LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
こんにちは。LINEヤフーで機械学習プラットフォームを開発している木原健太と袁逸凡です。今回は、LINEバイトの検索リランキングにおいて直面していた cold start problem を、embedding の扱いを工夫することでシンプルに解決した事例をご紹介します。
はじめに:LINEバイトの検索リランキング
LINEバイトはアルバイト求人を検索・応募できるサービスです。これまで私たちは、LINEバイトの検索結果一覧画面において、ユーザーの行動履歴を基に並び順をパーソナライズし、事業KPIおよびユーザー体験の向上を図ってきました。
検索は、ユーザーが指定したクエリに適合する候補を取得する retrieval stage と、その候補の上位を並び替えるリランキング stage の two-stage に分けられます。リクエストごとにユーザーのクエリが変わるという検索の性質上、事前にバッチで計算をしておくことは現実的ではありません。そのため、これらの処理はリアルタイムで行う必要があります。
このシステムや計算量の複雑さのため、これまでのLINEバイトの検索リランキングでは、別パイプラインのバッチで生成した user-to-item recommendation の two-tower embedding を転用し、cosine similarity 順に並び替えるというシンプルな方法を採用していました。
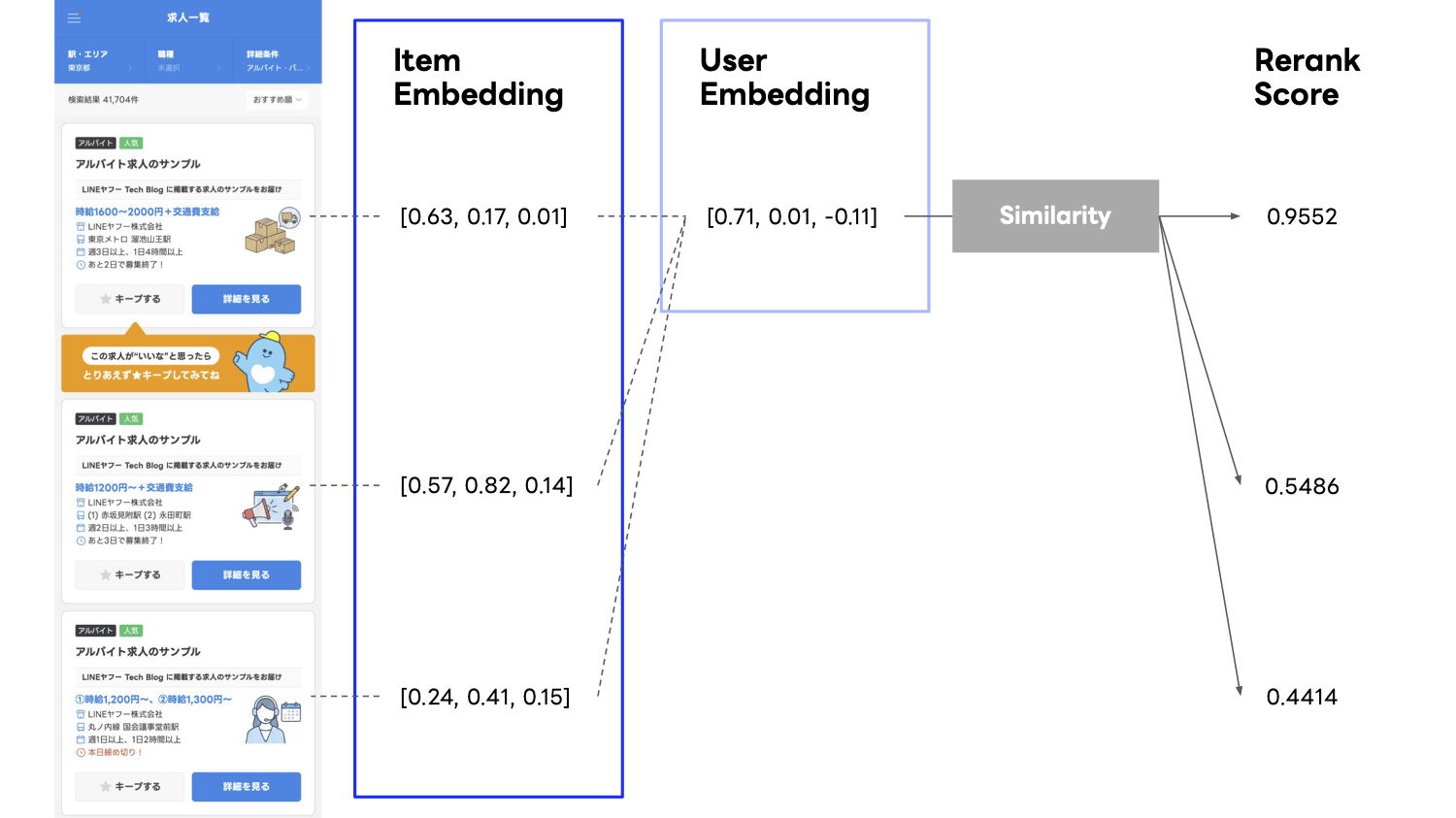
しかし、この手法にはいくつか改善の余地がありました。
まず、検索画面の情報を活用できていない点です。Embedding にはクエリの情報は含まれておらず、ユーザーが入力した意図を十分に反映できていませんでした。具体的には、駅を指定した際にも、駅からの近さは考慮されず、むしろ数百メートル歩く隣駅の求人が上位に来ることもありました。
また embedding は検索画面以外の情報も含みます。似ている求人のようなモジュールや、LINE公式アカウントを通じたおすすめなど、あらゆる面での行動を含んでいるため、ユーザーの好みの傾向を捉えられる有用性はあるものの、検索画面ではさらに改善の余地がありました。
このような画面やモジュールごとの特性を活かすため、チームでは専用のリランキングモデルを用いた two-stage 制の推薦を推進しており、LINEバイトの検索でも同様に専用モデルの導入によるリアルタイムなリランキングを検討していました。
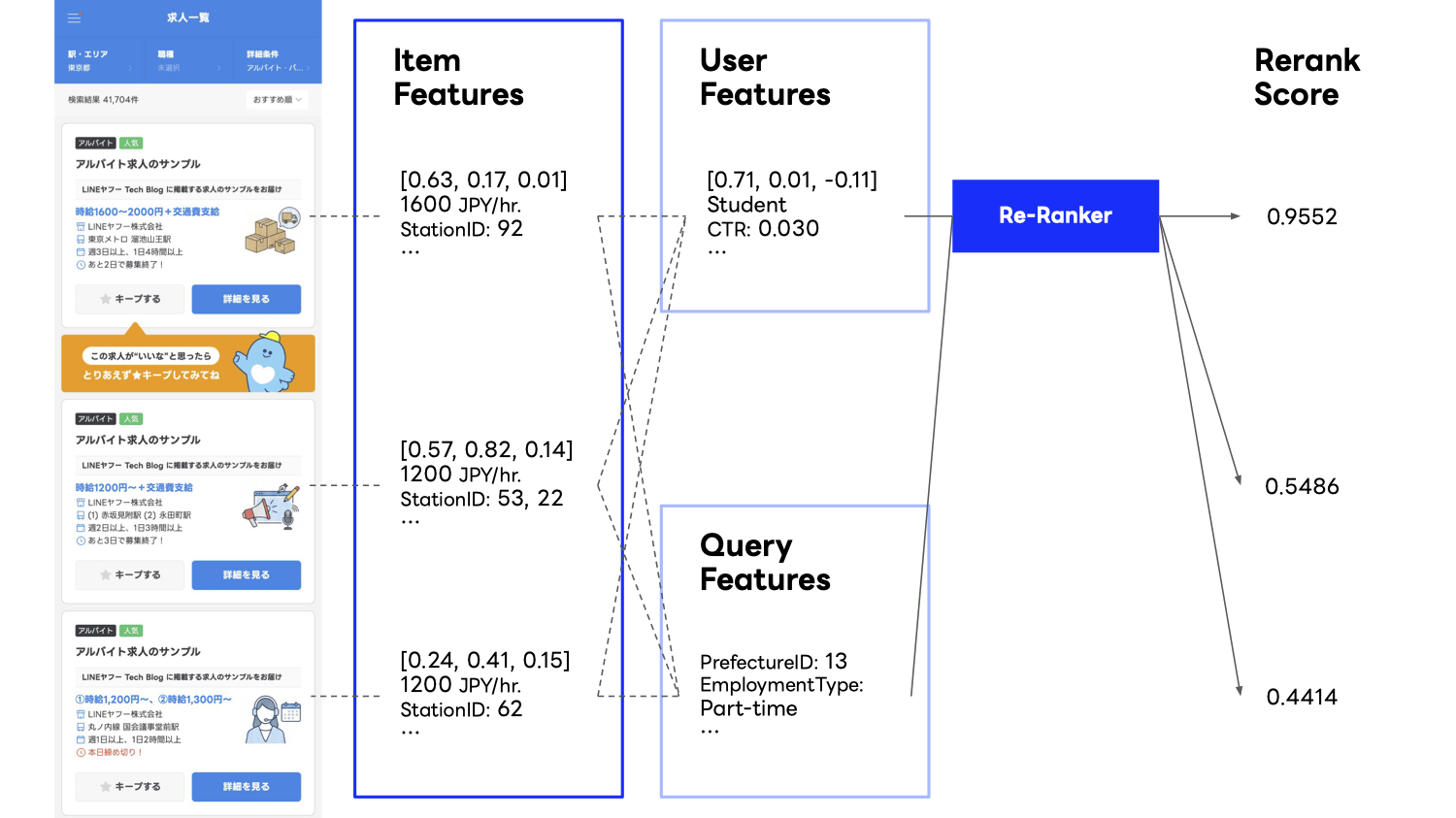
リランキングモデル導入の課題
専用リランキングモデルの導入に向けて実験を進めるなかで、以下の二つの課題に直面しました。
1. Cold start problem (コールドスタート問題)
LINEバイトで扱うアルバイト求人は、月初にその大部分が入れ替わります。そのため、検索リランキングのための十分な学習データが揃うまでの期間、モデルの性能が大幅に悪化するcold start problem が起こることがわかりました。
2. Embedding 空間の非定常性
上述の通り embedding にはユーザーの好みの傾向が反映されているため、特徴量として活用することで、リランキングモデルの性能を大幅に向上させることがオフラインの実験で確認できました。しかし、これをオンラインに、つまりリアルタイムで動くシステムにするためには、依存するモデルの性質も考慮する必要があります。
一般的に two-tower モデルは性能悪化を避けるため、定期的にランダムな重みからスクラッチで学習しますが、学習のたびに embedding 空間が変わってしまいます。そのため、下流のタスクで embedding を特徴量として利用すると、学習時と推論時のデータの不整合が生じてしまいます。
アプローチ:Embedding Stabilization
これらの問題を解決するために、私たちは embedding を後処理で安定化する手法を採用しました。ここからは、採用した論文の内容を詳細に解説したのち、LINEバイトにどのように適用したかを紹介します。
論文: Zielnicki & Hsiao. Orthogonal Low Rank Embedding Stabilization (RecSys '25)
基本アイデア
各日の embedding を前日の安定化済み embedding (初日なら安定化せずにそのまま使います) に対してアライメントすることで、embedding 空間を逐次的に安定化します。前日の変換済み embedding を次の日の基準として利用するため、特定の基準日を固定的に参照し続ける必要はありません。
これにより、日次でモデルを再学習しても、embedding の空間を連続的に保ち、時間をまたいで比較可能な feature として利用できます。
たとえば、昨日生成した embedding feature を、今日の feature で学習した下流モデルに入力しても問題なく扱えるようになります。その逆も同様です。つまり、embedding feature と下流モデルの更新タイミングを厳密に揃える必要がなくなり、モデルと feature のバージョン不整合を気にせずに運用できます。
手法
安定化の流れは、Low Rank SVD と Orthogonal Procrustes の二段階で構成されます。
Algorithm 1. Low Rank SVD
Low Rank SVD の作用は、各学習の embedding 空間を、より標準化された低ランク表現へ変換することにあります。
Embedding の次元数を , アイテム数を , ユーザー数を (, ) とすると、アイテムおよびユーザー embedding を並べた matrix はそれぞれ , と表せます。
Two-tower モデルではアイテム embedding とユーザー embedding の内積によってスコアを計算するため、スコア空間は の大きな行列になりますが、直接分解する代わりに Low Rank SVD で , から効率的に変換行列 , を求めます。これを作用させることで、より標準化された低ランク表現 , を得ることができます。

Algorithm 2. Orthogonal Procrustes
次は、Orthogonal Procrustes による空間アライメントです。
これは、当日の embedding を基準となる embedding (前日の安定化済み embedding) にできるだけ重ね合わせるための、直交変換を求める手法です。直交変換は空間を回転・反転させるだけなので、embedding の距離関係や内積構造を保ちやすいという特徴があります。これにより、two-tower モデルが持つスコア計算の性質を維持したまま、日々の embedding の空間を連続的に揃えることができます。

実装上の工夫
LINEバイトはデータ量が多いので、空間計算量を意識して実装する必要があります。今回は分散処理によるスケーラブルな計算が可能な Apache Spark でこのアルゴリズムを実装しました。
Low Rank SVD の効率化
元論文の Low Rank SVD では QR 分解を用いていましたが、必要なのは上三角行列 のみであるため、計算を効率化するため Cholesky 分解で実装しました。手順は以下の通りです。
- Gramian Matrix を算出
- を Cholesky 分解して、QR の を算出
上記の方法は QR と同値です。
-
- : orthogonal column vectors (直交する列ベクトル)
- : upper-triangular matrix (上三角行列)
-
- は列直交行列、つまり となり、消去できます。
これで Cholesky 分解 () で求めた と、QR 分解の が一致することが証明され、より効率的に計算できるようになりました。
Orthogonal Procrustes の分散処理
- を求める
- ここの行列積は巨大なので、Sparkによる分散並列処理で算出
- を SVD 分解
- は の非常に小さい行列なので、直接 NumPy で計算しても大丈夫です。 十分 1 ノードのメモリに収まります。
評価と考察
安定化の効果
安定化前は、任意の2日間で生成された embedding 間の相関は非常に弱く、ほぼ 0 に近い状態でした。
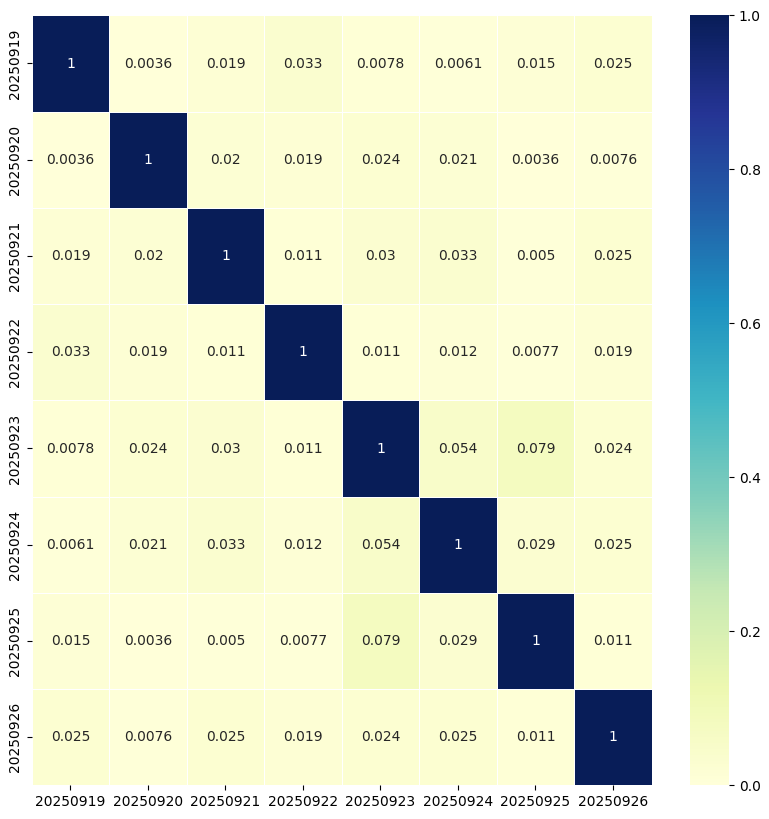
これに対し、安定化を導入すると、ユーザー側・アイテム側ともに 1週間後でも類似度 0.88 程度を維持できることを確認しました。
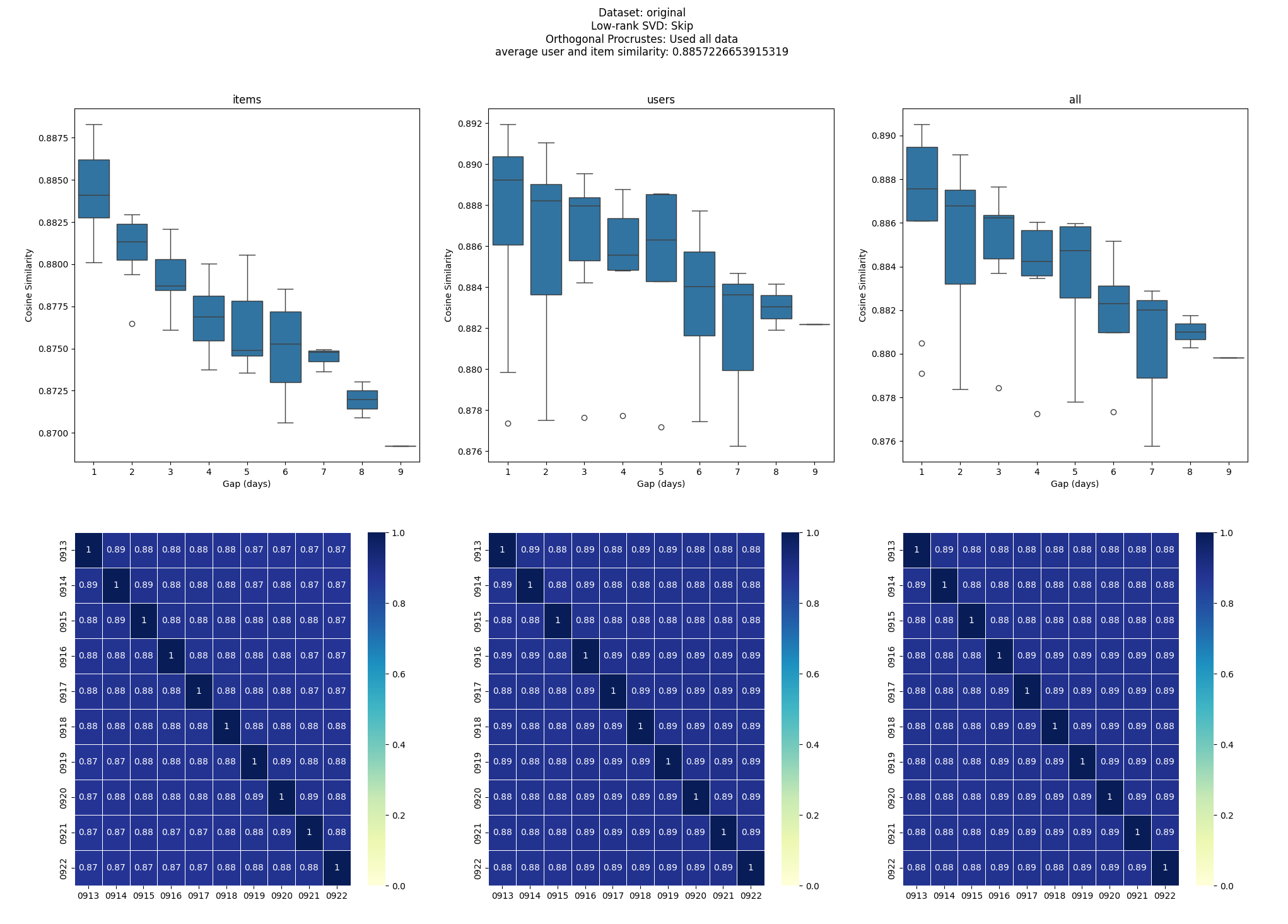
さらに長期間の検証では、1か月後でもベクトル類似度は 0.87 前後を維持していました。
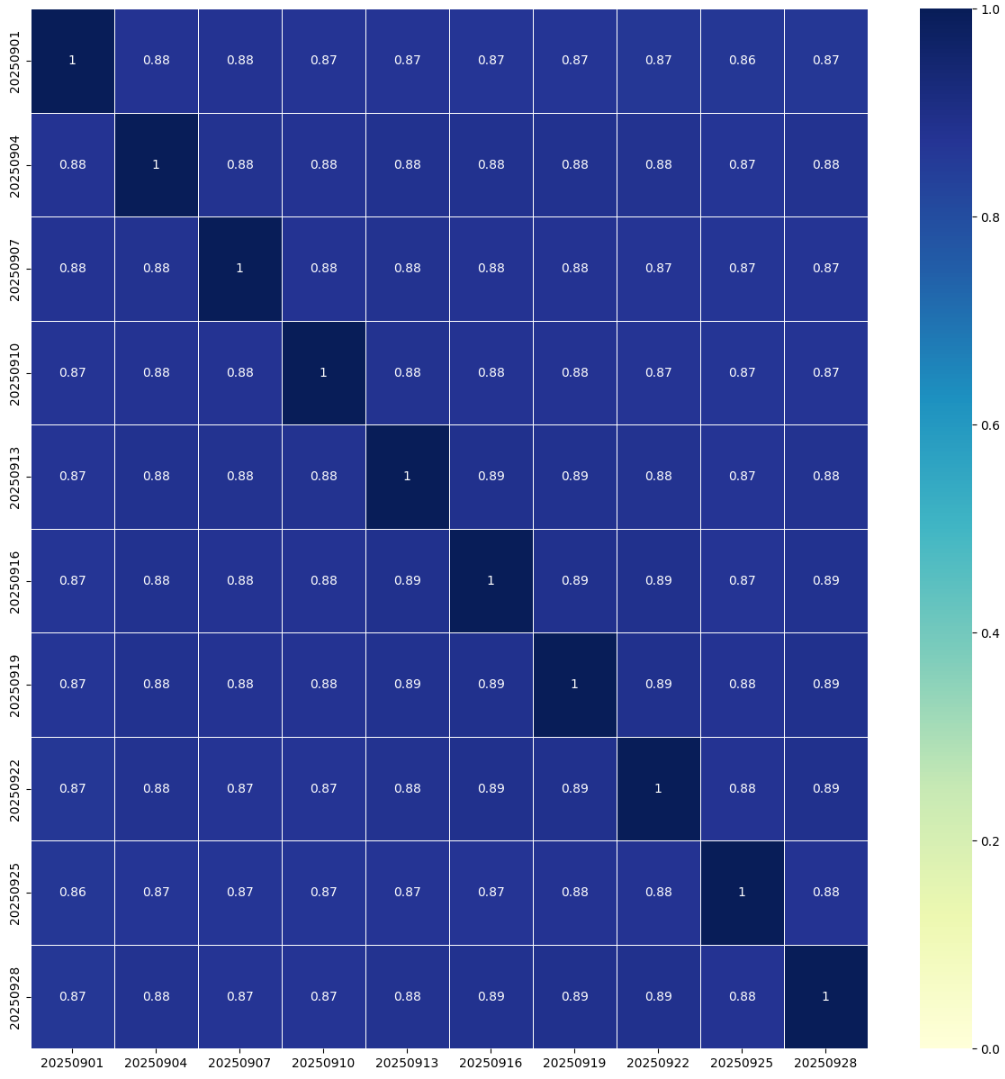
これらの結果から、推論時に利用するデータが学習時のデータと完全一致しない場合でも、embedding 空間のドリフトによるモデル性能の大きな劣化を抑制できることが示唆されます。
オフライン評価
安定化前後の embedding を特�徴量として学習したモデルを使い、click や conversion などの各種ユーザー行動を ground truth としてオフライン評価しました。Neural Network ベースの baseline モデルに、学習時と推論時で異なる日付に学習した two-tower embedding を直接特徴量として追加しています。
安定化前の embedding をモデルに追加すると、空間の不整合により nDCG は 1%〜5% 程度劣化しました。しかし、安定化した embedding を使うと、conversion nDCG は +9.0% 程度、click nDCG は +4.5% 程度それぞれ向上しました。
表. Embedding 安定化のオフライン評価結果
| モデル | click nDCG | conversion nDCG |
|---|---|---|
| baseline | 0.4898 | 0.4601 |
| 安定化前 | 0.4777 | 0.4540 |
| 安定化前 + 次元削減 | 0.4799 | 0.4533 |
| 安定化後 | 0.5120 | 0.5017 |
A/B テストによるオンライン評価
この安定化を行った embedding 特徴量、および、さらなる cold start problem 対策を組み合わせたモデルを A/B テストで評価しました。結果として、検索画面単体での KPI には有意な改善が見られなかったものの、サービス全体では KPI +4.7%、売上が +6.5% と、これまでの A/B テストの中でも大幅な向上を達成しました。
考察
A/B テストの結果、および two-tower embedding がサービス全体のユーザー行動を基に学習されていることを踏まえると、検索リランキングモデル�が embedding 特徴量に含まれる「長期的なユーザーの嗜好」をうまく捉え、検索画面を起点としたその後のユーザー行動 (回遊や他モジュールでの応募など) へ好影響を与えたと考えられます。
また当初リランキングモデルを適用した際に直面した cold start problem も、embedding 特徴量を加えた A/B テスト群では克服できていることがわかりました。
さらに本手法の大きなメリットは、two-tower モデル自体には変更を加えず、モデルが出力した embedding に対して後処理として空間アライメントを行う点にあります。つまり、既存の学習パイプラインやモデル構造を大きく変更する必要がなく、導入が容易です。この既存システムへの影響の低さは、実際の機械学習システムを運用する上で非常に重要なポイントです。
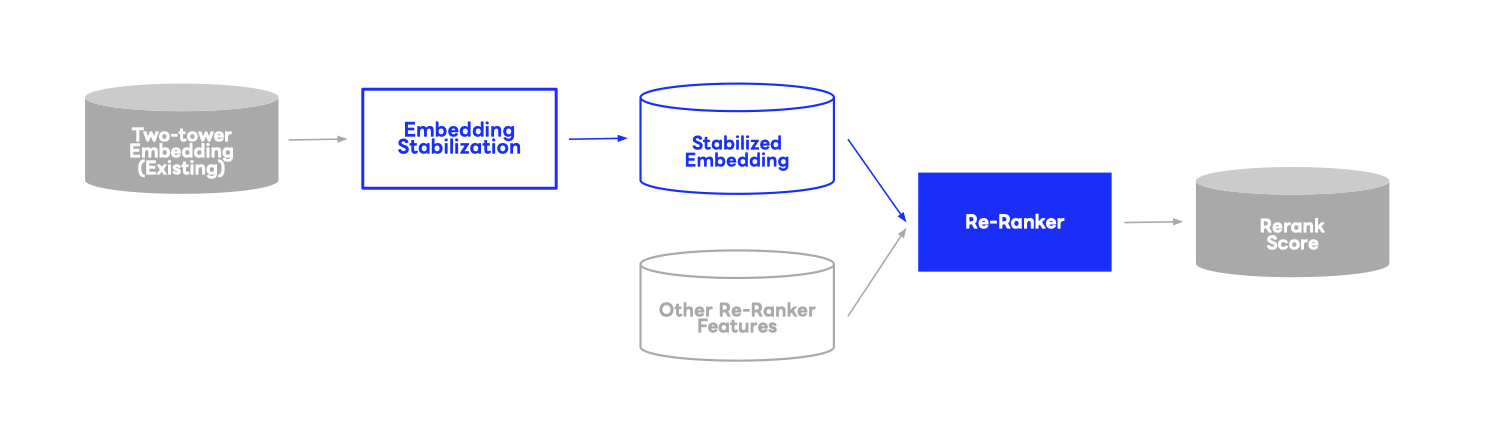
今後の展望
LINEバイトでは既存の求人掲載元に加え、新たな求人掲載元を増やす施策を進めており、求人情報の幅が拡大しています。このような動的な状況下でも、本手法が変わらず有用であることを引き続き検証していきたいです。
また、LINEヤフーの持つ多様なサービスで得たこのような知見を他のサービスでも活用できるように、全社的に使える機械学習基盤プラットフォームをさらに拡充し、ユーザー体験の向上に貢献していきたいです。この施策でも用いたリアルタイムなリランキングモデルはオンライン機械学習基盤の内製プロダクトを活用して構築しており、今後もこの基盤をさらに強化していく予定です。
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の挑戦や積み重ねてきた知識を共有します。
YouTube LIVEでの配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


