LY Corporationの技術カンファレンス Tech-Verse 2026 の公式記事です。
はじめに
こんにちは。社内クラウドサービス Verda および社内モニタリングツール IMON に Infrastructure as Code(以下 IaC)を適用した LINE Plus SRE チームのイ・チェスン、チョ・ウナクです。IaC とは、サーバーやロードバランサー、DNS、モニタリング設定など運用に必要なインフラリソースを Web UI で直接編集するのではなく、コードで宣言・管理する方式です。
私たちは Verda の VM(virtual machine)、LB(load balancer)、DNS(domain name service)、Kubernetes リソースと、IMON のアラートグループ(alert group)、アラートルール(alert rule)、アラートモニター(alert monitor)を OpenTofu/Terragrunt で管理しています。現在、約1,500個のリソースがコードで宣言されており、7つのサービスのインフラ変更はすべて PR(pull request)レビューと CI/CD(continuous integration/continuous deployment)パイプラインを通じて反映されています。コードと実インフラの差分も毎日自動で検知し、通知しています。
最初からこのような構成だったわけではありません。すでに運用中の約300台の VM、約160個の LB、約350個の DNS レコードを��コードに移行しなければならず、Verda ダッシュボードやスクリプトを使ったり、Wiki に手順をまとめたりと、チームごとに異なる方法で管理していた設定を GitOps(Git ベース運用自動化)という一つの流れにまとめる必要がありました。
この記事では、その過程を共有します。なぜ IaC が必要だったのか、既存リソースをどう取り込んだのか、運用中にどんな問題に出会ったのか、そしてどう Slack や AI エージェントを活用してコード生成まで自動化しようとしているのかを紹介します。
なぜ IaC を導入したのか
運用規模拡大による課題
従来は複数のチームがそれぞれの方法でインフラを管理していました。あるチームは Verda ダッシュボードで、あるチームはスクリプトで、あるチームは手順書通りに、設定の記録方法も Wiki、個人文書、GitHub などバラバラでした。
どの方法にも一長一短はありますが、サービスやリソースが増えるにつれて、以下のような共通の課題が生じ始めました。
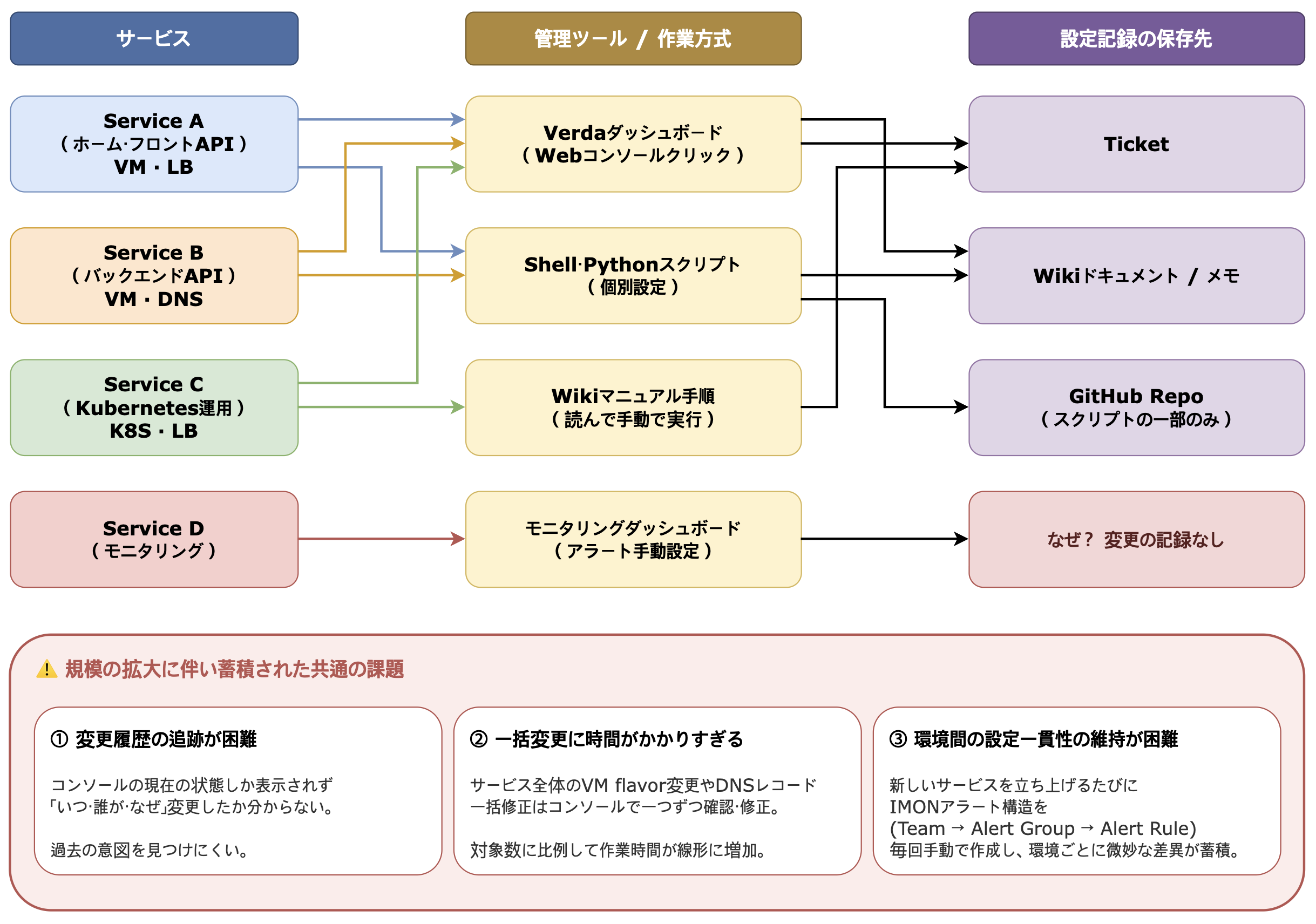
こうした課題は対象が少ないうちは単純な運用作業で済みますが、規模が大きくなると負担が蓄積し、対応しきれなくなります。そこで私たちはインフラをコードで管理する必要があると判断しました。リソースの状態を明示的に定義し、変更内容をレビューし、同じ作業を自動で繰り返せる仕組みが必要でした。
コンソールからコードへ、GitOps ��という答え
上記の課題をもとに、コンソールベース運用と IaC ベース運用を項目ごとに比較しました。各項目で期待した変化は次の通りです。
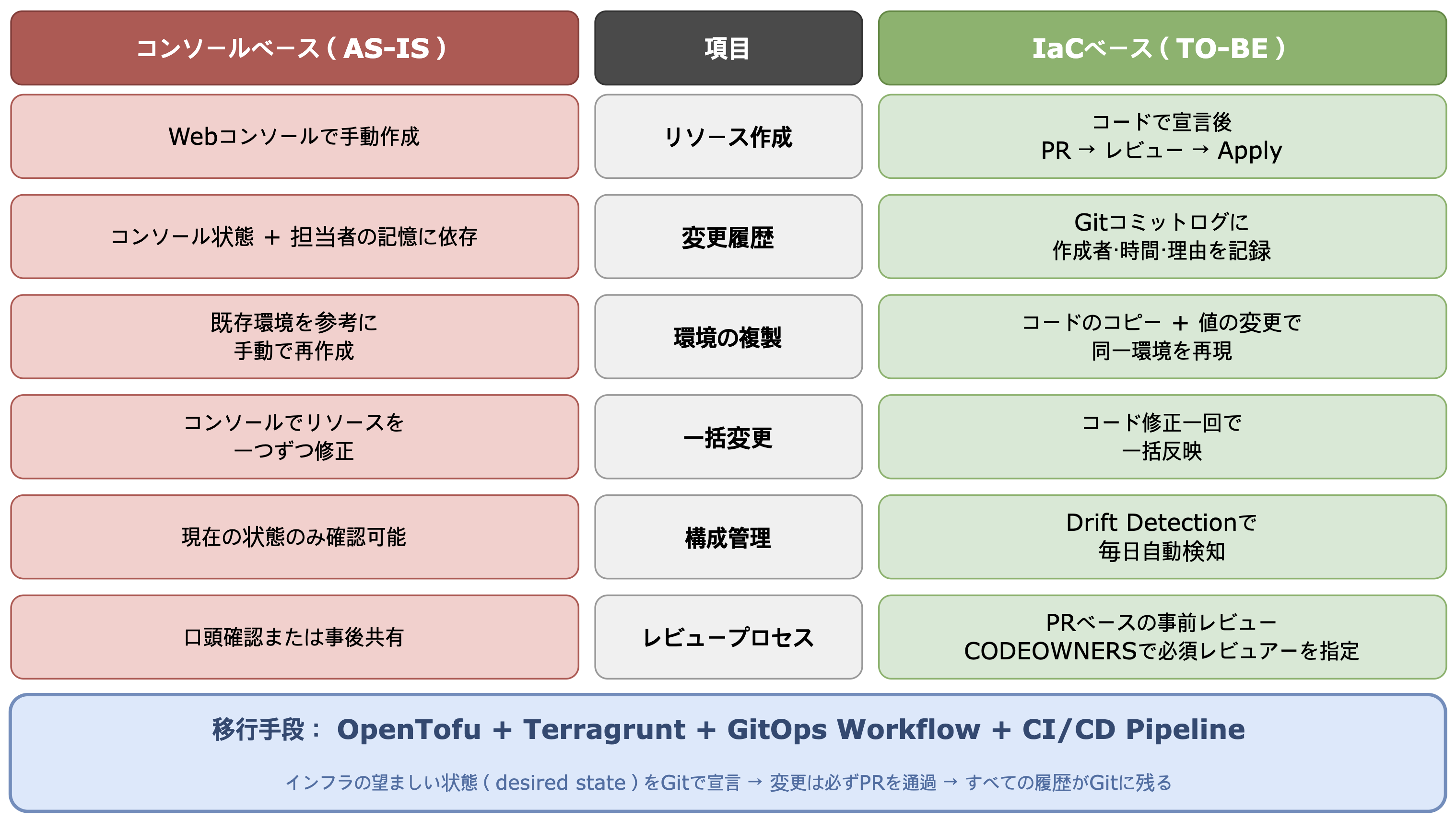
6つの項目が指し示す方向は一つです。望ましいインフラ状態を Git で宣言し、すべての変更履歴を Git に残して透明に管理することです。ソフトウェアをデプロイする際、誰も SSH でサーバーにファイルを直接アップロードはしません。Git にコードを push すれば CI/CD がビルドし、レビュー後にデプロイします。しかしインフラは、まだ多くのチームがコンソールでサーバーを作成し、Wiki に設定を記録しています。
GitOps はこのギャップを埋めます。望ましいインフラ状態(desired state)を Git リポジトリに宣言し、変更は必ず PR で行い、すべての変更履歴が Git に残ります。
“Your infra should be as reviewable, versionable, and reproducible as your application code.”
「インフラもアプリケーションコードのようにレビュー可能で、バージョン管理可能で、再現可能でなければならない。」
単なる自動化のためではありません。インフラもアプリケーションコードと同じレベルのエンジニアリング成果物として管理したかったのです。レビューを経ない変更がなく、痕跡のない変更も存在しない環境への移行を準備しました。
移行準備
ツール選定
移行を始める前に、まずどのツールを使うか整理しました。今回検討した中核ツールは OpenTofu と Terragrunt です。
OpenTofu は Terraform のオープンソースフォークで、従来の Terraform と同じ HCL(HashiCorp Configuration Language)構文・プロバイダー互換性を保ちつつ、オープンソースライセンスで利用できる IaC ツールです。Terraform ベースの記述方式と大きく変わらないため学習コストが低く、すでに利用していたプロバイダーやモジュール構成もほとんどそのまま移行できる点が強みでした。
OpenTofu とモジュール化
OpenTofu を導入して最初に整理したのは、繰り返し使うインフラ構成をモジュールとして分離することでした。VM、ロードバランサー、モニタリングアラートなどをモジュールにしておけば、各チームが同じモジュールに値だけ渡して自分たちのインフラを作れます。モジュールはバージョンで管理し、変更してもすぐ全環境に影響するのではなく、必要な場所だけ明示的にバージョンアップして反映できる形にしました。
しかしモジュール化だけでは不十分でした。モジュール化によりリソース定義の重複は減りましたが、環境ごとにモジュール呼び出しやバックエンド・プロバイダー設定の繰り返しまでは減らせませんでした。そのためリソースが増えるほど似たコードが複数ディレクトリに増えていきました。
DRY のための Terragrunt
Terragrunt は OpenTofu を使う際に環境構成まで DRY(don’t repeat yourself:繰り返しを避ける)を拡張できるラッパーツールです。共通設定は上位 root.hcl に一度だけ書き、各環境には異なる入力値(inputs)だけを残します。
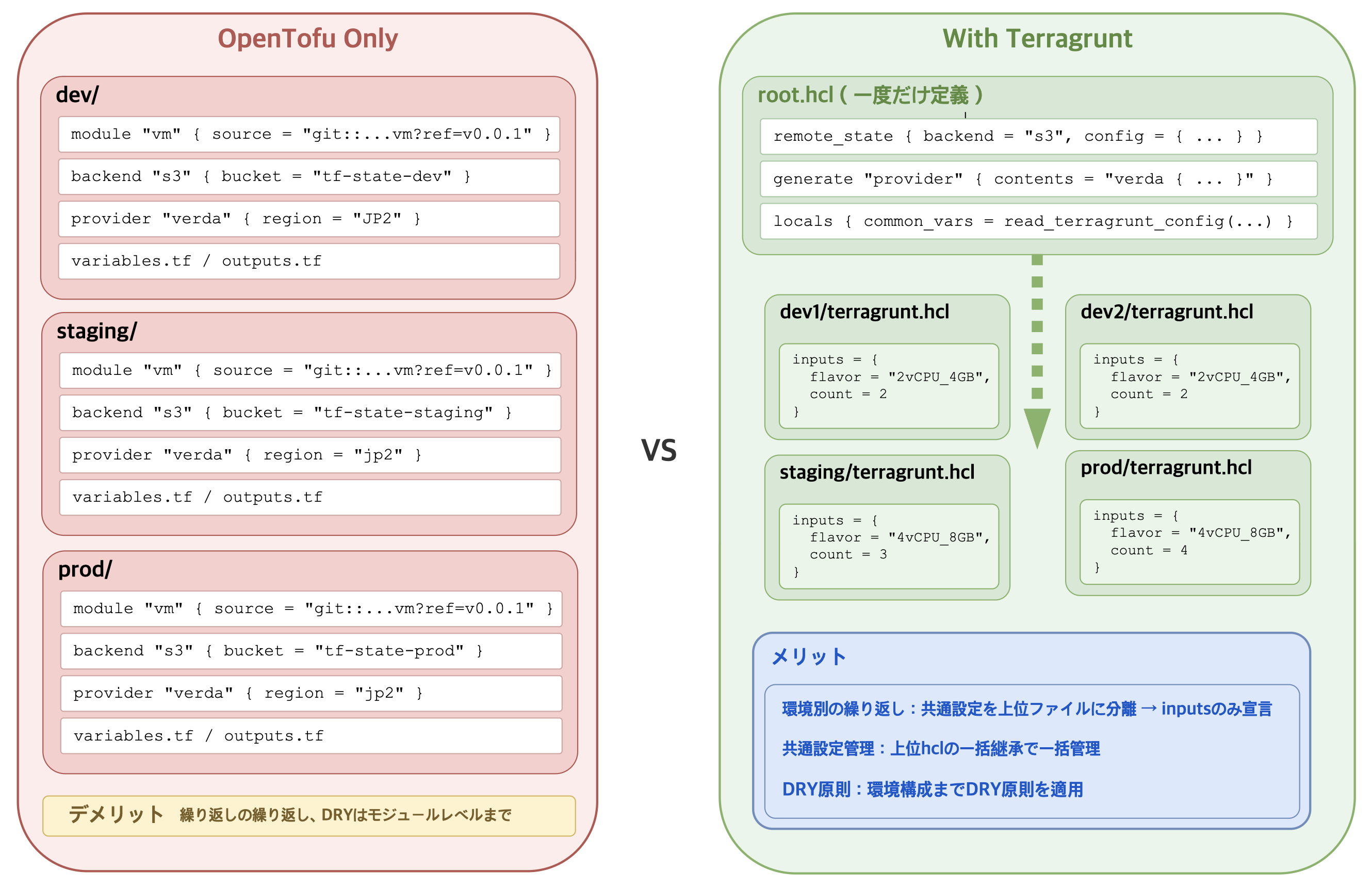
このようにモジュール化でリソース定義の重複を減らし、Terragrunt で環境ごとの重複も減らせます。
移行開始
移行のためのツールが揃ったので、実際に移行を進める中で意識したポイントを紹介します。
ゼロから IaC を導入する場合、最大のハードルはすでに運用中のリソースをコード管理体制に取り込むことです。OpenTofu にも import 機能はありますが、運用中リソースが多いと手動で import するのは現実的ではありません。リソースを一つずつ特定し、設定ファイルを作り、実インフラと紐付ける作業を人が繰り返すと時間がかかるだけでなく、ミスのリスクも高まります。
そこで私たちは移行を2段階に分けて進めることにしました。
第1段階ではまず import プロセスを自動化し、1サービスを選んでツール・プロセス・手順を試験適用し、OpenTofu/Terragrunt ベースのパイプライン全体を整えます。
第2段階では第1段階で検証したモジュールと import スクリプトを使い、他サービスへ迅速に展開します。
第1段階
import スクリプト作成
既存リソースを IaC へ取り込む作業は単なるコード変換ではありませんでした。運用中インフラが対象なので、まず現状に影響を与えず安全にコード管理体制へ移行することが重要でした。そのため import スクリプトはリソースを取得し、コードに変換し、実インフラと紐付け、plan(OpenTofu で実際に適用される予定の変更を事前確認)結果で検証する流れを基本に設計しました。
この過程で特に意識したポイントは2つ。1つ目はコード・state・実インフラリソースの状態をどう一致させるか。2つ目はリソースごとに異なる構造・依存関係をどう反映するか。この2点を中心に import で考慮した点を説明します。
import 後の正規化でコード・state ファイル・実インフラ状態を一致させる
OpenTofu の state ファイルは「コードで宣言したリソース」と「実クラウド上のリソース」を紐付ける情報です。
ここで直面した問題は、import で取り込んだ後でもコード・state・実リソースの値が一致しない場合があったことです。ネットワーク ID やイメージ ID など、実際は同じ値を指していても表現方法が異なり、plan で常に変更があるように見える場合がありました。このままでは plan 結果を信頼できないため、取り込み後に状態・入力値を整理する正規化プロセスを追加しました。
リソースごとに異なる import 戦略
すべてのリソースを同じ方法で取り込むことはできませんでした。リージョンごとにリソース取得方法や ID 体系が異なり、リソースタイプごとに import の単位や依存関係も異なりました。例えば VM は個別インスタンス単位で取り込めますが、LB は LB 単体だけでなくリスナーやプールなど連動するリソースも考慮が必要です。DNS はゾーンとレコードの関係維持、Kubernetes は��クラスタとノードプールをどの単位で管理するかを決める必要がありました。IMON アラートリソースもチーム・アラートグループ・アラートルール・アラートモニターが階層構造で繋がっています。そこで次のようにリソースごとに段階を分けて import しました。
-
現在のリソースを取得する。
-
IaCで管理する対象と除外する対象を区別する。
-
コード構造に合わせて変換し、Terragruntファイルを生成する。
-
実際のリソースをOpenTofu stateに紐付ける。
-
plan結果を確認し、不要な変更がないか検証する。
大枠は同じですが、詳細処理はリソースごとに異なります。これによりリソース特性を反映しつつ全体の import 手順を一貫して維持できました。
import 過程で出会った課題
このように設計した import スクリプトを実行すれば終わりかと思いきや、実運用環境はそう単純ではありませんでした。数百台の VM・LB・DNS レコードをコード化する過程で予想外の問題が発生しました。
手動作成 VM と Kubernetes 自動作成 VM の混在
OpenStack には人が直接作成した VM と Kubernetes サービスが自動生成した VM が混在していました。両者は同じ VM に見えても管理主体が異なります。人が作成した VM は IaC で管理して良いですが、Kubernetes 管理下の VM は誤って取り込むとクラスタの期待状態と IaC 管理状態が衝突する恐れがあります。
そこで全 VM を無条件で取り込まず、ネーミングパターンやメタデータを基準に Kubernetes 生成 VM は除外しました。このフィルタがなければ IaC 導入が運用中クラスタ��に影響を及ぼした可能性があります。
IMON の階層構造
IMON のアラートは単一リソースではなく、次のような階層構造です。
チーム(team)→ アラートグループ(alert group)→ アラートルール(alert rule)→ アラートモニター(monitor)
このため単純にアラートリソースを一括 import するだけでは正しく取り込めません。各アラートルールがどのアラートグループに属するか、各モニターがどのルール条件かも表現する必要がありました。
そのため IMON リソースは実際の階層に合わせてディレクトリを構成しました。こうすることでフォルダ構造を見るだけで「このアラートルールはどのグループに属するか」が一目で分かります。
alert-groups/
line_alert_group_a/
terragrunt.hcl # Alert Group
line_alert_rule_monitor_a/
terragrunt.hcl # Alert Rule + Monitor予想外のプロバイダー問題
プロバイダーやバックエンドの挙動が実クラウドと完全には一致しないケースもありました。
-
LB のネーミングコンベンション衝突
-
原因・現象:実クラウドではロードバランサー名に
-も_も許容されますが、プロバイダーのバックエンドモジュールでは_が許容されず、_を含む既存 LB を取り込む際にエラーとなり、モジュール内部で個別対応が必要でした。 -
解決策:Provider 側のバリデーションロジックを修正し、provider へコントリビュートする形で解決しました。
-
-
UUID(universally unique identifier)不一致
-
原因・現象:リージョンごとに flavor_id, image_id, network_id の UUID が異なり、
import後の plan で不要な変更が毎回表示されました。 -
解決策:モジュール内部にマッピングロジックを追加し、利用者は人間が読める名称を入力して、モジュール側でリージョンごとの実 ID へ変換するようにしました。これによりコードの可読性も向上し、
import後の偽差分も減らせました。
-
第2段階
第1段階で作成した import・正規化スクリプト、フィルタルール、モジュール補正ロジックは、第2段階で他サービスへ IaC を展開する際の重要な資産となりました。これらにより既存リソースのコード化ハードルが下がり、チームごとに異なるインフラ管理を OpenTofu/Terragrunt で作った一つの流れに統一できました。
IaC 展開:慣れ親しんだ UI からコードへ
IaC をサービスチームに展開する際、まず整理したのは変更フローでした。単に OpenTofu コードを提供するだけでなく、PR を作成すれば plan が自動生成され、レビュー・承認後に適用される手順を標準化しました。サービスチームにとっては新しいツールを覚えるよりも「今後インフラ変更はこの流れで行えばよい」という予測可能なプロセスが重要だったからです。
しかしフローを整えるだけで IaC が自然に広まるわけではありません。すべてのメンバーがすぐ HCL を書けるわけではないからです。HCL にはプロバイダーごとに固有のリソースタイプや引数があり、一気に覚えて使うのは難しいです。特にモニタリング管理は Web ダッシュボードに慣れたユーザーが多く、「これからはコードでアラートを作ってください」と言えば「ダッシ��ュボードの方が楽なのに」という反応が当然出ます。
そこで単に「コードを書いてください」と求めるのではなく、どうすればサービスチームが自然に「コード管理の方が便利だ」と感じられるか展開方法を工夫しました。その例をいくつか紹介します。
既存リソース import 支援:良いサンプルが最高のドキュメント
人はよくできたサンプルで学びます。そこで複雑な import 作業は SRE チームが先に実施し、各チームに「あなたのサービスの VM はコードではこうなります」と見せました。空のエディタで HCL をゼロから書くのと、自分のサービスリソースがすでにコード化された状態から始めるのとでは、ハードルが全く違います。
Chrome 拡張:クリックしていた画面からコードを出す
モニタリング管理はほとんどのユーザーが Web ダッシュボードだけでアラート作成・管理をしていました。CLI や API を使わずブラウザで完結する環境に慣れた人に「エディタで HCL を書いてください」は遠い話です。
そこでユーザーがすでにいる場所、つまりブラウザ内でコードに出会えるよう Chrome 拡張を作成しました。IMON2 の Web ダッシュボードでアラートルールページを開くと、拡張が DOM(document object model)から設定値を読み取り、OpenTofu HCL コードを自動生成します。ユーザーは慣れた画面で設定を見ながら、横のパネルに出たコードをコピーして PR に出せます。ポイントは「Web UI を捨てろ」ではなく「Web UI から始めてコードで終わる」アプローチです。Chrome 拡張は Web UI の代替ではなく、従来の運用習慣と IaC ワークフローをつなぐ橋渡しでした。
| プラグイン例 |
|---|
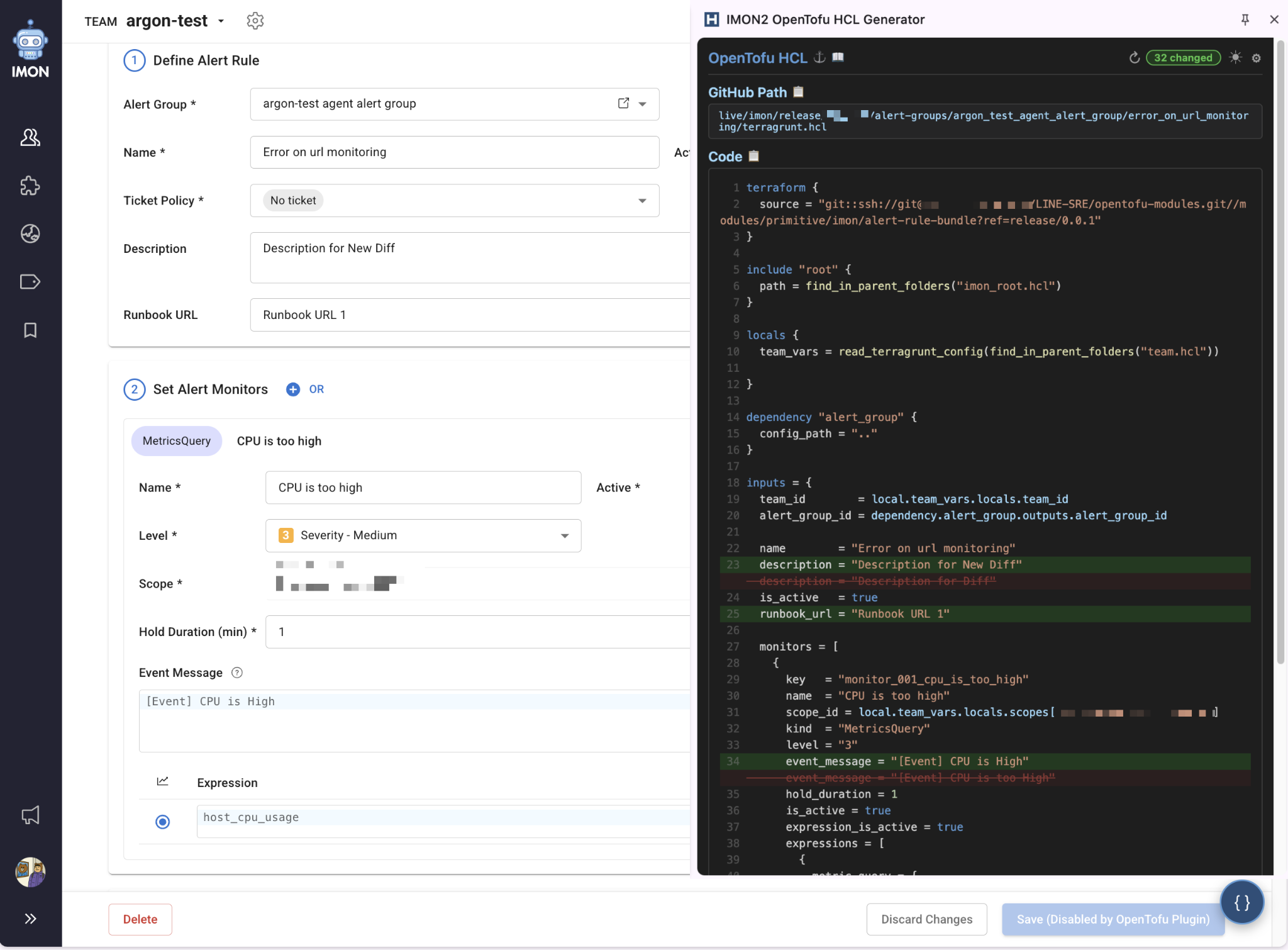 |
Opentalk:SRE からサービスチームへの伝播
ツールや自動化だけで展開が完了するわけではありません。人同士で直接共有することも必要です。当社 SRE では隔週で「Opentalk」という技術共有セッションを運営しています。このセッションで IaC 導入背景、リポジトリ構成設計、PR ベースの変更フローなどを共有しました。発表後のフィードバックは実際の改善にもつながりました。こうした現場の声を直接聞き、反映するプロセスがあったからこそ、ツールやプロセスを現場に合った形に磨き上げることができました。
展開経路も段階的に設計しました。最初から全サービスチームに一斉説明するより、「Opentalk」で各サービス担当 SRE に IaC 運用方法を先に伝え、その担当 SRE が自チームの状況に合わせて案内する方が効果的だと考えました。
ブログ
この記事自体も展開戦略の一部です。構成や意思決定過程を文章化しておけば、新規メンバーや IaC 導入を検討する他チームも「なぜこうしたのか」をコード以外からも理解できます。コードは「何を」を、ブログは「なぜ」を説明します。
導入後に変わったこと
IaC が定着し、変化はシステムから人にまで及びました。
運用変更:すべての変更が Git に残る
最も大きく変わったのは変更履歴です。すべてのインフラ変更に作成者・日時・理由・レビュー担当が残ります。「このサーバー誰が作った?」という疑問も担当者の記憶ではなく、Git ログや PR を見れば分かります。
commit a1b2c3d
Author: engineer-a
Date: 2024-12-15
feat: add staging VM for payment-service
- 4vCPU_8GB, Rocky Linux 9.4
- Requested by: payment team (#TICKET-1234)
Reviewed-by: engineer-bIaC の最大の価値の一つは PR ベースのレビューです。インフラ変更がコードで表現されることでフィードバックループが生まれます。例えば新規 VM 作成 PR で次のようなフィードバックがやり取りされます。
「custom_tag が抜けています。DB ACL 設定のためにこの tag の追加が必要です。」
「BMT(Benchmark Test)の結果、トラフィックに応じてメモリ使用量が多いので、この flavor ではなく Memory Intensive にした方が良いと思いますがどうでしょう?」
インフラ作成時にこうしたフィードバックがあるのは、コンソールで一人でクリックしていた時には不可能でした。これにより誤設定がインフラに反映される前に防げます。さらに CODEOWNERS 設定で必須レビュー担当を指定すれば、レビューなしではマージできないよう強制できます。このレビューは自動化 CI/CD パイプラインと連携し、次のように動きます。
-
Plan:PRが作成されると自動実行(変更内容の影響を事前に確認)
-
Review:チームが差分をレビュー(レビュアーが変更内容を確認し、フィードバック)
-
Apply:マージ時に自動デプロイ(承認済みの変更のみインフラに反映)
-
Drift Check:毎日自動スキャン(コードと実際のインフラの差分を検知)
こうしたレビュー付きワークフローはサービス・環境(Verda、Flava、IMON)ごとに分離して運用しています。加えて状態ロック時の「force-unlock」ワークフローも全プロジェクトに用意し、状態ロック復旧のためにサーバーへ直接入る必要もありません。
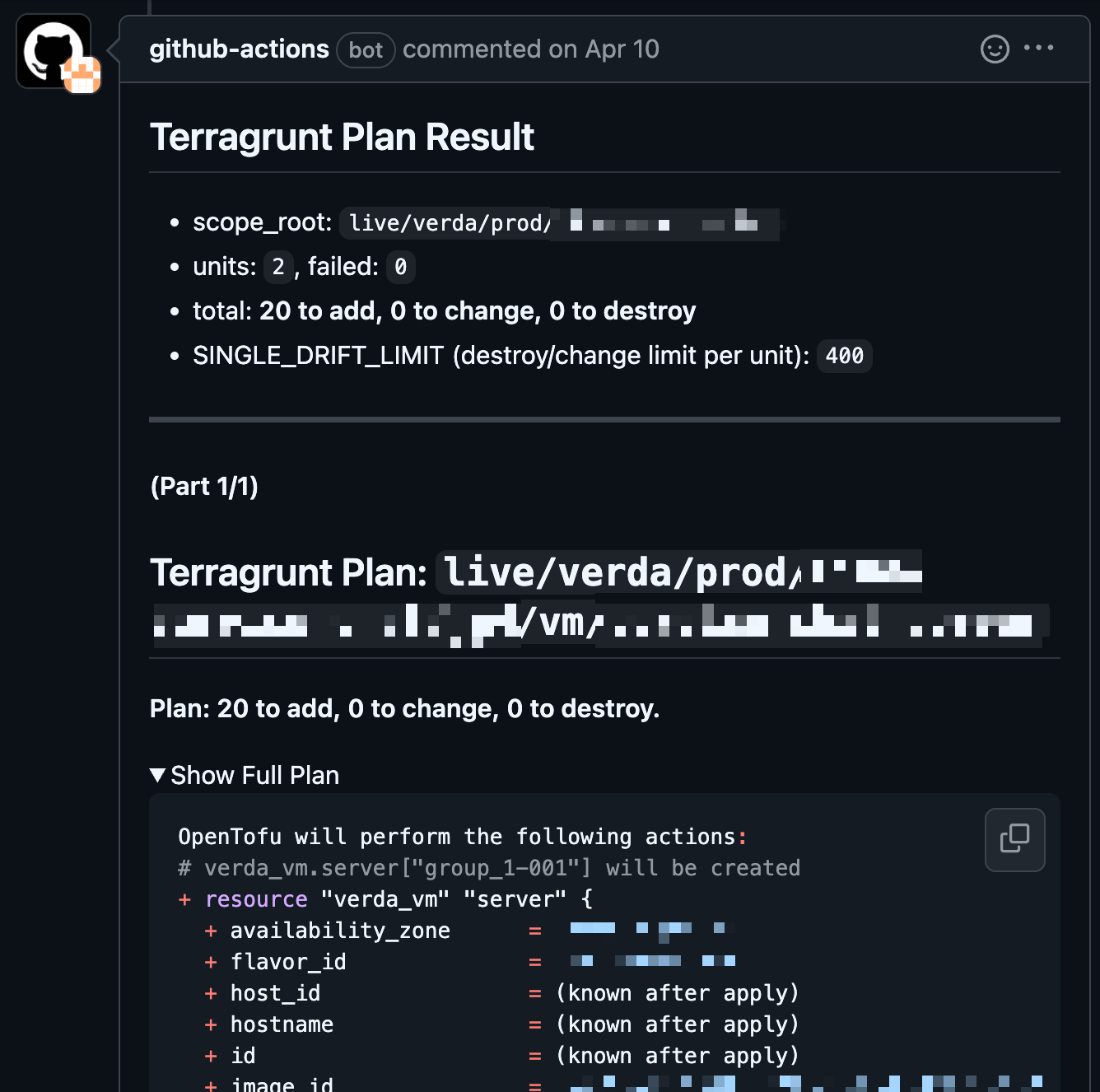
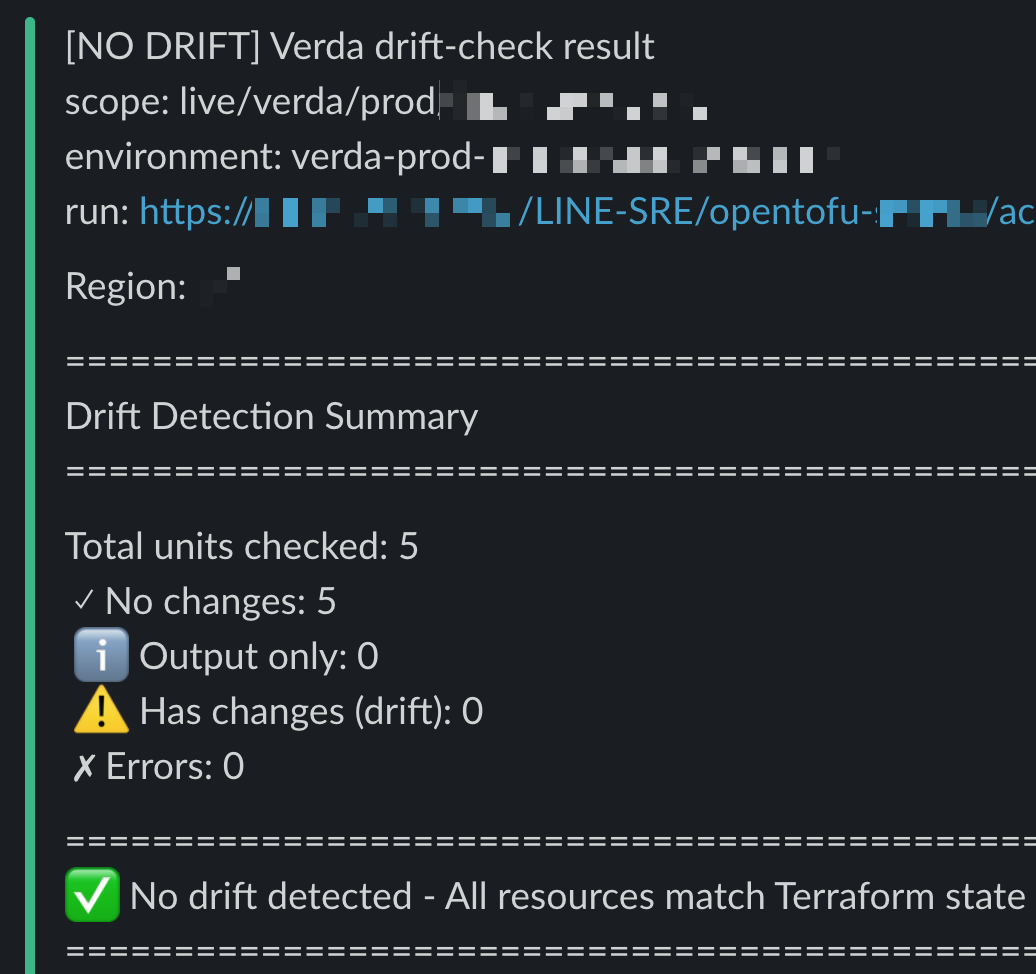
各段階の成果物はすべて透明に共有されます。plan 結果は PR に自動コメントされ、「この PR をマージすると何が起きるか」全員が確認できます。Apply 結果はデプロイ後に Slack へ通知され、成功/失敗を即時確認でき、Drift Check は毎日実行され、コンソールでの変更を全差分とともに Slack で通知します。
| PR に自動付与される Plan 結果 | Slack で受信した Drift Check 通知 |
|---|---|
 |  |
Drift Check:手動変更も自動検知
IaC の恩恵はリソース作成・変更だけではありません。前述の CI/CD パイプライン第4段階 Drift Check で毎日コードと実インフラの差分を検知し、Slack で通知します。
ここでいう Drift とは、コー��ド宣言状態と実クラウド状態が一致しない現象です。誰かがコンソールで直接修正すると発生します。例えばサービス公開前のテストで誰かが素早く DNS レコードの IP をコンソールで変更し、その後復元し忘れた場合、その変更は追跡困難です。しかしコードには元の IP が残っているため、Drift Check が公開前に差分を検知し、Slack で通知します。これによりサービス公開前に元に戻せ、ユーザートラフィックが誤った IP に流れる事態を未然に防げます。
モニタリングもコード化
モニタリングアラートもコードで管理することで、閾値変更時に PR 一つで複数アラートを一括修正できるようになりました。なぜ閾値を変更したかもコミットメッセージで履歴が残るため、後から「誰がなぜ値を変えた?」と追跡する必要がなくなりました。新サービスに同じアラート構成を作る際も、既存コードをコピーして値だけ変えれば済みます。ダッシュボードで一つずつクリックしていた時に発生していた微妙な設定差も消えました。インフラだけでなくモニタリングまでコードで管理することで、サービス全体の運用構成がリポジトリ内で追跡可能になりました。
ドキュメントを置き換えるコード
この変化はシステムにとどまらず、人にも及びました。以前は新メンバーが加わるとインフラ構成を Wiki や口頭で説明していました。どの VM がどのサービスか、LB 設定はどうなっているか、なぜこのアラートルールがこの閾値なのか、人が直接説明する必要がありました。
今はリポジトリを見せれば済みます。コードを読めば現状のインフラ構成が分かり、PR 履歴を追えば「なぜこう変�わったか」も分かります。過去 PR のレビューコメントには意思決定の背景も残るからです。「この flavor の代わりに Memory Intensive を使った理由」「このアラート閾値を下げた経緯」なども別途ドキュメント化せず履歴に残ります。シニアしか知らなかったインフラ知識がコードと履歴で自然に共有され、オンボーディングの時間も短縮されました。
インフラセルフサービスの始まり
IaC 導入前はすべてのインフラ変更が SRE チーム経由でした。しかしモジュール整備・展開が進むと変化が生まれました。A サービス担当開発チームは自ら Terragrunt コードを書き PR を出します。SRE チームはレビューのみで、コード作成は代行しません。
他チームも後述の AI エージェントでインフラ変更を進めています。Slack で自然言語リクエストすればエージェントがコード生成・PR 作成まで行うため、HCL を知らなくても IaC ワークフローに参加できます。直接コードを書く場合も AI エージェント経由でも、すべて同じ GitOps パイプラインを通ります。入口は違ってもレビュー・追跡の原則は同じです。
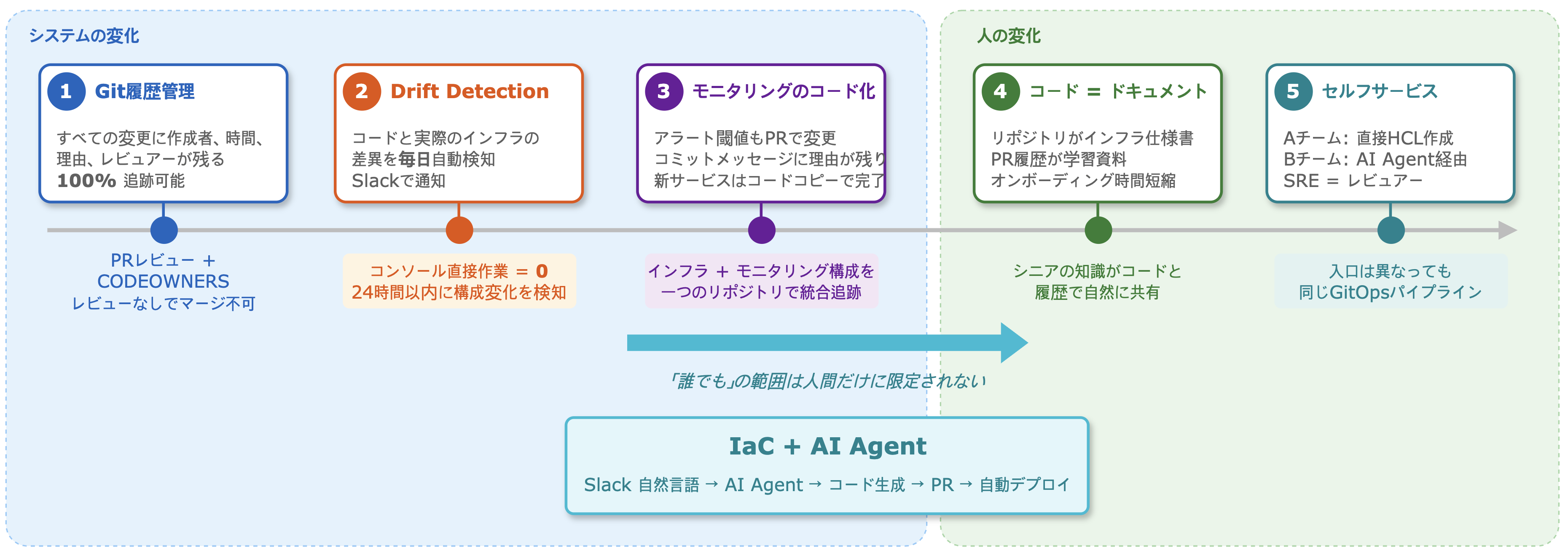
インフラのすべてがコードで表現され、誰もが同じ方法で読んで変更できる体制ができました。そしてここで「誰もが」の範囲が人だけに限られないことに気づきました。
次の段階:IaC と AI エージェントの融合
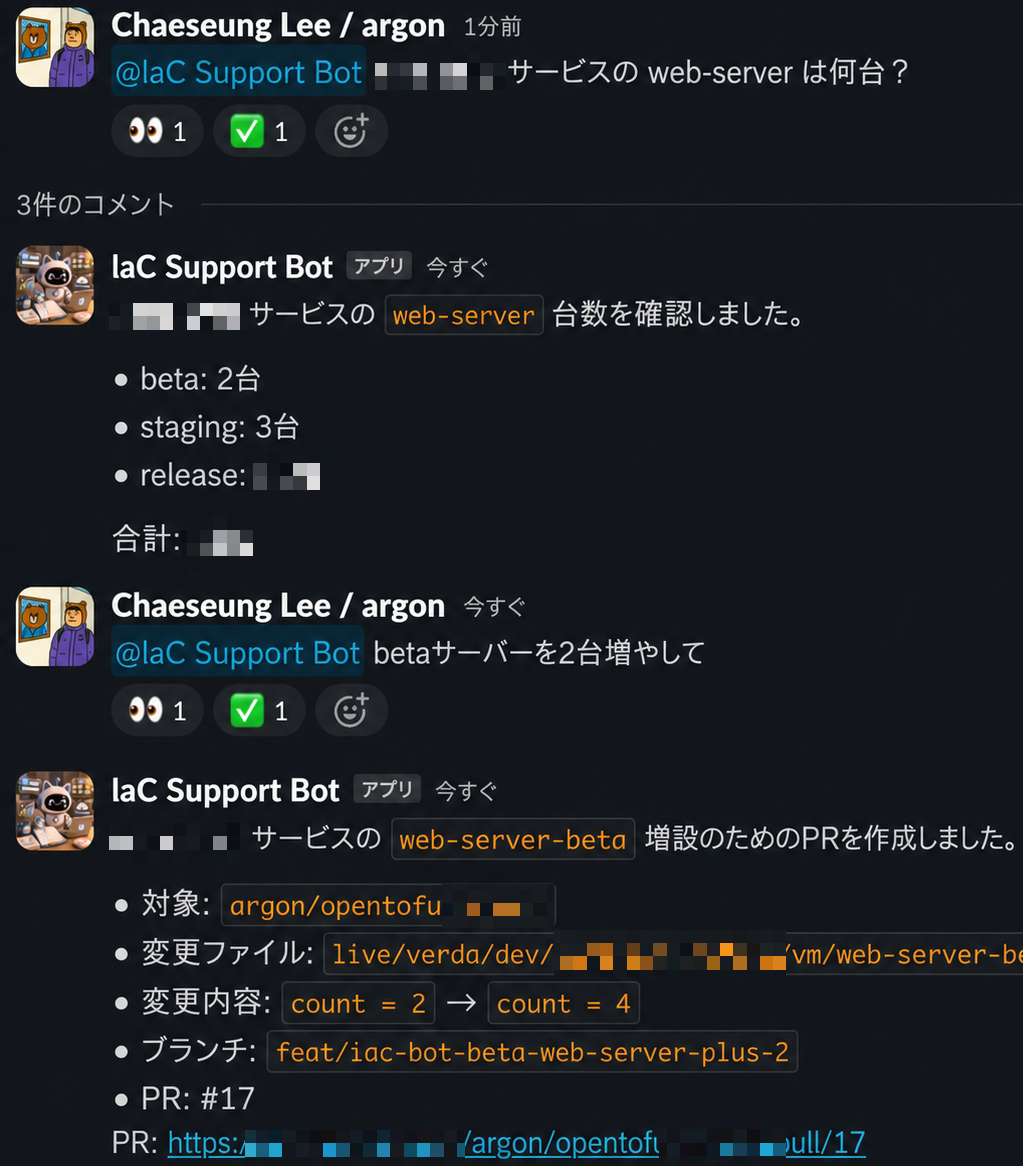
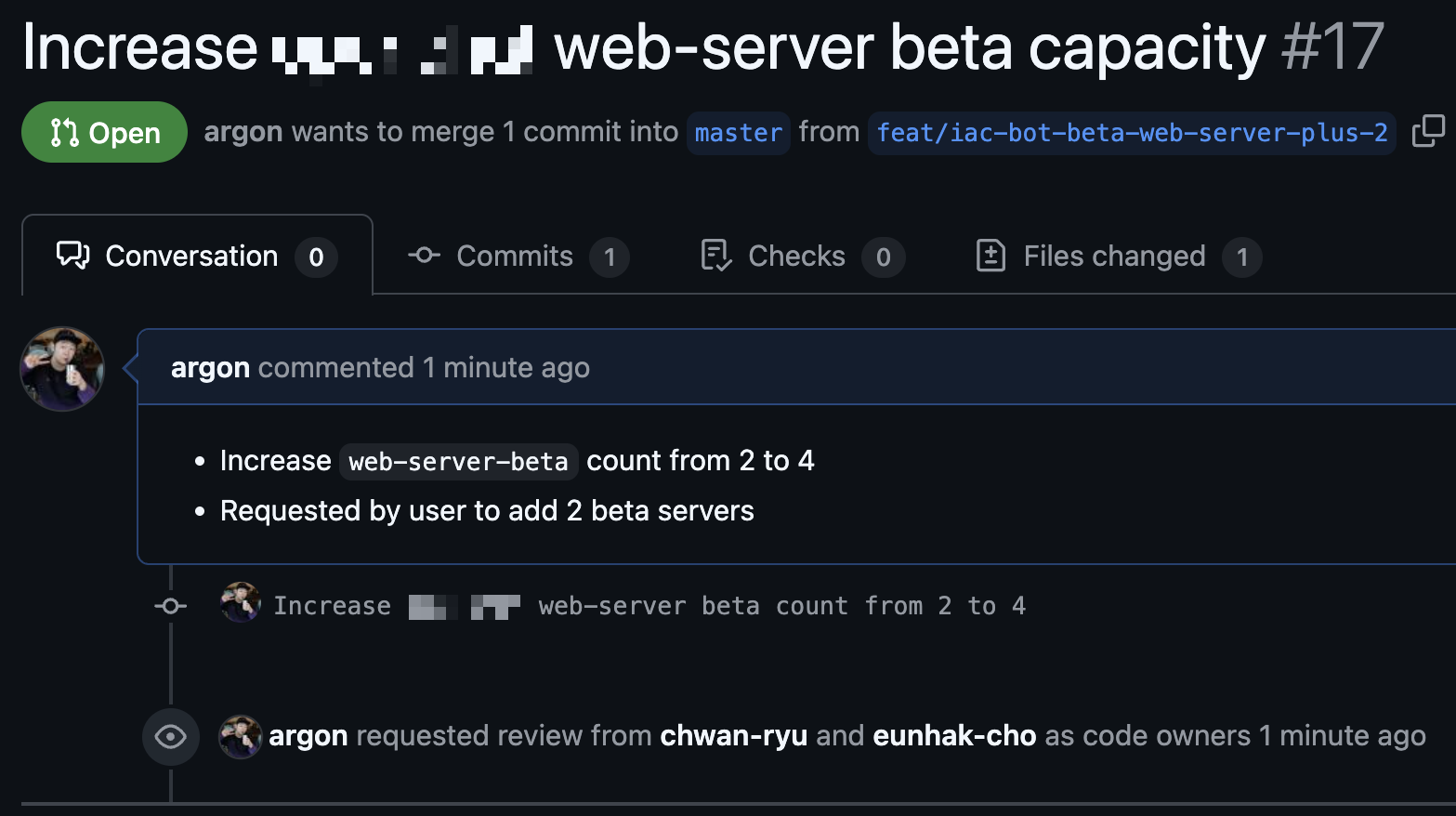
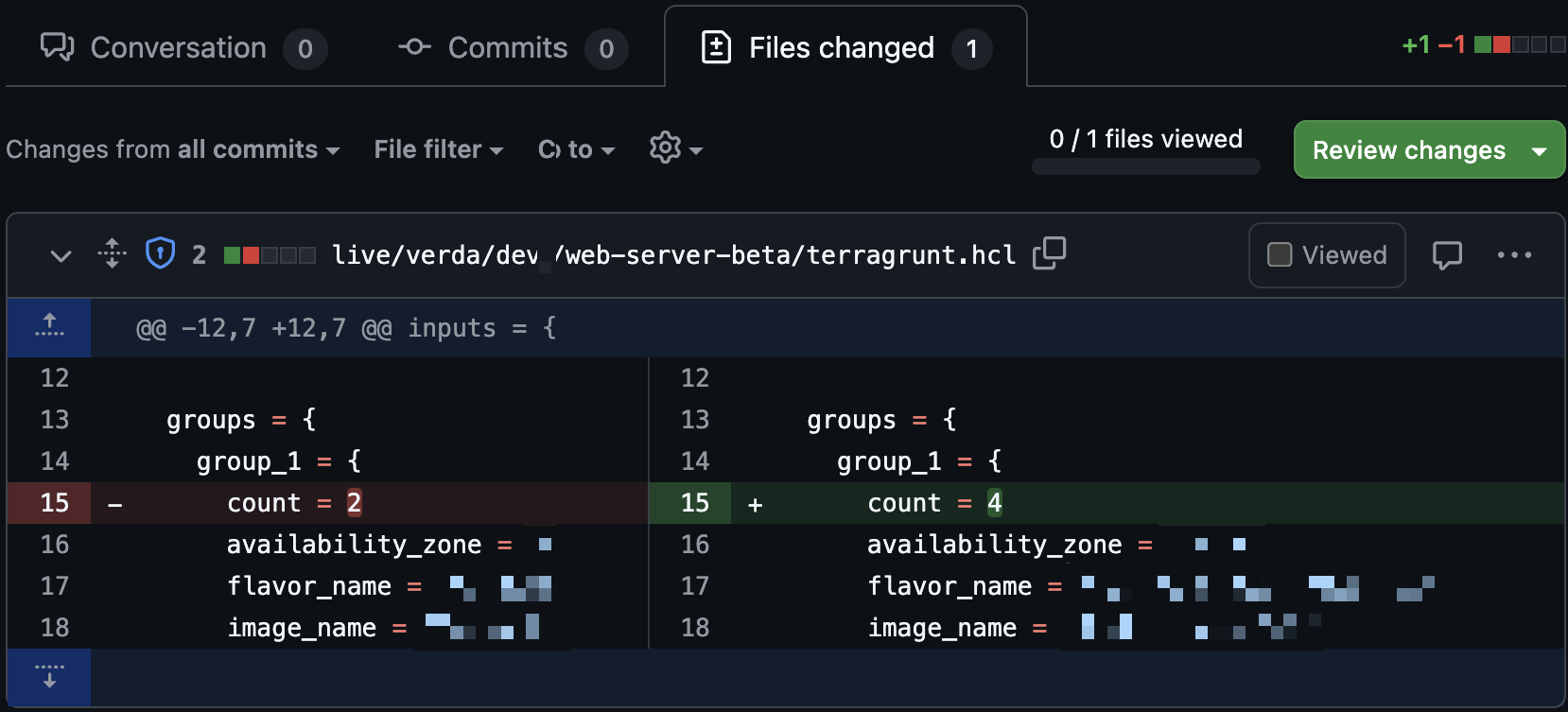
IaC でインフラを管理すると、コードで宣言されたインフラは人だけでな��く AI も同じように読めることに気づきます。「A サービスを2台増やして」「B サービスに LB を追加して」などの繰り返しリクエストはパターンが決まっています。AI エージェントが扱える領域です。そこで AI エージェントに OpenTofu リポジトリを MCP(model context protocol)で接続し、Slack から自然言語でインフラを変更できるボットを作りました。
Slack で自然言語リクエストすると、エージェントが既存コードパターンを参照し Terragrunt コードを生成・PR 作成します。plan 結果は Slack で共有され、人がレビュー・承認すれば自動でデプロイされます。
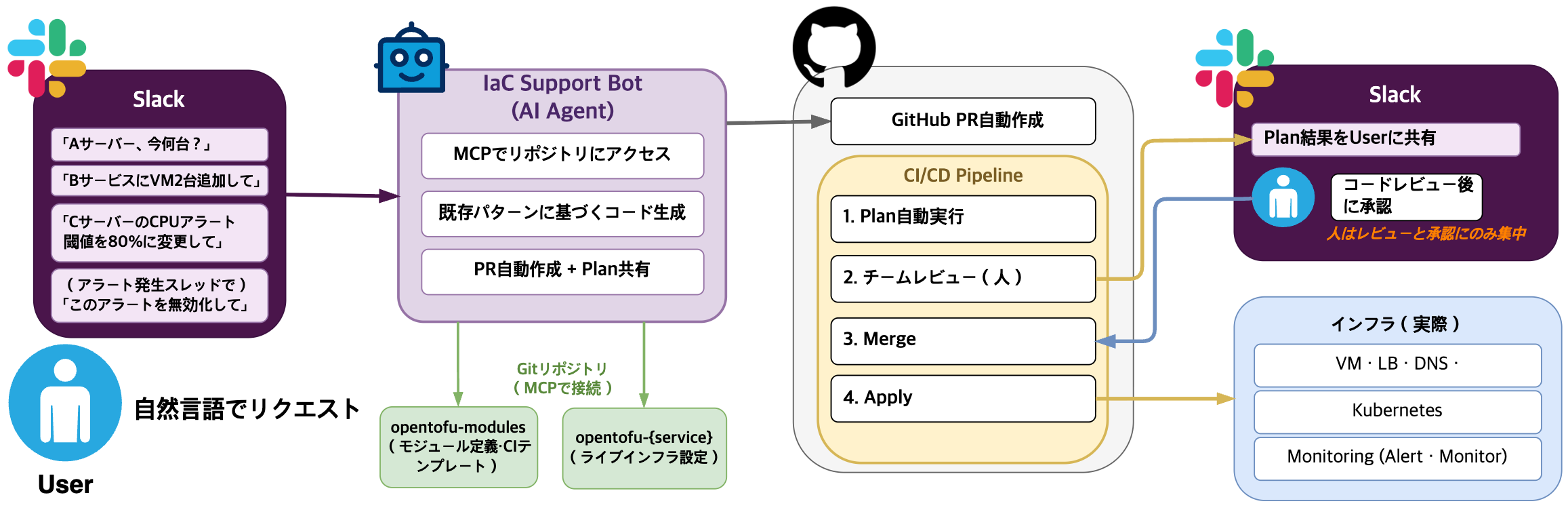
下記は活用例です。コードを直接書かなくても、Slack でサーバー情報を確認し、台数を増やしてと伝えるだけで後はエージェントが準備します。
| 自然言語リクエストに基づくボットの動作例 | PRおよびファイル変更の例 |
|---|---|
 |   |
自然言語リクエスト以外にも、モニタリングアラートをトリガーに AI エージェントが自動で対応コードを生成するシナリオも可能です。
| 対応フロー | 従来(手動対応) | IaC+AI エージェント(自動提案) |
|---|---|---|
| 1. アラート受信 | オンコール担当が Slack 通知を確認 | AI エージェントが自動受信 |
| 2. 状況把握 | コンソールで現状 VM 数・スペック確認 | エージェントが IaC から即時把握 |
| 3. 対応 | SRE にスケールアウト依頼 or 直接コンソールで VM 追加 | エージェントがスケールアウトコード自動生成・PR 作成 |
| 4. レビュー | 事後に「誰がサーバーに追加した?」 | PR に変更理由・アラート・plan 結果す�べて記録 |
| 所要時間 | アラート確認~反映まで数十分 | PR 作成まで数分、承認即反映 |
このように人がリクエストしても、モニタリングシステムがトリガーでも、コードは AI エージェントが書きます。人はレビュー・承認に集中できます。
IaC 導入を検討されている方へ
コンソール作業が面倒・ミスが怖い方なら誰でも試してみることをおすすめします。ただし導入前に知っておくと良い点があります。
導入後は小さな変更も手順を踏む必要あり
「VM のスペックを1つ上げて」などの依頼は、IaC 前ならコンソールで数クリックで済みます。しかし IaC 体制では「コード修正→PR 作成→レビュー→マージ→適用」という段階を踏みます。最初は面倒に見えますが、これは大きなメリットです。新メンバーでもコードを見ればインフラ構成が分かり、決まった手順で安全に変更できます。シニアしか知らなかった知識が自然にコードで共有されるのです。
チーム全体で IaC 文化を受け入れる必要あり
IaC 導入は技術ではなく文化の問題です。チームの誰か一人でもコンソールで直接修正すると、コードと実インフラに差分が生まれるからです。IaC 文化に反するコンソール作業は緊急対応などやむを得ない場合に限定し、変更後は必ず IaC コードに反映して再度一致させる必要があります。
もし反映を忘れても Drift Check が手動変更を検出してくれるので、文化定着の強力な安全装置になります。また意図的にコードと異なる状態を維�持したいリソースは ignore ファイル(例:.driftignore)で Drift Check 対象外にし、別途例外管理も可能です。
運用規模に関係なくまず始めてみてください
運用規模が小さければ import も簡単なので早く始められます。逆に規模が大きければ履歴管理や障害リスク低減のためにも一度試す価値があります。また IaC 導入は、人と AI エージェントが同じビューで見られる体制を作る=AI 自動化の土台を築くことでもあります。
おわりに
最初は途方に暮れました。運用中リソースをコード化するのは、走る列車の車輪を交換するような感覚でした。第1段階で初めて1サービスを移行するのに1か月かかりました。ツール選定、パイプライン設計、状態正規化スクリプト作成、ガードレール設置……。でもその1か月がなければ第2段階もありませんでした。同じ期間で4サービスを追加できたのは第1段階で作った基盤のおかげです。
今はインフラ変更が怖い作業ではありません。コードを直し、PR を出し、レビューを受け、マージする。普段の開発ワークフローそのままです。今や「このサーバー誰が作った?」と聞かれれば Git ログを見せれば済みます。
実はこのすべての始まりは、Verda・IMON の Terraform プロバイダーを作ってくれた SRE 9 チームのおかげです。社内クラウドプラットフォームをコードで扱えるようにしてくれたプロバイダーがなければ、この記事もありませんでした。この場を借りて感謝します。
本記事が私たちの事例にとどまらず、IaC 導入を検討する皆さんの第一歩の参考になれば幸いです。長文をお読みいただきありがとうございました。
Tech-Verse 2026 開催案内 — 6月29日

本記事は Tech-Verse 2026 イベントの公式記事として公開されています。Tech-Verse 2026 は LY Corporation が主催する技術カンファレンスです。革新的な技術的挑戦や現場のリアルなインサイトを発信します。
YouTube LIVE で生配信予定ですので、ご興味のある方はぜひご視聴ください。


