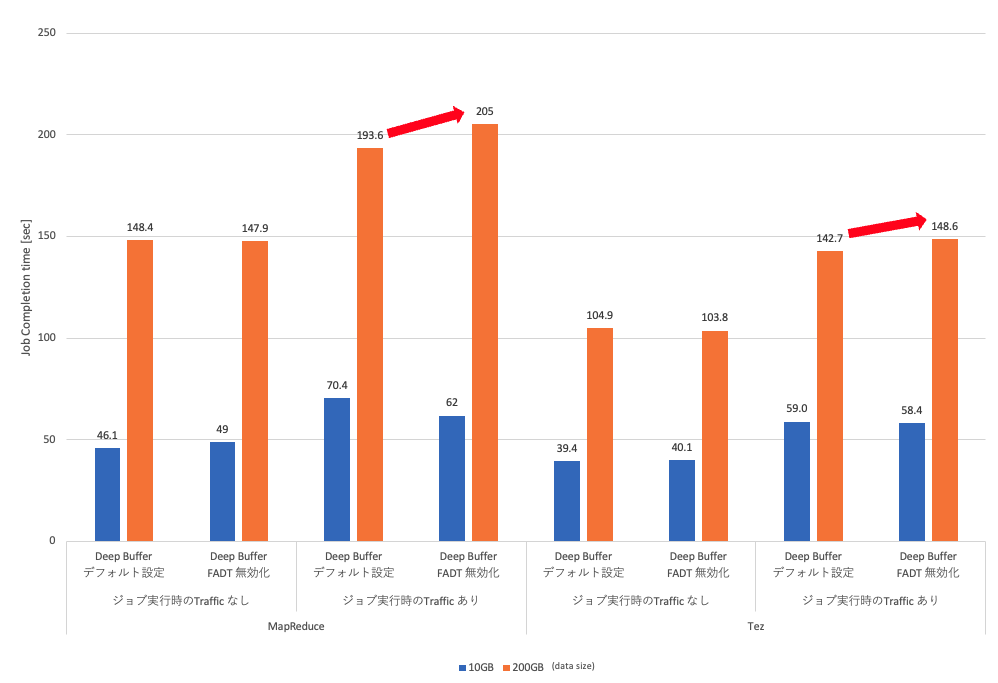
ジョブの完了時間が長くなったものの、Discards やQueue Drops、輻輳の状態は何も設定していない状態と変化はありませんでした。
この結果から、Fair Adaptive Dynamic Thresholds (FADT)の無効化によりジョブの完了時間が長くなっているため、
Fair Adaptive Dynamic Thresholds (FADT)のような制御アルゴリズムが有効に働いていると考えられます。
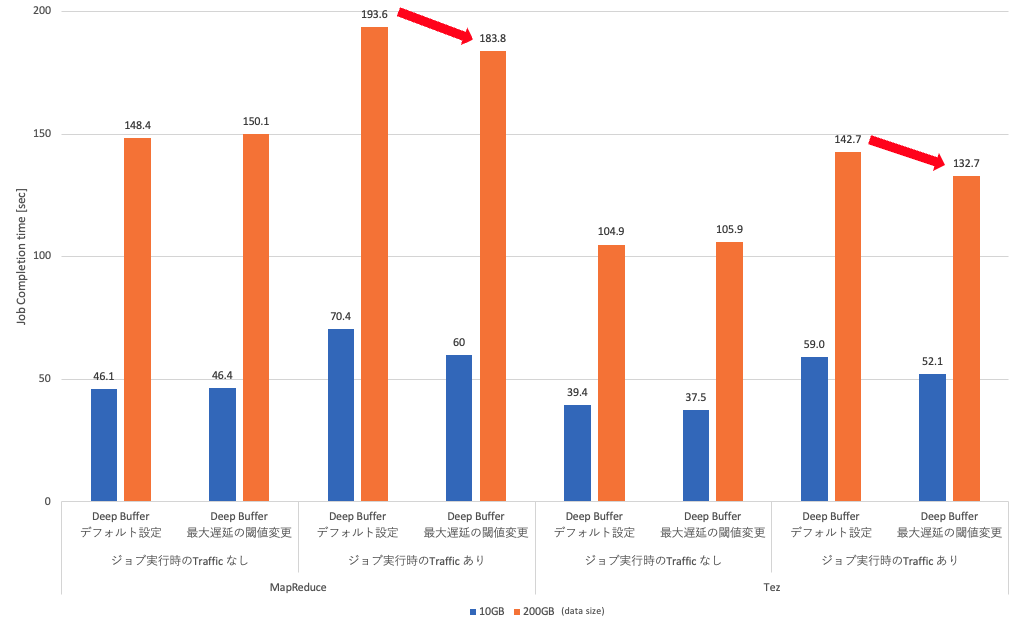
次にキューの最大遅延時間の閾値設定の変更の結果です。
トラフィックを流している状態で、200GBのMapReduceおよびTezで何も設定していない状態よりもHadoopのジョブの完了時間が短い結果になりました。
 しかし、輻輳は発生していないものの Out Discards の発生頻度が増える結果となりました。
しかし、輻輳は発生していないものの Out Discards の発生頻度が増える結果となりました。
これは同条件のECN設定なしのShallow Bufferの結果と近いものです。
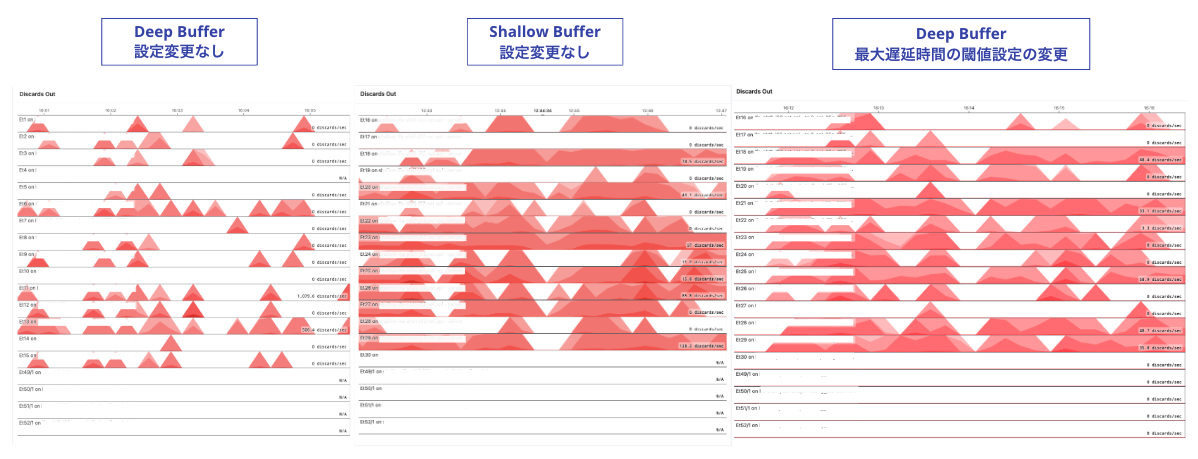 ですが、Queue Dropsや輻輳の状態は何も設定していない状態と変化はなく、ECN設定なしのShallow Bufferの結果とは違うものになりました。
ですが、Queue Dropsや輻輳の状態は何も設定していない状態と変化はなく、ECN設定なしのShallow Bufferの結果とは違うものになりました。
ECNの設定なしのShallow Bufferと追加検証のHadoopのジョブの完了時間を比較です。
最大遅延時間の閾値設定の変更によりトラフィックを流した状態の200GBのMapReduceとTezでShallow Bufferと
同程度のジョブ完了時間になっているのがわかります。
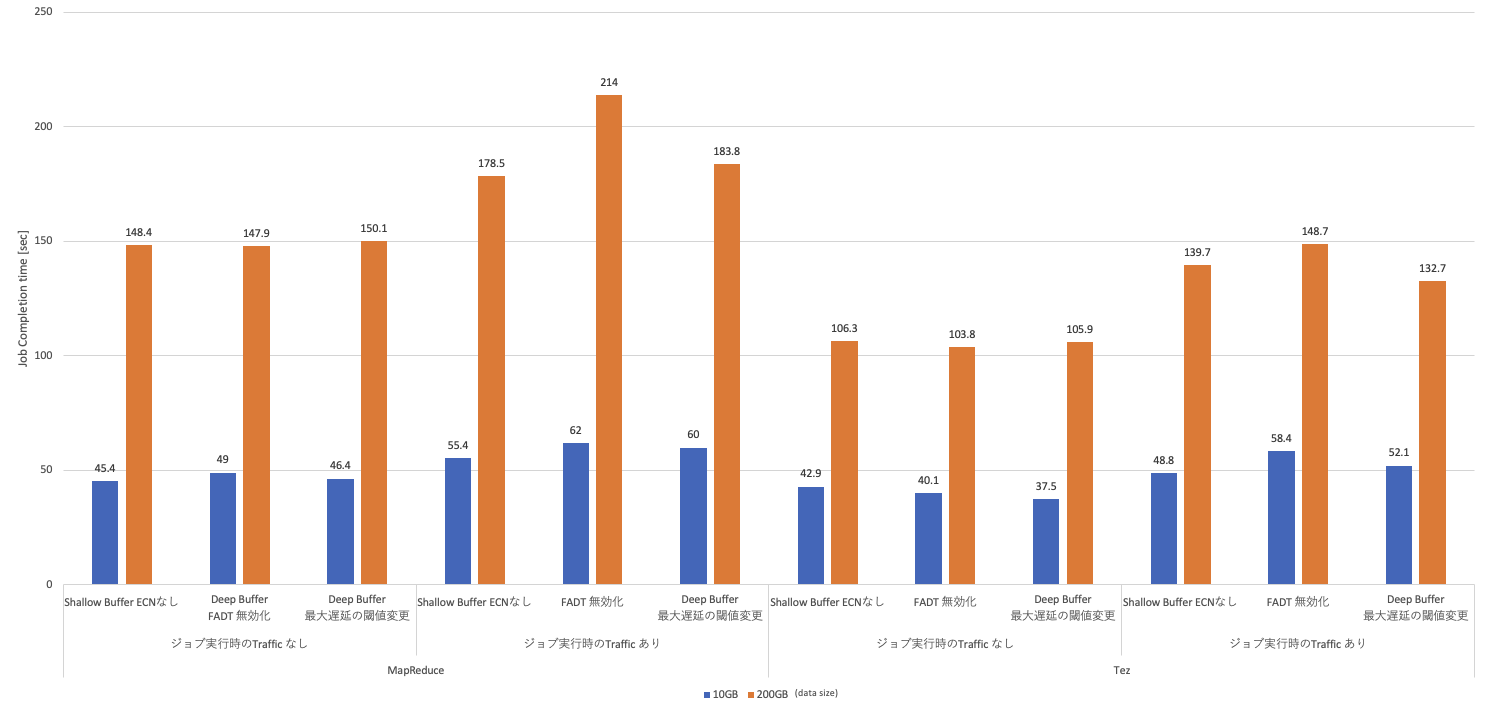
2つの結果のまとめです。ジョブの完了時�間は想定した通りとなりましたが、Queue Dropsや輻輳の状態で少し予想と違った結果になりました。
|
設定変更内容
|
ジョブの完了時間
|
Queue Dropsや輻輳の状態
|
|---|---|---|
|
Fair Adaptive Dynamic Thresholds (FADT)の無効化 | トラフィックを流している状態の200GBで長くなった | 変化なし |
|
キューの最大遅延時間の閾値設定の変更 | トラフィックを流している状態の200GBで短くなった | Out Discardsの発生頻度が増えた |
1.7.5. 考察
追加検証の結果から、
- Fair Adaptive Dynamic Thresholds (FADT)のような制御アルゴリズムが有効に働いている
- Fair Adaptive Dynamic Thresholds (FADT)の無効化によりジョブの完了時間が長くなっているため
- キューの最大遅延時間がジョブの完了時間に影響している
- キューの最大遅延時間を短くすることでジョブの�完了時間が短くなった
- そのため、バッファのサイズではなくキューの最大遅延時間がジョブの完了時間に影響していると考えられる
- ただ、デフォルト設定よりもOut Discardsが発生しているが、TCPの再送で救えておりジョブに影響は出ていない
- 更にTCPの再送がデフォルト設定よりも早く発生しているため、結果的にジョブの完了時間が短くなっている
ということがわかりました。
これまでの検証では、Shallow Bufferの機器にECNの設定を行うことが機器のコストが安く、Queue Dropsや輻輳を抑制した状態で
かつジョブの実行時間も長くならないため、最適な選択ではないかと考えていました。
しかし、この場合はECNの選択やパラメータチューニングが必要なため、その分の運用コストがかかるという課題もあります。
ですが、Deep Bufferの場合はECN設定ほど複雑ではない設定をすることで、完璧ではありませんがQueue Dropsや輻輳を抑制し、
ジョブの完了時間が長くなる傾向を抑えられました。
機器のコストがかかってしまいますが、パラメータチューニングの運用のコストは下げられると考えています。
今後はこれらの結果を踏まえて最適な選択をしていればと思っています。
1.8. おわりに
「データセンターネットワークでの輻輳対策どうしてる?」の登壇内容に加えて、追加検証の共有をさせていただきました。
今回の登壇でさまざまな方と議論��することで、私たちの考えがより深掘りでき、今回の追加検証に繋がったと思っています。
改めて会場やSlackで質疑応答や議論してくださった方々、ありがとうございました。
今後も引き続き、このような検証を続けていきたいと思いますので、また共有できる機会があれば積極的にしていきたいと思います。


