This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Introduction
Hello. We are Chaeseung Lee and Eunhak Cho of the LINE Plus SRE team, who applied infrastructure as code (IaC) to the in-house cloud service Verda and the in-house monitoring tool (IMON). IaC is a way to declare and manage infrastructure resources required for operations—such as servers, load balancers, domain name service (DNS), and monitoring settings—as code instead of editing them directly through a web UI.
We manage Verda's virtual machines (VMs), load balancers (LBs), domain name service (DNS), Kubernetes resources, and IMON's alert groups, alert rules, and alert monitors using OpenTofu/Terragrunt. About 1,500 resources are currently declared as code, and infrastructure changes for seven services are all applied through pull request (PR) reviews and continuous integration/continuous deployment (CI/CD) pipelines. Differences between code and actual infrastructure are also detected automatically every day and sent as alerts.
It wasn't always structured this way. We had to move roughly 300 virtual machines (VMs), about 160 load balancers (LBs), and about 350 domain name service (DNS) records into code, and consolidate settings that had been managed differently by each team—through the Verda dashboard, scripts, or wiki procedures—into a single Git-based operations automation (GitOps) workflow.
In this article, we share that process: Why IaC was needed, how we imported existing resources, what operational issues we encountered, and how we plan to automate code generation using Slack and AI agents.
Why we adopted IaC
Problems from growing operational scale
Previously, multiple teams managed infrastructure in their own ways. Some teams used the Verda dashboard, some used scripts, and some followed manual procedures documented in documents; record-keeping varied—Confluence (wiki), personal documents, GitHub, and so on.
Although none of these approaches were inherently wrong, as services and resources grew we began to see several common difficulties like those below.
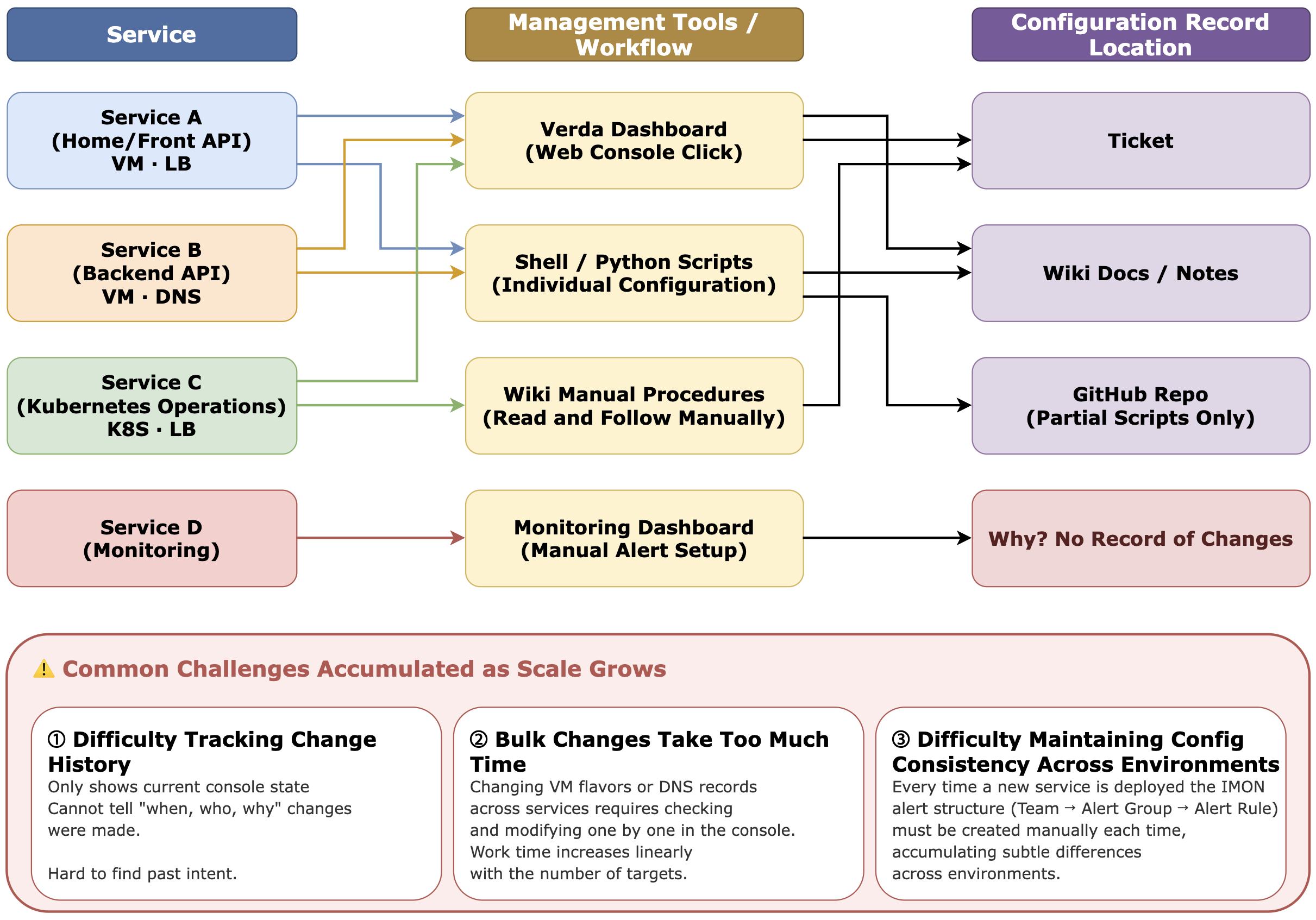
When the number of targets is small, these are manageable operational tasks, but as scale grows the burden accumulates and becomes hard to handle. That's why we decided to manage infrastructure as code. We needed a method to explicitly define resource states, review changes, and repeat the same work automatically.
From console to code — GitOps as the answer
We compared console-based operations and IaC-based operations against the challenges above. The changes we expected for each item are as follows.
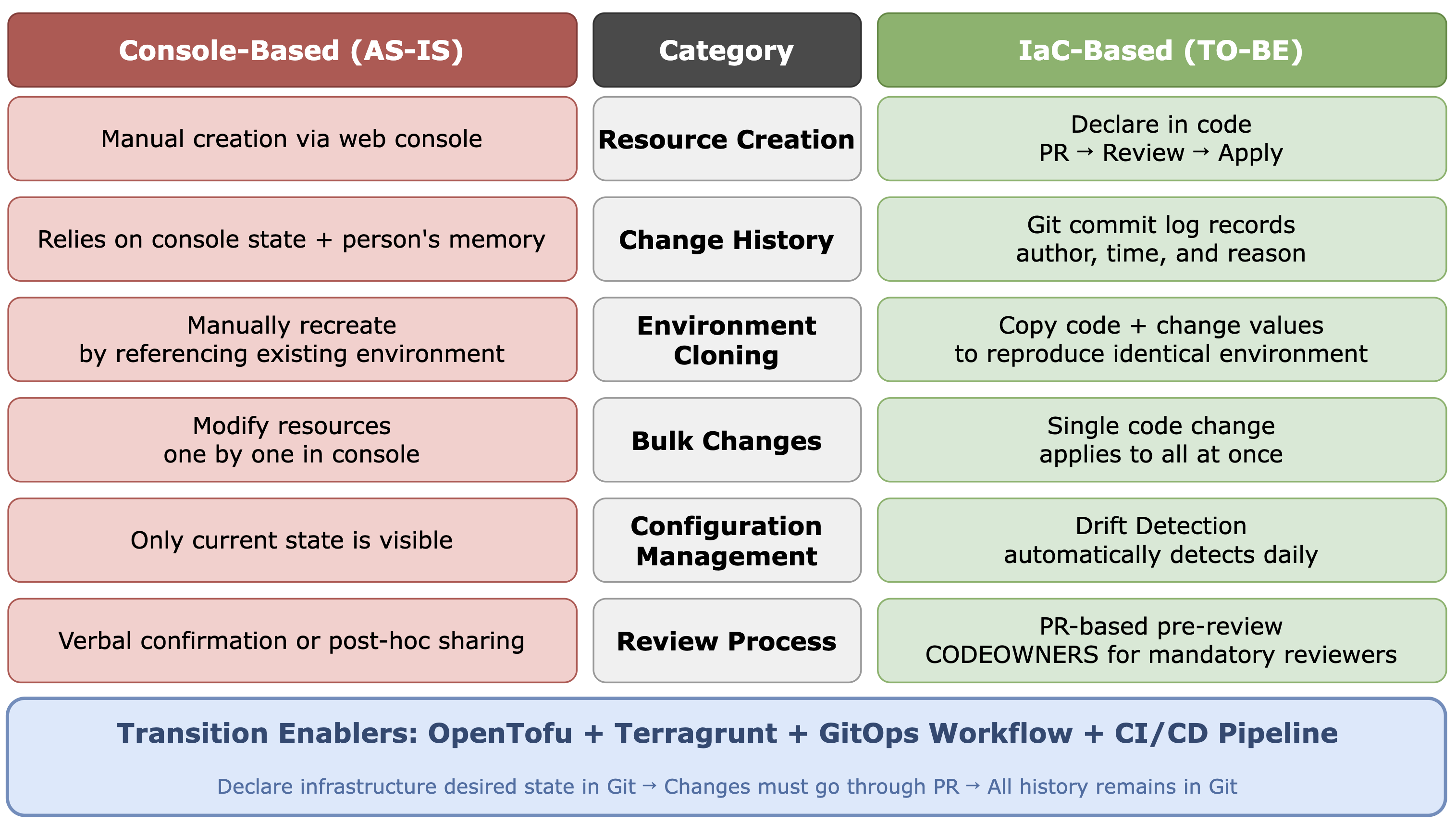
All six items point in one direction: declare the desired infrastructure state in Git and record all change history in Git for transparent management. When deploying software, no one directly uploads files to servers through SSH. Push code to Git, CI/CD builds and reviews it, then deploys. Yet many teams still create servers through the console and record settings in a wiki.
GitOps fills that gap. Declare the desired state in the Git repository, require changes to proceed through PRs, and keep every change history in Git.
"Infrastructure should be reviewable, versionable, and reproducible like application code".
This is not merely about automation. We wanted to manage infrastructure as engineering artifacts at the same level as application code. No changes without review, and no invisible changes—prepare to move into an environment where every change is traceable.
Preparing the move
Tool selection
Before starting the migration, we first decided which tools to use. The core tools we evaluated this time were OpenTofu and Terragrunt.
OpenTofu is an open-source fork of Terraform that retains the HashiCorp configuration language (HCL) syntax used by Terraform and provider compatibility while using an open-source license. Because it is not significantly different from Terraform in how you write configurations, it has a low learning cost and most existing providers and module structures in use can be reused—this was an advantage.
OpenTofu and modularization
The first thing we organized when adopting OpenTofu was to separate frequently used infrastructure configurations into modules. By making VMs, LBs, and monitoring alert configurations into modules, multiple teams can create their infrastructure by simply passing different values to the same module. Modules are versioned so that when versions change they don't immediately affect all environments—teams can explicitly bump versions where needed.
However, modularization alone was not enough. While modules reduced duplicated resource definitions, removing repeated module calls or backend/provider settings across environments was still difficult. As resources increased, similar code kept appearing across many directories.
Terragrunt for DRY
Terragrunt is a wrapper that lets you apply the don't repeat yourself (DRY) principle to environment configurations when using OpenTofu. Define common settings once in an upper-level root.hcl and leave only differing inputs in each environment.
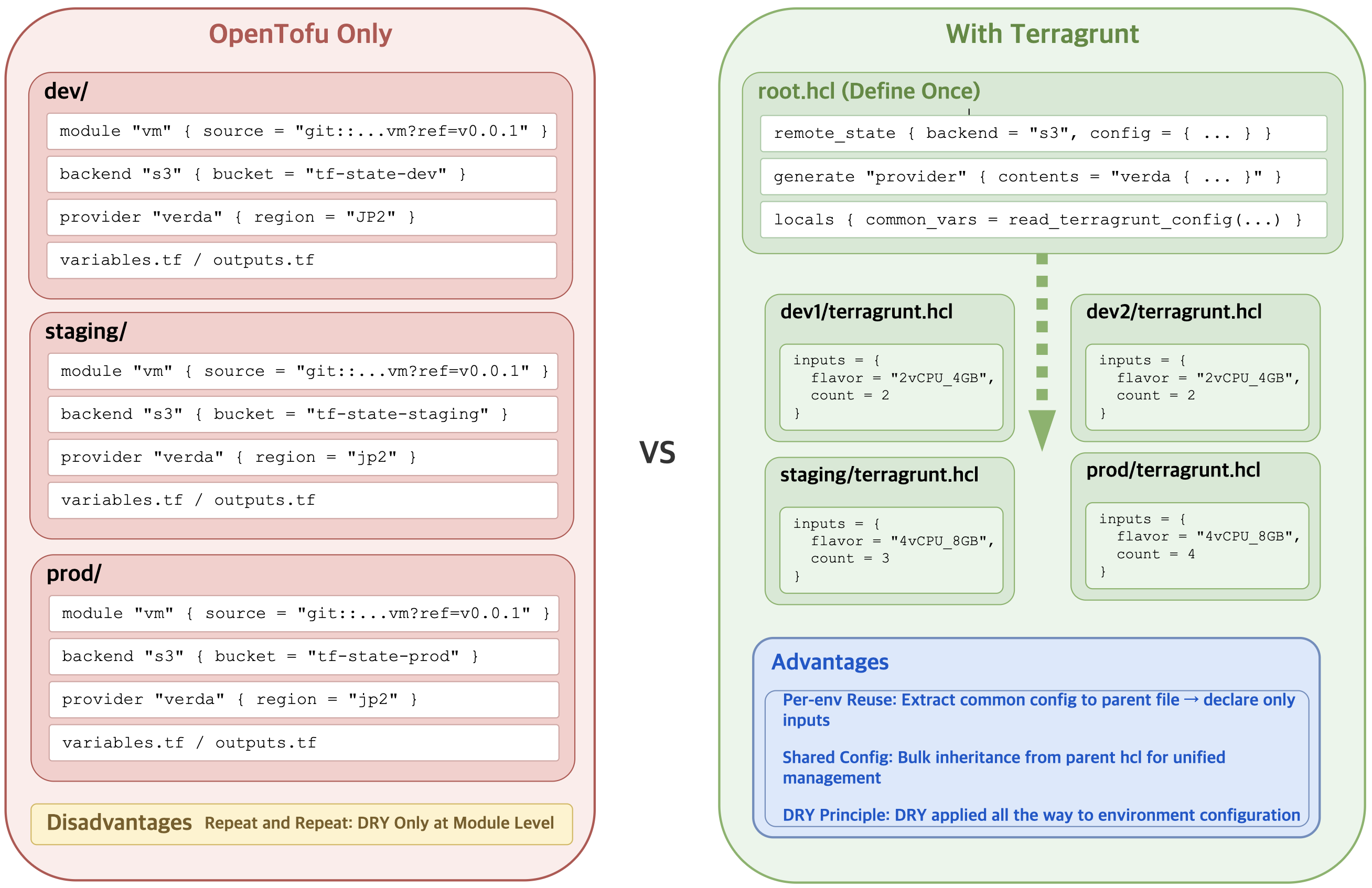
In this way, modules reduce resource definition duplication and Terragrunt reduces environment duplication.
Starting the move
With the tools ready for migration, we'll now talk about what we paid attention to while carrying out the migration.
The biggest hurdle when introducing IaC into an existing environment is bringing already-running resources into the code management system. OpenTofu provides an import feature, but when there are many running resources, manual import is impractical. Identifying resources one by one, writing configuration files, and linking to the actual infrastructure state is time-consuming and error-prone if done manually.
Therefore, we decided to run the migration in two phases.
In the first phase, we automated the import process and selected one service to pilot the tools, processes, and procedures—preparing the entire pipeline based on OpenTofu and Terragrunt.
In the second phase, we used the modules and import scripts validated in phase one to rapidly roll out to the remaining services.
Phase 1 of the migration
Writing the import scripts
Bringing existing resources into IaC was not simply a code translation task. Since the target was running infrastructure, it was critical to move resources into the code management system safely without affecting the current state. Therefore, the import script was designed to: Discover resources, convert them into code, link them to the real infrastructure state, and then verify with an OpenTofu plan (preview of changes that would be applied to the actual infrastructure).
We paid special attention to two main points in this process. First, how to make the code, the state, and the actual infrastructure resource states consistent; second, how to reflect different structures and dependency relationships per resource. We'll explain what we considered in the import process with these two points in mind.
Normalizing after import to align code, state files, and actual resources
OpenTofu's state file links the "resources declared in code" with the "resources that actually exist in the cloud".
A problem we encountered was that even after import, code, the state file, and actual resource values sometimes didn't match. For example, network IDs or image IDs may refer to the same thing but be expressed differently, causing plan to show constant differences. Leaving this as-is makes plan results unreliable, so we added a normalization step after import to clean up state and input values.
Different import strategies per resource
Not all resources can be imported the same way. Regions differ in how resources are queried and in identifier schemes, and each resource type has different units and dependency relationships required for import. For example, VMs can be imported per individual instance, but an LB cannot be treated in isolation—listeners and pools move together. DNS needs to keep zone and record relationships, and Kubernetes requires deciding how to split cluster and node pool management. IMON alert resources also have a hierarchy of team, alert group, alert rule, and alert monitor. So we divided import steps per resource as follows.
-
Query current resources.
-
Distinguish targets to manage with IaC from those to exclude.
-
Convert to match the code structure and generate Terragrunt files.
-
Link actual resources to the OpenTofu state.
-
Check plan results to verify there are no unnecessary changes.
The overall flow is the same, but detailed handling differs by resource. This allowed us to reflect per-resource characteristics while keeping the overall import procedure consistent.
Issues encountered during import
Even with a carefully designed import script, real operational environments are not that simple. Unexpected problems appeared while importing hundreds of VMs, LBs, and DNS records into code.
Mix of manually created VMs and VMs auto-created by Kubernetes
In OpenStack, both VMs created by people and VMs automatically created by Kubernetes services coexisted. They look like the same kind of VM, but the management owner differs. VMs created by people can be brought under IaC, but importing VMs managed by Kubernetes could conflict with the cluster's expected state and IaC-managed state if done incorrectly.
So we did not import all VMs indiscriminately; we excluded VMs created by Kubernetes based on naming patterns and metadata. Without this filtering, IaC adoption could have affected running clusters.
IMON's hierarchical structure
IMON alerts are not a single resource but are structured hierarchically as follows.
team → alert group → alert rule → alert monitor
Because of this structure, importing alert resources all at once could not capture relationships correctly. It was necessary to express which alert rule belongs to which alert group and which monitor corresponds to which rule conditions.
To represent this, IMON resources were organized into directories resembling the actual hierarchy. With this layout, the folder structure alone shows which alert rule belongs to which alert group.
alert-groups/
line_alert_group_a/
terragrunt.hcl # Alert Group
line_alert_rule_monitor_a/
terragrunt.hcl # Alert Rule + MonitorUnexpected provider issues
There were also cases where provider or backend behavior did not completely match the actual cloud.
-
LB naming convention conflicts
-
Cause and symptom: The actual cloud allowed both
-and_in LB names, but the provider's backend module did not allow_. This caused errors when importing LB resources that included_in their names, so we had to handle that inside modules. -
Solution: We solved this by contributing a fix to the provider's validation logic.
-
-
Universally unique identifier (UUID) mismatches
-
Cause and symptom: Universally unique identifier (UUID) values for flavor_id, image_id, and network_id differ across regions, causing repeated unnecessary changes in plan after
import. -
Solution: We added mapping logic inside modules. Users can input human-readable names and modules convert them to region-specific actual IDs. This improved code readability and reduced spurious diffs after
import.
-
Phase 2 of the migration
The import scripts, normalization scripts, filtering rules, and module correction logic developed in phase one became valuable assets for rolling IaC out to other services in phase two. These assets lowered the entry barrier for converting existing resources to code and helped consolidate infrastructure that had been managed differently across teams into a single flow combining OpenTofu and Terragrunt.
Spreading IaC: From familiar UI to code
The first thing we organized to propagate IaC to service teams was the change flow. Instead of simply providing OpenTofu code, we standardized procedures so that a plan is automatically generated when a PR is created, and after review and approval the change is applied. For service teams, a predictable process—"follow this flow for infrastructure changes"—was more important than learning a new tool.
But organizing the change flow alone did not make IaC spread naturally. Not every team member can immediately author HCL proficiently. Each provider has unique resource types and arguments in HCL, making it hard to master all at once. Especially for monitoring, most users were used to web dashboards, so telling them "from now on create alerts only as code" would naturally get the response "the dashboard is more convenient".
So rather than simply demanding "write code", we considered how to make service teams naturally feel "managing through code is more convenient". Here are some of the results of that thinking.
Supporting import of existing resources: Good examples are the best documentation
People learn easily from well-made examples. To leverage this, the SRE team first performed complex import work and then showed each team "this is how your service's VMs look in code". Starting from a blank editor and writing HCL from scratch is much harder than starting from code that already expresses your service's actual resources.
Chrome extension: Get code from the screen you're already clicking
Most users who manage monitoring create and manage alerts in a web dashboard. They're used to finishing everything in the browser without using CLI or API. "Open an editor and write HCL" felt too distant to these users.
So we built a Chrome extension that brings code into the web browser where users already are. When a user opens an alert rule page on the IMON2 web dashboard, the extension reads setting values from the DOM (document object model) and auto-generates OpenTofu HCL code. Users can check settings in the familiar screen and copy the code shown in a side panel into a PR. The point is not to replace the web UI but to start in the web UI and end in code. The Chrome extension acts as a bridge between existing operational habits and the IaC workflow.
| Plugin example |
|---|
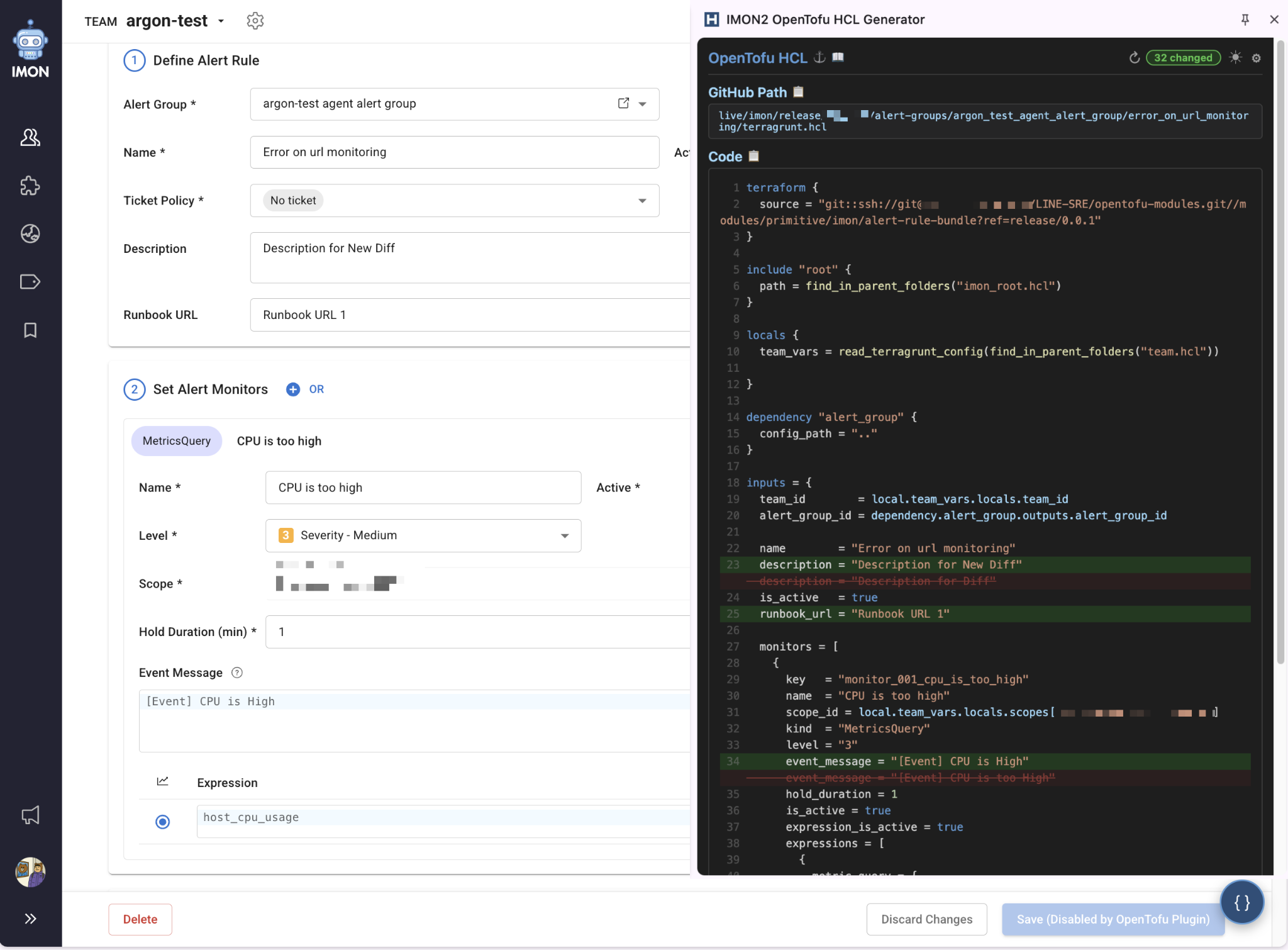 |
Opentalk: Spreading from SRE to service teams
Tools and automation alone don't complete dissemination. Direct sharing among people is also needed. Our company SREs run a biweekly technical sharing session called "Opentalk". In these sessions we shared IaC adoption background, repository structure design, and PR-based change workflows. Feedback from the sessions led to real improvements. Because we listened to and reflected user voices like this, we could shape tools and processes to fit actual usage better.
We also designed propagation paths in stages. Rather than explaining everything to all service teams at once, we first shared IaC operation methods through "Opentalk" with each service's responsible SRE. The SRE familiar with that service's infrastructure could then guide the team in a way tailored to their situation—this proved much more effective.
Blog
This article itself is part of the dissemination strategy. Writing about structure and decision processes lets new joiners or other teams considering IaC understand "why things were made this way" beyond code. Code explains "what"; this blog explains "why".
What changed after adoption
As IaC settled in, changes started in systems and extended to people.
Operational change: Every change is recorded in Git
The first change was the change history. Every infrastructure change now records author, time, reason, and reviewer. The question "who created this server"? no longer relies on someone's memory—you can check Git logs and PRs.
commit a1b2c3d
Author: engineer-a
Date: 2024-12-15
feat: add staging VM for payment-service
- 4 vCPU, 8 GB, Rocky Linux 9.4
- Requested by: payment team (#TICKET-1234)
Reviewed-by: engineer-bOne of IaC's greatest values is the review process through pull requests (PRs). When infrastructure changes are expressed as code, a feedback loop forms. For example, when someone opens a PR to create a new VM, feedback like the following can occur.
"custom_tag is missing. Add that tag for DB ACL settings."
"Reviewing BMT (Benchmark Test) results shows memory-heavy usage patterns under load, so instead of this flavor, how about using Memory Intensive?"
Receiving such feedback during infrastructure creation is impossible when clicking alone in the console. It filters out incorrect settings before they reach infrastructure. Combined with a CODEOWNERS setting to designate required reviewers for each repository, you can technically prevent merges without review. This review process works with the automated CI/CD pipeline as follows.
-
Plan: Automatically run when a PR opens (preview the impact of changes)
-
Review: Team reviews diffs (reviewers inspect changes and give feedback)
-
Apply: Automatic deployment on merge (only approved changes are applied to infrastructure)
-
Drift check: Daily automated scan (detect differences between code and actual infrastructure)
The review process workflow above is operated separately per service and environment (Verda, Flava, IMON). Additionally, a "force-unlock" workflow exists in every project for state lock situations, so you don't need to SSH into servers to recover a locked state.
Outputs from each step are shared transparently. Plan results are automatically commented on the PR so everyone can see "what will happen if this PR is merged". Apply results are sent to Slack after deployment so success/failure can be checked immediately, and Drift Check runs daily to send Slack alerts with the full diff of console-made changes.
| Plan results automatically attached to PRs | Drift Check alerts arriving in Slack |
|---|---|
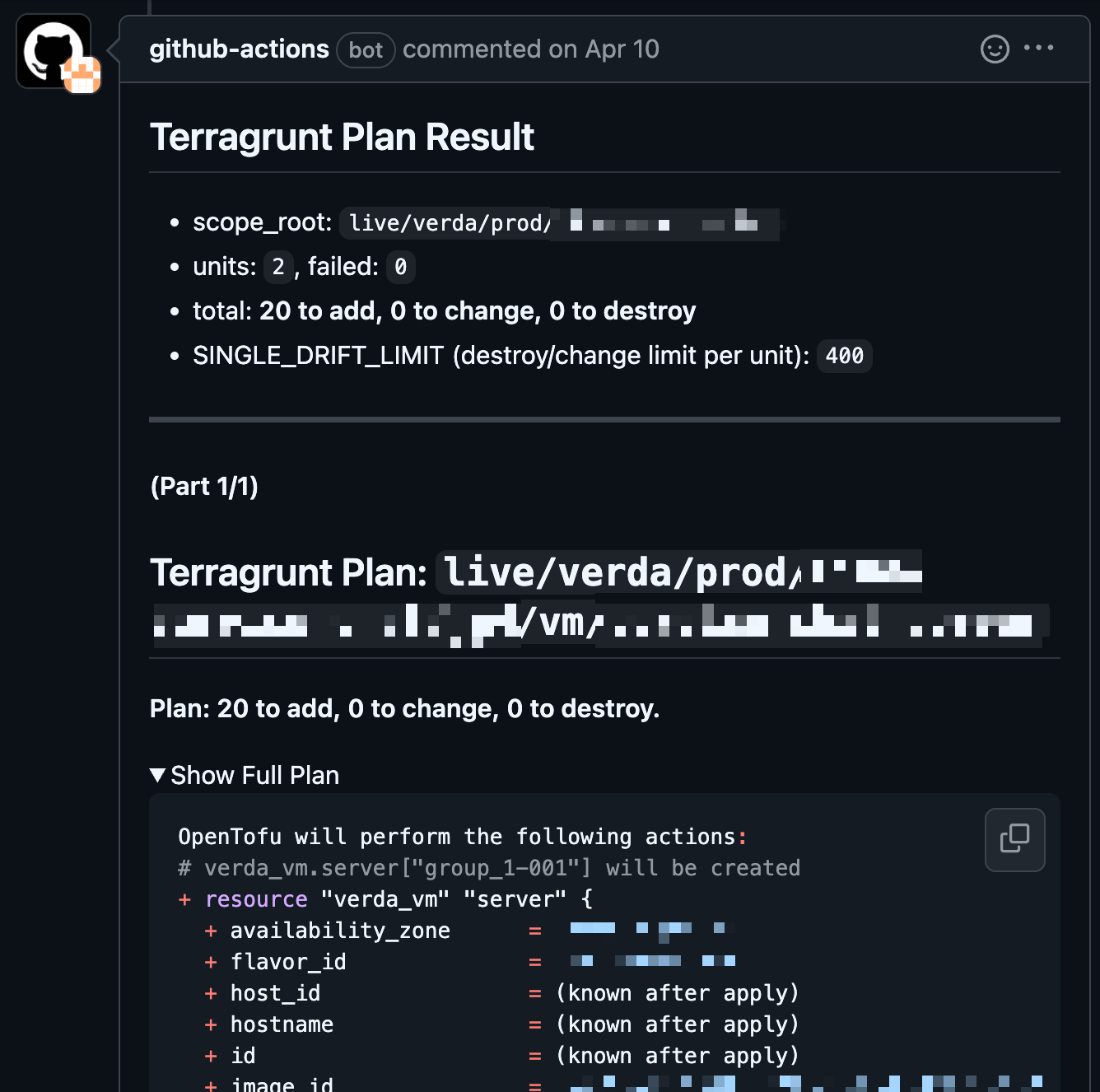 | 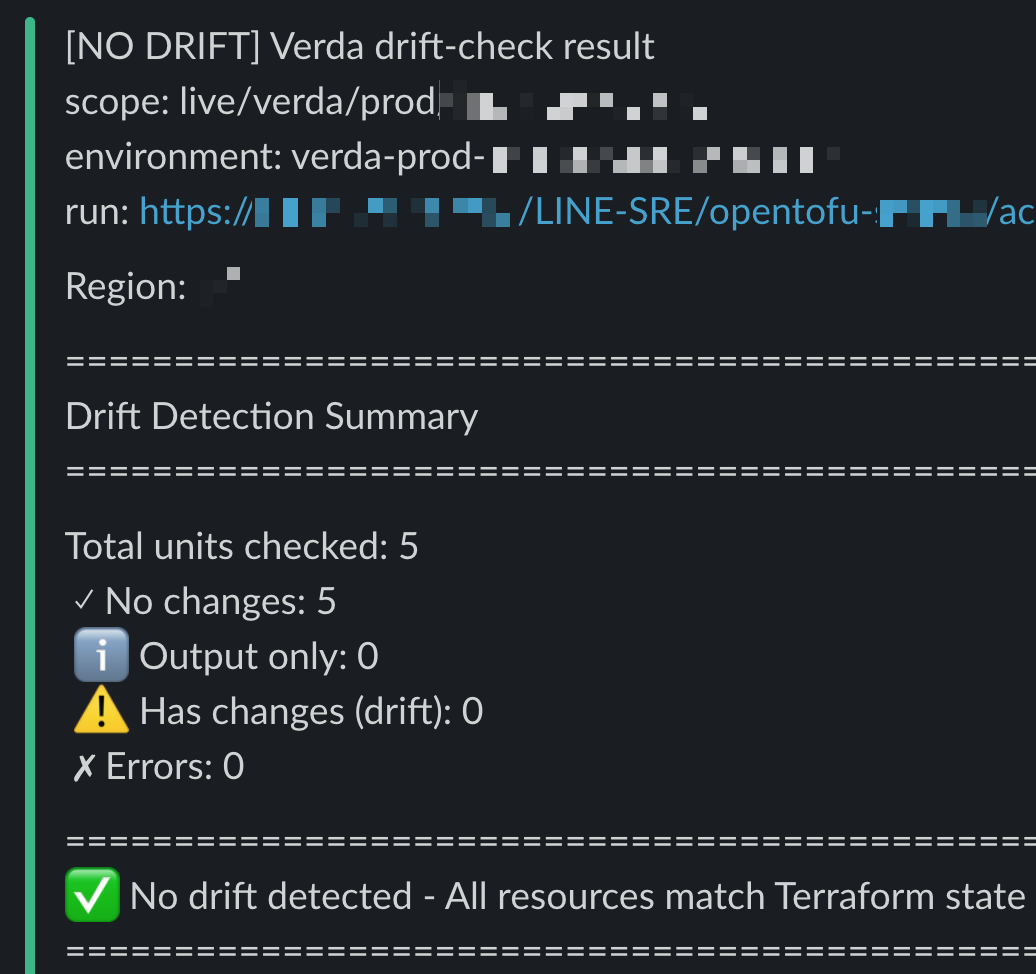 |
Drift Check: Automatically detect manual changes
The benefits of IaC go beyond resource creation and changes. Through the fourth CI/CD pipeline step described earlier—Drift Check—we detect daily differences between code and actual infrastructure and send alerts to Slack.
Drift refers to a mismatch between the declared state in code and the real cloud state. It happens when someone edits the console directly. For example, in a pre-launch test someone might quickly change a DNS record IP in the console. If they intended to revert it later but got busy, that change might be forgotten and hard to track. But since the code still declares the original IP, Drift Check detects this discrepancy before service launch and sends notifications to Slack. As a result, you can revert before launch and prevent user traffic from flowing to the wrong IP.
Monitoring as code
By managing monitoring alerts as code, we can modify multiple alerts at once with a single PR when changing thresholds. Because the change history records the reason for changing a threshold in the commit message, there is no longer a need to track "who changed this value and why"? later. When creating the same alert structure for a new service, you can copy the existing code and only change the values. Small configuration differences that used to occur when creating alerts one by one in the dashboard have disappeared. By managing not only infrastructure but also monitoring as code, the operational shape of the entire service can be traced within a single repository.
Code that replaced documentation
This change did not stop at the system level. Previously, when a new team member joined, the infrastructure configuration had to be conveyed in wiki documents and verbal explanations. Someone had to explain which VM belongs to which service, how the LB settings are configured, and why an alert rule was set to a particular threshold.
Now you just show the repository. Reading the code reveals the current infrastructure configuration, and by following PR history you can understand why things changed. Past PR review comments contain the context for decisions. Reasons like "why we chose Memory Intensive instead of this flavor" or "the rationale for lowering this alert threshold" remain in the history without needing separate documents. As infrastructure knowledge once held only by seniors is naturally shared through code and history, onboarding time has decreased.
The start of infrastructure self-service
Before adopting IaC, all infrastructure changes had to go through the SRE team. But once modules were created and propagated, things began to change. The development team responsible for service A now writes Terragrunt code and opens PRs directly. The SRE team participates as reviewers but no longer writes the code for them.
Other teams are moving to change infrastructure using AI agents described later. Because an agent can generate code and open a PR from a natural-language request in Slack, teams can participate in the IaC workflow without knowing HCL syntax. Whether changes are made by writing code directly or using an AI agent, all changes go through the same GitOps pipeline. Different entry paths are accepted, but review and traceability principles apply equally.
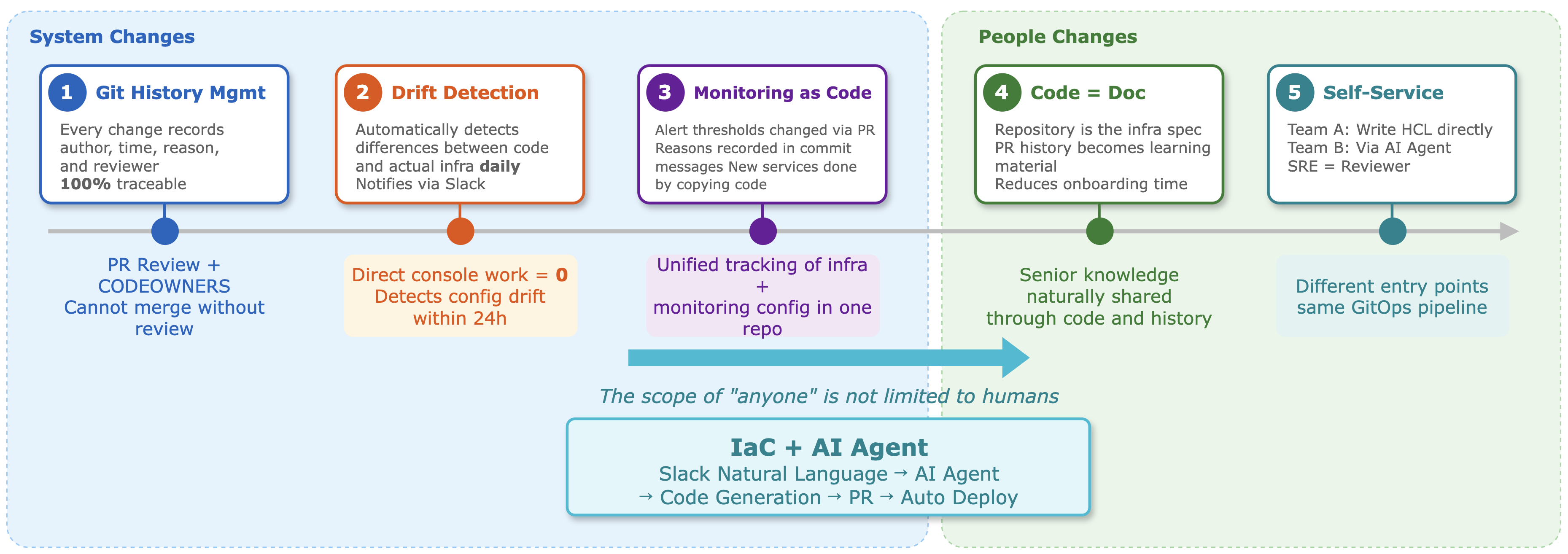
Everything in infrastructure is expressed as code, and a system was created where anyone can read and change it in the same way. We soon realized that the scope of "anyone" is not limited to people.
Next step: Combining IaC and AI agents
Managing infrastructure with IaC reveals one important fact: infrastructure declared as code is readable not only by humans but also by AI. Repetitive requests such as "add two instances for service A" or "add a LB for service B" follow established patterns that AI agents can handle. We connected the OpenTofu repository to an AI agent through model context protocol (MCP) and built a bot that changes infrastructure from natural language in Slack.
When a natural-language request is sent in Slack, the agent references existing code patterns to generate Terragrunt code and opens a PR. Plan results are shared to Slack, and after a human reviews and approves, deployment runs automatically.
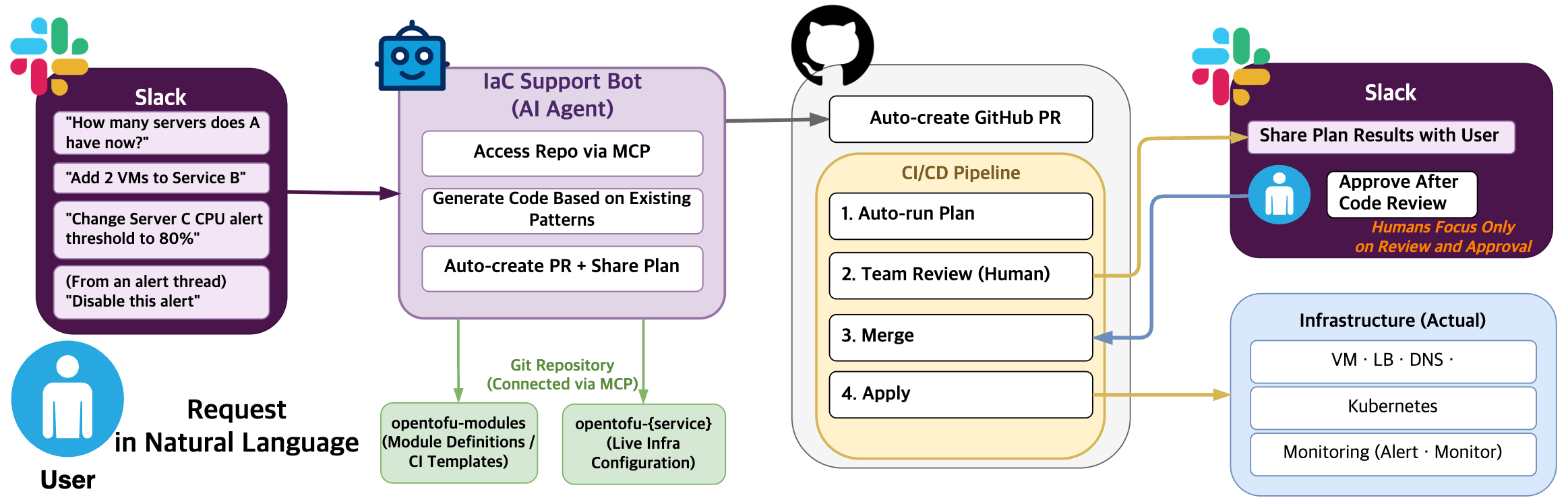
Below is an example use case: Without writing code yourself, you can check server information in Slack and ask the agent to increase the server count—the agent prepares everything else.
| Natural language request-based bot example | PR and file change example |
|---|---|
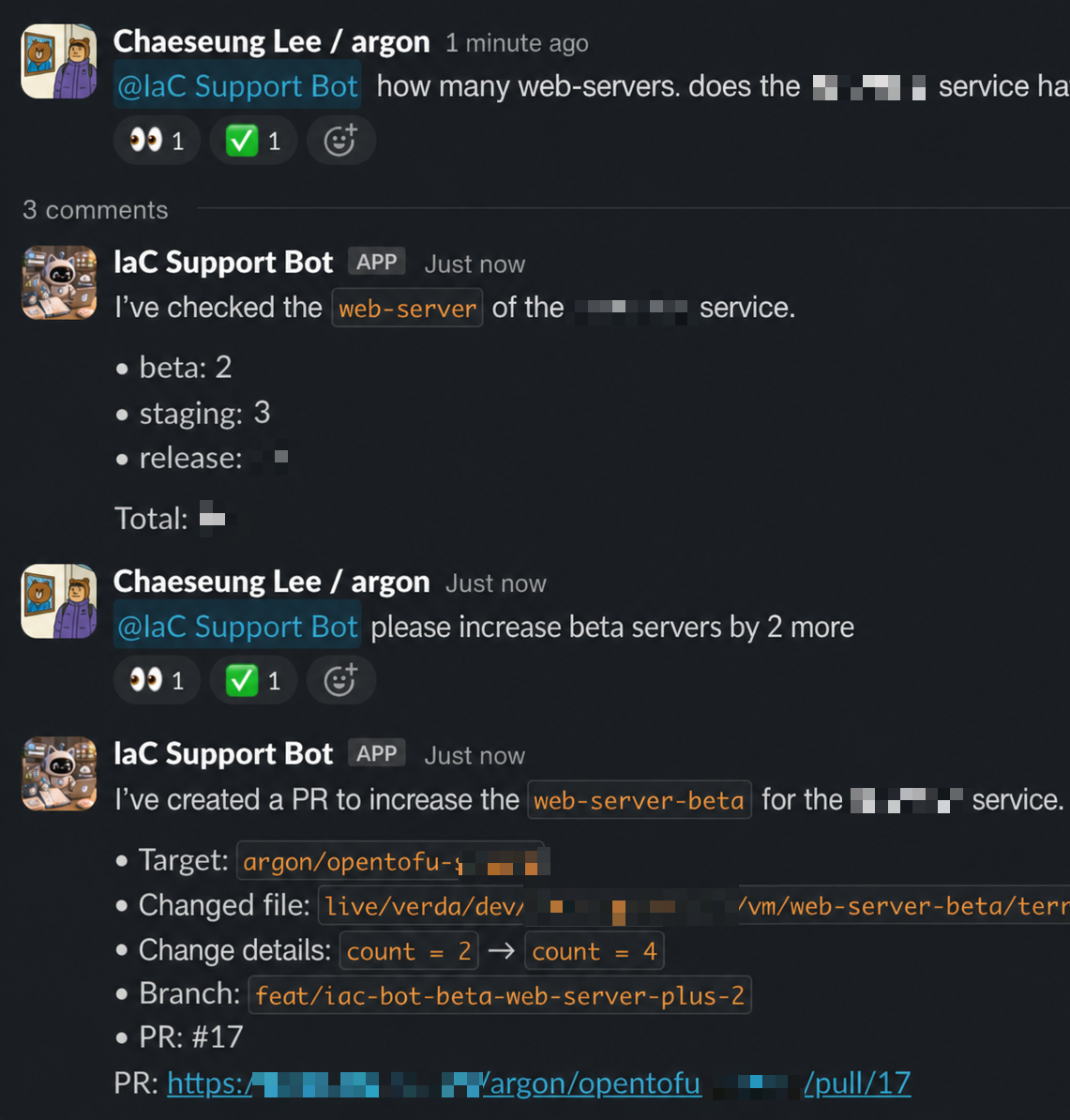 | 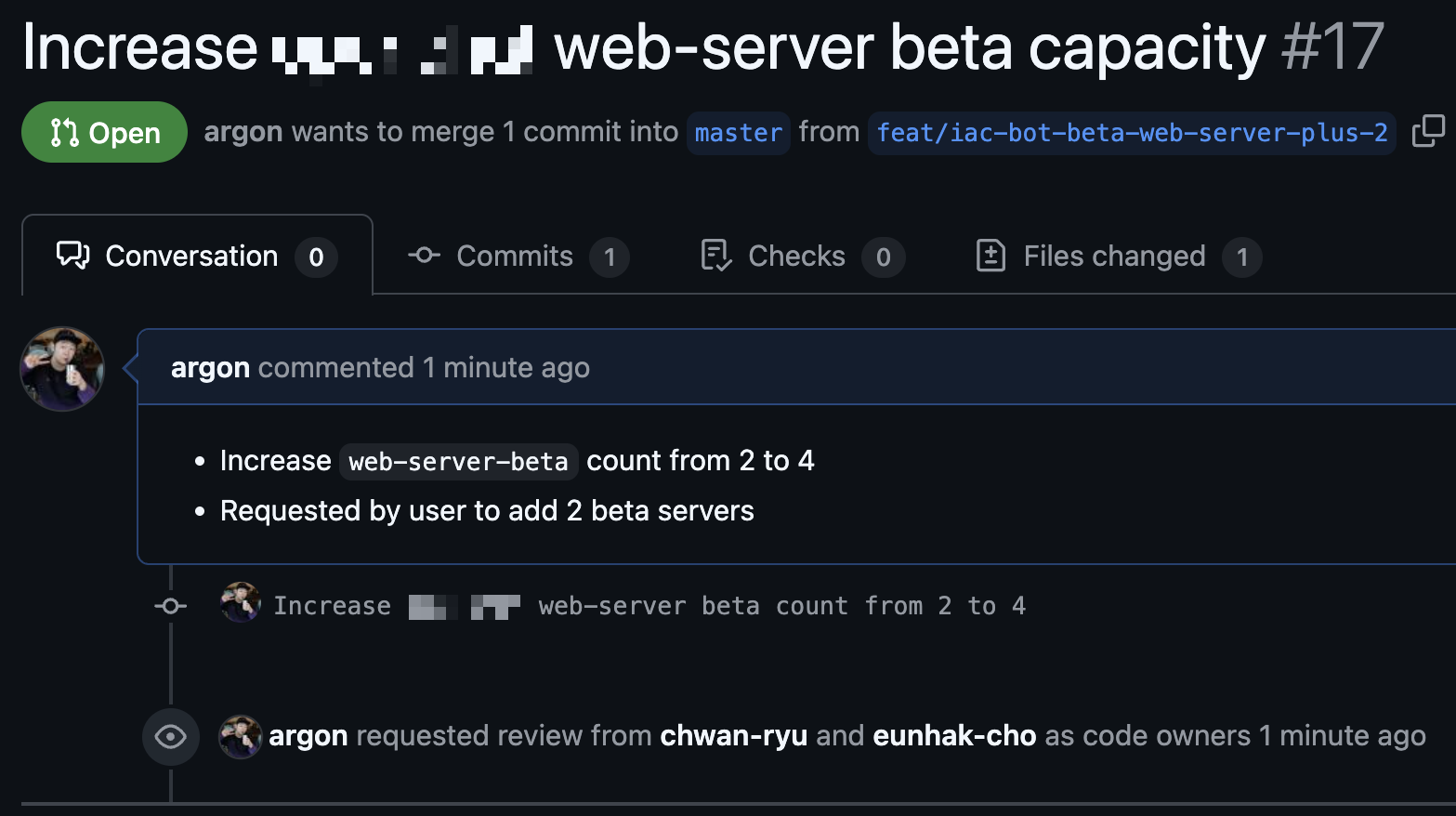 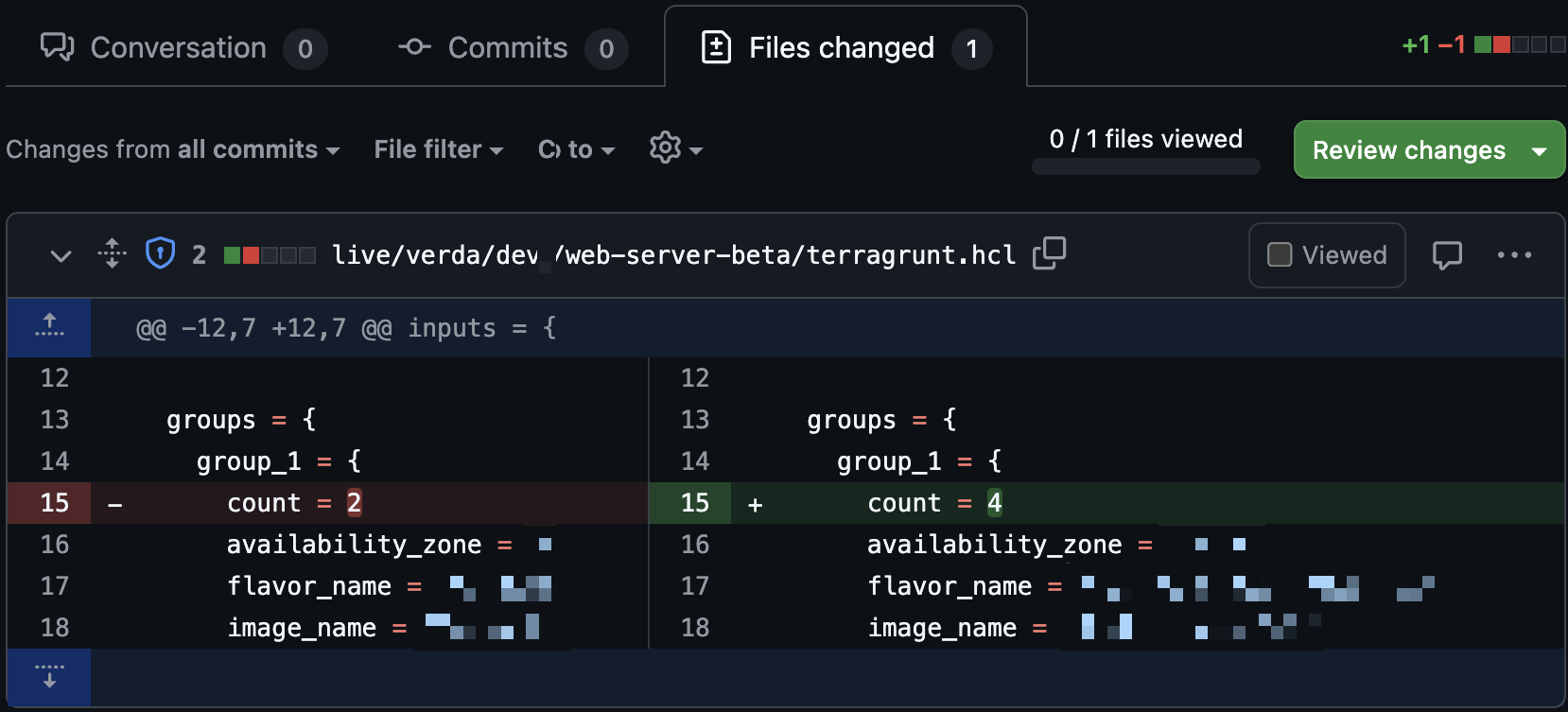 |
In addition to natural-language requests, monitoring alerts can also trigger AI agents to automatically generate response code.
| Response flow | Existing (manual response) | IaC + AI agents (automatic suggestion) |
|---|---|---|
| 1. Receive alert | On-call checks Slack alert | AI agent automatically receives the alert |
| 2. Assess situation | Log into console and check current VM count/specs | Agent immediately assesses using IaC |
| 3. Respond | Request SRE to scale out or add VMs directly in console | Agent automatically generates scale-out code and opens a PR |
| 4. Review | Later: "who added servers and why"? | PR records reason, alert, and plan results |
| Elapsed time | Tens of minutes from alert to application | Minutes to PR creation, immediate application upon approval |
Whether triggered by a person or a monitoring system, the agent writes the code. Humans focus only on review and approval.
For those considering IaC adoption
If you dislike clicking in consoles or fear mistakes, we recommend trying IaC. However, there are points to know before adopting.
Even small changes must follow procedure
Requests like "increase a VM's specs by one" could be done in a few console clicks before IaC. Under IaC, the flow is "edit code → create a PR → review → merge → apply". It may seem cumbersome at first, but it's a definite advantage: even a newly onboarded person can understand infrastructure by reading code, and following the procedure ensures safe changes. Tacit knowledge previously held only by seniors is naturally shared through code.
The whole team must embrace IaC culture
IaC adoption is a cultural, not a technical, challenge. If even one team member edits the console directly, a divergence arises between code and real infrastructure. Therefore, console edits that violate IaC culture should be limited to emergency responses, and afterward must be reflected back into IaC code to realign code and reality.
Even if that reflection is missed, Drift Check will catch manual changes, serving as a strong safety net for culture adoption. Resources that intentionally need to remain out-of-sync with code can be listed in an ignore file (for example .driftignore), and excluded from Drift Check as an exception.
Start regardless of scale
If your operation scale is small, imports are easy and you can start quickly. Conversely, if your scale is large, adopting IaC can reduce management and outage risks that arise from difficult traceability. Also, IaC adoption sets up a view that humans and AI agents can both read, laying the groundwork for AI automation.
Conclusion
At first it felt overwhelming. Moving running resources into code felt like replacing the wheels of a moving train. It took a month to migrate the first service in phase one: choosing tools, building the pipeline, writing state-normalization scripts, and putting guardrails in place. But without that month, there would have been no phase two. The reason we could onboard four more services in the same timeframe was the foundation built in phase one.
Now infrastructure changes are not scary. Edit the code, open a PR, get reviews, and merge — the same daily development workflow. If someone asks "who created this server"? you can simply show the Git logs.
In fact, this entire journey was possible thanks to SRE Team 9, who created the Terraform providers for Verda and IMON. Without the providers that connected our internal cloud platform to code, this article would not exist. We would like to express our gratitude here.
We hope the examples in this article can serve as a starting point for anyone considering IaC adoption, not just our team. Thank you for reading this long article.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


