This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Hello. We are Kenta Kihara and Yifan Yuan, developers of the machine learning platform at LY Corporation. In this article, we present a case study in which we solved the cold start problem encountered in LINE Part Time Jobs' search re-ranking by adjusting how embeddings are handled.
Introduction: Search re-ranking for LINE Part Time Jobs
LINE Part Time Jobs is a job listing service specializing in part-time jobs. Users can search and apply to part-time jobs. We have been personalizing the ranking on the search results screen based on user behavior history to improve business KPIs and user experience.
The search process consists of two stages: A retrieval stage that fetches candidates matching the user's query, and a re-ranking stage that re-orders the top of those candidates. Since queries change with every request, precomputing search results ordering via batch processing is impractical. Therefore, these operations must be computed in real time.
Due to the system requirements and computational complexity, for LINE Part Time Jobs' search re-ranking, we have been reusing the two-tower user-to-item embeddings produced by another batch pipeline, and ranking candidates by the cosine similarity between the user and item embeddings.
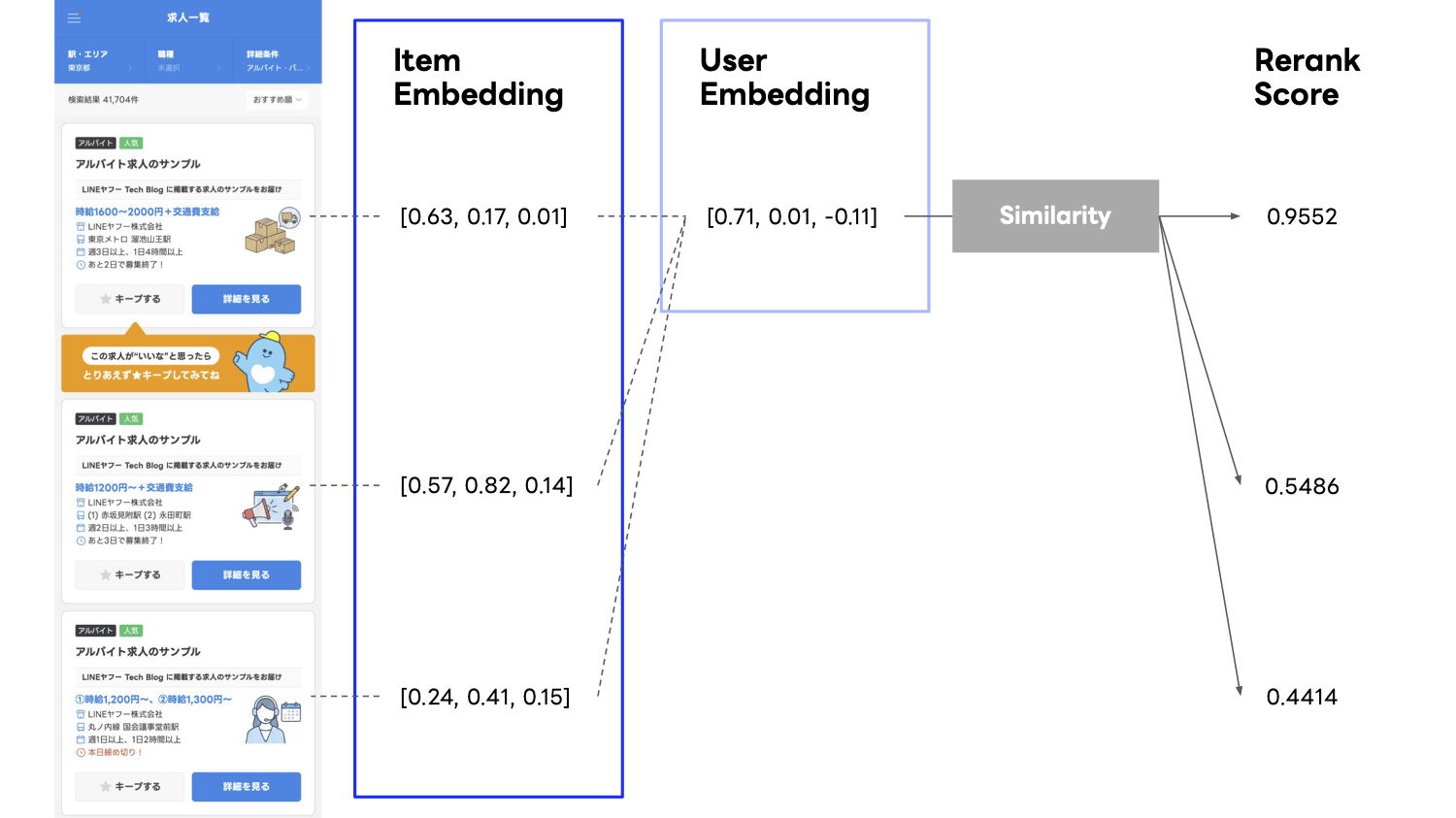
However, this approach still left room for improvement.
First, this system didn't utilize the information from the search screen. Since the embeddings didn't include query information, we could not fully reflect the user's intent. For instance, even if a user specified a station via a query, the proximity to the station was not taken into account; instead, a job listing near a neighboring station a few hundred meters away could sometimes be ranked higher.
Second, the embeddings include the information beyond the search screen. They capture actions from all modules other than the search screen, such as "similar jobs" or recommendations via LINE Official Account. While these embeddings are useful for capturing long-term user preferences, they leave room for improvement when used directly on the search screen.
To leverage the unique characteristics of each screen and module, our team has been promoting a two-stage recommendation approach with a dedicated re-ranking model, and we considered introducing a dedicated real-time re-ranking model for LINE Part Time Jobs search as well.
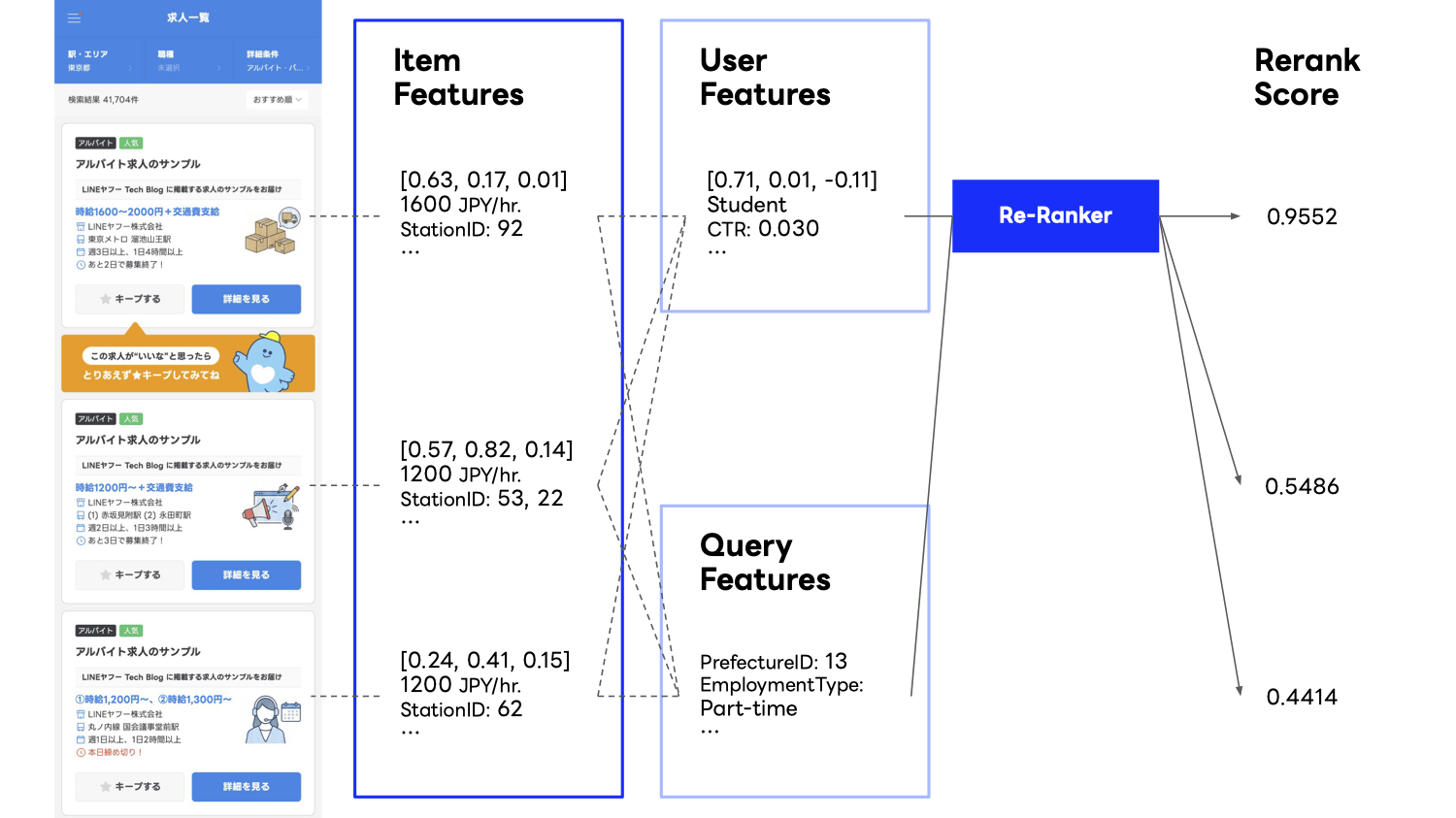
Challenges when introducing the re-ranking model
While experimenting with a dedicated re-ranking model, we encountered two main challenges:
1. Cold start problem
Most job listings on LINE Part Time Jobs are replaced at the start of each month. As a result, until sufficient training data accumulates for the re-ranking task, model performance can degrade significantly—a classic cold start problem.
2. Non-stationarity of the embedding space
As noted above, because the embeddings reflect user preferences, using them as features significantly improved re-ranking performance in offline experiments. However, deploying this in an online, real-time system requires considering the characteristics of the models it depends on.
Generally, two-tower models are periodically retrained from scratch with random weights to avoid performance degradation, which alters the embedding space with every training session. Consequently, if downstream tasks consume raw embeddings as features, it causes a data mismatch between training and inference.
Approach: Embedding stabilization
To address these issues, we adopted a post-processing technique to stabilize embeddings. Below we summarize the paper we adopted and describe how we applied it at LINE Part Time Jobs.
Paper: Zielnicki & Hsiao. Orthogonal Low Rank Embedding Stabilization (RecSys '25)
Basic idea
The embedding space is sequentially stabilized by aligning each day's embeddings with the previous day's stabilized ones (using raw embeddings on the first day). Since the previous day's stabilized embeddings serve as the next day's reference, anchoring the process to a fixed reference date is unnecessary.
This ensures continuity in the embedding space across daily model retrains, making them reliable, time-comparable features.
For example, yesterday's embeddings can be used in a downstream model trained on today's features, and vice versa. Thus, we don't need to strictly align the update schedules for embeddings and downstream models, removing the operational burden of version mismatches.
Method
The stabilization pipeline consists of two stages: Low-rank singular value decomposition (SVD) followed by orthogonal Procrustes alignment.
Algorithm 1. Low-rank SVD
Low-rank SVD transforms each training embedding space into a more standardized low-rank representation.
Let embedding dimensionality be , number of items , and number of users (, ). The item and user embedding matrices can be written as and , respectively.
In a two-tower model, scores are computed using inner products between item and user embeddings, so the score space corresponds to a large matrix . Instead of decomposing this huge matrix directly, low-rank SVD computes efficient transformation matrices and from and . Applying these yields standardized low-rank representations and .

Algorithm 2. Orthogonal Procrustes
Next is spatial alignment using orthogonal Procrustes.
This method finds an orthogonal transformation that best aligns the day's embeddings to a reference embedding (the previous day's stabilized embeddings). Because orthogonal transforms only rotate or reflect the space, they tend to preserve embedding distance relationships and inner-product structure. This enables us to align daily embedding spaces continuously while preserving the scoring properties of the two-tower model.

Implementation details
Since LINE Part Time Jobs handles a massive volume of data, the algorithm must be implemented with space complexity in mind. Therefore, we implemented it using Apache Spark, which enables scalable computation through distributed processing.
Optimizing low-rank SVD
Although the paper's original low-rank SVD relies on QR decomposition, we opted for Cholesky decomposition for better computational efficiency, as only the upper-triangular matrix is required. The procedure is as follows:
- Compute the Gramian matrix .
- Perform Cholesky decomposition on to obtain the QR .
This procedure is equivalent to QR decomposition.
-
- : Orthogonal column vectors
- : Upper-triangular matrix
-
- Since is column-orthogonal (), it cancels out.
Thus, the obtained from Cholesky () matches the from QR decomposition, enabling a more efficient computation.
Distributed processing for orthogonal Procrustes
- Compute .
- Since this matrix multiplication is huge, we leverage distributed parallel processing of Apache Spark.
- Perform SVD on .
- is a small matrix and sufficiently fits in a single node's memory, so it can be computed directly with NumPy.
Evaluation and discussion
Effect of stabilization
Before stabilization, correlations between embeddings generated on arbitrary two days were very weak, close to zero.
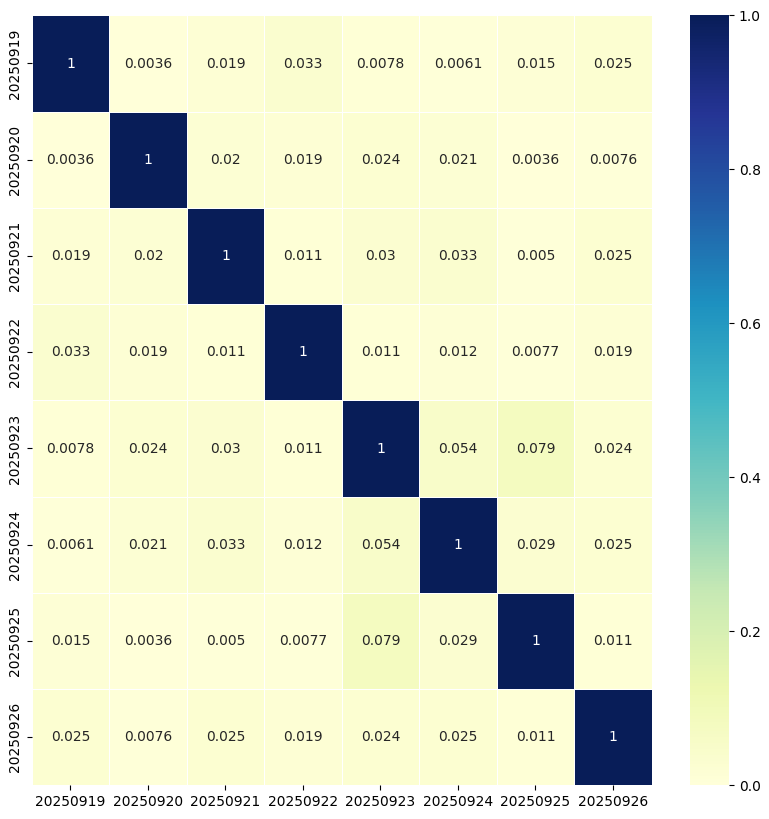
After introducing stabilization, we confirmed that both user and item sides maintain a similarity of about 0.88 even after one week.
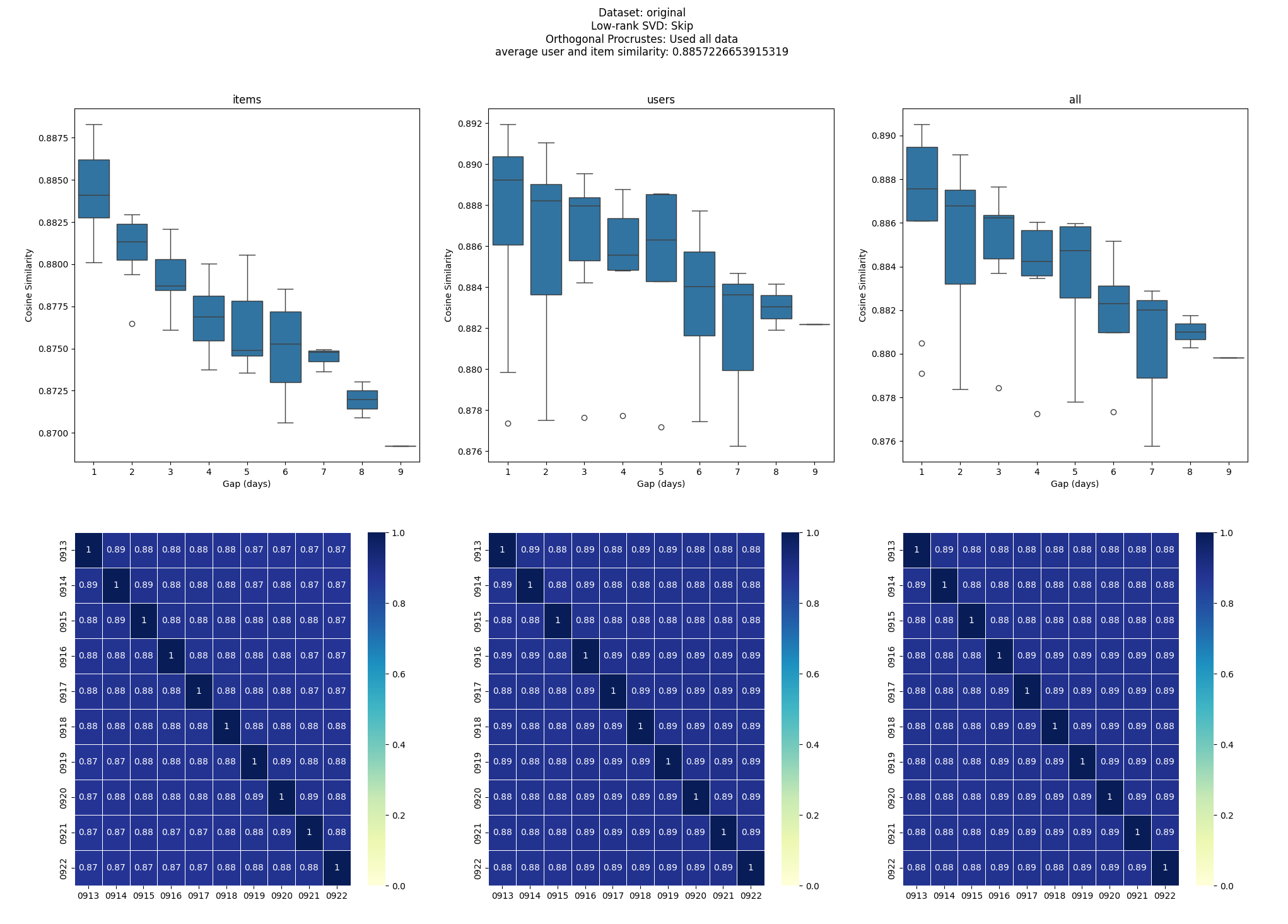
Even in longer-term verification, vector similarity remained around 0.87 after one month.
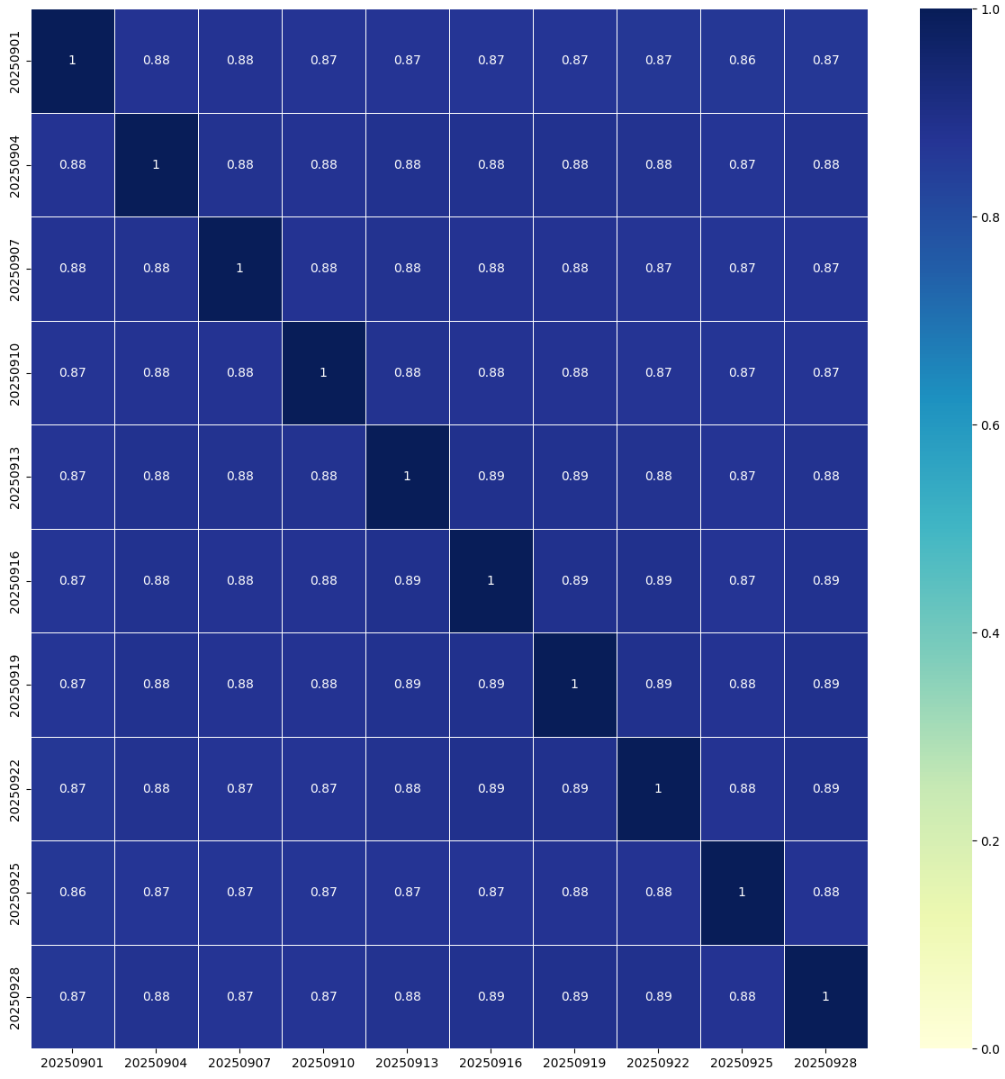
These results suggest that even when the data used during inference does not perfectly match the training data, significant degradation in model performance due to embedding space drift can be suppressed.
Offline evaluation
We performed offline evaluation using models trained with pre- and post-stabilization embeddings as features, with various user actions (such as clicks and conversions) as ground truth. We added two-tower embeddings—where the versions used for training and inference were trained on different dates—directly as features to a neural-network baseline model.
Adding pre-stabilization embeddings caused nDCG to degrade by about 1 %–5 % due to embedding space mismatch. However, using post-stabilization embeddings improved results: Conversion nDCG by about +9.0 % and Click nDCG by about +4.5 %.
Table. Offline evaluation results for embedding stabilization
| Model | Click nDCG | Conversion nDCG |
|---|---|---|
| Baseline | 0.4898 | 0.4601 |
| Pre-stabilization | 0.4777 | 0.4540 |
| Pre-stabilization + dimensionality reduction | 0.4799 | 0.4533 |
| Post-stabilization | 0.5120 | 0.5017 |
Online evaluation through A/B testing
We evaluated the model that combines stabilized embedding features with additional cold-start countermeasures through A/B testing. While there was no significant improvement on the search screen KPI alone, the overall service showed substantial gains: service-wide KPI +4.7 % and revenue +6.5 %, among the largest improvements we've observed in A/B tests.
Discussion
Given the A/B test results and the fact that the two-tower embeddings are trained on service-wide user behavior, it suggests that the re-ranking model effectively captured the "long-term user preferences" encoded in the embeddings and positively influenced subsequent user behavior starting from the search screen (for example, exploration and applications in other modules).
Furthermore, the cold start problem initially encountered when applying the re-ranking model was successfully overcome in the treatment group including the stabilized embedding features.
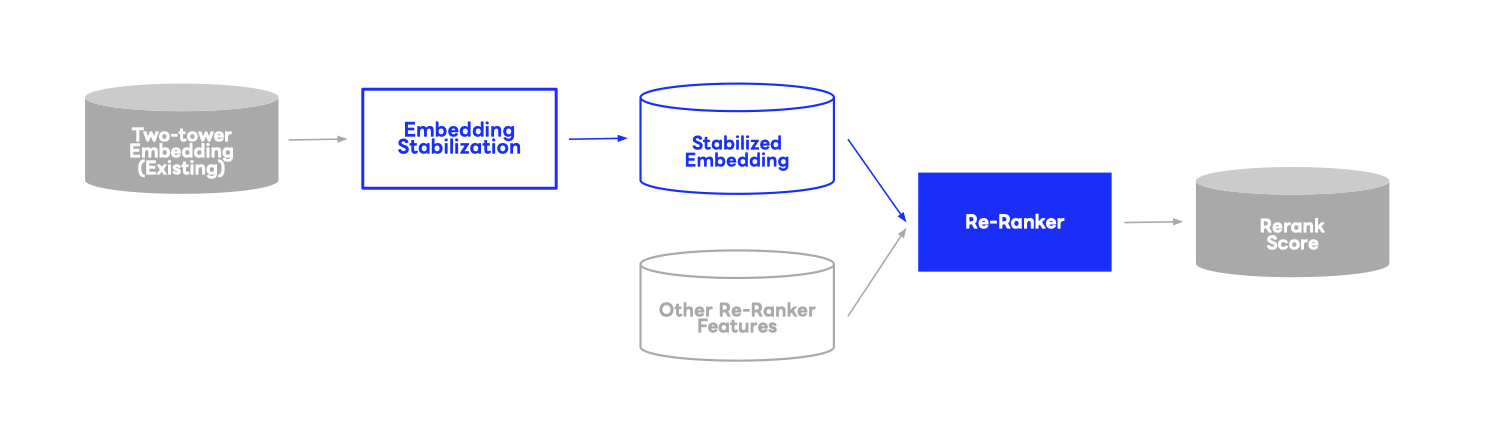
Another major advantage of this approach lies in the fact that spatial alignment is performed as a post-processing step on the generated embeddings, without any modification to the two-tower model itself. Consequently, there is no need to significantly alter existing training pipelines or model architectures, ensuring seamless adoption. Minimizing the impact on existing systems is a critical factor in operating real-world machine learning systems.
Future outlook
LINE Part Time Jobs is expanding the variety of job sources in addition to existing providers. We will continue validating that this method remains effective in such dynamic conditions.
Furthermore, to leverage these findings across LY Corporation's diverse services, we plan to further enhance a company-wide machine learning platform to improve user experience. The real-time re-ranking model used in this work was built on our in-house online ML platform, which we will continuously strengthen moving forward.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


