LINEヤフー Advent Calendar 2023の17日目の記事です。
こんにちは。LINEヤフー株式会社で自然言語処理�の開発を担当している伊奈です。
私が属する自然言語処理チームで開発しているテキスト解析 Web API は、Yahoo!デベロッパーネットワークから社外に公開しています。テキスト解析 Web API をより効果的に活用できるように、『テキスト解析 Web API クックブック』を公開しました。
今回はその活用事例集の中から、テキスト解析 Web API の「ルビ振り」と「かな漢字変換」の活用例を紹介します。
テキスト解析 Web API の「ルビ振り」と「かな漢字変換」の使い方
最初に、テキスト解析 Web API の「ルビ振り」と「かな漢字変換」について簡単に紹介します。
テキスト解析 Web API の各機能の入出力のインターフェースをできるだけ共通化するために、JSON-RPC 2.0 を採用しています。具体的には、下記のような入出力インターフェースです。今回紹介する「ルビ振り」や「かな漢字変換」もそれぞれ独自のインターフェースではなく、この共通のインターフェースを利用します。

ルビ振りの機能では、漢字かなまじりの文に、ひらがなとローマ字のふりがなをつけられます。以下の例では、ふりがながついた結果が返却されていることがわかります。

かな漢字変換の機能では、ひらがなの文を文節に区切り、漢字の変換候補を提示します。以下の例では、漢字の変換候補が返却されていることがわかります。

「ルビ振り」と「かな漢字変換」の機能は情報検索でも活用できます。その例を紹介します。
活用例 「ルビ振り」と「かな漢字変換」を用いた「クエリ拡張」
一般的に、ドキュメントは同一の単語でも書き手の表現スタイルにより、ひらがなや漢字など、さまざまな表記で記述されます。情報検索の分野では、この表記の揺れが問題となります。例えば、「薔薇」のキーワードで検索をしても、「ばら」と記載されたドキュメントはヒットせず、見つけられません。
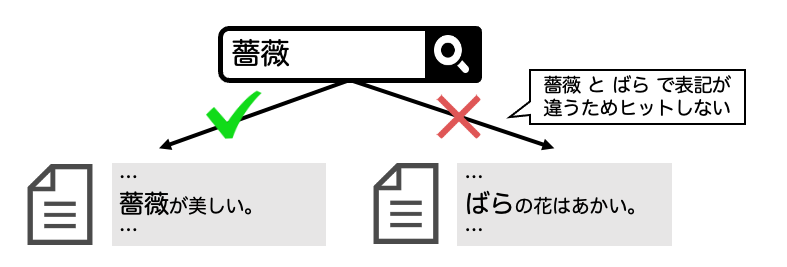
この問題に対処するための手段の一つとして、「クエリ拡張」という方法があります。これは、異なる表記をOR検索で組み合わせ拡張することで、検索範囲を広げる手法です。例えば、前述の「薔薇」に対するクエリを「薔薇 OR ばら OR バラ」に拡張し、検索範囲を広げることで、問題に対処できます。
本記事では、「ルビ振り」と「かな漢字変換」を用いて簡単なクエリ拡張を Python コードで実現します。
Pythonコード
テキスト解析 Web API のルビ振り・かな漢字変換をリクエストするためのメソッドを用意します。
import json
from urllib import request
APPID = 'あなたの Client ID(アプリケーション ID)'
FURIGANA_URL = "https://jlp.yahooapis.jp/FuriganaService/V2/furigana"
KANAKAN_URL = "https://jlp.yahooapis.jp/JIMService/V2/conversion"
# テキスト解析 Web API のルビ振りをリクエストするメソッド
def post_furigana_service(query: str) -> str:
headers = {
"Content-Type": "application/json",
"User-Agent": "Yahoo AppID: {}".format(APPID),
}
param_dic = {
"id": "1234-1",
"jsonrpc": "2.0",
"method": "jlp.furiganaservice.furigana",
"params": {"q": query},
}
params = json.dumps(param_dic).encode()
req = request.Request(FURIGANA_URL, params, headers)
with request.urlopen(req) as res:
body = res.read()
return body.decode()
# テキスト解析 Web API のかな漢字変換をリクエストするメソッド
def post_kanakan_service(query: str) -> str:
headers = {
"Content-Type": "application/json",
"User-Agent": "Yahoo AppID: {}".format(APPID),
}
param_dic = {
"id": "1234-1",
"jsonrpc": "2.0",
"method": "jlp.jimservice.conversion",
"params": {"q": query},
}
params = json.dumps(param_dic).encode()
req = request.Request(KANAKAN_URL, params, headers)
with request.urlopen(req) as res:
body = res.read()
return body.decode()なお、テキスト解析 Web API を利用するには、Client ID が必要です。お手数ですが各自 Client ID を取得してください。サンプルコード内の
APPID = 'あなたのClient ID(アプリケーションID)'を取得した Clinet ID へ置き換えてご利用ください。
上述のメソッドを使用してテキスト解析 Web API のルビ振りとかな漢字変換にアクセスし、対象クエリの「ひらがな」「ローマ字」および「かな漢字候補の一番目」を取得します。これらをクエリ拡張に使用します。
from typing import List
def expand_query(q: str) -> List[str]:
# ルビ振りの結果を取得
res_furigana = json.loads(post_furigana_service(q))
# ひらがなの結果を取得
q_hiragana = "".join([ seg["furigana"] if "furigana" in seg else seg["surface"]
for seg in res_furigana["result"]["word"]])
# ローマ字の結果を取得
q_roman = "".join([ seg["roman"] if "roman" in seg else seg["surface"]
for seg in res_furigana["result"]["word"]])
# ひらがなの結果を用いて、かな漢字変換の結果を取得
res_kanakan = json.loads(post_kanakan_service(q_hiragana))
# 今回はかな漢字変換候補の一番目を利用
q_kanakan = "".join([ seg["candidate"][0] for seg in res_kanakan["result"]["segment"]])
or_words = list(set([q, q_hiragana, q_roman, q_kanakan]))
return or_wordsq = "ブタ肉"
expand_query(q)
# 出力結果
['ブタ肉', 'ぶたにく', 'butaniku', '豚肉']実行例
サンプルのドキュメント集合を用意し、先ほど拡張したクエリで OR 検索を行ってみます。
# サンプルを用意
import pandas as pd
documents = pd.DataFrame({
"text": [
"豚肉と野菜の炒め",
"牛肉のすき焼き",
"ブタ肉の回鍋肉",
"butaniku shabu shabu",
"チキンカレー"
]
})
クエリを拡張せずに検索を行った場合
q = "ブタ肉"
pd_query = f'text.str.contains("{q}")'
documents.query(pd_query)
クエリを拡張して検索を行った場合
q = "ブタ肉"
q_ex = expand_query(q)
pd_query = ' or '.join([f'text.str.contains("{q_i}")' for q_i in q_ex])
documents.query(pd_query)
元のクエリを使用した場合、関連するドキュメントが1件しか見つからなかった��のに対し、クエリを拡張して検索することで、関連するドキュメントを1件から3件に増やせました。
本記事の例は、クエリ拡張の基本を説明するための簡単なものでした。複数のタームを考慮に入れたり、かな漢字変換候補の2、3番目を利用したりするなど、さまざまな工夫が可能です。ただし、クエリを過度に拡張すると、関連のないドキュメントも検索結果に含まれてしまう可能性があるため、その点はご注意ください。
さらに今回使用したルビ振りとかな漢字変換の機能以外にも、クエリ拡張に役立つ機能が存在します。これらを活用して、より高度なクエリ拡張をお試しください。
おわりに
今回はルビ振りとかな漢字変換の活用例「クエリ拡張」について紹介しました。今回使用した「かな漢字変換」は予測変換の機能を持っています。そのため、紹介した「クエリ拡張」以外にも、入力途中のクエリに対して自動的にクエリを補う「クエリ補完」などにも使えますので、ぜひお試しください。
今回紹介した内容は「テキスト解析 Web API クックブック」に含まれています。ぜひご覧ください。
関連記事
これまでのテキスト解析 Web API の記事をまとめました。興味がある方はこちらもどうぞ。


