はじめに
はじめまして、東京科学大学情報通信系学部3年の鈴木康太です。2025年8月25日からLINEギフトのSRE(Site Reliability Engineering)チーム��でインターンに参加しました。この記事では自分がインターン期間中に取り組んだことについて紹介します。
LINEギフトが抱えていた課題
SREチームの重要なミッションの1つは、サービスのパフォーマンスを改善し、ユーザーにとってより快適な体験を提供することです。
LINEギフトのサービスをさらに高速化するためには、まず「リクエスト処理のどこに時間がかかっているのか」、つまりパフォーマンスのボトルネックを正確に特定する必要がありました。しかし、これまでの仕組みでは、システムの内部動作を詳細に把握することが難しく、基本的には実際にコードを読むしかない状況でした。
そこで、データに基づいてボトルネックを発見するために、リクエストの処理経路や各処理にかかる時間を可視化する「トレース」の導入から着手しました。
トレースとは
トレースとは、サーバーアプリケーションに対するリクエストがシステムを通過する際に何が起こるかを示すものです。
- Aという処理に0.1秒かかった
- 次にBというデータベースへの問い合わせに0.5秒かかった
- さらにCという外部サービスへの問い合わせをしたら0.3秒かかった
といった、どこでどれだけ時間がかかったかを図のように時系列で正確に把握できます。
このトレースにより、サービス間の呼び出し関係の調査、エラー発生箇所の特定、ボトルネックの発見などができます。
トレースについて詳しくは OpenTelemetryのドキュメント を参照してください。
トレースの導入
LINEヤフー社内にはトレースを収集・集約する基盤が整っていたため、アプリケーション側でトレースをエクスポートする部分だけを実装すればよい状態でした。
今回トレースを導入したアプリケーションはJavaで書かれていたので、OpenTelemetry Java Agentを使用することになりました。使用するには、起動時の設定で -javaagent:path/to/opentelemetry-javaagent.jar を追加するだけです。これでプログラムコードに変更を入れることなく簡単にトレースの収集が開始されます。
OpenTelemetry Java Agentは非常に多くのライブラリをサポートしています。データベース(DB)アクセスやHTTPリクエストなどの主要処理に自動でスパンを挿入し、詳細なデータを収集します。このトレースにより、パフォーマンス改善のための調査が容易になりました。
OpenTelemetry Java Agentを導入したことで、もう1つ便利な改善がありました。それは、ログとトレースを紐づけて確認できるようになったことです。すべてのログにトレースID/スパンIDが記録されるようになり、以下のような流れでトレースを確認できるようになりました。
- 気になるログをKibanaで検索する
- ログに記録されているトレースIDをクリックする
- Grafanaの画面に移動し、トレースを確認する
ログとトレースの相互参照が可能になり、問題発生時の調査や原因特定が効率化されました。
ボトルネックの発見と解決
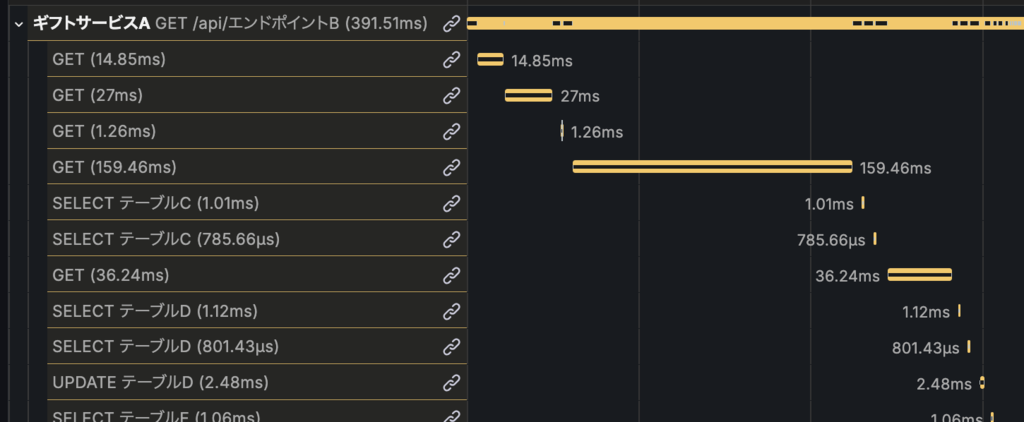
以下の図は、ユーザーの商品閲覧履歴を取得するエンドポイントで、実際にトレースをGrafanaで可視化したものです。
図を見ると以下の3つの処理が繰り返されていることがわかります。
GETSELECTSETEX
これらはそれぞれ商品の画像情報を取得する際に以下の繰り返しを行っていることを示しています。
- Redisキャッシュから情報を取得
- キャッシュヒットしなければDBから取得
- キャッシュに値を保存する
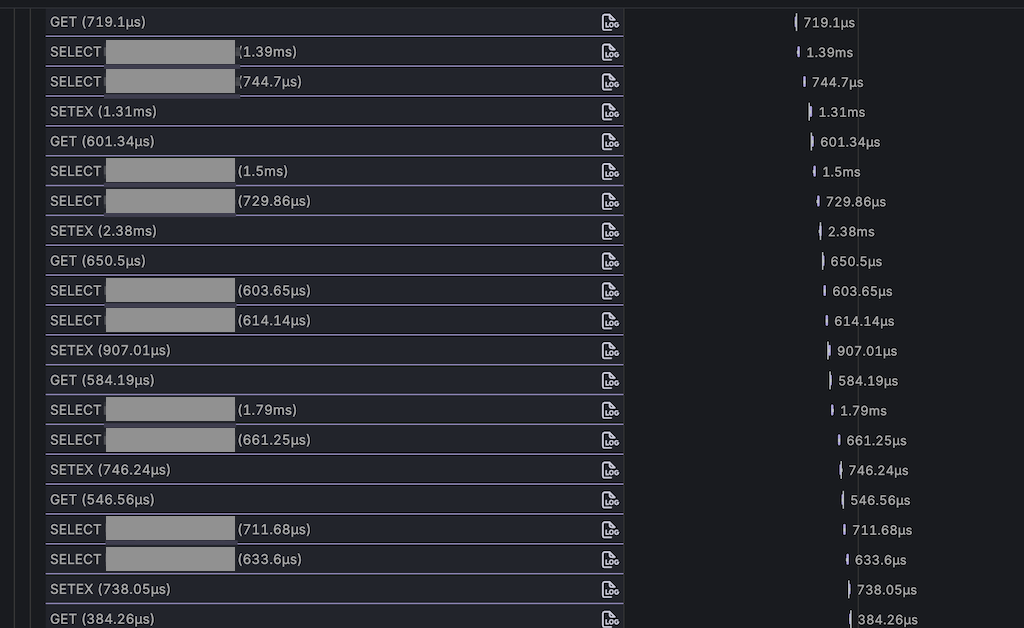
これは典型的なN+1問題です。閲覧履歴は直近100件までを保存していたため、最悪の場合はRedis 200回(GET/SET)+DB 100回のI/Oになります。1件ずつのクエリは軽いのですが、RTT(Round-Trip Time)が積み重なることでレスポンスタイム悪化の原因になっていました。
// 各itemIDに対してこの関数が呼び出される (N+1)
public List<ImageSpec> imageSpecsCached(Long itemId) {
final CacheKey<List<ImageSpec>> cacheKey = IMAGE_SPECS_CACHE_KEY.key(itemId);
// キャッシュから取得
final Optional<List<ImageSpec>> images = redisService.find(cacheKey);
// キャッシュに存在すればそれを�返す
if (images.isPresent()) {
return images.get();
}
// DBから取得
final List<ImageSpec> imageSpecs = imageSpecs(itemId);
// キャッシュにセット
redisService.set(cacheKey, Cache.TTL_IMAGE_SPECS_CACHE_KEY, imageSpecs);
return imageSpecs;
}今回はRedisからのキャッシュの取得、保存に MGET と MSET を用いて一括で処理し、キャッシュミスした場合は IN 句を使ってDBから取得するようにしました。
public Map<Long, List<ImageSpec>> getMultiImageSpecs(List<Long> itemIds) {
if (CollectionUtils.isEmpty(itemIds)) {
return Collections.emptyMap();
}
// 1. 複数のキーを一括で取得する (MGET)
final Map<String, List<ImageSpec>> cachedImages = redisService.mget(cacheKeys);
final Map<Long, List<ImageSpec>> result = new HashMap<>();
final List<Long> missedItemIds = new ArrayList<>();
// キャッシュヒットしたものと、ミスしたものを振り分ける
// ...(処理の詳細は省略)...
if (missedItemIds.isEmpty()) {
return result;
}
// 2. DBから一括で取得
final List<ItemImage> itemImages = itemImageMapper.findAllByItemIds(missedItemIds);
// itemIdごとにグループ化
final Map<Long, List<ItemImage>> itemImagesMap = itemImages.stream()
.collect(Collectors.groupingBy(ItemImage::getItemId));
// キャッシュミスした分の結果を設定
final Map<String, List<ImageSpec>> missed = new HashMap<>();
// ...(キャッシュ用データの準備)...
// 3. 一括でキャッシュに設定 (MSET)
redisService.mset(missed);
return result;
}改善結果
この対応により、対象エンドポイントの95パーセンタイルレスポンスタイムは約200ms(約40%)短縮しました。
以下は改善後のトレースです。
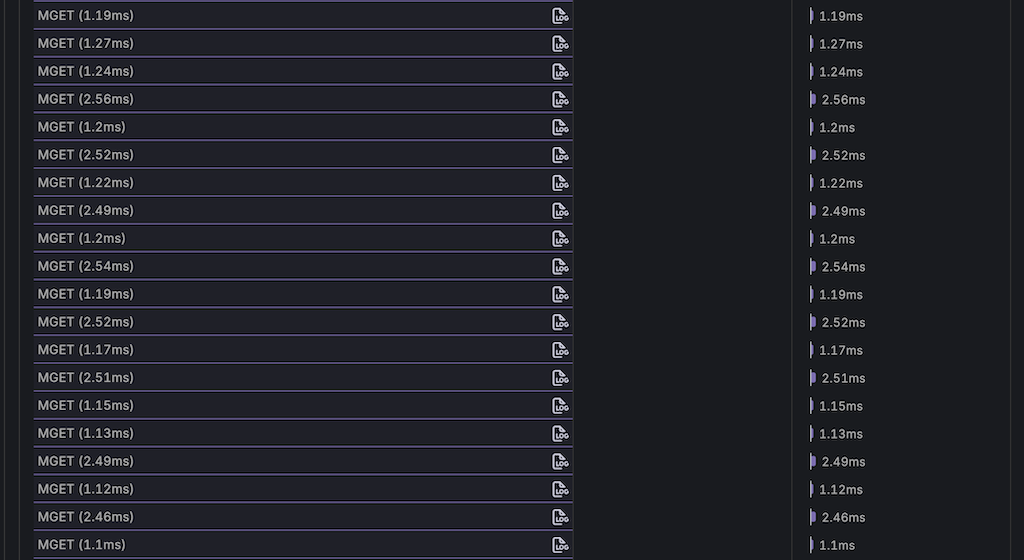
トレースを見ると、改善前のGETの繰り返しがMGETに置き換わっていることがわかります。なぜMGETが複数回実行されているかというと、LINEギフトで利用しているRedis Cluster環境では、各キーがスロットに分割されて保存されているためです。MGETは同じスロットに属するキーしかまとめられません。そのため、実行しているコマンド数はリリース前後で変化ありませんが、使用しているライブラリが自動でキーをスロットごとに分け、非同期に実行します。ライブラリが内部でpipeliningを活用し、効率的にリクエストを送信するため、トレースではMGETが縦一列に並びます。
問題発生
パフォーマンスがよくなったことで安心していたのですが、後から問題を紛れ込ませてしまっていたことに気づきました。複数回実行されていたキャッシュのSETをまとめるために MSET コマンドを使用しました。しかし MSET ではTTL(Time To Live)を設定できず、キャッシュが永続化してしまっていました。このことに気づいたのはリリース後だったため、ホットフィックス(Hotfix)をリリースすることになりました。
LINEギフトではインシデントが発生したときに、ポストモーテムを行います。これは、インシデントの発生原因と今後の改善点を挙げ、チームで共有し、文書化するプロセスです。今回は簡単なポストモーテムを行いました。
- 原因の特定
- TTLをサポートしていない
MSETコマンドを使用してしまった - キャッシュロジックのカプセル化ができていない
- 画像の更新についての動作確認が抜けていた
- TTLをサポートしていない
- 影響範囲
- 商品の画像を変更しても、LINEギフト上では更新されていないように見える
- 対策・改善点
- Redisのメトリクスから「TTLが設定されていないキーの数」を監視し、増加した際にアラートを出すようにする
- キャッシュロジックを見直し、必ずTTLを設定するインターフェースにする
このようにポストモーテムを通じて、ただの反省会にならず、今後似た障害を起こさないための仕組みを考える機会になりました。
最終的な改善結果
MSET コマンドの代わりに、SETEXコマンドをpipeliningを使ってまとめて実行する方法で対応しました。この方法により、MSETのようにネットワーク遅延を抑えつつ、各キャッシュキーに対してTTLを設定できました。
この対応の結果、対象エンドポイントの95パーセンタイルレスポンスタイムは約160ms(約30%)短縮しました。下のグラフは改善リリース前後と1週間前の95パーセンタイルレスポンスタイムの比較です。赤の縦の破線が改善リリースのタイミングを示しています。
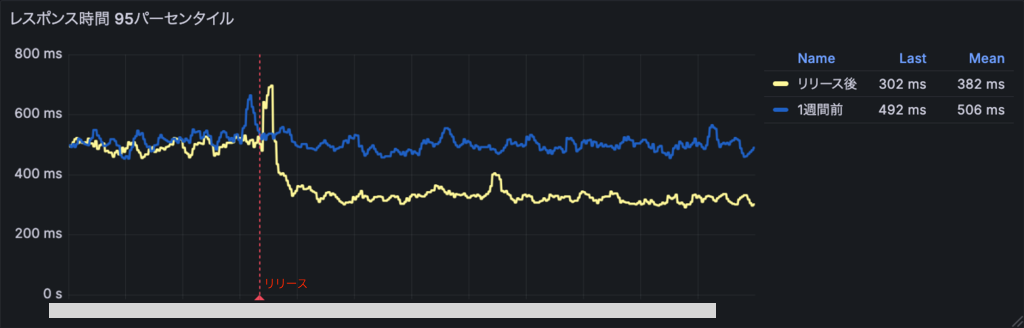
これによりボトルネックだったN+1問題を解消したことで大幅なパフォーマンス改善を達成できました。
さらに、リリース後にRedisのCPU使用率は11.8%から7.75%へ低下し、差分は4.05ポイント(約34%減)であることにも気づきました。下のグラフは先ほどと同様に改善リリース前後と1週間前のRedisのCPU使用率の比較です。赤の縦の破線が改善リリースのタイミングを示しています。
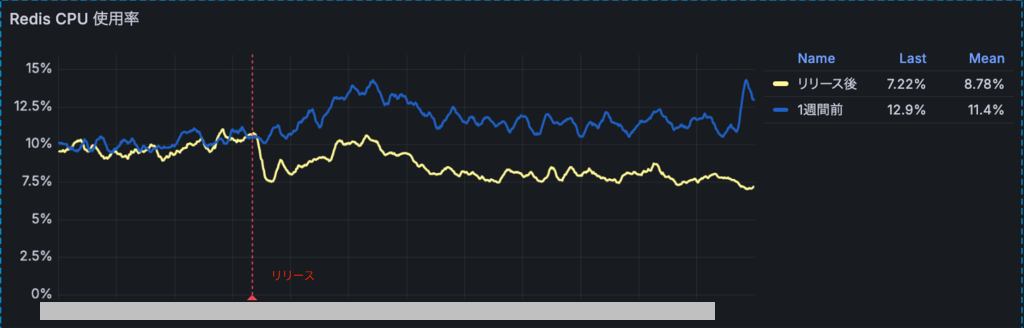
これはRedisのドキュメント にもあるように、pipeliningを用いることでRedis側のシステムコールの回数が少なくなり、コマンドを効率的にまとめて読み書きできるためです。
まとめ
今回のインターンでは、問題を可視化し、それに対処し、結果を確認するというSREの基本を体験できました。途中TTLの設定をし忘れるという失敗もしましたが、その後チームでのポストモーテムを通じて、仕組みで再発を防ぐ方法を考えられたことは、技術的な学び以上に貴重な体験でした。今後もこの経験を活かして、より良いサービス基盤づくりに挑戦していきたいです。
メンターから
鈴木さんのメンターを担当した宇井敬一朗です。
この記事では、インターン期間中に鈴木さんが取り組んだLINEギフトのAPIパフォーマンス改善について紹介しました。
鈴木さんは、トレース導入からパフォーマンス改善まで、一連の流れを短期間で実現してくれました。特に印象的だったのは、トレースという有効な手段を手に入れた後、すぐにボトルネックを発見し、具体的な改善策を実装した行動力です。
モニタリングの過程で鈴木さん自身が、キャッシュにTTLが付与されない設定箇所を確認し、速やかに是正リリースで対応しました。続いて社内手順に沿って振り返りを実施し、再発防止に向けた提案を取りまとめていただきました。自ら検知し、是正に加えて改善提案までつなげた姿勢は、SREに求められる行動だと感じました。
さらに特筆すべき点として、鈴木さんは与えられたタスクだけでなく、自発的にチームの課題を見つけて改善に取り組んでくれました。具体的には、CI(Continuous Integration)においてレビューしやすくなるための仕組みを実装・導入し、チームのコードレビュー環境の向上に貢献しました。このような主体的な姿勢は、インターン生としては非常に頼もしく、チームにとっても大きな価値がありました。
インターン期間は短かったですが、鈴木さんの技術力の高さと学習意欲には目を見張るものがありました。今後のご活躍を期待しています。


