This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
Hello. I'm Nakano from LY Corporation. I am responsible for optimizing large language models (LLMs) for Yahoo! JAPAN Search's AI answer service.
In this article, I present a method that automates prompt tuning using a genetic algorithm, reducing adjustment work that used to take days to weeks to about one hour, and share examples of its application.
Challenges of prompt tuning
When developing features that incorporate LLMs, prompt tuning is an unavoidable process. However, this work has the following challenges.
- The burden of repeated trial-and-error: Every time the prompt is tweaked slightly, outputs must be checked and a human must judge whether they match the intent. It is not uncommon to try dozens to hundreds of patterns for a single measure.
- Knowledge siloing: Tacit knowledge such as "including this phrasing stabilizes output" or "this order of instructions works" becomes confined to individual contributors, making it difficult to record the trial-and-error process or explain why improvements occurred.
- Slow improvement cycles: The adjust → output → evaluate cycle must be repeated many times, and it can take days to weeks from starting to completing a measure.
- Cost of keeping up with model changes and updates: Output quality can change with model or version updates, and rapidly evolving generative AI models require continuous re-tuning.
As a result, resources cannot be allocated to quality judgments, organizing evaluation perspectives, or verifying alignment with policies—tasks that humans should focus on.
To solve these issues, we attempted to introduce a mechanism to automate the prompt tuning itself.
Automated prompt optimization
Optimization methods
Automated prompt optimization has been an active research topic since the rise of large language models, and several approaches exist. Below are some examples.
- Reinforcement learning–based: Methods that compute policy gradients from scalar rewards on outputs and learn prompt generation policies (for example, GRPO).
- Bayesian optimization–based: Methods that efficiently sample candidate instructions and few-shot examples as a search space (for example, MIPROv2).
- Genetic algorithm–based: Methods that improve candidate prompts through population-based generational updates (for example, GEPA).
Among these, genetic algorithm–based methods have gained attention because prompts are natural language with discrete structure, which suits evolutionary approaches. They can use natural-language reflection to explore improvements and represent a different approach from reinforcement learning that relies solely on scalar rewards. This article introduces GEPA, a representative method in this category.
GEPA's optimization loop
The basic idea is based on genetic algorithms and evolutionary computation: generate multiple candidate prompts, keep the ones with high evaluation scores, and iteratively refine them. GEPA reviews each candidate's execution results in natural language (reflective prompt mutation), identifies issues, and generates improvement proposals. Additionally, selection based on the Pareto front maintains candidates that perform well across multiple evaluation axes. Running this loop for several to dozens of generations can converge to prompts that produce outputs aligned with evaluation criteria without human intervention, and has been reported to outperform existing optimization methods in accuracy (see ICLR 2026).
Below is an overview of GEPA's pipeline. For details of the method, please refer to the papers and other articles.
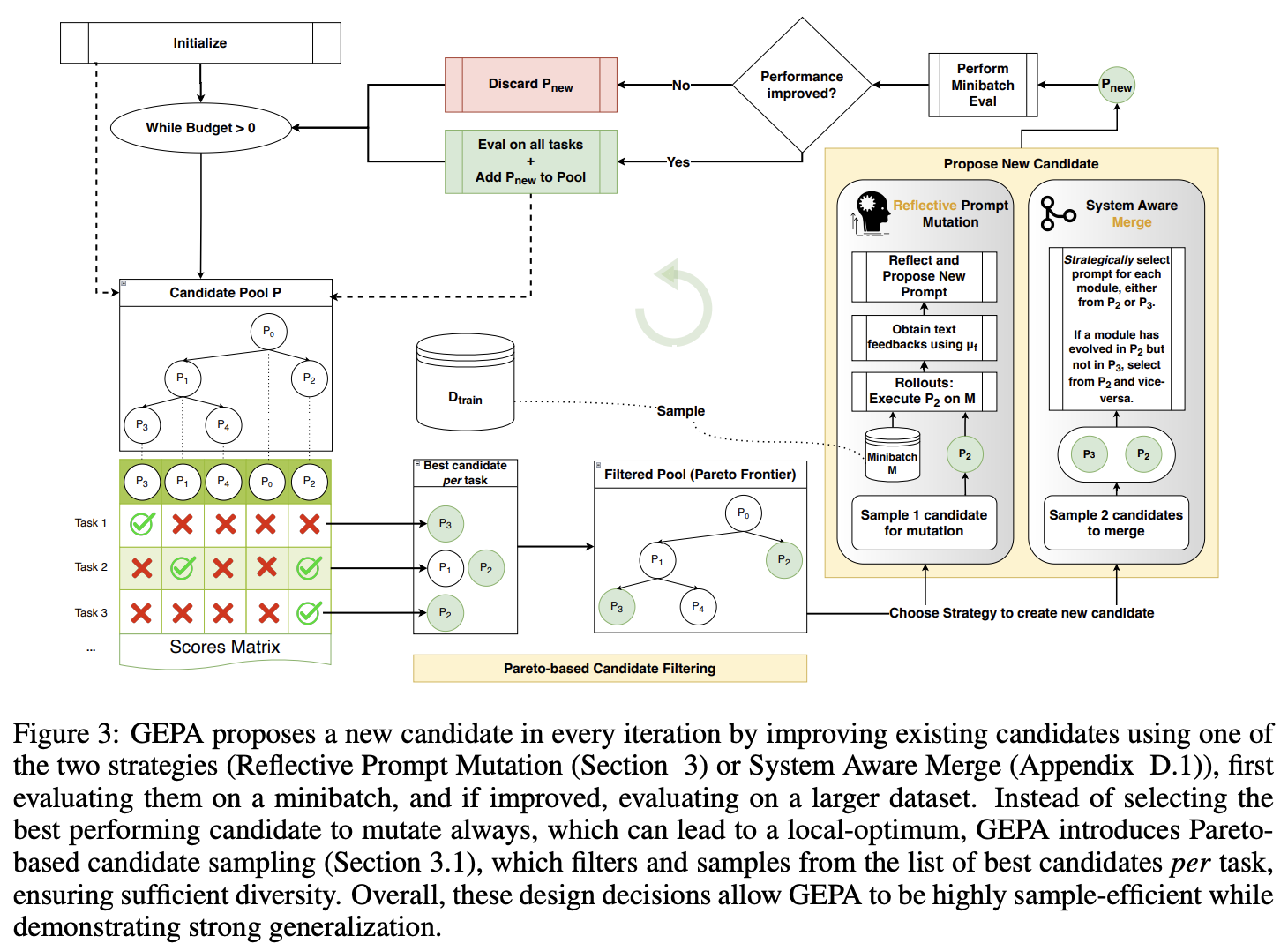
Implementation with DSPy and GEPA
GEPA is available from DSPy. DSPy is a framework that lets you control prompt optimization in code, and GEPA is officially supported as one of the optimizers that runs on top of it.
Below is an outline of the module definition.
import dspy
class TaskSignature(dspy.Signature):
"""You are a capable assistant. Please answer the user's questions politely."""
input = dspy.InputField(desc="Input text")
output = dspy.OutputField(desc="Generated text")
class MyModule(dspy.Module):
def __init__(self):
super().__init__()
self.predict = dspy.Predict(TaskSignature)
def forward(self, input: str) -> dspy.Prediction:
return self.predict(input=input)The Signature's docstring is passed to the LLM as an instruction, and GEPA rewrites and optimizes it.
Designing the evaluation function
The evaluation function passed to GEPA must return a single scalar value (float). If there are multiple evaluation aspects, aggregate the scores for each aspect into a single value.
One reason GEPA performs well is that, in addition to the scalar score, it can pass natural-language feedback to reflection. By returning dspy.Prediction(score=..., feedback=...) from the evaluation function, you can convey to GEPA's Reflective Prompt Mutation which aspects had issues and why points were deducted. Where a score alone would only indicate "it was 0.6", feedback can provide concrete information such as "aspect B had problems and was penalized", which is expected to help identify precise directions for improvement.
Note that the first argument of the evaluation function, gold, receives each sample from the training data. If you can prepare ground-truth data (expected outputs or labels) for the task, you can use gold to evaluate by comparing predictions against the correct answers. In the sample code below, automatic evaluation using LLM-as-a-Judge is defined without using gold, but rule-based correctness checks can of course also be used for scoring.
def create_metric(eval_lm: dspy.LM):
"""Evaluation metric across multiple aspects"""
class QualityEval(dspy.Signature):
output = dspy.InputField(desc="Generated text to evaluate")
criteria = dspy.InputField(desc="Evaluation criteria")
criterion_a = dspy.OutputField(desc="Score for aspect A", format=int)
criterion_b = dspy.OutputField(desc="Score for aspect B", format=int)
criterion_c = dspy.OutputField(desc="Score for aspect C", format=int)
explanation = dspy.OutputField(desc="Evaluation reasoning")
evaluator = dspy.ChainOfThought(QualityEval)
def metric_fn(gold, pred, trace=None, pred_name=None, pred_trace=None):
criteria = "..." # Describe detailed evaluation criteria for each aspect
with dspy.context(lm=eval_lm):
out = evaluator(output=pred.output, criteria=criteria)
# Score each aspect on a 0-10 scale and normalize the total into a single scalar value
scores = [
max(0, min(10, int(out.criterion_a))),
max(0, min(10, int(out.criterion_b))),
max(0, min(10, int(out.criterion_c))),
]
score = sum(scores) / (10 * len(scores))
# Pass the evaluation reasoning as feedback to GEPA's reflection
return dspy.Prediction(score=score, feedback=out.explanation)
return metric_fnRun optimization as follows. You can set separate models for inference, evaluation, and reflection.
# Inference model (used by the module being optimized)
task_lm = dspy.LM("openai/gpt-4o-mini")
# Evaluation model (used by LLM-as-a-Judge)
eval_lm = dspy.LM("openai/gpt-4o")
# Reflection model (used by GEPA when generating improvement proposals)
reflection_lm = dspy.LM("openai/gpt-4o")
dspy.configure(lm=task_lm)
metric = create_metric(eval_lm=eval_lm)
optimizer = dspy.GEPA(
)
optimized_module = optimizer.compile(
MyModule(),
trainset=training_examples,
)Tasks we worked on
Health and medical queries in Yahoo! JAPAN Search AI answers
In Yahoo! JAPAN Search's AI answer service, an LLM generates answers directly for users' search queries. We work to improve output quality across a wide range of query categories, and health and medical queries in particular have many policies that must be followed compared to general queries. Requirements for answers include things like "do not make definitive medical judgments", "use expressions appropriate to the level of evidence", and "include appropriate advice to consult a medical professional".
Two improvement goals
For this task, it was necessary to achieve the following two goals simultaneously.
- Policy compliance: Generate answers that satisfy the many policies specific to health and medical queries.
- Improved readability: Apply Markdown formatting (headings, lists, emphasis, etc.)—previously introduced for general queries—to health and medical queries as well, to make answers easier for users to read.
Both policy compliance and readability improvements must be controlled by prompt instructions. However, because there are many policies, prompt tuning becomes more complex, and improving one aspect can easily degrade the other. Because simultaneous manual optimization would be labor intensive, we decided to apply automated optimization.
Applying prompt optimization to this task
We applied the general mechanism introduced in the previous section to this task as follows.
Experimental setup
The Signature is a simple structure with the user's search query as input and the AI answer as output. The initial prompt was constructed by appending health and medical–specific policy language to an already tuned general prompt; GEPA rewrites this instruction part during optimization.
Below is an example structure of the initial prompt (excerpted and modified).
Please generate an answer in Markdown format that strictly follows the requirements below for the search query
## Answer quality requirements
- Specificity: Present a specific, practical answer to the query first
- Intent interpretation: Correctly capture the intent of the query and include necessary information without omission or excess
(...omitted: answer structure, format, checklist, answer examples...)
## Mandatory conditions
Always provide accurate and honest information and do not provide fictitious or unverified information.
(...omitted...)
### Health and medical annotation guideline compliance rules (MUST)
#### 1) Scope of answers
- Only general explanations (definition, symptoms, causes, course, prevention, complications).
#### 2) Common rules (prohibitions and constraints)
- [Diagnostic acts] Prohibit asserting diagnoses/severity.
- [Definitive expressions] Prohibit absolute statements such as effective/necessary/optimal.
(...the list continues with regexes for prohibited word stems...)In this way, the health and medical guideline is appended to the end of the general answer rules.
GEPA was configured as follows.
optimizer = dspy.GEPA(
metric=metric_fn,
auto="light",
num_threads=8,
track_stats=True,
reflection_minibatch_size=3,
reflection_lm=eval_lm,
)auto="light" controls the optimization budget; you can choose from "light", "medium", or "heavy". We selected "light" to get cost-effective results quickly. reflection_minibatch_size=3 processes reflections in mini-batches of three samples to generate improvement proposals efficiently.
Evaluation function
We defined policies that health and medical queries must satisfy across four aspects (diagnostic acts, definitive expressions, recommendation of specific brand names, psychological burden). We built an LLM-as-a-Judge that scores each defined policy on a 0–10 scale and aggregated the four aspect scores by averaging to a single scalar value. We also prepared a similar evaluation mechanism for readability improvements.
Below is an example of evaluation results for a given query (scores and feedback are illustrative, not actual).
| Aspect | Score | Example feedback |
|---|---|---|
| Diagnostic acts | 8/10 | There is no definitive diagnosis, but one expression like "...is likely" remains in one place. |
| Definitive expressions | 6/10 | Prohibited words such as "effective" or "necessary" are used in three places. |
| Recommendation of specific names | 10/10 | No recommendation of specific product or drug names. |
| Psychological burden | 9/10 | Overall wording is reasonable, but phrasing like "leaving it untreated is dangerous" is somewhat alarming. |
In this example, the total score is (8+6+10+9) / 40 = 0.825, and feedback describing issues for each aspect is passed to GEPA's reflection. GEPA can then generate improvement proposals that focus on eliminating definitive expressions.
Operational design
When applying automated optimization to a production product, it is important to design the boundary of how much is automated and what remains for human final judgment. For this task, we adopted a policy of automating reproducible judgments and leaving context-dependent judgments to humans, and we assigned roles as follows. This division frees people from routine work (repeated prompt tweaking and checks) so they can focus on quality judgments and policy design.
Scope of automation
- Generation and refinement of candidate prompts (evolutionary search using GEPA)
- Execution of each candidate and retrieval of outputs
- Calculation of policy-compliance scores by LLM-as-a-Judge
- Selection and elimination of candidates based on scores
Human responsibilities
- Define evaluation aspects (policies) and set priorities
- Qualitative evaluation of optimization results
- Detect evaluation omissions and provide feedback to evaluation prompts
- Make final release decisions for production
Optimization process
First, we optimized using a readability policy (Markdown formatting) evaluation function to obtain prompts that can generate structured answers. Then we ran optimization again with the health and medical policy evaluation function to produce prompts that meet requirements while maintaining readability.
Specifically, we followed these steps.
- Optimize using the readability policy
- Human check: Humans review optimization results and identify issues the automatic evaluation missed
- Update evaluations: Reflect discovered evaluation omissions in the evaluation prompts
- Optimize using the health and medical policy
- Human check again: Humans review and find any remaining evaluation omissions
- Update evaluations: Improve the evaluation prompts again
By iterating this "automated optimization → human check → evaluation update" cycle, the accuracy of automatic evaluation itself is expected to improve step by step.
Results
Applying this method produced the following outcomes.
- Optimization time: Tasks that previously took days to weeks with manual tuning were completed in about one hour.
- Policy compliance rate: Qualitative human evaluation achieved nearly 100 % policy compliance, meeting release standards.
- Labor reduction: Time spent on prompt trial-and-error was reduced, increasing opportunities to spend time on design of evaluations and policies—higher-level judgment work.
Below is a comparison of outputs before and after optimization for the query "meningitis headache features". The left is before optimization and the right is after. Before optimization, information was listed with bullet points and bolding only, but after optimization the answer is organized and structured with headings such as "Main features of meningitis headache", "Other symptoms", "Causes and types", and "Diagnosis and treatment", making it more readable.
(Note: The screen is from development and the text differs from what is actually displayed in search results.)

Prompts themselves were also significantly restructured. Below is part of the optimized prompt structure (excerpted and modified).
## 1. Intended task and assumptions
- The target audience is general users without medical or nutritional expertise.
- The answer should be compact and practical, similar to a "search result summary."
## 2. Overall structure and length
### 2-1. Three-layer structure (required)
1. Direct answer at the top (one paragraph)
2. Detailed explanation
3. Supplementary notes and cautions
## 4. Content guidelines
### 4-3. Queries about disease names and symptoms
- Basic structure:
1. Overview
2. Main symptoms
3. Causes and factors
4. Options for tests and treatments
5. Prevention and lifestyle precautions
## 5. Health and medical guidelines (required)
### 5-2. Prohibitions and restricted expressions
1. Prohibition of diagnostic acts
2. Prohibition of definitive expressions
- "Effective" -> "May be expected to be effective"
- "...is the cause" -> "...may be involved"
(...below, paraphrase templates, disclaimer wording, final checklist...)Before optimization, the health and medical guideline was simply appended to the end of the general rules, but GEPA reorganized it into a seven-chapter structure and systematically integrated query-type guidelines and paraphrase templates.
Below is the progression of automatic evaluation scores for the health and medical policy. Scores improve across generations, and the number of candidates reaching a perfect score increases.
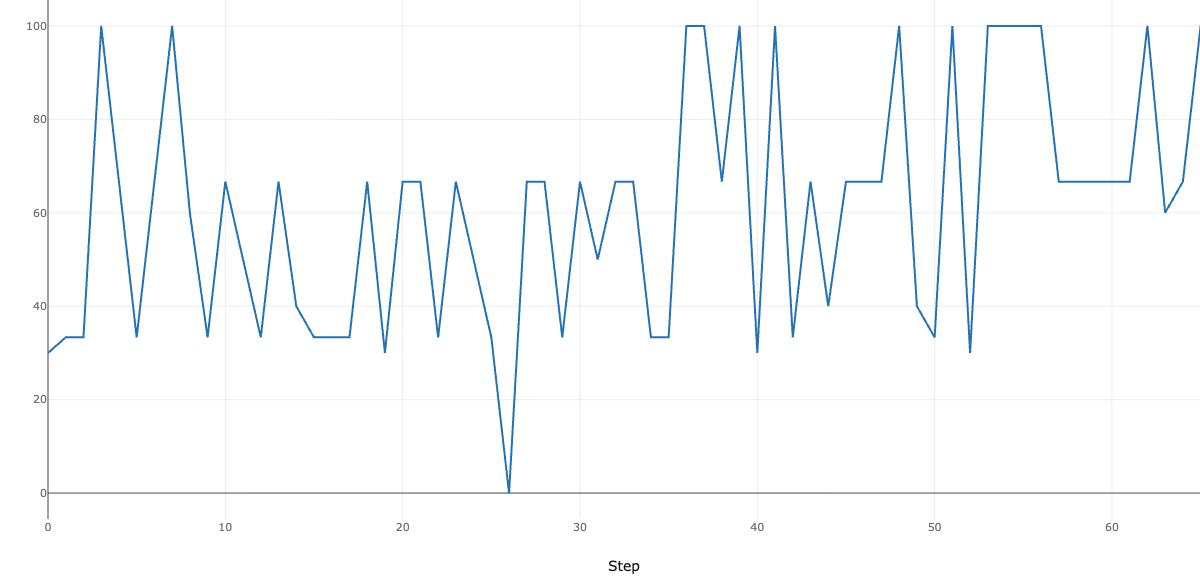
On the other hand, automatic evaluation by LLM-as-a-Judge is known to have issues with consistency. Gu et al.'s survey paper (A Survey on LLM-as-a-Judge) reports that LLM evaluators can produce inconsistent scores for the same input, and that subtle changes in context can alter judgments for the same input. Moreover, even models with advanced reasoning capabilities do not fully match human evaluations, so there is room for improvement in LLM evaluators. Approaches to reduce such inconsistencies include running the same evaluation multiple times and taking majority votes, or iteratively reflecting human feedback into evaluation prompts as in the optimization process introduced here.
We observed this characteristic in this task as well. The expression in the pre-optimized output "headache due to meningitis almost always occurs simultaneously with other symptoms such as fever, vomiting, seizures, and impaired consciousness" was judged by an LLM-as-a-Judge as "a diagnostic act", yet a similar phrasing in the post-optimized output was not judged as such. In practice, general descriptions of symptoms do not constitute diagnostic acts under the policy, so human checks judged both outputs acceptable for release.
Limitations of the current approach
GEPA is a powerful method for reducing manual tuning work, but we observed several limitations during practical experiments.
Evaluation functions that return a single scalar value
For improvements to health and medical queries implemented here, taking the average of scores across multiple evaluation axes can obscure the results for individual axes. It is possible to apply heuristic weighting to increase the expressiveness of the scores, but doing so may introduce a new hyperparameter-tuning problem for the weights, even though prompt tuning itself has been automated.
Time required for human evaluation
Although the tuning itself was sped up to about one hour, the need for human checks before and after automatic optimization can become a bottleneck. However, reflecting human feedback in the evaluation prompts can directly contribute to improvements in subsequent optimizations.
Prompt bloat
Optimized prompts generated by GEPA tend to include many individual examples derived from evaluation results, similar to few-shot demonstrations. In this task, optimization increased the prompt length by about 55%, from 5,521 characters to 8,561 characters. This increase requires consideration of inference cost and latency impacts.
For example, the optimized prompt added the following query-type-specific structure examples (excerpted and modified).
### 4-3. Disease and symptom queries
- Basic structure:
1. Overview
2. Main symptoms
- Example: "Ischemic colitis"
- Sudden abdominal pain (especially in the lower left abdomen)
- Diarrhea following abdominal pain
- Fresh blood in stools
- Example: "Mycoplasma pneumoniae — adult symptoms"
- A prolonged dry cough
- Fever of 38 °C or higher, or remittent fever
- Fatigue (tiredness), headache
3. Causes and factors
4. Options for tests and treatments
5. Prevention and lifestyle precautionsThe insertion of such individual examples is the primary cause of prompt bloat.
Not leveraging differential information
The current method evaluates candidate prompts from each generation separately and does not explicitly leverage the differences from the previous generation (the correspondence between prompt changes and output changes). A study presented at the 32nd Annual Meeting of the Association for Natural Language Processing (NLP2026) proposed a method that analyzes the differences between the immediately preceding and current prompts and inference results to identify and correct areas for improvement in natural language, reporting accuracy that exceeds GEPA (Koga et al., 2026).
Outlook: Foundation building and autonomous product improvement
Establishing the improvement loop as a platform
Currently, we run the cycle of "evaluation design → optimization execution → human verification → reflection" separately for each initiative. Going forward, we aim to develop this improvement loop itself as a shared platform and horizontally expand it beyond health and medical domains to LLM features across search, advertising, commerce, and internal operations where policy compliance is required.
Towards AI-driven autonomous product improvement
Looking further ahead, we aim to build a system that continuously improves autonomously without human intervention.
- Detect quality degradation from production monitoring and automatically trigger optimization
- Automatically run end-to-end—from generating evaluation prompts to executing optimization—when new policies are added
- Have humans only handle verification and approval flows, while AI autonomously executes improvements
Rather than one-off improvements, we believe the goal as a service is to build a platform that keeps the product's quality maintained and improved autonomously.
Conclusion
This article introduced prompt automatic optimization using DSPy and GEPA, and presented an application case for health and medical queries in Yahoo! JAPAN Search AI answers.
By automating prompt tuning, not only can adjustment work be drastically reduced, but people can also spend time on evaluation design and policy development—areas that require human attention. We hope this is helpful for those who face challenges in prompt tuning or want to streamline quality improvement for features and services that incorporate LLMs. Please try designing evaluation functions tailored to your tasks and test automated optimization!
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


