This is the official article for Tech-Verse 2026, LY Corporation's technology conference.
As large language models (LLMs) scale their physical input thresholds to millions of tokens, the software engineering industry faces a deceptive paradigm: the silicon fallacy. The prevailing assumption is that massive context windows inherently equate to heightened operational intelligence. However, in production-grade agentic workflows - such as automated code factoring, continuous code review, and long-horizon software development loops - relying on passive "token stuffing" triggers severe failure states. Without active runtime governance, multi-head attention mechanisms suffer from information entropy accumulation, leading to reasoning degradation, context rot, and critical data leakage vulnerabilities.
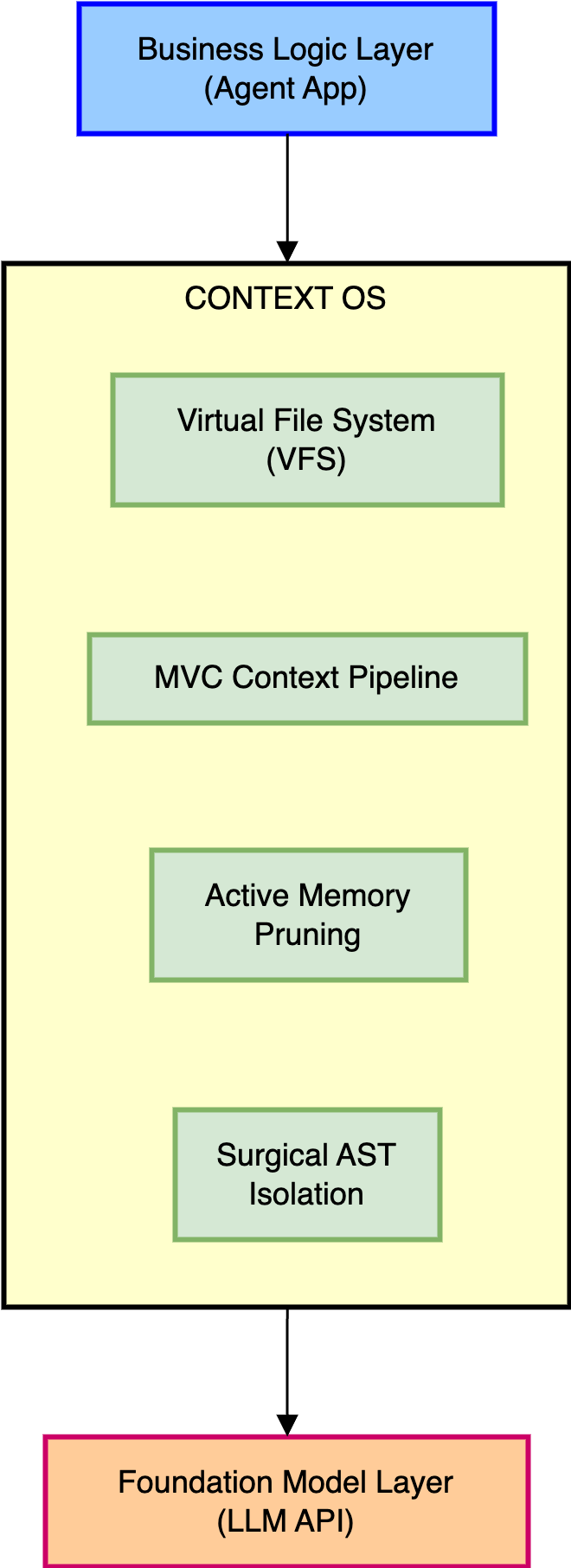
This article introduces the architecture of Semantic Context OS, a localized, high-throughput cognitive runtime substrate engineered to transform the context window from an unmanaged text stream into a deterministic system resource. Positioned as an intercepting loopback proxy (localhost:8080) between the autonomous agent application logic and external foundation APIs, Semantic Context OS implements a dedicated AI kernel. This kernel governs state topologies via a POSIX-like virtual file system (VFS), applies abstract syntax tree (AST) tree-pruning via the PathAlign stage, and executes in-flight token optimization using the asynchronous sawtooth memory model.
By establishing a clear separation of concerns between quantitative hardware-level token limits and qualitative semantic governance, Semantic Context OS shields downstream reasoning engines from structural noise and secures enterprise intellectual property. Ultimately, this framework establishes a mature, reproducible standard for architecting robust, secure, and cost-efficient autonomous software engineering agents at enterprise scale.
(Disclaimer: The term "Semantic Context OS" introduced in this article refers exclusively to an in-house, proprietary runtime substrate engineered by the authors for LLM attention governance and token lifecycle management within agentic workflows. It bears no relational, architectural, or trademark affiliation with commercial data integration platforms sharing similar nomenclature, such as ElixirData Context OS).
The "RAM crisis" & the long-context paradox
The Karpathy metaphor: Demystifying LLM memory dynamics
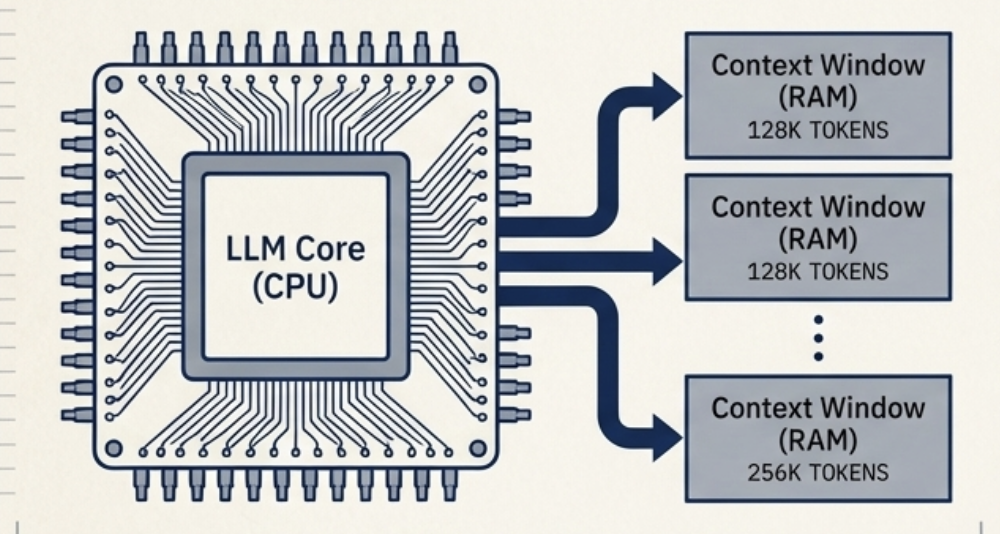
In modern software and distributed systems architecture, analogical reasoning serves as a powerful conceptual bridge to understand complex, non-deterministic computing paradigms. One of the most foundational frameworks for this is the Karpathy metaphor, which posits a clean structural alignment between traditional von Neumann computing architectures and LLM execution loops:
-
The LLM acts as the CPU: It's fundamentally a stateless, non-deterministic reasoning engine designed to execute complex mathematical instruction sets based on structural semantic patterns embedded within its pre-trained parametric weights.
-
The context window acts as RAM: It's the volatile, working memory space where the current execution state, historical telemetry, dynamic instructions, and runtime operational data must reside so that the core processor can maintain logic flow and state continuity.
 |  |
| Image created using generative AI | |
However as software engineers, we must recognize the exact boundaries where this metaphor fundamentally breaks down. In traditional computing engineering, physical silicon RAM operates on strict, deterministic, linear addressing. If a low-level pointer references a specific memory address such as 0x7FFF, the underlying operating system retrieves the exact byte stored at that precise coordinate with O(1) time complexity and 100% precision. This operation remains flawless regardless of whether the system is operating on 8 GB, 64 GB, or 128 GB of hardware memory.
Conversely, an LLM's contextual RAM is inherently probabilistic and non-linear. It relies entirely on the Attention Mechanism (Q, K, V matrices), where every single incoming token must compute a dense attention score against every other token in the sequence. Memory retrieval in an LLM is not an address lookup; it's a dynamic statistical distribution of relative weights. Consequently, expanding the physical capacity of the context window (for example, from 32 K tokens to 1 M or 2 M tokens) doesn't guarantee linear access precision. Instead, it exponentially scales the computational surface area, introducing systemic noise, structural degradation, and severe architectural vulnerabilities.
The attention dilution trap: The structural failure of massive context
The artificial intelligence industry is currently locked in what we define as the silicon fallacy - a brute-force engineering race to expand raw context windows under the assumption that larger input capacity inherently translates to higher operational intelligence. This approach ignores a critical mathematical reality embedded within the deep core of the Transformer architecture: the attention dilution trap. To demystify this failure state, we must evaluate the core mathematical computation of multi-head attention. Given Queries (Q), Keys (K), and Values (V), the scaled dot-product attention score is formulated as:
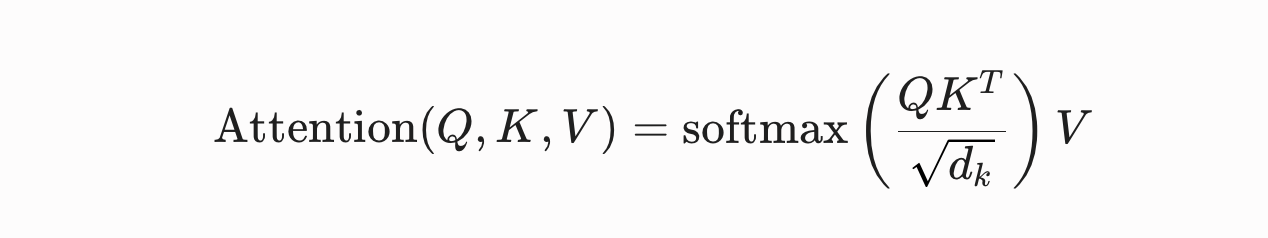
The mathematical vulnerability in long-context scaling doesn't stem from a naive linear flattening of the Softmax denominator itself. Rather, it's a direct consequence of information entropy accumulation within the dot-product matrix (QKT). In an enterprise codebase or extensive system logs, as the sequence length (N) scales exponentially, the payload introduces a massive volume of structural noise - such as boilerplate definitions, unreferenced imports, and redundant syntax tokens. Consequently, the Key matrix (K) becomes heavily populated with background vectors that exhibit low-amplitude, uniform semantic similarity to the Query (Q). When computing the dot product QKT, this high-dimensional noise generates a uniform distribution of attention logit scores with low variance. When passed through the Softmax exponential function, the energy distribution is mathematically forced to spread across an immense sequence area. This structural dispersion causes attention dilution: the sharp attention spikes (sharp delta distributions) required for precise factual retrieval are blunted into a high-entropy uniform distribution.
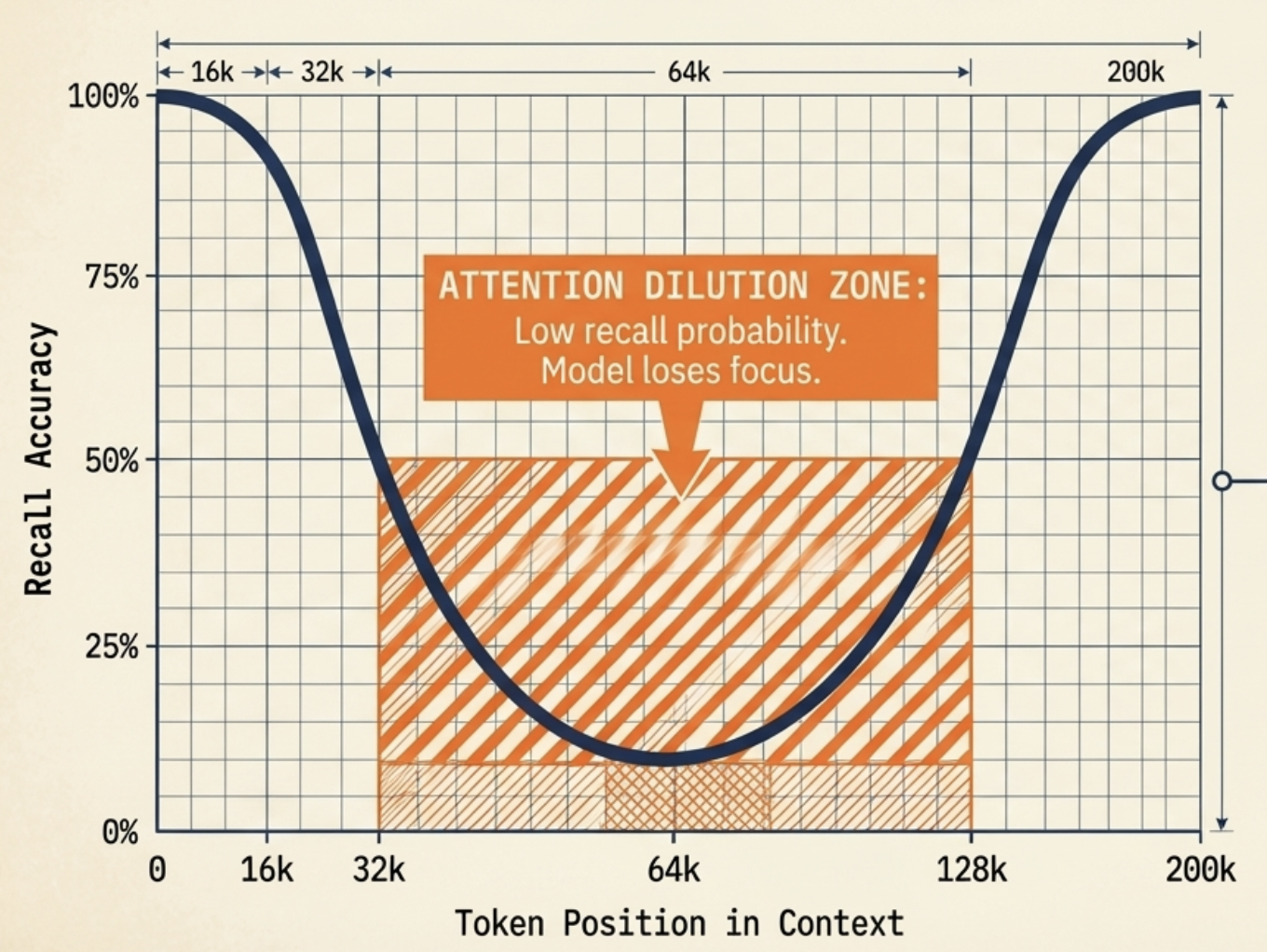
This mathematical dilution manifests in production environments as the well-documented "lost in the middle" phenomenon (originally isolated and empirically proven by Stanford University (Liu et al., 2023) via U-shaped retrieval accuracy curves). While an LLM can reliably retrieve information located at the absolute beginning of a payload (the primacy effect) or the absolute end of a payload (the recency effect), its structural retrieval accuracy decays dramatically within the middle 70% zone of the context window.
For enterprise-grade AI Agents tasked with complex software development lifecycle automation - such as reviewing tens of thousands of lines of code or tracing cross-service dependency graphs - this is an unacceptable margin of error. Relying on massive context windows without an active orchestration layer is an architectural anti-pattern that leads directly to reasoning degradation and severe logical failure.
The "context rot" pathologies in long-horizon tasks
When autonomous AI agents are deployed against complex, long-horizon tasks - such as automated enterprise code factoring, legacy migrations, or cross-service API contract validations - the state of the context window inevitably degrades over time. We define this systemic decay as context rot. Through empirical observation using runtime observability tracing, we have isolated three distinct architectural pathologies that constitute context rot:

-
Context poisoning: During multi-turn autonomous execution loops, the agent continuously appends historical raw data, system execution logs, and stale terminal error messages into the context window. This raw accumulation skews the attention matrix. The model begins to treat transient historical failures as active structural constraints, poisoning its ability to generate valid next-token distributions for the current task.
-
Context distraction: In large-scale, enterprise monorepos, identical naming conventions, overloaded methods, and duplicate auxiliary helper utilities frequently appear across entirely separate modules. When a standard retrieval mechanism dumps these unrelated code fragments into the context window, the attention mechanism suffers from structural distraction. The agent loses track of the core execution path because it cannot differentiate between the primary target logic and structurally similar but logically irrelevant code blocks.
-
Context clash: As an autonomous agent iterates through a multi-step execution plan, its internal prompt state must evolve. If the system fails to clear or update stale instructions from previous steps, the context window will concurrently host flatly contradictory directives (for example, "Step 1: Isolate the core database interface" vs. "Step 5: Merge the concrete implementation"). This layout creates a state of logical paralysis or infinite reasoning loops, causing the agent to stall, time out, or hallucinate.
Statistical telemetry indicates that without an active management layer, the failure rate of autonomous agents scales non-linearly with context depth, reaching an estimated 40% failure rate when encountering deeply nested codebase structures. This reality underscores the urgent engineering need to move past passive prompt stuffing and build a dedicated operating system to govern the context environment.
Bridge to architecture: The systemic decay introduced by context rot and the mathematical realities of attention dilution demonstrate that passive context accumulation is a structural dead-end for autonomous agents. To resolve these non-deterministic failure states, we must execute a fundamental architectural paradigm shift: we must transition from passive prompt engineering to an active, bounded governance layer. In the following section, we deconstruct the core engine designed to enforce this discipline - the Semantic Context OS AI kernel.
Architecting the AI kernel (VFS & MVC)
The paradigm shift: From passive prompts to active governance
To build resilient, enterprise-grade agentic workflows, systems engineers must execute a fundamental paradigm shift: We must stop treating context as a static text payload, and start managing it as a dynamic, bounded, and structured system resource.
Traditional implementation patterns rely on passive prompt engineering, where context is built incrementally by string concatenation and then stuffed blindly into the next API call. This approach forces the downstream foundation LLM to handle memory management, token optimization, and noise filtering implicitly within its hidden attention layers - a task it was never architecturally optimized to perform.
Our solution, Semantic Context OS, introduces a specialized AI kernel that sits directly between the application-level business logic and the raw foundation model layer. Semantic Context OS takes explicit ownership of memory logistics. It treats the context window as a finite hardware constraint, actively monitoring token lifecycles, governing state access, and applying strict isolation policies before a single token is transmitted over the wire.
The minimum viable context (MVC) pipeline
The architectural heart of Semantic Context OS is the MVC pipeline. Rejecting the "all-you-can-eat" philosophy of massive text dumps, the MVC pipeline enforces a strict technical policy: Provide the absolute minimum amount of highly purified, dense information required for the agent to successfully execute its immediate reasoning step.
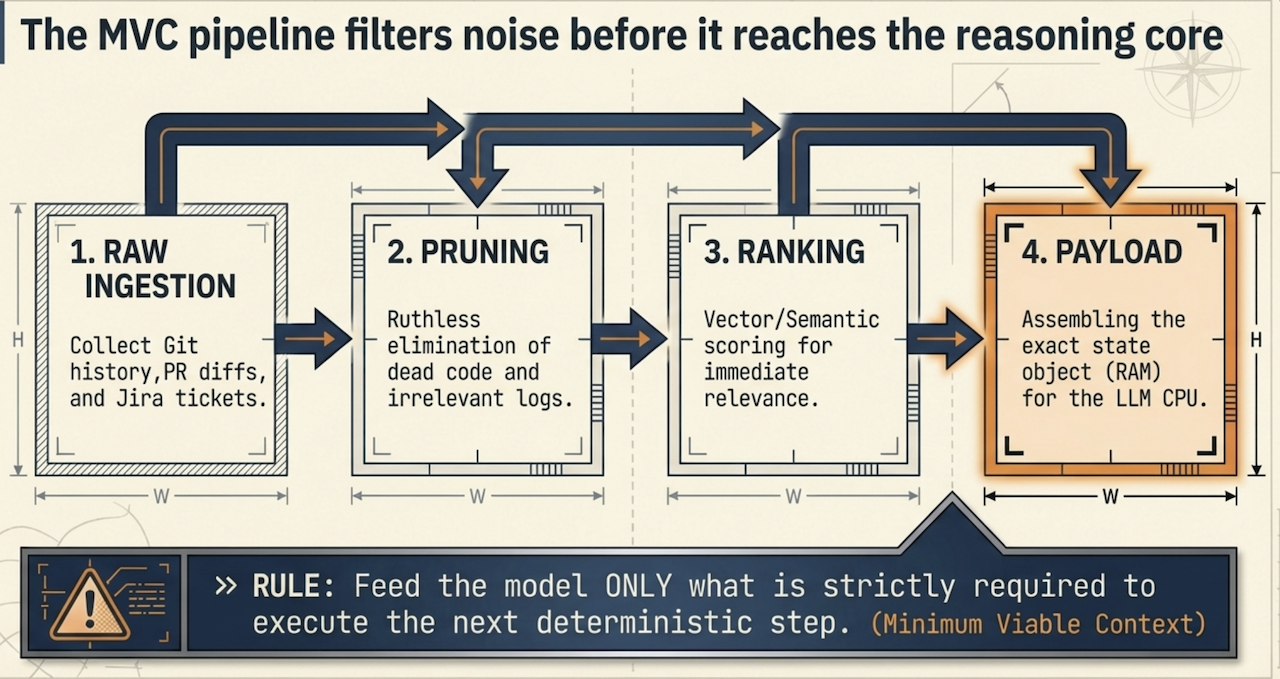
The MVC Pipeline processes all incoming contextual data through four distinct, high-throughput stages:
-
Ingestion & token mapping: Raw data sources (source files, dependency trees, runtime logs) are captured and mapped directly to their absolute token weights using exact model tokenizers (for example,
cl100k_baseoro200k_base). -
Structural pruning: The system evaluates incoming data using static code analysis and structural rules to instantly discard macro-level noise - such as compiler comments, unreferenced boilerplate imports, and unrelated utility code.
-
Semantic & dependency ranking: The remaining information is passed through a dual-scoring mechanism that combines semantic vector similarity with deterministic AST code dependency scoring to ensure perfect contextual alignment.
-
Payload stabilization & formatting: The final, optimized context is structured into clean, highly predictable JSON or XML envelopes, enforcing a consistent schema that mitigates structural hallucination at the model boundaries.
By keeping the context window permanently in this high-density, low-noise zone, the downstream LLM's attention heads remain perfectly focused on the critical task parameters, completely bypassing the attention dilution trap.
Implementing the VFS for agentic state management
To implement the MVC pipeline effectively, the AI kernel requires a highly structured mechanism to track, isolate, and manipulate different components of the agent's internal state. Semantic Context OS achieves this by abstracting the context window into a VFS, mimicking the standard directory structures of POSIX-compliant operating systems like Linux.
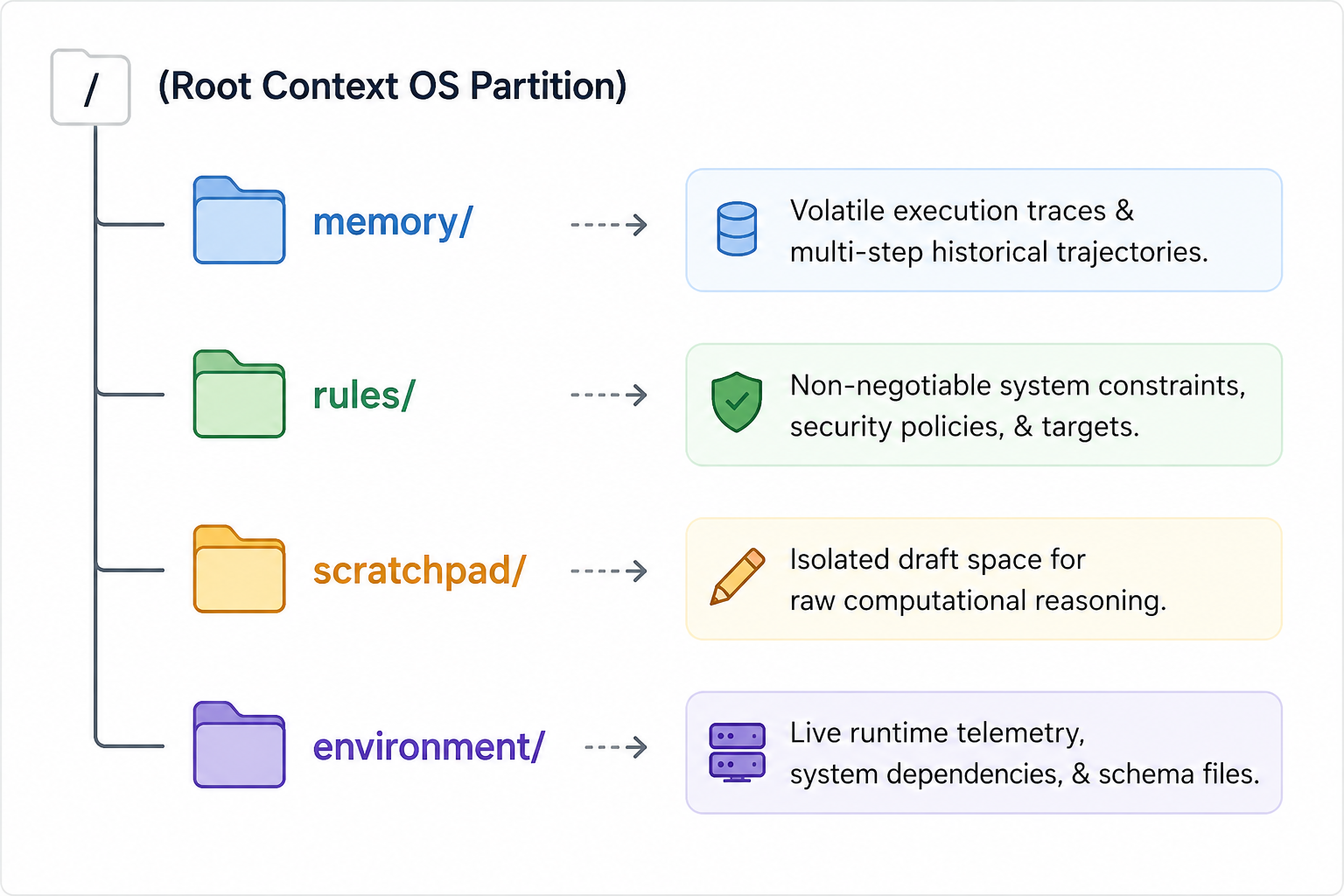
Instead of a flat, continuous block of text, the agent's working memory is partitioned into distinct, virtual logical drives:
-
The
/memorypartition: This partition manages the short-term volatile history of the active execution loop. It tracks exactly what steps the agent has performed, what logs were returned, and what sub-tasks have been completed. It's highly dynamic and subject to strict pruning policies. -
The
/rulespartition: This partition houses the non-negotiable architectural constraints, target coding standards, enterprise security policies, and strict definition-of-done criteria. This drive is protected with maximum attention weight, ensuring the agent never loses sight of core system guardrails, regardless of how deep the sub-task execution stack goes. -
The
/scratchpadpartition: This is a dedicated, isolated sandbox workspace. When the agent needs to perform multi-step planning, mathematical calculations, or code structural drafting, it executes these operations within/scratchpad. The data inside this partition is transient; once a logical conclusion is reached, the raw draft steps are discarded, and only the final, optimized result is promoted to the permanent core memory drive. - The
/environmentpartition: This partition serves as the runtime contextual anchor. It isolates and manages external environment metadata, schema definitions, live API specifications, and active cross-service system boundaries. By separating volatile environmental conditions from the agent's core instructions, the AI kernel can instantly swap, refresh, or update third-party service schemas when runtime dependencies shift - without polluting or resetting the underlying logical state of/memoryor/rules.
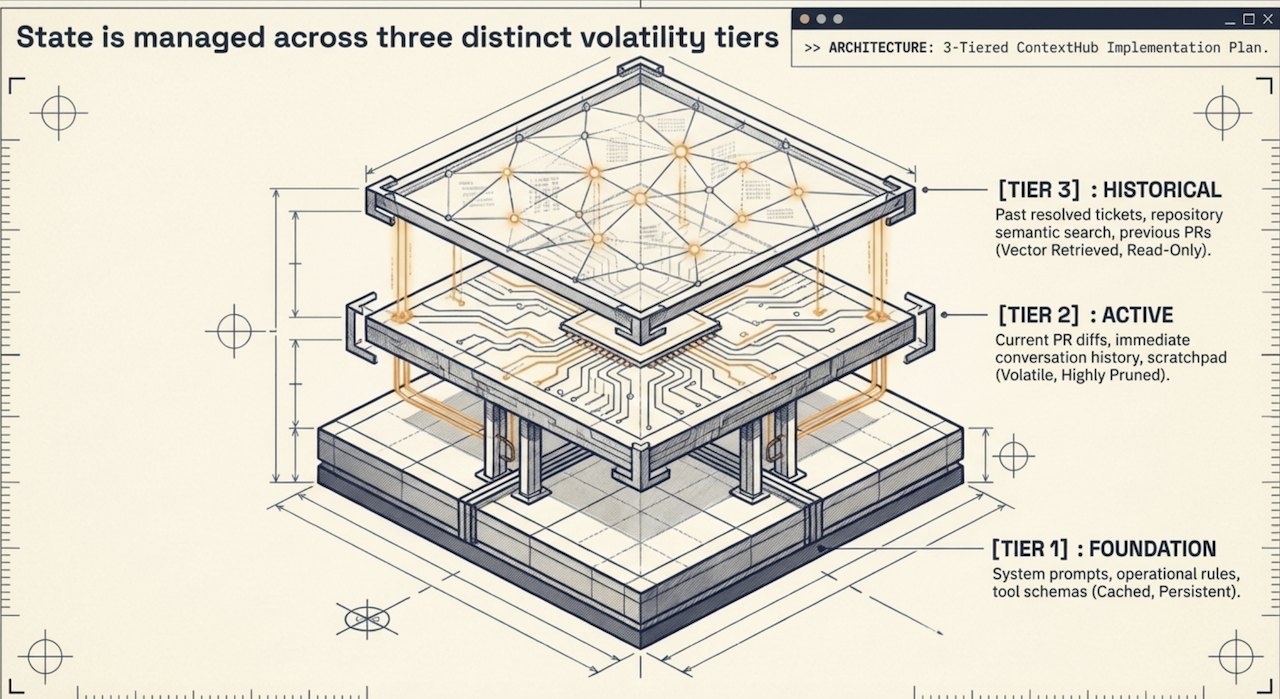
Through this VFS abstraction, Semantic Context OS can perform surgical, granular updates to specific memory segments without modifying or polluting the rest of the execution context. For instance, it can clear the volatile runtime logs in /memory/logs while keeping the system rules in /rules/security completely untouched, bringing deterministic order to the chaotic nature of LLM state tracking.
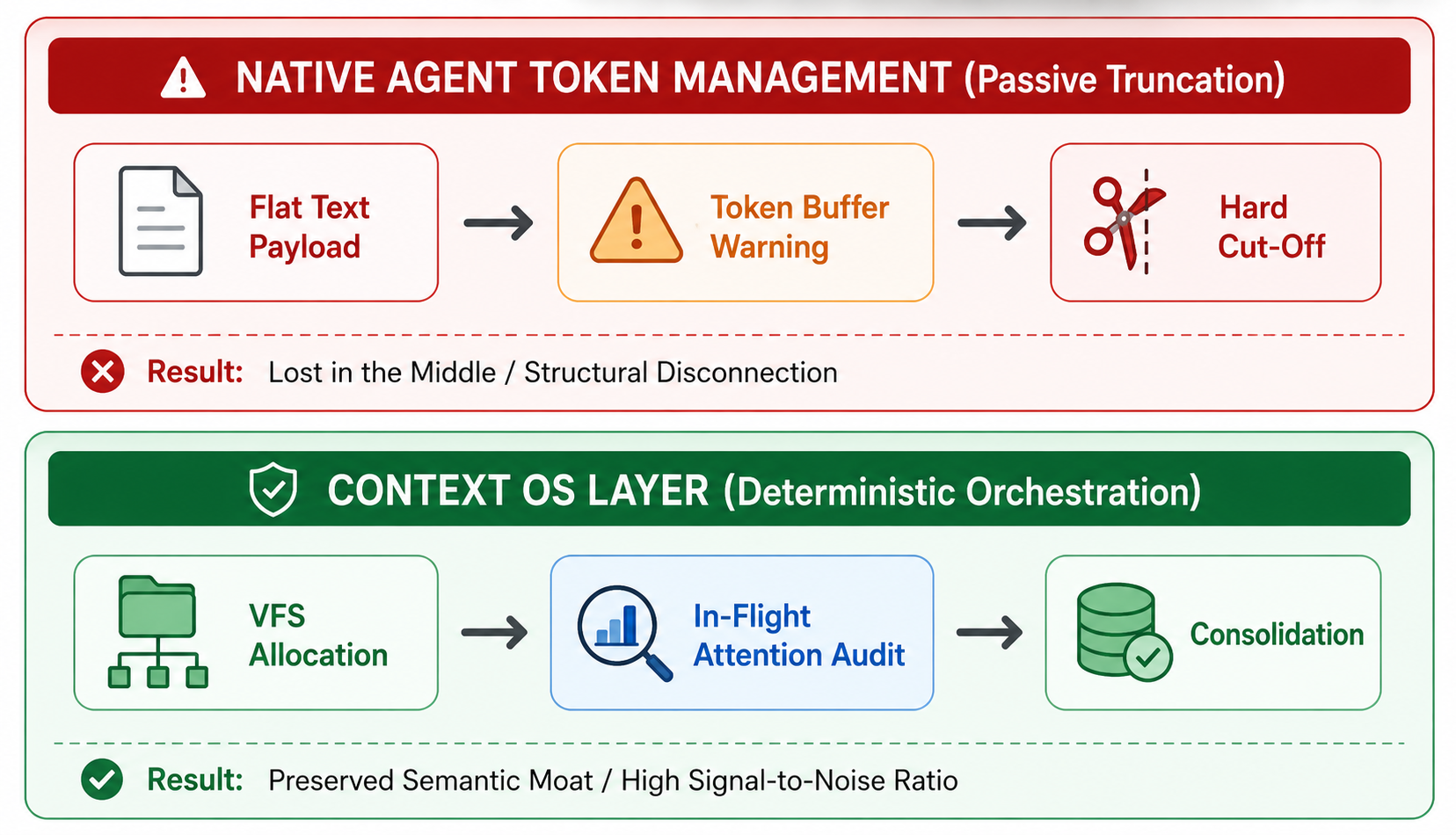
Architectural distinction: Beyond naive token management to Semantic Context OS
A foundational question arises when introducing the Semantic Context OS infrastructure: If modern agentic ecosystems - such as Claude Code, GitHub Copilot, or Codex - already possess built-in token management and prompt caching capabilities, does the implementation of a dedicated Semantic Context OS introduce redundant engineering overhead?
To resolve this apparent paradox, we must establish a strict separation of concerns between hardware-level compliance and cognitive runtime governance. Native client-side token management is fundamentally a quantitative infrastructure guardrail. Its role is blind boundary enforcement - monitoring string allocations and executing reactive truncation (FIFO) to prevent the downstream pipeline from throwing a hard HTTP 400 Bad Request or 429 Rate Limit error. It optimizes for api stability, not semantic reasoning density.
Semantic Context OS, conversely, operates as a qualitative semantic router and logic engine. It doesn't merely measure the volume of bytes passing over the wire; it actively structures, audits, and mutates the internal information topology based on domain-aware semantic execution paths.
| Evaluation vector | Native token management (infrastructure layer) | Semantic Context OS architecture (semantic layer) |
|---|---|---|
| Operational nature | Quantitative & blind to semantics (defensive) | Qualitative & domain-aware (orchestrated) |
| Primary objective | Hard boundary enforcement to prevent API exhaustion or failure | Attention maximization to eliminate reasoning drift and context rot |
| Mechanisms | Token counting, sliding-window eviction, and static prompt caching. | AST tree-pruning, active memory compaction, and dynamic scope overrides |
| Data topology | Flat text payload (contiguous string envelope containing all raw text data) | Bounded VFS partitions (/rules, /memory, /scratchpad, /environment) |
The execution paradox in production: A case study on rule conflicts
To understand the systemic failure of relying solely on native token management, consider a realistic enterprise scenario where an autonomous agent is deployed to perform a deep architectural refactoring across an inherited codebase.
If the pipeline relies exclusively on native token management: The system gathers all corporate style guidelines, regional repository conventions, and workspace documentation into a massive context window payload. Because the underlying token layer is blind to data relationships, it treats every file with equal weight.
If a global file (/global_rules.md) dictates that all interface methods must follow snake_case, while a hyper-focused local file (/src/modules/billing/rules.md) overrides this policy to enforce camelCase for concrete API serialization, both contradictory instructions are stuffed concurrently into the model's contextual RAM. The multi-head attention mechanism suffers immediate mathematical dilution, causing the agent to stall, fluctuate between patterns, or hallucinate invalid code interfaces.
When the system is governed by the Semantic Context OS architecture: Before a single token is serialized for transmission, the AI kernel intercepts the interaction loop and registers the active directory context into the VFS. The PathAlign engine parses the structural hierarchy of the rule files. Recognizing that the scoped billing rule block occupies a deeper, high-priority namespace path than the global configuration, the Kernel executes a dynamic rule collision override.
The conflicting global instruction is surgically stripped from the operational scope, and only the unified, high-density target instruction payload is promoted to the read-only /rules drive. The token envelope transmitted over the wire contains exclusively the distilled essence required for correct execution.
Bridge to execution: Localizing data partitions within a VFS and establishing enterprise-grade security boundaries provide the structural blueprint for a secure runtime substrate. However, maintaining this bounded context across multi-turn autonomous loops requires active, real-time computational execution. The next section delineates the low-level mathematical and programmatic routines - the sawtooth memory model and the PathAlign stage - engineered to actively enforce minimum viable context constraints in production under the Semantic Context OS architecture.
Active algorithms (sawtooth model & PathAlign stage)
The sawtooth memory model: Runtime active pruning execution algorithm
To enforce the constraints of the MVC pipeline across multi-turn autonomous operations without suffering from sudden out-of-memory errors or context truncation, Semantic Context OS implements the sawtooth memory model. This is an active runtime management algorithm that dynamically scales and optimizes token consumption.
Unlike passive data delivery frameworks, the sawtooth algorithm continually tracks the number of active tokens in the VFS partitions. As the agent interacts with external environments, the token count increases linearly, climbing towards a predefined saturation threshold.
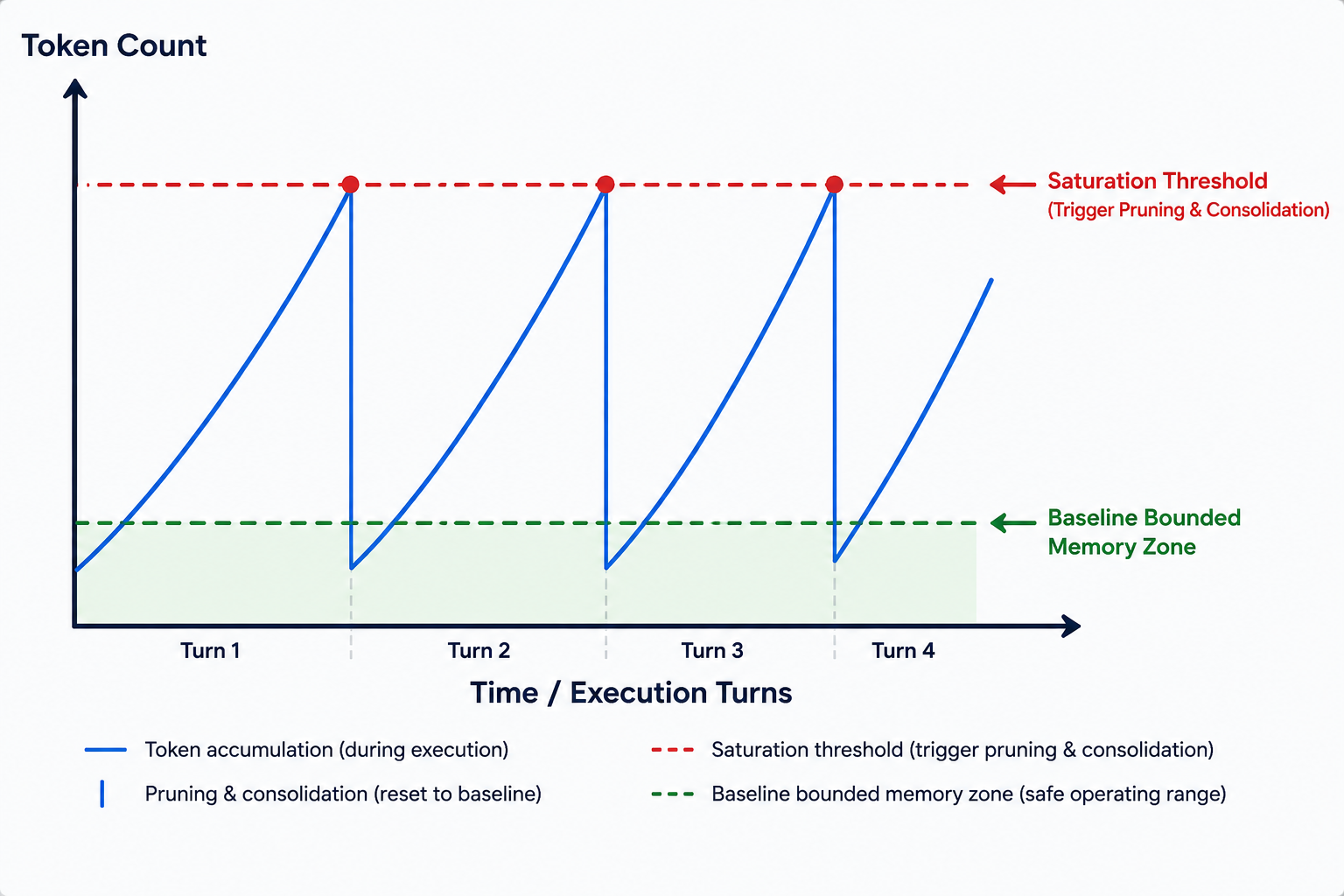
The moment this threshold is breached, the AI kernel halts execution and spawns a background compaction process that performs two major operations:
-
Surgical token pruning: Evaluates the cross-attention weight history of tokens inside
/memory. Tokens with weights falling below a certain standard deviation are immediately purged from the system. -
Semantic consolidation: Active text chains or multi-turn conversational logs are passed to a highly efficient utility model that compresses the raw historical conversational threads into dense semantic state vectors.
This compression drops the active token count back down to a safe base level, creating the distinctive "sawtooth" pattern on telemetry graphs. This cycle repeats indefinitely, keeping the agent bounded within its optimal reasoning zone.
Below is the conceptual algorithmic layout of the sawtooth mechanism:
# Pseudo-Code: Semantic Context OS In-Flight Memory Compaction Kernel Daemon
# Operating as an Asynchronous, Non-blocking Intercepting Middleware
class ContextOSKernel:
def __init__(self, vfs_driver, token_encoder, saturation_threshold=0.70):
self.vfs = vfs_driver
self.encoder = token_encoder
self.threshold = saturation_threshold
self.is_compacting = False
def on_agent_request_intercepted(self, request_payload):
"""
Triggered immediately when Claude Code / Codex dispatches an API payload.
Ensures the context window remains inside the optimal semantic zone before transmission.
"""
# Step 1: Compute real-time input token allocation across VFS partitions
active_tokens = self.encoder.count_allocated_tokens(self.vfs.read_partition('/memory'))
max_capacity = system_hardware_constraints.get_max_context_window()
current_usage_ratio = active_tokens / max_capacity
# Step 2: Evaluate the Saturation Threshold (Sawtooth Trigger Point)
if current_usage_ratio >= self.threshold and not self.is_compacting:
# Spawn asynchronous worker to prevent blocking the active client streaming IO loop
asynchronous_worker_pool.dispatch(self.execute_sawtooth_compaction)
# Step 3: Inject surgically isolated codebase graph from PathAlign Engine
purified_code_subgraph = PathAlignEngine.extract_syntax_subgraph(request_payload.target_files)
self.vfs.write_partition('/environment/codebase', purified_code_subgraph)
# Step 4: Re-serialize localized VFS states into a unified, high-density token envelope
return self.vfs.consolidate_to_raw_json_payload()
def execute_sawtooth_compaction(self):
"""
Asynchronous Kernel Routine executing in-flight pruning and semantic consolidation.
"""
self.is_compacting = True
try:
# Enforce an immutable isolation lock on system guardrails to prevent memory corruption
self.vfs.acquire_write_lock('/rules')
# Fetch diagnostic matrix telemetry (e.g., from Langfuse or local runtime trace)
attention_metrics = telemetry_engine.get_active_attention_logs()
# Identify target nodes containing obsolete execution outputs, stale errors, or duplicated traces
stale_nodes = self.filter_low_weight_tokens(
target_partition=self.vfs.read_partition('/memory/history'),
weights=attention_metrics
)
# Execute Surgical Pruning
for node in stale_nodes:
self.vfs.delete_node(node)
# Execute Lossless Semantic Consolidation on long conversational turns
raw_history_chain = self.vfs.read_partition('/memory/history')
# Compress raw logs into structured state vectors while strictly protecting critical entities
consolidated_state_vector = state_summarizer_utility.compress(
payload=raw_history_chain,
policy="Preserve entity names, function signatures, error codes, and compliance constraints"
)
# Commit consolidated vector and release the pipeline
self.vfs.write_partition('/memory/consolidated_state', consolidated_state_vector)
self.vfs.clear_partition('/memory/history')
finally:
self.vfs.release_write_lock('/rules')
self.is_compacting = False
logger.info("Sawtooth memory compaction cycle executed successfully. Optimal context restored.")The sawtooth memory model, on the other hand, is an autonomous, algorithmic kernel routine. It doesn't wait for a failure to happen; it proactively monitors attention decay and restructures memory patterns in flight, maintaining absolute system stability.
Surgical context retrieval: The PathAlign stage
When applying LLM agents to software intelligence tasks - such as automated code reviews, vulnerability discovery, or automated refactoring - traditional semantic vector search (standard RAG) fails completely. Code is not natural language. Breaking a codebase into flat text blocks based on fixed character limits (chunking) completely destroys the semantic syntax tree, breaking crucial import graphs and parent-child dependencies.
To solve the needle in a haystack trap within large repositories, our proposed architecture, Semantic Context OS introduces the PathAlign stage. PathAlign replaces vector distance lookup with AST-based isolation.
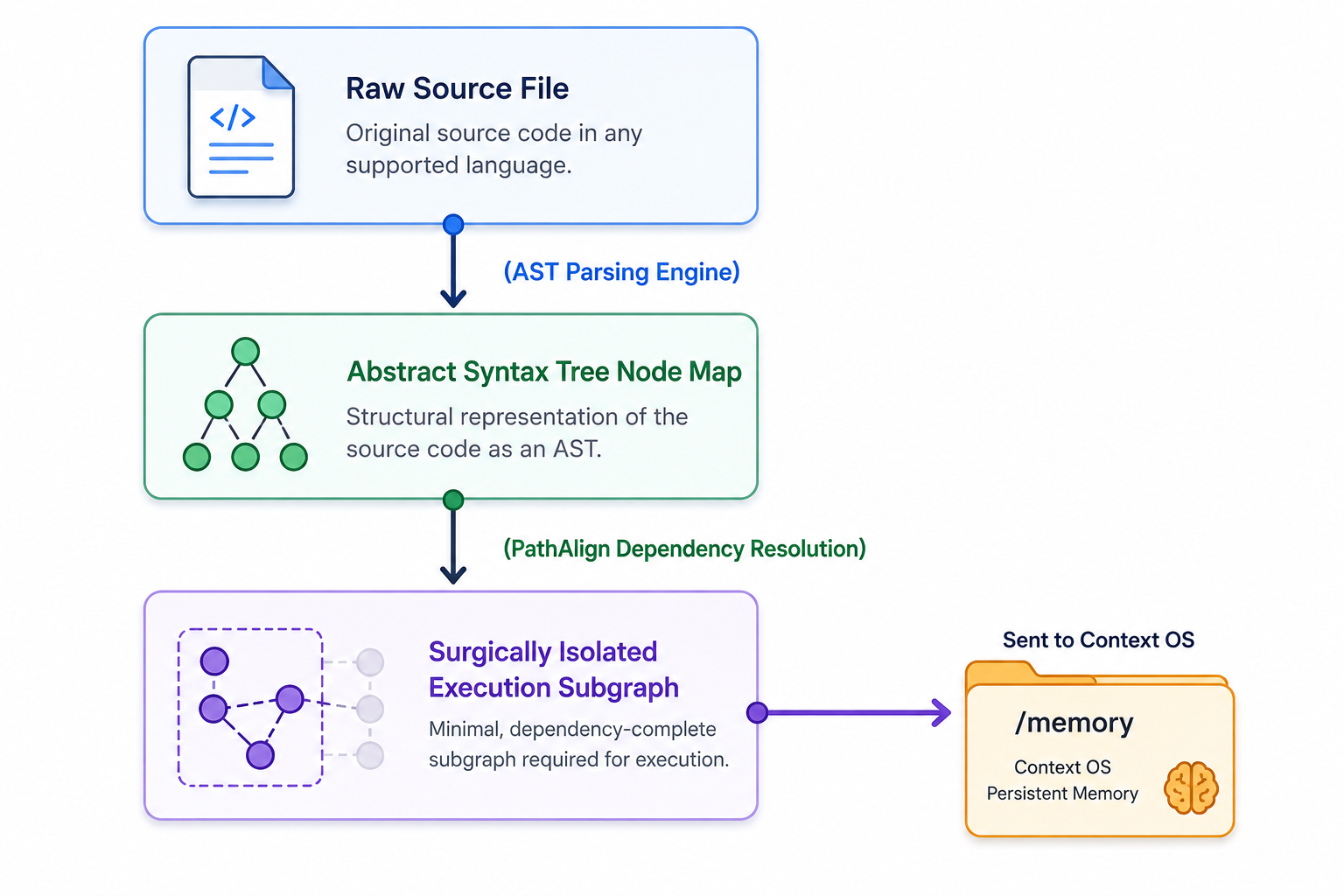
When an agent needs to examine a specific business function or investigate an error trace across a large system, PathAlign executes the following low-level sequence:
-
Static AST parsing: Compiles the targeted source files into memory as hierarchical syntax trees, identifying every class definition, interface implementation, function call, and variable reference.
-
Control-flow & dependency resolution: Traces the explicit execution path outward from the target function node, mapping its exact dependencies and downstream callers.
-
Contextual graph isolation: Isolates only the explicit execution subgraph required to understand the code path, completely cutting away unrelated comments, secondary helper functions, and disconnected lines of code.
This surgically isolated execution graph is formatted into a high-density structured payload and placed directly into the VFS, allowing the agent to locate complex errors within massive repositories without suffering from attention dilution.
Bridge to evaluation: While the algorithmic mechanics of the Sawtooth daemon and PathAlign parser bring deterministic order to token governance within the Semantic Context OS, their systemic viability must be audited through an empirical framework. Moving past subjective, vibe-based verification, the next section outlines our proposed engineering telemetry and details the targeted performance trajectories designed to mathematically validate the system.
Performance evaluation framework & design objectives
The proposed observability methodology & verification strategy
Recently, the evaluation of AI agents within enterprise platforms has suffered from a critical lack of engineering rigor, often relying on subjective visual analysis colloquially known as "vibe-based engineering". To establish absolute technical discipline, this section outlines our proposed architectural evaluation framework designed to mathematically audit context lifecycles.
-
Intended telemetry via Langfuse tracing: The target architecture integrates live tracking IDs at the boundary of every VFS partition swap. This framework is designed to capture attention distribution maps, logging exactly how individual heads react during runtime memory compaction loops.
-
The golden dataset blueprint: To stress-test reasoning consistency, we have designed a specialized repository baseline composed of 30 complex engineering Pull Requests. This suite incorporates multi-file cross-dependencies and complex code branches to serve as an objective evaluation baseline.
The estimated performance trajectories & empirical objectives
Initial small-scale execution passes conducted during the prototype phase indicate positive performance trajectories when contrasting our legacy baseline model (v1.1.0 - standard string aggregation) with the v2.0.0 Context OS active memory architecture.
-
Methodology Alignment Disclaimer: The metrics detailed below represent core architectural design targets and expected optimization trends. The evaluation harness is undergoing continuous methodology calibration to ensure absolute statistical reproducibility before deployment across full-scale enterprise production workloads.
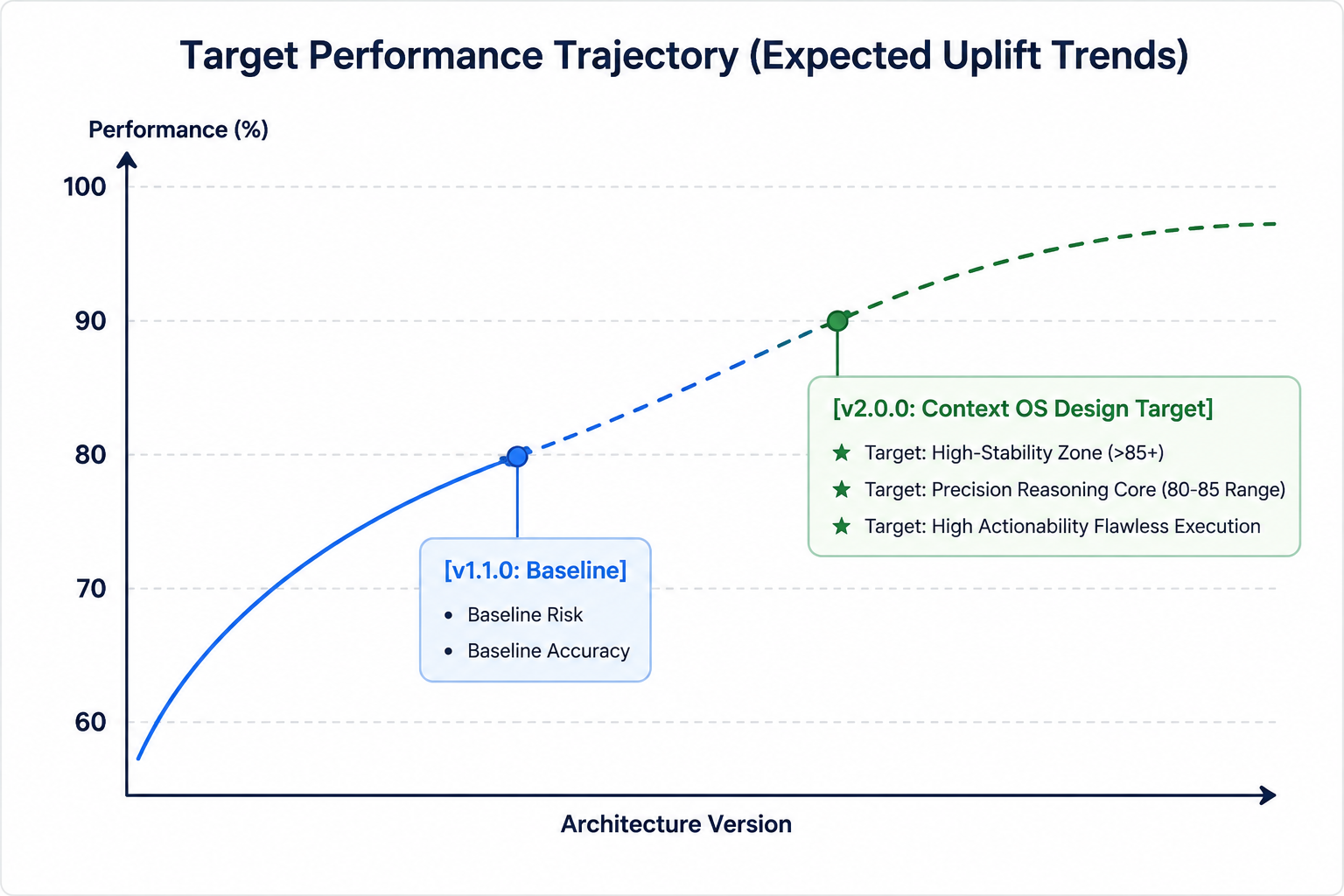
Trajectory 1: Resource optimization and token consumption limits
During initial execution loops, the active compaction mechanism inside the sawtooth memory model demonstrated a clear downward trajectory in total token allocation, targeting an expected 20% to 25% reduction in raw token overhead compared to the baseline v1.1.0. By systematically dropping low-weight historical nodes from /memory, the system targets a highly optimized runtime footprint.
Trajectory 2: Precision growth and signal-to-noise allocation
Under the legacy v1.1.0 baseline, the agent's Technical Accuracy score was structurally limited by attention decay inside the "lost in the middle" zone. Under the v200 framework, early tracking maps a targeted improvement into the optimal 80+ precision zone. This trajectory is driven by the PathAlign stage, which yields an estimated 15% to 20% improvement in the Signal-to-Noise ratio by ensuring that only compiled syntax graphs reach the model boundaries.
Trajectory 3: Governance continuity and risk assessment bounds
The most critical trajectory shift occurs within the Risk and Impact Assessment metric, tracking upward toward a highly resilient target zone of 85-90+. By locking foundational policies inside the read-only /rules VFS partition, the system architecture structurally prevents the agent from forgetting or drifting away from corporate compliance guidelines during long, multi-turn reasoning workflows.
Conclusion: The enterprise competitive moat
Models are commodities, context architecture is intellectual property
As the artificial intelligence ecosystem continues to evolve at a breakneck pace, the baseline capabilities of frontier foundation models are rapidly consolidating. Raw reasoning power, native context window sizes, and pricing structures are becoming commoditized across major cloud providers. In this landscape, simply invoking an API or appending strings to a prompt no longer constitutes a sustainable engineering advantage; it's basic plumbing.
The definitive competitive moat for enterprise AI systems in 2026 doesn't reside within the weights of the foundation model. It resides entirely within the orchestration layer that governs the input environments of those models.
Semantic Context OS represents a mature, systematic step toward true autonomous reliability. By introducing an active AI kernel, enforcing a strict minimum viable context pipeline, abstracting memory via a structured VFS, and applying advanced runtime compaction algorithms like the sawtooth model, we transform the chaotic, non-deterministic nature of LLM attention into a highly disciplined, enterprise-grade runtime asset.
Ultimately, mastering the context layer is the final engineering barrier to building AI agents that do not simply generate text, but reliably execute complex software engineering tasks at scale.
Architecting provenance & references
To maintain strict engineering integrity and professional transparency, this section delineates the boundaries between established industry methodologies and the specific technical inventions introduced by our team within the Context OS framework.
Industry standard foundations
The theoretical boundaries of our research build upon foundational paradigms developed by the global artificial intelligence community:
- The CPU-RAM Analogy (The Karpathy Metaphor): Originally posited by Andrej Karpathy to illustrate the conceptual alignment between LLM reasoning loops and modern computing architectures.
- The "Lost in the Middle" Pathology: Documented in the structural evaluation paper Lost in the Middle: How Language Models Use Long Context by Stanford University (Liu et al., 2023).
- Scaled Dot-Product Attention: The mathematical formulation of Multi-Head Attention mechanisms (Q, K, V matrices) inherited from Google's foundational paper Attention Is All You Need (Vaswani et al., 2017).
Core technical inventions by the authors
The following components represent original system architectures, algorithms, and implementations engineered entirely by the authors from scratch to solve enterprise scaling bottlenecks:
- The Semantic Context OS Framework: The paradigm shift of embedding an independent AI kernel as a local intercepting loopback proxy (
localhost:8080) to manage deterministic memory allocation. - The VFS State Engine: The abstraction of the flat token space into distinct POSIX-like directory partitions (
/rules,/memory,/scratchpad,/environment) to enforce strict behavioral isolation guardrails. - The sawtooth memory model: The dynamic, in-flight runtime compaction algorithm and asynchronous event-driven token optimization daemon detailed in "The sawtooth memory model" section.
- The PathAlign Stage: The specific static analysis methodology leveraging AST tree-pruning at the network boundary to isolate compiler execution subgraphs.
Tech-Verse 2026 to Be Held on June 29

This article has been published as the official article for the event.
Tech-Verse 2026 is a technology conference hosted by LY Corporation.
Explore cutting-edge challenges and real-world insights.
Be sure to watch the event live on YouTube LIVE.
https://tech-verse.lycorp.co.jp/2026/en/


