LINEヤフーの技術カンファレンス「Tech-Verse 2026」の公式記事です。
こんにちは。LINEヤフー株式会社の中野です。Yahoo!検索のAI回答サービスで大規模言語モデル(LLM)の最適化を担当しています。
本記事では、遺伝的アルゴリズムを用いてプロンプトチューニングを自動化し、数日〜数週間かかっていた調整作業を約1時間に短縮した手法と、その適用事例を紹介します。
プロンプトチューニングの課題
LLMを組み込んだ機能を開発する際、プロンプトのチューニングは避けて通れない工程です。しかし、この作業には以下のような課題があります。
- 試行錯誤の繰り返しの重さ:プロンプトを少し変えるたびに出力を確認し、意図通りかどうかを人が判断する必要がある。1回の施策で数十〜数百パターンを試すことも珍しくない
- ノウハウの属人化:この表現を入れると出力が安定する、この順序で指示すると効く、…、といった暗黙知が担当者個人に閉じてしまい、試行錯誤の工程が記録されづらかったり、なぜ改善したのか説明が難しくなる
- 改善サイクルの遅さ��:調整→出力→評価のサイクルを何度も行う必要があり、施策の着手から完了まで数日〜数週間かかることもある
- モデル変更・更新への追従コスト:モデル変更やバージョン更新によって出力品質が変化することがあり、更新サイクルの速い生成AIモデルでは継続的な再調整が必要になる
結果として、本来人が注力すべき品質判断や評価観点の整理、ポリシーとの整合性検証にリソースを割けなくなります。
この課題を解決するために、プロンプトチューニング自体を自動化する仕組みの導入に挑戦しました。
プロンプト自動最適化
最適化の手法
プロンプトの自動最適化は、大規模言語モデルの台頭以降、活発に研究されているテーマの一つであり、いくつかのアプローチが存在します。以下はその一例です。
- 強化学習ベース:出力に対するスカラー報酬からポリシー勾配を計算し、プロンプト生成方策を学習する手法(GRPOなど)
- ベイズ最適化ベース:候補命令やfew-shot例を探索空間として効率的にサンプリングする手法(MIPROv2など)
- 遺伝的アルゴリズムベース:候補プロンプトを集団として世代交代しながら改善する手法(GEPAなど)
中でも遺伝的アルゴリズムベースの手法は、プロンプトが自然言語であり離散的な構造を持つ点と相性が良く、注目を集めています。自然言語のリフレクションを活用して探索的に改善を進められ、ス��カラー報酬のみに頼る強化学習とは異なるアプローチの手法です。本記事ではその代表的な手法であるGEPAを紹介します。
GEPAの最適化ループ
基本的な考え方は「候補プロンプトを複数生成し、評価スコアの高いものを残して改良を繰り返す」という遺伝的アルゴリズムや進化的計算手法の考え方をベースとしたものです。GEPAは各候補の実行結果を自然言語で振り返り(Reflective Prompt Mutation)、問題を特定して改善案を生成します。さらにパレートフロンティアに基づく選択により、複数の評価軸でバランスよく優れた候補を維持します。このループを数世代〜数十世代回すことで、人手の介入なしで評価基準に沿った出力を行うプロンプトに収束し、既存の最適化手法の精度を上回ることが報告されています(ICLR 2026)。
以下はGEPAのパイプラインの全体像です。手法の詳細については、ぜひ論文や他の紹介記事を参照してみてください!
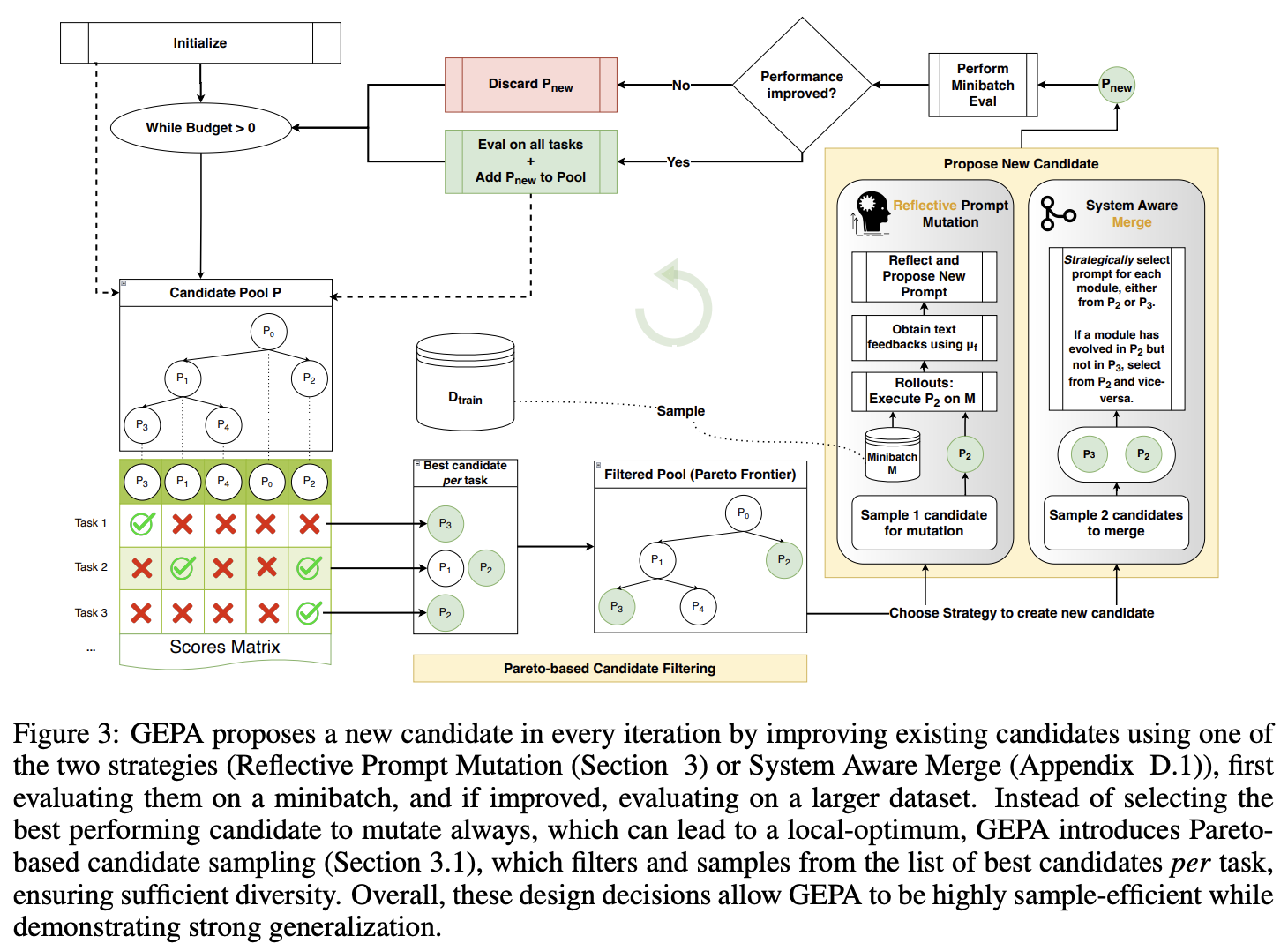
図引用:Agrawal, L. A. et al. "GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning." ICLR 2026 Oral. (ICLR 2026, arXiv:2507.19457)
DSPyとGEPAによる実装
GEPAはDSPyから利用できます。DSPyはプロンプトの最適化をコードで制御できるフレームワークで、GEPAはその上で動作するオプティマイザの一つとして公式にサポートされています。
以下にモジュール定義の概要を示します。
import dspy
class TaskSignature(dspy.Signature):
"""あなたは優秀なアシスタントです。ユーザーの質問に丁寧に回答してください。"""
input = dspy.InputField(desc="入力テキスト")
output = dspy.OutputField(desc="生成テキスト")
class MyModule(dspy.Module):
def __init__(self):
super().__init__()
self.predict = dspy.Predict(TaskSignature)
def forward(self, input: str) -> dspy.Prediction:
return self.predict(input=input)Signatureのdocstring部分がLLMへinstructionとして渡され、GEPAはこれを書き換えて最適化します。
評価関数の設計
GEPAに渡す評価関数は、単一のスカラー値(float)を返す必要があります。複数の評価観点がある場合は、各観点のスコアを集約して1つの値にまとめます。
GEPAが高い性能を発揮する理由の一つは、スカラースコアとは別に自然言語のfeedbackをリフレクションに渡せる点にあります。評価関数から dspy.Prediction(score=..., feedback=...) を返すことで、「どの観点で問題があるか」「なぜ減点されたか」などをGEPAのReflective Prompt Mutationに伝えられます。スコアだけでは「0.6だった」としか分からないところを、feedbackがあれば「観点Bに問題があり減点された」と具体的に伝わるため、的確な改善方向を見出せることが期待できます。
なお、評価関数の第1引数 gold には学習データの各サンプルが渡されます。正解データ(期待出力やラベル)を用意できるタスクであれば、gold �を参照して正解との比較に基づく評価も可能です。以下のサンプルコードでは、gold を使用しない形でLLM-as-a-Judgeによる自動評価を定義していますが、もちろんルールベースによる正誤判定などでスコアリングも可能です。
def create_metric(eval_lm: dspy.LM):
"""複数観点による評価メトリック"""
class QualityEval(dspy.Signature):
output = dspy.InputField(desc="評価対象の生成テキスト")
criteria = dspy.InputField(desc="評価基準")
criterion_a = dspy.OutputField(desc="観点Aのスコア", format=int)
criterion_b = dspy.OutputField(desc="観点Bのスコア", format=int)
criterion_c = dspy.OutputField(desc="観点Cのスコア", format=int)
explanation = dspy.OutputField(desc="評価理由")
evaluator = dspy.ChainOfThought(QualityEval)
def metric_fn(gold, pred, trace=None, pred_name=None, pred_trace=None):
criteria = "..." # 各観点の詳細な評価基準を記述
with dspy.context(lm=eval_lm):
out = evaluator(output=pred.output, criteria=criteria)
# 各観点を0-10で採点し、合計を正規化して単一スカラー値に集約
scores = [
max(0, min(10, int(out.criterion_a))),
max(0, min(10, int(out.criterion_b))),
max(0, min(10, int(out.criterion_c))),
]
score = sum(scores) / (10 * len(scores))
# 評価理由をfeedbackとしてGEPAのリフレクションに渡す
return dspy.Prediction(score=score, feedback=out.explanation)
return metric_fn最適化の実行は以下のように行います。推論、評価、リフレクション用モデルをそれぞれ別に設定することができます。
# 推論用モデル(最適化対象のモジュールが使用するLLM)
task_lm = dspy.LM("openai/gpt-4o-mini")
# 評価用モデル(LLM-as-a-Judgeが使用するLLM)
eval_lm = dspy.LM("openai/gpt-4o")
# リフレクション用モデル(GEPAが改善案を生成する際に使用するLLM)
reflection_lm = dspy.LM("openai/gpt-4o")
dspy.configure(lm=task_lm)
metric = create_metric(eval_lm=eval_lm)
optimizer = dspy.GEPA(
metric=metric,
reflection_lm=reflection_lm,
num_candidates=10,
num_generations=15,
)
optimized_module = optimizer.compile(
MyModule(),
trainset=training_examples,
)取り組んだタスク
Yahoo!検索 AI回答における健康医療系クエリ
Yahoo!検索のAI回答サービスでは、ユーザーの検索クエリに対してLLMが直接回答を生成します。幅広いカテゴリのクエリに対して高品質な回答が出力されるよう改善に努めていますが、その中でも、健康医療系クエリは、汎用的なクエリと比較して遵守すべきポリシーが多いという特徴があります。例えば「断定的な医療判断をしない」「エビデンスレベルに応じた表現を使う」「受診勧奨を適切に含める」など、回答に求められる要件が多岐にわたります。
2つの改善目標
このタスクでは、以下の2つを同時に達成する必要がありました。
- 要件準拠:健康医療系クエリ固有の多数のポリシーを満たす回答を生成する
- 読みやすさの改善:汎用ク��エリで先行導入されていたMarkdownによる整形表示(見出し、箇条書き、強調など)を健康医療系クエリにも適用し、ユーザーにとって読みやすい回答にする
要件準拠と読みやすさの改善は、どちらもプロンプトの指示で制御する必要があります。しかし、ポリシーが多い分だけプロンプトの調整が複雑になり、一方を改善すると他方が崩れるといった問題が起きやすくなります。これを人手で同時に最適化するのは工数がかかるため、自動最適化の適用に踏み切りました。
本タスクへのプロンプト最適化適用
前章で紹介した汎用的な仕組みを、本タスクに以下のように当てはめました。
実験設定
Signatureはユーザーの検索クエリを入力、AI回答を出力とするシンプルな構成です。初期プロンプトにはすでに調整済みの汎用プロンプトに健康医療固有のポリシー文言を単純につなげた文章を設定しており、GEPAはこのinstruction部分を書き換えて最適化します。
以下は初期プロンプトの構成イメージです(一部抜粋・改変)。
検索クエリに対し以下の要件に厳密に従って回答をMarkdown形式で生成してください
## 回答品質要件
- 具体性: クエリに対する具体的で実用的な回答を先に示す
- 意図解釈: クエリの意図を正しく捉え、必要な情報を過不足なく含める
(...中略: 回答構造、フォーマット、チェックリスト、回答例...)
## 必ず守る条件
常に正確かつ誠実な情報を提供し、架空の情報や確証のない情報は提供しません。
(...中略...)
### 健康医療アノテーションガイドライン遵守ルール(MUST)
#### 1) 回答範囲
- 一般的説明のみ(定義・症状・原因・経過・予防・合併症)。
#### 2) 共通ルール(禁止・制約)
- 【診断行為】病名/重症度の断定を禁止。
- 【断定表現】効果/必要/最適 等の言い切りを禁止。
(...以下、NG語幹の正規表現リスト等が続く...)このように、汎用的な回答ルールの末尾に健康医療固有のガイドラインが追記された構造になっています。
GEPAの実行設定は以下のとおりです。
optimizer = dspy.GEPA(
metric=metric_fn,
auto="light",
num_threads=8,
track_stats=True,
reflection_minibatch_size=3,
reflection_lm=eval_lm,
)auto="light" は最適化の計算予算を制御するパラメータで、"light" / "medium" / "heavy" から選択できます。今回は "light" を指定し、短時間でコストパフォーマンス良く結果を得られる設定としました。reflection_minibatch_size=3 により、リフレクション時に3サンプルずつミニバッチで処理し、効率的に改善案を生成しています。
評価関数
健康医療系クエリが満たすべきポリシーを4つの観点(診断行為、断定表現、具体的固有名詞の推奨、心理的負担)に分けて定義しました。定義したポリシーを各0〜10点で評価するLLM-as-a-Judgeを構築し、4観点のスコアの平均を取ることで単一スカラー値に集約します。読みやすさの改善に関するポリシーに対しても同様の評価の仕組みを用意しました。
以下は、あるクエリに対する出力の評価結果のイメージです(スコアとfeedbackは実際の値とは異なります)。
| ��観点 | スコア | feedbackの例 |
|---|---|---|
| 診断行為 | 8/10 | 病名の断定はないが「〜の可能性が高い」という表現が1カ所残っている |
| 断定表現 | 6/10 | 「効果的です」「必要です」など禁止語が3カ所で使用されている |
| 固有名詞の推奨 | 10/10 | 具体的な商品名・薬剤名の推奨なし |
| 心理的負担 | 9/10 | 全体的に穏当な表現だが「放置すると危険」がやや不安をあおる |
この例では合計スコアが (8+6+10+9) / 40 = 0.825 となり、feedbackとして各観点の問題点がGEPAのリフレクションに渡されます。GEPAはこのfeedbackをもとに「断定表現の排除」に重点を置いた改善案を生成できます。
運用設計
自動最適化の仕組みを実プロダクトに適用するにあたり、どこまで自動化し、どこから人が最終判断するかの境界設計が重要です。本タスクでは、再現性のある判断は自動化し、文脈依存の判断は人に残すという方針に基づき、以下のような役割分担を意識しました。この分担により、人はルーティンワーク(プロンプトの微調整と確認の繰り返し)から解放され、本来注力すべき品質判断やポリシー設計に集中できるようになります。
自動化の範囲
- 候補プロンプトの生成・改良(GEPAによる進化的探索)
- 各候補の実行と出力取得
- LLM-as-a-Judgeによるポリシー準拠スコアの算出
- スコアに基づく候補の選択・淘汰
人が判断する範囲
- 評価観点(ポリシー)の定義と優先度付け
- 最適化結果の定性評価
- ��評価漏れの発見と評価プロンプトへのフィードバック
- 本番環境への最終的なリリース判断
最適化プロセス
まず読みやすさポリシー(Markdown整形)の評価関数で最適化を回し、構造化された回答を生成できるプロンプトを獲得します。その後、健康医療ポリシーの評価関数で再度最適化を実行し、読みやすさを維持しつつ要件準拠を達成するプロンプトに仕上げました。
具体的には、以下のステップを踏みました。
- 読みやすさポリシーで最適化を実行
- 人手チェック:最適化結果を人が確認し、自動評価が見落としている問題を洗い出す
- 評価の修正:発見された評価漏れを評価プロンプトに反映する
- 健康医療ポリシーで最適化を実行
- 再度人手チェック:同様に人が確認し、評価漏れを発見する
- 評価の修正:評価プロンプトを再度改善する
このように「自動最適化 → 人手チェック → 評価修正」のサイクルを回すことで、自動評価の精度自体も段階的に向上していくことが期待できます。
結果
本手法を適用した結果、以下の成果が得られました。
- 最適化時間:従来の人手チューニングで数日〜数週間かかっていた作業が、約1時間で完了
- 要件準拠率:人手定性評価でほぼ100%のポリシー準拠を達成し、リリース基準をクリア
- 工数削減:プロンプトの試行錯誤に費やしていた時間を削減し、評価設計やポリシー整備といった高度な判断業務に費やす機会が増加
以下は、クエリ「髄膜炎 頭痛 特徴」に対する最適化前後の回答出力の比較です。左が最適化前、右が最適化後です。最適化前は箇条書きとボールドのみで情報が羅列されていましたが、最適化後は「髄膜炎の頭痛の主な特徴」「その他の症状」「原因と種類」「診断と治療」といった見出しで情報が整理され、読みやすく構造化された回答になっています。
(注:画面は開発中のものであり、実際の検索結果に掲出される文章とは異なります。)

また、プロンプト自体も大きく再構造化されました。以下は最適化後プロンプトの構成の一部です(抜粋・改変)。
## 1. 想定タスク・前提
- 回答対象は医療・栄養の専門知識がない一般ユーザーです。
- 回答は「検索結果の要約」のようにコンパクトかつ実用的にまとめてください。
## 2. 回答の全体構造・分量
### 2-1. 三層構造(必須)
1. 冒頭の直接回答(1段落)
2. 詳細説明
3. 補足・注意事項
## 4. 内容面のガイドライン
### 4-3. 病名・症状系クエリ
- 基本構成:
1. 概要
2. 主な症状
3. 原因・要因
4. 検査・治療の選択肢
5. 予防・生活上の注意
## 5. 健康医療ガイドライン(必須)
### 5-2. 禁止事項・制約表現
1. 診断行為の禁止
2. 断定表現の禁止
- 「有効」→「効果が期待される」
- 「〜が原因です」→「〜が関与する場合があります」
(...以下、言い換えテンプレート、免責文言、最終チェックリスト...)最適化前は汎用ルールの末尾に��健康医療ガイドラインを追記しただけの構造でしたが、GEPAによって7章構成に再編され、クエリタイプ別のガイドラインや言い換えテンプレートが体系的に統合されています。
以下は、健康医療ポリシーに関する自動評価スコアの推移です。世代を経るにつれてスコアが向上し、100点に到達する候補が増えていきます。
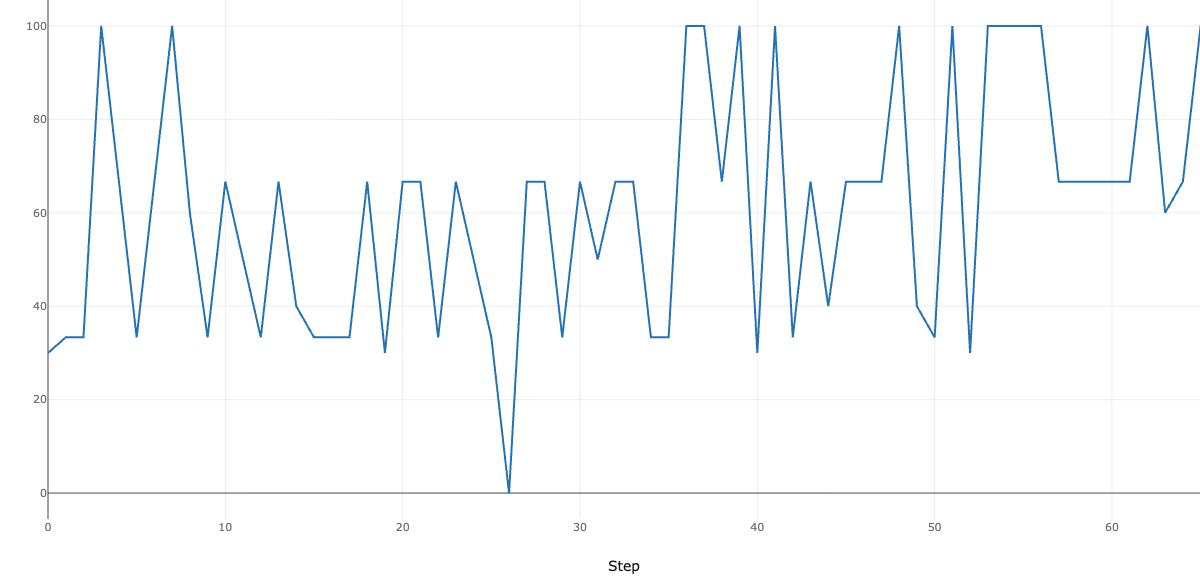
一方で、LLM-as-a-Judgeによる自動評価には判定の一貫性に課題があることが知られています。Gu らのサーベイ論文(A Survey on LLM-as-a-Judge)では、LLM評価器が同一の入力に対しても一貫しないスコアを出しうること、また文脈の微妙な変化が同じ入力への判定を変えうることが報告されています。さらに、高度な推論能力を持つモデルでも人間の評価との完全な一致には至っておらず、LLMに改善の余地があるとされています。こうした不一致を軽減するアプローチとして、同一評価の複数回実行による多数決や、今回紹介した最適化プロセスのように、人間のフィードバックを評価プロンプトに反映する反復的な最適化手法が提案されています。
本タスクでもこの特性が確認されました。最適化前の出力に含まれる「髄膜炎による頭痛は、発熱、嘔吐、けいれん、意識障害といった他の症状とほぼ必ず同時に現れ」という表現は「診断行為に該当する」とLLM-as-a-Judgeに判定されましたが、最適化後の出力にも類似の文言が含まれているにもかかわらず、こちらは診断行為と判定されていません。実際には、症状の一般的な説明はポリシー上の診断行為に該当しないため、人手チェックでいずれも問題なしと判断しリリースしています。
現手法の制約
GEPAは人手によるチューニング作業を減らす強力な手法ですが、実際に試した中で感じたいくつかの制約もあります。
単一のスカラー値を返す評価関数
今回実践した健康医療系クエリの改善のように、複数ある評価軸のスコアの平均を取ると、各軸の評価結果が埋もれやすくなります。ヒューリスティックに重み付けを行い、スコアの表現力を上げる方法も考えられますが、プロンプトチューニングを自動化したにもかかわらず今度は重みのハイパーパラメータチューニングが新たに発生する可能性があります。
人による評価にかかる時間
チューニング自体は1時間程度に高速化されましたが、自動最適化の前後に人手チェックが必要なため、そこがボトルネックになりえます。ただし、人のフィードバックを評価プロンプトに反映することで直接次の最適化の改善に生かせる側面もあります。
プロンプトの肥大化
GEPAが生成する最適化済みプロンプトには、評価結果から得られた個別事例がfew-shotのような形で多く挿入される傾向があります。本タスクでは最適化によりプロンプトが5,521文字から8,561文字へと約55%増加しました。推論コストやレイテンシへの影響を考慮する必要があります。
例えば、最適化後のプロンプトには以下のようなクエリタイプ別の具体的な構成例が追加さ�れています(抜粋・改変)。
### 4-3. 病名・症状系クエリ
- 基本構成:
1. 概要
2. 主な症状
- 例:「虚血性腸炎」
- 突然の腹痛(特に左下腹部)
- 腹痛に続く下痢
- 鮮血を含む血便
- 例:「マイコプラズマ肺炎 大人症状」
- 長く続く乾いた咳
- 38℃以上の発熱や弛張熱
- 倦怠感(だるさ)、頭痛
3. 原因・要因
4. 検査・治療の選択肢
5. 予防・生活上の注意このような個別事例の挿入がプロンプト肥大化の主因となっています。
差分情報を活用していない
現手法では各世代の候補プロンプトを個別に評価しており、前世代との差分(プロンプトの変更点と出力の変化の対応関係)を明示的に活用していません。言語処理学会第32回年次大会(NLP2026)で発表された研究では、直前と現在のプロンプト・推論結果の差分を分析し、改善箇所を自然言語で特定・修正する手法が提案されており、GEPAを上回る精度が報告されています(古賀ら, 2026)。
展望:基盤化と自律的プロダクト改善
改善ループの基盤化
現在は施策ごとに「評価設計 → 最適化実行 → 人手検証 → 反映」のサイクルを個別に回しています。今後はこの改善ループ自体を共通基盤として整備し、健康医療に限らず、検索・広告・コマース・社内業務など、ポリシー準拠が求められるLLM機能全般に横展開していくことを目指しています。
AIによる自律的プロダクト改善へ
さらに先の展望として、人間が介入しなくても自律的に改善が回り続ける仕組みを目指しています。
- 本番環境のモニタリングから品質劣化を検知し、自動で最適化を起動する
- 新たなポリシーが追加された際に、評価プロンプトの生成から最適化実行までを自動で回す
- 最適化結果の検証・承認フローのみ人が担い、改善の実行自体はAIが自律的に行う
単発の施策改善ではなく、プロダクトが自ら品質を維持・向上し続ける基盤を構築することが、サービスとしての目標になると考えています。
おわりに
本記事では、DSPyとGEPAを用いたプロンプト自動最適化の手法と、Yahoo!検索のAI回答における健康医療系クエリへの適用事例を紹介しました。
プロンプトチューニングを自動化することで、調整作業の工数を大幅に削減できるだけでなく、人が本来注力すべき評価設計やポリシー整備に時間を使えるようになります。プロンプトチューニングに課題を感じている方や、LLMを組み込んだ機能やサービスの品質改善を効率化したい方の参考になれば幸いです。ぜひ自身のタスクに合わせた評価関数を設計し、自動最適化を試してみてください!
Tech-Verse 2026 を開催します(6月29日)

この記事は、イベントの公式記事として公開されました。
Tech-Verse 2026は、LINEヤフーが開催する技術カンファレンスです。
最先端の挑戦や積み重ねてきた知識を共有します。
YouTube LIVE�での配信をぜひご覧ください。
https://tech-verse.lycorp.co.jp/2026/ja/


